
Lors de la conférence du printemps 2024, Kangaroo Cloud a présenté une nouvelle version de la version V6.2 du produit de pile de données . Parmi eux, EasyMR, en tant que fonctionnalité clé de la pile de données V6.2, représente la compréhension approfondie et l’innovation continue de Kangaroo Cloud de l’écosystème du Big Data.
EasyMR (ci-après collectivement appelé EMR) est un moteur informatique élastique construit par Kangaroo Cloud basé sur des composants open source tels que Hadoop, Hive, Spark, Flink et HBase. Il fournit des solutions sécurisées, fiables, évolutives de manière élastique et à faible coût. services de stockage de données et informatiques . Parmi eux, la plateforme de gestion de l'exploitation et de la maintenance du Big Data au niveau de l'entreprise EasyManager, développée indépendamment , prend en charge les fonctions centralisées de création, de gestion, de déploiement, d'exploitation, de maintenance et de surveillance des clusters Hadoop, fournissant ainsi une solution de centre de données efficace.
Face aux besoins croissants des entreprises en matière de traitement et d'analyse des données, la version EMR6.2 offrira aux utilisateurs de meilleurs services d'exploitation et de maintenance du Big Data et une optimisation des performances informatiques. Ce qui suit est une introduction détaillée à l'optimisation des quatre fonctions principales de la version EMR6.2 pour aider les utilisateurs à pleinement comprendre ce produit innovant.
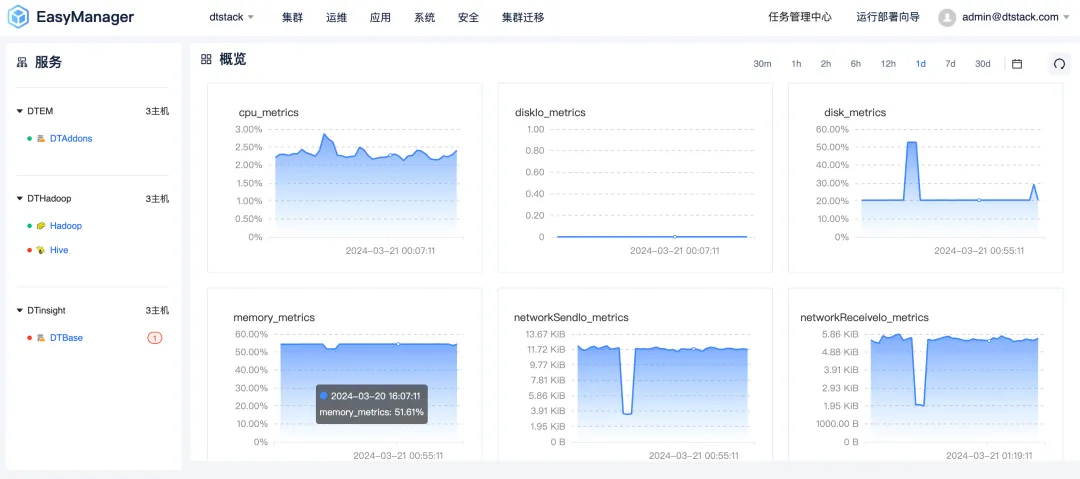
Interface utilisateur entièrement rafraîchie et améliorée : expérience interactive simple et confortable
Kangaroo Cloud comprend l'importance de l'expérience utilisateur, c'est pourquoi dans la version EMR6.2, nous avons entièrement actualisé et mis à niveau l'interface utilisateur. La nouvelle conception de l'interface suit un style simple mais élégant, visant à offrir aux utilisateurs une expérience interactive intuitive et confortable. Que vous soyez novice ou utilisateur expérimenté, vous pouvez rapidement démarrer et gérer facilement des clusters Big Data complexes.
En outre, nous avons également optimisé la vitesse de réponse et la fluidité de fonctionnement de l'interface pour garantir que les utilisateurs puissent profiter d'une expérience de fonctionnement plus fluide pendant l'exploitation et la maintenance du cluster .
Configuration différenciée : répondre à des besoins divers
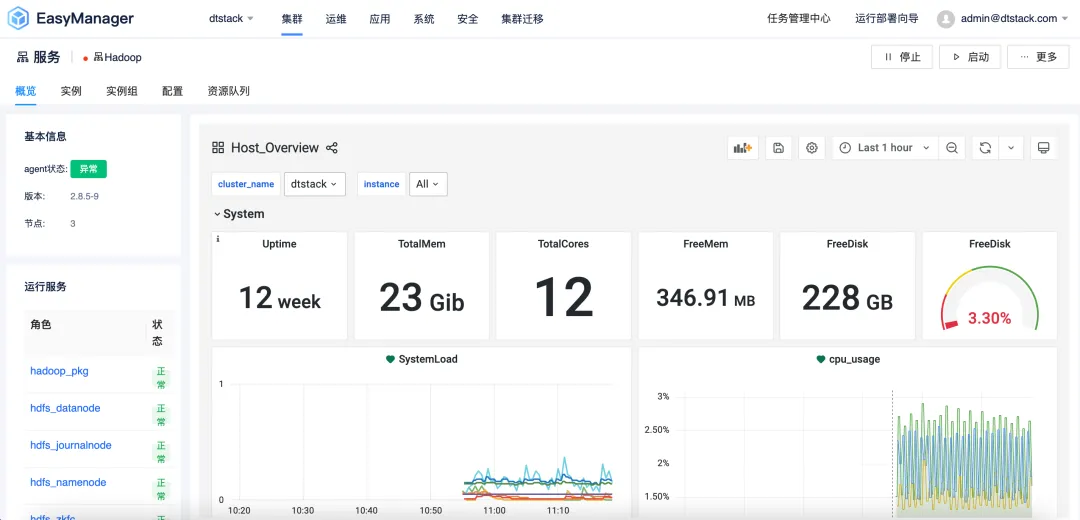
La version EMR6.2 introduit la fonction de configuration différenciée par groupe d'instances , permettant aux utilisateurs de personnaliser la configuration du cluster en fonction de leurs besoins spécifiques. Les utilisateurs peuvent créer des groupes d'instances indépendants à partir de différents nœuds du cluster EMR et définir des paramètres de configuration spécifiques dans le groupe d'instances pour obtenir de meilleures performances, une meilleure utilisation des ressources et une meilleure planification des tâches.
Qu'il s'agisse d'une start-up sensible aux coûts ou d'une grande entreprise ayant des exigences de performances plus élevées, EMR6.2 peut fournir des options de configuration flexibles pour répondre aux besoins des différents utilisateurs.
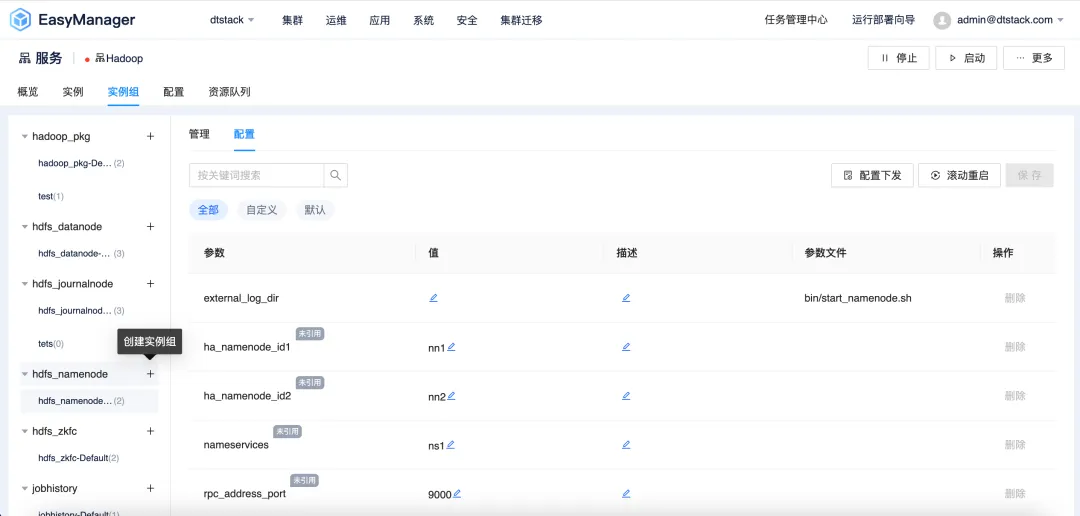
Les avantages spécifiques de la mise en œuvre de stratégies de configuration différenciées pour les groupes d'instances incluent, sans s'y limiter, les éléments suivants :
● Allocation des ressources
Une configuration différenciée peut mettre en œuvre efficacement une allocation affinée des ressources en fonction des besoins uniques de diverses tâches, couvrant plusieurs niveaux tels que les ressources informatiques, de stockage et de réseau. Évitez le gaspillage de ressources et améliorez leur utilisation pour garantir que toutes les tâches du cluster sont prises en charge par des ressources appropriées.
●Optimisation de la planification des tâches
Pour différents types de tâches ou de travaux, différents paramètres de configuration peuvent être définis en fonction de leurs caractéristiques afin d'optimiser la planification des tâches et l'efficacité de l'exécution.
● Tolérance aux pannes et stabilité
Grâce à une configuration différenciée, la tolérance aux pannes et la stabilité du cluster peuvent être améliorées. En fonction de l'importance et de la charge du nœud ou du groupe d'instances, différents mécanismes de tolérance aux pannes et stratégies de gestion des pannes peuvent être définis pour garantir que le cluster peut maintenir un fonctionnement stable face à des situations anormales.
● Gestion des coûts
Une configuration différenciée peut également aider à gérer les coûts. Selon les besoins de l'entreprise et les contraintes budgétaires, différents groupes d'instances du cluster peuvent être raisonnablement configurés pour éviter le gaspillage de ressources, réduire les coûts d'exploitation et de maintenance et trouver un équilibre entre performances et coûts.
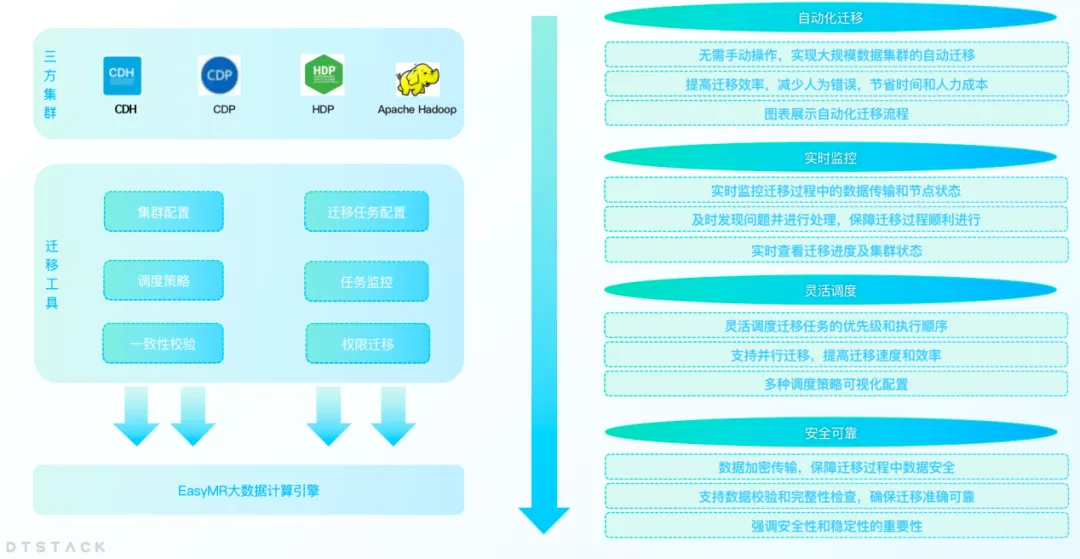
Migration de cluster : transition transparente sans interruption de l'activité
À mesure que les activités d'une entreprise se développent, la quantité croissante de données entraîne souvent des problèmes tels qu'une capacité insuffisante du centre de données ou des modifications du centre de données. Les entreprises doivent migrer les données d'un centre de données à un autre. Dans le même temps, dans le contexte du remplacement de la localisation, de plus en plus d'entreprises migrent des plates-formes non innovantes telles que CDH, HDP et CDP vers des plates-formes Big Data localisées. Par conséquent, EMR a lancé une fonction de migration de cluster Big Data pour aider les entreprises à mener à bien la migration efficace des centres de données.
La fonctionnalité de migration de cluster permet aux utilisateurs de migrer de manière transparente leurs clusters Big Data entre différents centres de données ou services cloud sans se soucier de la perte de données ou de l'interruption de l'activité. Grâce à cette fonctionnalité, les entreprises peuvent ajuster leur infrastructure informatique de manière plus flexible pour s'adapter aux besoins changeants du marché.
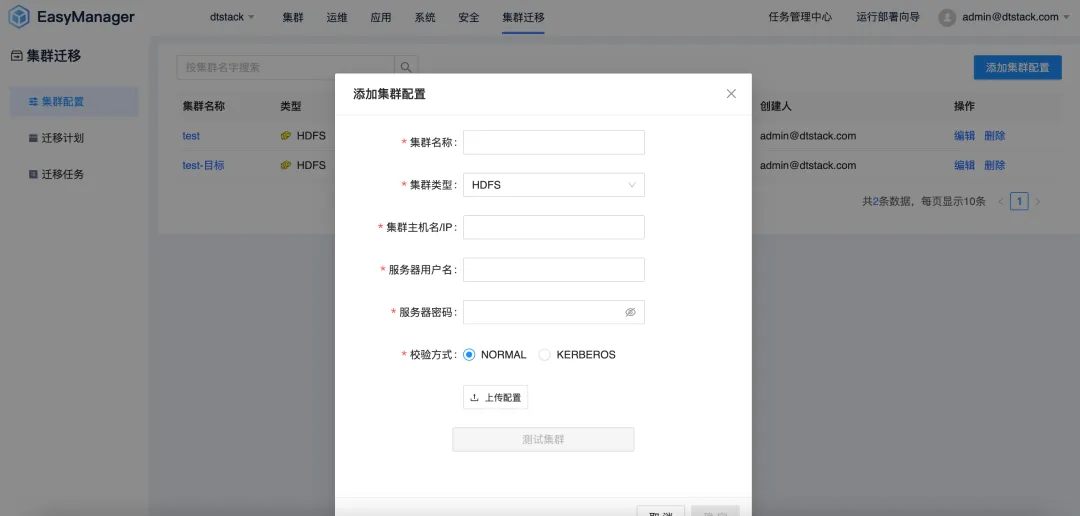
Mise à niveau du moteur révélée : saut de performances, nouvelle expérience
Le plus excitant est que la version EMR6.2 a réalisé une avancée majeure dans les performances du moteur de calcul . Nous avons non seulement optimisé les moteurs informatiques Spark et Flink existants, mais avons également introduit de nouveaux algorithmes et technologies pour améliorer la vitesse de traitement des données et l'efficacité informatique. Cela signifie que les utilisateurs peuvent effectuer des tâches d'analyse de données plus complexes dans un délai plus court, accélérant ainsi le processus de prise de décision et améliorant la compétitivité de l'entreprise.
● Spark3 prend en charge l'optimisation de l'index Z-order
Z-Order est une technologie qui peut compresser des données multidimensionnelles en une seule dimension pour une donnée, nous pouvons considérer ses multiples champs à trier comme plusieurs dimensions des données. Z-Order peut transmettre certaines règles de mappage de données multidimensionnelles . données unidimensionnelles.
Plus précisément, la valeur z est construite selon certaines règles . La valeur z peut être comprise comme les données unidimensionnelles mentionnées ci-dessus. À l'heure actuelle, nous pouvons trier en fonction des données unidimensionnelles. Comme indiqué ci-dessous:
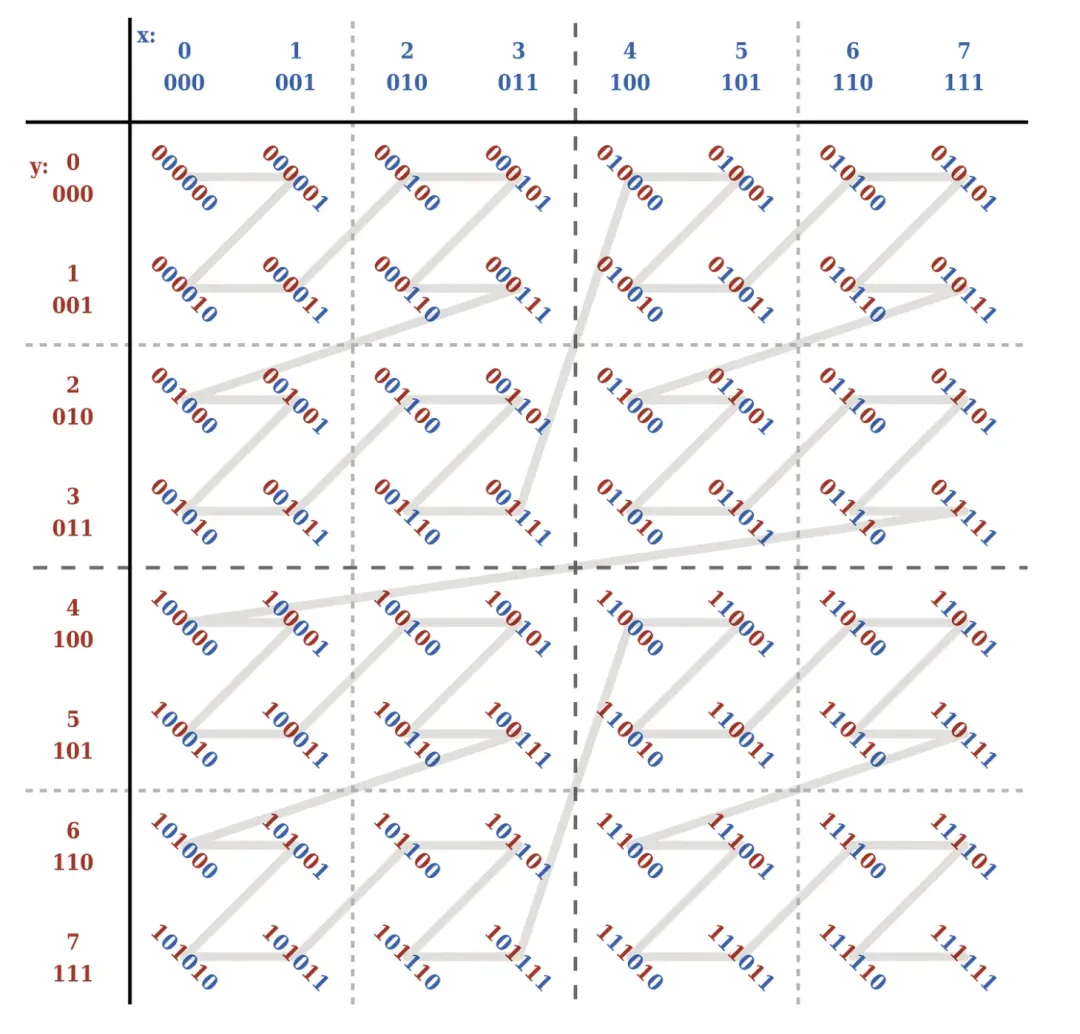
Dans Spark SQL, Kangaroo Cloud a ajouté la syntaxe OPTIMIZE XX ZORDER BY pour prendre en charge l'index Z-Order, réalisant l'optimisation de l'index Z-Order de la table INSERT INTO, de la table INSERT OVERWRITE, de la table CREATE TABLE AS SELECT, DISTINCT et d'autres SQL.
Spark3 prend en charge l'optimisation de l'ordre Z, ce qui améliore considérablement l'efficacité du traitement des données et des requêtes, réduit la surcharge d'E/S et accélère l'exécution des tâches. En particulier dans les scénarios où des ensembles de données à grande échelle et des opérations de requête complexes doivent être traités, l'optimisation de l'ordre Z peut jouer un rôle important. En résolvant le problème du taux de compression des fichiers, après avoir utilisé l'optimisation par ordre Z, le taux de compression des fichiers a augmenté de près de 20 % par rapport à l'optimisation manuelle et a augmenté de près de 10 fois par rapport à la tâche d'origine par rapport à l'open source Spark3. tâche, les performances sont également de près de 30%. L'amélioration a considérablement amélioré les performances et l'efficacité des opérations hors ligne.
● Mise à jour à chaud de la tâche Flink par tâche
Dans les opérations de production réelles, des modifications des paramètres de tâche en temps réel ou un réglage des opérateurs et des fonctions se produisent généralement. Habituellement, la tâche en cours ne peut être annulée qu'en premier, puis CheckPoint est sélectionné pour être restauré ou réexécuté. L'ensemble du processus prend environ 3 à 5 minutes. attendre, ce qui est très difficile. Une grosse perte de temps de développement des tâches.
Afin de résoudre le problème d'interruption de service causé par les mises à jour des tâches en mode par tâche traditionnel, d'améliorer la stabilité des tâches et la disponibilité du système, et de répondre aux exigences de continuité des activités et de haute disponibilité dans l'environnement de production. L'équipe Kangaroo Cloud Engine a mené des explorations pertinentes et des améliorations du code source, et optimisé le redémarrage à chaud des tâches dans le rappel asynchrone de l'annulation des tâches par tâche :
① Déterminez d'abord s'il existe actuellement un nouveau cache JobGraph. S'il existe un cache, entrez la logique de redémarrage à chaud.
② Obtenez les informations CheckPoint de la tâche annulée et remplissez-les dans le nouveau JobGraph
③Mettez à jour JobGrap vers JobMaster et effacez les informations du cache de JobGraph
④Effacer les ressources gérées par SloyPool dans JobMaster
⑤JobMaster recrée ScheduleNg et planifie son exécution. Cela lancera une nouvelle exécution de planification JobGraph.
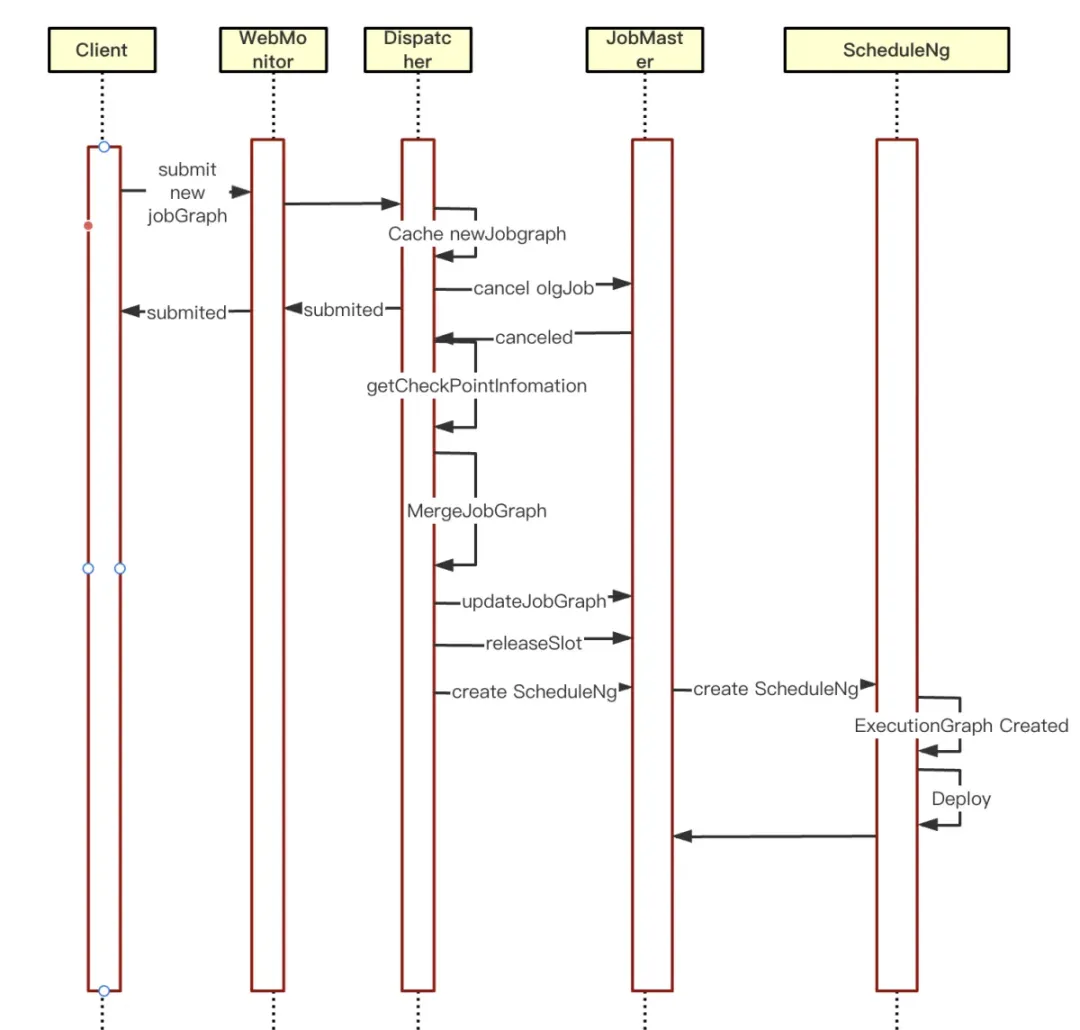
L'optimisation des mises à jour à chaud des tâches par tâche de Flink améliore considérablement l'efficacité du développement, réduit les temps d'arrêt et améliore la flexibilité et la fiabilité des applications. Pour les applications en temps réel qui nécessitent une itération rapide et un ajustement dynamique, il apporte une expérience d'efficacité ultime.
Efficacité de développement améliorée : les développeurs peuvent rapidement tester et itérer le code sans passer par le processus fastidieux d'arrêt et de redémarrage, ce qui accélère les cycles de développement et permet des versions plus fréquentes.
· Réduire les temps d'arrêt : les mises à jour à chaud peuvent minimiser les temps d'arrêt des applications, augmentant ainsi la disponibilité des services, ce qui est particulièrement important pour les applications critiques et en temps réel.
· Ajuster dynamiquement les paramètres : les paramètres de configuration du travail, tels que le parallélisme ou les paramètres de l'opérateur , peuvent être ajustés dynamiquement sans redémarrer le travail, permettant des ajustements flexibles basés sur le flux de données en temps réel ou les conditions de charge.
● Développement d'autres fonctions
De plus, du côté du moteur, nous avons également développé des fonctions telles que l'amarrage Spark Ranger , l'optimisation de la vue matérialisée Spark et l'isolation du chargement de classe en mode Session Flink pour améliorer les performances de calcul du moteur tout en améliorant la sécurité et l'évolutivité des tâches du moteur.
Résumer
En résumé, la sortie d' EMR6.2 marque une autre étape importante pour Kangaroo Cloud dans le domaine des services Big Data. Grâce à l'optimisation de quatre fonctions principales, notamment l'actualisation et la mise à niveau complètes de l'interface utilisateur, la configuration différenciée, la migration de cluster et la mise à niveau du moteur, EMR6.2 offre aux utilisateurs une plate-forme de moteur de calcul Big Data plus puissante, flexible et efficace , aidant les entreprises dans la gestion des données et A saut qualitatif dans l’analyse.
Adresse de téléchargement du « Livre blanc sur le système d'indicateurs industriels » : https://www.dtstack.com/resources/1057?src=szsm
Adresse de téléchargement du « Livre blanc sur les produits Dutstack » : https://www.dtstack.com/resources/1004?src=szsm
Adresse de téléchargement du « Livre blanc sur les pratiques de l'industrie de la gouvernance des données » : https://www.dtstack.com/resources/1001?src=szsm
Pour ceux qui souhaitent en savoir ou en savoir plus sur les produits Big Data, les solutions industrielles et les cas clients, visitez le site officiel de Kangaroo Cloud : https://www.dtstack.com/?src=szkyzg
Linus a pris sur lui d'empêcher les développeurs du noyau de remplacer les tabulations par des espaces. Son père est l'un des rares dirigeants capables d'écrire du code, son deuxième fils est directeur du département de technologie open source et son plus jeune fils est un noyau open source. contributeur. Robin Li : Le langage naturel deviendra un nouveau langage de programmation universel. Le modèle open source prendra de plus en plus de retard sur Huawei : il faudra 1 an pour migrer complètement 5 000 applications mobiles couramment utilisées vers Java, qui est le langage le plus enclin . vulnérabilités tierces. L'éditeur de texte riche Quill 2.0 a été publié avec des fonctionnalités, une fiabilité et des développeurs. L'expérience a été grandement améliorée. Bien que l'ouverture soit terminée, Meta Llama 3 a été officiellement publié. la source de Laoxiangji n'est pas le code, les raisons derrière cela sont très réconfortantes. Google a annoncé une restructuration à grande échelle.