
Auteur : Wu Jipeng, responsable de la technologie Big Data de la Wuxi Xishang Bank
Montage et finition : équipe technique SelectDB
Introduction : Afin de réaliser la transformation de la valeur des actifs de données et une gestion complète des risques numériques et intelligents, la plate-forme Big Data de Wuxi Xishang Bank a connu l'évolution de l'entrepôt de données hors ligne Hive à l' entrepôt de données en temps réel Apache Doris , et a actuellement accès à des centaines de tables en temps réel, des centaines d'interfaces de service de données et l'interface QPS atteint des millions de niveaux, résolvant les problèmes de rapidité insuffisante, de coût élevé et de faible efficacité des entrepôts de données hors ligne, accélérant les requêtes de plus de 10 fois. , et fournir aux utilisateurs des services de données et une expérience d'utilisation rapides, efficaces et sécurisés.
Face aux changements apportés au secteur financier par les technologies émergentes telles que le big data, l'Internet des objets et l'intelligence artificielle, la Wuxi Xishang Bank met un accent important sur le développement des capacités technologiques et des capacités du big data. Afin de réaliser la transformation de la valeur des actifs de données et une gestion complète des risques numériques et intelligents, la Wuxi Xishang Bank a créé une plate-forme Big Data basée sur la configuration technologique intégrée à trois ailes de « commerce en ligne, contrôle des risques basé sur les données et plate-forme. architecture". Pour gérer chaque jour l'afflux massif d'enregistrements de transactions et de données de demandes de crédit, et avec l'aide de portraits d'utilisateurs, de rapports en temps réel, de contrôle des risques en temps réel et d'autres applications, il offre aux utilisateurs des solutions plus rapides, plus efficaces et plus sécurisées. services de données et expérience utilisateur.
La plate-forme Big Data de Wuxi Xishang Bank est passée d'un entrepôt de données hors ligne basé sur Hive à un entrepôt de données en temps réel basé sur Apache Doris . Grâce à la mise à niveau de l'architecture, les problèmes de rapidité insuffisante, de coût élevé et de faible efficacité de l'entrepôt de données hors ligne ont été résolus, et la vitesse des requêtes a été multipliée par 10, permettant aux banques de percevoir plus rapidement le comportement des clients et d'obtenir des informations en temps opportun. dans des comportements de transaction anormaux, et identifier et prévenir les risques potentiels. Cet article présentera en détail l'évolution de la plateforme Big Data de la Wuxi Xishang Bank et la mise en œuvre d'Apache Doris dans les requêtes en temps réel, les services marketing, les services de contrôle des risques et d'autres scénarios.
Entrepôt de données Big Data hors ligne basé sur Hive
01 Scénario de demande
La Wuxi Xishang Bank a construit dès le début un entrepôt de données hors ligne Big Data, qui sert principalement à des scénarios tels que le reporting des données, le contrôle des risques liés aux données, les opérations sur les données, les requêtes ad hoc et la récupération quotidienne des données. Les scénarios de demande incluent, sans s'y limiter :
-
Reporting de données : risque client, reporting EAST, 1104, grande concentration, reporting de crédit, reporting sur les taux d'intérêt, lutte contre le blanchiment d'argent, reporting de données financières de base, etc.
-
Contrôle des risques liés aux données : y compris le contrôle des risques sur les indicateurs de contrôle des risques de prêt, les indicateurs de comportement des utilisateurs, la lutte contre la fraude, l'alerte précoce post-prêt, la gestion post-prêt et d'autres contrôles des risques.
-
Exploitation des données : fournissez régulièrement des données par lots pour les rapports commerciaux BI, le cockpit de gestion, les canaux externes et divers systèmes du secteur.
-
Requête ad hoc et récupération de données quotidiennes : effectuez l'analyse, le développement et l'extraction de données en fonction des besoins de l'entreprise.
02 Architecture et points faibles
Dans les premiers entrepôts de données hors ligne, les données provenaient principalement d'Oracle, MySQL, MongoDB, Elasticsearch et de fichiers. En utilisant des outils tels que Sqoop, Spark, des sources de données externes et Shell, les données sont extraites hors ligne dans l'entrepôt de données hors ligne Hive et traitées hiérarchiquement via ODS, DWD, DWS et ADS dans Hive. la couche de service applicatif.
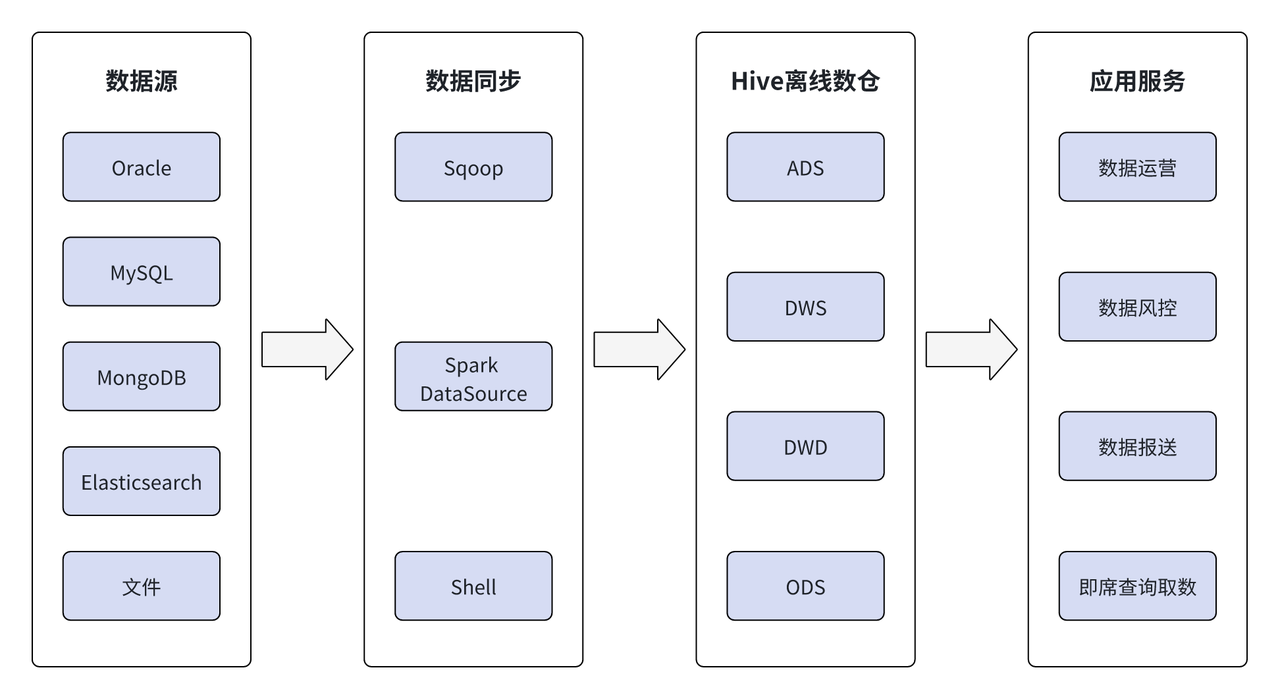
Ces dernières années, avec le développement et l'expansion des activités de la Wuxi Xishang Bank, les départements commerciaux concernés ont des exigences de plus en plus élevées en matière de traitement des données. L'entrepôt de données hors ligne ne peut plus répondre aux nouveaux besoins, ce qui se reflète principalement dans :
-
Actualité des données insuffisante : l'entrepôt de données hors ligne utilise une solution d'extraction hors ligne et l'actualité des données est T+1. Cependant, les rapports, les tableaux de bord de données, les indicateurs marketing et les variables de contrôle des risques nécessitent des mises à jour des données en temps réel, ce que l'architecture actuelle ne peut pas satisfaire. .
-
L'efficacité des requêtes de données est faible : une réponse aux requêtes au deuxième niveau et au niveau de la milliseconde est requise. Les moteurs d'exécution d'entrepôt de données hors ligne sont principalement Hive et Spark. Lorsque Hive s'exécute, il décompose la requête en plusieurs tâches MapReduce et doit lire et écrire des données dans HDFS. Le temps d'exécution est généralement infime, ce qui affecte sérieusement la requête. efficacité.
-
Coûts de maintenance élevés : la couche inférieure de l'entrepôt de données hors ligne implique de nombreuses piles technologiques, notamment LDAP, Ranger, ZooKeeper, HDFS, YARN, Hive, Spark et d'autres systèmes, ce qui entraînera des coûts de maintenance du système élevés. Bien qu'il existe également du stockage en temps réel et des services en ligne de HBase + Phoenix, il ne peut toujours pas résoudre complètement le problème actuel car ses composants sont relativement "lourds", la communauté n'est pas active et certaines fonctionnalités ne peuvent pas répondre aux besoins du temps réel. scénarios.
Sélection technologique
Face aux problèmes liés au manque de rapidité des entrepôts de données hors ligne, à la faible efficacité des requêtes et aux coûts de maintenance élevés causés par plusieurs piles technologiques, la construction d'entrepôts de données en temps réel est impérative. Après avoir mené des recherches approfondies sur plusieurs bases de données MPP, la Wuxi Xishang Bank a décidé de créer une plate-forme d'entrepôt de données en temps réel avec Apache Doris comme noyau. Cette sélection technologique vise à garantir que la plateforme puisse répondre aux exigences élevées de l'analyse commerciale en temps réel aux niveaux de l'écriture des données, des requêtes et du service. Les raisons du choix d'Apache Doris sont les suivantes :
-
Mise à jour efficace des données : Apache Doris Unique Key prend en charge les mises à jour de données par lots volumineux, l'écriture en temps réel de petites données par lots et les modifications légères de la structure des tables. En particulier lors du traitement d'une grande quantité de données et de partitions, il peut efficacement éviter le problème d'énormes quantités de modifications et de modifications inexactes, fournissant ainsi des mises à jour de données plus pratiques et en temps réel.
-
Écriture en temps réel à faible latence : prend en charge l'écriture, la mise à jour et la suppression en temps réel des données au deuxième niveau ; prend en charge la fusion en temps d'écriture du modèle de table de clé primaire, permettant l'écriture en temps réel à haute fréquence de micro-lots et de supports ; Modèle de clé primaire Paramètres de colonne de séquence pour garantir l'ordre d'importation des données dans le processus.
-
Excellentes performances de requête : Apache Doris dispose de puissantes capacités de jointure multi-tables. S'appuyant sur le moteur d'exécution vectoriel, l'optimiseur de requêtes CBO, l'architecture MPP, les vues matérialisées intelligentes et d'autres fonctions, il peut obtenir une réponse aux requêtes au niveau de la milliseconde pour des données massives, satisfaisant des données instantanées. requêtes. Dans le même temps, Apache Doris version 2.0 prend en charge le stockage mixte de lignes et de colonnes et peut obtenir des dizaines de milliers de réponses simultanées au niveau de la milliseconde dans des scénarios de requêtes ponctuelles.
-
La plateforme est extrêmement simple à utiliser : elle est compatible avec le protocole MySQL et fournit des interfaces API riches, ce qui peut réduire la difficulté d'utilisation des applications de couche supérieure. Dans le même temps, Apache Doris a une architecture rationalisée, avec seulement deux processus, FE et BE. Il simplifie l'expansion et la contraction des nœuds, prend en charge la gestion des clusters et la gestion de la copie de données. Il présente les caractéristiques d'un déploiement simple, d'un faible coût d'utilisation et d'un faible coût d'utilisation. faible coût d’exploitation et de maintenance.
Présentation d'Apache Doris pour créer un entrepôt de données Big Data en temps réel
En avril 2022, la Wuxi Xishang Bank a présenté Apache Doris pour créer une plateforme d'entrepôt de données en temps réel. Étant donné que l'échelle des données bancaires est très vaste, il est difficile de synchroniser la totalité des données historiques de la base de données commerciale tout en accédant aux données en temps réel. Par conséquent, la construction initiale des données en temps réel repose principalement sur des données hors ligne.
Premièrement, la méthode HDFS Broker est utilisée pour initialiser efficacement les données historiques en temps réel ; en même temps, l'outil de collecte DataPipeline est utilisé pour collecter les données dans le cluster Kafka en temps réel, puis Flink écrit le mode codé en dur dans écrire les données dans Apache Doris en temps réel. Enfin, grâce aux capacités de service d'interface de la plateforme Feiliu, Apache Doris est utilisé comme moteur de stockage et de requête unifié pour fournir des services pour chaque secteur d'activité.
La plateforme Feiliu est une plateforme complète unifiée construite par la Wuxi Xishang Bank pour faire face aux futurs scénarios commerciaux en temps réel. Elle comprend principalement la collecte en temps réel, les outils de synchronisation en temps réel, l'entrepôt de données en temps réel , le calcul en temps réel et les services de données. .
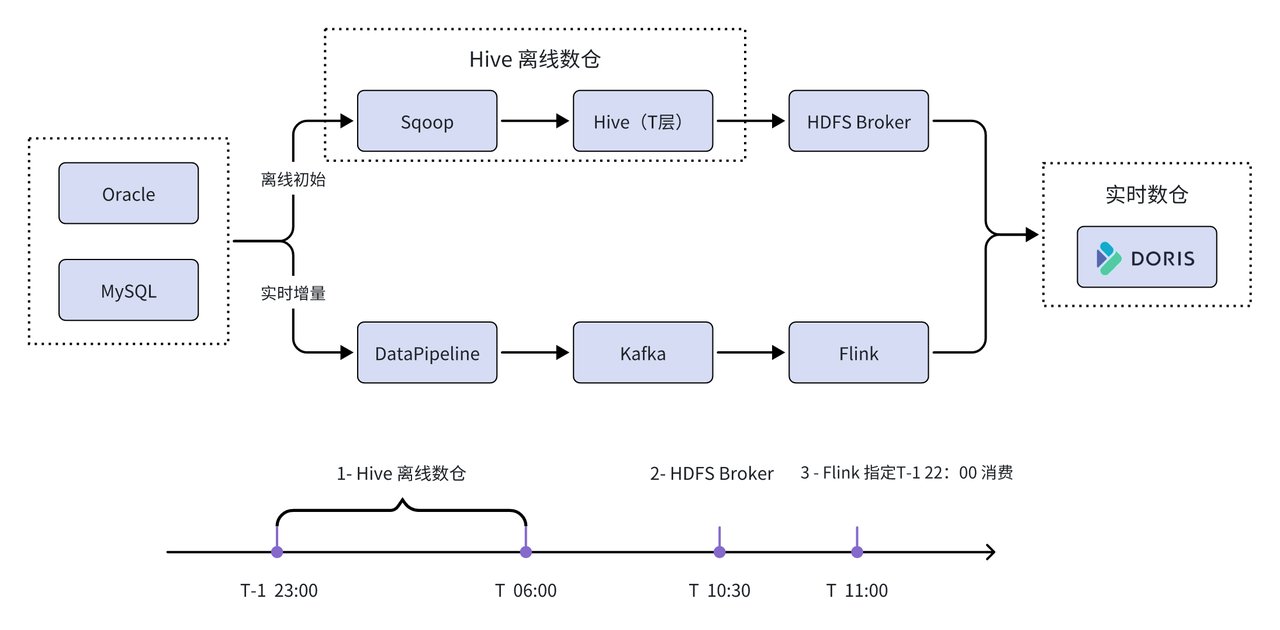
01 Améliorer les liens de flux de données
Partant des caractéristiques des données bancaires et combinant les avantages fonctionnels d'Apache Doris, Wuxi Xishang Bank a repensé et amélioré la liaison des flux de données :
-
La synchronisation des données historiques à partir d'entrepôts de données hors ligne minimise les risques : l'article mentionne qu'en raison de l'énorme quantité de données bancaires, si la totalité des données historiques est synchronisée directement depuis Oracle et MySQL, une grande quantité de données circulera à travers des pare-feu et des commutateurs. provoquant le blocage d'autres demandes commerciales et des problèmes tels que l'expiration du délai de service. Afin d'éviter ces risques et problèmes potentiels, créez d'abord la structure de table Doris par lots basés sur Oracle et MySQL, puis utilisez HDFS Broker pour synchroniser l'intégralité des données T-1 de la couche Hive ODS de l'entrepôt de données hors ligne avec Doris, minimisant ainsi des risques.
-
Extraction incrémentielle en temps réel, mode d'extraction plus sûr : l'extraction en temps réel produira une très petite quantité de consommation d'E/S disque, de mémoire et de CPU afin d'éviter d'affecter la base de données métier principale, par défaut, la base de données esclave métier ou la même. la récupération après sinistre de la ville sera sélectionnée. L'extraction de la bibliothèque en temps réel. Pour les besoins commerciaux exigeant des délais élevés, une évaluation complète est requise avant que les données puissent être extraites de la base de données commerciale principale.
-
Créez la couche Kafka pour garantir la cohérence des données : créez la couche Kafka en tant que couche de transmission de données intermédiaire pour garantir l'ordre et la cohérence des données. La clé des données envoyées par Datapipeline est configurée comme Database-Table-PK, et elle est envoyée à une partition (Partition) de Kafka Topic de manière ordonnée selon la même dimension. Étant donné que les partitions respectives de Kafka Topic sont stockées dans l'ordre, les consommateurs en aval peuvent traiter les données afin d'éviter des effets désordonnés sur l'exactitude des données de l'entrepôt de données en temps réel. De plus, la couche Kafka peut être utilisée comme couche publique de données et peut être utilisée dans le marketing, le contrôle des risques et d'autres scénarios commerciaux.
-
Les données sont écrites en temps réel pour garantir qu'elles ne sont pas perdues ou dupliquées : dans des scénarios d'application réels, la liaison hors ligne effectue un traitement par lots de données hors ligne de 23 heures à 6 heures du matin le jour T-1 et utilise la méthode HDFS Broker à 10 heures. horloge au jour T. Initialisation des données historiques de la table. Le lien en temps réel utilise Flink pour pointer directement vers le sujet Kafka consommé à T-1 à 22 heures pour la synchronisation des données en temps réel. Cependant, certaines données qui se chevauchent apparaîtront pendant le processus de consommation en temps réel. Pour résoudre ce problème, le modèle Unique Key d'Apache Doris est sélectionné (ce modèle prend en charge l'idempotence des données), qui peut rapidement couvrir les données qui se chevauchent, et le Flink-Doris-Connector est utilisé pour améliorer la liaison de l'entrepôt de données en temps réel afin de garantir ; une synchronisation cohérente des données en temps réel. Ce n’est pas lourd à jeter.
02 Services de données flexibles
Afin de fournir des réponses précises et efficaces aux requêtes, la Wuxi Xishang Bank a adopté les trois méthodes suivantes pour mettre en œuvre les services de données :
-
Requête de données hors ligne : pour les besoins hors ligne, les données doivent être rapidement interrogées. La Wuxi Xishang Bank importe régulièrement des données de l'entrepôt de données hors ligne vers la table Doris de l'entrepôt de données en temps réel. Cela permet d'effectuer des requêtes rapides dans l'entrepôt de données en temps réel pour répondre aux besoins d'analyse des données et de prise de décision hors ligne.
-
Exigences simples en temps réel : Pour des exigences simples en temps réel, la Wuxi Xishang Bank utilise les capacités de requête efficaces d'Apache Doris pour offrir la possibilité de configurer directement l'interface du service de données sur la plate-forme « Fei Liu ». Les utilisateurs peuvent utiliser SQL basé sur le. Couche ODS de l'entrepôt de données en temps réel Effectuer une configuration manuelle. De cette manière, les besoins de simples requêtes de données en temps réel peuvent être rapidement satisfaits.
-
Exigences complexes en temps réel : pour les exigences complexes en temps réel, la banque Wuxi Xishang utilise le flux de données Kafka en temps réel et l'informatique légère Flink pour écrire le flux de données dans la table de couche DWD de l'entrepôt de données en temps réel, et en fonction des détails sur la plate-forme "Fei Liu" Le SQL de la table est à nouveau agrégé et l'interface du service de données est configurée manuellement pour répondre aux besoins de requêtes de données complexes en temps réel.
Faire face à des scénarios de service plus diversifiés
01 Réponse à la requête du rapport BI en quelques secondes
Basée sur Apache Doris, Wuxi Xishang Bank répond aux besoins de plusieurs scénarios tels que l'analyse quotidienne des données, la récupération quotidienne des données et les rapports BI en temps réel. Le temps de réponse aux requêtes est considérablement réduit et les résultats de la requête peuvent être renvoyés en 1 seconde , ce qui est très rapide. réduit considérablement le temps d'attente des analystes de données. Coût et consommation des ressources du serveur.
Par exemple, en termes de rapports BI en temps réel, la Wuxi Xishang Bank a établi des tableaux de données de prêt en temps réel, des tableaux de données de dépôt en temps réel, des tableaux de soldes de comptes et d'autres rapports. **Ces rapports contiennent en moyenne 253 lignes de code SQL et un temps de réponse moyen de 1,5 seconde. **De plus, en optimisant les performances des requêtes et la conception du modèle de données, la Wuxi Xishang Bank peut générer des rapports précis en temps réel dans un court laps de temps afin de fournir en temps opportun un support de données pour les décisions commerciales.
02 Soutenir les plans marketing personnalisés
En termes de services de données marketing, la Wuxi Xishang Bank s'est basée sur Apache Doris pour enrichir les étiquettes des clients et améliorer les portraits précis des clients, et a mené diverses activités de marketing telles que des activités d'augmentation de l'actif net et des activités de boîte aveugle d'artistes. Grâce à l'analyse des données en temps réel, les banques peuvent observer en temps opportun l'état de conversion des utilisateurs actifs et ajuster rapidement la stratégie de sélection des opérations pour obtenir un marketing personnalisé de « mille personnes ont un visage » à « mille personnes en ont un ». affronter".
Par exemple, dans les activités de marketing telles que les activités d'augmentation de l'actif net et les activités de boîte aveugle des artistes, la Wuxi Xishang Bank utilise les capacités de l'entrepôt de données en temps réel Apache Doris pour collecter, analyser et commenter en continu les données d'activité. En observant les conversions des utilisateurs en temps réel, nous pouvons ajuster rapidement la stratégie de sélection des opérations pour garantir l'adéquation entre le personnel et les activités. Cette stratégie marketing personnalisée permet aux banques de mieux répondre aux besoins des clients et d’augmenter l’engagement, les taux de réponse et la fidélité des utilisateurs.
03 Identification et contrôle efficaces des risques
L'introduction d'Apache Doris permet à la Wuxi Xishang Bank de calculer plus rapidement les variables caractéristiques du contrôle des risques et les comportements de transaction anormaux. En prenant comme exemple l'enregistrement des nouveaux utilisateurs, lorsque les utilisateurs remplissent des informations, le système peut déterminer rapidement les résultats de la stratégie d'approbation sur la base de variables caractéristiques du contrôle des risques en temps réel, optimiser le modèle de stratégie en temps opportun et garantir la qualité et l'exactitude. d'approbation.
La Wuxi Xishang Bank est également en mesure d'identifier et de prévenir les risques potentiels en temps opportun. Par exemple, les banques peuvent collecter et surveiller en temps réel des données de transaction telles qu'un grand nombre de transactions et des montants de transactions anormaux sur une courte période de temps, afin de détecter en temps opportun les comportements de transaction anormaux et les fraudes. Grâce à l'analyse des données en temps réel, les banques peuvent identifier rapidement les risques potentiels et prendre les mesures appropriées pour les prévenir et y répondre.
En outre, la Wuxi Xishang Bank utilise également l'entrepôt de données en temps réel Apache Doris pour effectuer une analyse en temps réel des antécédents de crédit des clients et des informations sur les demandes de crédit. En déterminant rapidement si le montant demandé par le client correspond à sa capacité de remboursement, les banques peuvent évaluer les risques et prendre des décisions en temps opportun pour contrôler efficacement les risques de crédit.
04 Les données du schéma de flux de négociation sur sept jours sont automatiquement mises à jour.
Dans les scénarios d'application réels, la quantité de données dans le schéma de flux de transactions est très importante, impliquant le numéro de série de la transaction, la date de la transaction, le type de transaction, le montant de la transaction et d'autres données. Afin de garantir une mise à jour rapide des données, la Wuxi Xishang Bank a choisi d'utiliser la fonctionnalité de la table de partition dynamique Apache Doris. Cette fonctionnalité peut créer automatiquement des partitions et supprimer automatiquement les données de flux de transactions datant de plus de sept jours pour obtenir une mise à jour automatique des données dans la table de flux de transactions sur sept jours. Les opérations spécifiques comprennent les étapes suivantes :
-
Construisez une pseudo-colonne avec la date commerciale comme clé primaire commune ;
-
Lorsque les données d'identification sont
tran_datemises à jour au fil des jours, le code effectue une opération de retour de table ; -
Recherchez la valeur Date correspondante dans la table d'insertion et de partition des données, fusionnez-la dans Update Json et mettez-la à jour dans la base de données.

Avec l'aide de la fonctionnalité de partitionnement dynamique et de partitionnement de table d'Apache Doris, il peut non seulement garantir le fonctionnement stable de la clé primaire et du serveur sous-jacents, mais également mettre à jour et conserver automatiquement sept jours seulement de données de transaction pour que les analystes puissent les interroger et répondre aux exigences. Exigence de réponse aux requêtes en 1,5 seconde inférieure à un million de QPS .
05 Requête de points à haute concurrence
Les premiers scénarios d'application de marketing et de contrôle des risques reposaient principalement sur deux ensembles de clusters HBase pour prendre en charge les services d'énumération. Cependant, dans les applications réelles, des problèmes tels qu'une sortie anormale du serveur maître/région et RIT seront rencontrés. Pour éviter ce problème, vous pouvez tirer parti de la capacité élevée de requêtes simultanées d'Apache Doris et activer la stratégie de fusion sur écriture lors de la création de la table de clé unique, afin que la requête de clé primaire puisse être complétée via un chemin d'exécution SQL simplifié, avec un seul RPC requis. Réponse rapide et complète à la requête.
Enfin, grâce à des tests de résistance sur trois nœuds, chaque nœud étant configuré avec 8C et 10 Go, les avantages significatifs suivants ont été obtenus :
-
Dans un scénario de requête dans lequel une seule table contient 50 millions de données, le QPS peut atteindre 25 000 ;
-
Dans un scénario de lecture et d'écriture multi-tables impliquant 50 millions de données, le QPS atteint également 20 000 ;
-
La stabilité des requêtes SQL complexes reste également à un niveau élevé de 25 000 QPS ;
-
Dans le scénario de lecture et d'écriture en temps réel de plusieurs tables, le QPS peut également être stabilisé à 25 000.
Conclusion
À l'heure actuelle, Apache Doris a accédé à des centaines de tables en temps réel, à des centaines d'interfaces de services de données et à des QPS d'interface atteignant des millions dans la banque Wuxi Xishang. De plus, Apache Doris, en tant que passerelle de requêtes unifiée, améliore considérablement l'efficacité de l'analyse des données historiques. Par rapport au temps de réponse initial de l'ordre d'une minute, la vitesse de requête est plus de 10 fois.
À l'avenir, la Wuxi Xishang Bank continuera d'explorer les avantages d'Apache Doris et de promouvoir son application plus approfondie dans des scénarios en temps réel.
-
En termes de performances : optimiser davantage les requêtes à haute concurrence, le partitionnement et le regroupement automatiques, le moteur d'exécution et d'autres fonctionnalités pour améliorer l'efficacité des réponses aux requêtes de données ;
-
En termes d'équilibrage de charge : créez des clusters doubles pour obtenir un équilibrage de charge architectural ; en même temps, les mécanismes d'alerte précoce et de disjoncteur de l'architecture seront améliorés pour garantir des opérations commerciales ininterrompues ;
-
En termes de stabilité du cluster : Réaliser la « division du travail et la collaboration » du cluster Apache Doris, afin que chacun d'eux puisse entreprendre des tâches telles que le calcul et le stockage de l'entrepôt de données en temps réel, l'interrogation accélérée des services de données, etc., pour améliorer encore la stabilité et la fiabilité du système.