
En tant que l'un des piliers du fonctionnement de la société moderne, le système de réseau électrique fournit un soutien de base en énergie électrique à tous les horizons et à des milliers de foyers. Des maisons aux entreprises, des hôpitaux aux écoles, des transports aux communications, les réseaux électriques sont utilisés partout. Ces dernières années, les stations de conversion UHV sont devenues un projet de construction clé de la State Grid Corporation of China. Au cours de la période du « 14e plan quinquennal », la State Grid Corporation of China prévoit de construire un projet UHV de « 24 AC et 14 ». DC", impliquant plus de 30 000 kilomètres de lignes et une capacité de conversion et de conversion de 340 millions de kVA, avec un investissement total de 380 milliards de yuans.
La conférence de travail de 2024 du State Grid a proposé de continuer à accroître la construction de réseaux électriques puissants, numériques et intelligents. Le réseau électrique fort numérique et intelligent est une nouvelle forme de réseau électrique qui intègre profondément les technologies numériques et intelligentes dans le processus de production, d'exploitation et de gestion du réseau électrique. Le développement de l’intelligence numérique a mis en avant des exigences plus élevées pour l’utilisation des données par State Grid. Grâce à la construction de plates-formes de bases de données de séries chronologiques dans le cloud et côté station, l'efficacité de l'utilisation des données de séries chronologiques peut être efficacement améliorée, les coûts d'utilisation peuvent être considérablement réduits et une garantie de base de données solide peut être fournie pour la construction de l'intelligence numérique du State Grid.
Contexte du projet
Le projet de station de conversion numérique est un projet clé de l’intelligence numérique de State Grid. Chaque station de conversion UHV dispose de milliers d'appareils intelligents de grande et moyenne taille, traitant des données de précision de l'ordre de la milliseconde provenant de centaines de milliers de points de mesure, générant chaque jour des centaines de millions de lignes d'ensembles de données de séries chronologiques.
Face à des besoins aussi massifs en matière d'écriture de données de séries chronologiques, de gestion des requêtes et d'analyses, les produits de bases de données de séries chronologiques tels que CeresDB, InfluxDB ou auto-développés basés sur InfluxDB qui étaient auparavant utilisés sur le site ne peuvent plus répondre aux besoins. Dans le même temps, State Grid doit briser les îlots de données à chaque station et réaliser l'intégration des données aux deux extrémités de la station cloud.
Après des recherches approfondies et des tests de performances du produit, State Grid a finalement choisi d'utiliser le produit « GreptimeDB Time Series Database Enterprise Edition » de Greptime Technology comme « plate-forme de gestion de données de séries chronologiques station + cloud » pour le projet de station de conversion numérique, réalisant le convertisseur numérique. station L'intégration et l'utilisation efficaces des données de séries chronologiques entre stations et la réponse du traitement des données avec une précision de l'ordre de la milliseconde fournissent une base de données de haute qualité pour la construction de l'intelligence numérique de la State Grid.
Défis du projet
Avec l'accélération de la construction numérique du State Grid et la popularisation rapide des applications numériques, les exigences en matière de qualité et de vitesse de réponse des données de séries chronologiques sous-jacentes deviennent de plus en plus élevées. Les problèmes liés à l’utilisation des données continuent de croître :
1. Ilots de données de séries chronologiques
En raison de problèmes tels que les différences dans les délais de construction et les différences dans la sélection des intégrateurs de construction à chaque station, la base de données de séries chronologiques finales et l'architecture des données des différentes stations sont incohérentes, ce qui rend difficile l'obtention de données de séries chronologiques standardisées de haute qualité, affectant applications avancées et intelligence artificielle au niveau de la station et du cloud. La mise en œuvre à grande échelle des services a formé un îlot de données côté site.
2. Utilisation inefficace des données
Réponse lente aux données de séries chronologiques massives
Avec le déploiement de capteurs à grande échelle, la quantité de données de séries chronologiques que chaque station doit traiter chaque jour atteint des centaines de millions de lignes. La capacité d'écrire, d'interroger et d'analyser des données de séries chronologiques massives diminue et le temps de réponse devient plus long. de plus en plus lentement.
Faibles capacités de calcul des données de séries chronologiques et investissements importants en R&D
Lorsque le côté application met en avant des exigences plus élevées en matière de compatibilité des données de séries chronologiques et des capacités de calcul des données, State Grid doit investir d'énormes ressources en R&D pour répondre à certains des besoins.
3. Les coûts d'utilisation des données sont élevés
À mesure que la quantité de données devient de plus en plus importante, le coût du téléchargement des données et des ressources de cloud computing augmente également de façon exponentielle.
Solutions et architecture
architecture du produit
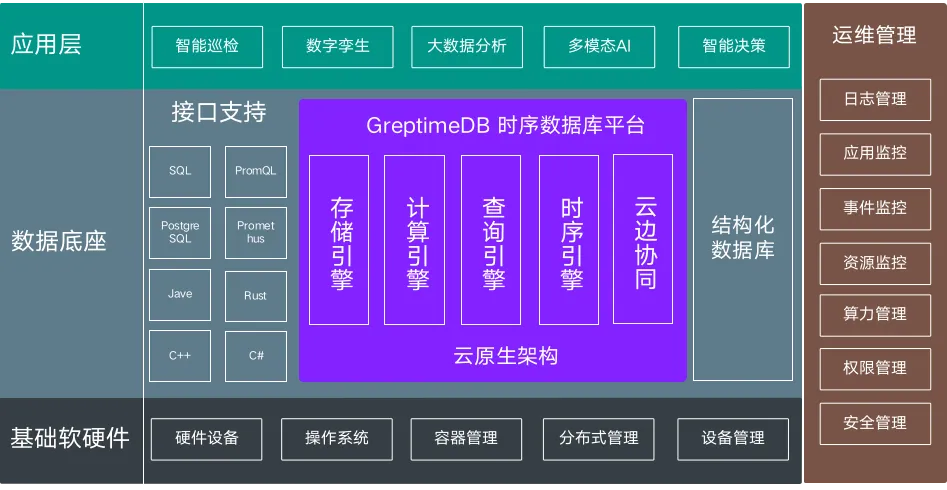
Schéma d'architecture de base de données
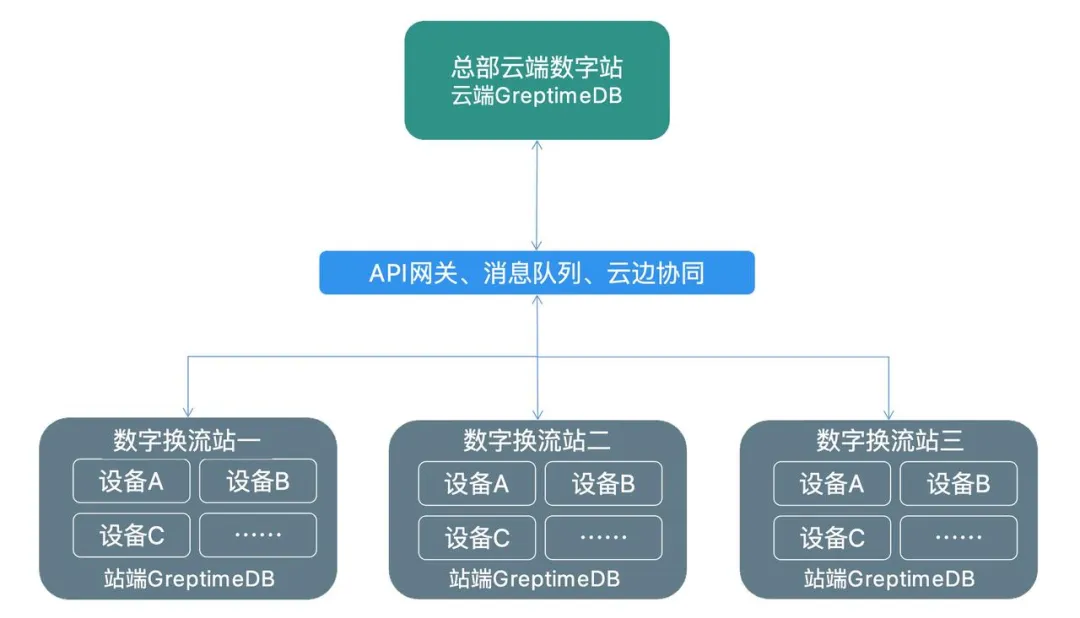
Schéma d'architecture d'entreprise
En tant que produit de base de données de base de la base de données de la station de conversion numérique State Grid, GreptimeDB assume la responsabilité du stockage des données de séries chronologiques, de l'interrogation, du calcul et de la gestion des équipements dans la station de conversion ; de données de séries chronologiques massives La réponse précise du traitement fournit une garantie de base de données pour l'application numérique du State Grid.
résultat du projet
1. Brisez les silos de données
GreptimeDB unifie les formats et modèles de données du cloud et de la station, permettant une intégration et une collaboration efficaces des données côté station et des données cloud de dizaines de stations de conversion numérique.
2. Obtenez une réponse de traitement précise à la milliseconde pour des données massives
GreptimeDB peut facilement réaliser chaque jour l'écriture, l'interrogation et l'analyse en temps réel de centaines de millions de lignes de données de séries chronologiques sur le site avec une précision de la milliseconde, fournissant une garantie de données de base fiable pour des applications telles que les jumeaux numériques, l'exploitation et la maintenance intelligentes et artificielles. intelligence.
3. Réduisez les coûts d’utilisation des données
GreptimeDB peut prendre en charge plus de 30 fois la capacité de compression sans perte de données, l'isomorphisme des données de fin de cloud et les capacités de calcul de pointe, réduisant considérablement les coûts de stockage de données, la surcharge des ressources de cloud computing et les coûts de trafic de téléchargement de données.
En tant que projet open source, GreptimeDB invite les étudiants intéressés par les bases de données de séries chronologiques, le langage Rust, etc. à participer aux contributions et aux discussions. Il est recommandé aux étudiants qui participent à un projet pour la première fois de commencer par le numéro avec la balise good first issue. Nous avons hâte de vous rencontrer dans la communauté open source ! Star nous sur GitHub maintenant : https://github.com/GreptimeTeam/greptimedb Recherchez GreptimeDB sur WeChat et suivez le compte officiel pour ne pas manquer plus d'informations techniques et d'avantages ~
À propos de Greptime
Greptime Greptime se concentre sur la fourniture de services efficaces de stockage et d'analyse de données en temps réel pour des domaines tels que l'Internet des objets (tels que l'énergie intelligente, les voitures intelligentes, etc.) et l'observabilité qui génèrent de grandes quantités de données de séries chronologiques, aidant ainsi les clients à exploiter le valeur profonde des données. Il existe actuellement trois produits principaux :
GreptimeDB est une base de données de séries chronologiques open source écrite en langage Rust. Elle présente les caractéristiques d'une expansion horizontale native et illimitée dans le cloud, de hautes performances, d'analyse intégrée, etc. Elle aide les entreprises à lire, écrire, traiter et analyser des données de séries chronologiques en temps réel. réduisant le coût du stockage à long terme. Nous fournissons GreptimDB Enterprise Edition, qui prend en charge plus de fonctions et de services personnalisés. Si nécessaire, veuillez contacter l'assistant : 15310923206 (identique à WeChat).
GreptimeCloud est une solution de base de données cloud en tant que service (DBaaS) entièrement gérée basée sur la base de données de séries chronologiques open source GreptimeDB, qui peut prendre en charge efficacement les applications dans les domaines de l'observabilité, de l'Internet des objets, de la finance et d'autres domaines. Les utilisateurs peuvent comprendre de manière globale le coût, les performances, le trafic et la sécurité des applications LLM grâce à la solution observable intégrée GreptimeAI.
La solution car-cloud intégrée est une solution de données collaborative car-cloud qui approfondit les scénarios commerciaux réels des constructeurs automobiles et résout les problèmes commerciaux réels après la croissance exponentielle des données sur les véhicules de l'entreprise. La base de données multimodale embarquée combinée à l'édition cloud GreptimeDB Enterprise Edition aide les constructeurs automobiles à réduire considérablement les coûts de trafic, de calcul et de stockage, et contribue à améliorer les données en temps réel et les capacités d'analyse commerciale.
En tant que projet open source, GreptimeDB invite les étudiants intéressés par les bases de données de séries chronologiques, le langage Rust, etc. à participer aux contributions et aux discussions. Il est recommandé aux étudiants qui participent à un projet pour la première fois de commencer par le numéro avec la balise good first issue. Nous avons hâte de vous rencontrer dans la communauté open source !
Site officiel : https://greptime.cn/ GitHub : https://github.com/GreptimeTeam/greptimedb Documents : https://docs.greptime.cn/ Twitter : https://twitter.com/Greptime Slack : https : //www.greptime.com/slack LinkedIn : https://www.linkedin.com/company/greptime
Un programmeur né dans les années 1990 a développé un logiciel de portage vidéo et en a réalisé plus de 7 millions en moins d'un an. La fin a été très éprouvante ! Des lycéens créent leur propre langage de programmation open source en guise de cérémonie de passage à l'âge adulte - commentaires acerbes des internautes : s'appuyant sur RustDesk en raison d'une fraude généralisée, le service domestique Taobao (taobao.com) a suspendu ses services domestiques et repris le travail d'optimisation de la version Web Java 17 est la version Java LTS la plus utilisée Part de marché de Windows 10 Atteignant 70 %, Windows 11 continue de décliner Open Source Daily | Google soutient Hongmeng pour prendre le relais des téléphones Android open source pris en charge par Docker ; Electric ferme la plate-forme ouverte Apple lance la puce M4 Google supprime le noyau universel Android (ACK) Prise en charge de l'architecture RISC-V Yunfeng a démissionné d'Alibaba et prévoit de produire des jeux indépendants sur la plate-forme Windows à l'avenir