
Auteurs : Yue Yang, Chen Dequan, Liu Jingna
Beijing Yushi Technology Co., Ltd. a été créée en juin 2023. Yushi Technology se positionne comme « l'entrée thématique dans l'ère de l'investissement intelligent ». À l'ère du changement, où le secteur de la gestion d'actifs passe d'un secteur centré sur l'institution à un secteur centré sur l'utilisateur. , il construit un moteur d'investissement thématique, permettant une intégration inclusive des investissements et créant un « nouveau pont » avec les investisseurs et les institutions de gestion d'actifs comme thème et noyau, et l'interaction en langage naturel comme entrée.

Yushi Technology traite en moyenne 10 000 informations financières chaque jour. En collectant des informations, en découvrant les tendances émergentes et en évaluant les tournants des tendances, elle a formé un système d'investissement thématique qui comprend plus de 10 super thèmes, plus de 40 thèmes d'investissement et plus de 200. sous-thèmes ; actuellement 10 Un client de référence dans le secteur, fournissant des services via une API de données et des rapports hebdomadaires et mensuels. À l'heure actuelle, un total d'environ 500 rapports et près de 1 000 articles d'analyse des comptes publics ont été publiés. À l'avenir, nous réaliserons un agent d'investissement thématique pour des milliers de personnes grâce à l'exploration en temps réel des intentions des utilisateurs et aux calculs thématiques.
Fonctionnalités de la plateforme et défis rencontrés
Les produits de Yushi Technology sont des produits typiques de services d'information. Une fois que la plateforme a collecté des informations sur le secteur financier via plusieurs canaux et les a stockées localement, elle démarre les processus de traitement pertinents selon le cadre d'analyse des investissements et forme enfin des produits de données financières pour fournir des services externes. Les fonctions commerciales de la plateforme et les exigences en matière de ressources système présentent les caractéristiques suivantes :
1. Grande quantité de données et exigences de stockage diverses
a) Les données de base de la plateforme sont principalement des données non structurées. La quantité totale de données à chaque étape de traitement, y compris les données sources, les données intermédiaires et les données de résultat, est au niveau de la To, bien que cette ampleur soit un jeu d'enfant pour le stockage de fichiers ou d'objets. , Cependant, il existe toujours une certaine pression sur le stockage d'analyse/index.
b) Le stockage de données non structurées nécessite la prise en charge de plusieurs interfaces d'accès face à différents processus de traitement, notamment les fichiers, les objets, les bases de données OLAP, les systèmes de cache et d'index, etc.
c) Le traitement des informations financières doit répondre à des exigences de rapidité. Il existe donc également des exigences élevées en matière de performances d'interrogation des systèmes de stockage analytique.
2. Le processus de traitement des données est complexe et changeant
a) Le processus de traitement des données est l'incarnation de la stratégie d'analyse des investissements dans le système et constitue le cœur de l'ensemble de la plateforme. La logique de traitement des nœuds clés dans ces processus ne peut pas être implémentée via des fonctions de plate-forme standardisées. Elle doit être publiée sur la plate-forme via du code Java/Python et peut être appelée de manière flexible par le processus.
b) Afin de répondre aux exigences de la logique métier, il existe des exigences fréquentes en matière de flux de données et d'interaction entre les nœuds de traitement dans le processus de traitement, entre les nœuds et les interfaces de stockage de données, et même entre les processus.
c) Les stratégies d'investissement doivent être ajustées en temps opportun en réponse aux changements du marché et aux besoins des clients. Les processus de traitement des données et même la logique de traitement de base doivent être ajustés simultanément en fonction des stratégies commerciales.
d) En raison de la complexité de la logique de traitement des données, une fois le développement mis en ligne, il est souvent nécessaire de suivre et d'analyser le traitement de données spécifiques dans l'environnement de production, et il est nécessaire de pouvoir visualiser facilement les informations d'exécution détaillées.
3. Il existe des hauts et des bas évidents dans la demande de ressources de plateforme.
a) Il y aura des pics fixes pendant toute la journée de fonctionnement de la plateforme, y compris la période pendant laquelle les informations sont intensément entrantes et traitées, et la période pendant laquelle le personnel commercial effectue des requêtes intensives. Parallèlement, il existe également des pics d’accès en début de semaine et en début de mois.
b) Les périodes de pointe nécessitent des taux d'expansion des performances de traitement plus élevés, et différents types de pointes ont des exigences différentes en matière de ressources système. Une planification préalable des actions d'expansion est requise pour différents scénarios.
4. Exigences de fiabilité et de rapidité
a) Les informations continueront à être générées et à circuler dans la plateforme 24 heures sur 24. Elles doivent être traitées quelques minutes après leur entrée sur la plateforme et entrer dans le pool de données de service externe. Par conséquent, la plateforme doit être capable de traiter de manière stable. et en continu, et se développe automatiquement en cas de pic de trafic pour éviter l'arriéré de données. S'il y a des omissions ou des erreurs dans le processus de traitement, celui-ci doit pouvoir réessayer automatiquement.
b) Les systèmes externes liés au service servent de portail d'accès pour les utilisateurs finaux et ont certaines exigences en matière de continuité de service.
Compte tenu de la conception des fonctions de la plate-forme ci-dessus, Yushi Technology a les exigences suivantes en matière d'infrastructure informatique, y compris IaaS/PaaS :
1. Divers types de stockage, accès mutuel fluide entre les systèmes, prise en charge de plusieurs types de stockage, accès mutuel transparent entre différents systèmes de stockage, utilisation quotidienne, gestion et transfert de données peuvent être configurés via l'interface graphique.
2. Processus de traitement des données simple et flexible
a) Fournir une entrée de gestion des flux de traitement unifiée et prendre en charge la conception graphique des processus.
b) Prend en charge l'utilisation de langages de développement courants pour mettre en œuvre une logique métier complexe et peut être intégré de manière transparente dans les processus.
c) Entre les nœuds de processus, l'interface de processus et de stockage de données, un contrôle interactif complexe peut être réalisé entre les processus.
d) Le processus d'exécution peut être suivi et analysé, et des données ou processus spécifiques peuvent être facilement suivis et analysés.
3. Expansion et contraction automatiques du système
a) La capacité du système du processus de traitement des données peut être automatiquement étendue et réduite en fonction des pics et des creux de trafic, et son expansion et sa contraction peuvent être traitées selon certains scripts basés sur les dépendances inter-systèmes.
b) Les autres systèmes d'entreprise doivent s'ajuster automatiquement en fonction des pics et des creux d'accès des entreprises.
4. Améliorer la qualité et l'efficacité globales des travaux de R&D
a) Réduire le coût direct des ressources informatiques et les coûts de gestion tout en garantissant la fiabilité du système. b) Améliorer l'efficacité du processus global CI/CD ;
Workflow cloud CloudFlow + Function Compute FC aide à améliorer le traitement des données complexes
Yushi Technology est une entreprise de technologie de données née sous la vague du cloud natif. Au début de sa création, elle a décidé d'adopter la technologie cloud native pour améliorer la qualité et l'efficacité globales du travail informatique et optimiser les coûts.
Les défis rencontrés dans l'amélioration de la qualité et de l'efficacité se concentrent principalement sur les processus de traitement des données. Par conséquent, en plus d'utiliser des outils réguliers d'amélioration de l'efficacité CI/CD tels que Alibaba Cloud et le déploiement conteneurisé, après inspection par l'équipe, nous avons finalement choisi le workflow cloud CloudFlow et les fonctions Calculate. FC Deux nouveaux produits. L'objectif est de résoudre le besoin de gérer des processus de données complexes via le workflow cloud CloudFlow et d'utiliser le calcul fonctionnel FC pour résoudre le problème de certains nœuds traitant une logique métier complexe pendant le fonctionnement du workflow cloud CloudFlow. peut parfaitement résoudre le besoin d’une mise à l’échelle élastique.
Le diagramme de flux de données est le suivant :
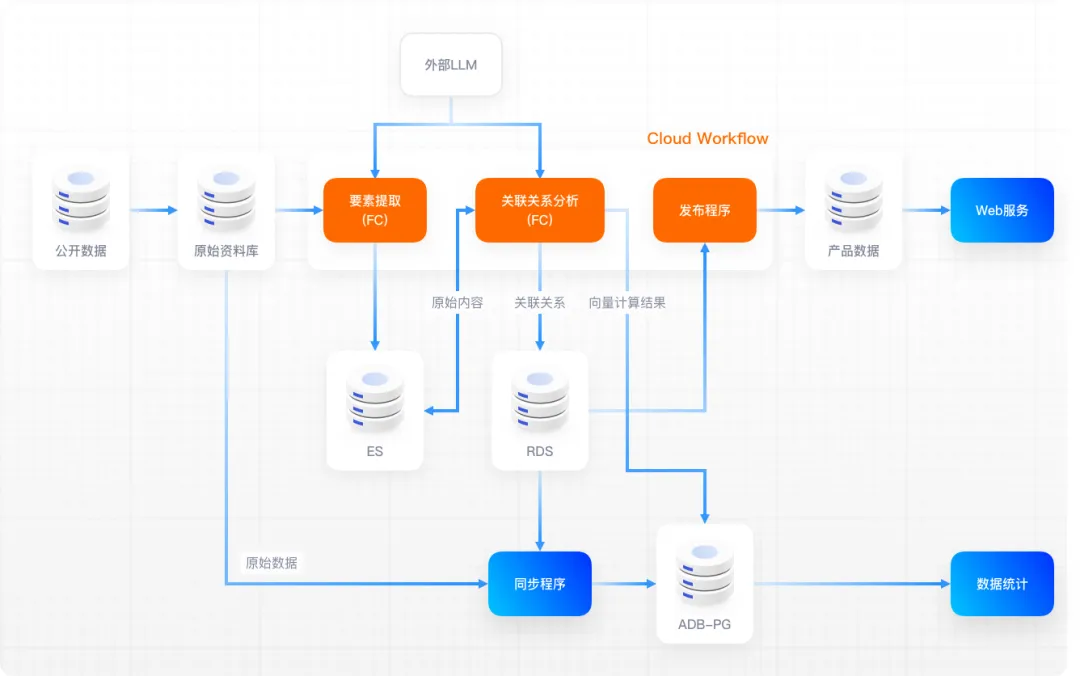
Grâce à la pratique, il a été constaté que pour les flux de travail courants, l'utilisation de CloudFlow pour développer des interfaces Web réduit la charge de travail de développement d'environ la moitié par rapport à l'utilisation des frameworks d'application Java traditionnels. Dans le même temps, puisque le lien de publication en ligne est omis, l'efficacité de la mise en ligne est réduite. le débogage a également été amélioré, l'efficacité d'utilisation du suivi et du débogage basés sur la console Web a également été considérablement améliorée après une période d'adaptation.
Au cours des six mois d'utilisation, Yushi Technology a développé près de 20 workflows, qui appellent des dizaines de fonctions et s'exécutent des centaines de milliers de fois. Bien qu'il n'y ait qu'un seul ingénieur responsable du flux de travail, il est toujours possible de maintenir une moyenne de lancement d'un nouveau flux de travail toutes les deux semaines environ. Pour les ingénieurs, à l'exception des besoins occasionnels de suivi et de débogage en ligne, il n'est fondamentalement pas nécessaire de se soucier de l'état d'exécution du flux de travail une fois qu'il a été mis en ligne, ce qui permet de véritablement « libérer et oublier ».
Perspectives
En tant que start-up centrée sur les données à l'ère des grands modèles, nous approfondirons la possibilité de combiner des plates-formes de données avec des capacités de grands modèles. Grâce aux capacités d'innovation en matière d'infrastructure fournies par Alibaba, nous fournirons à nos clients finaux des capacités et des capacités plus fortes. plus d'itérations. Produits de données rapides.
J'ai décidé d'abandonner les logiciels industriels open source. OGG 1.0 est sorti, Huawei a contribué à tout le code source. Ubuntu 24.04 LTS a été officiellement publié. L'équipe de Google Python Foundation a été tuée par la "montagne de merde de code" . ". Fedora Linux 40 a été officiellement lancé. Une société de jeux bien connue a publié de nouvelles réglementations : les cadeaux de mariage des employés ne doivent pas dépasser 100 000 yuans. China Unicom lance la première version chinoise Llama3 8B au monde du modèle open source. Pinduoduo est condamné à compenser 5 millions de yuans pour concurrence déloyale Méthode de saisie dans le cloud domestique - seul Huawei n'a aucun problème de sécurité de téléchargement de données dans le cloud.