
Il existe des exigences étendues en matière de contrôle des risques dans des domaines tels que l’accès au crédit et la commercialisation des transactions de produits financiers. À mesure que les types d’entreprises augmentent, les règles expertes et les modèles de cartes de pointage traditionnels ne sont pas en mesure de faire face à des scénarios de contrôle des risques de plus en plus complexes.
Dans le contexte du contrôle des risques traditionnel, où les systèmes de règles experts constituent l'application principale, les habitudes d'entrée des modèles de règles sont appelées « variables ». L'évaluation des risques basée sur des règles expertes présente les caractéristiques suivantes : il est difficile de quantifier le seuil de déclenchement des règles et il existe un goulot d'étranglement dans l'amélioration de la précision des règles appliquées.
Avec la mise en œuvre technique des algorithmes d'apprentissage automatique et de réseaux neuronaux, de plus en plus de « fonctionnalités » commencent à être utilisées pour désigner les paramètres d'entrée fournis au modèle d'algorithme . Plus précisément, les « fonctionnalités » servent de paramètre de sortie de l'interface étrangère en amont pendant son processus de sortie, et servent de paramètre d'entrée du modèle de règles en aval pendant le processus d'entrée côté application.
fond de construction
Les sources de données variables de fonctionnalités comprennent des informations de base sur les clients, la situation financière, le comportement de consommation et les graphiques des réseaux sociaux, etc., qui sont saisies dans différents modèles de contrôle des risques pour refléter l'état de crédit et le niveau de risque de l'emprunteur. La gestion efficace de l'extraction de fonctionnalités est une série de données en ligne. base de données pour les actions de contrôle des risques.
Dans les institutions financières telles que les banques et les compagnies d'assurance, en raison de la complexité de la structure organisationnelle des sources d'affaires à risque, il y a inévitablement un développement en cheminée de variables caractéristiques entre les différentes lignes. Les besoins en données des modélisateurs de stratégies sont souvent limités à un certain nombre. Il a été développé et déployé mais n'a pas formé un mécanisme de plate-forme de gestion et de partage unifié, ce qui entraîne des écarts dans la cohérence de l'utilisation des données et de la génération de politiques entre les entreprises.
Par conséquent, il est nécessaire de produire davantage l'abstraction du processus de données commerciales sur les risques afin de normaliser la dérivation, le stockage, l'appel et la surveillance des variables caractéristiques, et une plate-forme unifiée de variables caractéristiques de contrôle des risques a également vu le jour.
Analyse des points douloureux
Dans le scénario de développement de tâches de contrôle des risques, la tâche modèle récupère les nombres de la table de stockage de variables pré-développée. Dans le développement réel, il existe souvent des problèmes commerciaux et de développement tels qu'un seuil élevé pour le développement et le déploiement de fonctionnalités, des difficultés à extraire des fonctionnalités complexes, des calibres d'application de fonctionnalités incohérents et des processus de traitement de fonctionnalités incohérents.
01 Le seuil de développement de variables de fonctionnalités en temps réel est élevé
La pile technologique des modélisateurs de stratégies liées au contrôle des risques est principalement basée sur les capacités Python et SQL. Il existe un certain coût d'apprentissage pour le développement Flink basé sur la sémantique Java, en plus de la formation de modèles et du déploiement basé sur des données hors ligne et des fonctionnalités en temps réel. les capacités de traitement sont insuffisantes.
02 Il est difficile d'extraire des variables de fonctionnalités complexes
Les messages de retour de certaines interfaces de sources de données externes comportent de nombreux niveaux imbriqués, l'emplacement des paramètres prête à confusion, l'interface est difficile à obtenir et il existe un manque de gestion et de maintenance unifiées de la plate-forme pour les fonctionnalités extraites.
03 Le calibre d'application des variables de fonctionnalité est incohérent
Lors de la création d'un modèle de contrôle des risques , les tâches du modèle ont les mêmes exigences en matière de variables de fonctionnalités, mais il existe des situations où le traitement d'ingénierie des fonctionnalités est répété pour les mêmes données d'origine dans différentes équipes ou différents projets, ce qui entraîne la cohérence et la précision du SQL correspondant après la logique de la variable de fonctionnalité est modifiée.
04 Il est difficile d'unifier le processus de traitement des variables de caractéristiques
Les exigences relatives aux nouvelles variables de fonctionnalités côté stratégie et modèle en aval manquent d'un chemin de traitement cohérent et standardisé, ce qui entraîne une dénomination confuse des paramètres entrants et sortants dans la table de variables correspondante. Lorsque les nouveaux champs sont ajoutés, la table en amont ne peut pas être lue. le SQL d'origine, ce qui entraîne des opérations de jointure imbriquées plus complexes. Avec la configuration de fonctionnalités dérivées et d'ensembles de variables , l'échelle des tâches et l'utilisation des ressources sont souvent difficiles à contrôler.
Plan de construction du système variable avec caractéristiques de contrôle des risques
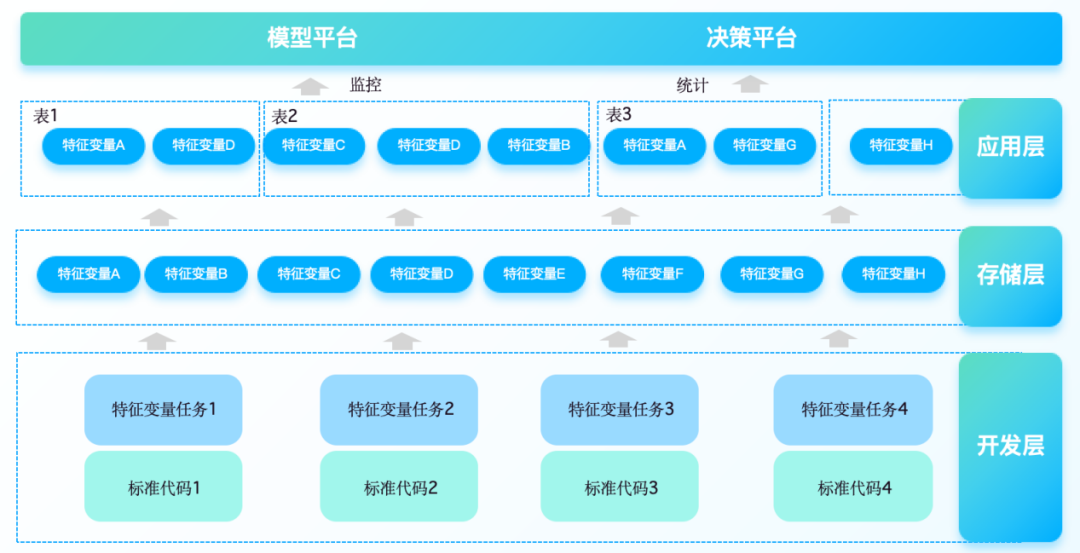
La construction d' un système de variables caractéristiques de contrôle des risques se concentre sur l'identification, la prévention et le contrôle des risques en temps réel des institutions financières . Grâce à l'extraction par lots, à l'agrégation et au traitement dérivé de données hétérogènes multi-sources, une plate-forme de variables caractéristiques unifiée, standardisée et facile à étendre. est précipité pour réaliser l'accès aux données, génère des variables de fonctionnalité , une boucle fermée de bout en bout qui fournit des données pour la formation du modèle en aval et l'exécution des décisions, améliorant ainsi la vitesse de réponse aux événements à risque et la précision de la prise de décision.
01 Capacités techniques
Les activités de contrôle des risques sont souvent confrontées à des exigences de traitement de données en temps réel dans les transactions clients, l'approbation du crédit et d'autres scénarios, l'informatique en flux peut mettre à jour les notations de crédit des clients, le contrôle des limites et d'autres informations sur les risques en temps réel, fournissant ainsi des capacités d'identification des risques inter-systèmes en temps réel. pour les moteurs de décision en aval.
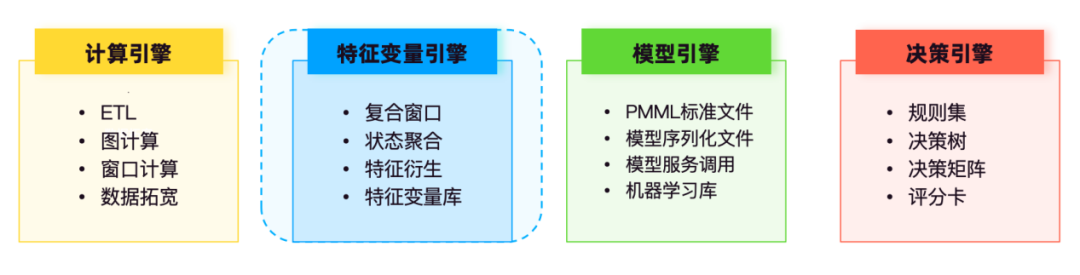
Dans l'architecture du système technologique de contrôle des risques en temps réel , l'informatique comprend le calcul par lots, le calcul de flux et le calcul graphique, en prenant comme exemple les capacités de calcul de flux, Flink fournit des capacités de calcul de fonctionnalités en temps réel sous-jacentes, qui sont principalement utilisées pour les données ETL, les tables larges. traitement et traitement de fenêtre. Informatique, jointure à double flux et d'autres scénarios, grâce au pré-calcul, au calcul d'agrégation d'état et à d'autres capacités, le traitement des variables de caractéristiques d'origine, des variables de caractéristiques standard et des variables de caractéristiques dérivées est réalisé pour fournir une prise en charge des fonctionnalités pour modèles de prise de décision.
Le moteur de modèles est principalement responsable du stockage et de la gestion de divers modèles formés, tels que les modèles de notation de crédit, les modèles de détection de fraude , les modèles d'avertissement de désabonnement, etc.
Le moteur de décision gère de manière centralisée des modèles de politique tels que des ensembles de règles, des arbres de décision, des matrices de décision et des cartes de pointage. L'ensemble de règles appelle le service de variable de fonctionnalité et le service de modèle du moteur de modèle pour participer au fonctionnement logique du flux de décision.
Basé sur des sources de données hétérogènes, le moteur de variables de fonctionnalités effectue l'extraction, le traitement et le calcul des données, la gestion et la maintenance standardisées, et permet des requêtes en libre-service par le personnel de contrôle des risques, rendant la récupération et l'analyse des données commerciales plus pratiques et standardisées.
02 Source de données
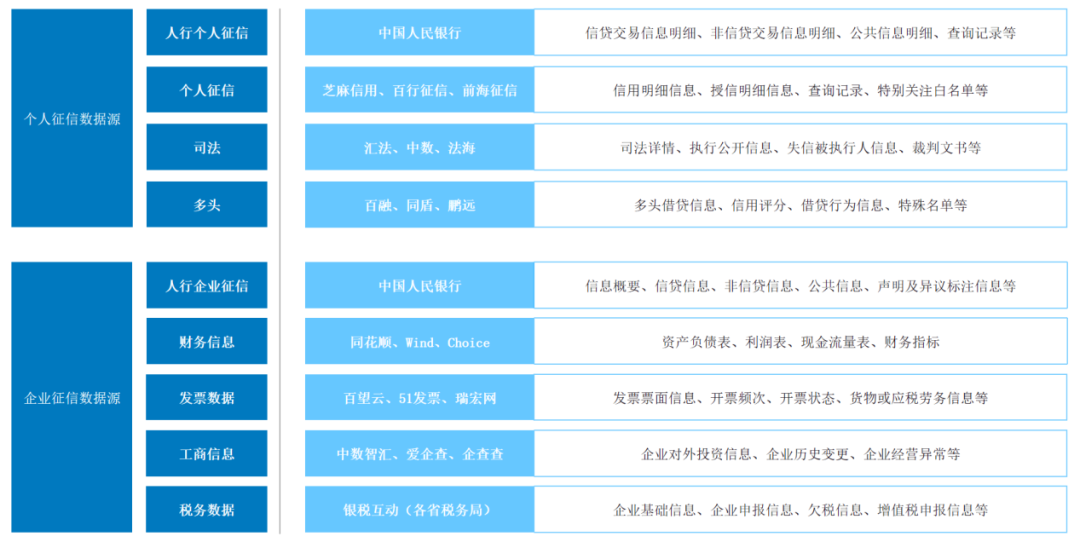
En prenant comme exemple la source de données sur les entreprises de crédit, selon différentes entités de crédit, elle peut généralement être divisée en crédit personnel To C et crédit d'entreprise To B. Dans les revues d'affaires réelles, les chargés de comptes analysent généralement la faisabilité du crédit client sur la base de deux indicateurs : le niveau de trésorerie et le niveau d'endettement.
Dans le scénario du crédit personnel, les niveaux de flux de trésorerie des clients peuvent être décomposés en flux de revenus liés aux paiements de sécurité sociale, aux banques et aux plateformes de paiement tiers. Le niveau de responsabilité provient principalement du rapport de crédit de la Banque populaire de Chine, qui couvre tous les prêts émis par les institutions financières au nom d'un individu, les produits financiers présentant des expositions à risque et les informations sur les garanties externes. En plus des données du rapport de crédit de la Banque populaire de Chine. Les sources incluent d'autres rapports de crédit individuels tiers agréés, tels que Baihang Credit Information, Pudao Credit Information et Qiantang Credit Information.
Dans le scénario de crédit aux entreprises, les sources de risque des petits et microcrédits inclusifs sont concentrées dans le contrôleur lui-même. Outre les flux personnels du contrôleur lui-même, le niveau de flux de trésorerie est collecté simultanément à partir du flux des comptes de l'entreprise, et le niveau de passif est en outre collecté. consulté à partir du rapport de solvabilité des entreprises de la Banque populaire de Chine. Dans le cadre de l'octroi de crédits aux moyennes et grandes entreprises et des prêts spécifiques à un secteur, les événements de comportement à risque des principales entités sont difficiles à mesurer directement sur la base des données fiscales sur le crédit. Contrairement aux prêts inclusifs destinés aux petites et microentreprises, d'autres besoins de diligence raisonnable hors ligne sont nécessaires. à combiner avec l'inventaire sur place de l'entreprise et les conditions d'exploitation des entreprises affiliées.
Pour les deux types d'entreprises de crédit ci-dessus, le traitement des caractéristiques collecte souvent les sources de données multidimensionnelles suivantes :
03 Traitement des données
Pour les sources de données dans différents scénarios de contrôle des risques, des méthodes de traitement de variables de fonctionnalités qui intègrent des modes par lots, flux, pré-calcul et autres sont utilisées pour parvenir à un développement agile des besoins commerciaux et à un contrôle des coûts de stockage et de calcul.
Calcul par lots : pour les ensembles de données historiques à grande échelle, le traitement par lots est utilisé pour traiter les variables de caractéristiques. Les problèmes tels que les valeurs manquantes et les valeurs aberrantes dans les données sont traités à l'aide de méthodes telles que l'interpolation et le lissage pour garantir la qualité des données.
Calcul de flux : pour les flux de données en temps réel, le mode de traitement de flux est utilisé pour le traitement des variables de fonctionnalité. Grâce à la technologie de traitement des flux en temps réel , l'analyse des données en temps réel est réalisée pour répondre aux exigences en temps réel des scénarios de contrôle des risques. Dans le même temps, une architecture événementielle est adoptée pour garantir l’efficacité et la flexibilité du traitement des données.
Précalcul : pour les données du système d'entreprise, précalculez et stockez les variables de fonctionnalités en fonction de leur fréquence de changement, ce qui peut réduire efficacement les coûts de calcul des flux et améliorer l'efficacité du système de prise de décision dans la récupération des données du moteur de fonctionnalités.
04 Construction de la plateforme
Plus précisément, la plate-forme de variables caractéristiques doit intégrer des données provenant de sources multiples telles que des systèmes d'évaluation du crédit, des sources de données tierces et des systèmes internes d'entreprise, et effectuer un traitement dérivé des capacités de traitement par lots, de manière à prendre en charge les exigences d'entrée des modèles de contrôle des risques dans différents scénarios commerciaux. Prend en charge les méthodes de traitement low-code configurables et dirigées par l’entreprise pour les variables de fonctionnalités de complexité différente. Par conséquent, la construction d’une plate-forme de variables de fonctionnalités comprend généralement les aspects suivants :
1. Fonctionnalités d'extraction et de génération de variables, nettoyage et prétraitement automatisés des données, conversion des données brutes en fonctionnalités pouvant être utilisées pour la modélisation. Fournit un modèle IDE WEB unique basé sur un canevas et des composants pour améliorer l'efficacité du développement et prend en charge la logique de calcul des fonctionnalités définie par l'utilisateur ou intégrée au système.
2. Fonctionnalité de stockage et de gestion des variables
Basé sur un mécanisme de stockage distribué , il stocke des données caractéristiques historiques et en temps réel à grande échelle. Implémentez le contrôle des versions des fonctionnalités, enregistrez l'historique des modifications de la logique de calcul des fonctionnalités et assurez-vous que la formation du modèle peut être retracée jusqu'à une version spécifique des données.
3. Servitisation des variables caractéristiques
Fournit une interface de service de fonctionnalités pour fournir des services de requête de fonctionnalités en temps réel ou par lots pour divers moteurs de formation de modèles, de prédiction et de prise de décision. Grâce au composant de sortie, vous pouvez vous connecter rapidement aux moteurs de règles en aval, aux entrepôts de données en temps réel et aux files d'attente de messages pour répondre aux exigences de performances en matière de faible latence et d'accès simultané élevé dans des scénarios commerciaux complexes.
4. Exploration et analyse des variables caractéristiques
Fournit une multitude d' outils d'analyse statistique pour aider les analystes à comprendre rapidement la distribution des variables de caractéristiques, les relations de corrélation, etc. L'interface visuelle affiche l'importance des fonctionnalités, leur influence et d'autres indicateurs pour faciliter la sélection et l'itération des fonctionnalités.
5. Intégration avec les systèmes internes et externes
Intégrez plusieurs sources de données telles que les systèmes de négociation internes des institutions financières, les systèmes CRM et les systèmes ERP. Prend en charge la connexion avec d'autres composants de contrôle des risques (tels que des moteurs de règles, des bibliothèques de modèles, etc.) et des fournisseurs de services de données tiers tels que les rapports de solvabilité externes.
05 Revenus de construction
Dans la mise en œuvre d'un projet de variables caractéristiques du client d'une banque, la plateforme répond aux besoins de traitement et de gestion des dérivés des variables caractéristiques dans les scénarios de crédit préalables au prêt, et se connecte à des sources de données diversifiées en amont, telles que des opérateurs externes, des données industrielles et commerciales et judiciaires. ; et l'équipement client interne de la banque Informations, informations sur les transactions de compte ; données d'évaluation des actifs et de calcul des limites collectées avant le prêt. Grâce aux capacités de calcul des variables de fonctionnalités en temps réel , il peut s'appliquer aux modèles en aval tels que les cartes de pointage pour fournir des données.
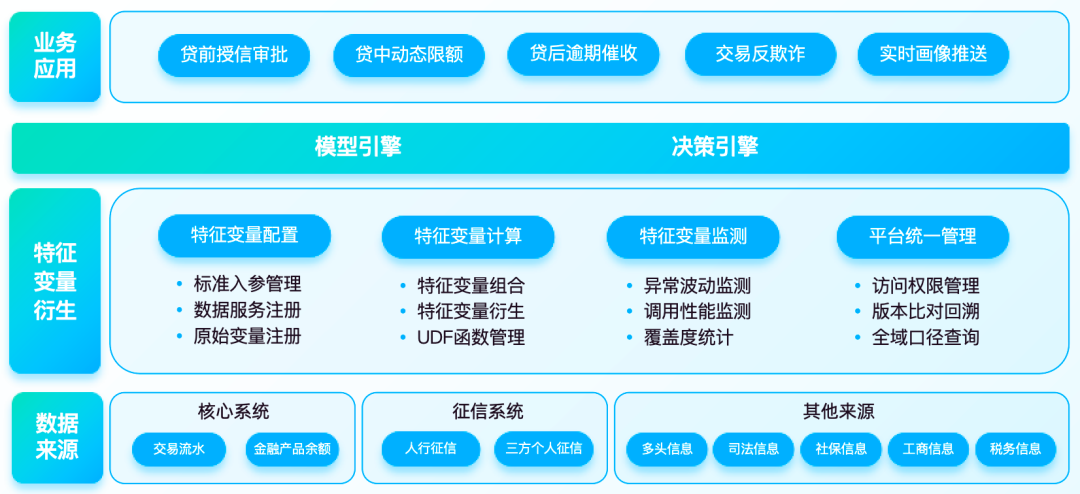
1. Extraction basée sur les composants des variables de caractéristiques
La plate-forme analyse les variables de fonctionnalité par lots à partir de commandes SQL. Pour les exigences d'acquisition de données des tâches de modèle, les utilisateurs peuvent librement traiter et combiner les variables de fonctionnalité requises sur la plate-forme et les écrire dans la table de ruche thématique correspondante pour la lecture et le traitement.
2. Mise à jour synchrone des ensembles de variables de fonctionnalité
La page prend en charge l'ajout, la suppression et la modification d'ensembles de variables de fonctionnalité, et les opérations sur la structure de la table de plate-forme sont automatiquement synchronisées avec la table du modèle physique. Lorsque la logique des variables de fonctionnalité change, il vous suffit de modifier le code dérivé de la variable de fonctionnalité standard correspondant ou l'opération de normalisation de la variable de fonctionnalité d'origine pour éviter le développement complexe de grandes fonctions SQL.
3. Surveillance de la stabilité et des anomalies
La fonction de tableau de bord de surveillance fournie par la plateforme prend en charge la surveillance de la fluctuation des variables caractéristiques et l'appel d'ensembles de variables. La surveillance des valeurs de variables caractéristiques garantit que lorsque les données en amont sont anormales, les tâches en aval sont arrêtées à temps, ainsi. maximiser la possibilité d'éviter les problèmes causés par des différences excessives dans les variables caractéristiques lorsque le modèle est utilisé ; distorsion des résultats du modèle sur l'état d'appel de chaque ensemble de variables, et transmission en temps réel d'alarmes de base et d'informations de vérification de règles fortes et faibles.
4. Gestion et contrôle unifiés de la plateforme
La plate-forme fournit la gestion des membres, le centre d'approbation, l'analyse des appels, l'archivage automatique, le redémarrage des tâches et d'autres méthodes de gestion et de contrôle, prend en charge l'ajustement de la priorité des tâches et planifie uniformément les opérations des tâches pour améliorer les performances des services de données et l'utilisation des ressources du cluster.
La plateforme a été déployée en ligne, couvrant et prenant en charge plus de 30 scénarios de crédit pour les prêts à la consommation, les petits et microcrédits et d'autres entreprises. En se combinant avec le moteur de modèle de règles en aval, la plate-forme variable caractéristique réalise la mise en œuvre de capacités de prise de décision en temps réel dans des scénarios de contrôle des risques, ce qui répond au besoin d'améliorer l'expérience client des utilisateurs et l'efficacité du prêt dans la demande de carte de crédit et l'approbation du prêt. processus dans les scénarios de crédit avant le prêt. En outre, il fournit également des données pour la collecte après le prêt, la lutte contre la fraude dans les transactions et d'autres scénarios, prenant en charge les systèmes en aval pour surveiller les comportements de transaction anormaux des utilisateurs en temps réel et effectuer une identification d'identité anti-blanchiment d'argent. , et poussez des alarmes en temps réel.
Adresse de téléchargement du « Livre blanc sur les produits Dutstack » : https://www.dtstack.com/resources/1004?src=szsm
Adresse de téléchargement du « Livre blanc sur les pratiques de l'industrie de la gouvernance des données » : https://www.dtstack.com/resources/1001?src=szsm
Pour ceux qui souhaitent en savoir ou en savoir plus sur les produits Big Data, les solutions industrielles et les cas clients, visitez le site officiel de Kangaroo Cloud : https://www.dtstack.com/?src=szkyzg
Linus a pris sur lui d'empêcher les développeurs du noyau de remplacer les tabulations par des espaces. Son père est l'un des rares dirigeants capables d'écrire du code, son deuxième fils est directeur du département de technologie open source et son plus jeune fils est un noyau open source. contributeur. Robin Li : Le langage naturel deviendra un nouveau langage de programmation universel. Le modèle open source prendra de plus en plus de retard sur Huawei : il faudra 1 an pour migrer complètement 5 000 applications mobiles couramment utilisées vers Java, qui est le langage le plus enclin . vulnérabilités tierces. L'éditeur de texte riche Quill 2.0 a été publié avec des fonctionnalités, une fiabilité et des développeurs. L'expérience a été grandement améliorée. Bien que l'ouverture soit terminée, Meta Llama 3 a été officiellement publié. la source de Laoxiangji n'est pas le code, les raisons derrière cela sont très réconfortantes. Google a annoncé une restructuration à grande échelle.