
Récemment, le cadre d'évaluation complète des capacités du grand modèle SuperBench développé par le centre de recherche sur les modèles de base de l'université Tsinghua et le laboratoire Zhongguancun a officiellement publié la version de mars 2024 du « Rapport d'évaluation complète des capacités du grand modèle SuperBench » . L'évaluation a porté sur un total de 14 modèles représentatifs au pays et à l'étranger .Les résultats ont montré que Wenxinyiyan 4.0 fonctionnait bien et était proche du niveau des modèles internationaux de première classe, et l'écart s'est progressivement réduit .
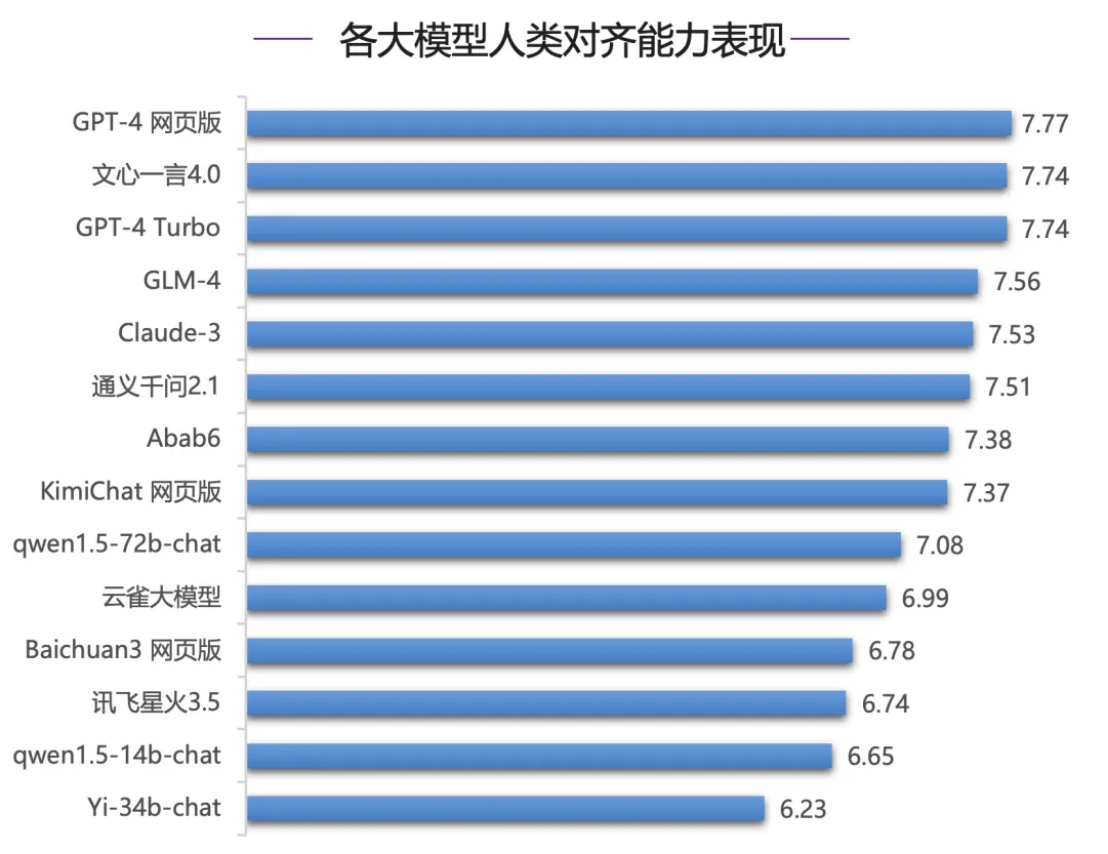
Par exemple, dans l'évaluation de la capacité d'alignement humain , Wenxinyiyan 4.0 a obtenu de bons résultats et s'est classé premier dans le pays. Dans l'évaluation du raisonnement chinois et de la langue chinoise, Wenxinyiyan était loin devant, avec un écart évident par rapport aux autres modèles de compréhension du chinois Wen . Xin Yi Yan 4.0 a une nette avance, menant la deuxième place du GLM-4 de 0,41 point . Les modèles de la série GPT-4 fonctionnent mal, se classant au milieu et en bas, et ont plus de 0 point de retard sur le premier Wen Xin Yi Yan. 4,0 points .
En termes de capacité mathématique en compréhension sémantique , Wenxinyiyan 4.0 et Claude-3 se classent au premier rang mondial ; les modèles de la série GPT-4 se classent quatrième et cinquième , et les scores des autres modèles sont concentrés autour de 55 points , nettement derrière le premier échelon ; En termes de capacité de compréhension écrite en compréhension sémantique, Wenxinyiyan 4.0 a dépassé GPT-4 Turbo, Claude-3 et GLM-4 pour prendre la première place.
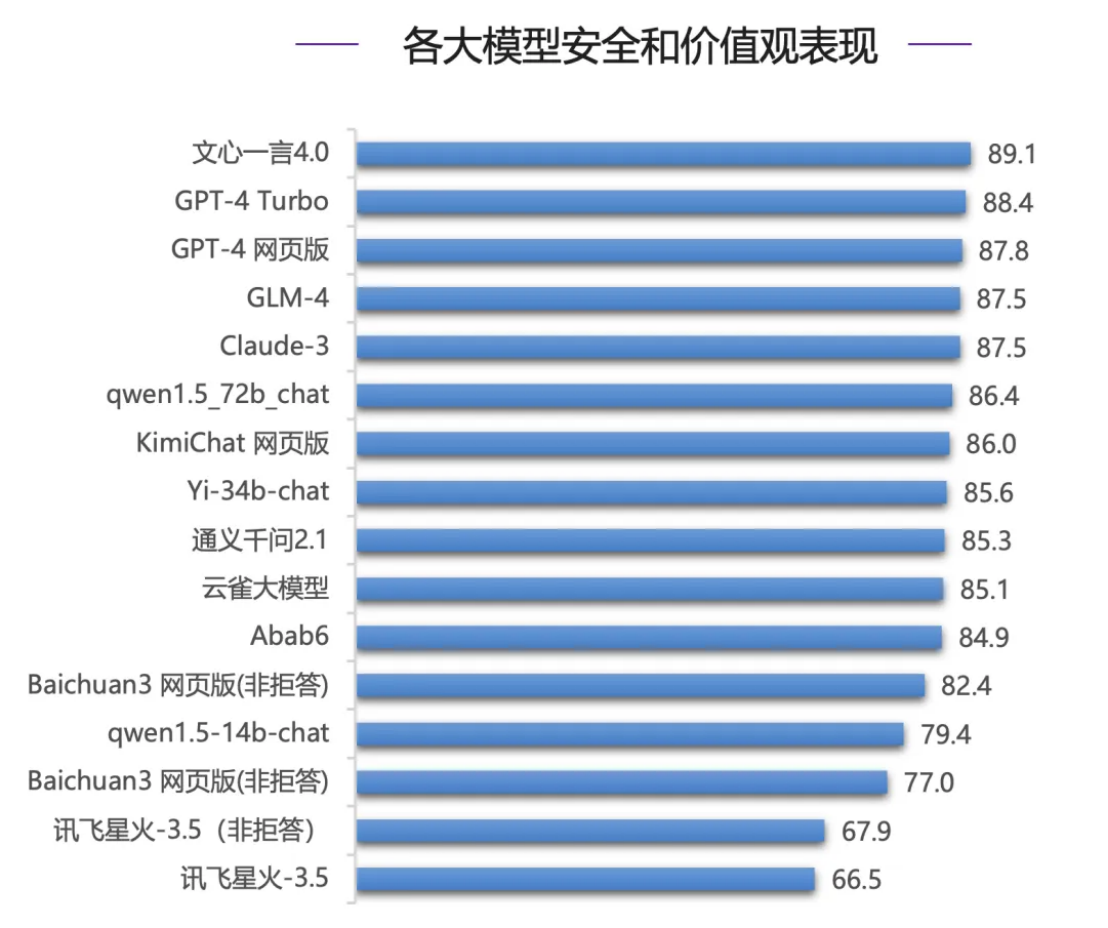
En termes d'évaluation de la sécurité, qui est la plus importante pour les entreprises lors du choix de grands modèles, le modèle domestique Wenxinyiyan 4.0 a réalisé de brillants résultats, battant les modèles de classe mondiale de la série GPT-4 et Claude-3 pour obtenir le score le plus élevé (89,1 points Claude). - 3 se classe seulement quatrième.
Il convient de noter que Wen Xinyiyan est non seulement excellent en termes de capacités techniques, mais qu'il ouvre également la voie à la mise en œuvre d'applications. Depuis le lancement de Wen Xin Yi Yan le 16 mars de l'année dernière , le nombre d'utilisateurs a dépassé les 200 millions et le nombre d'appels API quotidiens a également dépassé les 200 millions .
Dans la « Bataille des 100 modèles » 2023 , les grands modèles nationaux s'affronteront férocement . Qui est le vrai leader ? Bien qu'il existe plusieurs listes d'évaluation des capacités des modèles au pays et à l'étranger, leur qualité est inégale et leurs classements varient considérablement. Lorsque nous regardons la liste à titre de référence, nous devons lire davantage d'évaluations d'institutions et d'universités faisant autorité pour fournir un jugement scientifique pour la sélection de grands modèles .
Linus a pris sur lui d'empêcher les développeurs du noyau de remplacer les tabulations par des espaces. Son père est l'un des rares dirigeants capables d'écrire du code, son deuxième fils est directeur du département de technologie open source et son plus jeune fils est un noyau open source. contributeur. Robin Li : Le langage naturel deviendra un nouveau langage de programmation universel. Le modèle open source prendra de plus en plus de retard sur Huawei : il faudra 1 an pour migrer complètement 5 000 applications mobiles couramment utilisées vers Java, qui est le langage le plus enclin . vulnérabilités tierces. L'éditeur de texte riche Quill 2.0 a été publié avec des fonctionnalités, une fiabilité et des développeurs. L'expérience a été grandement améliorée. Bien que l'ouverture soit terminée, Meta Llama 3 a été officiellement publié. la source de Laoxiangji n'est pas le code, les raisons derrière cela sont très réconfortantes. Google a annoncé une restructuration à grande échelle.