
Alibaba Cloud et Tencent Cloud ont tous deux connu des situations où toutes les zones de disponibilité étaient paralysées en même temps en raison d'une panne de composant. Cet article explorera comment réduire le domaine des pannes du point de vue de la conception architecturale et minimiser les pertes commerciales lorsque des pannes se produisent, et prendra la pratique de stabilité de Sealos comme exemple pour partager des expériences et des leçons.
Abandonnez le maître-esclave et adoptez l’architecture peer-to-peer
Il ressort du rapport de panne de Tencent Cloud que la défaillance de plusieurs zones de disponibilité en même temps est essentiellement causée par certains composants centralisés, tels que l'API unifiée, l'authentification unifiée et d'autres défaillances du système.
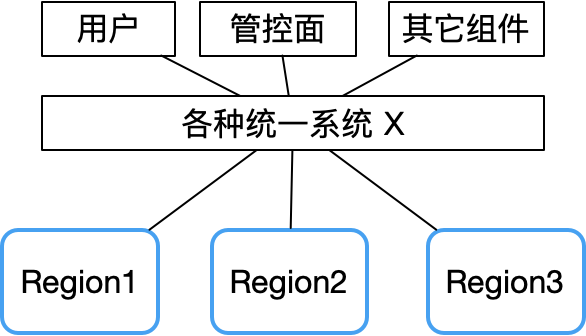
Par conséquent, une fois le système X défaillant, le domaine de pannes sera très vaste.
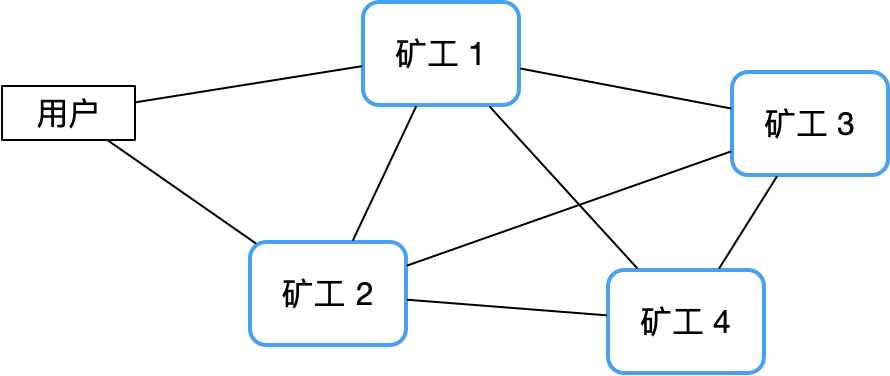
En revanche, une architecture peer-to-peer décentralisée peut bien éviter ce risque. Prenons l'exemple du réseau Bitcoin puisqu'il n'y a pas de nœud central, sa stabilité est bien supérieure à celle d'un cluster maître-esclave traditionnel, et il est presque difficile de raccrocher.
Par conséquent, Sealos a pleinement absorbé les leçons d'Alibaba Cloud et de Tencent Cloud lors de la conception de zones multi-disponibilité et a adopté une architecture sans propriétaire. Toutes les zones de disponibilité sont autonomes. Le principal problème est la manière dont les données telles que les comptes d'utilisateurs sont stockées dans plusieurs zones de disponibilité. problème. C'est devenu une structure comme celle-ci :
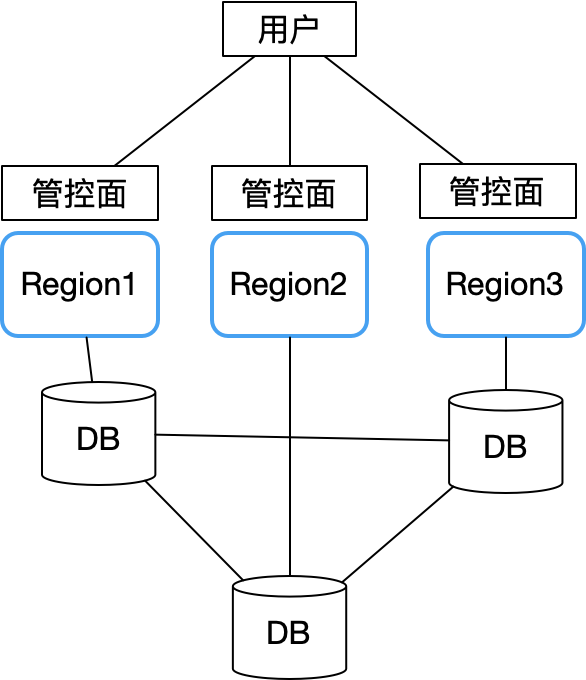
Chaque zone de disponibilité est complètement autonome et synchronise uniquement les données partagées clés (telles que les informations de compte utilisateur) via une base de données distribuée inter-régions (nous utilisons CockroachDB). Chaque zone de disponibilité est connectée au nœud local de la base de données distribuée CockroachDB.
De cette façon, une panne dans une seule zone de disponibilité n’affectera pas la continuité des activités dans les autres régions. Ce n'est que lorsqu'un problème global survient dans le cluster de bases de données distribuées que le plan de contrôle de toutes les zones de disponibilité devient indisponible. Heureusement, CockroachDB lui-même présente d'excellentes performances en matière de tolérance aux pannes, de reprise après sinistre et de réponse aux partitions réseau, ce qui réduit considérablement la probabilité que cette situation se produise. De cette façon, l'architecture globale est simple. Concentrez-vous simplement sur l'amélioration de la stabilité de la base de données, la surveillance et les tests destructifs.
Un autre avantage est que cela facilite la publication en niveaux de gris et les opérations différenciées. Par exemple, de nouvelles fonctions peuvent d'abord être vérifiées avec un faible trafic dans certaines zones, puis entièrement lancées après stabilisation, différentes zones peuvent également fournir des services personnalisés basés sur les caractéristiques des groupes de clients sans avoir à être complètement cohérents ;
Il n'existe pas de système absolument stable
Tout le monde se plaint beaucoup de la stabilité du cloud, mais tous les fournisseurs de cloud sans exception ont connu des échecs. Le plus important ici est de savoir comment converger. Ce n'est pas seulement un problème technique, mais aussi un problème d'organisation. Les questions de gestion sont également une question de coûts. Je vais partager cela avec vous sur la base d'exemples précis que nous avons rencontrés au cours du processus entrepreneurial.
Les leçons de Sealos tirées des échecs
Panne majeure de la Laf le 17 mars 2023
C'est le premier échec majeur que nous avons rencontré lors du démarrage d'une entreprise. Deux jours seulement après le lancement du produit, nous avons reçu une gifle. La raison pour laquelle nous nous souvenons si clairement de cette époque est qu'il s'agissait de la célébration du premier anniversaire de l'entreprise. , et nous n'avons même pas eu le temps de couper le gâteau. Cela a duré jusqu'à environ trois heures du soir.
La cause finale de l'échec était très étrange. Nous avons utilisé des serveurs légers à bas prix . La virtualisation du réseau des conteneurs sur des serveurs légers entraînerait une perte de paquets. En fin de compte, nous avons migré l'ensemble du cluster vers un serveur VPC normal, ce qui pose souvent le problème. était stable. Le sexe et le coût sont indissociables.
Par conséquent, beaucoup de gens pensent que le cloud public coûte cher. Dans de nombreux cas, la résolution des 10 % de problèmes restants coûte plusieurs fois.
Laf a ensuite rencontré une série de problèmes de stabilité liés à la base de données, car il utilisait un modèle dans lequel plusieurs locataires partageaient une bibliothèque MongoDB . La conclusion finale était que cette voie n'allait pas fonctionner et qu'il était difficile pour nous de résoudre l'isolation de la base de données. problème, alors maintenant tous ont adopté la méthode de base de données indépendante et le problème a finalement été résolu.
Il y a aussi le problème de stabilité sur la passerelle. Nous avons initialement choisi un contrôleur Ingress peu fiable , ce qui a causé des problèmes fréquents, je ne nommerai pas le contrôleur spécifique. Finalement, nous l'avons remplacé par Higress, ce qui a complètement résolu le problème. Cela nécessite moins de ressources et est plus stable. Je suis également très reconnaissant à l'équipe d'Alibaba Higress pour son soutien personnel. Les problèmes que nous avons exposés ont également aidé Higress à devenir plus mature, une situation gagnant-gagnant.
En juin 2023, notre cloud public Sealos a été officiellement lancé. L'un des plus gros problèmes que nous avons rencontrés était les attaques CC avec un trafic important. L'ajout d'une protection peut le résoudre, mais cela signifie également une augmentation des coûts, donc un compromis entre les deux. les deux sont très déroutants. Si vous n’empêchez pas la stabilité, il est difficile de la résoudre. Si vous l’empêchez, vous ne pourrez pas récupérer le coût en la vendant. Plus tard, après avoir remplacé la passerelle, nous avons constaté qu'Envoy était vraiment puissant et pouvait réellement résister au trafic d'attaque. Avant cela, nous utilisions Nginx, qui était un guichet unique. De plus, l'avantage du K8 est sa forte capacité d'auto-réparation. Même si la passerelle est en panne, elle peut s'auto-réparer en 5 minutes, tant qu'elle n'est pas en panne en même temps, l'entreprise ne sera pas affectée.
Meilleures pratiques pour la convergence de la stabilité
Processus de dépannage
Afin d'améliorer continuellement la stabilité du système, Sealos a mis en place un processus strict de gestion des pannes en interne :
Chaque fois qu’une panne survient, elle doit être enregistrée en détail et suivie en permanence. De nombreuses entreprises mettent fin au processus d'examen des défaillances, mais en réalité, l'objectif n'est pas de procéder à une évaluation. La clé est de formuler des mesures correctives pratiques et de les mettre en œuvre pour empêcher complètement que des défaillances similaires ne se reproduisent. Une fois le traitement du défaut terminé, vous devez continuer à l'observer pendant un certain temps jusqu'à ce qu'il soit confirmé que le problème ne se produit plus.
En termes d'objectifs de gestion, nous avons initialement défini l'objectif de stabilité et de convergence dans l'OKR du premier trimestre 2024 comme suit :

Plus tard, j'ai découvert que cet OKR général de style slogan n'était pas fiable et que la convergence de la stabilité devait être plus spécifique. Le résultat de ce KR était que nous n'y sommes pas parvenus et qu'il n'a eu presque aucun effet. Dans le processus de convergence, vous n'avez pas besoin de vous épanouir pleinement sur quelques points centraux chaque trimestre et de continuer à itérer pendant quelques trimestres et la convergence sera très bonne.
Ainsi, au deuxième trimestre, nous avons fixé des objectifs plus spécifiques :

La définition de la stabilité ne peut pas se limiter à la définition d’un indicateur, ni être trop générale. Elle nécessite des mesures concrètes et visibles et des méthodes de mesure spécifiques.
Par exemple, si 99,9 % est défini, comment y parvenir ? Alors, quelle est la disponibilité actuelle ? Quelles sont les questions centrales à résoudre ? Comment mesurer? Ce qui doit être fait? Qui le fera ? Les paramètres ne sont pas limités au temps disponible, mais doivent être répertoriés en détail, comme le niveau de défaut, le nombre de défauts, la durée du défaut, l'observation des défauts importants du client, etc.
Il est nécessaire de séparer les catégories spéciales et de lister les priorités, telles que : la stabilité de la base de données, la stabilité de la passerelle, les grands indicateurs de disponibilité du service client, la défaillance de surcharge des ressources CPU/mémoire.
Nous devrions également nous concentrer sur la surveillance des gros clients, tels que Auto Chess, les clients commerciaux FastGPT, Chongchunxue Studio, etc. (utilisation mensuelle de plus de 30 cœurs, choisissez-en 5 typiques).
Il n'y a qu'un nombre limité de problèmes de stabilité. Une fois que ces gros clients sont bien servis, les petits clients peuvent essentiellement être couverts. Ne vous concentrez pas sur la résolution des problèmes de stabilité fondamentaux actuels, puis assurez-vous d'établir un processus de suivi complet.
Les étudiants qui provoquent des dysfonctionnements peuvent être sanctionnés, se voir retirer leurs primes, voire être expulsés. En tant que start-up, nous n'utilisons généralement pas de mesures punitives , car les parties impliquées ne veulent pas provoquer de dysfonctionnements et tout le monde travaille vraiment dur pour résoudre le problème. Ceux qui peuvent vraiment se battre sont ceux qui ont été blessés . préférez les incitations positives, telles que Si la fréquence trimestrielle des échecs diminue, donnez des incitations appropriées .
Conception architecturale simple
L'architecture du système est liée à la stabilité dès le début de la conception. Plus l'architecture est complexe, plus il est facile d'avoir des problèmes, c'est pourquoi de nombreuses entreprises n'y prêtent pas attention. Je participe souvent à la conception et à la révision de l'architecture de l'entreprise, et je trouve généralement. que la conception est trop complexe pour que je puisse la comprendre. , je pense que quelque chose ne va pas. La zone multi-disponibilité de Sealos est un très bon exemple pour transformer une chose complexe en un simple CRUD, il vous suffit d'améliorer la stabilité de la base de données. La conception de la structure des tables de base de données est simple et de nombreux problèmes de stabilité sont résolus dès le berceau.
Il en va de même pour notre système de mesure. Nous l'avons initialement conçu pour avoir plus d'une douzaine de CRD, mais après avoir lutté pendant plus de six mois, la stabilité n'a pas pu être stabilisée. Finalement, nous avons repensé et sélectionné le système. deux semaines pour se développer, et il était en ligne de manière stable en un mois.
Par conséquent : une conception simple est essentielle à la stabilité !
Surveillance modérée, ciblée
La surveillance est une arme à double tranchant : trop n’est pas suffisant. De nombreux échecs de Sealos étaient causés par la surveillance de Prometheus qui occupait trop de ressources et le serveur API était submergé, ce qui a provoqué de nouveaux problèmes de stabilité. Après avoir appris notre leçon, nous sommes passés à une solution de suivi plus légère comme VictoriaMetrics, tout en contrôlant strictement le nombre d'indicateurs de suivi. Des outils comme Uptime Kuma sont très utiles. Ils peuvent se tester mutuellement dans toutes les régions et détecter les problèmes à temps.
Il en va de même pour la garde. Il y a des milliers d’alarmes chaque jour. Donc, ici, nous partons de 0 et additionnons lentement les choses. Par exemple, nous le faisons d'abord du point de vue de la « stabilité finale de l'activité du gros client ». Par exemple, si une panne de conteneur déclenche cela, s'il y a un appel. , le téléphone sonnera probablement sans arrêt. Ajoutez ensuite lentement des éléments comme l'hôte qui n'est pas prêt. Théoriquement, l'hôte n'est pas prêt et ne devrait pas affecter l'activité. Au fur et à mesure que le système mûrit, il sera éventuellement possible de rendre l'hôte non prêt sans avoir besoin d'une garde.
N'ayez pas peur de l'embarras lorsque vous signalez des défauts
Le rapport d'évaluation de Tencent Cloud était très bon. Il expliquait honnêtement les raisons de l'échec, analysait objectivement ce qui n'était pas suffisant et promettait d'y remédier activement. Ce type d’attitude franche et responsable permet en réalité de gagner plus facilement la confiance des utilisateurs. En revanche, garder le sujet secret par crainte de la fermentation de l'opinion publique équivaut à boire du poison pour étancher sa soif. Au lieu de cela, cela donne aux utilisateurs le sentiment qu'il s'agit d'une boîte noire opaque et ils ne savent pas ce qui se passera dans le futur . Les clients qui aiment vraiment vos produits et sont prêts à évoluer avec vous peuvent tolérer des erreurs sans principes. La clé est de faire preuve de sincérité et d’actions pour une réelle amélioration.
Résumer
Le service de cloud public Sealos est lancé depuis plus d'un an et compte plus de 100 000 utilisateurs enregistrés. Avec ses excellentes fonctionnalités, son expérience et sa rentabilité, de nombreux développeurs le privilégient, et certains gros clients ont également commencé à essayer de migrer leur entreprise vers notre cloud Sealos. Parmi eux figurent des produits Internet à grande échelle. Par exemple, le jeu "Happy Auto Chess" compte plus de 4 millions d'utilisateurs actifs .
En regardant vers l'avenir, nous pensons que grâce à une gestion systématique des pannes, nous continuerons à faire converger la stabilité grâce à une conception d'architecture simple et efficace, une stratégie de surveillance stable et constante, et complétée par une attitude de communication ouverte et honnête, Sealos, un cloud qui a été. nourri et développé par une petite entreprise open source nationale, il deviendra certainement un cloud très avancé !
Linus a pris les choses en main pour empêcher les développeurs du noyau de remplacer les tabulations par des espaces. Son père est l'un des rares dirigeants capables d'écrire du code, son deuxième fils est directeur du département de technologie open source et son plus jeune fils est un noyau. contributeur à l'open source. Huawei : Il a fallu 1 an pour convertir 5 000 applications mobiles couramment utilisées Migration complète vers Hongmeng Java est le langage le plus sujet aux vulnérabilités tierces Wang Chenglu, le père de Hongmeng : l'open source Hongmeng est la seule innovation architecturale. dans le domaine des logiciels de base en Chine, Ma Huateng et Zhou Hongyi se serrent la main pour « éliminer les rancunes ». Ancien développeur de Microsoft : les performances de Windows 11 sont « ridiculement mauvaises » " Bien que ce que Laoxiangji est open source, ce ne soit pas le code, les raisons qui le sous-tendent. sont très réconfortants. Meta Llama 3 est officiellement publié. Google annonce une restructuration à grande échelle.