

Si vous êtes un utilisateur de deux applications RAG différentes, comment décider laquelle est la meilleure ? Pour les développeurs, comment améliorer quantitativement et itérativement les performances de votre application RAG ?
De toute évidence, il est important que les utilisateurs et les développeurs évaluent avec précision les performances des applications RAG. Cependant, une simple comparaison de quelques exemples ne peut pas mesurer pleinement la qualité des réponses des candidatures RAG. Des indicateurs crédibles et reproductibles doivent être utilisés pour évaluer quantitativement les candidatures RAG.
Cet article explique comment évaluer quantitativement une application RAG du point de vue de la boîte noire et de la boîte blanche.
01. Méthode boîte noire VS méthode boîte blanche
Nous comparons l'évaluation des applications RAG au test d'un système logiciel. Il existe deux façons d'évaluer la qualité du système RAG, l'une est la méthode de la boîte noire et l'autre est la méthode de la boîte blanche.
Lors de l'évaluation d'une application RAG à la manière d'une boîte noire, nous ne pouvons pas voir l'intérieur de l'application RAG et pouvons uniquement évaluer l'effet de RAG à partir des informations saisies dans l'application RAG et des informations qu'elle renvoie. Pour un système RAG général, nous ne pouvons accéder qu'à ces trois informations : la requête de l'utilisateur, les contextes récupérés rappelés par le système RAG et la réponse de RAG. Nous utilisons ces trois informations pour évaluer l'effet des applications RAG. La méthode de la boîte noire est une méthode d'évaluation de bout en bout et est également plus adaptée à l'évaluation des applications RAG à source fermée.
Lors de l'évaluation d'une application RAG en boîte blanche, nous pouvons voir tous les processus internes de l'application RAG. Par conséquent, certains composants internes clés peuvent déterminer les performances de cette application RAG. En prenant le processus de candidature RAG commun comme exemple, certains composants clés incluent le modèle d'intégration, le modèle de reclassement et le LLM. Certains RAG ont des capacités de rappel multicanal et peuvent également disposer d'algorithmes de recherche de fréquence de termes. Le remplacement et la mise à niveau de ces composants clés peuvent également apporter de meilleurs résultats aux applications RAG. L'approche boîte blanche peut être utilisée pour évaluer les applications RAG open source ou pour améliorer les applications RAG auto-développées.
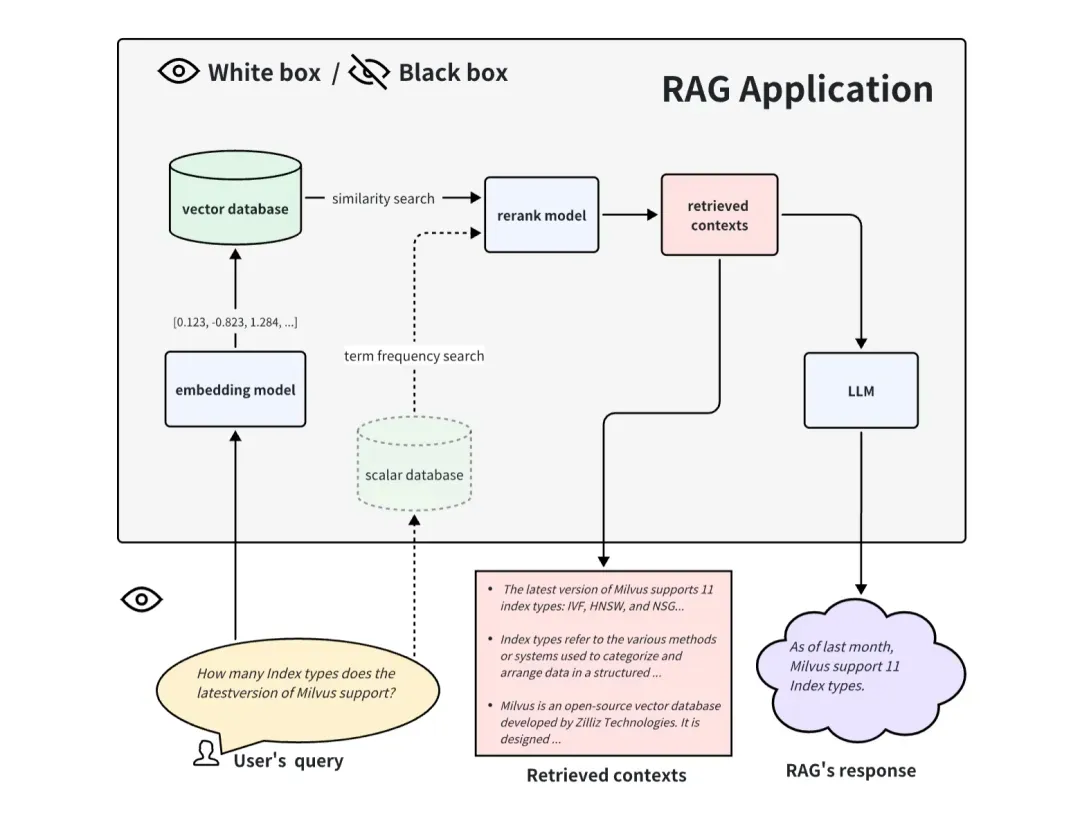
02.Méthode d'évaluation de bout en bout de la boîte noire
Indicateurs d’évaluation dans les conditions de la boîte noire
Dans le cas où l'application RAG est une boîte noire, on ne peut accéder qu'à ces trois informations : la requête de l'utilisateur, les contextes récupérés rappelés par le système RAG et la réponse de RAG. Ils constituent le triplet le plus important de tout le processus de RAG, et deux d'entre eux se retiennent mutuellement. Nous pouvons évaluer l'effet d'une application RAG en détectant la corrélation entre deux éléments du triplet.
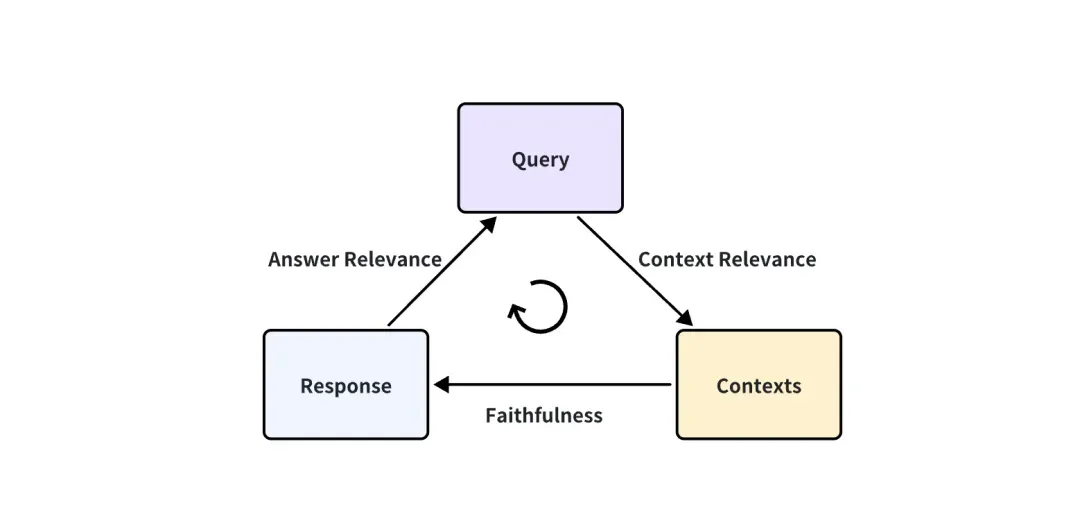
Les trois scores d’indicateurs correspondants suivants sont proposés :
-
Pertinence du contexte : mesure dans quelle mesure le contexte rappelé peut prendre en charge la requête. Si le score est faible, cela signifie que trop de contenus non pertinents pour la question de requête ont été rappelés, et ces connaissances erronées rappelées auront un certain impact sur la réponse finale du LLM.
-
Fidélité : Cette métrique mesure la cohérence factuelle des réponses générées dans un contexte donné. Il est calculé en fonction de la réponse et du contexte récupéré. Si ce score est faible, reflétant le fait que la réponse du LLM n'adhère pas aux connaissances rappelées, alors la réponse est plus susceptible d'être illusoire.
-
Pertinence de la réponse : se concentre sur l'évaluation de la pertinence de la réponse générée à une invite de requête donnée. Des notes inférieures sont attribuées aux réponses incomplètes ou contenant des informations redondantes.
Prenons l'exemple de la pertinence de la réponse :
Question: Where is France and what is it’s capital?
Low relevance answer: France is in western Europe.
High relevance answer: France is in western Europe and Paris is its capital.
Comment calculer quantitativement ces indicateurs ?
À la question « Où est la France et quelle est sa capitale ? », une réponse peu pertinente est « La France est en Europe occidentale ». C'est une conclusion tirée de l'analyse des connaissances humaines antérieures. Existe-t-il un moyen de la quantifier ? Score, cette réponse est de 0,2 point, et l'autre réponse est de 0,4 point ? Et objectivement, il faut s’assurer que l’effet de 0,4 point est bien meilleur que 0,2 point.
De plus, si chaque réponse exige que les humains obtiennent un score, alors une grande quantité de travail doit être organisée et certaines normes directrices doivent être formulées afin qu'ils puissent apprendre cette ligne directrice et s'y conformer pour marquer. Cette méthode prend du temps et est évidemment irréaliste. Existe-t-il un moyen de marquer automatiquement ?
Heureusement, les LLM avancés tels que GPT-4 peuvent désormais atteindre un niveau similaire à celui des annotateurs humains. Il peut répondre à la fois aux deux besoins mentionnés ci-dessus. L’un est qu’il peut obtenir des scores quantitatifs, objectifs et équitables, et l’autre est qu’il peut être automatisé.
Dans cet article LLM-as-a-Judge ( https://arxiv.org/abs/2306.05685), l'auteur a proposé la possibilité d'un LLM en tant que juge et a mené un grand nombre d'expériences sur cette base. Les résultats montrent que de puissants juges LLM (tels que GPT-4) peuvent bien faire correspondre les préférences humaines de contrôle et de crowdsourcing, atteignant une cohérence de plus de 80 %, soit le même niveau de cohérence entre les humains. Par conséquent, LLM en tant que juge est une méthode évolutive et interprétable pour se rapprocher des préférences humaines, ce qui serait autrement très coûteux à obtenir pour les humains.
Vous pensez peut-être que l'accord de 80 % entre les évaluateurs LLM et humains ne signifie pas que LLM et les humains sont très cohérents. Mais vous devez savoir que deux personnes différentes ayant reçu des conseils peuvent ne pas être en mesure de parvenir à un accord à 100 % sur la notation de questions aussi subjectives. Par conséquent, le fait que GPT-4 soit cohérent à 80 % avec les humains montre que GPT-4 peut complètement devenir un juge qualifié.
Concernant la façon dont GPT-4 est noté, nous prenons toujours la pertinence de la réponse comme exemple. Nous utilisons l'invite suivante pour poser des questions GPT-4 :
There is an existing knowledge base chatbot application. I asked it a question and got a reply. Do you think this reply is a good answer to the question? Please rate this reply. The score is an integer between 0 and 10. 0 means that the reply cannot answer the question at all, and 10 means that the reply can answer the question perfectly.
Question: Where is France and what is it’s capital?
Reply: France is in western Europe and Paris is its capital.
Réponse de GPT-4 :
10
On peut voir que tant qu'une invite appropriée est conçue à l'avance, comme l'invite dans l'exemple ci-dessus, et que la question et la réponse sont remplacées, toutes les paires d'assurance qualité peuvent être automatiquement évaluées. Par conséquent, la manière de concevoir l'invite est également très importante. L'invite dans l'exemple ci-dessus n'est qu'un exemple. L'invite réelle est souvent très longue afin de rendre la notation GPT plus juste et plus robuste. Cela nécessite l'utilisation de certaines techniques avancées d'ingénierie rapide, telles que les techniques de chaîne de réflexion multi-shot ou CoT (Chain-of-Thought). Lors de la conception de ces invites, certains biais du LLM doivent parfois être pris en compte, tels que le biais de position commun du LLM : lorsque l'invite est relativement longue, LLM a tendance à remarquer une partie du contenu au début de l'invite et à ignorer une partie du contenu dans le milieu.
Heureusement, nous n'avons pas trop à nous soucier de la conception rapide. Les outils d'évaluation de ces applications RAG ont déjà été conçus et intégrés. La communauté et le temps peuvent aider à tester dans quelle mesure ils conçoivent les invites. Ce dont nous devons nous préoccuper davantage, c'est que l'accès à des LLM comme GPT-4 en grande quantité nécessite de consommer trop de clés API. À l'avenir, j'espère qu'il y aura un LLM moins cher ou un LLM local qui pourra atteindre le niveau d'un bon juge.
Dois-je marquer la vérité terrain ?
Vous avez peut-être remarqué que la vérité terrain n'est pas utilisée dans l'exemple ci-dessus. Il s'agit d'une réponse standard écrite par des humains pour répondre aux questions correspondantes. Par exemple, un indicateur entre la vérité terrain et la réponse peut être défini, appelé Answer Correctness, qui est utilisé pour mesurer l'exactitude des réponses RAG. Le principe de notation est le même que la façon dont Answer Relevance utilise la notation LLM ci-dessus.
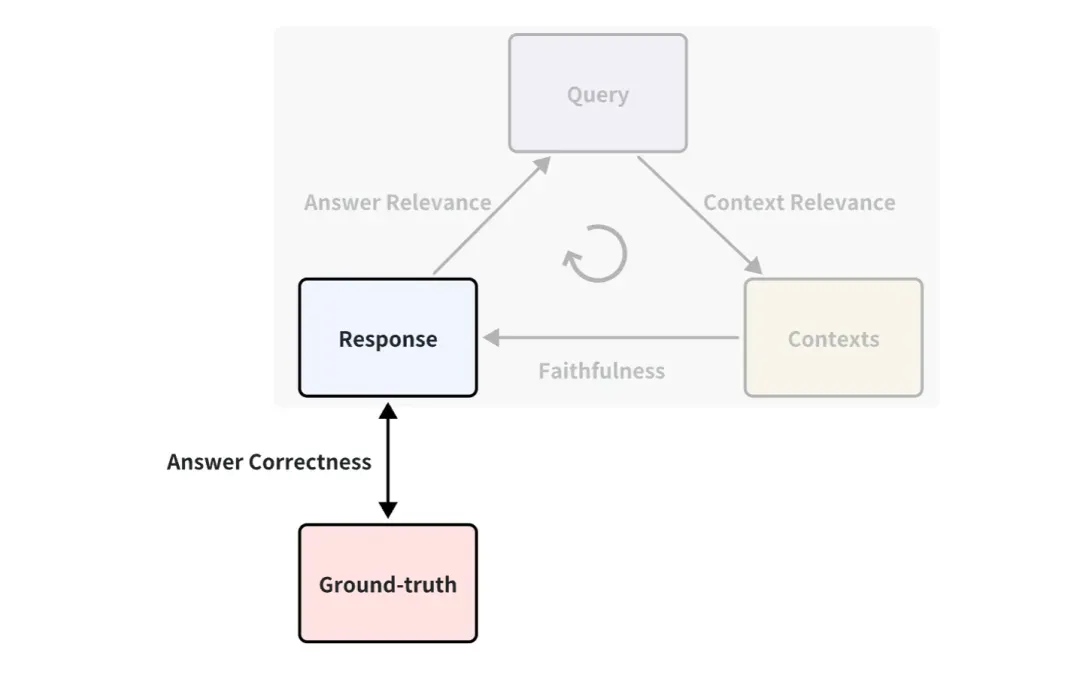
Par conséquent, s’il existe une vérité sur le terrain, les indicateurs d’évaluation seront plus riches, c’est-à-dire que l’effet de l’application du RAG pourra être mesuré sous davantage d’angles. Mais dans la plupart des cas, l’obtention d’un bon ensemble de données standard de vérité sur le terrain est coûteuse et peut nécessiter beaucoup de main d’œuvre et de temps pour l’annoter. Existe-t-il un moyen d'obtenir une annotation rapide ?
Puisque LLM peut tout générer, il est possible de laisser LLM générer des requêtes et des vérités terrain basées sur des documents de connaissances. Par exemple, il existe certaines méthodes intégrées dans la génération de données de test synthétiques de ragas et dans QuestionGeneration de lama-index, qui peuvent être utilisées directement et facilement.
Jetons un coup d'œil à l'effet généré sur la base des documents de connaissances dans les ragas :

Questions et réponses générées sur la base de documents de connaissances ( https://docs.ragas.io/en/latest/concepts/testset_generation.html)
Comme vous pouvez le constater, la figure ci-dessus génère de nombreuses questions de requête et réponses correspondantes, y compris les sources contextuelles correspondantes. Afin de garantir la diversité des questions générées, vous pouvez également choisir la proportion de différents types de questions générés, comme la proportion de questions simples et de questions de raisonnement.
De cette façon, nous pouvons facilement et directement utiliser ces questions générées et la vérité sur le terrain pour évaluer quantitativement une application RAG. Nous n'avons plus besoin d'aller en ligne pour trouver divers ensembles de données de référence. De cette manière, nous pouvons également évaluer des données privées ou internes. au sein de l’entreprise.
03. Méthode d'évaluation en boîte blanche
Pipeline RAG dans des conditions de boîte blanche
En regardant les applications RAG du point de vue de la boîte blanche, nous pouvons voir le pipeline de mise en œuvre interne de RAG. En prenant le processus de candidature RAG commun comme exemple, certains composants clés incluent le modèle d'intégration, le modèle de reclassement et le LLM. Certains RAG ont des capacités de rappel multicanal et peuvent également disposer d'algorithmes de recherche de fréquence de termes. De toute évidence, tester ces composants clés peut également refléter l'efficacité du pipeline RAG à une certaine étape. Le remplacement et la mise à niveau de ces composants clés peuvent également apporter de meilleures performances aux applications RAG.
Ci-dessous, nous expliquons comment évaluer ces 3 éléments clés typiques :
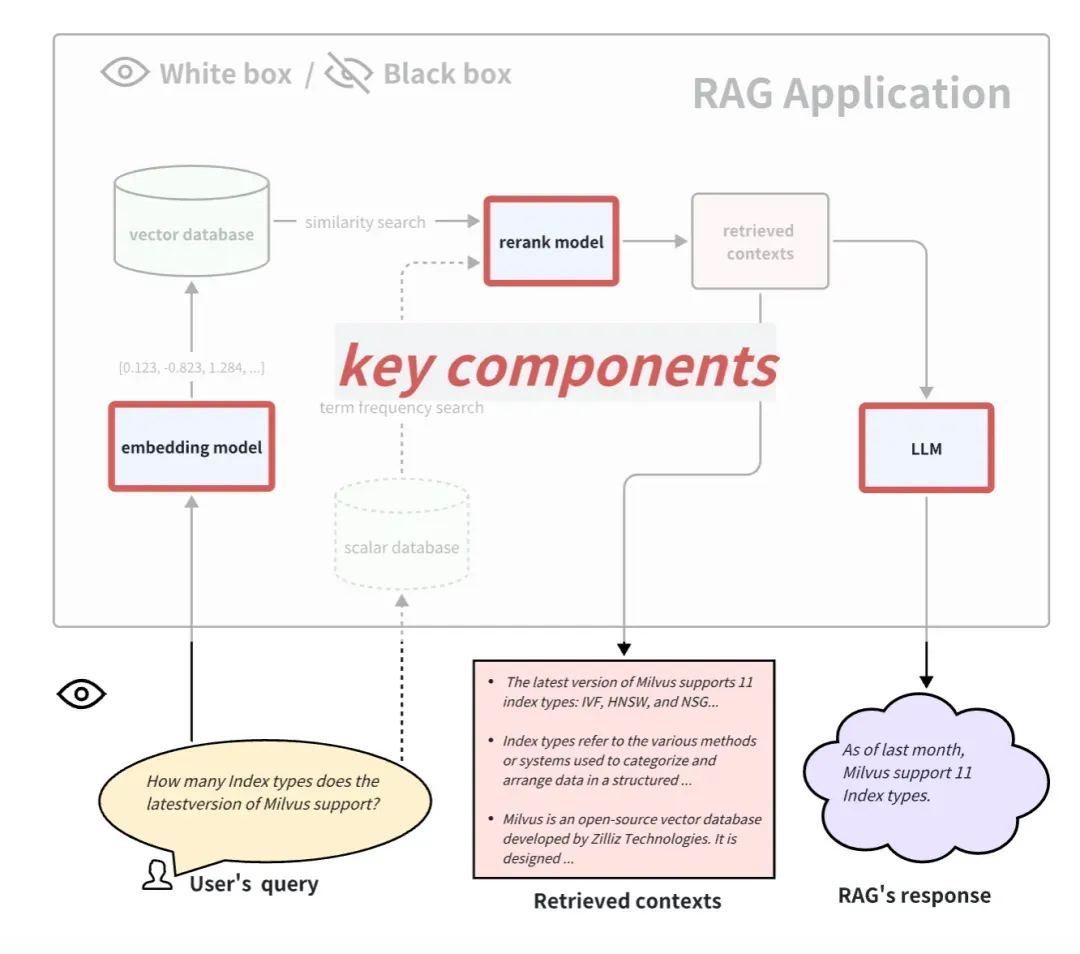
Comment évaluer le modèle d'intégration et reclasser le modèle
Le modèle d'intégration et le modèle de reclassement fonctionnent ensemble pour compléter la fonction de récupération des documents associés. Ci-dessus, nous avons introduit l'indicateur de pertinence contextuelle, qui peut être utilisé pour évaluer la pertinence des documents rappelés. Mais généralement pour les ensembles de données avec Ground-truth, les gens utilisent plus couramment certains indicateurs déterministes dans le domaine de la récupération et du rappel d'informations pour mesurer l'effet du rappel. Par rapport aux indicateurs de pertinence contextuelle basés sur LLM, ces indicateurs sont plus rapides, moins chers et plus déterministes à calculer (mais doivent fournir des contextes de vérité sur le terrain).
Indicateurs couramment utilisés pour la recherche d’informations
Dans le domaine de la récupération et du rappel d'informations, les indicateurs couramment utilisés comprennent des indicateurs qui prennent en compte le classement et des indicateurs qui ne prennent pas en compte le classement.
L'index qui prend en compte le classement est sensible au classement des documents de vérité de terrain rappelés parmi tous les documents rappelés, c'est-à-dire que la modification de l'ordre de corrélation entre tous les documents rappelés entraînera une modification du score de cet index quels que soient les indicateurs de classement. sont le contraire.
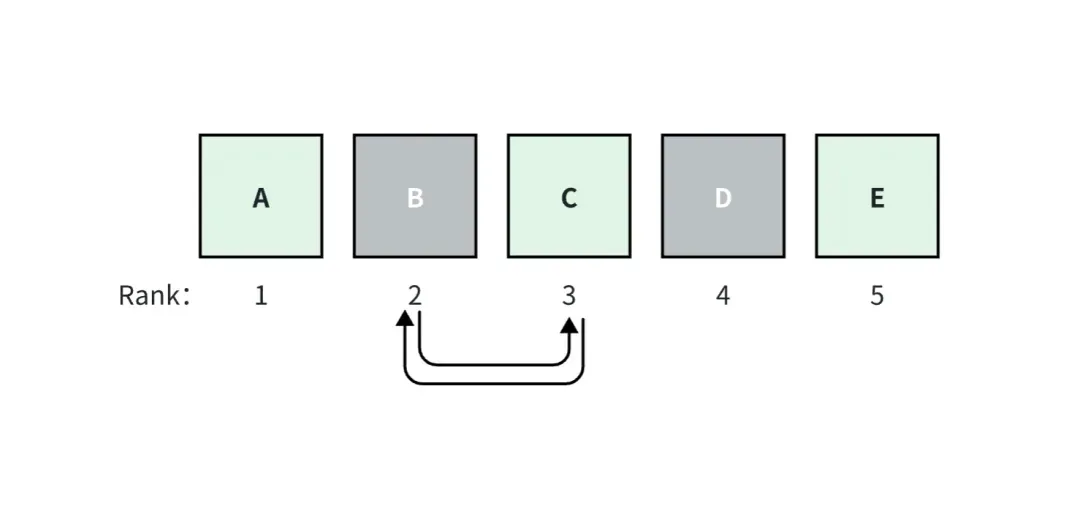
Par exemple, dans la figure ci-dessus, nous supposons que l'application RAG rappelle top_k=5 documents, parmi lesquels les documents A, C et E sont des vérités terrain. Le document A est classé 1, il a le score de pertinence le plus élevé et les scores diminuent vers la droite.
Si les documents B et C sont échangés, les scores des mesures prises en compte pour le classement changeront, mais les scores des mesures qui ne sont pas prises en compte pour le classement ne changeront pas.
Voici quelques indicateurs spécifiques courants :
Des indicateurs qui ne prennent pas en compte les classements
-
Rappel de contexte : mesure dans laquelle le système a complètement récupéré tous les documents nécessaires.
-
Précision du contexte : dans quelle mesure le système récupère le signal (par rapport au bruit).
Métriques prises en compte pour le classement
-
La précision moyenne (AP) mesure tous les blocs pertinents récupérés et calcule un score pondéré. La moyenne de AP sur un ensemble de données est souvent appelée MAP.
-
Le classement réciproque (RR) mesure l'endroit où le premier bloc pertinent apparaît dans votre recherche. La moyenne du RR sur un ensemble de données est souvent appelée MRR.
-
Le gain cumulatif actualisé normalisé (NDCG) prend en compte le cas où votre classification de corrélation est non binaire.
Le référentiel d'évaluation le plus courant : MTEB
Le Massive Text Embedding Benchmark (MTEB) est un benchmark complet conçu pour évaluer les performances des modèles d'intégration de texte sur une variété de tâches et d'ensembles de données. MTEB couvre 8 tâches d'intégration, notamment l'exploration bilingue (Bitext Mining), la classification, le clustering, la classification par paires, la réorganisation, la récupération, la similarité sémantique de texte (STS) et la synthèse. Il couvre un total de 58 ensembles de données dans 112 langues, ce qui en fait l'un des benchmarks d'intégration de texte les plus complets à ce jour.
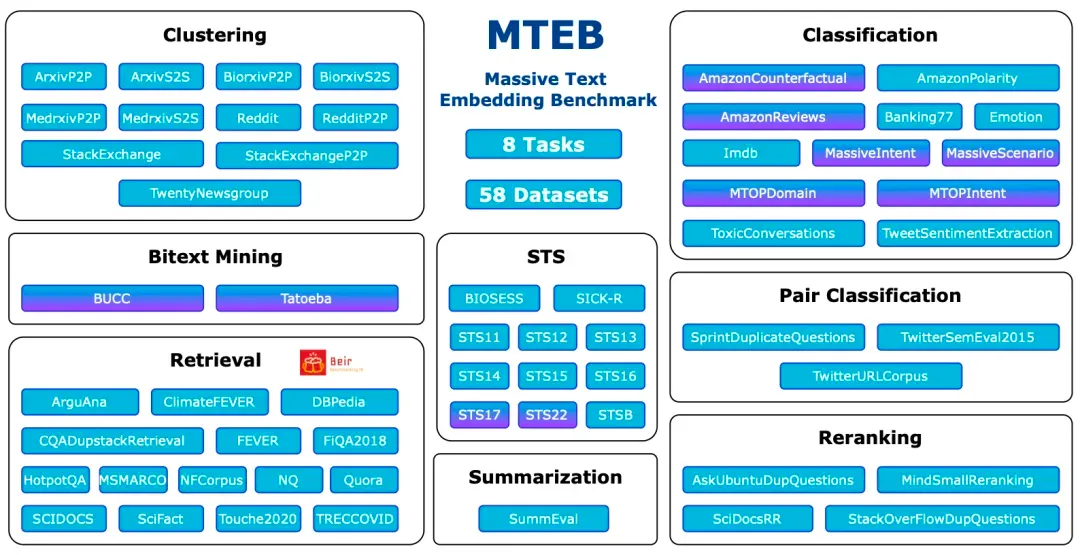
MTEB : référence pour l'intégration massive de texte
https://arxiv.org/abs/2210.07316
On peut voir que MTEB contient des tâches de récupération et des tâches de reclassement Lors de l'évaluation des modèles d'intégration et de reclassement dans les applications RAG, concentrez-vous sur les modèles avec des scores plus élevés dans ces deux tâches. Dans les recommandations du document MTEB ( https://arxiv.org/abs/2210.07316), pour le modèle Embedding, NDCG est l'indicateur le plus important pour le modèle Rerank, MAP est l'indicateur le plus important ;
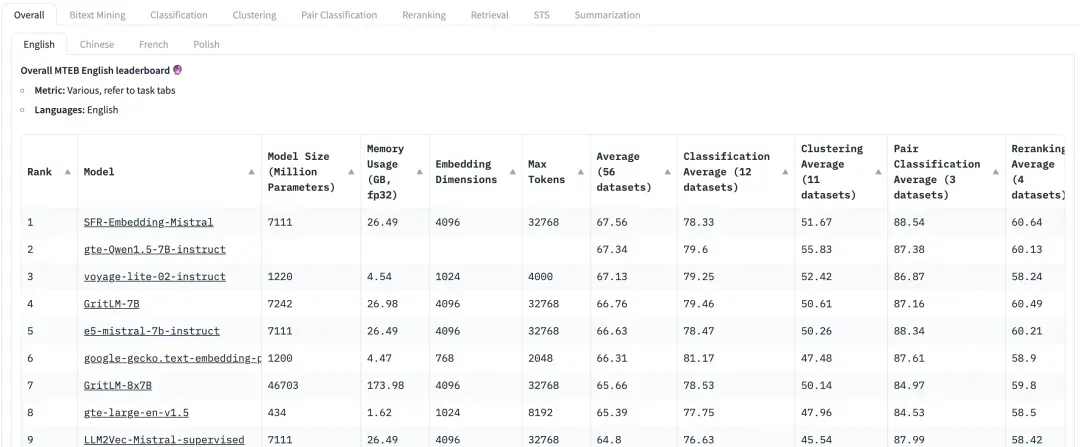
Sur HuggingFace, MTEB est le classement auquel tout le monde accorde une grande attention. Cependant, étant donné que l'ensemble de données est public, certains modèles peuvent avoir surajusté cet ensemble de données dans une certaine mesure, ce qui dégradera les performances de l'ensemble de données réel. Par conséquent, lors de l’évaluation de l’effet de rappel, il est également nécessaire d’accorder plus d’attention aux performances d’évaluation sur des ensembles de données personnalisés orientés métier.
Comment évaluer le LLM ?
En général, le processus de génération peut être directement évalué à l'aide de l'indicateur basé sur LLM de l'étape du contexte à la réponse introduit ci-dessus, à savoir la fidélité.
Mais pour certains tests de requêtes relativement simples, comme ceux où les réponses standards ne comportent que quelques expressions simples, certains indicateurs classiques peuvent également être utilisés. Par exemple, ROUGE-L Précision, Précision Token Overlap. Cette évaluation déterministe nécessite également un contexte de vérité terrain annoté.
ROUGE-L Precision mesure la plus longue sous-séquence commune entre la réponse générée et le contexte récupéré.
Précision du chevauchement des jetons Calcule la précision du chevauchement des jetons entre la réponse générée et le contexte récupéré.
Par exemple, les problèmes relativement simples suivants peuvent toujours être évalués à l’aide d’indicateurs tels que ROUGE-L Precision et Token Overlap Precision.
Question: How many Index types does the latest version of Milvus support?
Reply: As of last month, Milvus support 11 Index types.
Ground-truth Context: In this version, Milvus support 11 Index types.
Cependant, il convient de noter que ces indicateurs ne conviennent pas aux scénarios RAG comportant des questions complexes. Dans ce cas, des indicateurs basés sur le LLM doivent être utilisés pour l'évaluation. Par exemple, des questions ouvertes comme celles-ci :
Question: Please design a text search application based on the features of the latest version of Milvus and list the application usage scenarios.
04. Introduction aux outils d'évaluation couramment utilisés
À l'heure actuelle, des outils professionnels ont émergé dans la communauté open source et les utilisateurs peuvent les utiliser pour faciliter et réaliser rapidement des évaluations quantitatives. Ci-dessous, nous présentons les outils d'évaluation RAG actuellement courants et faciles à utiliser ainsi que certaines de leurs caractéristiques.
Ragas ( https://docs.ragas.io/en/latest/getstarted/index.html ) : Ragas est un outil axé sur l'évaluation des applications RAG. L'évaluation peut être réalisée via une interface simple. Les indicateurs Ragas sont riches en variété et n'ont aucune exigence sur le cadre d'application RAG. Vous pouvez également surveiller le processus de chaque évaluation via Langsmith ( https://www.langchain.com/langsmith) pour vous aider à analyser les raisons de chaque évaluation et à observer la consommation des clés API.
Continuous Eval ( https://docs.relari.ai/v0.3) : Continu-eval est un progiciel open source permettant d'évaluer les pipelines d'applications LLM, en mettant l'accent sur les pipelines de génération augmentée de récupération (RAG). Il offre une option d’évaluation moins chère et plus rapide. De plus, il permet la création de pipelines d’évaluation d’ensemble fiables avec des garanties mathématiques.
TruLens-Eval : Trulens-Eval est un outil spécifiquement utilisé pour évaluer les indicateurs RAG. Il s'intègre relativement bien avec LangChain et Llama-Index et peut être facilement utilisé pour évaluer les applications RAG construites par ces deux frameworks. De plus, Trulens-Eval peut également lancer une page dans le navigateur de suivi visuel, permettant d'analyser les raisons de chaque évaluation et d'observer la consommation des clés API.
Llama-Index : Llama-Index est très approprié pour créer des applications RAG, et son écologie actuelle est relativement riche et il subit actuellement un développement itératif rapide. Il inclut également la fonction d'évaluation de RAG et de génération d'ensembles de données synthétiques. Les utilisateurs peuvent facilement évaluer les applications RAG créées par Llama-Index lui-même.
De plus, il existe certains outils d’évaluation dont les fonctions sont similaires à celles mentionnées ci-dessus. Par exemple, Phoenix ( https://docs.arize.com/phoenix ), DeepEval (https://github.com/confident-ai/deepeval), LangSmith, OpenAI Evals ( https://github.com/openai/ évaluations) . Le développement itératif de ces outils d’évaluation est également très rapide. Pour des fonctions et modalités d’utilisation spécifiques, vous pouvez consulter les documents officiels correspondants.
05. Résumé
Pour les utilisateurs et développeurs d’applications RAG, il est crucial en pratique d’évaluer les performances des applications RAG. Cet article présentera la méthode d'évaluation quantitative des applications RAG du point de vue de la boîte noire et de la boîte blanche, et présentera quelques outils d'évaluation pratiques, visant à aider les lecteurs à comprendre rapidement la technologie d'évaluation et à démarrer rapidement. Pour plus d'informations sur RAG, veuillez vous référer aux autres articles de cette série « RAG Cultivation Manual | Un article expliquant la technologie derrière RAG » « RAG Cultivation Manual | RAG sonne-t-il le glas ? Le contexte long du grand modèle signifie-t-il que la récupération de vecteurs n'est plus importante ?
Linus a pris les choses en main pour empêcher les développeurs du noyau de remplacer les tabulations par des espaces. Son père est l'un des rares dirigeants capables d'écrire du code, son deuxième fils est directeur du département de technologie open source et son plus jeune fils est un noyau. contributeur à l'open source. Huawei : Il a fallu 1 an pour convertir 5 000 applications mobiles couramment utilisées Migration complète vers Hongmeng Java est le langage le plus sujet aux vulnérabilités tierces Wang Chenglu, le père de Hongmeng : l'open source Hongmeng est la seule innovation architecturale. dans le domaine des logiciels de base en Chine, Ma Huateng et Zhou Hongyi se serrent la main pour « éliminer les rancunes ». Ancien développeur de Microsoft : les performances de Windows 11 sont « ridiculement mauvaises » " Bien que ce que Laoxiangji est open source, ce ne soit pas le code, les raisons qui le sous-tendent. sont très réconfortants. Meta Llama 3 est officiellement publié. Google annonce une restructuration à grande échelle.