
Cette citation de Charity Majors résume probablement le mieux l’état actuel de l’observabilité dans l’industrie technologique : un chaos complet et massif. Tout le monde est confus. Qu’est-ce que la trace ? Qu’est-ce que la durée ? Une ligne de journal est-elle une étendue ? Si j’ai des journaux, dois-je quand même effectuer un suivi ? Si j’ai de bonnes mesures, pourquoi ai-je besoin d’un suivi ? La liste se rallonge de plus en plus. Charity, aux côtés d’autres grands esprits des systèmes observables Honeycomb , a travaillé dur pour résoudre ces problèmes. Cependant, d'après ma propre expérience, il est encore difficile d'expliquer ce que Charity veut dire lorsqu'elle dit que « les journaux sont des déchets », sans parler du fait que la journalisation et le traçage sont essentiellement la même chose. Pourquoi tout le monde est-il si confus ?
Avec un léger risque, je vais blâmer Open Telemetry. Oui, c'est le moteur de la pile d'observabilité moderne, mais je lui reproche le désordre. Ce n’est pas parce que c’est une mauvaise solution – c’est génial ! Cependant, son introduction et son explication des concepts et des fonctions de la télémétrie ouverte rendent l’observabilité délicate et compliquée.
Premièrement, Open Telemetry fait clairement la distinction entre les traces, les métriques et les journaux dès le début :
OpenTelemetry est un ensemble d'API, de SDK et d'outils. Utilisez-le pour instrumenter, générer, collecter et exporter des données de télémétrie (métriques, journaux et traces) afin de vous aider à analyser les performances et le comportement de votre logiciel.
Expliquez ensuite chacune de ces 3 questions plus en profondeur.
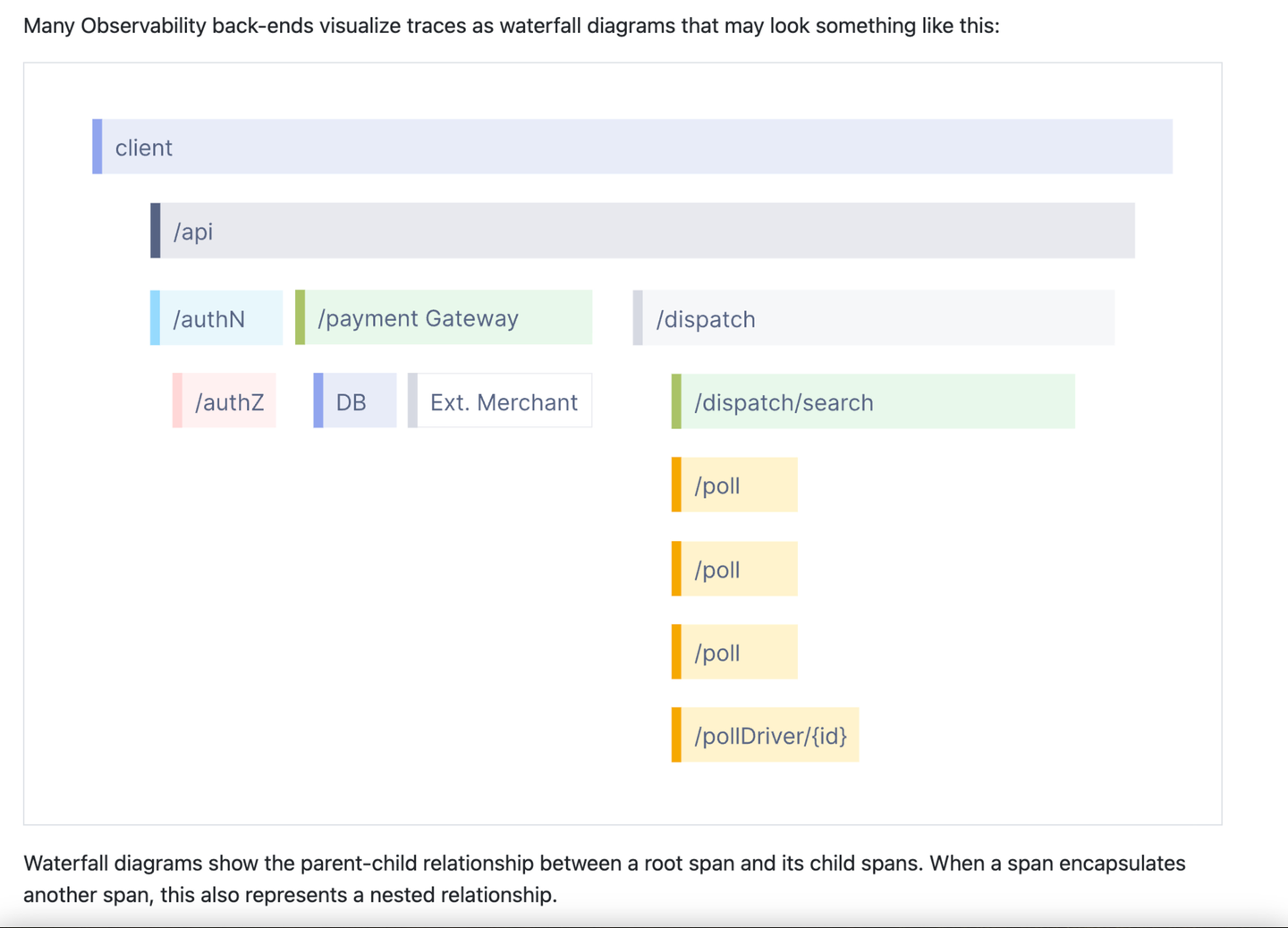
Il s'agit d'une capture d'écran partielle de l'introduction de trace sur le site Web OpenTelemetry. D'après mon expérience de discussion avec l'équipe d'OpenTelemetry, cette présentation est vraiment devenue l'une des principales images liées à l'observabilité. Pour certains, c'est l'observabilité. Cela distingue également la trace de toute autre chose. Ce n'est évidemment pas un journal, n'est-ce pas ? Cela ne ressemble pas non plus à un indicateur, n’est-ce pas ? C'est quelque chose de spécial, peut-être un peu génial, et qui nécessite un dévouement à l'apprentissage. D'après mon expérience, une fois que les gens comprennent les traces, ils n'y pensent que dans le contexte de cette image et des termes associés comme span, root span, nested span, etc. Le site OpenTelemetry dispose d'une page de glossaire avec plus de 60 termes ! Tout cela est extrêmement compliqué !
Mais plus important encore, cette concentration sur les « journaux, métriques et traces de liens » représente-t-elle le véritable pouvoir de l'observabilité ? Bien sûr, cela couvre certains scénarios, mais lorsqu'il s'agit de systèmes distribués à grande échelle, il est plus important de pouvoir approfondir les données - les "couper en dés", construire et analyser diverses vues, établir des corrélations. Analyse sexuelle, à la recherche d'anomalies... et des systèmes offrant toutes ces capacités existent.
Plongée : le paradis de l'observabilité
Lorsque je travaillais chez Meta, je ne réalisais pas que j'avais la chance de travailler avec le meilleur système d'observabilité jamais créé. Ce système s'appelle Scuba, et c'est la première chose qui manque le plus aux gens après avoir quitté Meta Corporation.
L'idée de base de Scuba est suffisamment simple pour qu'il ne soit pas nécessaire de lire des pages de terminologie pour la comprendre. Il utilise des événements étendus. Un événement généralisé n'est qu'une collection de champs avec des noms et des valeurs, tout comme un document JSON. Si vous avez besoin de consigner certaines informations - qu'il s'agisse de l'état actuel du système ou provoqué par un appel API, une tâche en arrière-plan ou un autre événement - il vous suffit d'écrire quelques événements généralisés dans Scuba. Par exemple, si un système diffuse de la publicité, il souhaitera naturellement enregistrer les impressions publicitaires, c'est-à-dire le fait qu'une publicité a été vue par un utilisateur. L'événement généralisé correspondant pourrait ressembler à ceci :
{
"Timestamp": "1707951423",
"AdId": "542508c92f6f47c2916691d6e8551279”,
"UserCountry": "US",
"Placement": "mobile_feed",
"CampaingType": "direct_ads",
"UserOS": "Android",
"OSVersion": "14",
"AppVersion": "798de3c28b074df9a24a479ce98302b6",
"...": ""
}De tels événements sont appelés événements généralisés car toutes les informations imaginables sont encouragées à y être stockées. Tout ce qui pourrait être pertinent dans le contexte de ces données particulières - il suffit de le publier et cela pourrait être utile plus tard. Cette approche jette les bases de la gestion des inconnues inconnues - des choses auxquelles on ne peut pas penser maintenant et qui pourraient être révélées lors d'une enquête sur un accident.
Faire face à des situations inconnues et inconnues peut être mieux illustré par un exemple. Scuba possède une interface intuitive et conviviale qui facilite son exploration et son utilisation. Il comporte une section pour sélectionner les métriques à afficher, ainsi que des sections pour le filtrage et le regroupement. Scuba tracera un joli graphique de séries chronologiques. Un premier aperçu de l'ensemble de données sur les impressions publicitaires tracera simplement un graphique contenant le nombre d'impressions :
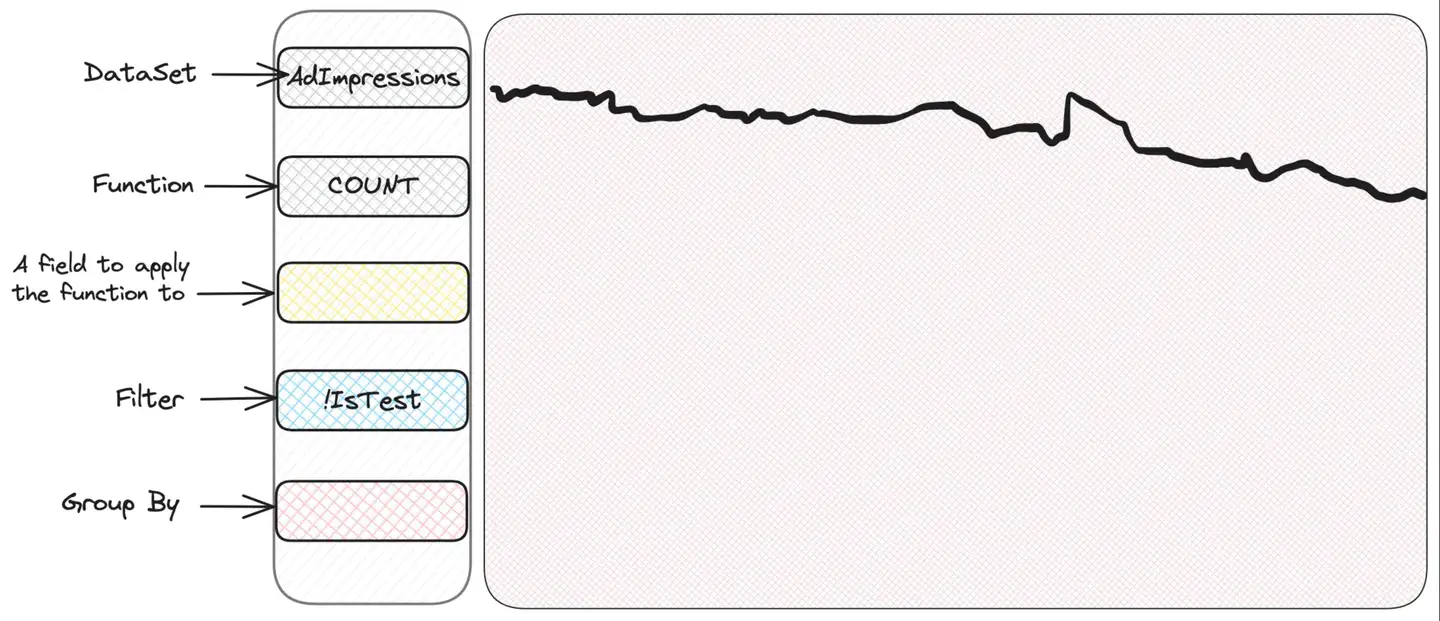
Si nous exprimions en SQL ce qui est exactement sélectionné ici, cela ressemblerait à :
SELECT COUNT(*) FROM AdImpressions
WHERE IsTest = FalseCe n’est pas tout à fait le cas. Scuba présente également le concept d'échantillonnage natif. Lorsqu'un événement est écrit dans Scuba, un champ appelé , qui représente le taux d'échantillonnage de cet événement particulier, doit également être écrit. Scuba utilise ces informations pour « zoomer » correctement sur les résultats affichés sur la carte, il n'est donc pas nécessaire de faire ce grossissement dans votre tête. C'est un concept génial car il permet un échantillonnage dynamique - par exemple, un certain type de présentation peut être échantillonné plus fréquemment qu'un autre type de présentation, tout en préservant les valeurs « réelles » dans l'interface utilisateur. La véritable requête ci-dessous est donc : samplingRate
SELECT SUM(samplingRate) FROM AdImpressions
WHERE IsTest = False Notez que l'intégralité du "zoom avant" est effectué de manière transparente par l'interface utilisateur et que l'utilisateur n'a pas besoin d'y penser lors de la requête. Supposons qu'une alerte se produise et que notre précieux graphique d'impressions publicitaires semble étrange :
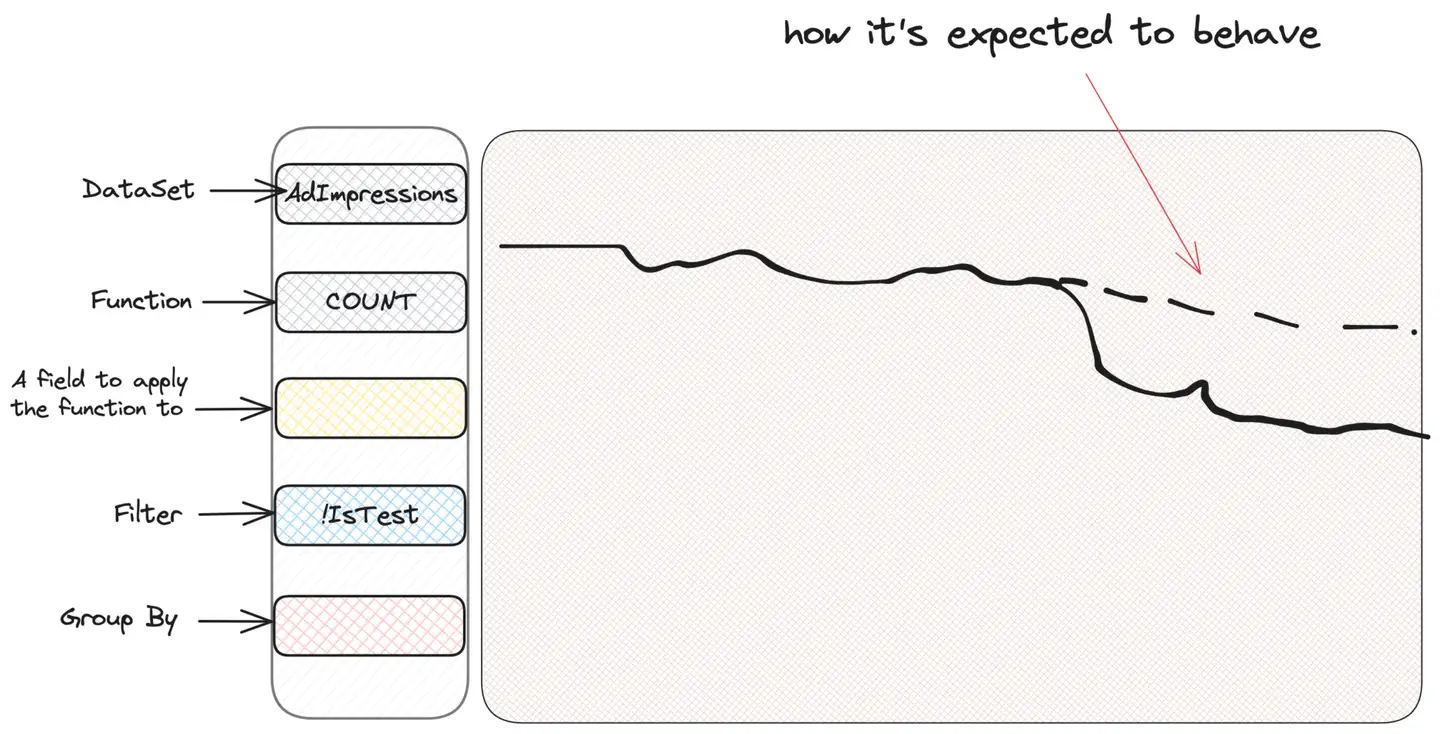
Le premier réflexe de tous ceux qui utilisent Scuba pour enquêter est de « couper en dés », c'est-à-dire de filtrer ou de regrouper en fonction de critères, pour voir s'ils peuvent obtenir des informations. Nous ne savons pas ce que nous cherchons, mais nous pensons que nous le trouverons. Par conséquent, nous regroupons par type d'impression, pays d'utilisateur ou emplacement de l'annonce jusqu'à ce que nous trouvions quelque chose de suspect. Supposons un regroupement par type de campagne (CampaignType) :
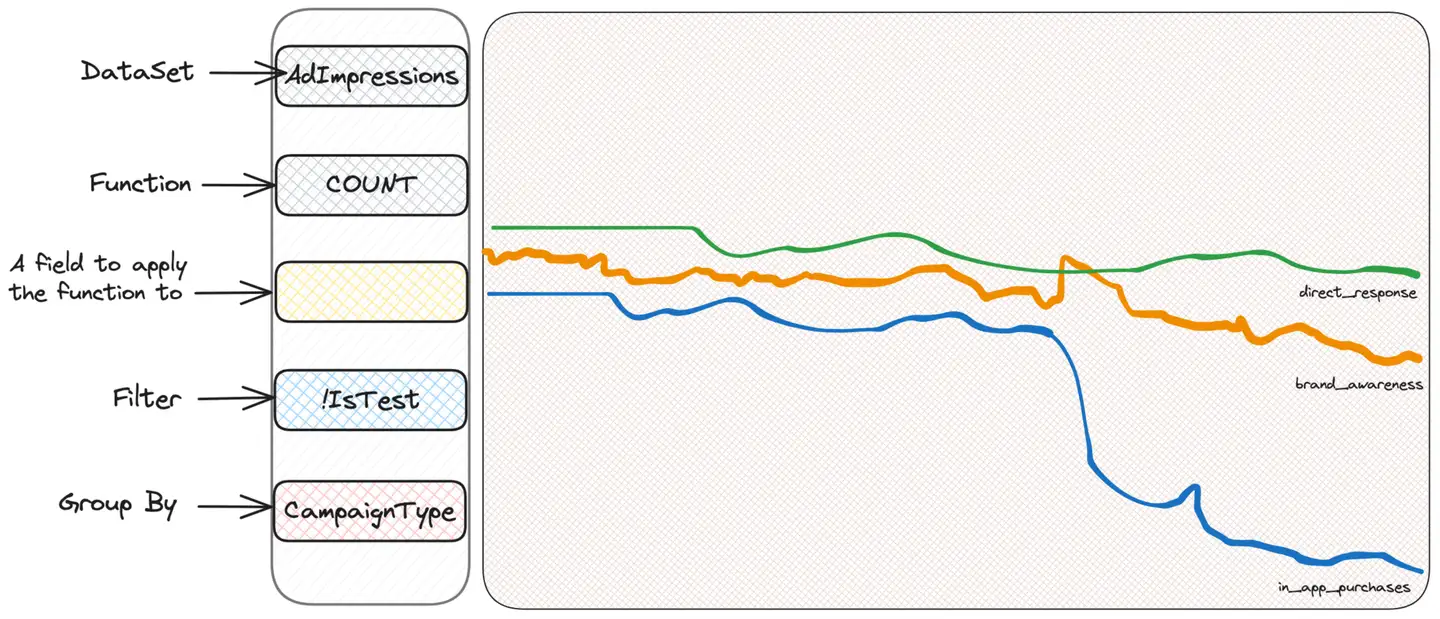
Nous avons découvert qu'un type de campagne appelé in_app_purchases (veuillez noter que c'est moi qui l'ai inventé) semble être différent des autres types. Nous ne savons pas vraiment ce que cela signifie – et nous n’avons pas besoin de le savoir ! - Nous devons juste continuer à creuser. D'accord, nous pouvons maintenant filtrer uniquement ces campagnes et continuer à les regrouper en fonction d'autres critères auxquels nous pouvons penser. Par exemple, le système d'exploitation de l'utilisateur est logique.
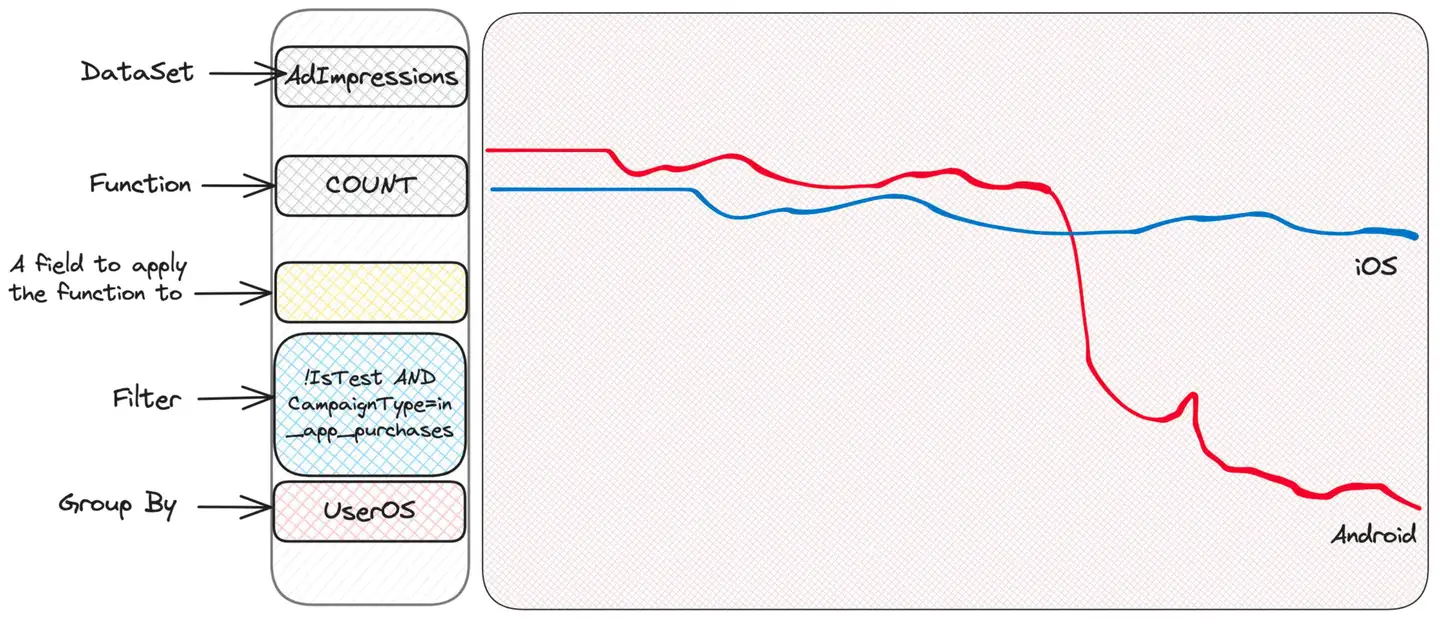
Eh bien, il semble y avoir un problème avec Android. iOS fonctionne correctement, ce qui suggère que le problème peut provenir du côté client - peut-être une version boguée de l'application ?
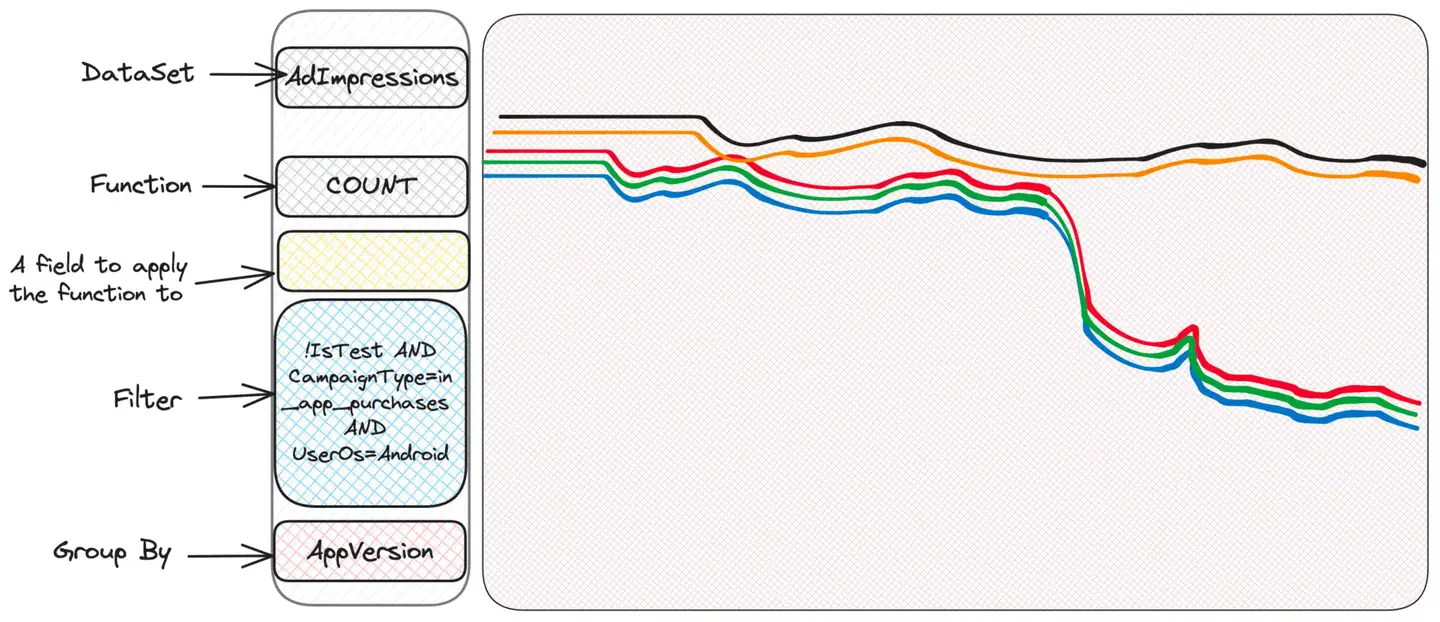
étrangeté. Certaines personnes ont des problèmes, d’autres non. Peut-être vérifier la version du système d'exploitation ?
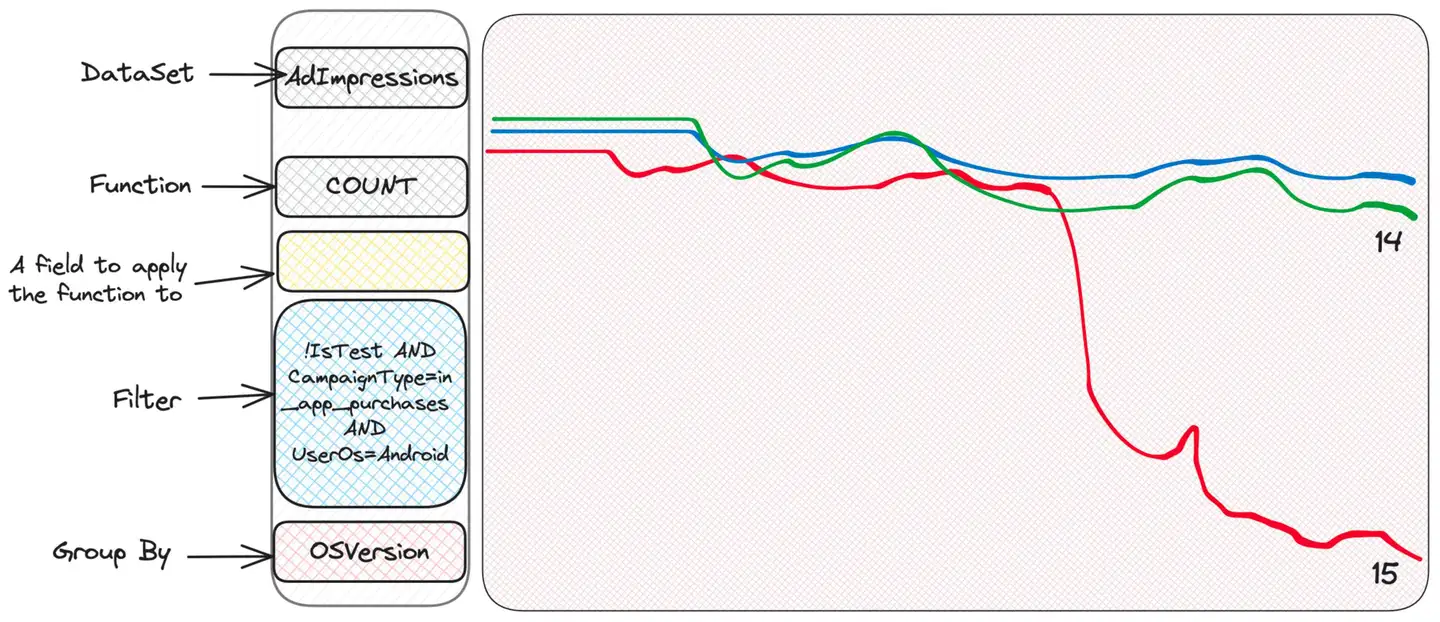
Ha! Il s'agit de la dernière version du système d'exploitation et il semble que certaines versions d'applications ne fonctionnent pas bien pour ce type de campagne sur cette version du système d'exploitation. Grâce à ces informations, l’équipe dédiée peut désormais approfondir ses recherches.
ce qui s'est passé? Sans aucune connaissance du système, nous avons circonscrit le problème et identifié l'équipe responsable d'une enquête plus approfondie. Aurions-nous pu savoir à l'avance que cette étrange combinaison de système d'exploitation, de version du système d'exploitation, de type de campagne et de version de l'application pourrait causer des problèmes et avions-nous les métriques prêtes ? Bien sûr, c'est impossible. Ceci est un exemple de gestion d’inconnus inconnus. Nous stockons simplement toutes les informations contextuelles pertinentes dans des événements généralisés et les utilisons en cas de besoin. Scuba rend l'exploration facile car elle est rapide et possède une interface utilisateur très belle et facile à utiliser. Notez également que nous n’avons jamais mentionné la cardinalité. Parce que cela n'a pas d'importance, n'importe quel champ peut avoir n'importe quelle cardinalité. Scuba fonctionne avec des événements bruts et n'effectue aucune pré-agrégation, la cardinalité n'est donc pas un problème.
Parfois, l'aspect interface/visualisation ne reçoit pas suffisamment d'attention et le système de surveillance fournit un langage de requête - peut-être propriétaire (une expérience particulièrement mauvaise) ou SQL (légèrement meilleur, mais toujours pas bon). Une telle interface rendrait presque impossible la réalisation d’une enquête similaire. Un aspect important de Scuba est que tous les champs (fonctions, filtres, regroupements, etc.) sont explorables. Cela dit, il existe un moyen simple de voir les types de valeurs que nous pouvons sélectionner. Lorsque la personne en charge d'un certain champ de données déploie des efforts supplémentaires pour améliorer les données dont elle est responsable, elle va au-delà de la simple collecte des données. Elle fournira même une description détaillée du champ donné, y compris les liens associés. C'est très important. J'ai effectué avec succès des dépannages à plusieurs reprises sans comprendre pleinement le système dans son ensemble ni les données disponibles dans cet ensemble de données. Et au cours de ces processus de dépannage, j'ai beaucoup appris sur le système simplement en interagissant avec Scuba ! Ceci est incroyable. C'est le paradis de l'observabilité.
La douleur après avoir quitté Meta
Imaginez maintenant ma confusion et mon incrédulité lorsque j'ai quitté Meta et que j'ai appris l'état du système d'observabilité externe.

enregistrer? piste? indice? Qu'est-ce que c'est exactement ? Quelqu'un est-il au courant des événements généralisés ? Puis-je ne pas apprendre le glossaire de 60 termes et simplement... explorer des choses ?
J'ai passé pas mal de temps à mapper le modèle mental basé sur Scuba au modèle mental Open Telemetry. J'ai réalisé que le Span d'Open Telemetry est en fait un événement généralisé. En fait, je ne suis toujours pas sûr d'avoir bien compris :

Si l'on prend l'exemple d'un affichage publicitaire, cet affichage n'est pas réellement une opération, ce sont juste des faits que l'on souhaite enregistrer... Pour être honnête, la notion d'événement existe bel et bien en Open Telemetry :

Mais si nous suivons le lien et creusons plus profondément, nous constatons à nouveau que l'événement est en réalité l'une des traces, des métriques ou des journaux.

Mais en tout cas, Span est le concept le plus proche d’un événement généralisé. Le problème est qu'il est difficile de défendre le modèle mental proposé par Open Telemetry quand on y est habitué. C'est vraiment frustrant car les traces, les métriques et les journaux ne sont en réalité que des cas particuliers d'événements généralisés :
- Traces et spans (Spans) : ce ne sont que des événements généralisés avec les champs SpanId, TraceId et ParentSpanId. Nous pouvons donc filtrer toutes les étendues avec un TraceId donné, les trier topologiquement en fonction de la relation SpanId → ParentSpanId et dessiner la vue de trace distribuée préférée de chacun.
- Journaux : Pour être honnête, je suis vraiment confus par ce qu'Open Telemetry appelle les journaux. Il semble qu'il contienne beaucoup de choses, dont la journalisation structurée, qui est essentiellement constituée d'événements à grande échelle. Très bien! Le problème, cependant, est que « journal » est un concept assez bien défini et que les gens pensent généralement à ce que ces appels produisent. Quoi qu’il en soit, quoi que cela signifie, les journaux peuvent certainement être facilement mappés à des événements de grande envergure. Dans le cas le plus simple, nous prenons simplement le message du journal, le plaçons dans le champ "log_message", ajoutons un tas de métadonnées et sommes satisfaits. Dans un cas plus complexe, nous pourrions essayer d'extraire automatiquement un modèle du message du journal en supprimant le jeton qui ressemble à un identifiant, et obtenir le hachage de ce modèle. Cela nous permet d'obtenir rapidement les erreurs les plus fréquentes, par exemple en regroupant par ce hachage. Meta a un système comme celui-ci, et c'est plutôt cool.
logger.info(…) - Métriques : les métriques peuvent également être facilement cartographiées. Il nous suffit d'émettre un large événement contenant l'état du système (tel que des indicateurs système du processeur, divers compteurs, etc.) dans un certain intervalle. À propos, Prometheus fait exactement cela grâce à la méthode de grattage - en prenant un instantané occasionnel du système. Cependant, contrairement à Prometheus, en utilisant l'approche événementielle large, nous n'avons pas à nous soucier des problèmes de cardinalité.
Mais les Wide Events peuvent apporter bien plus que ces « trois piliers » (Traces, Logs, Metrics). La session de débogage susmentionnée est déjà (du moins pas naturellement) un cas couvert par les traces, les journaux et les métriques. Il peut y avoir d'autres cas d'utilisation : par exemple, les données de profilage continu peuvent être facilement représentées sous la forme d'un événement étendu et interrogées pour créer un Flame Graph. Il n'est pas nécessaire d'avoir un système séparé pour cela : un seul système gérant des événements à grande échelle peut tout faire. Imaginez les possibilités de corrélation croisée et d’analyse des causes profondes lorsque tout est stocké ensemble, au même endroit. Surtout à l’ère de l’essor des outils d’intelligence artificielle, excellents pour découvrir les relations entre les données.
Donc alors?
Je ne sais pas... Je voulais juste exprimer ma déception et ma frustration que l'observabilité soit si confuse et déroutante et concentrée sur ce que sont les "trois piliers"...
J'espère juste que les fournisseurs d'observabilité s'opposeront au chaos et fourniront un moyen simple et naturel d'interagir avec le système. Honeycomb semble le faire, et quelques autres systèmes comme Axiom le font également. c'est bien! Espérons que d’autres fournisseurs suivront.
ci-joint
Cet article est une traduction, texte original : https:// isburmistrov.substack.com /p/all-you-need-is-wide-events-not-metrics
Permettez-moi d'insérer une petite publicité à la fin de l'article. Je crée une entreprise depuis deux ans, et notre entreprise fait également de l'observabilité, ce qui ressemble un peu à l'idée decet article. Si vous avez des besoins dans ce domaine, n'hésitez pas à nous contacter pour des échanges produits et techniques.
À propos de la nébuleuse de Kuaimao
Kuaimao Nebula est une société de technologie d'exploitation et de maintenance intelligente native du cloud. Elle est composée de l'équipe de développement principale du célèbre projet open source « Nightingale ». L'équipe fondatrice est issue de sociétés Internet telles que Alibaba, Baidu et Didi. Nightingale est un outil de surveillance cloud natif open source. Il s'agit du premier projet open source offert et hébergé par la Computer Society of China. Il compte plus de 8 000 étoiles sur GitHub, a publié plus de 100 versions itératives et compte des centaines de communautés. contributeurs. Il s’agit de la principale solution d’observabilité open source en Chine.
La « plate-forme Flashcat » construite par Kuaimao Nebula avec le logiciel open source Nightingale comme noyau est la mise en œuvre de produits des pratiques d'observabilité des principales sociétés Internet nationales. Elle s'engage à faire en sorte que la technologie d'observabilité serve mieux les entreprises et garantisse la stabilité des services. La plateforme Flashcat présente les fonctionnalités suivantes :
- Collection unifiée : en adoptant le concept de plug-in, des centaines de plug-ins de collecte intégrés sont intégrés. Les serveurs, les équipements réseau, les middlewares, les bases de données, les applications et les entreprises peuvent tous être surveillés et utilisés immédiatement.
- Alarme unifiée : prend en charge l'amarrage de dizaines de sources de données, collecte les événements d'alarme de divers systèmes de surveillance et effectue une convergence d'alarmes unifiée, une réduction du bruit, une planification, une réclamation, une mise à niveau et une collaboration, améliorant considérablement l'efficacité du traitement des alarmes.
- Observation unifiée : intégrez diverses données d'observabilité telles que les métriques, les journaux, les traces, les événements et le profilage, ainsi que les meilleures pratiques prédéfinies du secteur. Il fournit non seulement un cockpit d'un point de vue commercial global et d'un point de vue technique, mais fournit également une analyse approfondie des erreurs. Capacité de positionnement, réduisant efficacement le temps de découverte des défauts et de positionnement.
La nébuleuse Kuaimao rend les données d'observabilité plus précieuses ! https://flashcat.cloud/