
Cet article est partagé par la communauté Huawei Cloud « Pratique de création de systèmes hautement disponibles avec Huawei Cloud FunctionGraph » par Xiaozhi, Huawei Cloud PaaS Service.
Introduction
Chaque année, des informations circulent sur Internet selon lesquelles le système XXX est anormalement indisponible, entraînant d'énormes pertes économiques pour les clients. Les services cloud ont une clientèle plus large. Une fois que des problèmes surviennent, ils auront un impact important sur les clients et sur le service lui-même. Basé sur les propres pratiques de Huawei Cloud FunctionGraph, cet article présentera en détail comment créer une plate-forme informatique sans serveur hautement disponible pour parvenir à une situation gagnant-gagnant à la fois pour les clients et pour la plate-forme.
Introduction à la haute disponibilité
Haute disponibilité [1] (anglais : haute disponibilité, en abrégé HA), terme informatique , fait référence à la capacité du système à exécuter ses fonctions sans interruption, représentant la disponibilité du système . C'est l'un des critères lors de la conception d'un système.
L'industrie utilise généralement des indicateurs SLA pour mesurer la disponibilité du système.
L'accord de niveau de service [2] (anglais : accord de niveau de service, abréviation SLA), également appelé accord de niveau de service, accord de niveau de service, est un engagement formel défini entre un prestataire de services et un client . Le prestataire de services et le client desservi ont spécifiquement atteint les indicateurs de service promis : qualité, disponibilité et responsabilité. Par exemple, si le fournisseur de services promet un SLA de 99,99 %, le temps annuel maximum de panne de service est de 5,26 minutes (365*24*60*0,001 %).
FunctionGraph mesure intuitivement les deux indicateurs clés de la disponibilité du système, SLI et la latence. SLI est l'indicateur du taux de réussite des demandes du système, et la latence est la performance du traitement du système.
Les défis de la haute disponibilité
En tant que sous-service de Huawei Cloud, FunctionGraph doit non seulement prendre en compte la robustesse du système lui-même, mais également la robustesse des services dépendants environnants tout en développant ses propres capacités (par exemple, le service d'authentification d'identité dépendant n'est pas disponible, la passerelle pour le transfert du trafic Le service de service est en panne, l'accès au service à l'objet de stockage échoue, etc.). De plus, lorsque les ressources matérielles sur lesquelles repose le système échouent ou que le système est soudainement attaqué par le trafic, etc., face à ces scénarios anormaux incontrôlables, il est difficile pour le système de développer ses propres capacités afin de maintenir une haute disponibilité commerciale. La figure 1 montre les interactions périphériques de FunctionGraph.

Figure 1 Interaction périphérique de FunctionGraph
Pour les problèmes courants, quatre grandes catégories ont été classées, comme le montre le tableau 1.
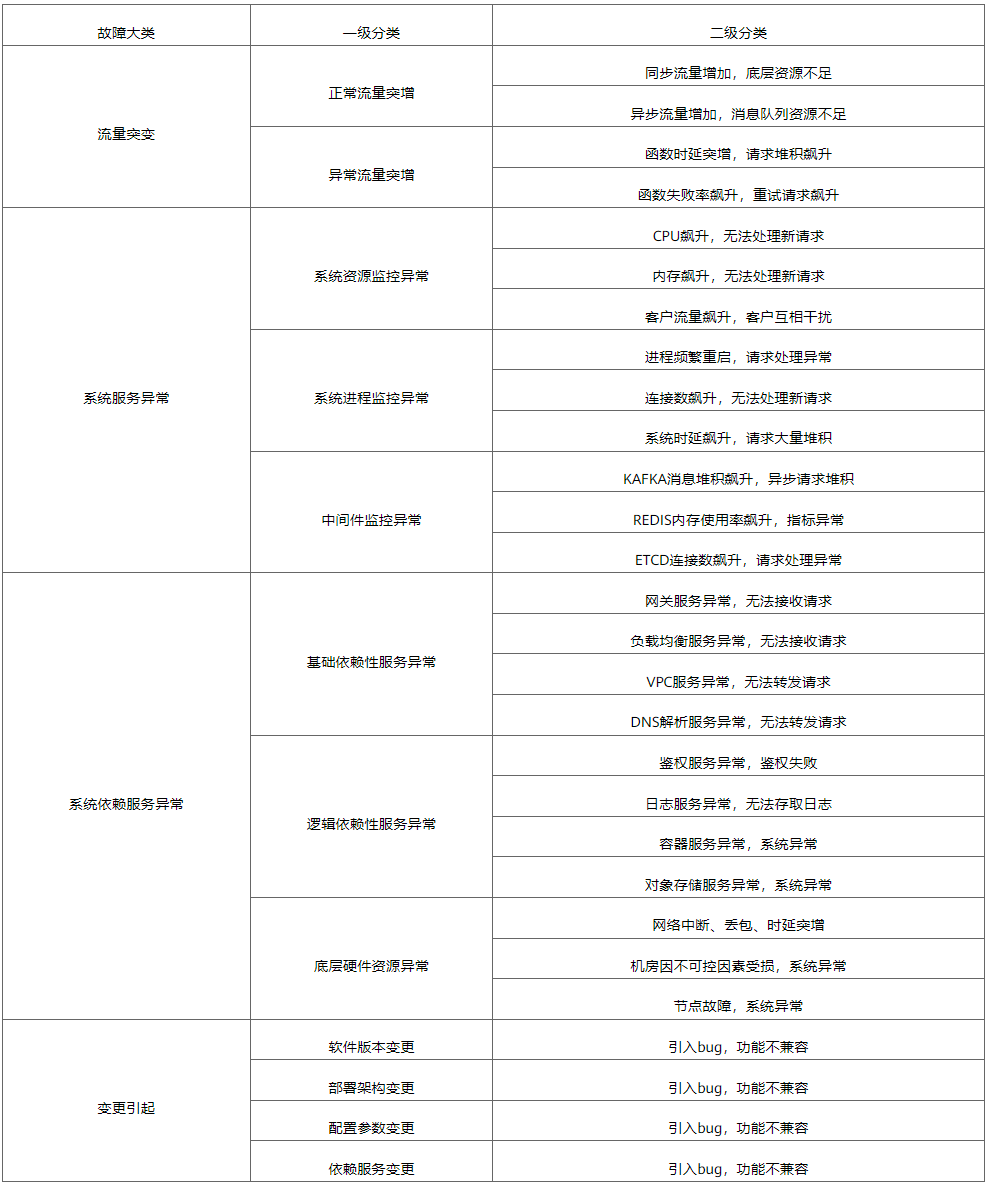
Tableau 1 Résumé des questions fréquemment posées dans FunctionGraph
En réponse à ces problématiques, nous avons résumé les modalités générales de gouvernance suivantes :
- Gestion des mutations du trafic : protection contre les surcharges + expansion et contraction élastiques + disjoncteur + coupure de pointe asynchrone + surveillance et alarme Basée sur le concept de conception défensive, la protection contre les surcharges + le disjoncteur garantit que toutes les ressources du système sont sous contrôle, puis sur ce point. Sur cette base, il offre la capacité d'expansion ultime pour répondre à un trafic important, des scénarios clients appropriés recommandent un écrêtage asynchrone des pointes pour réduire la pression du système et des alarmes de surveillance pour détecter les problèmes de surcharge en temps opportun.
- Gestion des exceptions de service système : architecture de reprise après sinistre + nouvelle tentative + isolation + surveillance et alarme. L'architecture de reprise après sinistre évite les temps d'arrêt complets du système et réduit l'impact des anomalies du système sur l'activité du client. découvrez rapidement les anomalies de service du système grâce à la surveillance des alarmes.
- Gestion des exceptions de service dépendant du système : architecture de récupération après sinistre + rétrogradation du cache + surveillance et alarme. L'architecture de récupération après sinistre réduit les points de défaillance uniques dans les services dépendants et garantit que le système peut toujours fonctionner normalement après des pannes de services dépendants. détecter les exceptions de service dépendant.
- Gouvernance causée par les changements : mise à niveau en niveaux de gris + contrôle des processus + surveillance et alarme. Grâce à la mise à niveau en niveaux de gris, nous pouvons éviter les pannes globales causées par des mises à niveau anormales du système pour les clients formels. Grâce au contrôle des processus, nous pouvons minimiser le risque de changements humains. changements après changements grâce à la surveillance et aux pannes alarmantes.
Pratique de conception de systèmes FunctionGraph
Afin de résoudre les problèmes du tableau 1, FunctionGraph a optimisé de nombreux aspects tels que la reprise après sinistre architecturale, le contrôle de flux, les nouvelles tentatives, le cache, la mise à niveau en niveaux de gris, la surveillance et les alarmes, ainsi que les processus de gestion, et sa convivialité a été considérablement améliorée. Ce qui suit présente principalement certaines pratiques de conception orientées exceptions de FunctionGraph et ne développe pas les capacités élastiques, les fonctions système, etc. pour le moment.
Architecture de reprise après sinistre
Pour mettre en œuvre l'architecture Huawei Cloud Disaster Recovery 1.1 (par exemple : domaine de pannes de niveau de service AZ, capacité d'auto-réparation de cluster entre AZ, isolation des dépendances de service de niveau AZ), plusieurs ensembles de plans de gestion FunctionGraph et de clusters de plans de données sont déployés, et chaque ensemble des clusters sont isolés de AZ pour réaliser une reprise après sinistre de AZ à l'intérieur. Comme le montre la figure 2, FunctionGraph déploie plusieurs ensembles de clusters de plans de données (pour entreprendre la fonction FunctionGraph en cours d'exécution) et de clusters de planification de répartiteur (pour entreprendre les tâches de planification du cluster de trafic de FunctionGraph) afin d'augmenter la capacité du système et la reprise après sinistre. Lorsqu'un des clusters Yuanrong est anormal, le composant de planification du répartiteur peut rapidement supprimer le cluster défectueux et distribuer le trafic à plusieurs autres clusters.

Figure 2 Diagramme d'architecture simple FunctionGraph
La conception d'une architecture décentralisée distribuée prend en charge une expansion et une contraction horizontales flexibles
Cette stratégie est la clé de la conception de services multi-tenants logiques. Elle doit résoudre le problème du rééquilibrage après la décentralisation et l’expansion et la contraction des composants.
Décentralisation de la gestion des données statiques : les métadonnées des services logiques multi-tenants peuvent toutes être stockées dans le même ensemble de middleware en raison de la petite quantité dans la phase initiale. À mesure que les clients augmentent leur volume, il est nécessaire de concevoir un plan de fractionnement des données pour prendre en charge le partage des données afin de faire face à la lecture et à l'écriture massives de données ultérieures, ainsi qu'à la pression de la fiabilité.
Décentralisation de la fonction de planification du trafic : la conception des fonctions du composant prend en charge la décentralisation (dépendances centralisées communes : verrous, valeurs de contrôle de flux, tâches de planification, etc.). Une fois le trafic augmenté, le nombre de copies de composants peut être étendu. stratégie d’équilibrage. Rechargement complet du trafic.
Stratégie de contrôle de flux multidimensionnel
Avant que le trafic de la fonction client sur FunctionGraph n'atteigne enfin le moment de l'exécution, il passera par plusieurs liens, et chaque lien peut avoir un trafic dépassant son seuil de transport. Par conséquent, afin de garantir la stabilité de chaque lien, FunctionGraph ajoute de manière défensive différentes stratégies de contrôle de flux sur chaque lien. Les principes de base abordent l'isolation des ressources au niveau de la granularité des fonctions sur l'informatique (processeur), le stockage (disque, disque I/0) et le réseau (connexion http, bande passante).
Le trafic de fonctions est déclenché du côté client et le contrôle de flux de liaison qui s'exécute finalement est illustré à la figure 3.

Figure 3 Contrôle de flux FunctionGraph
Contrôle de flux APIG de passerelle
APIG est l'entrée du trafic de FunctionGraph. Il prend en charge le contrôle total du trafic au niveau de la région et peut être étendu de manière flexible en fonction de l'activité commerciale de la région. Dans le même temps, APIG prend en charge le contrôle du trafic au niveau du client. Lorsqu'un trafic client anormal est détecté, le trafic client peut être rapidement restreint via APIG afin de réduire l'impact de chaque client sur la stabilité du système.
Contrôle des flux métier du système
Contrôle de flux au niveau de l'API
Une fois que le trafic client passe par APIG, il passe du côté système de FunctionGraph. Sur la base du scénario d'échec du contrôle de flux APIG, FunctionGraph construit sa propre stratégie de contrôle de flux. Actuellement, le contrôle de flux au niveau du nœud, le contrôle de flux total de l'API client et le contrôle de flux au niveau des fonctions sont pris en charge. Lorsque le trafic client dépasse la capacité de charge de FunctionGraph, le système le rejette directement et renvoie 429 au client.
Contrôle du flux de ressources système
FunctionGraph est un service logique multi-tenant. Les ressources du plan de contrôle et du plan de données sont partagées par les clients lorsque des attaques malveillantes de clients illégaux provoquent une instabilité du système. FunctionGraph implémente un contrôle du flux client basé sur le nombre de demandes simultanées de ressources partagées, limitant strictement les ressources disponibles pour les clients. De plus, la mise en commun des ressources partagées garantit que la quantité totale de ressources partagées est contrôlable, garantissant ainsi la disponibilité du système. Par exemple : pool de connexions http, pool de mémoire, pool de coroutines.
Contrôle de concurrence : construisez une stratégie de contrôle de flux basée sur la granularité de la fonction FunctionGraph en fonction du nombre de requêtes simultanées. Le temps d'exécution de la fonction client de FunctionGraph a différents types tels que les millisecondes, les secondes, les minutes, les heures, etc. La stratégie conventionnelle de contrôle de flux QPS des requêtes par. le deuxième est traité. Les requêtes qui s'exécutent sur des périodes extrêmement longues présentent des défauts inhérents et ne peuvent pas limiter les ressources partagées du système occupées par les clients en même temps. La stratégie de contrôle basée sur le nombre de concurrence limite strictement le nombre de requêtes en même temps. Si le nombre de requêtes dépasse le nombre, elle est directement rejetée pour protéger les ressources partagées du système.
Pool de connexions http : lors de la création de services à haute concurrence, le maintien raisonnable du nombre de connexions http longues peut minimiser le temps de surcharge des ressources des connexions http, tout en garantissant que le nombre de ressources de connexion http est contrôlable, garantissant ainsi la sécurité du système tout en améliorant les performances du système. L'industrie peut se référer à la réutilisation des connexions http2 et à la mise en œuvre du pool de connexions dans fasthttp. Les principes sont de minimiser le nombre de http et de réutiliser les ressources existantes.
Pool de mémoire : dans les scénarios où les messages de demande et de réponse du client sont particulièrement volumineux et où la concurrence est particulièrement élevée, la mémoire système occupée par unité de temps est importante. Lorsque le seuil est dépassé, cela peut facilement provoquer un débordement de la mémoire système et entraîner le redémarrage du système. . Sur la base de ce scénario, FunctionGraph a ajouté un contrôle unifié du pool de mémoire à l'entrée de la demande et à la sortie de la réponse, il vérifie si le message de demande du client dépasse le seuil pour protéger la mémoire système et la contrôler.
Pool de coroutines : FunctionGraph est construit sur une plate-forme cloud native et utilise le langage go. Si chaque requête utilise une coroutine pour traiter les journaux et les indicateurs, lorsque de grandes requêtes simultanées arrivent, un grand nombre de coroutines seront exécutées simultanément, entraînant une baisse significative des performances globales du système. FunctionGraph introduit le pool de coroutines de go et transforme les tâches de traitement des journaux et des indicateurs en tâches individuelles et les soumet au pool de coroutines. Ensuite, le pool de coroutines les gère de manière uniforme, ce qui atténue considérablement le problème de l'explosion des coroutines.
Contrôle du taux de consommation asynchrone : lorsqu'une fonction asynchrone est appelée, elle sera placée en premier dans Kafka de FunctionGraph. En définissant raisonnablement le taux de consommation Kafka du client, cela garantit que les instances de fonction sont toujours suffisantes et empêche les appels de fonction excessifs d'entraîner l'activation des ressources sous-jacentes. être rapidement consommé.
Contrôle d'instance de fonction
- Quota d'instance client : en limitant le quota total de client, nous empêchons les clients malveillants de consommer toutes les ressources sous-jacentes pour garantir la stabilité du système. Lorsque l'entreprise du client en a vraiment besoin, le quota client peut être rapidement augmenté en demandant un bon de travail.
- Quota d'instance de fonction : en limitant le quota de fonction, il est possible d'empêcher une fonction d'un seul client de consommer toutes les instances du client. Cela peut également empêcher le quota du client de devenir invalide et d'entraîner une consommation importante de ressources sur une courte période de temps. De plus, si l'activité du client implique l'utilisation de middleware tels que des bases de données et Redis, le nombre de connexions middleware du client peut être protégé dans une plage contrôlable grâce à des restrictions de quota d'instances de fonctions.
Capacités efficaces d’élasticité des ressources
Le contrôle de flux est un concept de conception défensive qui réduit le risque de surcharge du système grâce à un blocage précoce. Lorsque les activités normales d'un client augmentent soudainement et nécessitent une grande quantité de ressources, la première chose à résoudre est le problème de l'élasticité des ressources. Dans le but d'assurer le succès de l'activité du client, des stratégies de contrôle des flux peuvent être utilisées pour couvrir les anomalies du système et les prévenir. la propagation des explosions. FunctionGraph prend en charge plusieurs fonctionnalités élastiques telles que l'élasticité rapide des nœuds de cluster, l'élasticité rapide des instances de fonction client et l'élasticité de prédiction intelligente des instances de fonction client, garantissant que FunctionGraph peut toujours être utilisé normalement lorsque l'activité du client augmente soudainement.
Stratégie de nouvelle tentative
En concevant une stratégie de nouvelle tentative avec les avantages appropriés, FunctionGraph peut garantir que la demande du client est finalement exécutée avec succès lorsqu'une exception se produit. Comme le montre la figure 4, la stratégie de nouvelle tentative doit avoir des conditions de terminaison, sinon elle provoquera une tempête de nouvelles tentatives et dépassera plus facilement la limite de charge du système.

Figure 4 : Stratégie de nouvelle tentative
Échec de la nouvelle tentative de demande de fonction
- Requête synchrone : lorsqu'un client demande une exécution et rencontre une erreur système, FunctionGraph transmettra la demande à d'autres clusters et réessayera jusqu'à 3 fois pour garantir que la demande du client peut être exécutée dans d'autres clusters même si elle rencontre des exceptions de cluster occasionnelles.
- Requêtes asynchrones : étant donné que les fonctions asynchrones n'ont pas d'exigences élevées en temps réel, après l'échec de l'exécution de la fonction client, le système peut mettre en œuvre une stratégie de nouvelle tentative plus raffinée pour les demandes ayant échoué. Actuellement, FunctionGraph prend en charge les tentatives d'intervalle exponentielle binaire Lorsqu'une fonction se termine anormalement en raison d'une erreur système, la fonction s'arrête de manière exponentielle selon la méthode 2, 4, 8 et 16. Lorsque l'intervalle revient à 20 minutes, les tentatives suivantes. sera basé sur 20 minutes. Le temps de nouvelle tentative de demande de fonction est effectué à intervalles. Le temps de nouvelle tentative de demande de fonction prend en charge un maximum de 6 heures. Lorsqu'il dépasse, il sera traité comme une demande ayant échoué et renvoyé au client. Grâce à un recul exponentiel binaire, la stabilité des activités des clients peut être garantie au maximum.
Nouvelles tentatives entre services dépendants
- Mécanisme de nouvelle tentative du middleware : en prenant Redis comme exemple, lorsque le système ne parvient pas à lire et à écrire Redis de temps en temps, il se met en veille pendant un certain temps, puis répète les opérations de lecture et d'écriture de Redis, avec un nombre maximum de tentatives de 3. fois.
- Mécanisme de nouvelle tentative de requête http : lorsque des erreurs telles que eof et io timeout se produisent dans une requête http en raison de fluctuations du réseau, elle se met en veille pendant un certain temps et répète l'opération d'envoi http, avec un nombre maximum de tentatives de 3 fois.
cache
La mise en cache peut non seulement accélérer l'accès aux données, mais peut également continuer à utiliser les données mises en cache pour garantir la disponibilité du système en cas de panne des services dépendants. Divisé en catégories fonctionnelles, FunctionGraph doit mettre en cache deux types de composants. Le premier est le middleware et le second est celui des services cloud dépendants. Le système donne la priorité à l'accès aux données mises en cache et actualise en même temps régulièrement les données mises en cache locales. middleware et services cloud dépendants. La méthode est illustrée à la figure 5.
- Données du middleware en cache : FunctionGraph surveille les modifications des données du middleware et les met à jour dans le cache local en temps opportun via la publication et l'abonnement. Lorsque le middleware est anormal, le cache local peut continuer à être utilisé pour maintenir la stabilité du système.
- Mettre en cache les données du service dépendant de la clé : prenez comme exemple le service d'authentification d'identité de Huawei Cloud. FunctionGraph s'appuiera fortement sur IAM. Lorsque le client lance la première demande, le système mettra en cache le jeton localement avec un délai d'expiration de 24 heures. vers le haut, elle ne sera pas affectée. Utilisation du système FunctionGraph. D'autres services cloud clés reposent sur la mise en cache temporaire des données clés dans la mémoire locale.

Figure 5 Mesures de mise en cache de FunctionGraph
fusible
Les mesures ci-dessus peuvent garantir le bon fonctionnement de l'activité du client.Cependant, lorsque l'activité du client est anormale et ne peut pas être récupérée ou que des clients malveillants continuent d'attaquer la plate-forme FunctionGraph, les ressources du système seront gaspillées sur un trafic anormal, occupant les ressources des clients normaux. , et le système peut également échouer. Des erreurs inattendues se produisent après un fonctionnement continu à charge élevée avec un trafic anormal. Pour ce scénario, FunctionGraph a construit sa propre stratégie de disjoncteur basée sur le modèle de volume d'appels de fonction. Comme le montre la figure 6, des disjoncteurs à plusieurs niveaux sont mis en œuvre en fonction du taux de défaillance du volume d'appels pour garantir le bon déroulement des activités des clients et la stabilité du système.

Figure 6 Modèle de stratégie de disjoncteur
isolement
- Isolation métier des fonctions asynchrones : selon la catégorie de requêtes asynchrones, FunctionGraph divise les groupes de consommateurs de Kafka en groupes de consommateurs à déclenchement temporisé, groupes de consommateurs exclusifs, groupes de consommateurs généraux et groupes de consommateurs de nouvelles tentatives de messages asynchrones. Les sujets sont également divisés en catégories homologues de la même manière. . En subdivisant les groupes de consommateurs et les sujets, en isolant les services de déclenchement planifiés des services à fort trafic et en isolant les services normaux des services de demande de nouvelle tentative, les demandes de service client sont garanties avec la plus haute priorité.
- Isolation sécurisée des conteneurs : les conteneurs CCE traditionnels sont isolés en fonction de groupes de contrôle. Lorsque le nombre de clients et le nombre d'appels clients augmentent, des interférences mutuelles entre les clients se produiront occasionnellement. Grâce à des conteneurs sécurisés, une isolation au niveau des machines virtuelles peut être obtenue afin que les services clients n'interfèrent pas les uns avec les autres.
Service multi-tenant logique, une fois qu'il y aura un problème avec la mise à niveau, l'impact sera incontrôlable. FunctionGraph prend en charge les mises à niveau en anneau (réparties en fonction du risque de l'entreprise dans la région), les stratégies de version bleu-vert et de version Canary. L'action de mise à niveau est brièvement décrite en trois étapes :
- Isolation du trafic du cluster avant la mise à niveau : lorsque le FunctionGraph actuel est mis à niveau, la priorité est donnée à l'isolement du trafic du cluster mis à niveau pour garantir qu'aucun nouveau trafic n'entre dans le cluster mis à niveau ;
- Migration du trafic et sortie en douceur du cluster avant la mise à niveau : migrez le trafic vers d'autres clusters et effectuez l'opération de mise à niveau après la fin de la demande de mise à niveau du cluster.
- Le cluster mis à niveau prend en charge la migration du trafic par client : une fois la mise à niveau terminée, le trafic des clients de test d'accès à distance sera transféré vers le cluster mis à niveau. Une fois tous les cas d'utilisation de test d'accès à distance exécutés avec succès, le trafic des clients officiels sera transféré. emménagé.
Lorsqu'une erreur survient dans FunctionGraph qui ne peut être évitée par le système, notre solution consiste à créer des capacités de surveillance et d'alarme pour découvrir rapidement les points anormaux, récupérer des pannes au niveau infime et minimiser le temps d'interruption du système. En tant que dernière ligne de défense pour la haute disponibilité du système, la capacité à détecter rapidement les problèmes est cruciale. FunctionGraph a construit plusieurs points d'alarme autour des chemins critiques de l'entreprise. Comme le montre le tableau 2.
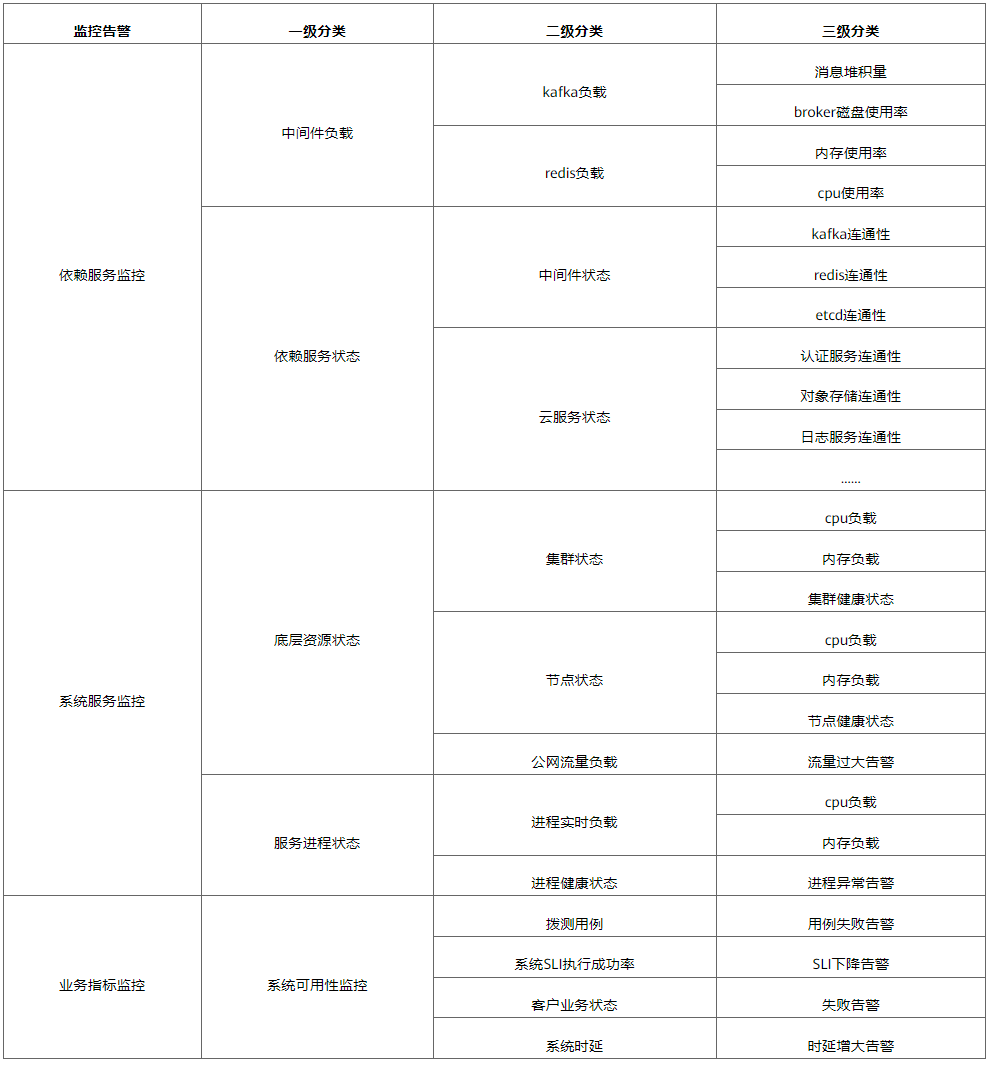
Tableau 2 : Surveillance des alarmes créées par FunctionGraph
Spécifications du processusCertaines des mesures ci-dessus résolvent le problème de disponibilité du système dès le niveau de la conception technique. FunctionGraph a également formé un ensemble de règles et de réglementations à partir du processus. Lorsque la technologie ne peut pas résoudre le problème à court terme, le risque peut être rapidement éliminé par l'humain. intervention. Plus précisément, il existe les spécifications de fonctionnement de l'équipe suivantes :
- Processus de salle de guerre interne : lorsqu'elle rencontre un problème d'urgence sur le réseau en direct, l'équipe organise rapidement les rôles clés au sein de l'équipe pour restaurer la panne du réseau en direct dès que possible ;
- Processus d'examen des modifications internes : une fois que la version du système est immergée dans l'environnement de test et vérifiée comme ne présentant aucun problème, avant la modification officielle du réseau en direct, une directive de modification doit être rédigée pour identifier les points de fonction modifiés et les points de risque. Seulement après. l'évaluation des rôles clés de l'équipe est autorisée à être mise sur le réseau en direct. Réduire les anomalies causées par les changements humains grâce à une gestion de processus standard ;
- Analyse et examen réguliers des problèmes de réseau en direct : évaluation hebdomadaire en direct des risques du réseau, analyse et examen des alarmes, identification des lacunes dans la conception du système à travers les problèmes, tirer des conclusions à partir d'une instance et optimiser le système.
Reprise après sinistre client
Même les services cloud les plus avancés du secteur ne peuvent pas promettre un SLA à 100 % au monde extérieur. Par conséquent, lorsque le système lui-même ou même une intervention humaine ne peut pas restaurer rapidement l’état du système dans un court laps de temps, le plan de reprise après sinistre conçu conjointement avec le client devient crucial. Généralement, FunctionGraph travaillera avec les clients pour concevoir un plan de reprise après sinistre pour le client. Lorsque le système continue de rencontrer des exceptions, le client doit réessayer pour les retours. Lorsque le nombre d'échecs atteint un certain niveau, il est nécessaire d'envisager de déclencher un retour. disjoncteur côté client pour limiter l’impact sur les systèmes en aval tout en passant rapidement aux options d’évacuation.
Résumer
Lorsque FunctionGraph réalise une conception haute disponibilité, il suit généralement les principes suivants de « redondance + basculement ». Tout en répondant aux besoins de base de l'entreprise, il garantit la stabilité du système puis améliore progressivement l'architecture.
" Redondance + Failover " inclut les fonctionnalités suivantes :
Architecture de reprise après sinistre : mode multi-cluster, mode actif-veille
Protection contre les surcharges : contrôle de flux, écrêtage asynchrone, mutualisation des ressources
Gestion des pannes : réessai, cache, isolation, downgrade, disjoncteur
Version en niveaux de gris : streaming en niveaux de gris et sortie gracieuse
Reprise après sinistre client : nouvelle tentative, disjoncteur, évasion
À l'avenir, FunctionGraph continuera à créer davantage de services disponibles à partir des dimensions de la conception, de la surveillance et des processus du système. Comme le montre la figure 7, nous pouvons découvrir rapidement les problèmes en développant des capacités de surveillance, résoudre rapidement les problèmes grâce à une conception de fiabilité, réduire les problèmes grâce aux spécifications de processus, améliorer continuellement les capacités de disponibilité du système et fournir aux clients des services SLA plus élevés.

Figure 7 : Pratique d'itération de haute disponibilité FunctionGraph
les références
[1] Définition haute disponibilité : https://zh.wikipedia.org/zh-hans/%E9%AB%98%E5%8F%AF%E7%94%A8%E6%80%A7
[2]Définition SLA : https://zh.wikipedia.org/zh-hans/%E6%9C%8D%E5%8A%A1%E7%BA%A7%E5%88%AB%E5%8D%8F %E8%AE%AE
Auteur : Un relecteur : Jiulang, Wenruo