
Open-Sora a été discrètement mis à jour dans la communauté open source ! Un seul objectif prend désormais en charge la génération vidéo jusqu'à 16 secondes dans des résolutions allant jusqu'à 720p et peut gérer n'importe quel rapport d'aspect texte-image, texte-vidéo, image-vidéo, vidéo-vidéo et génération vidéo de durée illimitée. besoins. Essayons l'effet.
Générez une scène de neige de Noël sur écran horizontal et publiez-la sur le site B

Créez à nouveau un écran vertical et créez Douyin

Il peut également générer de longues vidéos avec un seul plan de 16 secondes, désormais tout le monde peut devenir accro à l'écriture de scénarios.

Comment jouer? Itinéraire vers GitHub : github.com/hpcaitech/Open-Sora
Ce qui est encore plus cool, c'est que la dernière version d'Open-Sora est toujours open source et pleine de sincérité. L'entrepôt contient la dernière architecture de modèle, les derniers poids de modèle, les processus de formation multi-temps/résolution/format/fréquence d'images, la collecte de données. et Le processus complet de prétraitement, tous les détails de la formation, des exemples de démonstration et des didacticiels détaillés de démarrage .
1. Interprétation complète des rapports techniques
Récemment, l'équipe d'auteurs d'Open-Sora a officiellement publié la dernière version du rapport technique [1] sur GitHub. Ci-dessous, nous utiliserons le rapport technique pour interpréter les fonctions, l'architecture, les méthodes de formation, la collecte de données, le prétraitement et autres. aspects un par un.
1.1 Aperçu des dernières fonctionnalités
Cette mise à jour d'Open-Sora inclut principalement les fonctionnalités clés suivantes :
- Prise en charge de la génération de vidéos longues ;
- La résolution de génération vidéo peut atteindre jusqu'à 720p ;
- Un seul modèle prend en charge n'importe quel rapport d'aspect, différentes résolutions et durées de texte à image, texte à vidéo, image à vidéo, vidéo à vidéo et besoins de génération vidéo illimités ;
- Proposition d'une conception d'architecture de modèle plus stable qui prend en charge l'entraînement multi-temps/résolution/rapport d'aspect/fréquence d'images ;
- Le dernier processus de traitement automatique des données est open source ;
1.2 Modèle de diffusion spatio-temporelle
Cette mise à niveau d'Open-Sora a apporté des améliorations clés à l'architecture STDiT dans la version 1.0, visant à améliorer la stabilité de la formation et les performances globales du modèle. Pour la tâche actuelle de prédiction de séquence, l’équipe a adopté les meilleures pratiques des grands modèles de langage (LLM) et a remplacé le codage positionnel sinusoïdal dans l’attention temporelle par le codage positionnel rotationnel plus efficace (intégration RoPE).
De plus, afin d'améliorer la stabilité de la formation, ils se sont référés à l'architecture du modèle SD3 et ont introduit en outre la technologie de normalisation QK pour améliorer la stabilité de la formation de demi-précision. Afin de prendre en charge les exigences de formation de plusieurs résolutions, différents formats d'image et fréquences d'images, l'architecture ST-DiT-2 proposée par l'équipe de l'auteur peut automatiquement mettre à l'échelle le codage de position et gérer des entrées de différentes tailles.
1.3 Formation en plusieurs étapes
Le rapport technique indique qu'Open-Sora utilise une méthode d'entraînement en plusieurs étapes, où chaque étape continue l'entraînement en fonction des poids de l'étape précédente. Par rapport à la formation en une seule étape, cette formation en plusieurs étapes atteint plus efficacement l'objectif de génération vidéo de haute qualité en introduisant les données étape par étape.
- Étape initiale : la plupart des vidéos utilisent une résolution de 144p et sont mélangées avec des images et des vidéos de 240p et 480p pour la formation. La formation dure environ 1 semaine et la taille totale des étapes est de 81 000.
- La deuxième étape : augmenter la résolution de la plupart des données vidéo à 240p et 480p, avec une durée d'entraînement de 1 jour et une taille de pas de 22k.
- La troisième étape : encore améliorée à 480p et 720p, la durée de l'entraînement est de 1 jour et l'entraînement de 4 000 étapes est terminé. L'ensemble du processus de formation en plusieurs étapes s'est déroulé en environ 9 jours.
Par rapport à la version 1.0, la dernière version améliore la qualité de la génération vidéo dans plusieurs dimensions.
1.4 Cadre vidéo unifié de génération d'images/vidéo génératrice de vidéos
L'équipe d'auteurs a déclaré que, sur la base des caractéristiques de Transformer, l'architecture DiT peut être facilement étendue pour prendre en charge les tâches image à image et vidéo à vidéo. Ils ont proposé une stratégie de masquage pour prendre en charge le traitement conditionnel des images et des vidéos. En définissant différents masques, diverses tâches de génération peuvent être prises en charge, notamment : vidéo graphique, vidéo en boucle, extension vidéo, génération vidéo autorégressive, connexion vidéo, montage vidéo, insertion de trames, etc.
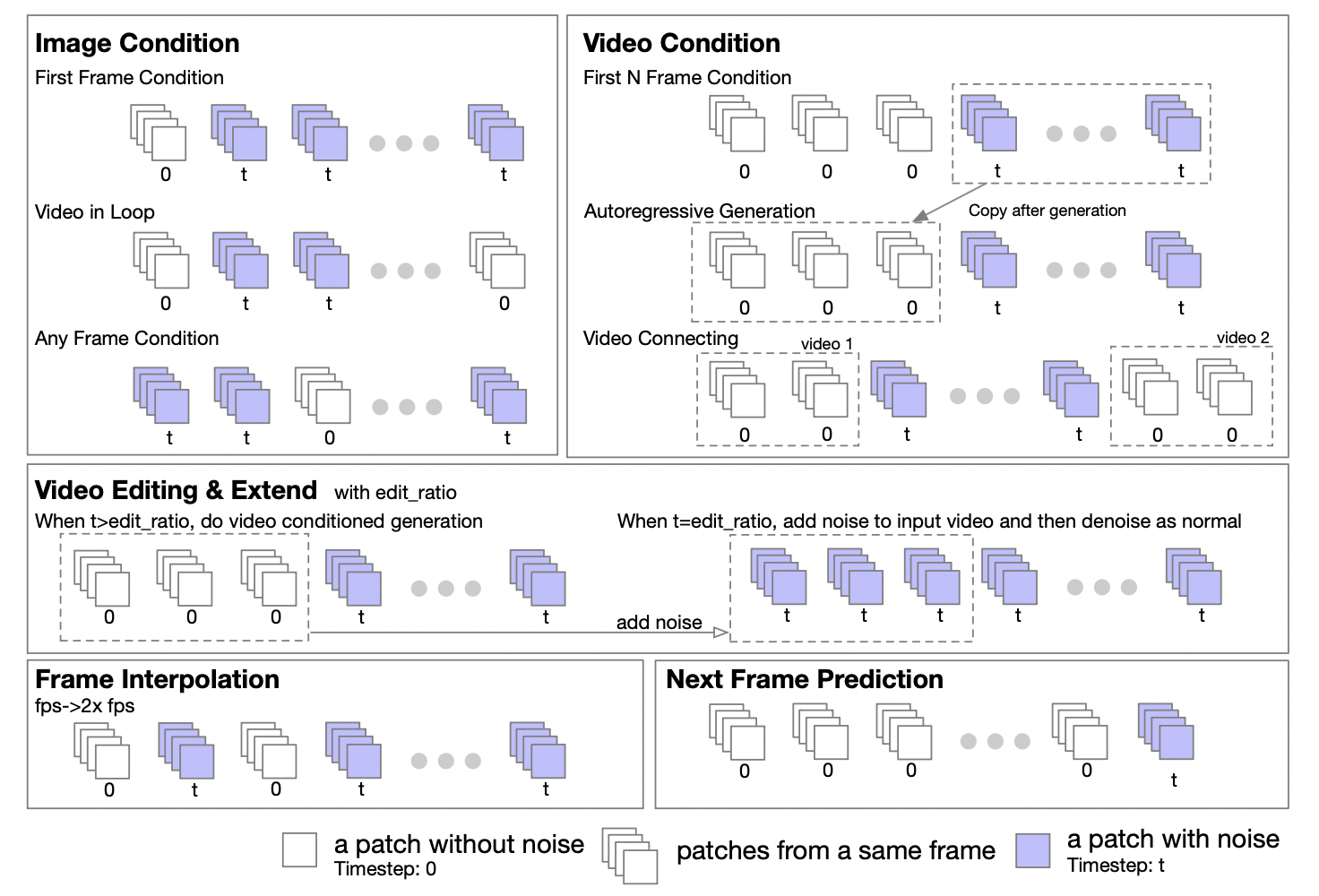
Inspirés par la méthode UL2[2], ils ont introduit une stratégie de masquage aléatoire lors de la phase de formation du modèle. Plus précisément, il s'agit de sélectionner et de démasquer de manière aléatoire des trames pendant le processus de formation, y compris, mais sans s'y limiter, le démasquage de la première trame, des k premières trames, des k trames suivantes, des k trames éventuelles, etc. Le rapport révèle également que, sur la base d'expériences sur Open-Sora 1.0, en appliquant la stratégie de masquage avec une probabilité de 50 %, le modèle peut mieux apprendre à gérer le conditionnement d'image en quelques étapes seulement. Dans la dernière version d'Open-Sora, ils ont adopté une méthode de pré-entraînement à partir de zéro utilisant une stratégie de masquage.
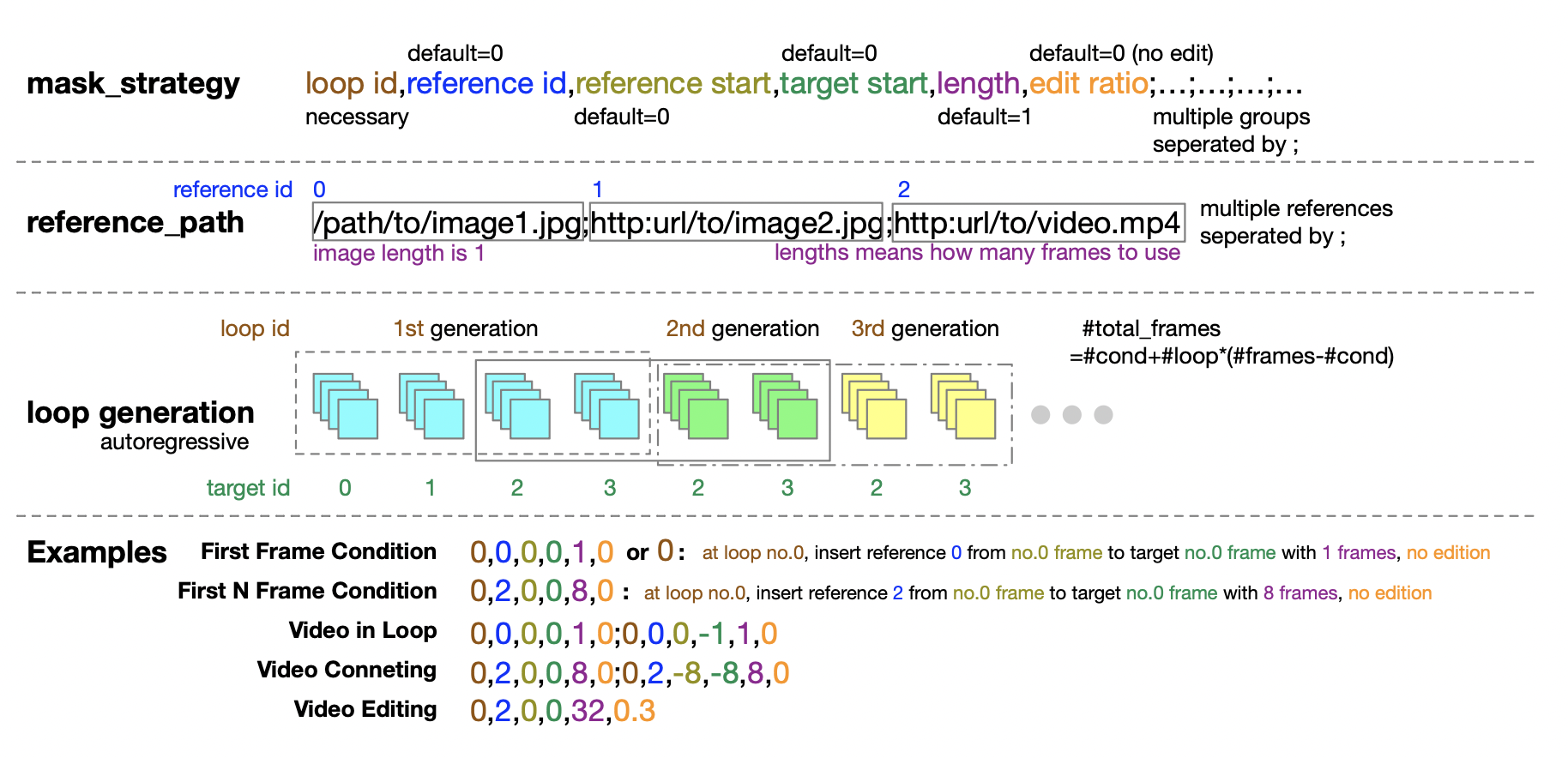
En outre, l'équipe d'auteurs fournit également des conseils détaillés pour la configuration de la politique de masquage pour l'étape d'inférence. La forme tuple de cinq nombres offre une grande flexibilité et un grand contrôle lors de la définition de la politique de masquage.
1.5 Prend en charge l'entraînement multi-temps/résolution/rapport d'aspect/fréquence d'image
Le rapport technique d'OpenAI Sora [3] souligne que l'entraînement utilisant la résolution, le rapport hauteur/largeur et la longueur de la vidéo originale peut augmenter la flexibilité de l'échantillonnage et améliorer les images et la composition. À cet égard, l’équipe des auteurs a proposé une stratégie de regroupement.
Comment le mettre en œuvre concrètement ? Grâce à une lecture approfondie du rapport technique publié par l'auteur, nous avons appris que ce qu'on appelle le bucket est un triplet de (résolution, nombre d'images, rapport hauteur/largeur). Ils prédéfinissent une gamme de formats d'image pour les vidéos à différentes résolutions afin de couvrir les types de formats d'image vidéo les plus courants. Avant le début de chaque cycle de formation epoch, ils remanient l'ensemble de données et attribuent les échantillons aux compartiments correspondants en fonction de leurs caractéristiques. Plus précisément, ils placent chaque échantillon dans un compartiment dont la résolution et la longueur d'image sont inférieures ou égales à cette fonctionnalité vidéo.
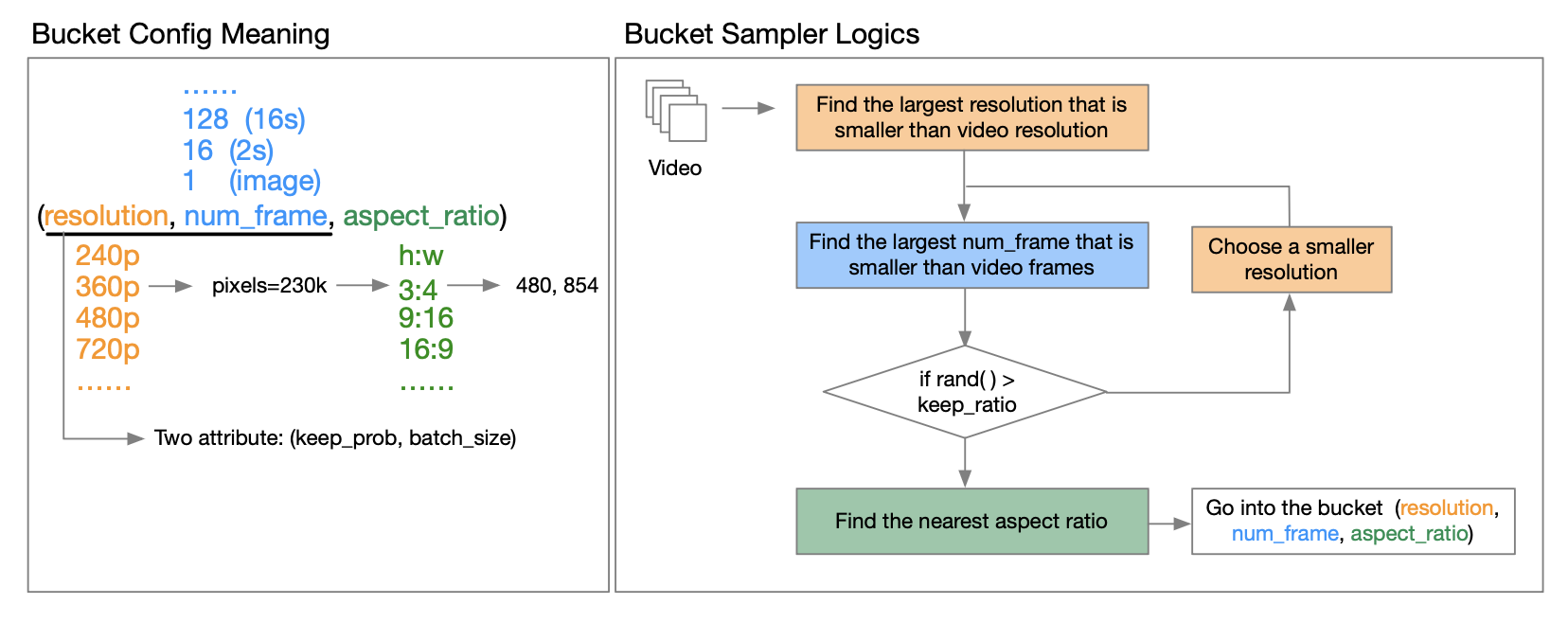
Pour réduire les besoins en ressources de calcul, ils introduisent deux attributs (résolution, nombre de trames) pour chacun keep_prob, réduisent les coûts de calcul et permettent une formation en plusieurs étapes. batch_sizeCela vous permet de contrôler le nombre d'échantillons dans différents compartiments et d'équilibrer la charge GPU en recherchant une bonne taille de lot pour chaque compartiment. Ceci est expliqué en détail dans le rapport technique. Les amis intéressés peuvent lire le rapport technique sur GitHub pour obtenir plus d'informations.
Adresse GitHub : github.com/hpcaitech/Open-Sora
1.6 Processus de collecte et de prétraitement des données
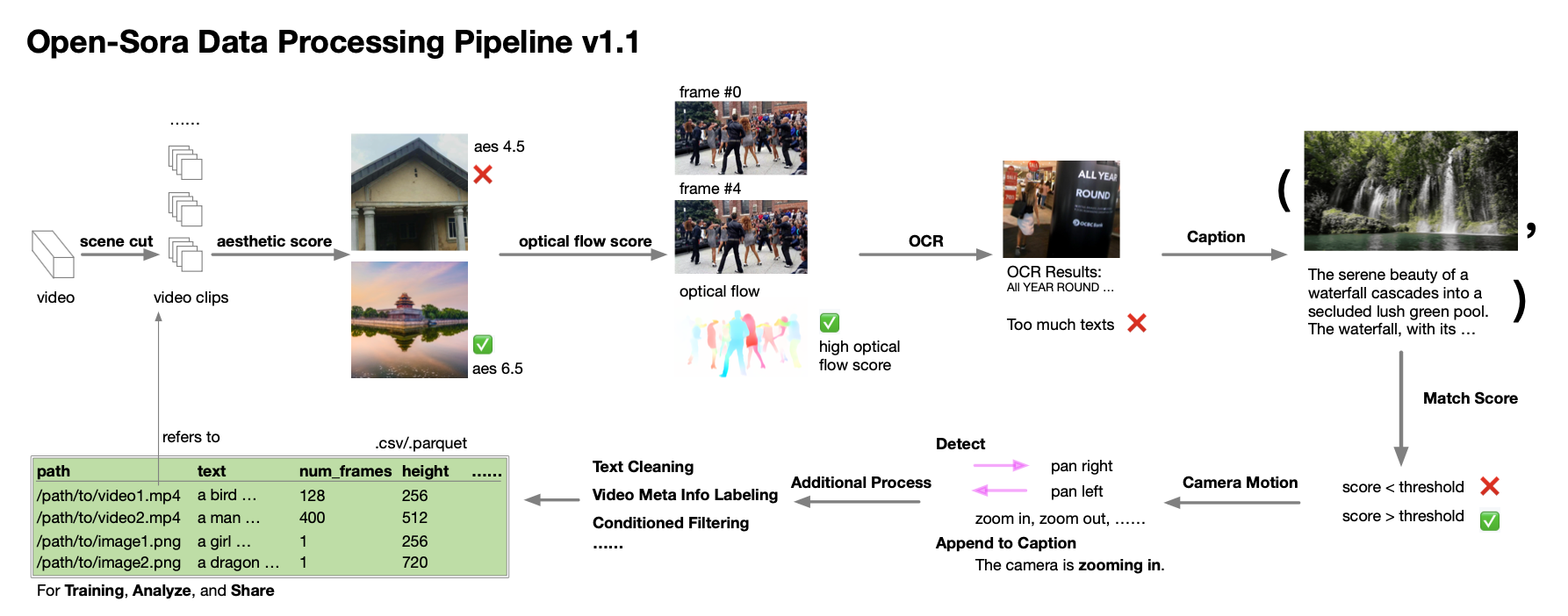
L'équipe d'auteurs fournit même des conseils détaillés sur la collecte et le traitement des données. Selon le rapport technique, au cours du processus de développement d'Open-Sora 1.0, ils ont réalisé que la quantité et la qualité des données sont extrêmement critiques pour développer un modèle haute performance, ils ont donc travaillé pour étendre et optimiser l'ensemble de données. Ils ont établi un processus de traitement automatisé des données qui suit le principe de décomposition en valeurs singulières (SVD) et couvre la segmentation des scènes, le traitement des sous-titres, la notation et le filtrage de la diversité, ainsi que le système de gestion et la spécification de l'ensemble de données.
De même, ils partagent de manière désintéressée des scripts liés au traitement des données avec la communauté open source. Les développeurs intéressés peuvent désormais utiliser ces ressources, combinées à des rapports techniques et du code, pour traiter et optimiser efficacement leurs propres ensembles de données.
2. Évaluation complète des performances
Après avoir dit tant de détails techniques, profitons des derniers effets de génération vidéo d'Open-Sora et détendons-nous.
Le point culminant le plus frappant de cette mise à jour d'Open-Sora est qu'elle peut capturer et transformer la scène dans votre esprit en une vidéo animée grâce à une description textuelle. Les images et les imaginations qui vous traversent l’esprit peuvent désormais être enregistrées de manière permanente et partagées avec d’autres. Ici, l’auteur a essayé plusieurs invites différentes comme point de départ.
2.1 Paysage
Par exemple, l'auteur a essayé de générer une vidéo d'une visite dans une forêt en hiver. Peu de temps après que la neige soit tombée, les pins étaient recouverts de neige blanche. Des aiguilles de pin sombres et des flocons de neige blancs étaient dispersés en couches claires.

Ou, par une nuit calme, vous vous trouvez dans une forêt sombre comme celle décrite dans d'innombrables contes de fées, avec un lac profond étincelant sous les étoiles brillantes du ciel.

La vue nocturne sur l'île animée depuis les airs est encore plus belle. Les lumières jaunes chaudes et l'eau bleue en forme de ruban attirent instantanément les gens dans le temps tranquille des vacances.

La ville est très fréquentée et les immeubles de grande hauteur et les magasins de rue encore éclairés tard dans la nuit ont une saveur différente.

2.2 Organismes naturels
En plus des paysages, Open-Sora peut également restaurer diverses créatures naturelles. Que ce soit une petite fleur rouge,

Qu’il s’agisse d’un caméléon qui tourne lentement la tête, Open-Sora peut générer des vidéos plus réalistes.

2.3 Différentes résolutions/rapports d'aspect/durées
L'auteur a également essayé une variété de tests rapides et a fourni de nombreuses vidéos générées pour votre référence, y compris différents contenus, différentes résolutions, différents formats d'image et différentes durées.



L'auteur a également découvert qu'avec une seule commande simple, Open-Sora peut générer des clips vidéo multi-résolution, dépassant ainsi complètement les limites de la créativité.



2.4 Vidéo Tusheng
Nous pouvons également fournir à Open-Sora une image statique et lui faire générer une courte vidéo.

Open-Sora peut également connecter intelligemment deux images fixes. Cliquez sur la vidéo ci-dessous et vous ferez l'expérience des changements de lumière et d'ombre de l'après-midi au crépuscule. Chaque image est un poème du temps.

2.5 Montage vidéo
Pour un autre exemple, nous souhaitons éditer la vidéo originale Avec une simple commande, la forêt initialement lumineuse a déclenché de fortes chutes de neige.


2.6 Générer des images haute définition
Nous pouvons également permettre à Open-Sora de générer des images haute définition :

Il convient de noter que les pondérations des modèles d’Open-Sora ont été rendues publiques gratuitement sur leur communauté open source. Puisqu'ils prennent également en charge la fonction de collage vidéo, cela signifie que vous avez la possibilité de créer gratuitement une nouvelle avec une histoire pour concrétiser votre créativité.
Adresse de téléchargement du poids : github.com/hpcaitech/Open-Sora
3. Limites actuelles et projets futurs
Bien qu'Open-Sora ait fait de bons progrès dans la reproduction des modèles vidéo Vincent de type Sora, l'équipe d'auteur a également humblement souligné que les vidéos actuellement générées doivent encore être améliorées à bien des égards, notamment les problèmes de bruit pendant le processus de génération, le manque de temps. cohérence, mauvaise qualité de génération de personnages et faibles scores esthétiques.
Concernant ces défis, l'équipe d'auteurs a déclaré qu'elle donnerait la priorité à leur résolution lors du développement de la prochaine version afin d'atteindre des normes de génération vidéo plus élevées. Les amis intéressés souhaiteront peut-être continuer à y prêter attention. Nous attendons avec impatience la prochaine surprise que la communauté Open-Sora nous apportera.
Adresse GitHub : github.com/hpcaitech/Open-Sora
les références:
[1] https://github.com/hpcaitech/Open-Sora/blob/main/docs/report_02.md
[2] Tay, Yi et coll. "Ul2 : Unifier les paradigmes d'apprentissage des langues." Préimpression arXiv arXiv :2205.05131 (2022).
[3] https://openai.com/research/video-Generation-models-as-world-simulators
J'ai décidé d'abandonner l'open source Hongmeng Wang Chenglu, le père de l'open source Hongmeng : L'open source Hongmeng est le seul événement logiciel industriel d'innovation architecturale dans le domaine des logiciels de base en Chine - OGG 1.0 est publié, Huawei contribue à tout le code source. Google Reader est tué par la "montagne de merde de code" Fedora Linux 40 est officiellement publié Ancien développeur Microsoft : les performances de Windows 11 sont "ridiculement mauvaises" Ma Huateng et Zhou Hongyi se serrent la main pour "éliminer les rancunes" Des sociétés de jeux bien connues ont publié de nouvelles réglementations : les cadeaux de mariage des employés ne doivent pas dépasser 100 000 yuans Ubuntu 24.04 LTS officiellement publié Pinduoduo a été condamné pour concurrence déloyale Indemnisation de 5 millions de yuans