
Auteur : Li Ruifeng
Titre de l'article
StreamE : mises à jour légères des représentations pour les graphiques de connaissances temporels dans les scénarios de streaming
Source de papier
VACHE 2023
Lien papier
https://dl.acm.org/doi/10.1145/3539618.3591772
lien de code
https://github.com/zjs123/StreamE_MindSpore
En tant que framework d'IA open source, MindSpore apporte une collaboration industrie-université-recherche et développeurs dans des scénarios complets de collaboration périphérique-cloud, un développement minimaliste, des performances ultimes, une pré-formation en IA à très grande échelle, un développement minimaliste et un environnement sûr et digne de confiance. expérience, 2020.3.28 L'Open source compte plus de 5 millions de téléchargements. MindSpore a pris en charge des centaines d'articles de conférences de premier plan sur l'IA, a été enseigné dans plus de 100 universités et est disponible dans le commerce sur plus de 5 000 applications via HMS. et est dans le domaine du centre informatique de l'IA, de la finance, de la fabrication intelligente, de la finance, du cloud, du sans fil, des communications de données, de l'énergie, des consommateurs 1+8+N, des voitures intelligentes et d'autres scénarios de voiture cloud de pointe. est le logiciel open source avec l'indice Gitee le plus élevé. Tout le monde est invité à participer aux contributions open source, aux kits, à l'intelligence collective modèle, à l'innovation et aux applications industrielles, à l'innovation algorithmique, à la coopération universitaire, à la coopération en matière de livres d'IA, etc., et à contribuer à vos cas d'application du côté cloud, côté appareil, côté périphérie et domaines de sécurité.
Grâce au soutien massif de SunSilicon MindSpore de la part de la communauté scientifique et technologique, du monde universitaire et de l'industrie, les articles sur l'IA basés sur SunSilicon MindSpore représentaient 7 % de tous les frameworks d'IA en 2023, se classant au deuxième rang mondial pendant deux années consécutives. toutes les universités Avec le soutien des enseignants, nous continuerons à travailler dur ensemble pour faire de la recherche et de l'innovation en IA. La communauté MindSpore soutient les meilleures recherches sur les articles de conférence et continue de produire des résultats originaux en matière d'IA. Je sélectionnerai occasionnellement d'excellents articles à promouvoir et à interpréter. J'espère que davantage d'experts de l'industrie, du monde universitaire et de la recherche coopéreront avec Shengsi MindSpore pour promouvoir la recherche originale sur l'IA. La communauté Shengsi MindSpore continuera à soutenir l'innovation et les applications de l'IA. vient de Shengsi. Pour le 15e article de la série d'articles de la conférence MindSpore AI, j'ai choisi d'interpréter un article de l'équipe du professeur Shao Jie de l'École d'informatique de l'Université des sciences et technologies électroniques de Chine. pour remercier tous les experts, professeurs et camarades de classe pour leurs contributions. Cet article a été téléchargé sur Zhihu, cliquez pour lire le texte original pour l'afficher.
MindSpore vise à atteindre trois objectifs majeurs : un développement facile, une exécution efficace et une couverture complète des scénarios. Grâce à l'expérience d'utilisation, MindSpore, un framework d'apprentissage en profondeur, se développe rapidement et la conception de ses différentes API est constamment optimisée dans une direction plus raisonnable, plus complète et plus puissante. En outre, divers outils de développement qui émergent constamment de Shengsi aident également cet écosystème à créer des méthodes de développement plus pratiques et plus puissantes, telles que MindSpore Insight, qui peut présenter l'architecture du modèle sous la forme d'un diagramme et peut également surveiller dynamiquement divers aspects. du modèle pendant l'exécution. Les modifications des indicateurs et des paramètres rendent le processus de développement plus pratique.
01
Fond de recherche
Le procédé d'intégration de graphe de connaissances temporel vise à apprendre la représentation vectorielle des éléments dans le graphe de connaissances temporel sur la base de la conservation de la temporalité du graphe de connaissances temporel. Bien que les travaux existants puissent représenter les graphes de connaissances temporelles sous forme de vecteurs de faible dimension, ces travaux supposent qu'aucune nouvelle connaissance ne sera ajoutée aux graphes de connaissances temporelles, ce qui est évidemment déraisonnable. Les connaissances du monde réel sont constamment mises à jour, de nouvelles connaissances seront donc continuellement ajoutées au graphe de connaissances. Ce scénario est appelé scénario de flux. Les travaux existants sont principalement confrontés aux trois problèmes suivants lorsqu’ils sont appliqués à des scénarios de streaming :
(1) Premièrement, de nouvelles entités continueront à s'accumuler dans le graphe de connaissances à mesure que les connaissances sont mises à jour. Les travaux existants apprennent directement la représentation intégrée fixe de chaque entité, de sorte qu'ils ne peuvent pas générer de représentations intégrées pour les nouvelles entités.
(2) Divers événements dans le monde réel se produisent tout le temps, ce qui entraîne des mises à jour très fréquentes des connaissances. Les travaux existants nécessitent de régénérer la représentation intégrée du moment actuel à partir de zéro à chaque instant, ce qui rend difficile leur application dans le monde réel. -les domaines de la vie qui nécessitent une réponse rapide, tels que les systèmes d'alerte précoce en cas de crise.
(3) Les travaux existants ne peuvent obtenir que des représentations intégrant des entités avec des horodatages de connaissances pertinents. Cependant, les exigences du monde réel sont générées à tout moment et les travaux existants renverront toujours la même représentation d'intégration jusqu'à la prochaine mise à jour des connaissances, ce qui amènera le modèle à fournir la même réponse pendant cette période, ce qui n'est évidemment pas raisonnable.
Ainsi, même si les travaux existants ont connu un certain succès, aucun d’entre eux ne peut être appliqué aux scénarios de streaming, très courants dans le monde réel (comme les systèmes de recommandation, les systèmes d’alerte de crise, etc.).
02
présentation de l'équipe
Le premier auteur de l'article, Zhang Jiasheng, est un doctorant de deuxième année à l'École d'informatique de l'Université des sciences et technologies électroniques de Chine. Ses intérêts de recherche comprennent l'apprentissage de la représentation graphique dynamique, les graphiques de connaissances séquentielles et l'exploration de données spatio-temporelles. . Jusqu'à présent, un total de 5 articles ont été publiés, dont 2 articles de conférence CCF de catégorie A, 1 article de conférence CCF de catégorie B et C et 1 article de revue dans la première région de l'Académie chinoise des sciences. Brevets d'invention nationaux et 2 droits d'auteur sur les logiciels. Il a présidé l'achèvement du projet clé du projet de semis d'innovation et d'entrepreneuriat du Département provincial des sciences et technologies du Sichuan, « Recherche et application du modèle d'apprentissage de représentation graphique de connaissances guidé par des connaissances séquentielles », et a été sélectionné dans le programme DiDi-Future. Projet conjoint de formation des talents école-entreprise Elite. Il a remporté de nombreuses bourses universitaires de l'Université des sciences et technologies électroniques de Chine et les titres d'« Excellent étudiant diplômé » et d'« Individu avancé en innovation scientifique et technologique ».
Le directeur de thèse Shao Jie est professeur et directeur de doctorat à l'Université des sciences et technologies électroniques de Chine. Il a publié plus de 100 articles universitaires de haut niveau (notamment IEEE TKDE, IEEE TNNLS, IEEE TCYB, IEEE TMM, IEEE TGRS, IEEE). THMS, IEEE TCSVT, ACM TOIS et ACM Journals tels que TOMM et conférences telles que ACM MM, IEEE ICDE, VLDB, IJCAI et AAAI). Il a présidé 2 projets généraux de la Fondation nationale des sciences naturelles de Chine et 1 projet clé de R&D dans la province du Sichuan. En tant que responsable de l'unité coopérative, il a entrepris 1 projet clé de la Fondation nationale des sciences naturelles de Chine. Il a également été le parrain de l'APWeb. -WAIM 2019, la conférence internationale sur le domaine du Big Data recommandée par le président du comité de programme de la Computer Society of China. A remporté le deuxième prix du Prix provincial du progrès scientifique et technologique du Sichuan 2021.
Le Centre de recherche sur les médias du futur de l'Université des sciences et technologies électroniques de Chine, où se trouve l'auteur de l'article, a mené certaines recherches dans le sens des graphes de connaissances multimodaux, des graphes de connaissances temporels et de la construction, du raisonnement et de la construction de graphes de connaissances. application. Un certain nombre de projets provinciaux, ministériels et nationaux pertinents sont en cours de recherche.
03
Introduction au document
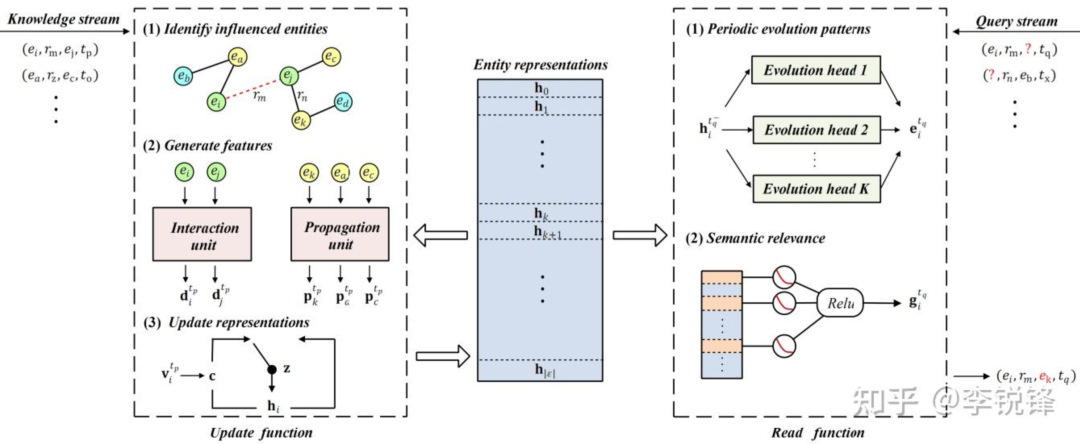
Cet article propose un cadre de représentation d'intégration léger (StreamE) pour résoudre le problème selon lequel les méthodes d'intégration de graphes de connaissances temporelles précédentes ne peuvent pas être appliquées aux scénarios de streaming. Nous pensons que la principale raison pour laquelle les travaux existants sont difficiles à adapter aux scénarios de streaming est qu'ils couplent fortement le processus de génération d'intégration avec le processus de prédiction, ce qui rend difficile la génération efficace de représentations d'intégration à tout moment. Par conséquent, nous obtenons des mises à jour légères des représentations intégrées dans des scénarios de streaming en découplant les deux processus ci-dessus.
Plus précisément, nous utilisons la représentation d'intégration d'entité comme module de stockage externe pour préserver la sémantique historique et dissocier le processus de génération de la représentation d'intégration en une fonction de mise à jour et une fonction de lecture. Dans la fonction de mise à jour, notre framework écoute les connaissances entrantes et met à jour progressivement la représentation d'intégration stockée en fonction des connaissances entrantes ; dans la fonction de lecture, notre framework écoute les besoins de requête de l'utilisateur et met à jour la représentation d'intégration stockée en fonction des connaissances entrantes. La prédiction de trajectoire est utilisée pour générer des représentations d'intégration au moment de la requête afin de répondre aux exigences de la requête.
Afin de mettre à jour avec précision les représentations des entités, nous considérons à la fois l'impact direct entre les entités participantes des nouvelles connaissances, ainsi que l'impact de la propagation des nouvelles connaissances sur les entités impliquées dans les connaissances associées passées. Pour un impact direct, inspiré par le mécanisme de transmission de messages, nous pensons que les entités qui génèrent des connaissances se transmettront également des informations. En même temps, la sémantique des relations reflète la corrélation entre les entités, nous espérons donc utiliser les entités et les relations pour. message passant en même temps des mécanismes pour modéliser les effets directs. Pour les effets de propagation, étant donné que les chemins sont largement utilisés pour modéliser des corrélations d'ordre supérieur entre entités, nous pensons que les chemins composés de nouvelles connaissances et d'entités liées passées peuvent refléter la corrélation entre elles. Nous modélisons donc les effets de propagation en fonction des chemins. Enfin, étant donné que le mécanisme de contrôle peut sélectionner de manière adaptative les informations à mettre à jour, nous l'utilisons pour sélectionner de manière adaptative les informations en influence directe et en influence de propagation afin de mettre à jour la représentation intégrée de l'entité.
Afin de simuler avec précision la trajectoire d’évolution de la sémantique des entités, nous avons considéré deux aspects. Premièrement, la sémantique de la plupart des entités a des caractéristiques cycliques. Par exemple, les Jeux Olympiques ont lieu tous les quatre ans et la Coupe d'Europe a lieu tous les deux ans. La prise en compte des changements sémantiques cycliques des entités peut aider à mieux prédire les connaissances qui peuvent survenir au sein de l'entité. avenir. Deuxièmement, nous avons constaté qu’une entité ne générera des connaissances qu’avec une partie des entités de l’ensemble de la collection d’entités, et que ces entités ont naturellement de fortes corrélations. La trajectoire sémantique future d'une entité doit s'adapter aux changements sémantiques de ses entités associées pour maintenir cette corrélation.
04
Résultats expérimentaux
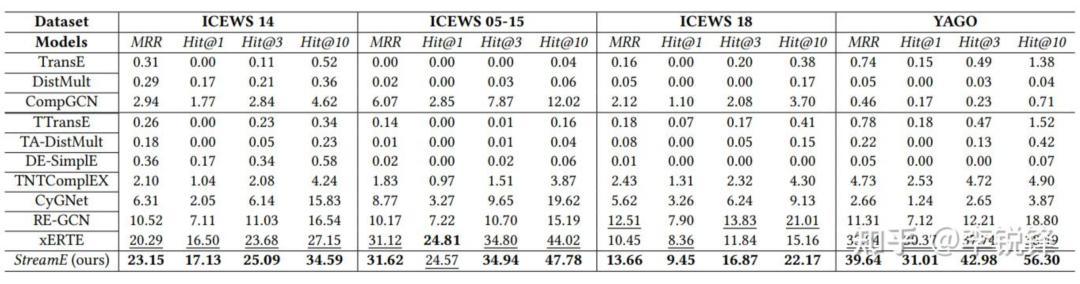
Nous avons vérifié l'efficacité du cadre StreamE mis en œuvre sur la base de Shengsi MindSpore sur la tâche de prédiction inductive des liens futurs sur quatre ensembles de données de référence, comme le montre la figure ci-dessous, notre cadre a mieux fonctionné que l'état de l'art sur tous les ensembles de données. sont des modèles avec de meilleures performances.
Dans le même temps, nous avons vérifié les avantages de notre cadre proposé en termes d'efficacité de l'intégration de la génération de représentations par rapport aux modèles existants. Comme le montre la figure ci-dessous, notre cadre peut maintenir une croissance sous-linéaire du temps de consommation lorsque le nombre de requêtes augmente, ce qui est nettement plus efficace que les modèles existants.

05
Résumé et perspectives
Dans cet article, nous étudions pour la première fois les défis techniques des graphes de connaissances temporelles dans les scénarios de streaming et proposons un framework léger StreamE pour mettre à jour les représentations d'intégration dans les scénarios de streaming. Nous avons implémenté le framework StreamE à l'aide du framework Shengsi MindSpore et avons prouvé ses avantages en termes d'efficacité et de précision grâce à des expériences approfondies. En tant que framework d'apprentissage profond national, MindSpore fournit un grand nombre d'opérateurs très utiles, ce qui simplifie grandement le processus de mise en œuvre du framework. En même temps, il présente également de grands avantages en termes d'efficacité du raisonnement. La communauté Shengsi MindSpore est très active et les suggestions d'autres utilisateurs et développeurs Huawei nous ont grandement aidés à mettre en œuvre le cadre. Nous pensons que sous la direction d'une communauté aussi active et professionnelle, Shengsi MindSpore deviendra de plus en plus parfait.
Un programmeur né dans les années 1990 a développé un logiciel de portage vidéo et en a réalisé plus de 7 millions en moins d'un an. La fin a été très éprouvante ! Google a confirmé les licenciements, impliquant la « malédiction des 35 ans » des codeurs chinois des équipes Flutter, Dart et . Python Arc Browser pour Windows 1.0 en 3 mois officiellement la part de marché de GA Windows 10 atteint 70 %, Windows 11 GitHub continue de décliner l'outil de développement natif d'IA GitHub Copilot Workspace JAVA. est la seule requête de type fort capable de gérer OLTP+OLAP. C'est le meilleur ORM. Nous nous rencontrons trop tard.