
Tout le monde est invité à nous mettre en vedette sur GitHub :
Système d'apprentissage causal distribué à lien complet OpenASCE : https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
Grand graphe de connaissances basé sur un modèle OpenSPG : https://github.com/OpenSPG/openspg
Système d'apprentissage de graphes à grande échelle OpenAGL : https://github.com/TuGraph-family/TuGraph-AntGraphLearning
En moins de 5 ans, la technologie des grands modèles et des Transformers a presque complètement changé le domaine du traitement du langage naturel et a commencé à révolutionner des domaines tels que la vision par ordinateur et la biologie computationnelle. Le Dr Sebastian Raschka se concentre sur les articles de recherche universitaires et a préparé une liste de lectures d'introduction pour les chercheurs et les praticiens de l'apprentissage automatique. Après l'avoir lue dans l'ordre, vous pouvez vraiment vous lancer dans le domaine actuel de la technologie des grands modèles.
Bien entendu, le Dr Sebastian Raschka a également mentionné qu’il existe de nombreuses autres ressources utiles, telles que :
- Jay Alammar的《Transformateur illustré》;
- Articles de blog plus techniques par Lilian Weng ;
- Tous les catalogues et généalogie des Transformers organisés par Xavier Amatriain ;
- Une implémentation en code minimal d'un modèle de langage génératif écrit à des fins éducatives par Andrej Karpathy ;
- et une série de conférences et un chapitre de livre de l'auteur de cet article.
Comprendre l'architecture et les tâches principales
Si vous êtes nouveau dans les Transformers/grands modèles, il est plus logique de repartir de zéro.
1. Traduction automatique neuronale par apprentissage conjoint pour aligner et traduire (2014)
Auteur: Bahdanau, Cho Wa Bengio
Lien papier : https://arxiv.org/abs/1409.0473
Si vous avez quelques minutes à perdre, je vous recommande de commencer par cet article. Cet article présente un mécanisme d'attention aux réseaux de neurones récurrents (RNN) pour améliorer les capacités de modélisation de longues séquences. Cela permet aux RNN de traduire des phrases plus longues avec plus de précision, ce qui était la motivation derrière le développement de l'architecture originale du Transformer.
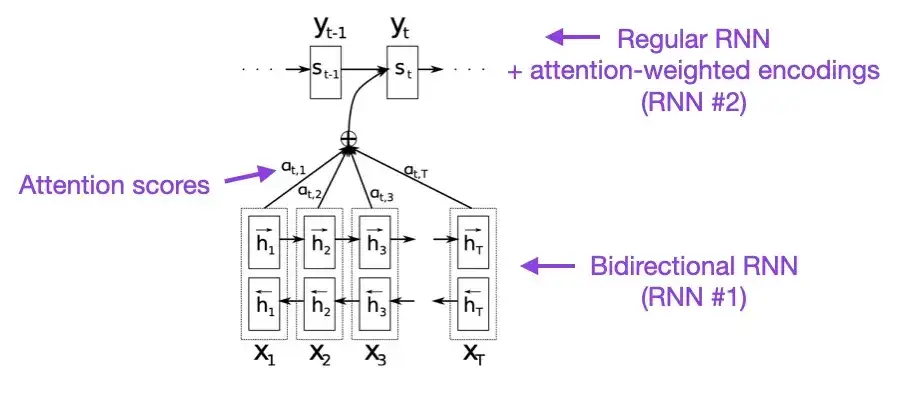
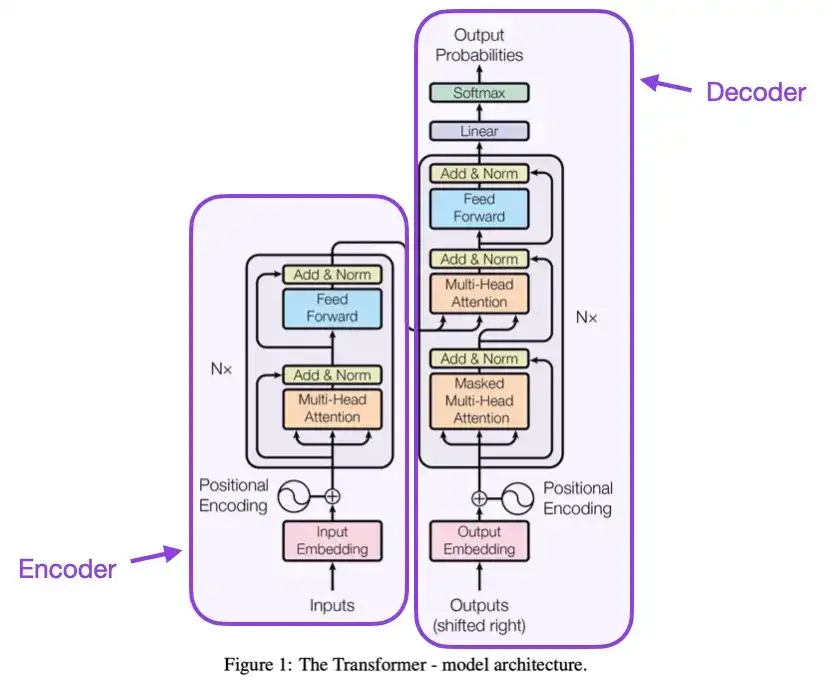
2. L'attention est tout ce dont vous avez besoin (2017)
Crédits : Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser et Polosukhin
Lien papier : https://arxiv.org/abs/1706.03762
Cet article présente l'architecture originale du Transformer, qui se compose de deux parties : un encodeur et un décodeur. Ces deux parties deviendront plus tard des modules indépendants pour explication. En outre, cet article a également introduit des concepts tels que la mise à l'échelle des mécanismes d'attention des produits scalaires, les blocs d'attention multi-têtes et le codage d'entrée positionnel, qui constituent toujours le fondement des modèles Transformer modernes.
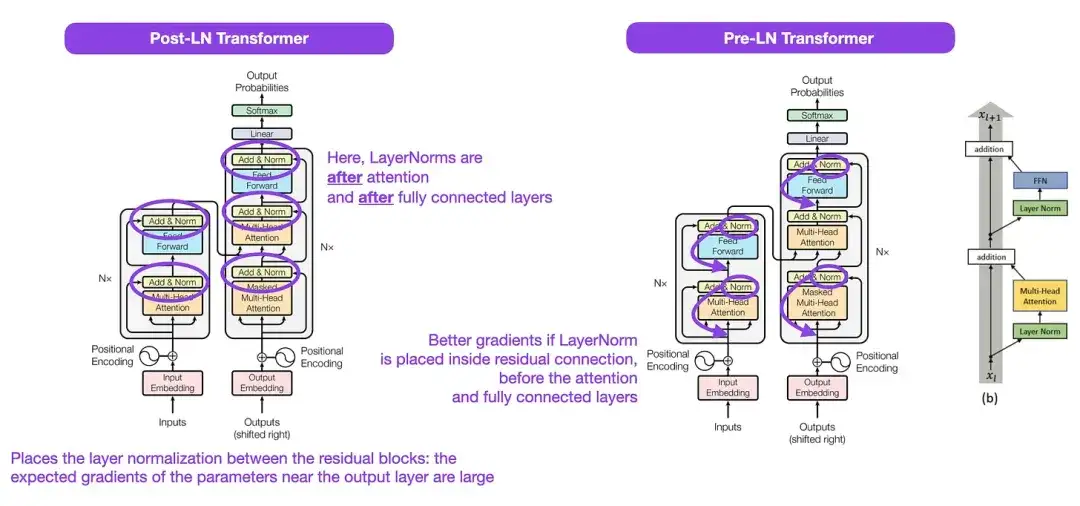
3. Sur la normalisation des couches dans l'architecture du transformateur __ (2020)
Auteurs : Yang, He, K Zheng, S Zheng, Xing, Zhang, Lan, Wang, Liu
Lien papier : https://arxiv.org/abs/2002.04745
Bien que la structure originale du Transformer présentée dans la figure ci-dessus soit un très bon résumé de l'architecture originale du codeur-décodeur, la position de LayerNorm dans la figure a été controversée. Par exemple, le diagramme de structure de Transformer dans « L'attention est tout ce dont vous avez besoin » place LayerNorm entre les blocs résiduels, ce qui est incompatible avec l'implémentation du code officiel (mis à jour) accompagnant le document Transformer d'origine. La variante présentée dans l'image « L'attention est tout ce dont vous avez besoin » s'appelle Post-LN Transformer, et l'implémentation du code mis à jour utilise la variante Pre-LN par défaut.
Dans l'article « Normalisation des couches dans l'architecture du transformateur », il est souligné que Pre-LN fonctionne mieux et peut résoudre le problème du gradient. Comme indiqué ci-dessous, de nombreuses architectures adoptent cette approche dans la pratique, mais cela peut conduire à un effondrement de la représentation. Par conséquent, tandis que la discussion sur l'opportunité d'utiliser Post-LN ou Pre-LN se poursuit, un nouvel article « ResiDual : Transformer with Dual Residual Connections » ( https://arxiv.org/abs/2304.14802 ) propose d'utiliser les deux avantages ; son efficacité dans la pratique reste à voir.
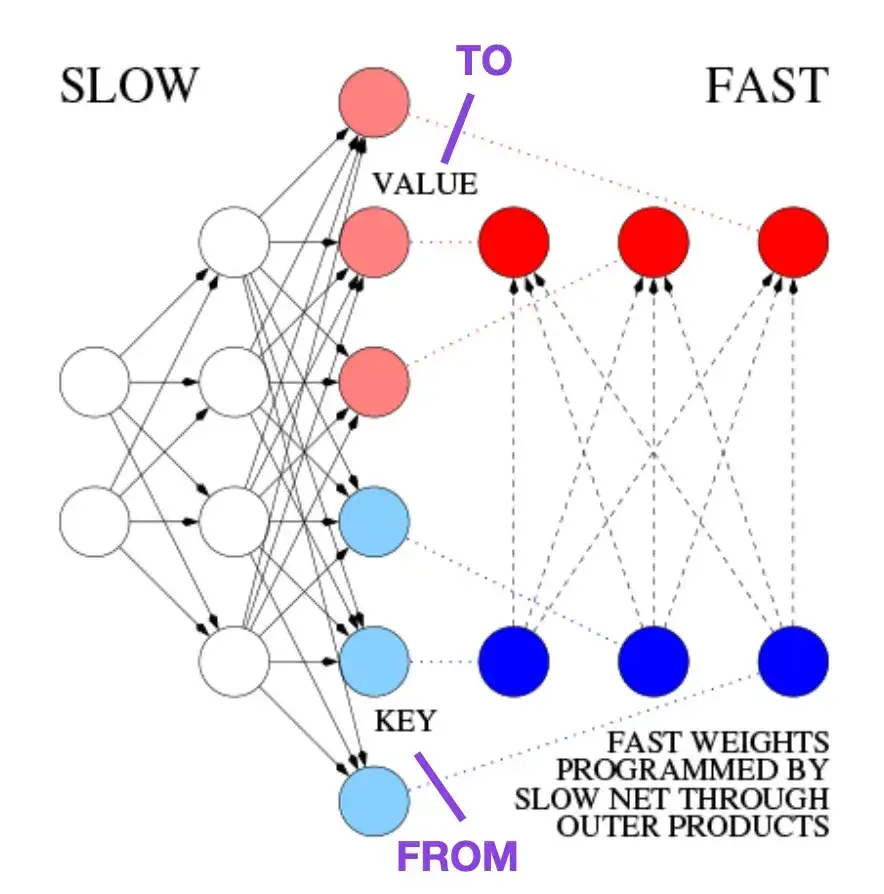
4. Apprendre à contrôler les mémoires à poids rapide : une alternative aux réseaux de neurones récurrents dynamiques __ (1991)
Auteur : Schmidhuber
Lien papier :
Cet article est recommandé aux lecteurs intéressés par les anecdotes historiques et les premières technologies similaires à l'architecture moderne du Transformer. Par exemple, en 1991, environ 25 ans avant l'article original de Transformer, Attention Is All You Need , Juergen Schmidhuber a proposé un programmeur de poids rapide (FWP) comme alternative aux réseaux neuronaux récurrents. La méthode FWP implique un réseau neuronal à action directe qui apprend lentement, via une descente de gradient, à programmer les changements de poids rapides d'un autre réseau neuronal. L'analogie avec un Transformer moderne est expliquée dans l'article de blog suivant :
Dans la terminologie actuelle de Transformer, FROM et TO sont appelés respectivement clés et valeurs. L'ENTRÉE utilisée par les réseaux rapides est appelée une requête. Essentiellement, la requête est traitée via une matrice de poids rapide, qui est la somme des produits externes des clés et des valeurs (en ignorant la normalisation et la projection). Étant donné que toutes les opérations des deux réseaux sont différenciables, nous obtenons un contrôle actif différenciable de bout en bout des changements de poids rapides grâce à l'ajout de produits externes ou de produits tensoriels de second ordre. Par conséquent, le réseau lent peut être appris via une descente de gradient, modifiant rapidement le réseau rapide pendant le traitement de la séquence. Ceci est mathématiquement équivalent (à l'exception de la normalisation) à ce qui est devenu connu sous le nom de transformateur d'auto-attention linéaire (ou transformateur linéaire).
Comme mentionné dans l'extrait du billet de blog ci-dessus, cette approche est désormais connue sous le nom de « Transformateur linéaire » ou « Transformateur avec auto-attention linéarisée ». Par la suite, l'équivalence entre l'attention personnelle linéarisée et les programmeurs de poids rapides des années 1990 a été clairement démontrée dans l'article de 2021 « Les transformateurs linéaires sont des programmeurs de poids secrètement rapides ».
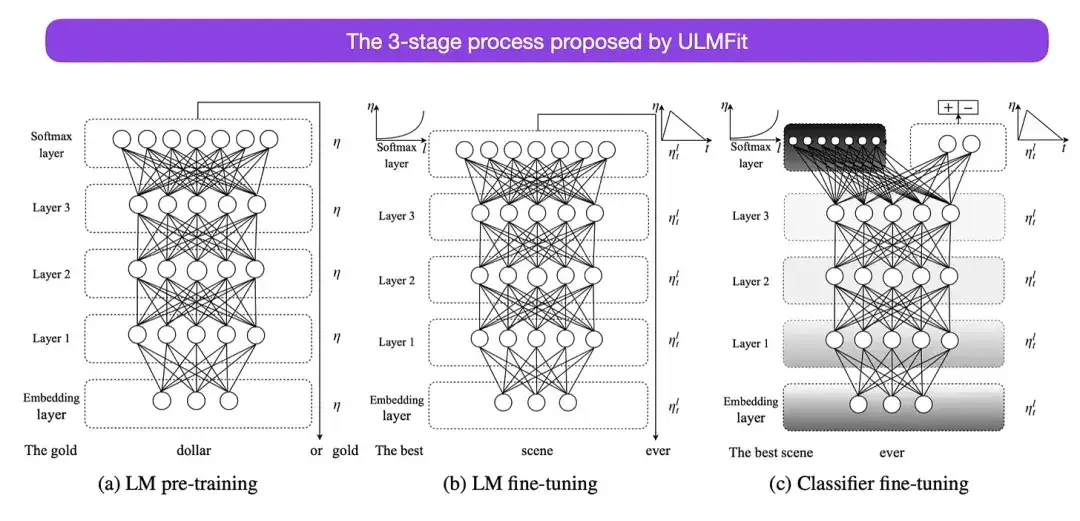
5. Affinement du modèle de langage universel pour la classification de texte (2018)
Auteur ; Howard, Ruder
Adresse papier : https://arxiv.org/abs/1801.06146
C'est un article très intéressant d'un point de vue historique. Il a été écrit un an après la sortie de "Attention Is All You Need", mais il n'impliquait pas Transformer, mais se concentrait sur les réseaux de neurones récurrents. Cependant, il mérite toujours l'attention car il propose efficacement des modèles de langage pré-entraînés et un apprentissage par transfert pour les tâches en aval. Bien que l’apprentissage par transfert soit bien établi dans le domaine de la vision par ordinateur, il n’est pas encore devenu populaire dans le traitement du langage naturel (NLP). ULMFit est l'un des premiers articles à démontrer des modèles de langage pré-entraînés et à les affiner pour des tâches spécifiques, ce qui aboutit à des résultats de pointe dans de nombreuses tâches de PNL.
Le processus en trois étapes d'ajustement des modèles de langage proposé par ULMFit est le suivant :
- Former un modèle de langage sur un grand corpus de texte ;
- Affiner ce modèle de langage pré-entraîné sur des données spécifiques à une tâche pour l'adapter au style et au vocabulaire du texte spécifique ;
- Évitez les oublis catastrophiques en dégelant progressivement les couches tout en affinant le classificateur sur les données spécifiques à la tâche.
Cette méthode - former d'abord un modèle de langage sur un grand corpus, puis l'affiner aux tâches en aval - est la méthode de base des modèles basés sur Transformer et des modèles de base (tels que BERT, GPT-2/3/4, RoBERTa, etc.). Cependant, l'élément clé d'ULMFit, le dégel progressif, n'est généralement pas effectué de manière routinière lors de l'exploitation réelle de l'architecture du convertisseur, et généralement toutes les couches sont affinées en même temps.
6. BERT : Pré-formation de transformateurs bidirectionnels profonds pour la compréhension du langage ****(2018)
Lire : Devlin, Chang, Lee, Toutanova
Lien papier : https://arxiv.org/abs/1810.04805
Selon l'architecture originale de Transformer, la recherche sur les modèles de langage à grande échelle a commencé à diverger dans deux directions : les Transformers basés sur des encodeurs pour les tâches de modélisation prédictive (telles que la classification de texte) et les tâches de modélisation générative (telles que la traduction, la synthèse et le décodage). Transformateur de style pour d'autres formulaires de création de texte).
L'article BERT susmentionné a introduit les concepts originaux de modélisation du langage masqué et de prédiction de la phrase suivante, et il reste l'architecture de style encodeur la plus influente. Si cette branche de recherche vous intéresse, je vous recommande de continuer à vous renseigner sur RoBERTa, qui simplifie l'objectif de pré-formation en supprimant la tâche de prédiction de phrase suivante.
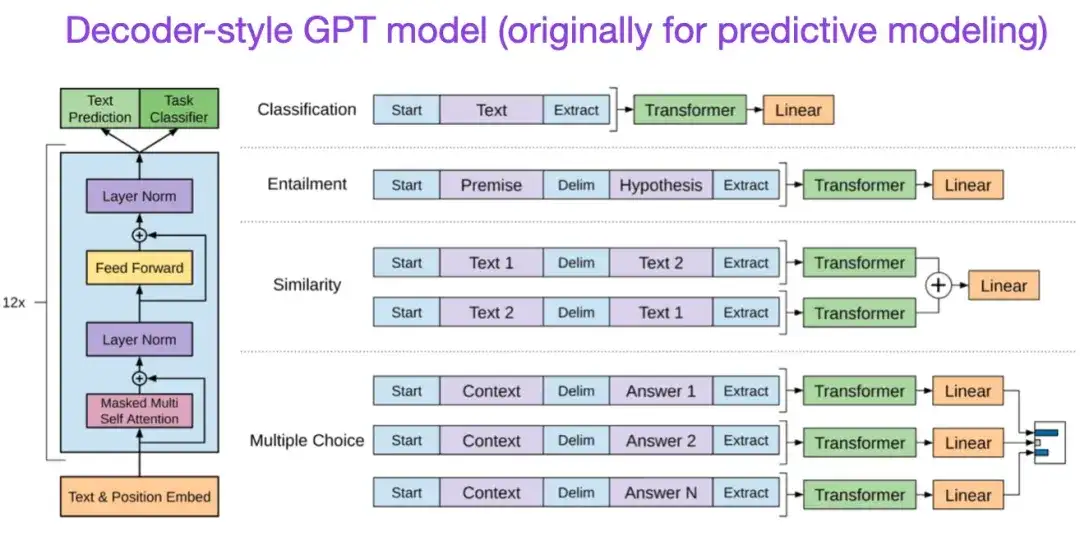
** 7. Améliorer la compréhension du langage grâce à la pré-formation générative (2018)** Auteur : Radford et Narasimhan Adresse de l'article :
L'article GPT original présentait l'architecture populaire de style décodeur et la pré-formation via la prédiction du mot suivant. Alors que BERT peut être considéré comme un transformateur bidirectionnel en raison de son objectif de pré-formation de modèle de langage masqué, GPT est un modèle autorégressif unidirectionnel. Bien que les intégrations GPT puissent également être utilisées pour la classification, les méthodes GPT sont au cœur des grands modèles de langage (LLM) les plus influents d'aujourd'hui, tels que ChatGPT.
Si cette direction de recherche vous intéresse, je vous recommande de continuer à en apprendre davantage sur les articles liés au GPT-2 et au GPT-3. Ces deux articles démontrent que les LLM peuvent réaliser un apprentissage sans ou avec quelques coups, et mettent en évidence les capacités émergentes des LLM. GPT-3 est toujours le modèle de base et de base le plus couramment utilisé pour la formation LLM actuelle. La technologie InstructGPT qui a donné naissance à ChatGPT sera présentée plus tard dans une entrée distincte.
Articles liés à GPT2 : https://www.semanticscholar.org/paper/Language-Models-are-Unsupervised-Multitask-Learners-Radford-Wu/9405cc0d6169988371b2755e573cc28650d14dfe
Articles liés à GPT3 : https://arxiv.org/abs/2005.14165
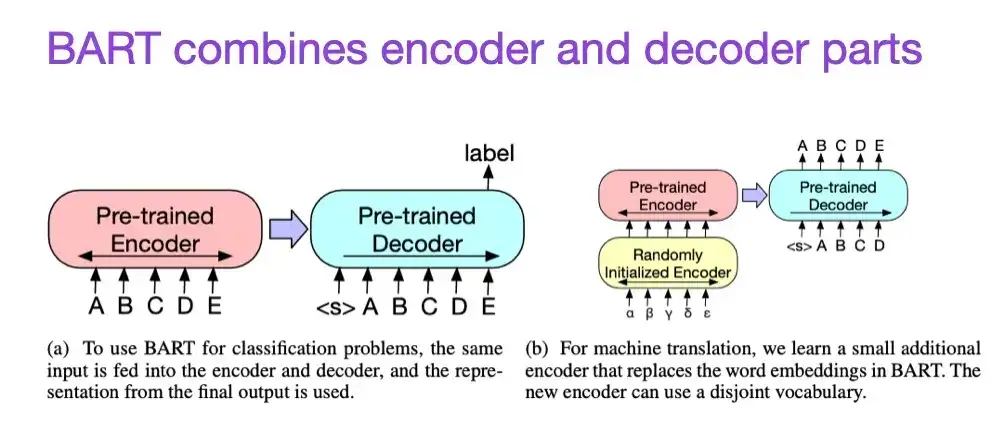
8. BART : Pré-formation au débruitage séquence à séquence pour la génération, la traduction et la compréhension du langage naturel (2019)
Lire : Lewis, Liu, Goyal, Ghazvininejad, Mohamed, Levy, Stoyanov, Zettlemoyer
Lien papier : https://arxiv.org/abs/1910.13461 .
Comme mentionné précédemment, les grands modèles linguistiques (LLM) de type encodeur de type BERT sont généralement mieux adaptés aux tâches de modélisation prédictive, tandis que les LLM de style décodeur de type GPT sont plus efficaces pour générer du texte. Afin de combiner le meilleur des deux mondes, l'article BART mentionné ci-dessus combine les parties codeur et décodeur (ce qui est similaire à la structure originale du Transformer présentée dans le deuxième article).
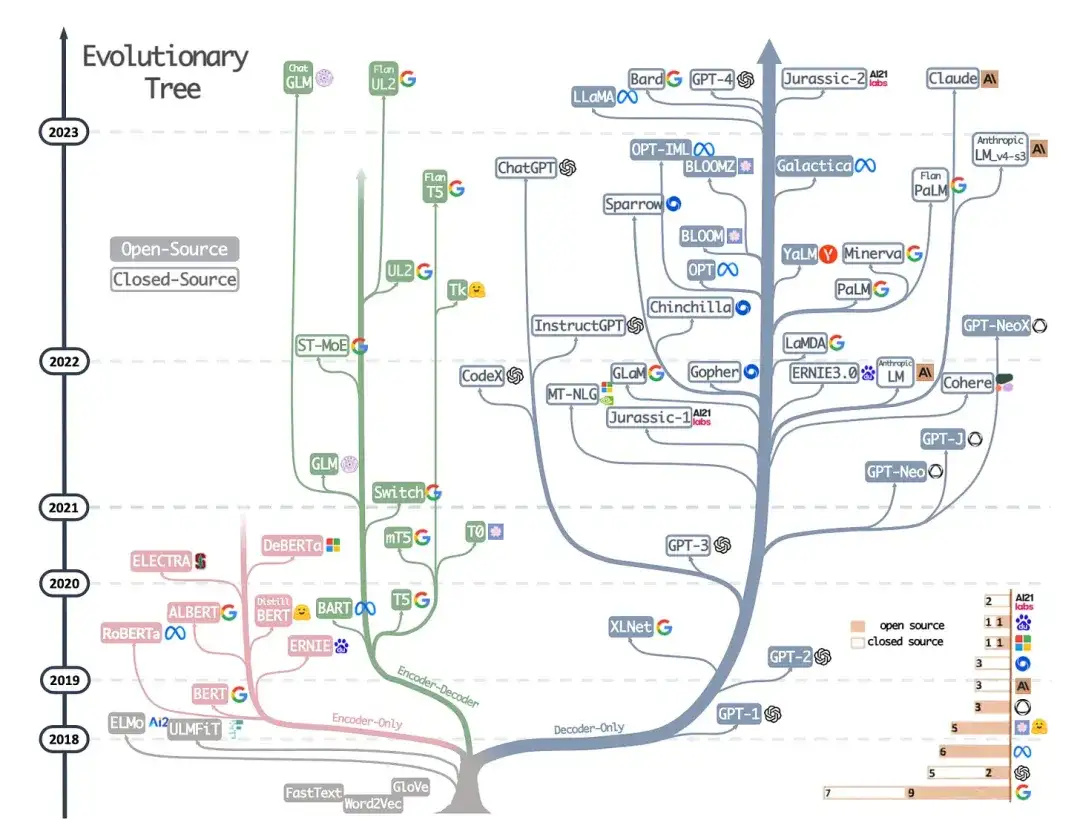
9. Exploiter la puissance des LLM en pratique : une enquête sur ChatGPT et au-delà (2023)
Auteurs : Yang, Jin, Tang, Han, Feng, Jiang, Yin, Hu,
Lien papier : https://arxiv.org/abs/2304.13712
Il ne s’agit pas d’un document de recherche, mais c’est probablement le meilleur article de présentation de l’architecture à ce jour, et il montre de manière vivante comment les différentes architectures ont évolué. Cependant, en plus de discuter des modèles de langage masqués de style BERT (encodeurs) et des modèles de langage autorégressifs de style GPT (décodeurs), il fournit également des discussions et des conseils utiles sur la pré-formation et le réglage fin des données.
Faire évoluer les lois et améliorer l’efficacité
Si vous souhaitez en savoir plus sur les différentes techniques permettant d'améliorer l'efficacité des transformateurs, je vous recommande de lire l'article de 2020 « Efficient Transformers : A Survey » et l'article de 2023 « A Survey on Efficient Training of Transformers ». De plus, voici quelques articles que j’ai trouvés particulièrement intéressants et qui méritent d’être lus.
- 《Transformateurs efficaces : une enquête》 :
https://arxiv.org/abs/2009.06732
- 《Une enquête sur la formation efficace des transformateurs》:
https://arxiv.org/abs/2302.01107
10. FlashAttention : Attention exacte rapide et économe en mémoire avec IO-Awareness (2022)
Auteurs : Dao, Fu, Ermon, Rudra, Ré
Lien papier : https://arxiv.org/abs/2205.14135 .
Bien que la plupart des articles de Transformer ne prennent pas la peine de remplacer le mécanisme de produit scalaire mis à l'échelle d'origine pour obtenir une attention personnelle, le seul mécanisme que je vois cité le plus récemment est FlashAttention.
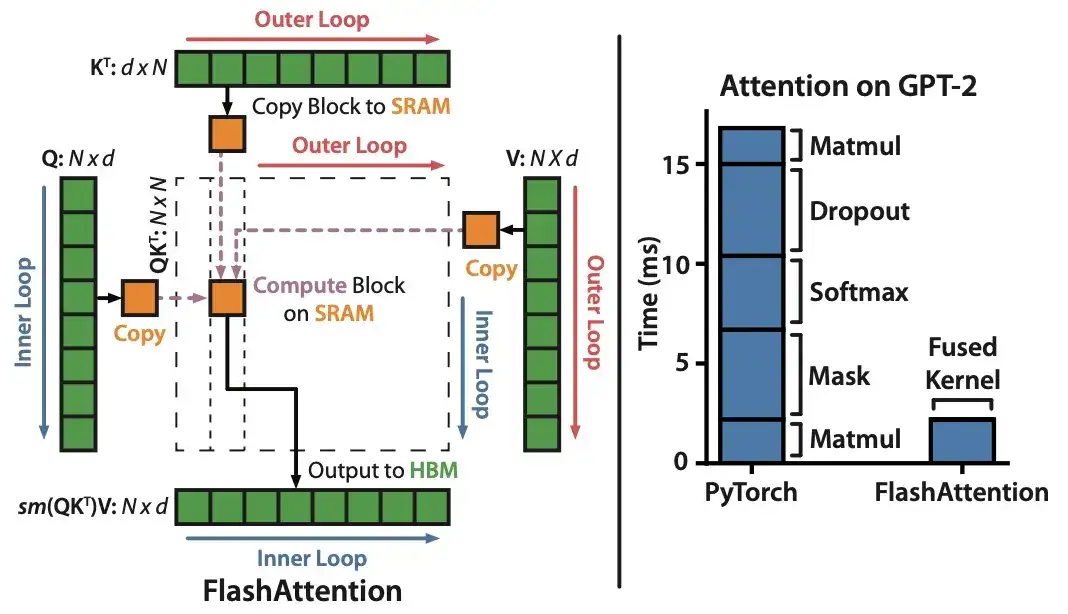
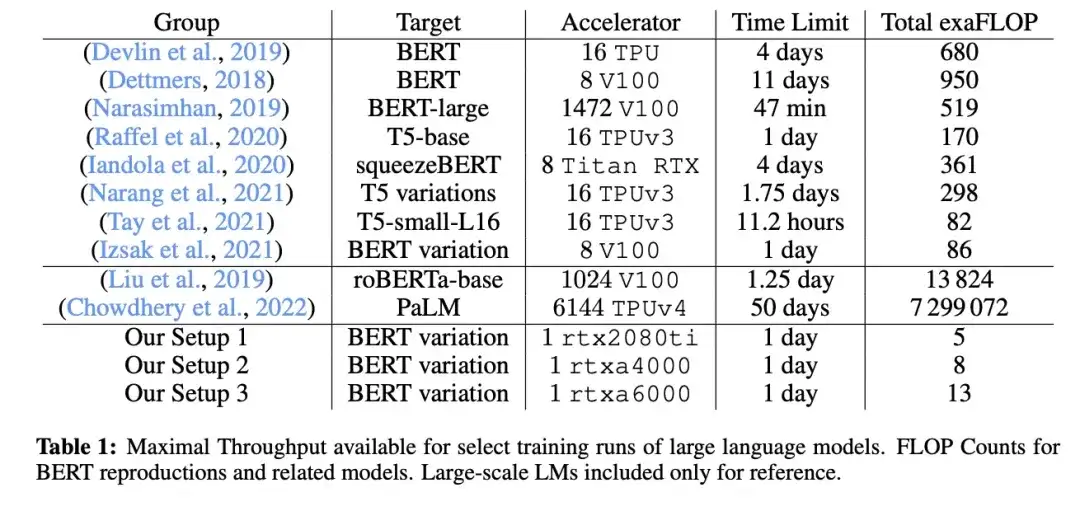
11. Cramming : formation d'un modèle de langage sur un seul GPU en une journée (2022)
_Auteur :_Geiping et Goldstein,
Lien papier : https://arxiv.org/abs/2212.14034
Dans cet article, les chercheurs ont utilisé un seul GPU pour entraîner un grand modèle de langage masqué/style encodeur (ici BERT) pendant 24 heures. À titre de comparaison, l'article BERT original de 2018 a été formé sur 16 TPU pendant quatre jours. Une découverte intéressante est que même si les modèles plus petits ont un débit plus élevé, ils apprennent également moins efficacement. Par conséquent, les modèles plus grands ne nécessitent pas de temps de formation plus longs pour atteindre un certain seuil de performances prédictives.
12. LoRA : Adaptation de bas rang de grands modèles de langage (2021)
Auteur : par Hu, Shen, Wallis, Allen-Zhu, Li, L Wang, S Wang, Chen
Lien papier : https://arxiv.org/abs/2106.09685 .
Les modèles linguistiques modernes à grande échelle présentent des capacités émergentes grâce à une pré-formation sur des ensembles de données à grande échelle et fonctionnent bien dans une variété de tâches, notamment la traduction linguistique, la génération de résumés, la programmation et la réponse aux questions. Cependant, il est utile d'affiner un transformateur pour améliorer ses capacités sur les données spécifiques à un domaine et les tâches spécialisées. L'adaptation de bas rang (LoRA) est l'une des méthodes les plus influentes pour le réglage fin et efficace des paramètres des grands modèles de langage.
Bien qu’il existe d’autres méthodes permettant un réglage fin des paramètres, LoRA mérite une attention particulière car elle est à la fois élégante et très générale et peut être appliquée à d’autres types de modèles. Les poids d'un modèle pré-entraîné ont un rang complet sur la tâche pour laquelle ils ont été pré-entraînés, tandis que les auteurs de LoRA notent que les grands modèles de langage ont une « dimensionnalité intrinsèque » plus faible lorsqu'ils sont adaptés à de nouvelles tâches. Par conséquent, l'idée principale de LoRA est de décomposer le changement de poids ΔW en représentations de rang inférieur pour obtenir une efficacité de paramètre plus élevée.

13_. Réduire à l’échelle : un guide pour un réglage fin efficace des paramètres (2022)_
Auteurs : Lialin, Deshpande, Rumshisky
Lien papier : https://arxiv.org/abs/2303.15647 .
Cette revue passe en revue plus de 40 articles sur les méthodes efficaces de réglage fin des paramètres (couvrant des techniques populaires telles que l'ajustement des préfixes, les adaptateurs et l'adaptation de bas rang), visant à rendre le processus de réglage fin (extrêmement) efficace sur le plan informatique.
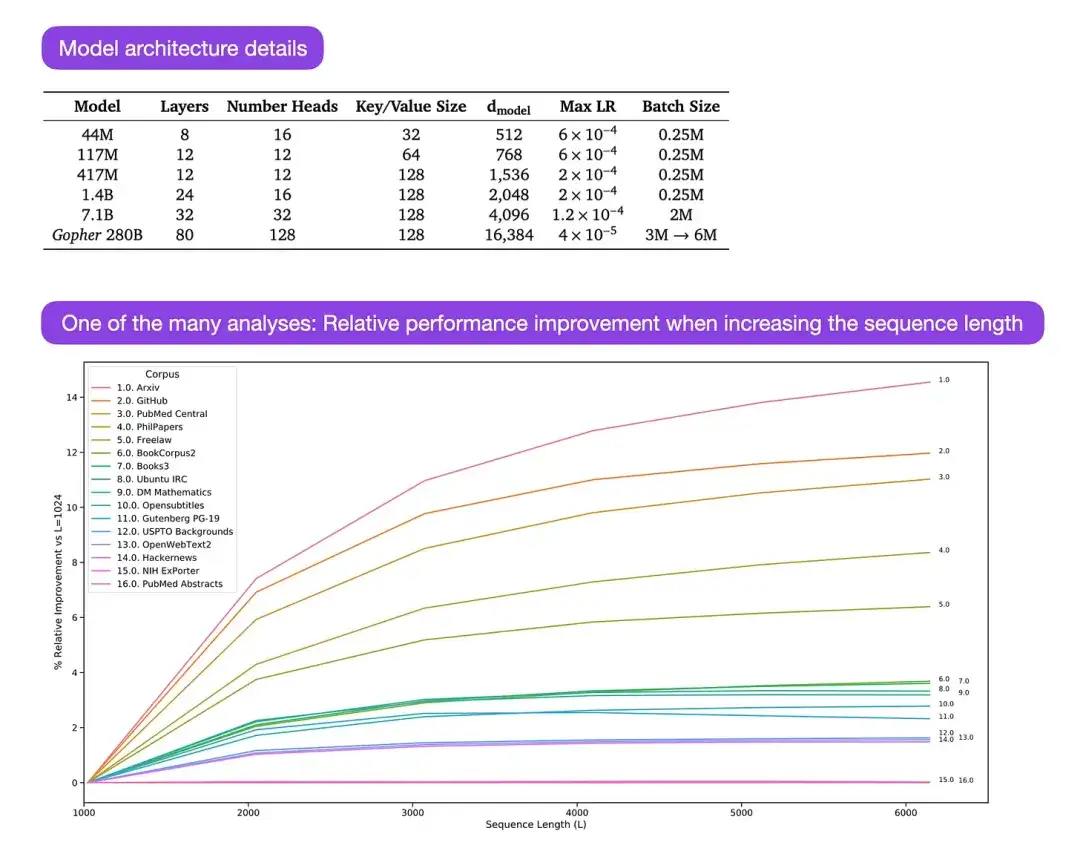
** 14. Mise à l'échelle des modèles linguistiques : méthodes, analyses et informations de Training Gopher (2022)** Auteur : Rae et 78 collègues
Lien papier : https://arxiv.org/abs/2112.11446
Gopher est un article particulièrement bon qui contient de nombreuses analyses pour comprendre le processus de formation des grands modèles de langage (LLM). Le chercheur a formé ici un modèle avec 280 B de paramètres et 80 couches. Le modèle a été formé sur la base de 300 B de jetons. Il contient des améliorations architecturales intéressantes, telles que l'utilisation de RMSNorm (normalisation quadratique moyenne) au lieu de LayerNorm (normalisation de couche). LayerNorm et RMSNorm sont préférés à BatchNorm car ils ne dépendent pas de la taille du lot et ne nécessitent pas de synchronisation, ce qui est particulièrement avantageux lors de l'utilisation de lots plus petits dans des environnements distribués. Cependant, on pense généralement que RMSNorm est plus efficace pour stabiliser le processus de formation des architectures profondes.
Outre ces détails intéressants, l’objectif principal de cet article est l’analyse de la performance des tâches à différentes échelles. Les évaluations de 152 tâches diverses montrent que l'augmentation de la taille du modèle a l'effet d'amélioration le plus significatif sur des tâches telles que la compréhension, la vérification des faits et l'identification du langage préjudiciable. Cependant, les tâches liées au raisonnement logique et mathématique bénéficient moins des extensions architecturales.
15. Formation de grands modèles de langage optimisés pour le calcul (2022)
Parmi eux : Hoffmann, Borgeaud, Mensch, Buchatskaya, Cai, Rutherford, de Las Casas, Hendricks, Welbl, Clark, Hennigan, Noland, Millican, van den Driessche, Damoc, Guy, Osindero, Simonyan, Elsen, Rae, Vinyals et Sifre
Lien papier : https://arxiv.org/abs/2203.15556 .
Cet article présente un modèle de paramètres 70B appelé Chinchilla, qui surpasse le populaire modèle GPT-3 de paramètres 175B sur les tâches de modélisation générative. Cependant, son point central est de souligner que les grands modèles de langage actuels sont « considérablement sous-entraînés ». L'article définit une loi d'échelle linéaire pour la formation de grands modèles de langage. Par exemple, bien que Chinchilla ne soit que la moitié de la taille de GPT-3, il surpasse GPT-3 car il a été formé sur 1,4 billion de jetons (au lieu de seulement 300 milliards). En d’autres termes, le nombre de jetons de formation est tout aussi important que la taille du modèle.
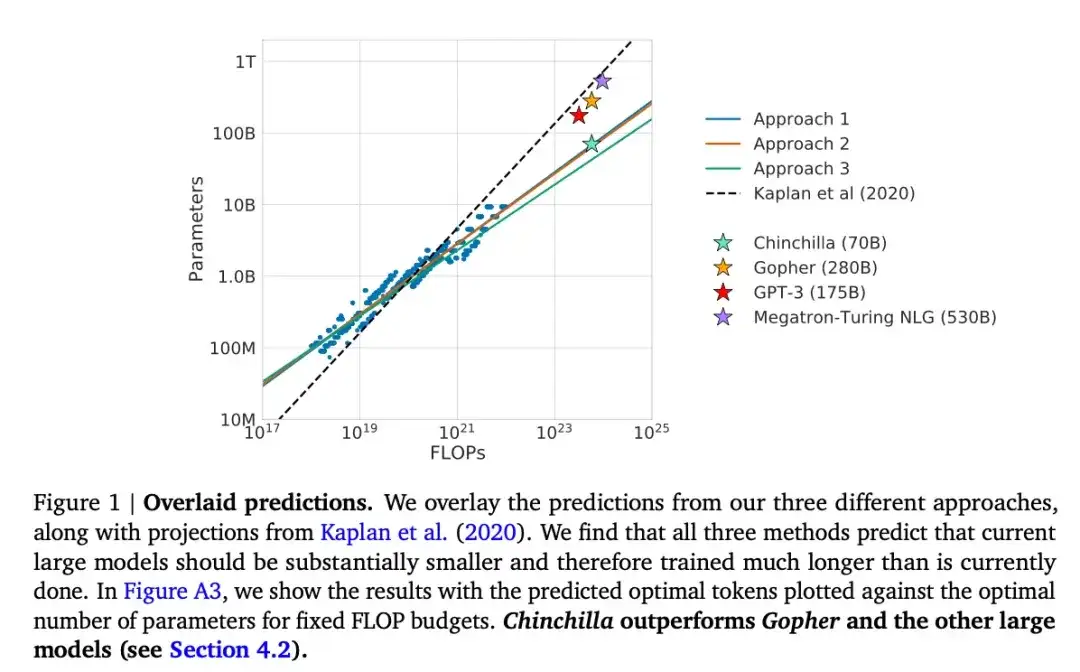
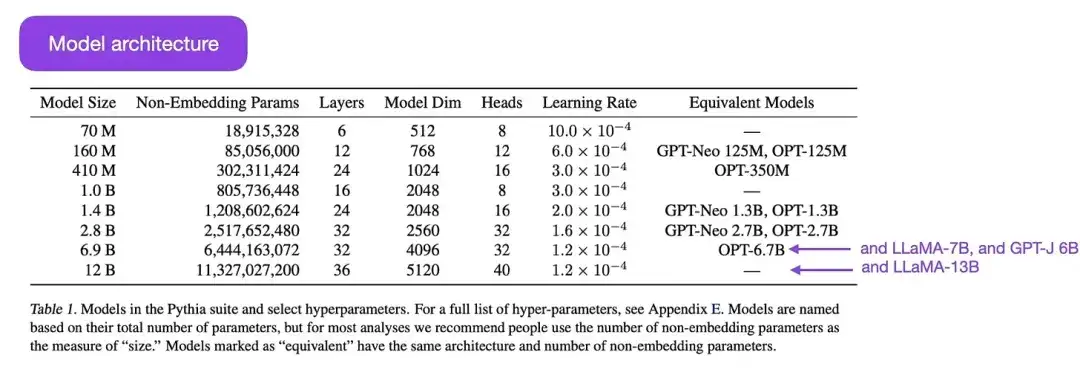
16.Pythia : une suite pour analyser de grands modèles de langage à travers la formation et la mise à l'échelle (2023)
Par exemple : Biderman, Schoelkopf, Anthony, Bradley, O'Brien, Hallahan, Khan, Purohit, Prashanth, Raff, Skowron, Sutawika et Van der Wal.
Lien papier : https://arxiv.org/abs/2304.01373
Pythia est une série de grands modèles de langage open source (allant de 700 M à 12 B de paramètres), conçus pour étudier l'évolution de grands modèles de langage au cours du processus de formation. Son architecture est similaire à GPT-3, mais inclut quelques améliorations, telles que Flash Attention (similaire à LLaMA) et Rotary Positional Embeddings (similaire à PaLM). Pythia est formé sur l'ensemble de données The Pile (825 Go) et la formation utilise 300 Go de jetons (environ l'équivalent d'une époque sur un PILE normal ou de 1,5 époques sur un PILE dédupliqué).
Les principales conclusions de l’étude Pythia sont les suivantes :
- La formation sur des données répétées (ce qui signifie une formation sur plus d'une époque en raison de la manière dont les grands modèles de langage sont formés) n'aide ni ne nuit aux performances ;
- L'ordre des entraînements n'affecte pas l'effet mémoire. C'est regrettable, car si le contraire était vrai, nous pourrions atténuer le problème indésirable de mémoire verbatim en réorganisant les données d'entraînement ;
- La fréquence des mots pendant la pré-formation affecte la performance des tâches. Par exemple, pour les mots qui apparaissent plus fréquemment, la précision avec un plus petit nombre d’échantillons a tendance à être plus élevée ;
- Doubler la taille du lot réduit de moitié le temps de formation sans affecter la convergence.
Alignement : guidez les grands modèles linguistiques vers les objectifs et les intérêts souhaités
Ces dernières années, nous avons assisté à un certain nombre de modèles linguistiques à grande échelle, relativement puissants et capables de générer du texte réaliste (tels que GPT-3 et Chinchilla, etc.). Il semble que nous ayons atteint un plafond de ce qui peut être réalisé dans le cadre des paradigmes de pré-formation couramment utilisés.
Pour rendre le modèle linguistique plus utile et réduire la génération de désinformations et de langages nuisibles, les chercheurs ont conçu des paradigmes de formation supplémentaires pour affiner le modèle de base pré-entraîné.
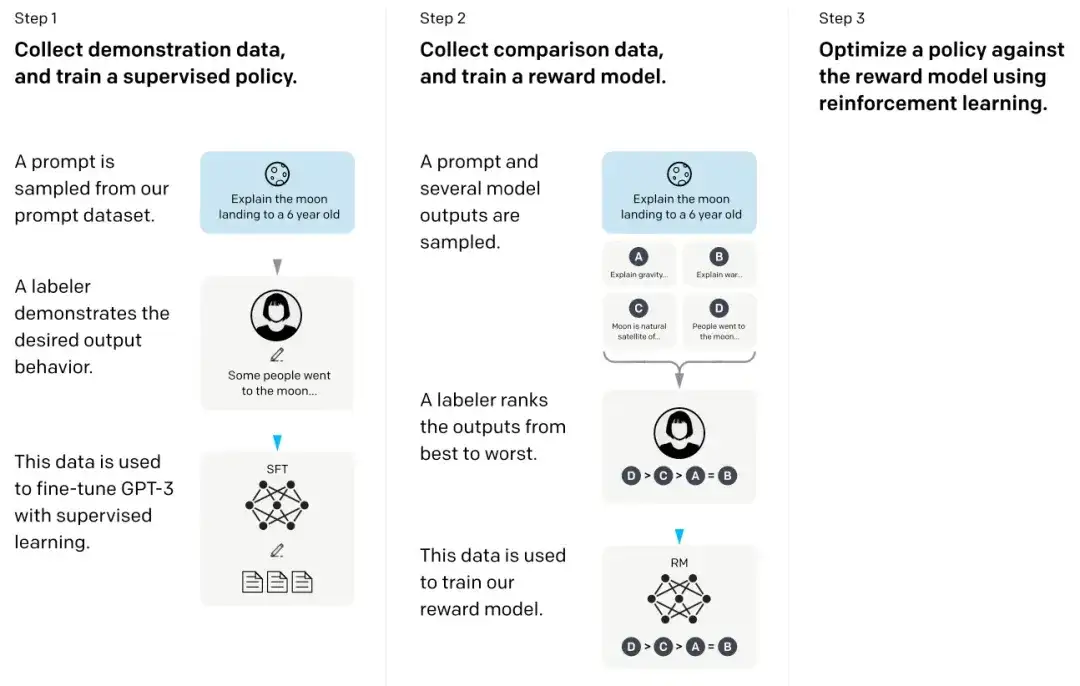
17. Formation de modèles linguistiques pour suivre les instructions avec des commentaires humains **** (2022)
Mots-clés : Ouyang, Wu, Jiang, Almeida, Wainwright, Mishkin, Zhang, Agarwal, Slama, Ray, Schulman, Hilton, Kelton, Miller, Simens, Askell, Welinder, Christiano, Leike, 和Lowe,
Lien papier : https://arxiv.org/abs/2203.02155 .
Dans l’article dit InstructGPT, les chercheurs ont utilisé un mécanisme d’apprentissage par renforcement combiné à la rétroaction humaine (RLHF). Ils ont d’abord utilisé le modèle de base GPT-3 pré-entraîné et l’ont affiné via un apprentissage supervisé sur des paires signal-réponse générées par l’homme (étape 1). Ensuite, ils ont formé un modèle de récompense en demandant aux humains de classer les résultats du modèle (étape 2). Enfin, ils ont utilisé le modèle de récompense pour mettre à jour le modèle GPT-3 pré-entraîné et affiné grâce à la méthode d’apprentissage par renforcement d’optimisation des politiques proximales (étape 3).
Soit dit en passant, cet article est également considéré comme l'article qui explique l'idée derrière ChatGPT - selon des rumeurs récentes, ChatGPT est une version à l'échelle d'InstructGPT qui a été affinée avec un ensemble de données plus important.
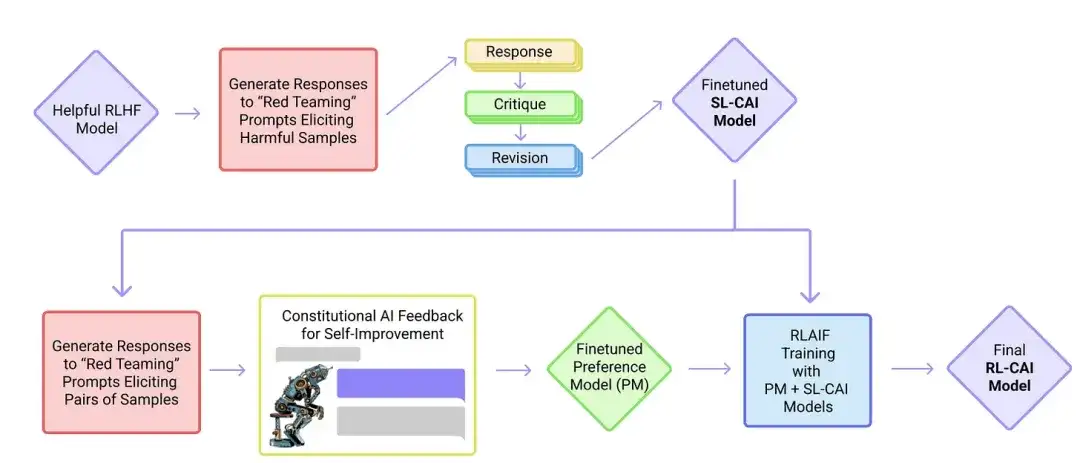
18. IA constitutionnelle : innocuité grâce aux commentaires de l'IA (2022 )
En vedette : Yuntao, Saurav, Sandipan, Amanda, Jackson, Jones, Chen, Anna, Mirhoseini, McKinnon, Chen, Olsson, Olah, Hernandez, Drain, Ganguli, Li, Tran-Johnson, Perez, Kerr, Mueller, Ladish, Landau, Ndousse, Lukosuite, Lovitt, Sellitto, Elhage, Schiefer, Mercado, DasSarma, Lasenby, Larson, Ringer, Johnston, Kravec, El Showk, Fort, Lanham, Telleen-Lawton, Conerly, Henighan, Hume, Bowman, Hatfield-Dodds, Mann , Amodei, Joseph, McCandlish, Brown, Kaplan
Lien papier : https://arxiv.org/abs/2212.08073 .
Dans cet article, les chercheurs développent plus avant l'idée d'« alignement » et proposent un mécanisme de formation pour créer des systèmes d'IA « inoffensifs ». Au lieu d’une supervision humaine directe, les chercheurs proposent un mécanisme d’auto-formation basé sur une liste de règles fournies par les humains. Semblable à l'article InstructGPT mentionné ci-dessus, la méthode proposée utilise des méthodes d'apprentissage par renforcement.
19. Auto-apprentissage : aligner le modèle de langage avec l'enseignement auto-généré (2022)
Auteurs de l'article : Wang, Kordi, Mishra, Liu, Smith, Khashabi et Hajishirzi
Lien papier : https://arxiv.org/abs/2212.10560
Le réglage fin de l'instruction est la façon dont nous passons de modèles de base pré-entraînés comme GPT-3 à des LLM plus puissants comme ChatGPT. Des ensembles de données d'instructions open source générées par l'homme, comme databricks-dolly-15k, peuvent contribuer à rendre ce processus possible. Mais comment atteindre l’échelle ? Une approche consiste à laisser LLM effectuer un apprentissage bootstrap basé sur son propre contenu généré.
L'auto-instruction est une méthode (presque sans annotation) permettant d'aligner les LLM pré-entraînés avec les instructions. Comment fonctionne ce processus ? En bref, il se compose de quatre étapes :
- Initialiser un pool de tâches avec un ensemble d'instructions écrites par l'homme (175 dans ce cas) et des exemples d'instructions à partir de celui-ci ;
- Utilisez un LLM pré-formé (tel que GPT-3) pour déterminer la catégorie de tâche ;
- Pour de nouvelles instructions, laissez le LLM pré-entraîné générer des réponses ;
- Ces réponses sont collectées, filtrées et filtrées avant de les ajouter au pool de tâches.
De cette manière, la méthode d'auto-instruction peut améliorer efficacement la capacité du modèle de langage pré-entraîné à suivre et à générer des instructions tout en réduisant les annotations manuelles, élargissant et optimisant ainsi les capacités du modèle.
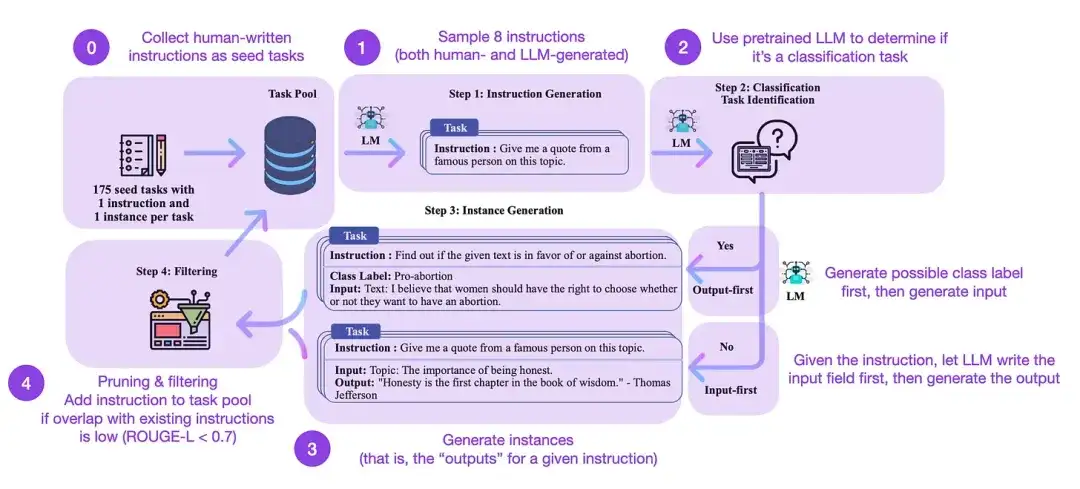
En pratique, cette méthode fonctionne relativement bien sur la base du score ROUGE. Par exemple, le réglage fin autoguidé des grands modèles de langage (LLM) a surpassé le modèle de base GPT-3 et a pu rivaliser avec les LLM pré-entraînés sur de grands ensembles d'instructions écrites par l'homme. De plus, l’auto-orientation peut également bénéficier aux LLM qui ont été affinés par des instructions humaines.
Bien entendu, la norme de référence pour évaluer le LLM est d’inviter des évaluateurs humains à participer. Basées sur l'évaluation humaine, les méthodes autoguidées vont au-delà du LLM de base, ainsi que du LLM formé sur des ensembles de données d'instructions humaines de manière supervisée (comme SuperNI, T0 Trainer). Mais il est intéressant de noter que l’autoguidage n’a pas surpassé ceux formés grâce à des méthodes d’apprentissage par renforcement intégrant le feedback humain (RLHF).
Qu'est-ce qui est le plus prometteur : les ensembles de données d'instructions générés par l'homme ou les ensembles de données autoguidés ? Je suis optimiste sur les deux. Pourquoi ne pas commencer avec un ensemble de données d'instructions générées par l'homme, comme les 15 000 instructions de databricks-dolly-15k, puis l'étendre de manière autonome ?
Apprentissage par renforcement et feedback humain (RLHF) Pour plus d'explications sur l'apprentissage par renforcement et le feedback humain (RLHF), ainsi que des articles connexes sur l'optimisation des politiques proximales pour mettre en œuvre le RLHF, veuillez consulter mon article plus détaillé ci-dessous :
Lorsque je parle de grands modèles de langage (LLM), que ce soit dans des mises à jour de recherche ou des tutoriels, je fais souvent référence à un processus appelé apprentissage par renforcement avec feedback humain (RLHF). Le RLHF est devenu un élément important du pipeline de formation LLM moderne car il peut intégrer les préférences humaines dans le cadre d'optimisation, améliorant ainsi l'utilité et la sécurité du modèle.
Lisez entièrement l'article:
https://magazine.sebastianraschka.com/p/llm-training-rlhf-and-its-alternatives
Conclusion et lectures complémentaires
J'ai essayé de garder la liste ci-dessus concise et concise, en me concentrant sur les dix principaux articles (plus trois articles sur RLHF) qui comprennent la conception, les limites et l'évolution des modèles de langage contemporains à grande échelle. Pour une étude plus approfondie, il est recommandé de se référer aux documents cités dans les articles ci-dessus. Voici quelques ressources supplémentaires :
Alternatives open source au GPT :
- BLOOM : un modèle de langage multilingue en libre accès à 176 B paramètres (2022), https://arxiv.org/abs/2211.05100
- OPT : modèles de langage de transformateur pré-entraînés ouverts (2022), https://arxiv.org/abs/2205.01068
- UL2 : Unifier les paradigmes de l'apprentissage des langues (2022), https://arxiv.org/abs/2205.05131
Alternatives à ChatGPT :
- LaMDA : Modèles linguistiques pour les applications de dialogue (2022), https://arxiv.org/abs/2201.08239
- (Bloomz) Généralisation multilingue grâce au réglage fin multitâche (2022), https://arxiv.org/abs/2211.01786
- (Sparrow) Améliorer l'alignement des agents de dialogue via des jugements humains ciblés (2022), https://arxiv.org/abs/2209.14375
- BlenderBot 3 : un agent conversationnel déployé qui apprend continuellement à s'engager de manière responsable, https://arxiv.org/abs/2208.03188
Grands modèles en bioinformatique :
- ProtTrans : Vers déchiffrer le langage du code de la vie grâce à l'apprentissage profond auto-supervisé et au calcul haute performance (2021), https://arxiv.org/abs/2007.06225
- Prédiction très précise de la structure des protéines avec AlphaFold (2021), https://www.nature.com/articles/s41586-021-03819-2
- Les grands modèles de langage génèrent des séquences de protéines fonctionnelles dans diverses familles (2023), https://www.nature.com/articles/s41587-022-01618-2
Recommandations d'articles
7 conseils rapides pour rendre votre conversation avec l'IA plus efficace
À une époque où tout le monde est développeur, est-il encore utile d’apprendre la programmation ?
En cas d'infraction, veuillez nous contacter pour la supprimer. Liens de référence :
https://magazine.sebastianraschka.com/p/understanding-large-lingual-models
Suivez-nous
OpenSPG :
Site officiel : https://spg.openkg.cn
Github : https://github.com/OpenSPG/openspg
OpenASCE :
Site officiel : https://openasce.openfinai.org/
GitHub : [https://github .com /Open-All-Scale-Causal-Engine/OpenASCE ]