
Bienvenue dans le rapport de mise à jour des fonctionnalités du produit Kangaroo Cloud 09. Dans ce rapport, nous adhérons au concept d'importance égale accordée à l'innovation et à l'optimisation, et effectuons un polissage en profondeur et une mise à niveau complète du produit. L'amélioration de chaque détail est notre recherche incessante d'excellente qualité. Nous espérons que ces nouvelles fonctions pourront aider les opérations et le développement de votre entreprise, rendant ainsi le chemin vers la transformation numérique plus fluide.
Voici le contenu du rapport de mise à jour des fonctions du produit Kangaroo Cloud numéro 09. Pour plus d'exploration, veuillez continuer la lecture.
Plateforme de développement hors ligne
Nouvelles mises à jour de fonctionnalités
1.Modèle de tâche
Contexte : Les clients espèrent conserver quotidiennement des modèles de code communs hors ligne et les référencer directement lors du développement des données.
La différence entre les modèles et les composants :
1. L'édition est prise en charge une fois le code du modèle référencé, mais l'édition n'est pas prise en charge une fois le composant référencé.
2. Les modifications du modèle n'affecteront pas les tâches référencées, mais les modifications des composants affecteront les tâches référencées.
Description de la nouvelle fonctionnalité : prend en charge les modèles de code de projet et les modèles de code de locataire pour chaque type de tâche, et prend en charge les modèles de code de référence lors de la création de tâches .
2.shell sur agent/python sur agent ajoute un nouveau contrôle de dimension de projet
arrière-plan:
Shell sur agent est un type de tâche spécial pour les plateformes hors ligne.
La tâche Shell n'est pas exécutée directement sur la machine déployée en cluster, mais le Shell est exécuté sur un nœud de serveur déployé indépendamment. Étant donné qu'une tâche hors ligne nécessite deux cœurs, s'il existe de nombreuses tâches Shell dans le scénario client, il est facile de remplir les ressources du cluster . Par conséquent, l’exécution de tâches telles que Shell et Python sur des nœuds déployés indépendamment peut réduire efficacement la pression sur le cluster.
Il existe actuellement un problème. Tant que le client configure l'utilisateur du nœud et du serveur sur EM et la console, tous les projets sous le cluster peuvent utiliser l'utilisateur du nœud et du serveur configuré. Cela pose un problème de sécurité. Par exemple, pour les utilisateurs disposant d'autorisations élevées telles que root, les clients accordent plus d'attention aux problèmes de sécurité et ne souhaitent pas que tous les projets puissent utiliser ce compte. Il est donc nécessaire de concevoir une solution capable de contrôler la configuration des nœuds du serveur. et les utilisateurs du serveur pour résoudre ce problème.
Description des nouvelles fonctionnalités :
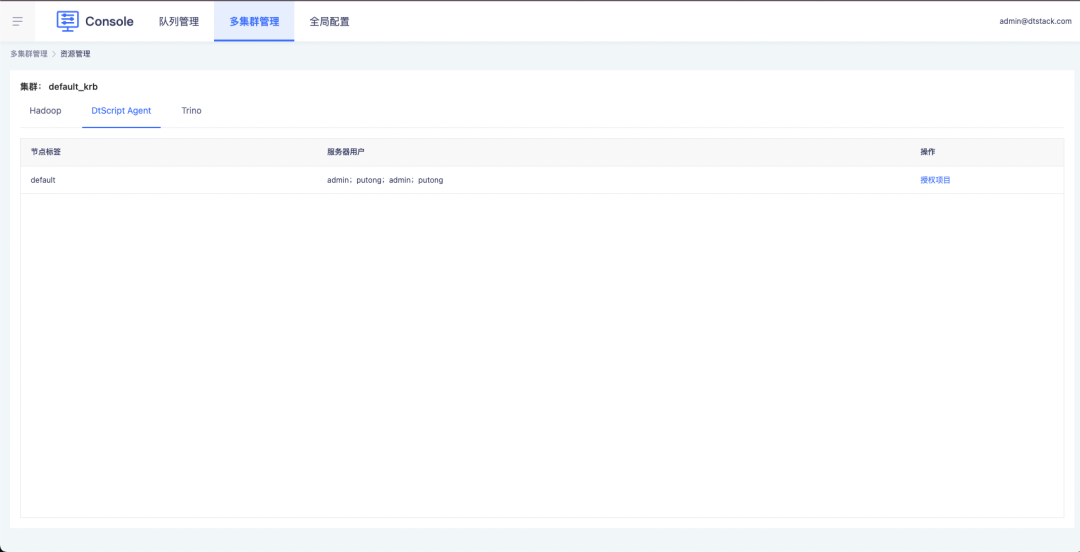
1. La console contrôle les autorisations des utilisateurs des nœuds et des serveurs via l'autorisation du projet.
2. Les tâches des projets hors ligne prennent en charge la sélection des nœuds de serveur et des utilisateurs autorisés.
Optimisation des fonctions
1. Optimisation de la configuration de la planification, qui peut contrôler toute instance périodique reposant sur des tâches en amont
arrière-plan:
Actuellement, la planification des tâches Zhongtian ne peut s'appuyer par défaut que sur l'instance en amont du cycle en cours. Les clients peuvent avoir les scénarios suivants :
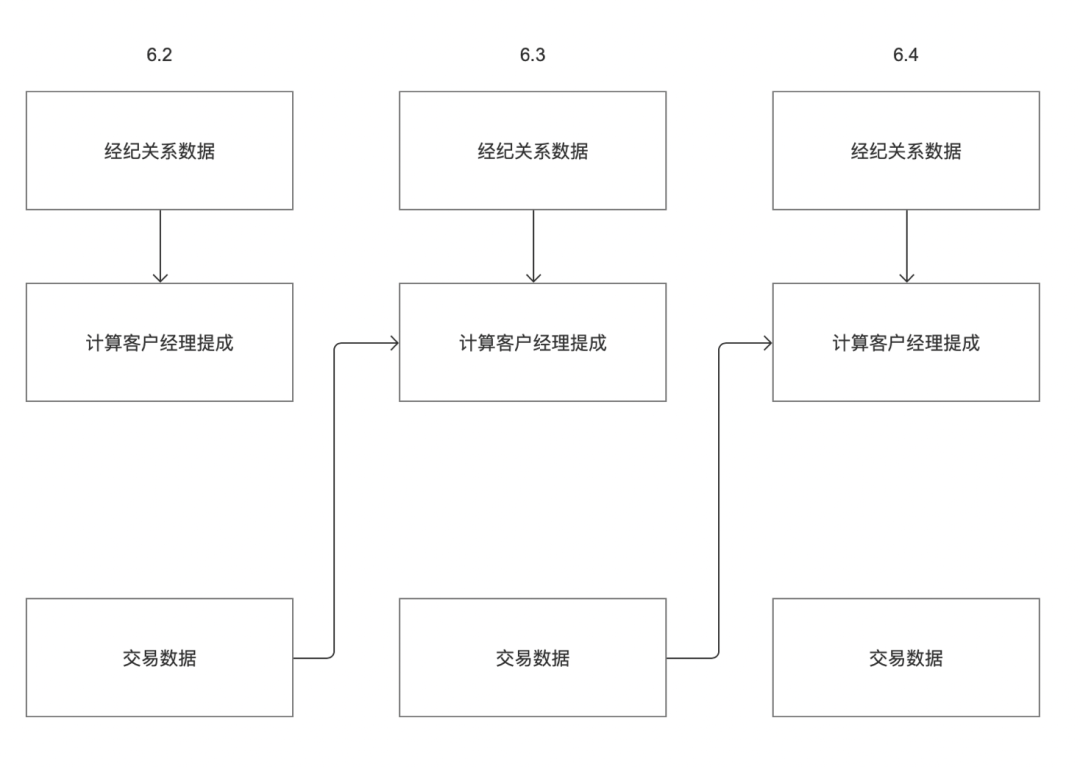
Par exemple, un client dispose de deux systèmes commerciaux « données sur les relations de courtage » et « données sur les transactions ». La commission du client au 3 juin doit être calculée sur la base respectivement des « données sur les relations de courtage » et des « données sur les transactions ». Comme le montre la figure ci-dessus, l'heure de sortie des données du système d'entreprise « données de relation de courtage » le 2 juin est le 3 juin ; l'heure de sortie des données du système d'entreprise « données de transaction » le 2 juin est le soir du 2 juin.
Selon la logique de dépendance actuelle hors ligne en amont et en aval, la tâche « Calculer la commission du gestionnaire de compte » ne peut obtenir des tâches que le 3 juin, mais ne peut pas obtenir de tâches le 2 juin. Par conséquent, elle doit être modifiée pour prendre en charge les paramètres de dépendance d'instance de tâche, qui peut être personnalisé.
Instructions d'optimisation de l'expérience :
Prend en charge la personnalisation du cycle de planification des tâches dépendantes en amont .
T représente l'heure planifiée de la tâche en cours (tâche en aval), "+ -" représente la direction du décalage, "+" représente le décalage temporel par rapport au futur, "-" représente le décalage temporel par rapport au passé et "-" est sélectionné par défaut.
Le décalage est une zone de saisie numérique avec une valeur maximale de 10 et une valeur minimale de 1, qui représente le nombre de cycles de tâches en amont du décalage.
Plateforme de développement en temps réel
Nouvelles mises à jour de fonctionnalités
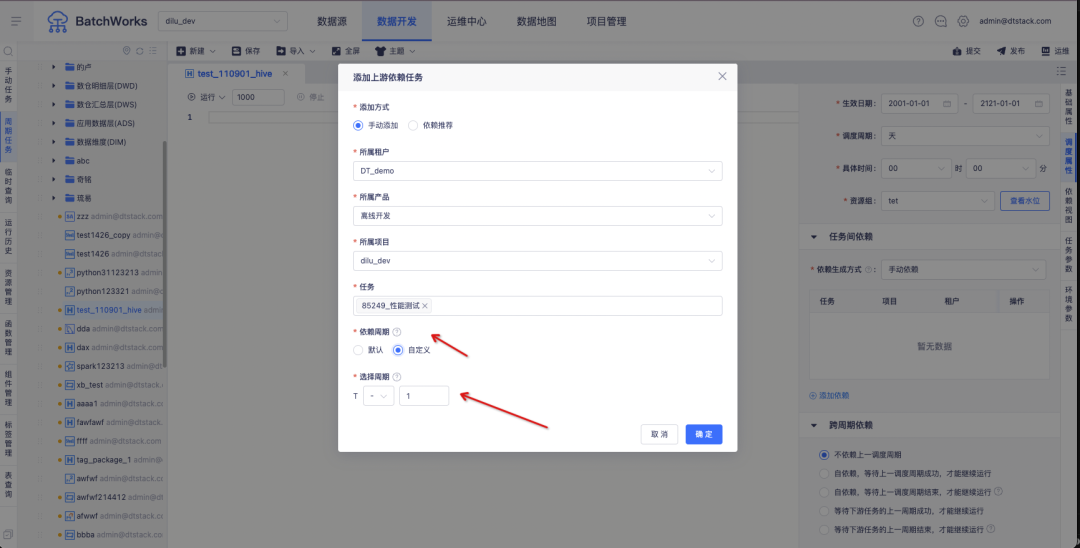
1. Afficher l'analyse de la lignée
Contexte : Actuellement, SQLParser ne prend pas en charge l'analyse de lignage des vues de FlinkSQL. Cependant, dans les scénarios de développement généraux, si la tâche implique plus de trois tables, de nombreuses réunions choisissent de créer des vues dans l'EDI pour faciliter la lecture de la logique SQL.
Fonction:
1. SQLParser prend en charge la table d'affichage FlinkSQL pour afficher l'analyse des liens sanguins
2. Opération et maintenance des tâches-tâches en temps réel-détails des tâches FlinkSQL-fonction d'affichage de l'analyse de la lignée sanguine
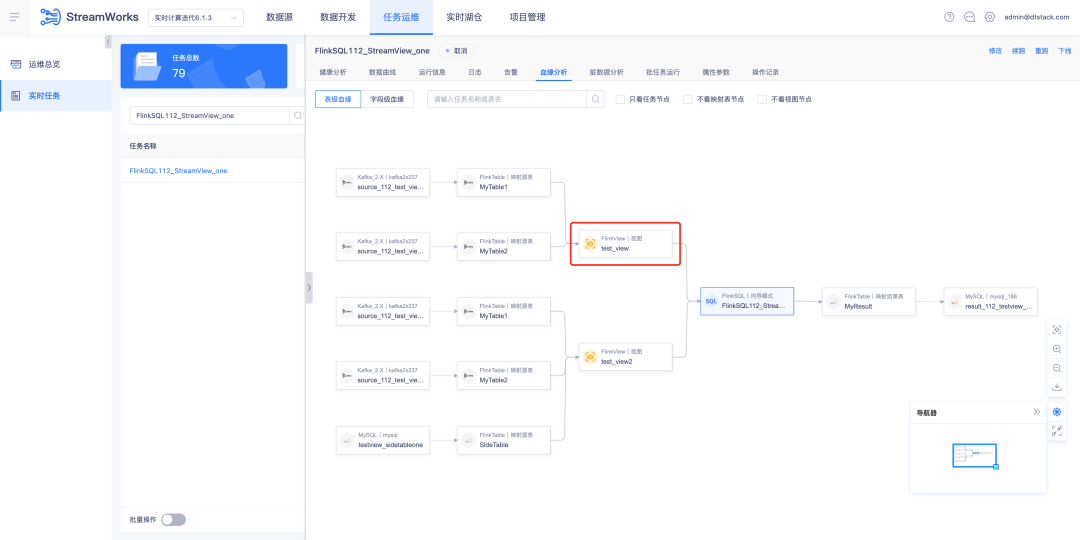
2.FlinkSQL prend en charge Oceanbase Sink
FlinkSQL version 1.16 prend en charge les tables de résultats OceanBase et est compatible avec les modes MySQL et Oracle d'OceanBase version 4.2.0, offrant aux utilisateurs des capacités de traitement de données plus flexibles et plus efficaces.
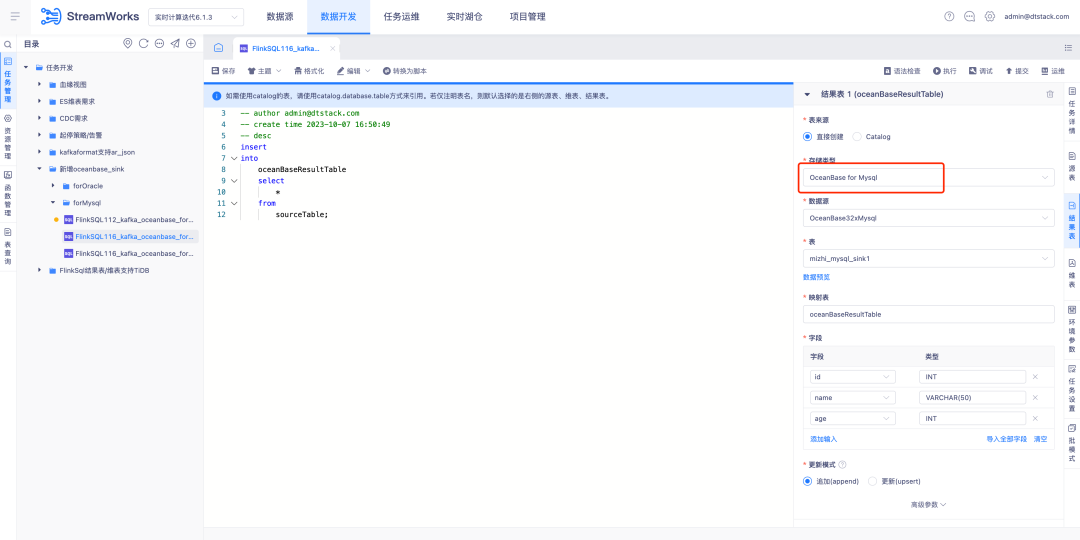
3. Le type de lecture de la table source Kafka prend en charge AR Json
Contexte : OGG et Attunity Replicate sont deux produits commerciaux largement utilisés à l'étranger. Afin de mieux répondre aux besoins des clients, nous devons nous assurer que le format JSON de Kafka est compatible avec le type de lecture AR Json.
Description de la nouvelle fonctionnalité : La table source de la version FlinkSQL1.16. Le type de lecture Kafka prend en charge le type AR Json et prend en charge les fonctions liées au mappage automatique pour analyser Json.
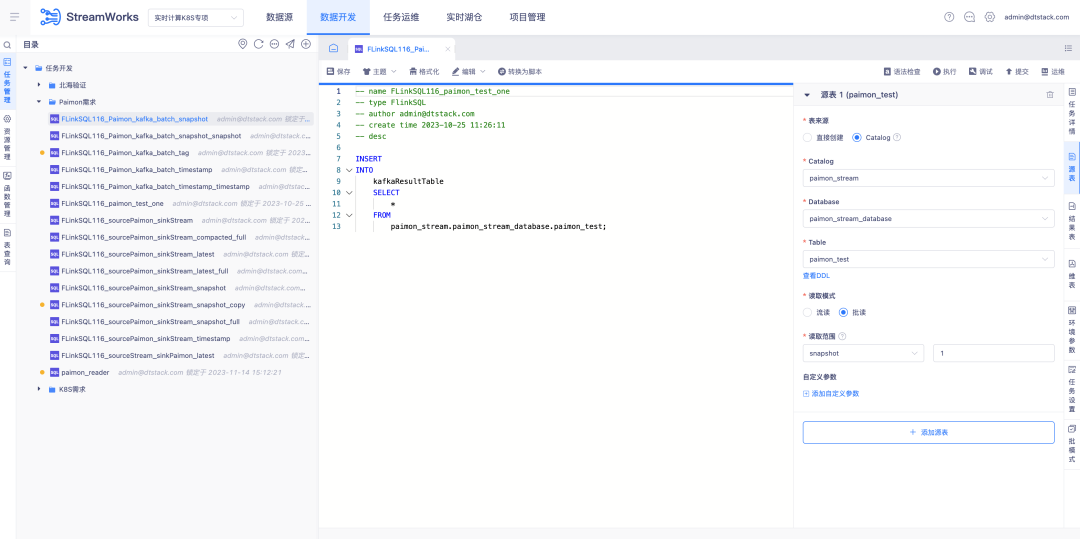
4. Assistance Paimon pour l'entrepôt du lac en temps réel
Contexte : Avec le développement de Paimon, un nouveau modèle de développement FlinkSQL doit être itéré cette fois. En utilisant ce modèle, le module de gestion d'entrepôt de Lake peut être enchaîné sur l'ensemble de la chaîne.
Description des nouvelles fonctionnalités :
1. La gestion de l'entrepôt Lake ajoute la possibilité d'ajouter, de supprimer, de modifier et d'interroger les tables Paimon
3. La plateforme de développement de données utilise l'IDE pour compléter les fonctions de lecture et d'écriture de la table Paimon.
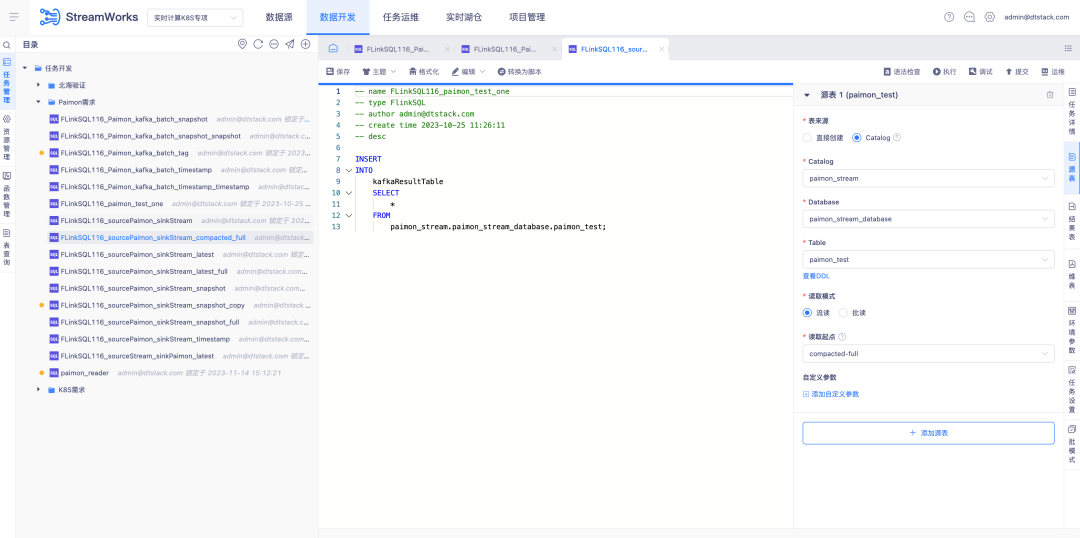
5.FlinkSQL FlinkCDC intégré
Contexte : FlinkCDC est un composant de collecte en temps réel open source avec une vitesse d'itération très rapide. Le framework Flink sous-jacent sur lequel il s'appuie est également le même que le framework ChunJun que nous utilisons. Par conséquent, nous envisageons d’en faire un composant par défaut pour le déploiement de la plateforme en temps réel et de l’intégrer dans notre système.
Description des nouvelles fonctionnalités :
1. Package de déploiement par défaut en temps réel, configurez la collecte en temps réel FlinkCDC
2. En mode script de plate-forme, vous devez vérifier les capacités de collecte intégrées de FlinkCDC et les connecteurs pris en charge
3. Le mode Assistant de plateforme configurera la collection de connecteurs prise en charge par FlinkCDC en fonction de la situation du projet.
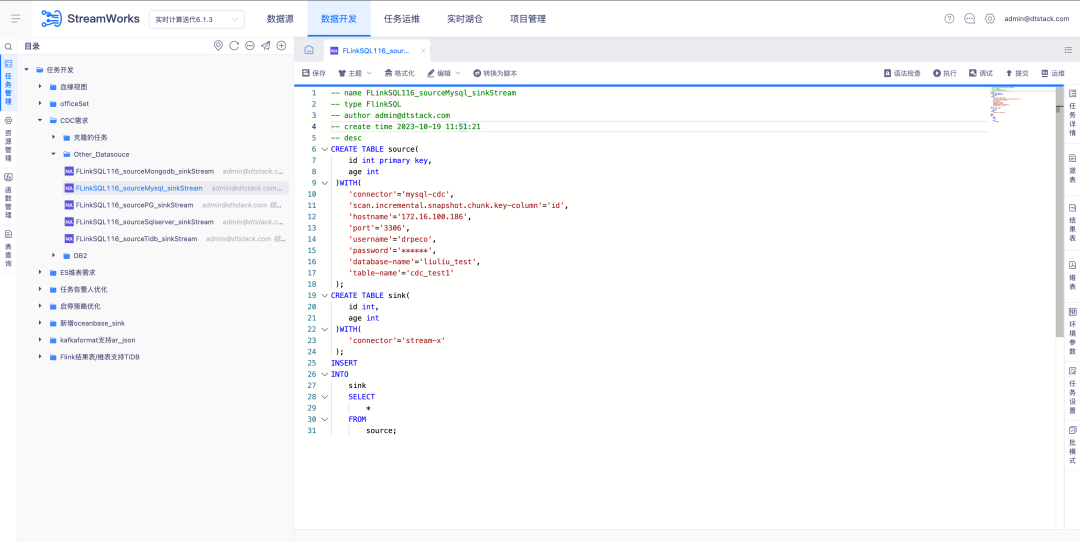
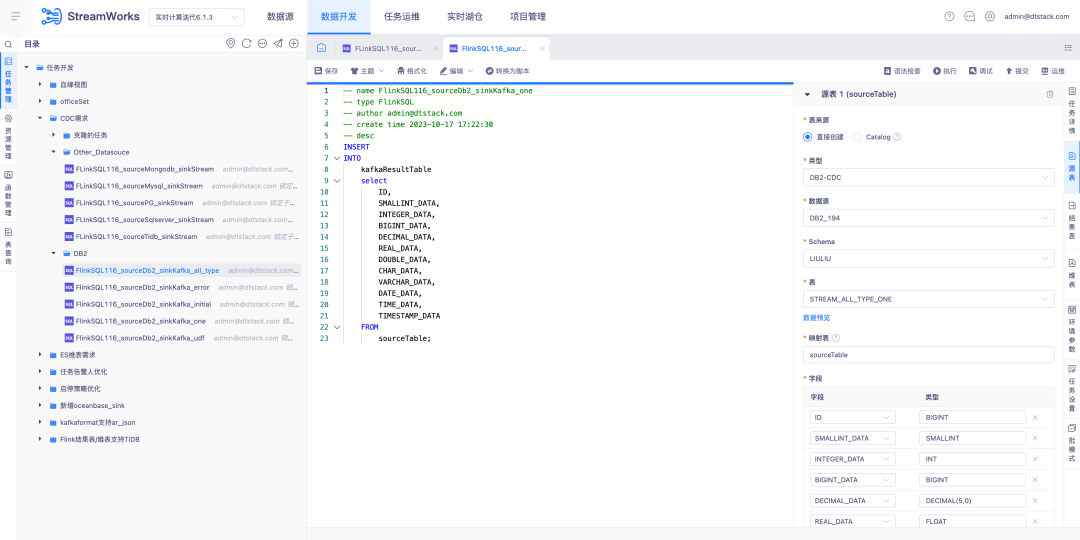
6.FlinkSQL prend en charge la source de données FlinkCDC DB2
Contexte : les clients doivent prendre en charge la collecte en temps réel de DB2. Étant donné que le développement du connecteur CDC est difficile, FinkCDC le prend simplement en charge, de sorte que la couche inférieure emprunte les capacités de FlinkCDC.
Description de la nouvelle fonction : La plateforme temps réel prend en charge le mode assistant pour configurer la table source comme source de données DB2-CDC .
Optimisation des fonctions
1.Optimisation de la logique de continuation
Contexte : lorsqu'une tâche en temps réel reprend via CheckPoint et continue de s'exécuter, un point temporel doit être sélectionné manuellement. Cependant, en fait, la plupart des scénarios de continuation sélectionnent le dernier CheckPoint.
Description de l'optimisation de l'expérience : lors de l'optimisation de la restauration et de la poursuite de l'exécution via CheckPoint , le CheckPoint le plus proche dans la date sera automatiquement sélectionné.
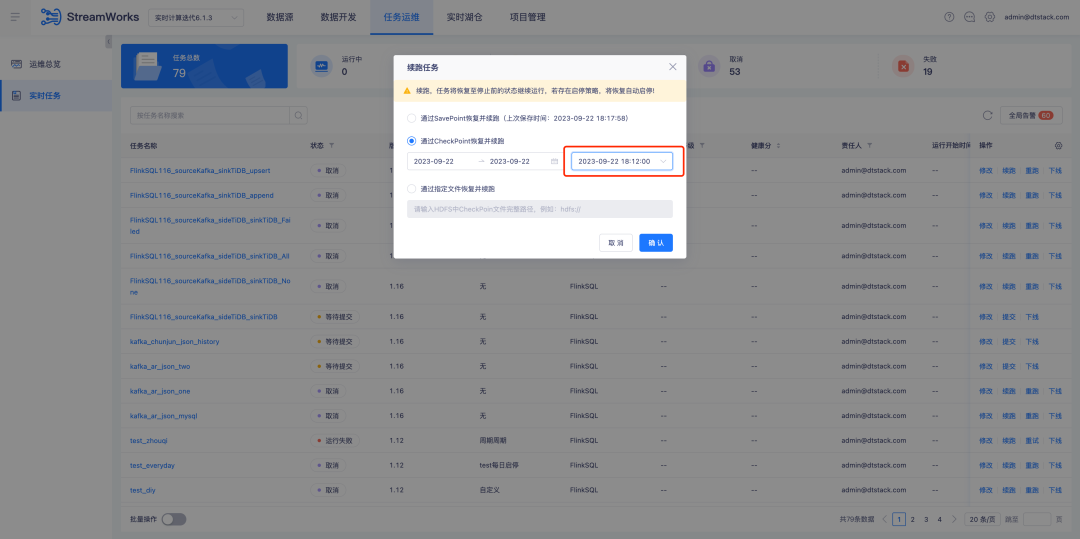
2. Stratégie start-stop/Optimisation hors site
Contexte : Au cours d'une utilisation approfondie par les clients, nous avons constaté que des aspects tels que la stratégie start-stop, la soumission et la réexécution peuvent être optimisés pour obtenir un flux de travail plus efficace et une meilleure expérience utilisateur.
Actuellement, la configuration de l'horodatage hors site dans nos tables sources de développement de données est corrigée. Cependant, dans les scénarios de calcul de tâches en temps réel, certains clients se concentrent uniquement sur le calcul des données de la journée et configurent donc une politique start-stop pour réexécuter la tâche chaque jour. Ils souhaitent pouvoir réexécuter la tâche chaque jour à partir de minuit, plutôt que d’utiliser un horodatage fixe. Bien que Latest puisse théoriquement répondre à cette exigence, la consommation du temps de démarrage des tâches en temps réel peut entraîner un écart du temps d'exécution réel par rapport à zéro, entraînant des erreurs de données.
Instructions d'optimisation de l'expérience :
1. Optimisez la configuration de la politique start-stop , prenez désormais en charge la politique start-stop sur plusieurs jours et améliorez l'interaction actuelle de la page de politique start-stop pour offrir une expérience d'exploitation plus efficace et plus pratique.
2. Développement de données - table source, prend en charge la configuration paramétrée des emplacements hors site
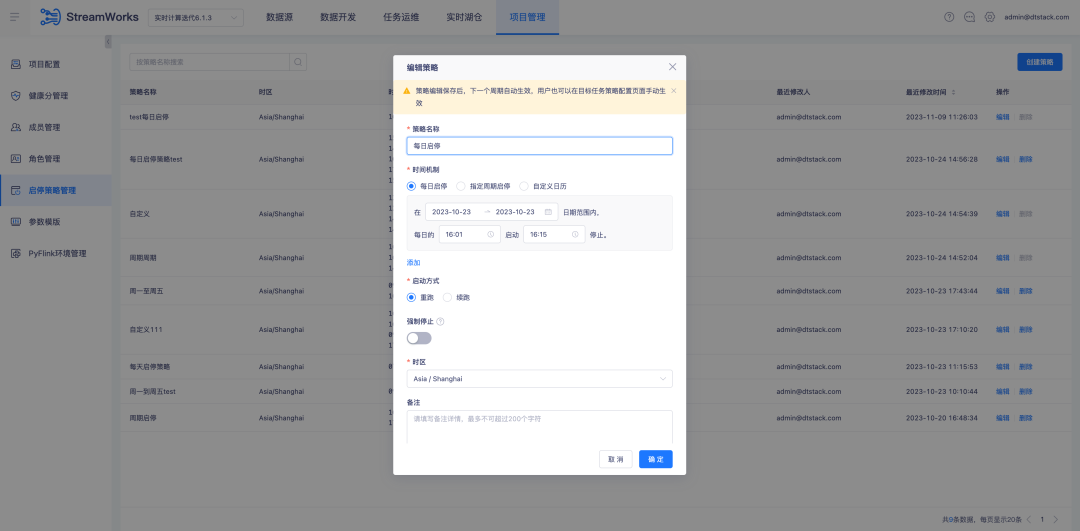
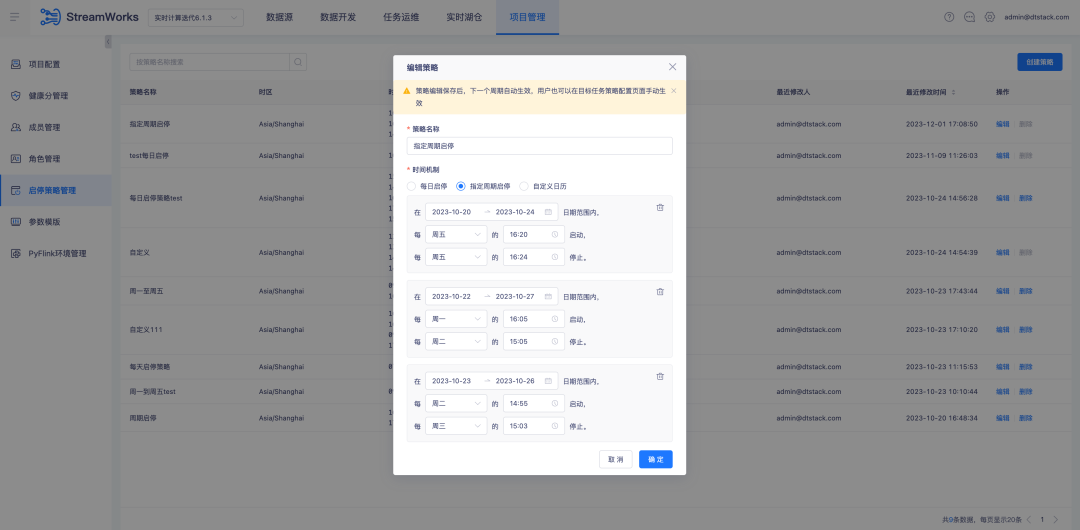
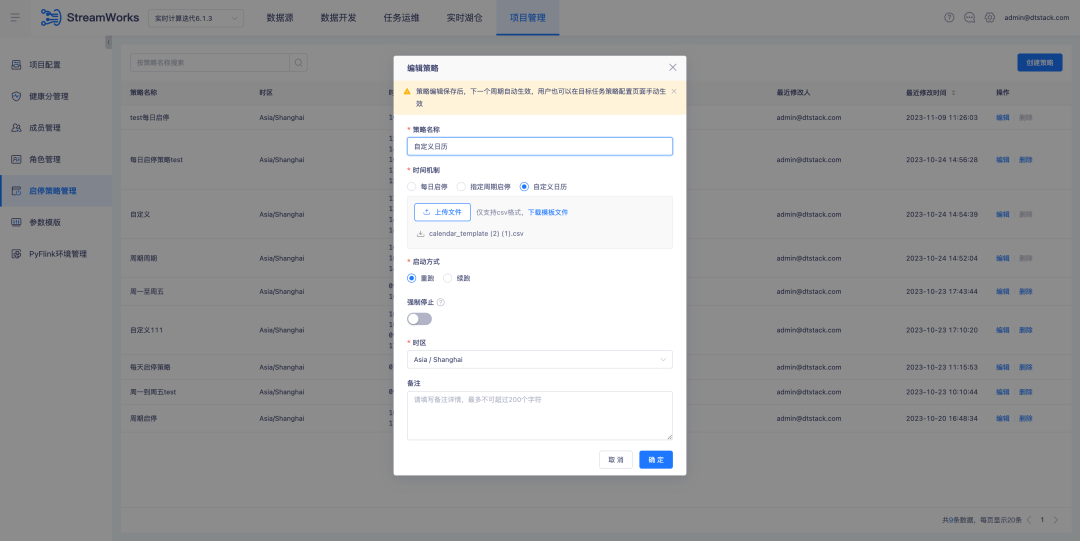
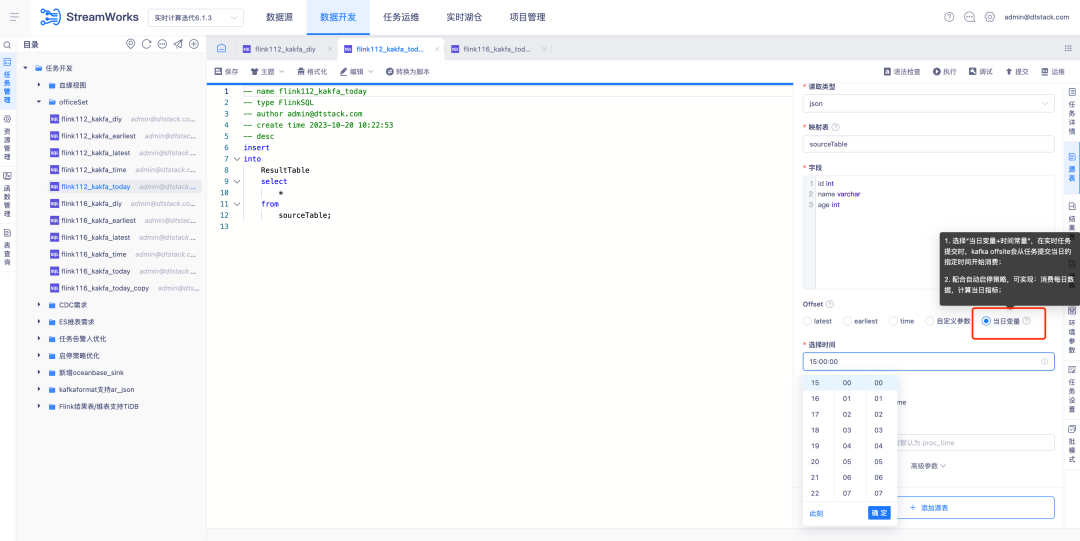
3.Optimisation du plug-in FlinkSQL1.16 version ES7.x
Contexte : Le plug-in ES de FlinkSQL version 1.10 prend en charge la configuration du délai d'expiration de la table de dimensions et de la limite de données de délai d'expiration. Cette fonction est temporairement indisponible dans la version actuelle de FlinkSQL 1.16 et est activement optimisée.
Instructions d'optimisation de l'expérience :
La table de dimension du plug-in FlinkSQL1.16 version ES7.x configure table.exec.async-lookup.timeout ou utilise la syntaxe d'indications pour définir le délai d'expiration. Lorsque la tâche est exécutée en mode LRU de la table de dimension, le délai d'expiration de la requête asynchrone prend. effet.
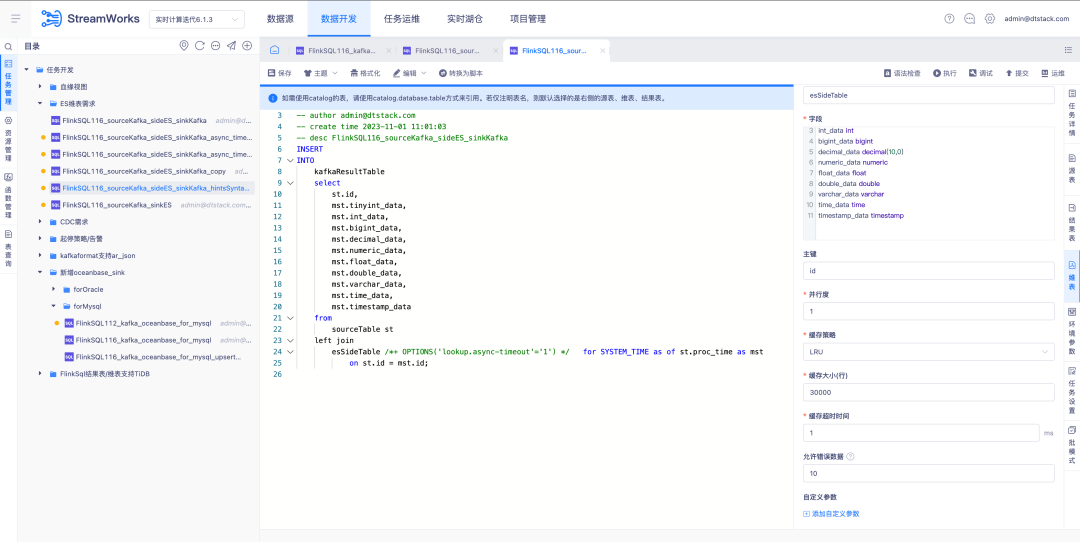
4.Optimisation de la configuration des alarmes
Contexte : Dans les règles d'alarme de tâche, la configuration de réception d'alarme doit être sélectionnée manuellement. Il n'est pas possible de faire correspondre et d'envoyer automatiquement les informations d'alarme en fonction de la personne responsable de la tâche. En même temps, dans la configuration globale de l'alarme, c'est également le cas. impossible d'envoyer automatiquement les informations d'alarme correspondantes en fonction du responsable de la tâche.
Instructions d'optimisation de l'expérience :
1. Ajustement du destinataire de la configuration de la règle d'alarme de tâche unique . La personne responsable de la tâche est sélectionnée par défaut. D'autres destinataires peuvent être sélectionnés via la zone de sélection.
2. La configuration de la règle d'alarme globale sera effectivement envoyée à la personne responsable de chaque tâche lorsque la personne responsable de la tâche est cochée. Lorsque d'autres destinataires sont sélectionnés, la tâche sélectionnée sera envoyée au destinataire sélectionné lorsque la tâche sélectionnée est anormale.
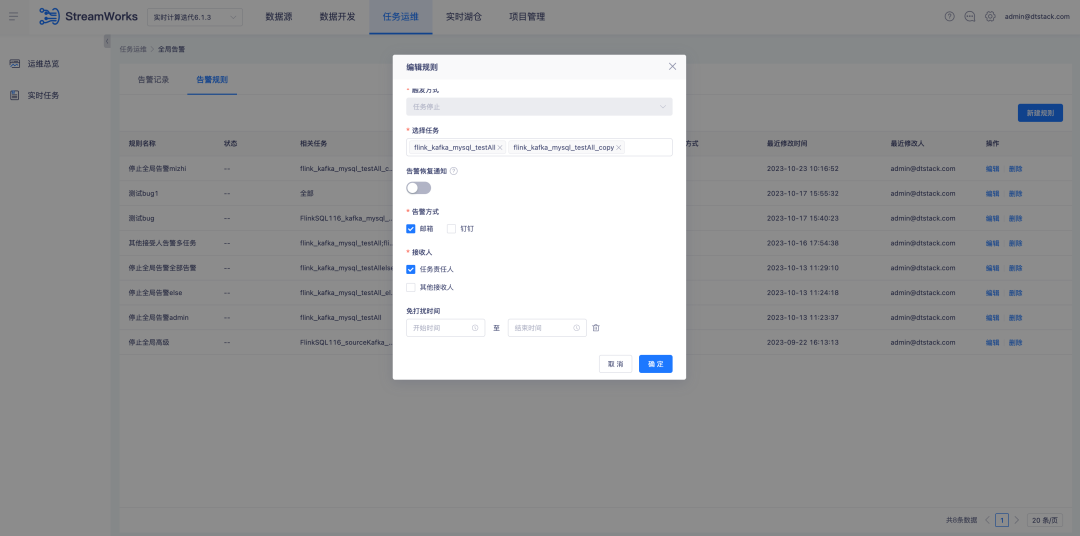
5. La plate-forme de plug-in Tidb version FlinkSQL1.12 et 1.16 est compatible
Contexte : les versions 1.12 et 1.16 de FlinkSQL ont terminé leur adaptation à Tidb. Cependant, la couche plateforme n'a été adaptée que dans la version 1.10, les versions 1.12 et 1.16 ne sont donc pas prises en charge.
Instructions d'optimisation de l'expérience :
La plateforme en temps réel est compatible avec les plug-ins Tidb versions 1.12 et 1.16 et doit prendre en charge à la fois les tableaux de dimensions et les tableaux de résultats.
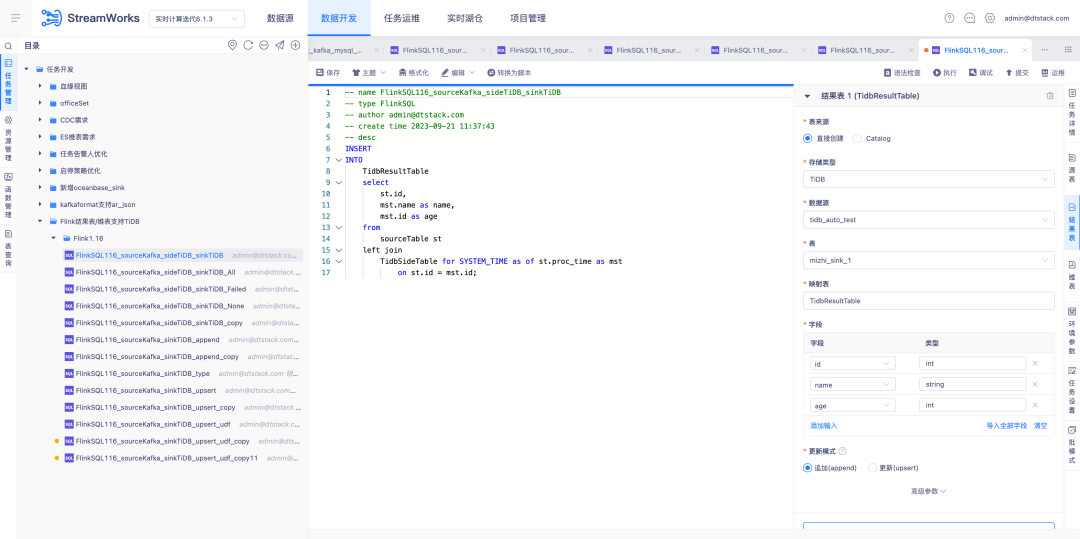
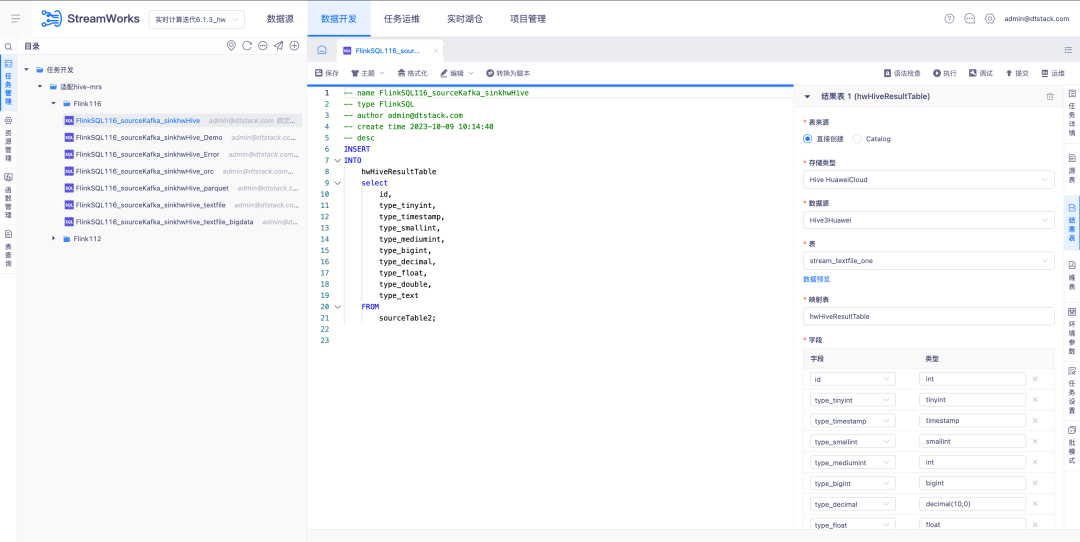
6.FlinkSQL1.12 et 1.16 versions Hive huaweiCloudAdaptation
Contexte : La sauvegarde en temps réel des données Kafka est saisie dans MRS Hive. En cas de problème avec les données de calcul en temps réel, les messages de sauvegarde dans Hive peuvent être analysés.
Instructions d'optimisation de l'expérience :
FlinkSQL version 1.12 et 1.16 est adapté à Hive HuaweiCloud. Le centre de source de données, le moteur et la plate-forme sont développés simultanément pour prendre en charge le tableau de résultats Hive HuaweiCloud . Vous devez faire attention au scénario d'activation de Kerberos.
Plateforme de services de données
Nouvelles mises à jour de fonctionnalités
1. Prise en charge de l'API de création de versions HBase TBDS
Ajout de l'API de création de version HBase TBDS, notamment : API de génération en mode assistant , importation et exportation, et publication sur des projets cibles.

Optimisation des fonctions
1.La source de données Oracle prend en charge DML
Améliorer les sources de données prises en charge par DML .
2. L'analyse des commentaires en mode SQL personnalisé n'écrase plus la description
Contexte : Pour la logique historique, une fois le schéma SQL personnalisé ré-analysé pour la base de données, les commentaires fournis avec la base de données écraseront les instructions modifiées.
Instructions d'optimisation de l'expérience : modifiez la logique historique Pour les instructions modifiées, les commentaires dans la base de données ne seront plus écrasés après une nouvelle analyse.
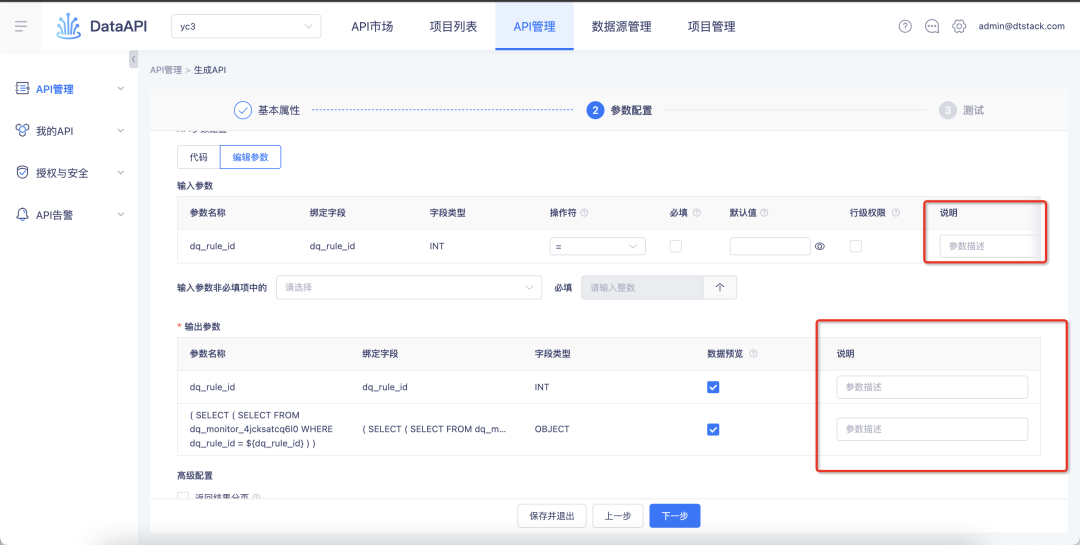
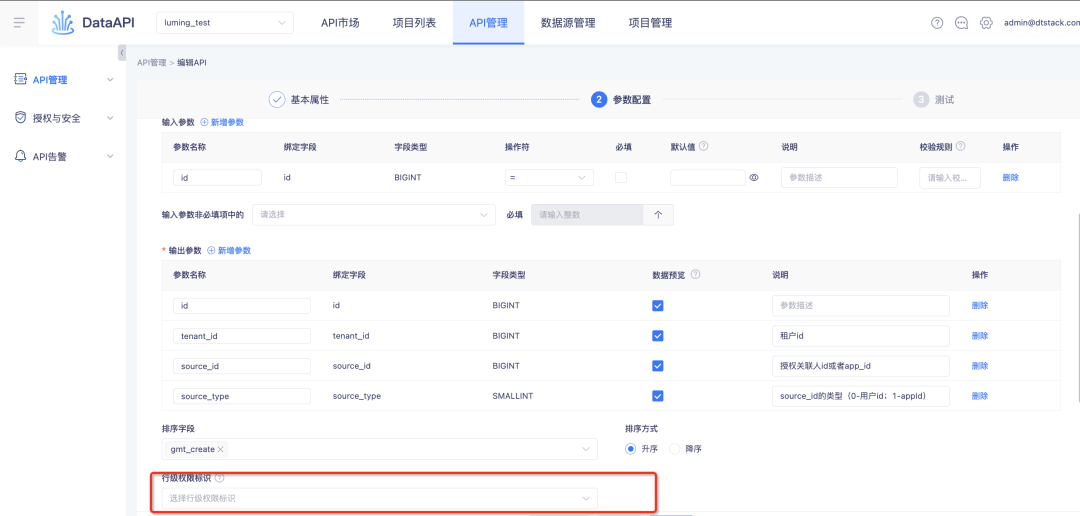
3. Une fois les autorisations au niveau de la ligne activées, il n'est pas nécessaire de les renseigner par défaut.
Contexte : pour les autorisations historiques au niveau des lignes, les autorisations au niveau des lignes seront activées à partir des champs du tableau. Après avoir été activées, les champs seront requis par défaut et l'annulation par l'utilisateur n'est pas prise en charge.
Description de l'optimisation de l'expérience : cette itération ajuste la logique historique. Les autorisations au niveau de la ligne seront activées à partir du niveau de l'API. Après avoir été activées, lorsque l'API utilise la table, elle sera limitée par les autorisations au niveau de la ligne.
4. Version du framework et mise à niveau des composants
La version du framework Spring Cloud (Boot) est mise à niveau et le composant Nacos est mis à niveau pour réduire la probabilité de vulnérabilités et améliorer la stabilité de l'API elle-même.
Plateforme d'analyse des données clients
Nouvelles mises à jour de fonctionnalités
1. Prise en charge des fonctions UDF personnalisées
Contexte : Le numéro de téléphone mobile, le numéro d'identification et les autres données impliquées dans les données traitées par le client sont des données cryptées du point de vue de l'audit, ce type de données ne peut pas être affiché en texte brut, mais il existe des scénarios dans lesquels le contenu en texte brut l'est. affiché dans l'entreprise de niveau supérieur. Par exemple : marketing par SMS basé sur des numéros de téléphone mobile.
Les clients doivent retarder le processus de décryptage le plus tard possible, le placer sur la plate-forme d'étiquettes pour le terminer et ajouter des étiquettes personnalisées via la personnalisation de la fonction UDF pour terminer le traitement.
Description des nouvelles fonctions : Un nouveau module de gestion des fonctions a été ajouté au centre de balises , sous lequel les fonctions UDF peuvent être créées, visualisées et supprimées (seules les versions Trino385 et supérieures prennent en charge la création de fonctions)
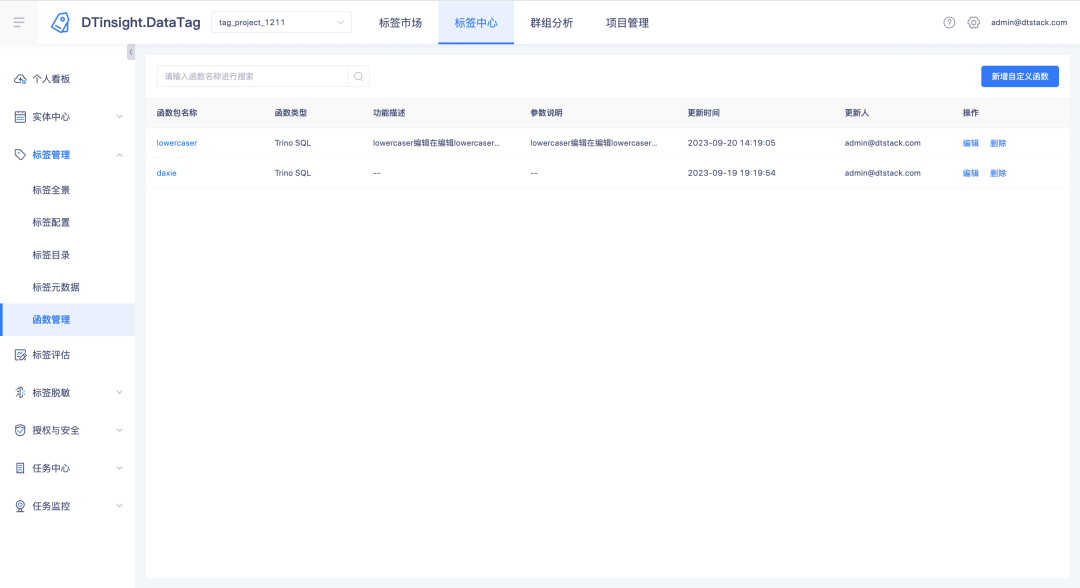
Pour les fonctions téléchargées, vous pouvez cliquer sur le nom de la fonction pour afficher les détails de la fonction.
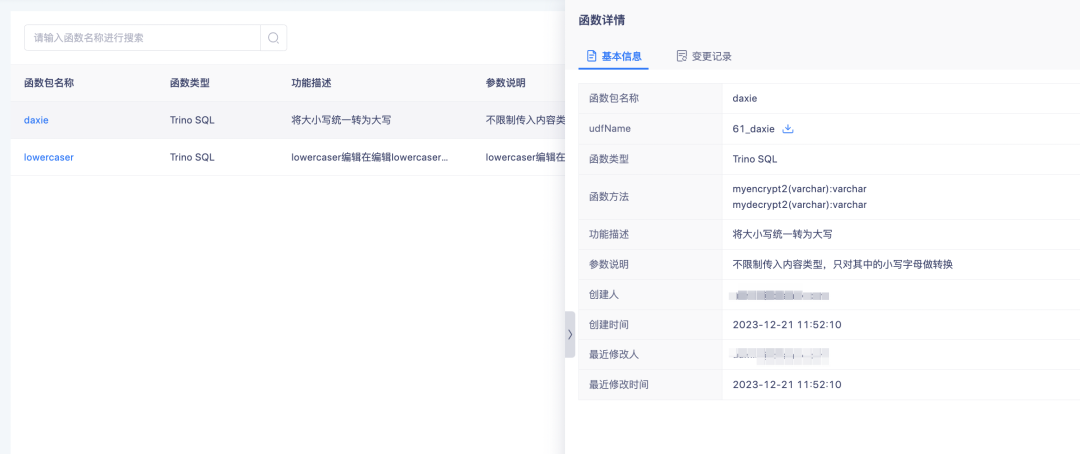
La fonction téléchargée est principalement utilisée pour traiter les balises SQL dérivées.
2. Prise en charge du traitement des balises à valeurs multiples
Contexte : Les règles de traitement actuelles pour les balises dérivées et les balises combinées sont que lorsqu'une instance atteint pour la première fois une certaine condition de règle, la valeur de balise correspondante sera marquée sur l'instance et les autres valeurs de balise ne correspondront plus. , les résultats des balises à valeur unique seront stockés dans la base de données.
Cependant, dans les applications pratiques, les conditions ne s'excluent pas nécessairement mutuellement. Par exemple, l'utilisateur reçoit une étiquette de préférence de produit basée sur le nombre de fois où il a acheté un type spécifique de produit. Un utilisateur peut aimer à la fois les meubles et les vêtements. Dans ce cas, plusieurs valeurs doivent être prises en charge.
Description des nouvelles fonctionnalités :
Les balises de règle dérivées, les balises SQL dérivées, les balises combinées et le traitement des balises personnalisées prennent en charge la configuration en tant que balises à valeurs multiples et le système les calcule en fonction du type de valeur de balise défini.
• Balises à valeur unique : faites correspondre dans l'ordre selon la configuration de la règle. Arrêtez la correspondance lorsqu'une certaine valeur de balise est atteinte. Il y a au plus une valeur de balise dans le résultat des données.
• Balises à valeurs multiples : correspondance en séquence selon l'ordre de configuration des règles. Chaque règle sera mise en correspondance une fois. Il y aura au plus n valeurs de balise configurées dans le résultat des données.
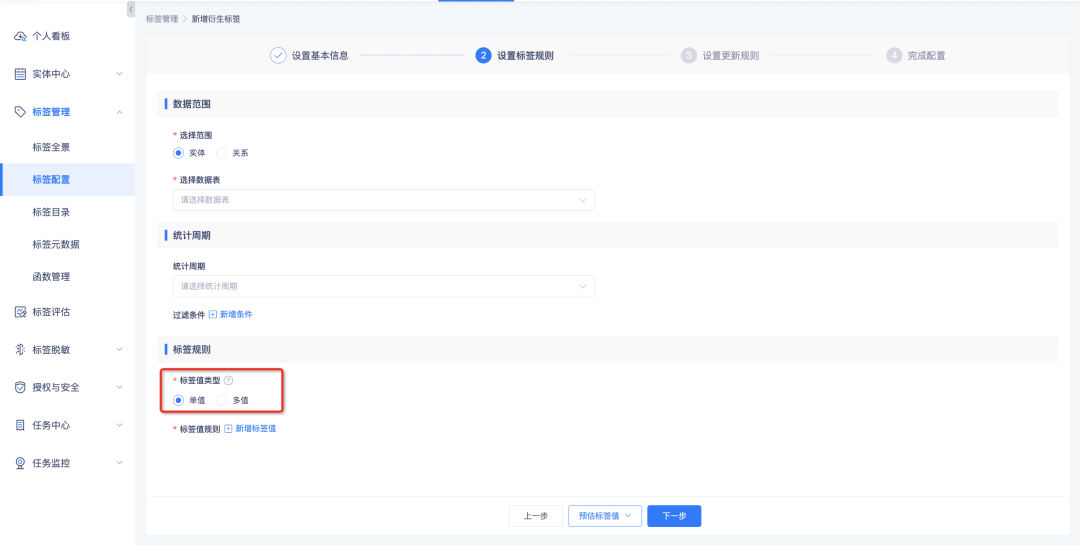
Sur la base des résultats du calcul, les détails de l'étiquette compteront le nombre d'instances pour chaque étiquette individuelle, c'est-à-dire que la somme du nombre d'instances couvertes par chaque valeur d'étiquette d'une étiquette à valeur unique correspond au nombre d'instances couvertes par l'étiquette. et le nombre d'instances couvertes par chaque valeur d'étiquette d'une étiquette à valeurs multiples. La somme des nombres est supérieure ou égale au nombre d'instances de couverture d'étiquette.
3. Centre d'affaires d'accueil de rôle personnalisé
Contexte : Auparavant, les rôles étaient des rôles intégrés dans le système et les rôles ne pouvaient pas être ajoutés/modifiés/supprimés. Les autorisations de rôle ne pouvaient pas être personnalisées. Les fonctions étaient trop fixes et ne pouvaient pas être ajustées de manière flexible en fonction des scénarios commerciaux réels. clients. Dans la version 6.0, le centre d'affaires a ajouté une fonction de rôle de personnalisation, le produit tag est connecté à cette fonction du centre d'affaires pour obtenir les effets suivants :
1. Soutenir de nouveaux rôles
2. Prise en charge des autorisations de rôle personnalisées
Nouvelle description de la fonction : configurez les rôles et leurs autorisations d'indicateur dans le centre d'affaires, et la plateforme d'étiquetage introduira automatiquement les résultats de configuration des autorisations pour la requête.
1. Ajoutez de nouveaux rôles et configurez les points d'autorisation des rôles dans le centre d'affaires :
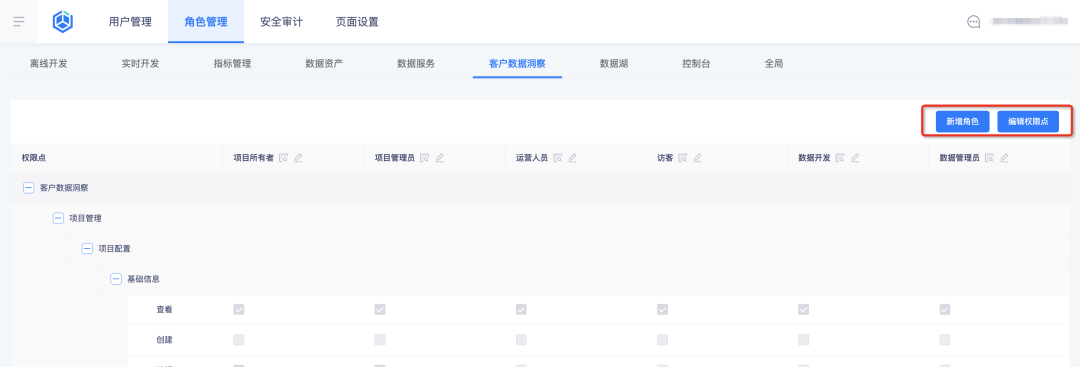
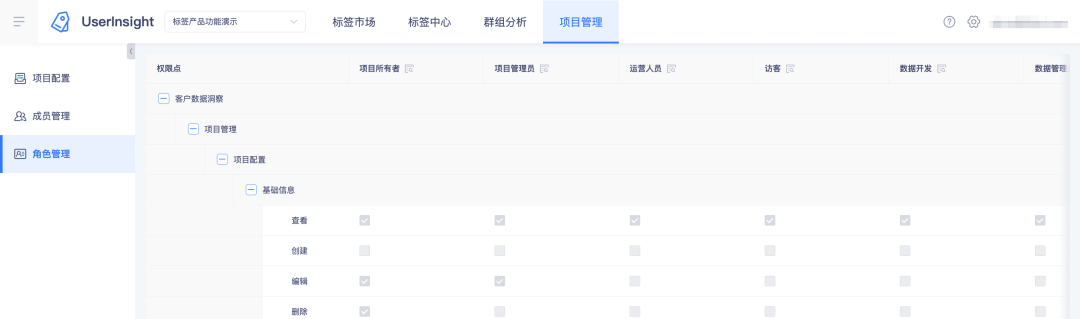
2. Affichez les rôles et leurs points d'autorisation sur la plateforme de balises :
4. Le format d'affichage des données prend en charge la personnalisation
Contexte : Pour les balises numériques, la définition de la précision d'affichage n'est actuellement pas prise en charge, ce qui entraîne un affichage irrégulier de la page. Certaines affichent des nombres entiers tels que 1 et d'autres des décimales telles que 1,234. L'expérience de lecture globale n'est pas élevée. Afin d'améliorer l'utilisateur. expérience, il est nécessaire d'ajouter des paramètres de règle d'affichage des données.
Description des nouvelles fonctionnalités :
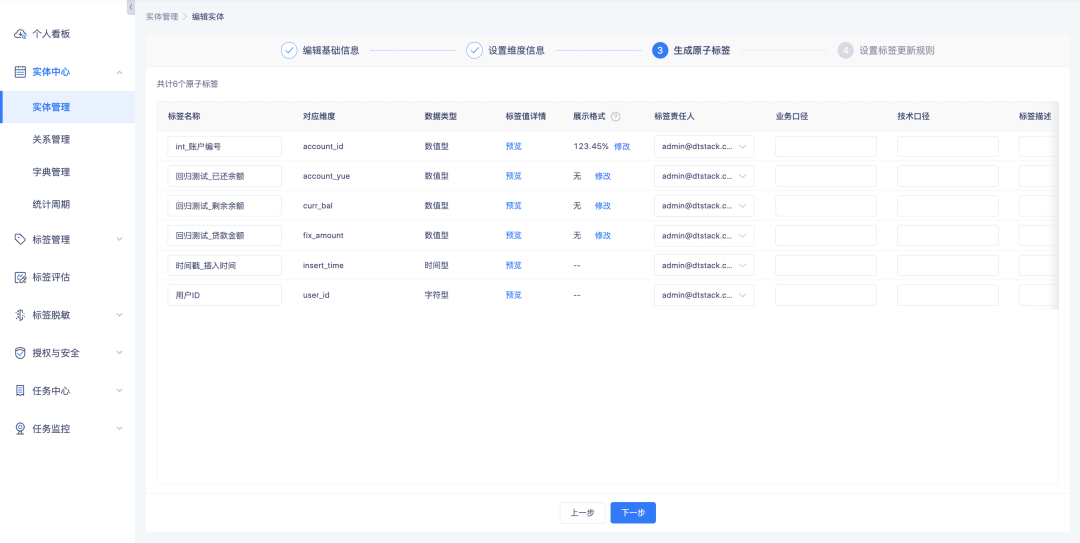
1. Lors de la création/modification d'entités, de la modification de balises atomiques et de la création/modification de balises SQL dérivées, il est pris en charge pour définir des règles d'affichage pour les balises numériques.
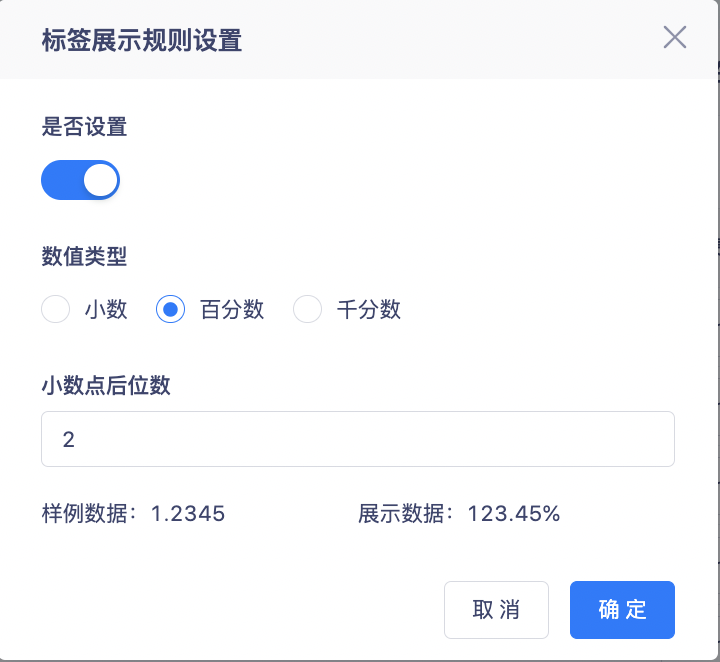
2. Prend en charge l'affichage sous forme de décimales, de pourcentages et de millièmes, et prend en charge le réglage du nombre de chiffres après la virgule décimale.
3. Les données de balise affichées sur les pages liées au groupe sont affichées selon les règles d'affichage définies.
5. Le téléchargement de fichiers de balises/groupes prend en charge l'affichage de la progression du téléchargement
Contexte : La fonction d'importation de fichiers est actuellement téléchargée sans invites de progression. Lorsque le fichier est trop volumineux, le temps d'attente est long, ce qui amènera les utilisateurs à mal comprendre que la page est bloquée. Des invites de progression doivent être ajoutées pour que la progression actuelle soit claire. utilisateurs.
Description des nouvelles fonctionnalités :
1. Ajout d'invites de progression lors des tâches d'étiquette, de téléchargement de fichiers de groupe et de requête hors ligne.
2. Le téléchargement de fichiers de groupe a été ajusté pour prendre en charge le téléchargement de fichiers d'une taille maximale de 500 Mo.
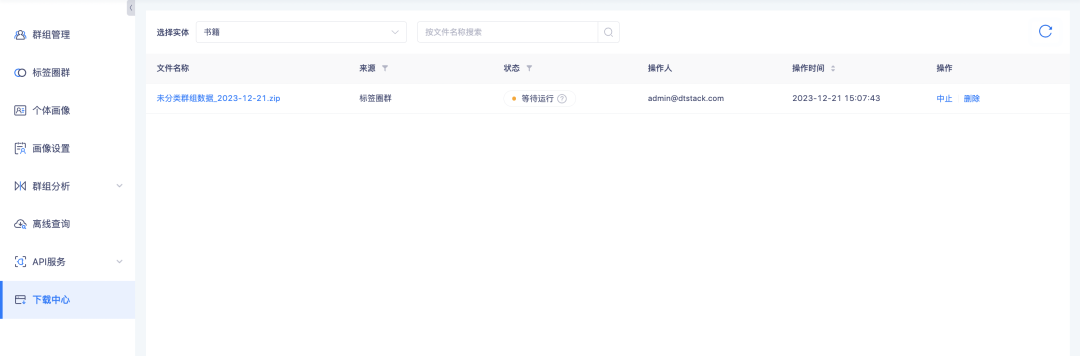
6. Le centre de téléchargement prend en charge l'interrogation de la progression du téléchargement.
Contexte : pendant le processus de téléchargement des données, en raison de la grande quantité de données, la préparation des données avant de pouvoir être téléchargées prend beaucoup de temps. Les utilisateurs ne s'y attendent pas lorsqu'ils les utilisent et doivent les actualiser fréquemment pour déterminer si le téléchargement est effectué. peut être effectuée. Des invites de progression du téléchargement doivent être ajoutées pour guider les utilisateurs dans la détermination du temps d'attente.
Nouvelle description de la fonction : L'état de la tâche du centre de téléchargement ajoute l'état d'attente d'exécution et d'abandon. Parmi eux, le téléchargement de la liste de groupes-groupes de cercles de balises, la liste de groupes de détails de groupe, le téléchargement de la liste d'instances de groupe locale, la liste d'instances de détails de groupe de requête hors ligne, l'intersection de groupe et la liste d'instances de différence dépendent des données de la liste de groupe. le volume de téléchargement est important, il sera exécuté en mode de téléchargement en série. Les tâches liées à la liste de groupes seront mises en file d'attente pour être exécutées en séquence. Celles qui ne sont pas en file d'attente attendent d'être exécutées directement. . Pendant que les tâches sont en cours d'exécution, vous pouvez abandonner celles qui ne sont plus nécessaires.
Optimisation des fonctions
1. L'exportation des données est ajustée pour télécharger des fichiers via le centre de téléchargement
Contexte : les téléchargements de fichiers sur certaines pages sont téléchargés directement, ce qui fait que le bouton est toujours en cours d'exécution et que l'utilisateur ne peut pas percevoir la progression du téléchargement.
Description de l'optimisation de l'expérience : Après avoir cliqué sur le bouton relatif à l'exportation des données, le fichier sera téléchargé de manière asynchrone. Une fois le téléchargement terminé, vous pourrez accéder au module "Centre de téléchargement" pour télécharger les détails des données. Les boutons de page concernés sont les suivants : Groupe de cercles - Exportation de données, Détails du groupe - Exportation de données de liste de groupe, téléchargement de données de liste d'instance de groupe local, téléchargement de requêtes hors ligne, intersection de groupe/groupe local et exportation de données de détails de différence, intersection de groupe et exportation de données de différence.
Si la quantité de données est trop importante, le système les exportera dans des fichiers séparés en fonction de la limite supérieure du nombre d'enregistrements défini par l'utilisateur.
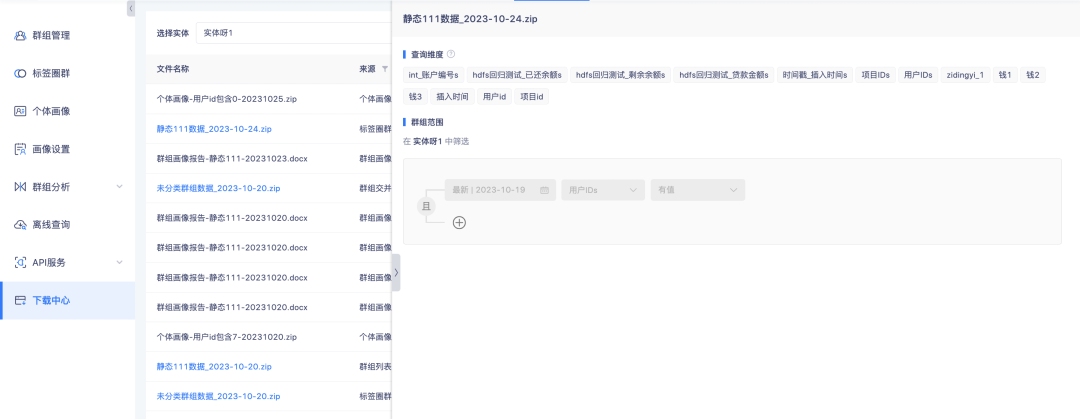
2. Répertorier les données des groupes de cercles de balises et les détails des groupes dans le centre de téléchargement prend en charge l'affichage des détails de configuration.
Contexte : Actuellement, il existe de nombreuses sources de fichiers dans le centre de téléchargement, et il n'est pas pratique de distinguer le contenu uniquement en fonction des noms de fichiers. Il est nécessaire d'augmenter les sources de données de fichiers pour améliorer la disponibilité des données.
Description de l'optimisation de l'expérience : répertoriez les données des groupes de cercles de balises et les clics sur les détails du groupe. Cliquez sur la barre latérale pour ouvrir les détails de configuration.
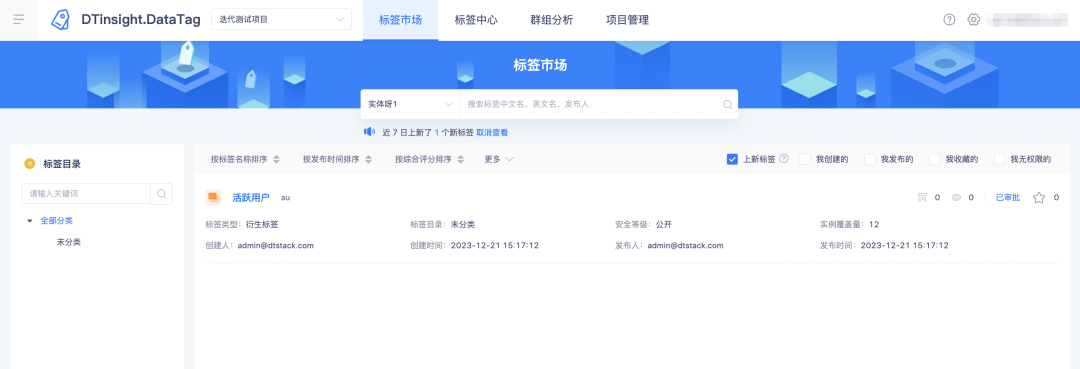
3. Optimisation des nouvelles fonctions des tags sur le marché des tags
Contexte : Actuellement, la plateforme n'explique pas la définition des nouvelles balises et doit être ajoutée.
Description de l'optimisation de l'expérience : les nouvelles balises sur la plate-forme sont définies comme les dernières 24 heures, mais dans la réalité, les gens n'y prêtent généralement pas attention le week-end. Lorsqu'ils y prêtent à nouveau attention lundi, il y aura des situations où les balises mises à jour proviennent. Le vendredi au dimanche matin ne peut pas être notifié sur place. Ajustez la définition aux 7 derniers jours.
4. Optimisation de l'adaptation des autorisations de commutation entre sous-produits
Lorsqu'un produit balisé passe d'un sous-produit à l'autre, le contenu de l'onglet sur la page sera manquant en raison de problèmes d'autorisation. Cette optimisation garantit que la fonction est disponible lors du changement de page entre les produits.
5. Prise en charge du réglage et de la personnalisation de la largeur des colonnes
La liste de groupes, la liste de groupes de détails de groupe, la liste d'utilisateurs de groupe de cercles de balises, la liste d'intersections de groupes et d'instances de différence et la largeur de colonne de la liste de balises prennent en charge la personnalisation.
Après avoir personnalisé la largeur de la colonne, elle prendra effet pour les utilisations ultérieures en fonction du navigateur actuel et de l'utilisateur actuellement connecté. Lorsque l'utilisateur se connecte à l'aide d'un nouveau navigateur, efface le cache du navigateur actuel ou se reconnecte, le. les paramètres par défaut seront affichés.
Plateforme de gestion d'indicateurs
Nouvelles mises à jour de fonctionnalités
1. Centre d'affaires d'accueil de rôle personnalisé
Contexte : Auparavant, les rôles étaient des rôles intégrés dans le système et les rôles ne pouvaient pas être ajoutés/modifiés/supprimés. Les autorisations de rôle ne pouvaient pas être personnalisées. Les fonctions étaient trop fixes et ne pouvaient pas être ajustées de manière flexible en fonction du scénario commercial réel du client. .
Description des nouvelles fonctionnalités :
Configurez le rôle et ses autorisations d'indicateur dans le centre d'affaires , et la plateforme d'indicateurs introduira automatiquement les résultats de configuration des autorisations pour la requête :
1. Ajoutez de nouveaux rôles et configurez les points d'autorisation des rôles dans le centre d'affaires
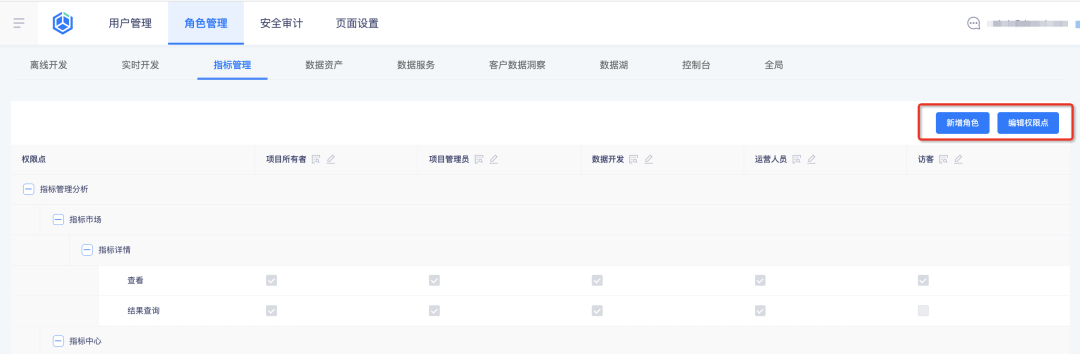
2. Affichez les rôles et leurs points d'autorisation sur la plateforme d'indicateurs
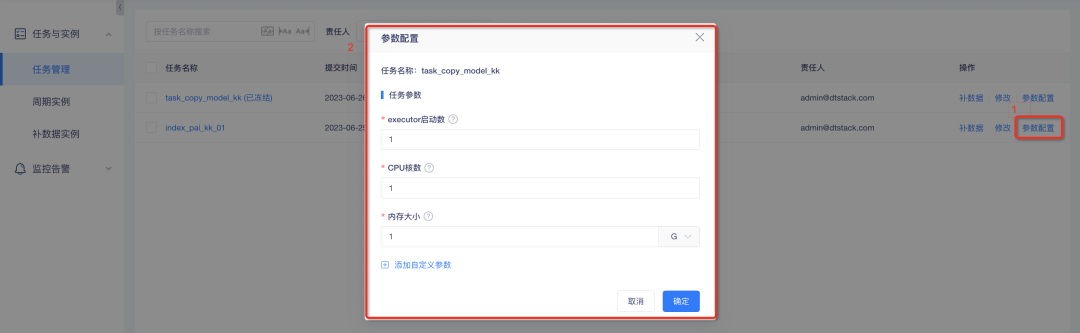
2. Les tâches Spark et de synchronisation des données prennent en charge la configuration des paramètres personnalisés
Contexte : Pour les tâches Spark et les tâches de synchronisation de données, les ajustements de paramètres ne peuvent actuellement être effectués que via la console. Les résultats des ajustements prendront effet globalement. Cependant, les différences d'ampleur des données entre les tâches d'indicateur sont importantes et la configuration des mêmes paramètres entraînera un gaspillage. Par conséquent, des paramètres au niveau des tâches peuvent être définis pour les tâches Spark et de synchronisation des données afin de faciliter un contrôle flexible des tâches.
Description des nouvelles fonctionnalités :
1. Configuration des paramètres personnalisés de la tâche Spark : parmi eux, le nombre de démarrages de l'exécuteur, le nombre de cœurs de processeur et la taille de la mémoire sont requis ;
2. Configuration des paramètres personnalisés pour les tâches de synchronisation des données : en mode par tâche, la mémoire du gestionnaire de tâches, la mémoire du gestionnaire de tâches et les emplacements sont requis ; le nombre de tâches simultanées et les paramètres personnalisés WriteBufferSize de HBase peuvent être définis ;
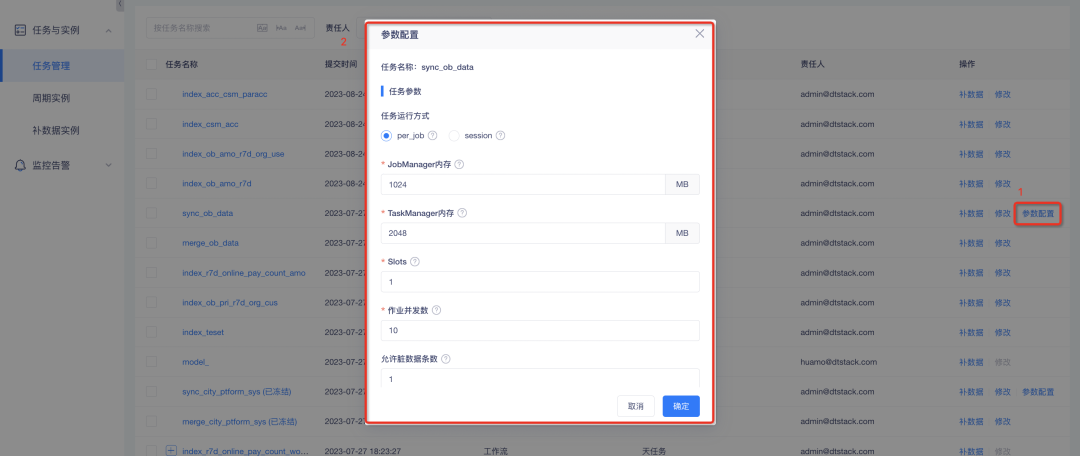
Optimisation des fonctions
1. Le navigateur prend en charge l'ouverture de plusieurs projets en même temps
Contexte : Dans la fonction d'historique, le cookie ne stocke pas les paramètres du projet. Par conséquent, lorsque la pile de données ouvre une nouvelle fenêtre de projet, le contenu de la fenêtre d'historique sera actualisé et l'utilisateur reviendra à la page de liste des projets du projet. sélection, ce qui affecte l’utilisation du client.
Description de l'optimisation de l'expérience : cette optimisation permet au navigateur d'ouvrir plusieurs projets en même temps pour des requêtes, des opérations, etc. afin d'améliorer l'efficacité de l'utilisation du produit.
Compatible avec le navigateur 2.edge
Compatibles avec le navigateur egde, les fonctions seront adaptées en conséquence pour améliorer l'ergonomie du produit sur les navigateurs grand public.
3. Temps de mise à jour du tableau supplémentaire de mise à jour des lignes
Contexte : L'enregistrement de données de mise à jour de ligne ne dispose pas de la période de modification des données de la table, ce qui rend la récupération des données peu pratique. Afin d'améliorer l'efficacité de la récupération des données, les données pertinentes sont ajoutées à la plate-forme.
Description de l'optimisation de l'expérience : la mise à jour de la ligne d'indicateur ajoute l'heure de début et l'heure de fin de la modification des données du tableau.
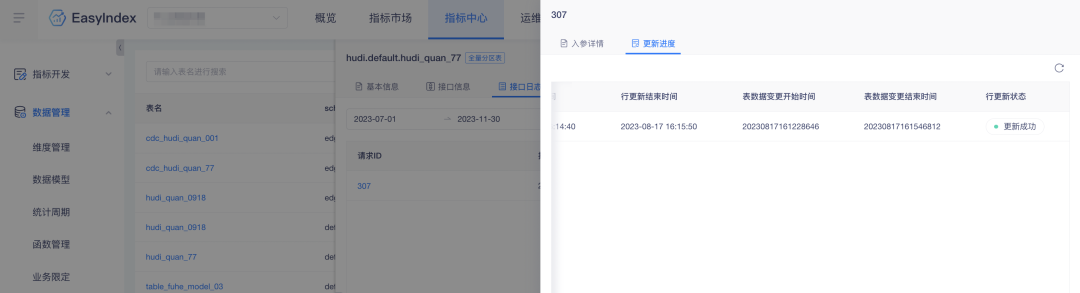
4. Ajouter une fonction d'actualisation manuelle à l'état de mise à jour des lignes
Pendant le processus de mise à jour des lignes, afin de faciliter le suivi en temps opportun de la progression de la mise à jour, un bouton d'actualisation est ajouté à la page pour améliorer l'efficacité de l'actualisation.
5. Optimisation des objets dimensionnels remplis par le modèle et des fonctions d'attributs dimensionnels
Lors de l'édition du modèle, à l'étape de définition des informations sur les dimensions, le système remplira par défaut les informations sur les dimensions liées aux champs de la table de dimensions principale si l'utilisateur a modifié les dimensions associées dans la version historique et si vous n'y prêtez pas attention. à l'ajustement pendant le processus d'édition, des données incorrectes seront enregistrées pour éviter le taux d'erreur de données, ajusté pour faire écho aux informations enregistrées dans la version précédente.
6. La passerelle API prend en charge les préfixes personnalisés
Les informations de préfixe de l'indicateur sont actuellement écrites dans l'élément de configuration de l'API. Dans le même temps, l'API dispose actuellement d'une fonction de préfixe personnalisée pour améliorer la flexibilité de la configuration de l'API. À l'heure actuelle, lorsque les éléments de configuration de l'API de l'indicateur ne correspondent pas au préfixe personnalisé de l'API, les données ne peuvent pas être appelées normalement. Elles doivent être ajustées aux paramètres de configuration de l'API d'accueil pour garantir que la configuration globale est unique.
Adresse de téléchargement du « Livre blanc sur les produits Dutstack » : https://www.dtstack.com/resources/1004?src=szsm
Adresse de téléchargement du « Livre blanc sur les pratiques de l'industrie de la gouvernance des données » : https://www.dtstack.com/resources/1001?src=szsm
Pour ceux qui souhaitent en savoir ou en savoir plus sur les produits Big Data, les solutions industrielles et les cas clients, visitez le site officiel de Kangaroo Cloud : https://www.dtstack.com/?src=szkyzg
Linus a pris sur lui d'empêcher les développeurs du noyau de remplacer les tabulations par des espaces. Son père est l'un des rares dirigeants capables d'écrire du code, son deuxième fils est directeur du département de technologie open source et son plus jeune fils est un noyau open source. contributeur. Robin Li : Le langage naturel deviendra un nouveau langage de programmation universel. Le modèle open source prendra de plus en plus de retard sur Huawei : il faudra 1 an pour migrer complètement 5 000 applications mobiles couramment utilisées vers Java, qui est le langage le plus enclin . vulnérabilités tierces. L'éditeur de texte riche Quill 2.0 a été publié avec des fonctionnalités, une fiabilité et des développeurs. L'expérience a été grandement améliorée. Bien que l'ouverture soit terminée, Meta Llama 3 a été officiellement publié. la source de Laoxiangji n'est pas le code, les raisons derrière cela sont très réconfortantes. Google a annoncé une restructuration à grande échelle.