
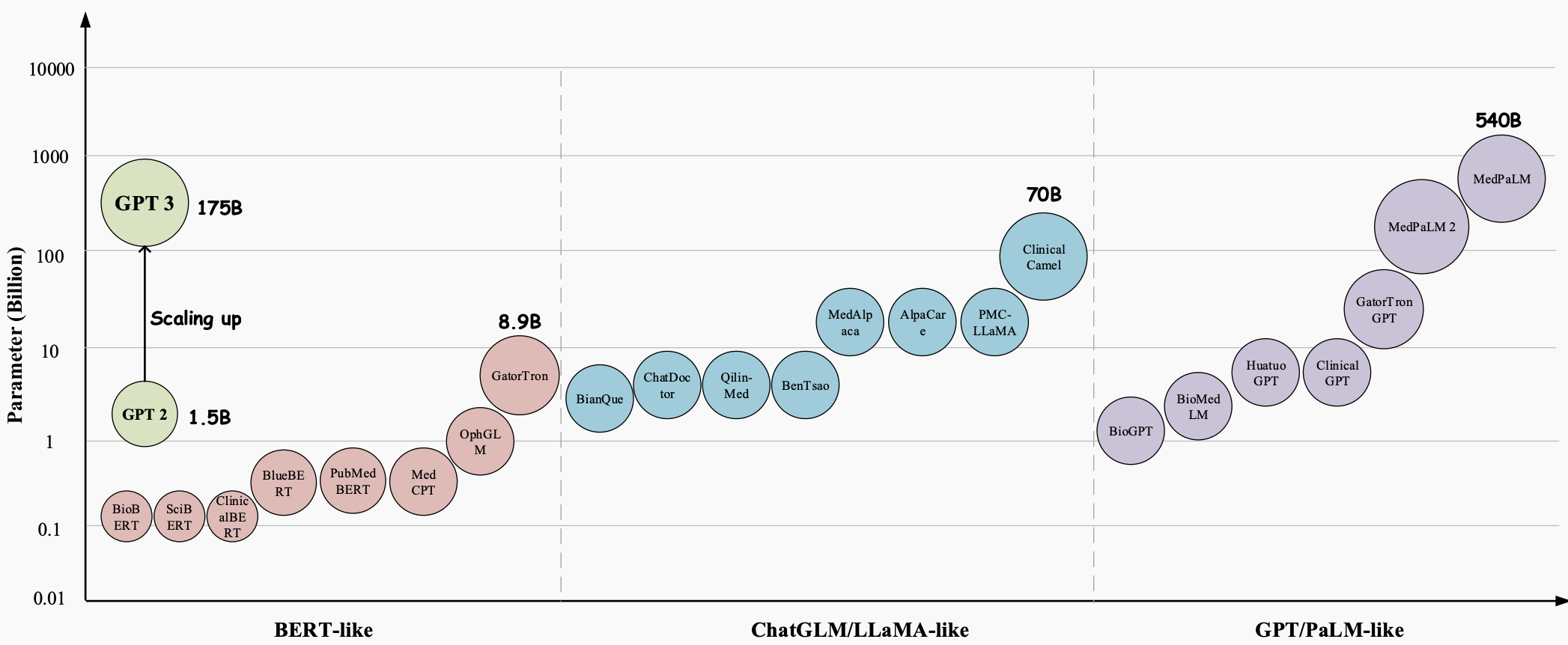
Au fil des années, les grands modèles linguistiques (LLM) sont devenus une technologie révolutionnaire dotée d’un énorme potentiel pour révolutionner tous les aspects du secteur de la santé. Ces modèles, tels que GPT-3 , GPT-4 et Med-PaLM 2 , ont démontré des capacités supérieures dans la compréhension et la génération de textes de type humain, ce qui en fait des outils précieux pour gérer des tâches médicales complexes et améliorer les soins aux patients. Ils se révèlent très prometteurs dans diverses applications médicales, telles que la réponse aux questions médicales (AQ), les systèmes de dialogue et la génération de texte. De plus, avec la croissance exponentielle des dossiers de santé électroniques (DSE), de la littérature médicale et des données générées par les patients, les LLM peuvent aider les professionnels de la santé à extraire des informations précieuses et à prendre des décisions éclairées.
Cependant, malgré l’énorme potentiel des grands modèles linguistiques (LLM) dans le domaine médical, il reste encore des défis importants et spécifiques à résoudre.
Lorsque le modèle est utilisé dans le contexte de conversations de divertissement, l’impact des erreurs est minime. Toutefois, ce n’est pas le cas lorsqu’il est utilisé dans le domaine médical, où des interprétations et des réponses incorrectes peuvent avoir de graves conséquences sur les soins et les résultats des patients. L’exactitude et la fiabilité des informations fournies par les modèles linguistiques peuvent être une question de vie ou de mort, car elles peuvent avoir un impact sur les décisions médicales, les diagnostics et les plans de traitement.
Par exemple, lorsqu'on a demandé au GPT-3 quels médicaments les femmes enceintes pouvaient utiliser, le GPT-3 a recommandé à tort la tétracycline, même s'il a également indiqué à juste titre que la tétracycline est nocive pour le fœtus et ne devrait pas être utilisée par les femmes enceintes. Si vous suivez vraiment ces mauvais conseils et donnez des médicaments aux femmes enceintes, cela pourrait entraîner une mauvaise croissance des os de l'enfant à l'avenir.

Pour faire bon usage de modèles de langage aussi vastes dans le domaine médical, ces modèles doivent être conçus et comparés en fonction des caractéristiques de l’industrie médicale. Les données et applications médicales ayant leurs propres particularités, celles-ci doivent être prises en compte. Et il est en fait important de développer des méthodes pour évaluer ces modèles à des fins médicales, non seulement pour la recherche, mais aussi parce qu'ils pourraient présenter des risques s'ils étaient utilisés de manière incorrecte dans le travail médical réel.
Le classement Open Source Medical Large Model Ranking vise à relever ces défis et limitations en fournissant une plate-forme standardisée pour évaluer et comparer les performances de divers grands modèles de langage sur une variété de tâches et d'ensembles de données médicaux. En fournissant une évaluation complète des connaissances médicales et des capacités de réponse aux questions de chaque modèle, le classement favorise le développement de modèles médicaux plus efficaces et plus fiables.
Cette plateforme permet aux chercheurs et aux praticiens d'identifier les forces et les faiblesses de différentes approches, de stimuler le développement dans le domaine et, à terme, de contribuer à améliorer les résultats pour les patients.
Ensembles de données, tâches et paramètres d'évaluation
Le classement médical des grands modèles contient une variété de tâches et utilise la précision comme principale mesure d'évaluation (la précision mesure le pourcentage de réponses correctes fournies par le modèle de langage dans divers ensembles de données de questions et réponses médicales).
MedQA
L'ensemble de données MedQA contient des questions à choix multiples de l'examen de licence médicale des États-Unis (USMLE). Il couvre un large éventail de connaissances médicales et comprend 11 450 questions d’ensemble de formation et 1 273 questions d’ensemble de test. Avec 4 ou 5 options de réponse par question, cet ensemble de données est conçu pour évaluer les connaissances médicales et les capacités de raisonnement requises pour obtenir une licence médicale aux États-Unis.

MedMCQA
MedMCQA est un ensemble de données de questions et réponses à choix multiples à grande échelle dérivé de l'examen médical indien d'entrée (AIIMS/NEET). Il couvre 2 400 sujets du domaine médical et 21 sujets médicaux, avec plus de 187 000 questions dans l'ensemble de formation et 6 100 questions dans l'ensemble de tests. Chaque question comporte 4 options de réponse avec des explications. MedMCQA évalue les connaissances médicales générales et les capacités de raisonnement d'un modèle.

PubMedQA
PubMedQA est un ensemble de données de réponse à des questions en domaine fermé où il est possible de répondre à chaque question en examinant le contexte pertinent (résumé PubMub). Il contient 1 000 paires questions-réponses étiquetées par des experts. Chaque question est accompagnée d'un résumé PubMed pour le contexte, et la tâche consiste à fournir une réponse oui/non/peut-être basée sur les informations récapitulatives. L'ensemble de données est divisé en 500 questions de formation et 500 questions de test. PubMedQA évalue la capacité d'un modèle à comprendre et à raisonner sur la littérature scientifique biomédicale.

Sous-ensemble MMLU (médecine et biologie)
Le benchmark MMLU (Measuring Large-Scale Multi-Task Language Understanding) contient des questions à choix multiples provenant de divers domaines. Pour le classement des grands modèles médicaux open source, nous nous concentrons sur le sous-ensemble le plus pertinent pour les connaissances médicales :
- Connaissances cliniques : 265 questions évaluant les connaissances cliniques et les compétences décisionnelles.
- Génétique médicale : 100 questions couvrant des sujets liés à la génétique médicale.
- Anatomie : 135 questions évaluant les connaissances en anatomie humaine.
- Médecine professionnelle : 272 questions qui évaluent les connaissances requises des professionnels de la santé.
- Biologie collégiale : 144 questions couvrant les concepts de biologie de niveau collégial.
- Médecine collégiale : 173 questions évaluant les connaissances médicales de niveau collégial. Chaque sous-ensemble MMLU contient des questions à choix multiples avec 4 options de réponse conçues pour évaluer la compréhension du modèle d'un domaine médical et biologique spécifique.

Les classements des grands modèles médicaux open source fournissent une évaluation robuste des performances du modèle dans divers aspects des connaissances et du raisonnement médicaux.
Aperçus et analyses
Le classement des grands modèles médicaux open source évalue les performances de divers grands modèles de langage (LLM) sur une gamme de tâches de réponse à des questions médicales. Voici quelques-unes de nos principales conclusions :
- Les modèles commerciaux tels que GPT-4-base et Med-PaLM-2 obtiennent systématiquement des scores de précision élevés sur divers ensembles de données médicales, démontrant ainsi de solides performances dans différents domaines médicaux.
- Les modèles open source, tels que Starling-LM-7B , gemma-7b , Mistral-7B-v0.1 et Hermes-2-Pro-Mistral-7B , bien que le nombre de paramètres ne soit que d'environ 7 milliards, fonctionnent bien sur certaines données ensembles et tâches ont fourni des performances compétitives.
- Les modèles commerciaux et open source fonctionnent bien dans des tâches telles que la compréhension et le raisonnement sur la littérature scientifique biomédicale (PubMedQA) et l'application des connaissances cliniques et des compétences de prise de décision (sous-ensemble de connaissances cliniques MMLU).

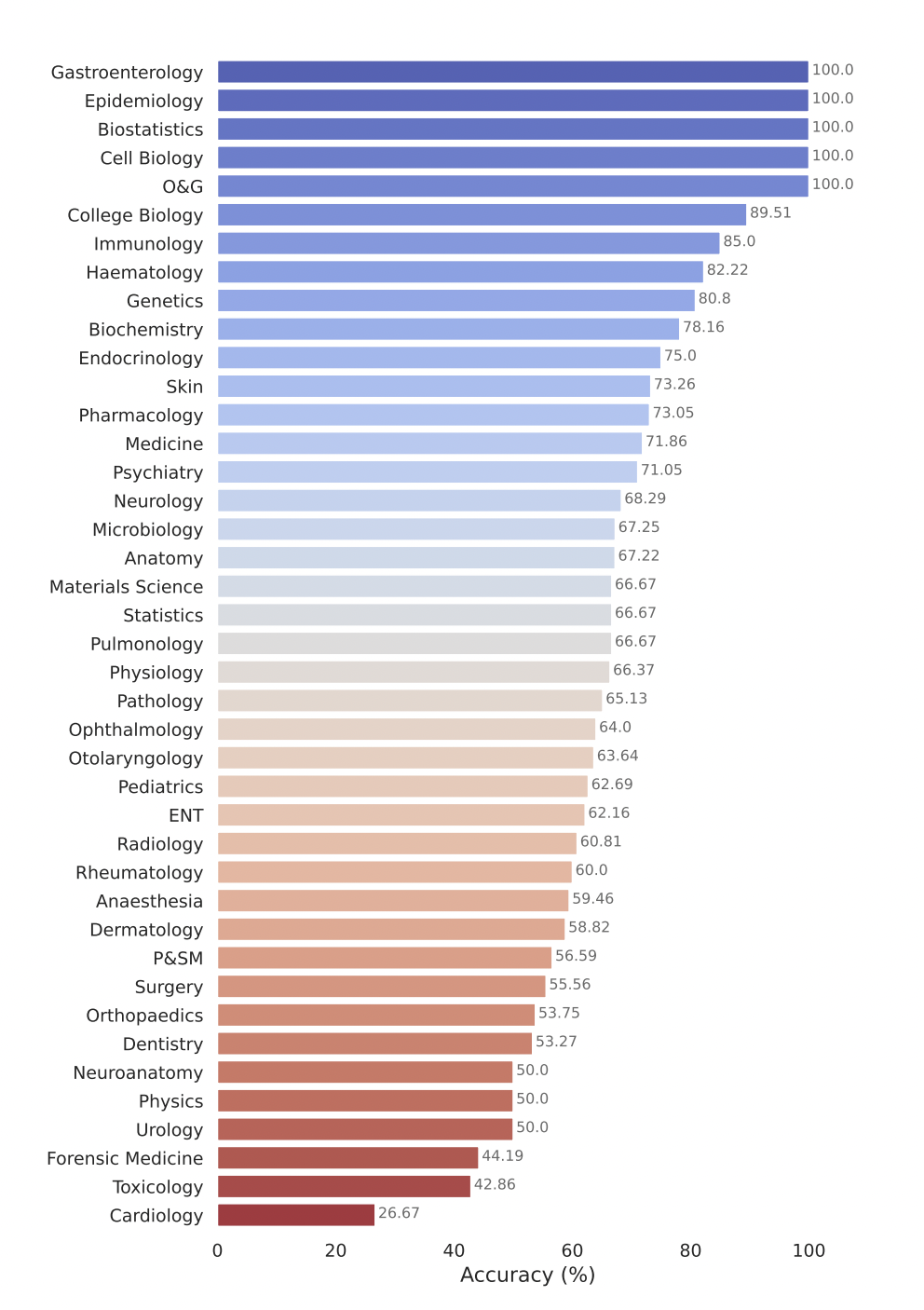
Le modèle Gemini Pro de Google a démontré de solides performances dans plusieurs domaines médicaux, en particulier dans les tâches procédurales et gourmandes en données telles que la biostatistique, la biologie cellulaire, l'obstétrique et la gynécologie. Cependant, il a montré des performances modérées à faibles dans des domaines clés tels que l’anatomie, la cardiologie et la dermatologie, révélant des lacunes qui nécessitent des améliorations supplémentaires pour une application dans une médecine plus complète.
Soumettez votre modèle pour évaluation
Pour soumettre votre modèle pour évaluation dans le classement des grands modèles de soins de santé Open Source, veuillez suivre ces étapes :
1. Convertir les poids du modèle au format Safetensors
Tout d’abord, convertissez les poids de votre modèle au format safetensors. Les Safetensors sont un nouveau format de stockage de poids plus sûr et plus rapide à charger et à utiliser. La conversion de votre modèle dans ce format permettra également au classement d'afficher le nombre de paramètres de votre modèle dans le tableau principal.
2. Assurer la compatibilité avec les AutoClasses
Avant de soumettre le modèle, assurez-vous de pouvoir charger le modèle et le tokenizer à l'aide des AutoClasses dans la bibliothèque Transformers. Utilisez l'extrait de code suivant pour tester la compatibilité :
from transformers import AutoConfig, AutoModel, AutoTokenizer
config = AutoConfig.from_pretrained(MODEL_HUB_ID)
model = AutoModel.from_pretrained("your model name")
tokenizer = AutoTokenizer.from_pretrained("your model name")
Si vous échouez à cette étape, suivez le message d'erreur pour déboguer votre modèle avant de le soumettre. Il est fort probable que votre modèle n'ait pas été téléchargé correctement.
3. Rendez votre modèle public
Assurez-vous que votre modèle est accessible au public. Les classements ne peuvent pas évaluer les modèles privés ou les modèles nécessitant un accès spécial.
4. Exécution de code à distance (à venir)
Actuellement, les classements des grands modèles médicaux open source ne prennent pas en charge les use_remote_code=Truemodèles requis. Cependant, l'équipe du classement ajoute activement cette fonctionnalité, alors restez à l'écoute des mises à jour.
5. Soumettez votre modèle via le site Web du classement
Une fois votre modèle converti au format safetensors, compatible avec les AutoClasses et accessible au public, vous pouvez l'évaluer à l'aide du panneau Soumettre ici ! sur le site Web Open Source Medical Large Model Ranking. Remplissez les informations requises, telles que le nom du modèle, la description et tout détail supplémentaire, puis cliquez sur le bouton Soumettre. L'équipe du classement traitera votre soumission et évaluera les performances de votre modèle sur divers ensembles de données de questions-réponses médicales. Une fois l'évaluation terminée, le score de votre modèle sera ajouté au classement et vous pourrez comparer ses performances avec d'autres modèles.
Et après? Classement élargi des grands modèles médicaux open source
Le classement des grands modèles de soins de santé Open Source s'engage à se développer et à s'adapter pour répondre aux besoins changeants de la communauté de la recherche et du secteur de la santé. Les domaines clés comprennent :
- Intégrez des ensembles de données de santé plus larges couvrant tous les aspects des soins tels que la radiologie, la pathologie et la génomique grâce à une collaboration avec des chercheurs, des organismes de santé et des partenaires industriels.
- Améliorez les mesures d'évaluation et les capacités de reporting en explorant des mesures de performances supplémentaires au-delà de la précision, telles que les scores point à point et les mesures spécifiques à un domaine qui capturent les besoins uniques des applications médicales.
- Des travaux sont déjà en cours dans ce sens. Si vous souhaitez collaborer sur le prochain benchmark que nous prévoyons de proposer, veuillez rejoindre notre communauté Discord pour en savoir plus et vous impliquer. Nous serions ravis de collaborer et de réfléchir !
Si vous êtes passionné par l'intersection de l'IA et des soins de santé, par la création de modèles pour les soins de santé et par les problèmes de sécurité et d'hallucinations des grands modèles médicaux, nous vous invitons à rejoindre notre communauté active sur Discord .
Remerciements

Un merci spécial à tous ceux qui ont contribué à rendre cela possible, notamment Clémentine Fourrier et l'équipe de Hugging Face. Je tiens à remercier Andreas Motzfeldt, Aryo Gema et Logesh Kumar Umapathi pour les discussions et les commentaires lors de l'élaboration du classement. Nous tenons à exprimer nos sincères remerciements au professeur Pasquale Minervini de l'Université d'Édimbourg pour son temps, son assistance technique et son soutien GPU.
À propos de l’IA pour les sciences de la vie ouvertes
Open Life Sciences AI est un projet qui vise à révolutionner l’application de l’intelligence artificielle dans les domaines des sciences de la vie et de la médecine. Il sert de plate-forme centrale qui répertorie les modèles médicaux, les ensembles de données, les références et suit les délais des conférences, favorisant ainsi la collaboration, l'innovation et le progrès dans le domaine des soins de santé assistés par l'IA. Nous nous efforçons de faire de l’Open Life Sciences AI la destination de choix pour toute personne intéressée par l’intersection de l’IA et des soins de santé. Nous fournissons une plate-forme permettant aux chercheurs, cliniciens, décideurs politiques et experts de l'industrie d'engager un dialogue, de partager des idées et d'explorer les derniers développements dans le domaine.

Citation
Si vous trouvez notre évaluation utile, pensez à citer nos travaux
Classement des grands modèles médicaux
@misc{Medical-LLM Leaderboard,
author = {Ankit Pal, Pasquale Minervini, Andreas Geert Motzfeldt, Aryo Pradipta Gema and Beatrice Alex},
title = {openlifescienceai/open_medical_llm_leaderboard},
year = {2024},
publisher = {Hugging Face},
howpublished = "\url{https://huggingface.co/spaces/openlifescienceai/open_medical_llm_leaderboard}"
}
> Texte original anglais : https://hf.co/blog/leaderboard-medicalllm > Auteurs originaux : Aaditya Ura (en recherche de doctorat), Pasquale Minervini, Clémentine Fourrier > Traductrice : innovation64
Un programmeur né dans les années 1990 a développé un logiciel de portage vidéo et en a réalisé plus de 7 millions en moins d'un an. La fin a été très éprouvante ! Des lycéens créent leur propre langage de programmation open source en guise de cérémonie de passage à l'âge adulte - commentaires acerbes des internautes : s'appuyant sur RustDesk en raison d'une fraude généralisée, le service domestique Taobao (taobao.com) a suspendu ses services domestiques et repris le travail d'optimisation de la version Web Java 17 est la version Java LTS la plus utilisée Part de marché de Windows 10 Atteignant 70 %, Windows 11 continue de décliner Open Source Daily | Google soutient Hongmeng pour prendre le relais des téléphones Android open source pris en charge par Docker ; Electric ferme la plate-forme ouverte Apple lance la puce M4 Google supprime le noyau universel Android (ACK) Prise en charge de l'architecture RISC-V Yunfeng a démissionné d'Alibaba et prévoit de produire des jeux indépendants sur la plate-forme Windows à l'avenir