
Depuis l'émergence de ChatGPT fin 2022, l'intelligence artificielle est redevenue au centre des préoccupations du monde, et l'IA basée sur de grands modèles de langage (LLM) est devenue un « poulet chaud » dans le domaine de l'intelligence artificielle. Au cours de l'année qui a suivi, nous avons été témoins des progrès rapides de l'IA dans le domaine du texte Wensheng et des images Wensheng, mais le développement dans le domaine de la vidéo Wensheng a été relativement lent. Début 2024, OpenAI a de nouveau publié un blockbuster : le modèle vidéo de Vincent, Sora. La dernière pièce du puzzle de création de contenu a été complétée par l'IA.
Il y a un an, une vidéo de Smith mangeant des nouilles est devenue virale sur les réseaux sociaux. Sur la photo, l'acteur avait un visage hideux, des traits déformés et mangeait des spaghettis dans une posture tordue. Cette terrible image nous rappelle que la technologie de la vidéo générée par l’IA n’en était qu’à ses balbutiements à l’époque.

À peine un an plus tard, une vidéo d'IA de « femmes à la mode marchant dans les rues de Tokyo » générée par Sora a une fois de plus enflammé les médias sociaux. En mars suivant, Sora s'est associée à des artistes du monde entier pour lancer officiellement une série de courts métrages d'art surréaliste qui bouleversaient la tradition. Le court métrage suivant "Air Head" a été créé par les célèbres réalisateurs Walter et Sora. L'image est exquise et réaliste, et le contenu est sauvage et imaginatif. On peut dire que Sora a « écrasé » les modèles vidéo d’IA grand public tels que Gen-2, Pika et Stable Video Diffusion lors de ses débuts.

L’évolution de l’IA est bien plus rapide que prévu. Nous pouvons facilement prévoir que la structure industrielle existante, y compris les courtes vidéos, les jeux, le cinéma et la télévision, la publicité, etc., sera remodelée dans un avenir proche. L'arrivée de Sora semble nous rapprocher d'un modèle de construction du monde.
Pourquoi Sora a-t-il une magie si puissante ? Quelles technologies magiques utilise-t-il ? Après avoir examiné le rapport technique officiel et de nombreux documents connexes, l'auteur expliquera dans cet article les principes techniques derrière Sora et la clé de son succès.
1 Quel problème central Sora veut-il résoudre ?
Pour résumer en une phrase, le défi auquel Sora est confronté est de savoir comment transformer plusieurs types de données visuelles en une méthode de représentation unifiée afin qu'un entraînement unifié puisse être effectué.
Pourquoi avons-nous besoin d’une formation unifiée ? Avant de répondre à cette question, jetons d'abord un coup d'œil aux précédentes idées de génération de vidéos IA grand public de Sora.
1.1 Méthode de génération de vidéo IA à l'ère pré-Sora
- Développer en fonction du contenu de l'image à image unique
Les extensions basées sur des images à image unique utilisent le contenu de l'image actuelle pour prédire l'image suivante. Chaque image est une continuation de l'image précédente, formant ainsi un flux vidéo continu (l'essence de la vidéo est une image affichée en continu image par image). .
Dans ce processus, des descriptions textuelles sont généralement utilisées pour générer des images, puis des vidéos sont générées sur la base des images. Cependant, cette idée pose un problème : l'utilisation de texte pour générer des images elle-même est aléatoire. Ce caractère aléatoire est amplifié deux fois lors de l'utilisation d'images pour générer des vidéos, et la contrôlabilité et la stabilité de la vidéo finale sont très faibles.
- Entraînez-vous directement sur toute la vidéo
Étant donné que l'effet vidéo basé sur la dérivation d'une seule image n'est pas bon, l'idée est alors modifiée pour entraîner la vidéo entière.
Ici, un clip vidéo de quelques secondes est généralement sélectionné et le modèle est informé de ce que montre la vidéo. Après de nombreux entraînements, l'IA peut apprendre à générer des clips vidéo dont le style est similaire aux données d'entraînement. Le défaut de cette idée est que le contenu appris par l’IA est fragmenté, qu’il est difficile de générer de longues vidéos et que la continuité des vidéos est mauvaise.
Certaines personnes peuvent se demander pourquoi ne pas utiliser des vidéos plus longues pour la formation ? La raison principale est que les vidéos sont très volumineuses par rapport au texte et aux images, et que la carte graphique a une mémoire vidéo limitée et ne peut pas prendre en charge une formation vidéo plus longue. Sous diverses restrictions, la quantité de connaissances de l’IA est extrêmement limitée. Lors de la saisie de contenus qu’elle « ne connaît pas », les résultats générés sont souvent insatisfaisants.
Par conséquent, si vous souhaitez briser le goulot d’étranglement de la vidéo IA, vous devez résoudre ces problèmes fondamentaux.
1.2 Défis liés à la formation de modèles vidéo
Les données vidéo se présentent sous diverses formes, de l'écran horizontal à l'écran vertical, de 240p à 4K, différents formats d'image, différentes résolutions et différents attributs vidéo. La complexité et la diversité des données entraînent de grandes difficultés dans la formation de l'IA, ce qui conduit à de mauvaises performances du modèle. C'est pourquoi ces données vidéo doivent d'abord être représentées de manière unifiée.
La tâche principale de Sora est de trouver un moyen de convertir plusieurs types de données visuelles en une méthode de représentation unifiée afin que toutes les données vidéo puissent être efficacement entraînées dans un cadre unifié.
1.3 Sora : jalons vers l'AGI
Notre mission est de faire en sorte que l’intelligence artificielle générale profite à l’ensemble de l’humanité. ——OpenAI
L'objectif d'OpenAI a toujours été clair : atteindre l'intelligence générale artificielle (AGI), alors quelle importance la naissance de Sora a-t-elle dans la réalisation de l'objectif d'OpenAI ?
Pour mettre en œuvre l’AGI, le grand modèle doit comprendre le monde. Tout au long du développement d'OpenAI, le modèle GPT initial a permis à l'IA de comprendre le texte (une dimension, uniquement la longueur), et le modèle DALL·E lancé par la suite a permis à l'IA de comprendre les images (deux dimensions, longueur et largeur), et maintenant le modèle Sora. permet à l'IA de comprendre la vidéo (tridimensionnelle, longueur, largeur et temps).
Grâce à une compréhension globale des textes, des images et des vidéos, l’IA peut progressivement comprendre le monde. Sora est l'avant-poste d'OpenAI en matière d'AGI. C'est plus qu'un simple modèle de génération vidéo, comme l'indique le titre de son rapport technique [1] : "Un modèle de génération vidéo comme simulateur mondial".
La vision de Tuoshupai coïncide avec l'objectif d'OpenAI. Les vulgarisateurs estiment que l’utilisation d’un petit nombre de symboles et de modèles informatiques pour modéliser la société humaine et l’intelligence individuelle a jeté les bases des premières IA, mais que les dividendes plus importants dépendent de plus grandes quantités de données et d’une puissance de calcul plus élevée. Lorsque nous ne pouvons pas créer un nouveau modèle révolutionnaire, nous pouvons rechercher davantage d'ensembles de données et utiliser une plus grande puissance de calcul pour améliorer la précision du modèle, échanger la puissance de calcul des données contre la puissance du modèle et stimuler l'innovation dans les systèmes informatiques de données. Dans le système informatique de données à grand modèle publié par Tuoshupai, les modèles mathématiques, les données et les calculs de l'IA seront connectés de manière transparente et se renforceront mutuellement comme jamais auparavant, devenant ainsi une nouvelle force productive favorisant un développement de haute qualité de la société [2].
2 Interprétation du principe de Sora
Sora n'est pas le premier modèle vidéo de Vincent à être publié, alors pourquoi fait-il tant de bruit ? Quel est le secret derrière cela ? Si vous décrivez le processus de formation de Sora en une phrase : la vidéo originale est compressée dans l'espace latent via un encodeur visuel et décomposée en patchs spatio-temporels, qui sont combinés avec du texte. Des contraintes conditionnelles sont utilisées pour effectuer la formation de diffusion et la génération via le transformateur. les blocs d'images sont finalement mappés sur l'espace des pixels via le décodeur visuel correspondant.
2.1 Réseau de compression vidéo
Sora convertit d'abord les données vidéo brutes en fonctionnalités d'espace latent de faible dimension. Les données vidéo que nous regardons quotidiennement sont trop volumineuses et doivent d’abord être converties en vecteurs de faible dimension que l’IA peut traiter. Ici, OpenAI s'appuie sur un article classique : les modèles de diffusion latente[3].
L'objectif principal de cet article est d'affiner l'image originale en une caractéristique spatiale latente, qui peut non seulement conserver les informations clés sur les caractéristiques de l'image originale, mais également compresser considérablement la quantité de données et d'informations.
OpenAI a probablement mis à niveau l'encodeur automatique variationnel (VAE) pour les images dans cet article afin de prendre en charge le traitement des données vidéo. De cette manière, Sora peut convertir une grande quantité de données vidéo originales en fonctionnalités d'espace latent de faible dimension, c'est-à-dire extraire les informations clés de base de la vidéo, qui peuvent représenter le contenu clé de la vidéo.
2.2 Correctifs spatio-temporels
Pour effectuer une formation vidéo sur l’IA à grande échelle, l’unité de base des données de formation doit d’abord être définie. Dans le grand modèle de langage (LLM), l'unité de base de formation est le Token[4]. OpenAI s'inspire du succès de ChatGPT : le mécanisme du Token unifie avec élégance différentes formes de texte : code, symboles mathématiques et divers langages naturels. Sora pourra-t-il trouver son « Token » ?
Grâce aux résultats de recherches précédentes, Sora a finalement trouvé la réponse : Patch.
- Transformateur de vision (ViT)
Qu'est-ce qu'un patch ? Patch peut être compris familièrement comme un bloc d’image. Lorsque la résolution de l’image à traiter est trop grande, la formation directe n’est pas pratique. Par conséquent, une méthode est proposée dans l'article Vision Transformer [5] : diviser l'image originale en blocs d'image (Patch) de même taille, puis sérialiser ces blocs d'image et ajouter leurs informations de position (Position Embedding), de sorte que les images complexes peut être converti en séquences les plus familières de l'architecture Transformer, en utilisant le mécanisme d'auto-attention pour capturer la relation entre chaque bloc d'image et, finalement, comprendre le contenu de l'image entière.
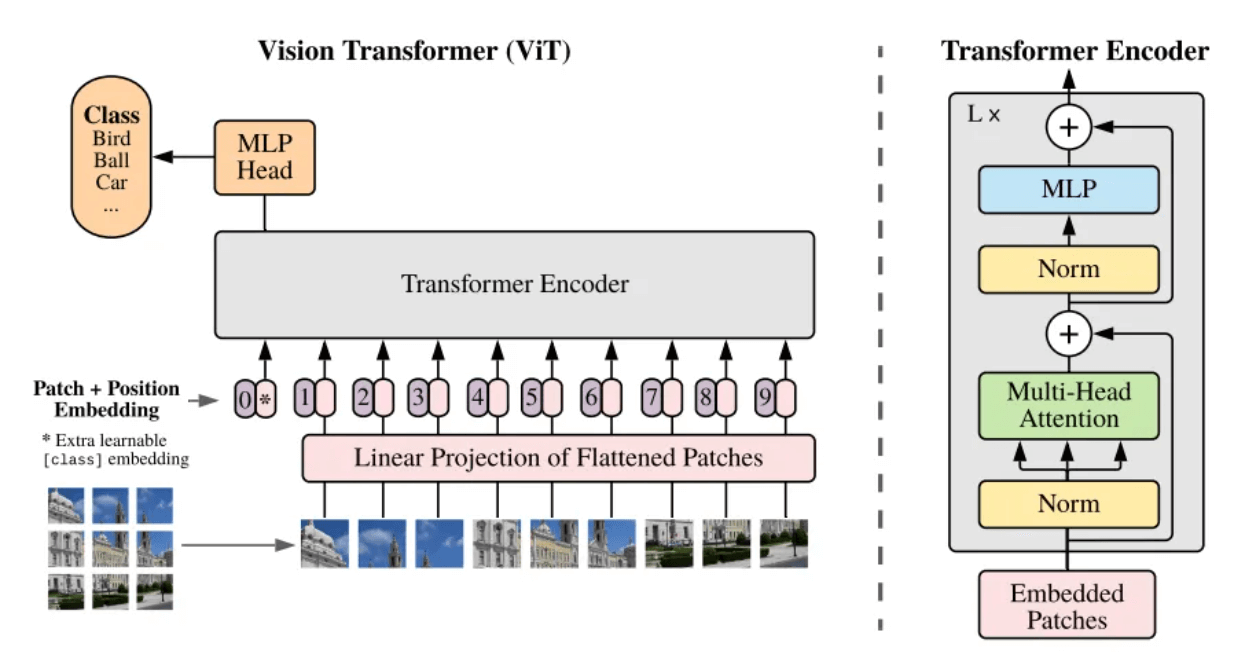
Structure du cadre du modèle ViT[5]
La vidéo peut être vue comme une séquence d'images distribuées le long de l'axe du temps, donc Sora ajoute la dimension du temps, en mettant à niveau les blocs d'images statiques en patchs d'images spatio-temporelles (Spacetime Patches). Chaque bloc d'image spatio-temporelle contient à la fois des informations temporelles et des informations spatiales dans la vidéo, c'est-à-dire qu'un bloc d'image spatio-temporelle représente non seulement une petite zone spatiale dans la vidéo, mais représente également les changements dans cette zone spatiale sur une période de 30 000 heures. temps.
En introduisant le concept de patch, la corrélation spatiale peut être calculée pour des blocs d'images spatio-temporels à différentes positions dans une seule image ; la corrélation temporelle peut être calculée pour des blocs d'images spatio-temporels à la même position dans des images consécutives. Chaque bloc d’image n’existe plus isolément, mais est étroitement lié aux éléments environnants. De cette façon, Sora est capable de comprendre et de générer du contenu vidéo avec des détails spatiaux et une dynamique temporelle riches.

Décomposer les images de séquence en blocs d'images spatio-temporelles
- Résolution native (NaViT)
Cependant, le modèle ViT présente un très gros inconvénient : l'image originale doit être carrée et chaque bloc d'image a la même taille fixe. Les vidéos quotidiennes ne sont que larges ou hautes, et il n'y a pas de vidéos carrées.
Par conséquent, OpenAI a trouvé une autre solution : la technologie « Patch n' Pack » [6] dans NaViT , qui peut traiter le contenu d'entrée de n'importe quelle résolution et format d'image.
Cette technologie divise le contenu avec différents formats et résolutions en blocs d'images. Ces blocs d'images peuvent être redimensionnés en fonction de différents besoins. Les blocs d'images de différentes images peuvent être regroupés de manière flexible dans la même séquence pour une formation unifiée. De plus, cette technologie peut également supprimer des blocs d'images identiques en fonction de la similarité des images, réduisant ainsi considérablement le coût de la formation et permettant une formation plus rapide.
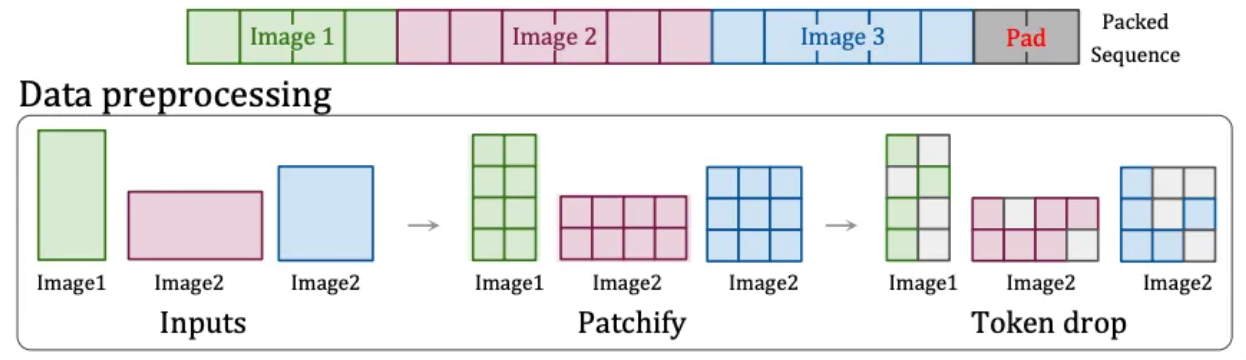
Technologie Patch n'Pack[6]
C'est pourquoi Sora peut prendre en charge la génération de vidéos de différentes résolutions et formats d'image. De plus, l'entraînement avec le rapport hauteur/largeur natif peut améliorer la composition et le cadrage de la vidéo de sortie, car le recadrage perdra inévitablement des informations et le modèle comprendra facilement le contenu principal de l'image originale, ce qui entraînera une image avec seulement une partie du contenu principal. corps.
Le rôle joué par les patchs spatio-temporels est le même que celui du jeton dans le grand modèle de langage. C'est l'unité de base de la vidéo. Lorsque nous compressons et décomposons une vidéo en une série de patchs spatio-temporels, nous convertissons en fait les informations visuelles continues en. Une série d'unités discrètes qui peuvent être traitées par le modèle, qui constituent la base de l'apprentissage et de la génération du modèle.
2.3 Description du texte vidéo
Grâce à l'explication ci-dessus, nous avons compris le processus par lequel Sora convertit les vidéos originales en vecteurs spatio-temporels finaux pouvant être entraînés. Mais il y a un problème qui doit être résolu avant la formation proprement dite : expliquer au modèle de quoi parle cette vidéo.
Pour former un modèle vidéo Wensheng, il est nécessaire d'établir une correspondance entre le texte et la vidéo . Lors de la formation, un grand nombre de vidéos avec les descriptions textuelles correspondantes sont nécessaires. Cependant, la qualité des descriptions annotées manuellement est faible et irrégulière, ce qui affecte la qualité. résultats de la formation. Par conséquent, OpenAI a emprunté la technologie de re-sous-titrage [7] de son propre DALL·E 3 et l'a appliquée au domaine vidéo.
Plus précisément, OpenAI a d'abord formé un modèle de génération de sous-titres hautement descriptif et a utilisé ce modèle pour générer des informations de description détaillées pour toutes les vidéos de l'ensemble de formation conformément aux spécifications. Cette partie des informations de description textuelle a été combinée avec les correctifs d'image spatio-temporels mentionnés précédemment lors de la finale. Après la correspondance et la formation, Sora peut comprendre et correspondre à la description du texte et aux blocs d'images vidéo.
De plus, OpenAI utilisera également GPT pour convertir les brèves invites de l'utilisateur en phrases de description plus détaillées similaires à celles de la formation, ce qui permettra à Sora de suivre avec précision les invites de l'utilisateur et de générer des vidéos de haute qualité.
2.4 Formation et génération vidéo
Il est clairement mentionné dans le rapport technique officiel [1] que Sora est un transformateur de diffusion, c'est-à-dire que Sora est un modèle de diffusion avec Transformer comme réseau fédérateur.
- Diffusion Transformer(DiT)
Le concept de diffusion vient du processus de diffusion en physique. Par exemple, lorsqu'une goutte d'encre tombe dans l'eau, elle se propage lentement au fil du temps. Cette diffusion est le processus d'une faible entropie à une entropie élevée. se dispersera progressivement d'une goutte à diverses parties d'eau.
Inspiré de ce processus de diffusion, le Modèle de Diffusion est né. Il s’agit d’un modèle de « dessin » classique sur lequel sont basés Stable Diffusion et Midjourney. Son principe de base est d'ajouter progressivement du bruit à l'image originale, lui permettant de devenir progressivement un état de bruit complet, puis d'inverser ce processus, c'est-à-dire le débruitage (Denoise) pour restaurer l'image. En laissant le modèle apprendre un grand nombre d'expériences d'inversion, le modèle apprend finalement à générer un contenu d'image spécifique à partir de l'image de bruit.
Selon le rapport, la méthode de Sora est susceptible de remplacer l'architecture U-Net dans le modèle de diffusion original par l'architecture Transformer qu'il connaît le mieux. Parce que selon l'expérience dans d'autres tâches d'apprentissage profond, par rapport à U-Net, les paramètres de l'architecture Transformer sont hautement évolutifs. À mesure que le nombre de paramètres augmente, l'amélioration des performances de l'architecture Transformer sera plus évidente.
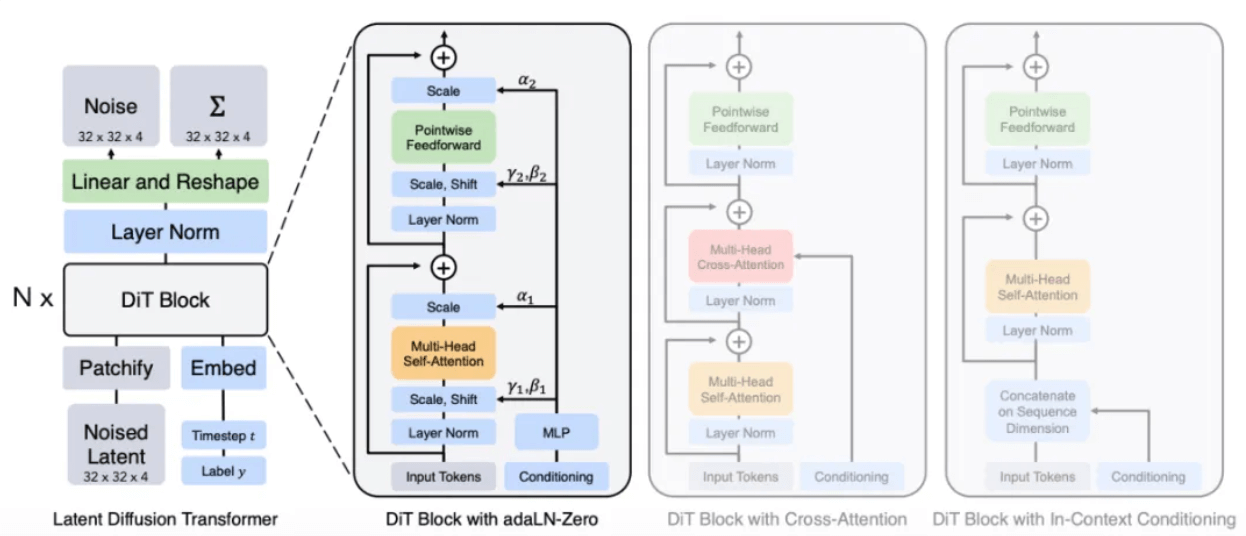
Architecture du modèle DiT[8]
Grâce à un processus similaire au modèle de diffusion, des correctifs de bruit (et des informations conditionnelles telles que des invites textuelles) sont fournis pendant la formation, et le bruit est ajouté et débruité à plusieurs reprises, et enfin le modèle apprend à prédire les correctifs d'origine.

Restaurer le patch de bruit sur le patch d'image d'origine
- Processus de génération vidéo
Enfin, nous résumons l'ensemble du processus de génération de vidéos par Sora à partir de texte.
Lorsque l'utilisateur saisit une description textuelle, Sora appelle d'abord le modèle pour le développer en une phrase de description vidéo standard, puis génère un premier bloc d'image spatio-temporelle à partir du bruit basé sur la description. Sora continue ensuite à générer la vidéo. sur la base du bloc d'image spatio-temporelle existant et des conditions de texte. Le prochain bloc d'image spatio-temporelle est supposé être généré (de la même manière que GPT prédit le prochain jeton basé sur le jeton existant), et enfin la représentation potentielle générée est mappée sur L'espace des pixels via le décodeur correspondant pour former une vidéo.
3 Le potentiel de l'informatique des données
En regardant le rapport technique de Sora, nous pouvons constater qu'en fait, Sora n'a pas réalisé de percée technologique majeure, mais a bien intégré les travaux de recherche antérieurs. Après tout, aucune technologie n'apparaîtra soudainement d'un coin. La raison la plus importante du succès de Sora est l’accumulation de puissance de calcul et de données.
Sora montre des effets d'échelle évidents au cours du processus de formation. La figure ci-dessous montre que pour les entrées et les graines fixes, à mesure que la quantité de calcul augmente, la qualité des échantillons générés s'améliore considérablement.

Comparaison des effets avec une puissance de calcul de base, 4 fois la puissance de calcul et 32 fois la puissance de calcul
De plus, en apprenant de grandes quantités de données, Sora a également démontré des capacités inattendues.
➢ Cohérence 3D : Sora est capable de générer des vidéos avec des mouvements de caméra dynamiques. À mesure que la caméra bouge et tourne, les personnages et les éléments de la scène conservent toujours des schémas de mouvement cohérents dans l'espace tridimensionnel.
➢Cohérence à long terme et persistance des objets : dans les plans longs, les personnes, les animaux et les objets conservent une apparence cohérente même après avoir été masqués ou avoir quitté le cadre.
➢Interactivité mondiale : Sora peut simuler des comportements qui affectent l'état du monde de manière simple. Par exemple, dans la vidéo décrivant la peinture, chaque trait laisse une trace sur la toile.
➢Simuler le monde numérique : Sora peut également simuler des vidéos de jeux, comme « Minecraft ».
Ces propriétés ne nécessitent pas de biais inductif explicite pour les objets 3D, etc., elles sont purement un phénomène d'effets d'échelle.
4 Système informatique de données grand modèle Tuoshupai
Le succès de Sora prouve une fois de plus l'efficacité de la stratégie « une plus grande puissance fait des miracles » : l'expansion continue de l'échelle du modèle favorisera directement l'amélioration des performances, qui dépendent fortement d'un grand nombre d'ensembles de données de haute qualité et d'ultra- une puissance de calcul à grande échelle Les données et le calcul sont indispensables.
Au début de sa création, Tuoshupai a positionné sa mission comme « l'informatique de données, uniquement pour de nouvelles découvertes », et notre objectif est de créer un « jeu de modèles infinis ». Son système de calcul de données de grands modèles utilise une technologie cloud native pour reconstruire le stockage et le calcul des données, avec un stockage unique et un calcul de données multimoteur, rendant les modèles d'IA plus grands et plus rapides et mettant à niveau complètement le système de Big Data vers l'ère des grands modèles.
Dans le système informatique de données à grand modèle, tout ce qui se trouve dans le monde et ses mouvements peuvent être numérisés en données. Les données peuvent être utilisées pour entraîner le modèle initial qui forme des règles de calcul et est ensuite ajoutée au système informatique de données. Le processus continue d’itérer et d’explorer à l’infini l’intelligence de l’IA. À l'avenir, Tuoshupai continuera d'explorer dans le domaine des données, de renforcer les capacités de recherche technologique de base, de travailler avec des partenaires industriels pour explorer les meilleures pratiques dans l'industrie des éléments de données et de promouvoir la prise de décision numérique intelligente.
Remarque : le rapport technique officiel d'OpenAI montre uniquement la méthode de modélisation générale et n'implique aucun détail de mise en œuvre. S'il y a des erreurs dans cet article, veuillez me corriger et communiquer avec moi.
les références:
- [1] Modèles de génération vidéo comme simulateurs mondiaux
- [2] Système informatique de données sur grands modèles - théorie
- [3] Synthèse d'images haute résolution avec modèles de diffusion latente
- [4] L'attention est tout ce dont vous avez besoin
- [5] Une image vaut 16 × 16 mots : transformateurs pour la reconnaissance d'images à grande échelle
- [6] Patch n'Pack : NaViT, un transformateur de vision pour tous les formats et toutes les résolutions
- [7] Améliorer la génération d'images avec de meilleures légendes
- [8] Modèles de diffusion évolutifs avec transformateurs