
Auteur : Jin Xuefeng
arrière-plan
L'exécution de grands modèles de langage sur des graphiques statiques présente de nombreux avantages, notamment :
-
Amélioration des performances apportée par l'optimisation de la fusion des opérateurs/l'exécution du graphe entier ; s'il s'agit d'Ascend, vous pouvez également utiliser l'exécution de l'immersion du graphique entière pour améliorer encore les performances, et l'exécution de l'immersion du graphique entière n'est pas affectée par l'exécution du traitement des données du côté hôte, et les performances sont stables et bonnes ;
-
L'orchestration de la mémoire statique permet une utilisation élevée de la mémoire, aucune fragmentation, augmente la taille des lots et améliore ainsi les performances d'entraînement ;
-
Optimisez automatiquement la séquence d'exécution et obtenez une bonne concurrence de communication et de calcul ;
-
......
Cependant, l'exécution de modèles de langage volumineux sur des images statiques présente également des défis, le plus important étant les performances de compilation.
Le processus de compilation du modèle de réseau de neurones convertit en fait le code nn exprimé en Python en un graphe de calcul de flux de données :
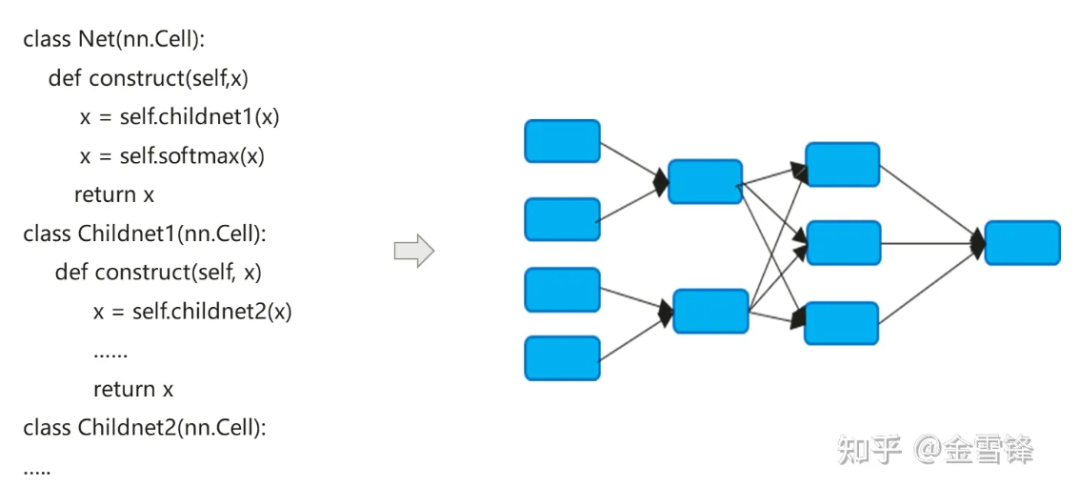
Le processus de compilation des modèles de réseaux neuronaux est un peu différent des compilateurs traditionnels. La méthode Inline par défaut est souvent utilisée pour finalement étendre l'expression de code hiérarchique en un graphe de calcul plat. D'une part, elle cherche à maximiser les opportunités d'optimisation de la compilation, et d'autre part. d'un autre côté, cela peut également simplifier la différenciation automatique et la logique d'exécution.
Par défaut, le graphique de calcul formé après Inline inclut tous les nœuds de calcul, et les nœuds n'ont plus de partitions de graphique de sous-calcul. Par conséquent, l'optimisation en cours de processus peut être effectuée à plus grande échelle, comme le repliement constant, la fusion de nœuds, l'analyse parallèle. , etc., et il peut mieux réaliser l'allocation de mémoire et réduire la surcharge d'application de mémoire et de performances lors des appels entre procédures. Même pour les unités de calcul appelées à plusieurs reprises, les compilateurs dans le domaine de l'IA utilisent toujours la même stratégie en ligne. Tout en payant le prix de l'expansion de la taille du programme et de la croissance du code exécutable, ils peuvent maximiser les méthodes d'optimisation de la compilation pour améliorer les performances d'exécution.
Comme le montre la description ci-dessus, l'optimisation en ligne est très utile pour améliorer les performances d'exécution, mais en conséquence, une optimisation en ligne excessive entraîne également une charge de temps de compilation ; À mesure que le graphe de sous-calcul est intégré dans l'ensemble du graphe, d'un point de vue global, le nombre de nœuds de graphe de calcul que le compilateur doit traiter augmente rapidement. Les compilateurs utilisent généralement le mécanisme Pass pour organiser et organiser les méthodes d'optimisation. Différentes méthodes d'optimisation sont connectées en série sous la forme de Pass, et un processus de traitement passera par chaque nœud du graphe de calcul. Le nombre de passes de traitement dépend du processus de correspondance et de conversion du nœud et de la passe. Parfois, plusieurs passes sont nécessaires pour terminer le traitement. D'une manière générale, si le nombre de passes est M et le nombre de nœuds du graphe de calcul est N, le temps de l'ensemble du processus de compilation et d'optimisation est directement lié à la valeur de M * N. À l'ère des grands modèles de langage, ce problème est devenu plus important.Il y a deux raisons principales : premièrement, la structure des grands modèles de langage est profonde et comporte un grand nombre de nœuds ; l'activation du parallélisme du pipeline, l'échelle du modèle et les nœuds sont réduits. Le nombre est encore augmenté. Si la taille du graphique d'origine est O, activez le parallélisme du pipeline et la taille du graphe à nœud unique devient (O/X)*Y. , où X est le nombre d'étapes dans le pipeline et Y est le nombre de microlots. En réalité, pendant le processus de configuration, Y est beaucoup plus grand que X. Par exemple, X est 16 et Y est généralement défini sur 64-192. De cette manière, une fois la parallélisation du pipeline activée, l'échelle de compilation du graphique augmentera encore jusqu'à 4 à 12 fois la taille d'origine.

En prenant comme exemple un certain réseau 13B de dizaines de milliards de modèles de langage, le nombre de nœuds de calcul dans le graphe de calcul atteint 135 000, et un seul temps de compilation peut être proche de 3 heures.
**1.** Idées d'optimisation
Nous avons observé que la structure du réseau neuronal de l'apprentissage profond est composée de plusieurs couches.Dans le modèle de langage de modèle étendu, ces couches sont des piles de blocs Transformer. Surtout lorsque le parallélisme du pipeline est activé, les couches de chaque micro-lot sont exactement les mêmes. même. Par conséquent, nous nous demandons si nous pouvons conserver ces structures Layer sans Inline ou Inline à l'avance, afin que les performances de compilation puissent être améliorées de manière exponentielle. Par exemple, si nous suivons le micro-lot comme limite et conservons la structure de sous-graphe du micro-lot, alors théoriquement, le temps de compilation peut être Il devient une fois supérieur au Y d'origine (Y est le nombre de micro-lots).
Spécifique au code écrit dans le modèle, nous pouvons voir que la manière de réutiliser le même Layer est généralement une boucle ou un appel itératif. Layer correspond généralement à un élément de la structure séquentielle dans le processus itératif, souvent un sous-graphe ; en utilisant une boucle Ou itérer pour appeler plusieurs fois la même unité de calcul, comme indiqué dans le code ci-dessous, le bloc correspond à un sous-graphe Layer ou micro batch.
class Block(nn.Cell):
def __init__(self, config):
.......
def construct(self, x, attention_mask, layer_past):
......
class GPT_Model(nn.Cell):
def __init__(self, config):
......
for i in range(config.num_layers):
self.blocks.append(Block)
......
self.num_layers = config.num_layers
def construct(self, input_ids, input_mask, layer_past):
......
present_layer = ()
for i in range(self.num_layers):
hidden_states, present = self.blocks[i](...)
present_layer = present_layer + (present,)
......
Par conséquent, si nous considérons le corps de la boucle comme un sous-graphe fréquemment appelé et demandons au compilateur de différer le traitement en ligne en le marquant comme Lazy Inline, alors des gains de performances peuvent être obtenus dans la plupart des étapes de compilation. Par exemple, lorsque le réseau neuronal appelle cycliquement la même structure de sous-graphe, nous ne développons pas le sous-graphe pendant la phase de compilation ; puis, à la fin de la compilation, l'optimisation en ligne est déclenchée pour effectuer l'optimisation et le traitement de conversion nécessaires. De cette façon, pour le compilateur, il s'agit la plupart du temps de code à plus petite échelle au lieu de code développé en ligne, améliorant ainsi considérablement les performances de compilation.
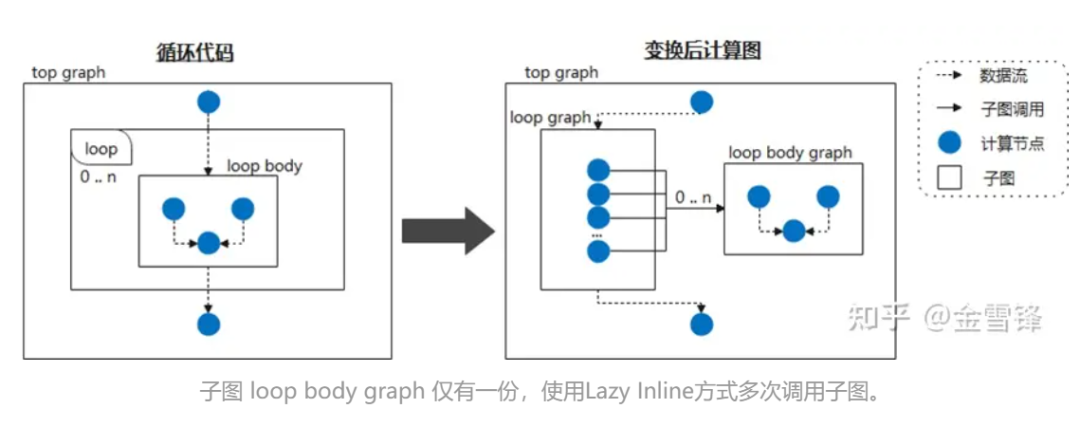
Lors d'une implémentation spécifique, vous pouvez mettre une marque similaire à @lazy-inline sur la classe Layer appropriée pour demander au compilateur si le Layer marqué est appelé dans le corps de la boucle ou d'une autre manière, il ne sera pas inclus lors de l'expansion en ligne. n’est effectué qu’avant l’exécution.
**2. ** Pratique MindSpore
Il semble que les principes et les idées de Lazy Inline ne soient pas compliqués, mais le mécanisme de compilation de graphiques AI existant n'est généralement pas le genre de compilateur qui prend en charge des fonctionnalités de compilation complètes, il est donc toujours très difficile de réaliser cette fonction.
Heureusement, le compilateur de graphiques de MindSpore a pris en compte la polyvalence lors de la conception d'IR, y compris les appels de sous-fonctions, les fermetures et d'autres fonctionnalités.
① Les instances de cellules sont compilées dans des graphiques de calcul réutilisables
Cell est l'élément de base du réseau neuronal MindSpore et la classe de base de tous les réseaux neuronaux. Cell peut être une seule unité de réseau neuronal, telle que conv2d, relu, batch_norm, etc., ou une combinaison d'unités qui construisent un réseau neuronal. réseau. En GRAPH_MODE (mode graphique statique), la cellule sera compilée en un graphique de calcul.
Lorsque vous devez personnaliser le réseau, vous devez hériter de la classe Cell et remplacer les méthodes __init__ et construct. La classe Cell remplace la méthode __call__. Lorsqu'une instance de classe Cell est appelée, la méthode constructeur est exécutée. Définir la structure du réseau dans la méthode de construction.
Dans l'exemple suivant, un réseau simple est construit pour implémenter la fonction de calcul de convolution. Les opérateurs du réseau sont définis dans __init__ et utilisés dans la méthode de construction. La structure réseau du cas est : Conv2d -> BiasAdd.
Dans la méthode de construction, x correspond aux données d'entrée et la sortie est le résultat obtenu après calcul de la structure du réseau.
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Parameter
from mindspore.common.initializer import initializer
from mindspore._extends import lazy_inline
class MyNet(nn.Cell):
@lazy_inline
def __init__(self, in_channels=10, out_channels=20, kernel_size=3):
super(Net, self).__init__()
self.conv2d = ops.Conv2D(out_channels, kernel_size)
self.bias_add = ops.BiasAdd()
self.weight = Parameter(initializer('normal', [out_channels, in_channels, kernel_size, kernel_size]))
def construct(self, x):
output = self.conv2d(x, self.weight)
output = self.bias_add(output, self.bias)
return output
@Lazy_Inline est le décorateur de Cell::__init__. Sa fonction est de générer tous les paramètres de __init__ dans la valeur de l'attribut cell_init_args de Cell, self.cell_init_args = type(self).__name__ + str(arguments). L'attribut cell_init_args sert d'identifiant unique de l'instance Cell dans la compilation MindSpore. La même valeur cell_init_args indique que les valeurs du nom de la classe Cell et du paramètre d'initialisation sont les mêmes.
construct(self, x) définit la structure du réseau, qui est la même que la classe Cell. La structure du réseau dépend des paramètres d'entrée self et x. Self contient des paramètres tels que des poids. Ces poids sont initialisés de manière aléatoire ou sont les résultats de l'entraînement. Ces poids sont donc différents pour chaque instance de cellule. D'autres attributs personnels sont déterminés par le paramètre __init__, et le paramètre __init__ est calculé par @lazy_inline pour obtenir l'identification de l'instance de cellule cell_init_args. Par conséquent, le graphique de calcul de compilation d'instance de cellule construct(self, x) est transformé en construct(x, self. cell_init_args, self.trainable_parameters() ).
S'il s'agit de la même classe Cell et que les paramètres cell_init_args sont les mêmes, nous appelons ces instances de neurones instances de neurones réutilisables, et le graphe de calcul correspondant à cette instance de neurone est nommé graphe de calcul réutilisable reuse_construct(X, self. trainable_parameters()). On peut en déduire que le graphe de calcul de chaque instance de Cell peut être converti en :
def construct(self, x)
Reuse_construct(x, self.trainable_parameters())
Après l'introduction des graphiques informatiques réutilisables, les cellules neuronales (graphiques informatiques réutilisables) avec les mêmes cell_init_args ne doivent être composées et compilées qu'une seule fois. Plus il y a de cellules dans le réseau, meilleures sont les performances. Mais tout a deux côtés : si le graphe de calcul de ces cellules est trop petit ou trop grand, cela entraînera une mauvaise compilation et optimisation de certaines fonctionnalités, telles que la fusion d'opérateurs, le multiplexage de la mémoire, le naufrage de graphe entier et l'appel multi-graphe, etc. .
Par conséquent, la version MindSpore ne prend actuellement en charge que l'identification manuelle des étapes de compilation de cellules qui génèrent des graphiques de calcul réutilisables. Les versions ultérieures planifieront des stratégies automatiques pour générer des graphiques de calcul réutilisables, tels que le nombre d'opérateurs qu'une cellule contient, le nombre de fois qu'une cellule est utilisée et d'autres facteurs pour déterminer s'il convient de générer un graphique de calcul réutilisable et donner des suggestions d'optimisation.
Ce qui suit utilise la structure GPT pour une explication abstraite et simplifiée :
class Block(nn.Cell):
@lazy_inline
def __init__(self, config):
.......
def construct(self, x, attention_mask, layer_past):
......
class GPT_Model(nn.Cell):
def __init__(self, config):
......
for i in range(config.num_layers):
self.blocks.append(Block(config, None))
......
self.num_layers = config.num_layers
def construct(self, input_ids, input_mask, layer_past):
......
present_layer = ()
for i in range(self.num_layers):
hidden_states, present = self.blocks[i](...)
present_layer = present_layer + (present,)
......
GPT est composé de plusieurs couches de blocs. Les paramètres d'initialisation de ces blocs sont tous de la même configuration, donc les structures de ces blocs sont les mêmes et seront converties en interne par le compilateur dans la structure suivante :
def Reuse_Block(x, attention_mask, layer_past,block_parameters) :
......
具体的Block 实例的计算图如下:
def construct(self, x, attention_mask, layer_past):
return Reuse_Block(x, attention_mask, layer_past,
self. trainable_parameters())
Avec cette structure, dans la première moitié du processus de compilation, il s'agit d'un graphe de calcul indépendant et n'est pas intégré dans le graphe de calcul global. Seule la petite quantité finale d'optimisation Pass est intégrée dans le grand graphe de calcul.
② La combinaison de L****azy Inline et de différenciation/parallèle/recalcul automatique et d'autres fonctionnalités
Après l'adoption de la solution de Lazy Inline, celle-ci aura un certain impact sur le processus d'origine et nécessitera des adaptations pertinentes, principalement la différenciation automatique, le parallélisme et le recalcul.
Pour la différenciation automatique, un nœud avant similaire à la fonction d'appel apparaît et un traitement de différenciation doit être fourni ;
Pour les processus parallèles, l'essentiel est que le traitement des passes parallèles du Pipeline doit être adapté aux scénarios d'image non complète, car la découpe précédente du Pipeline était basée sur l'image entière, mais elle doit maintenant être coupée en fonction du sous-graphe partagé. Le plan spécifique consiste d'abord à colorer en fonction de l'étape, à diviser les nœuds dans la cellule partagée en fonction de l'étape, à conserver uniquement les nœuds correspondant à l'étape du processus en cours, et à insérer l'opérateur Send/Recv, puis à diviser les nœuds. en dehors de la cellule partagée, en conservant les nœuds correspondants du processus en cours. Le nœud d'étape fait également sortir l'opérateur Send/Recv dans la cellule partagée de la cellule partagée ;
Pour le processus de recalcul, l'ancien processus de recalcul traite les opérateurs sur l'ensemble du graphique après Inline. En recherchant les blocs d'opérateurs continus recalculés, les opérateurs qui doivent être recalculés et les paramètres de recalcul sont déterminés en fonction de la configuration de recalcul de l'utilisateur. opérateur dont dépend l’exécution de l’opérateur calculé. Après Lazy Inline, les opérateurs de recalcul consécutifs peuvent se trouver dans différents sous-graphes, et aucune relation de connexion ne peut être trouvée entre le nœud avant et le nœud inverse, de sorte que la stratégie de recherche originale basée sur l'opérateur graphique entier échoue.
Notre plan d'adaptation est de traiter les Cellules ou opérateurs recalculés après différenciation automatique. Le processus de différenciation automatique générera une fermeture pour le sous-graphe ou l'opérateur unique produit par Cell, qui renvoie la fonction de sortie avant et de rétropropagation, et nous obtiendrons également la relation entre chaque fermeture et la partie avant d'origine, un mappage. Grâce à ces informations, basées sur la configuration de recalcul de l'utilisateur, chaque fermeture est utilisée comme unité de base, la cellule et l'opérateur sont traités uniformément, et la partie avant d'origine est recopiée dans le graphique d'origine, et la relation de dépendance peut être transmise. la fermeture dans la fermeture. L'acquisition de la fonction de rétropropagation peut enfin réaliser un schéma de recalcul qui ne repose pas sur l'ensemble du graphique en ligne.
③Traitement backend et impact
L'IR généré après l'activation de Lazy Inline sur le front-end est envoyé au back-end. Le back-end doit découper l'IR avant de pouvoir être exécuté sur l'appareil via la descente de sous-graphes. Cependant, après Lazy Inline, il y aura encore quelques problèmes dans l'exécution du naufrage de sous-graphes, tels que l'incapacité d'utiliser la méthode optimale de réutilisation de la mémoire et d'allocation de flux, l'impossibilité d'utiliser le cache interne du graphe pour accélérer la compilation lors de la compilation. , et l'incapacité d'effectuer un traitement entre graphes (optimisation de la mémoire, fusion de communication, fusion d'opérateurs, etc.) et d'autres problèmes.
Afin d'obtenir des performances optimales, le backend doit traiter l'IR de Lazy Inline sous une forme adaptée à l'exécution du backend. La principale chose à faire est de convertir l'opérateur Partial généré par la différenciation automatique en un appel de sous-graphe ordinaire et de modifier le. variables capturées dans Transmettez-les comme paramètres ordinaires, afin que l'ensemble du graphique puisse être coulé et que l'ensemble du réseau puisse être exécuté.
Dans l'ensemble du processus de puits de graphe, ces appels ont deux méthodes de traitement : Inline sur le graphe et Inline sur la séquence d'exécution. Inline sur le graphique entraînera l'expansion du graphique et la vitesse de compilation ultérieure sera plus lente ; cependant, l'inline de la séquence d'exécution entraînera un cycle de vie de la mémoire d'une partie de la séquence d'exécution Inline particulièrement long lors de la réutilisation de la mémoire et dans le à la fin, la mémoire ne suffira pas.
En fin de compte, la méthode de traitement que nous avons adoptée consistait à réutiliser la séquence d'exécution du processus en ligne dans la passe d'optimisation, la sélection des opérateurs, la compilation des opérateurs et d'autres processus afin de rendre la taille du graphique aussi petite que possible et d'éviter qu'un trop grand nombre de nœuds de graphique n'affectent le back-end. compilation du graphique temps. Avant d'exécuter l'optimisation de séquence, l'allocation de flux, la réutilisation de la mémoire et d'autres processus, ces appels sont effectués dans des nœuds réels en ligne pour obtenir l'effet optimal de réutilisation de la mémoire. De plus, grâce à une certaine optimisation de la mémoire et de la communication, à l'élimination des calculs redondants et à d'autres méthodes après l'intégration du graphique, il est possible d'obtenir aucune dégradation de la mémoire et des performances.
À l'heure actuelle, il n'est pas possible de réaliser toutes les optimisations au niveau des graphiques croisés. L'identification d'un point unique ne peut être placée que dans l'étape après Inline, et il est impossible de gagner du temps sur l'optimisation de l'ordre d'exécution, l'allocation de flux et la réutilisation de la mémoire.
④Obtenir des effets
L'optimisation des performances de compilation de grands modèles utilise la solution Lazy Inline pour améliorer les performances de compilation de 3 à 8 fois. En prenant comme exemple le réseau 13B du grand modèle de 10 milliards, après avoir appliqué la solution Lazy Inline, l'échelle de compilation du graphique de calcul est passée de 130 000+. nœuds à plus de 20 000 nœuds, le temps de compilation a été réduit de 3 heures à 20 minutes et, combiné à la mise en cache des résultats de la compilation, l'efficacité globale a été considérablement améliorée.
⑤Restrictions d'utilisation et étapes suivantes
1. Cell L'identifiant de l'instance Cell est généré en fonction du nom de la classe Cell et de la valeur du paramètre __init__. Ceci est basé sur l'hypothèse que les paramètres de init déterminent toutes les propriétés de Cell et que les propriétés de Cell au début de la composition de la construction sont cohérentes avec les propriétés après l'exécution de init. Par conséquent, les propriétés de Cell liées à la composition ne peuvent pas être modifiées. après l'exécution de init.
2. Les paramètres de la fonction de construction ne peuvent pas avoir de valeurs par défaut. Si la version existante de MindSpore a des valeurs par défaut pour les paramètres de la fonction de construction, chaque fois qu'elle sera utilisée, elle sera spécialisée dans un nouveau graphe de calcul ; les versions ultérieures optimiseront le mécanisme de spécialisation d'origine ;
3. Cell se compose de plusieurs instances Cell_X partagées, et chaque Cell_X se compose de plusieurs instances Cell_Y partagées. Si l'initialisation de Cell_X et Cell_Y sont toutes deux décorées comme @lazy_inline, seul le Cell_X le plus externe peut être compilé dans un graphe de calcul réutilisé, et le graphe de calcul du Cell_Y interne est toujours en ligne. Les versions ultérieures prévoient de prendre en charge cet inline paresseux à plusieurs niveaux ; mécanisme.
Comment aider les clients à écrire du code avec une cohésion élevée et un faible couplage est également l'un des objectifs poursuivis par le framework MindSpore. Par exemple, en cours d'utilisation, il y a ce paramètre Block:: __init__ comprenant l'index de couche et les valeurs. des autres paramètres sont les mêmes. Depuis l'index des couches, chaque couche est différente, ce qui fait que le bloc n'est pas réutilisable en raison de différences subtiles. Par exemple, le code suivant existe dans un certain code de version GTP :
class Block (nn.Cell):
"""
Self-Attention module for each layer
Args:
config(GPTConfig): the config of network
scale: scale factor for initialization
layer_idx: current layer index
"""
def __init__(self, config, scale=1.0, layer_idx=None):
......
if layer_idx is not None:
self.coeff = math.sqrt(layer_idx * math.sqrt(self.size_per_head))
self.coeff = Tensor(self.coeff)
......
def construct(self, x, attention_mask, layer_past=None):
......
Afin de rendre le bloc réutilisable, nous pouvons l'optimiser, extraire les calculs liés à l'index de couche, puis les utiliser comme paramètres de Construct pour les saisir dans la composition originale, afin que les paramètres d'initialisation du bloc soient les mêmes.
Modifiez le segment de code ci-dessus par le segment de code suivant, supprimez les parties liées à Init et Layer Index et ajoutez le paramètre coeff à construire.
class Block (nn.Cell):
def __init__(self, config, scale=1.0):
......
def construct(self, x, attention_mask, layer_past, coeff):
......
Dans les versions ultérieures de Shengsi MindSpore, nous prévoyons d'identifier ces blocs subtilement différents et de fournir des suggestions d'optimisation pour ces blocs à des fins d'optimisation et d'amélioration.
Un programmeur né dans les années 1990 a développé un logiciel de portage vidéo et en a réalisé plus de 7 millions en moins d'un an. La fin a été très éprouvante ! Google a confirmé les licenciements, impliquant la « malédiction des 35 ans » des codeurs chinois des équipes Flutter, Dart et . Python Arc Browser pour Windows 1.0 en 3 mois officiellement la part de marché de GA Windows 10 atteint 70 %, Windows 11 GitHub continue de décliner l'outil de développement natif d'IA GitHub Copilot Workspace JAVA. est la seule requête de type fort capable de gérer OLTP+OLAP. C'est le meilleur ORM. Nous nous rencontrons trop tard.