
La semaine dernière, nous avons annoncé la feuille de route GreptimeDB 2024, révélant plusieurs projets de versions majeures pour GreptimeDB cette année. Avec l'arrivée du début du printemps en mars, la première version open source de GreptimeDB adaptée au niveau de production est également arrivée comme prévu pendant la saison « Jingzhe », lorsque tout se rétablit. La v0.7 marque une étape importante vers une version prête pour la production, et nous invitons chaque membre de la communauté à participer activement et à fournir de précieux commentaires.
De la v0.6 à la v0.7, l'équipe Greptime a fait des progrès significatifs : un total de 184 Commits ont été fusionnés, 705 fichiers ont été modifiés, dont 82 améliorations de fonctionnalités, 35 corrections de bugs, 19 refactorisations de code et un grand nombre de travail de test. Au cours de cette période, un total de 8 contributeurs indépendants ont participé à la contribution au code de GreptimeDB. Un merci spécial à Eugene Tolbakov, en tant que premier committer de GreptimeDB, qui continue d'être actif dans la contribution au code de GreptimeDB et grandit avec nous !
Points forts de la mise à jour (version de sauvegarde de flux) Moteur métrique : un nouveau moteur conçu pour les scénarios observables est recommandé et peut gérer un grand nombre de petites tables, adapté aux scénarios de surveillance cloud natifs. Migration de région : optimise l'expérience d'utilisation et peut être facilement exécuté via SQL ; Migration de région ; index inversé : localisez efficacement les segments de données impliqués dans les requêtes des utilisateurs, réduisez considérablement les opérations d'E/S nécessaires à l'analyse des fichiers de données et accélérez le processus de requête.
La v0.7 est l'une des rares mises à jour de version majeures depuis que GreptimeDB est open source. Cette fois, nous la diffuserons également en direct sur le compte vidéo. Pour en savoir plus sur les détails fonctionnels, regarder des démonstrations de démonstration ou avoir des discussions approfondies avec notre équipe de développement principale, n'hésitez pas à rejoindre la diffusion en direct à 19h30 jeudi prochain (14 mars).
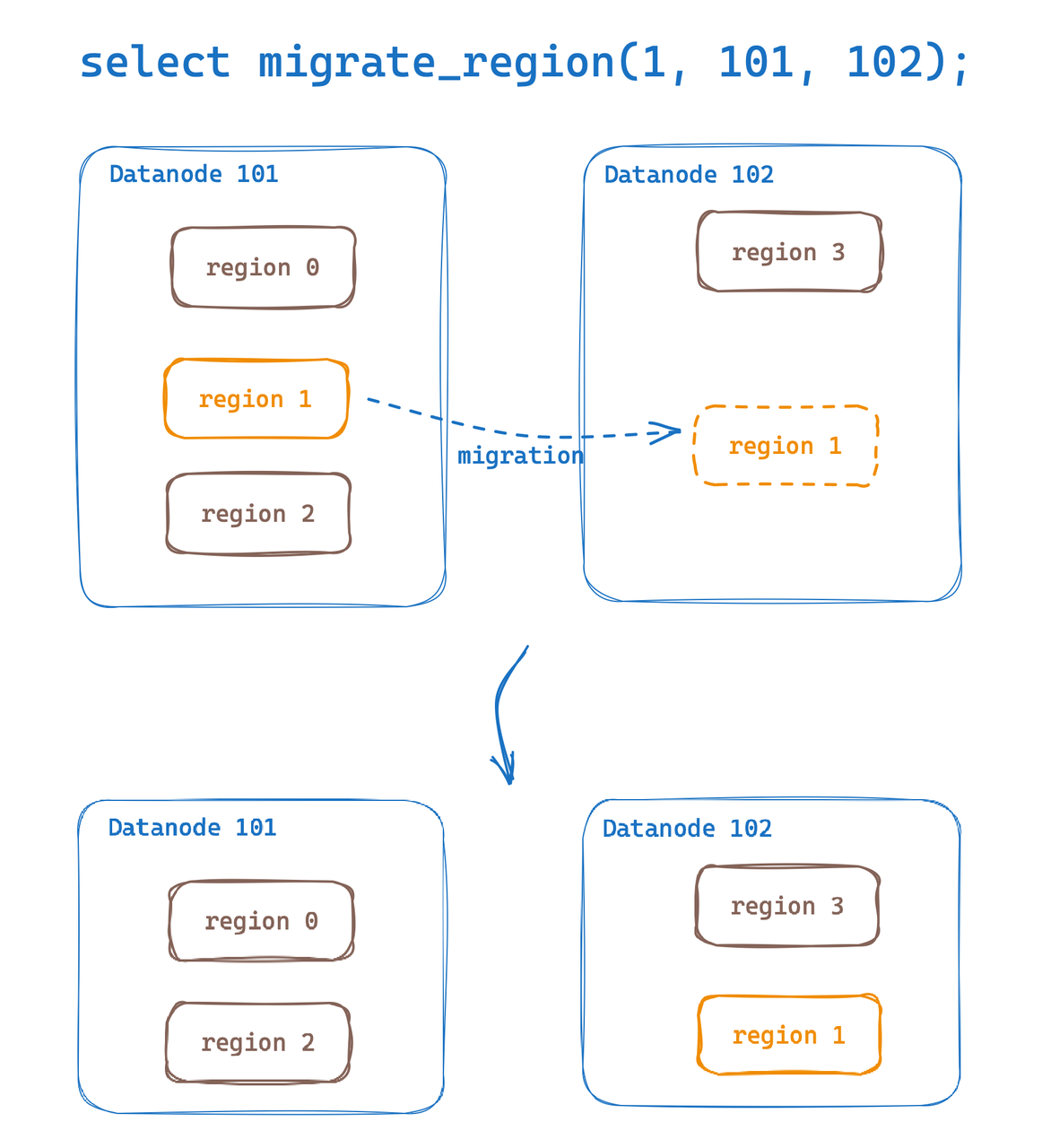
Migration de région
La migration de région offre la possibilité de migrer des régions de tables de données entre des Datanodes. Grâce à cette fonctionnalité, nous pouvons facilement mettre en œuvre la migration des données de points d'accès et l'expansion horizontale de l'équilibrage de charge. GreptimeDB a mentionné que la migration de région a été initialement mise en œuvre lors de la sortie de la version 0.6. Cette mise à jour améliore et optimise l'expérience utilisateur.
Désormais, nous pouvons facilement effectuer une migration de région via SQL :
select migrate_region(
region_id,
from_dn_id,
to_dn_id,
[replay_timeout(s)]);
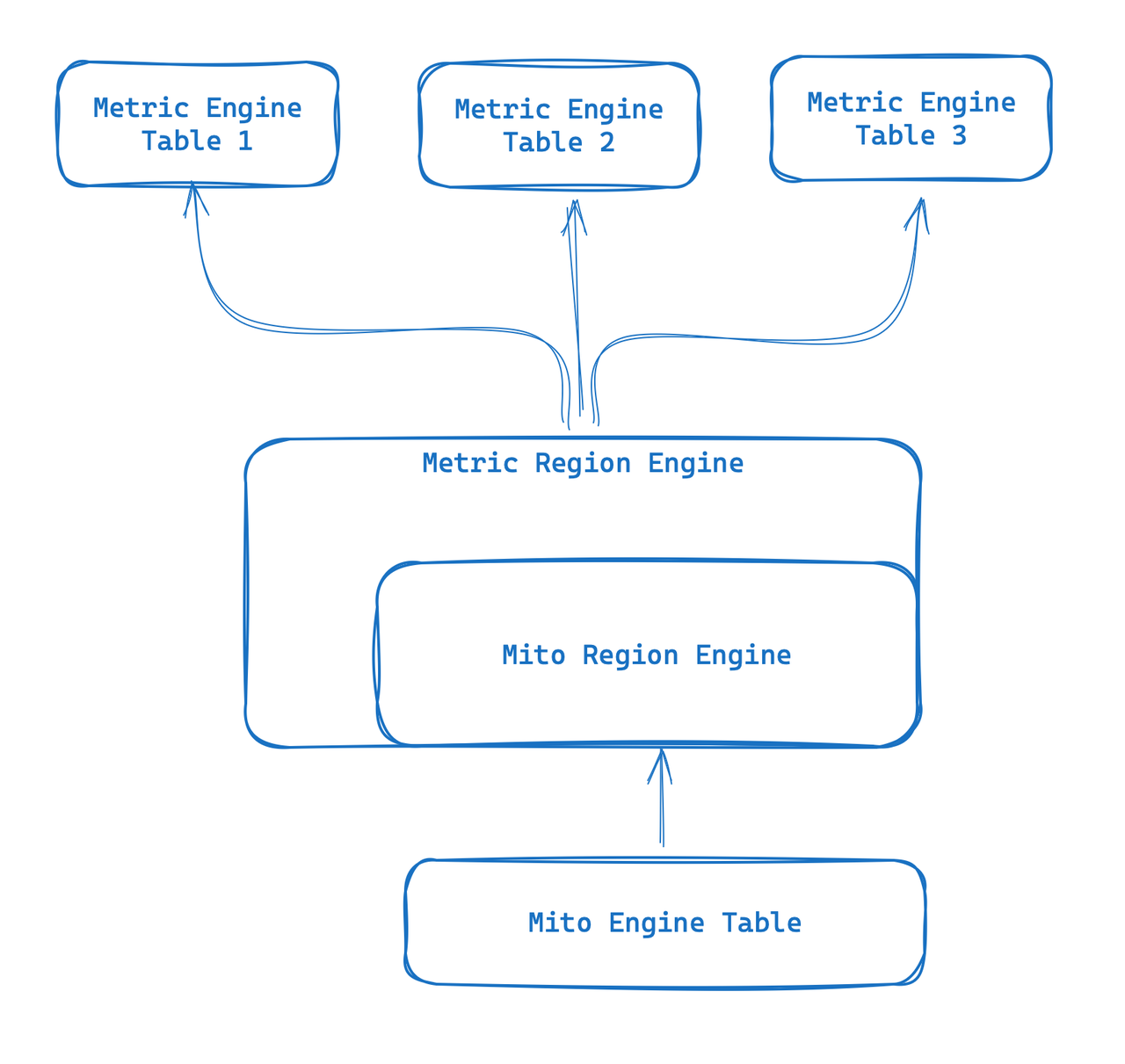
Moteur métrique
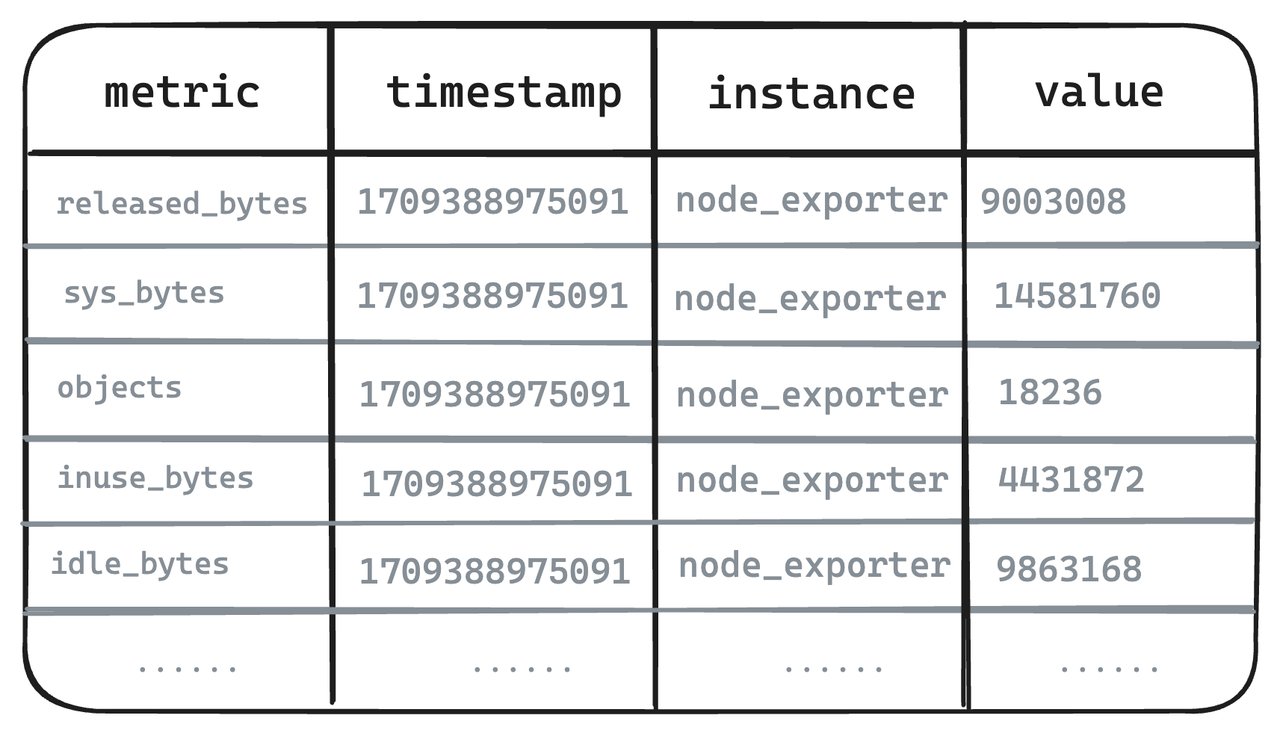
Metric Engine est un tout nouveau moteur conçu pour les scénarios observables. Son objectif principal est de pouvoir gérer un grand nombre de petites tables et est particulièrement adapté aux scénarios de surveillance cloud natifs tels que l'utilisation de Prometheus. En utilisant des tableaux synthétiques larges, ce nouveau moteur offre la possibilité de stocker les données des indicateurs et de réutiliser les métadonnées. La « table » devient plus légère et peut surmonter certaines des tables du moteur Mito existantes qui sont trop lourdes.
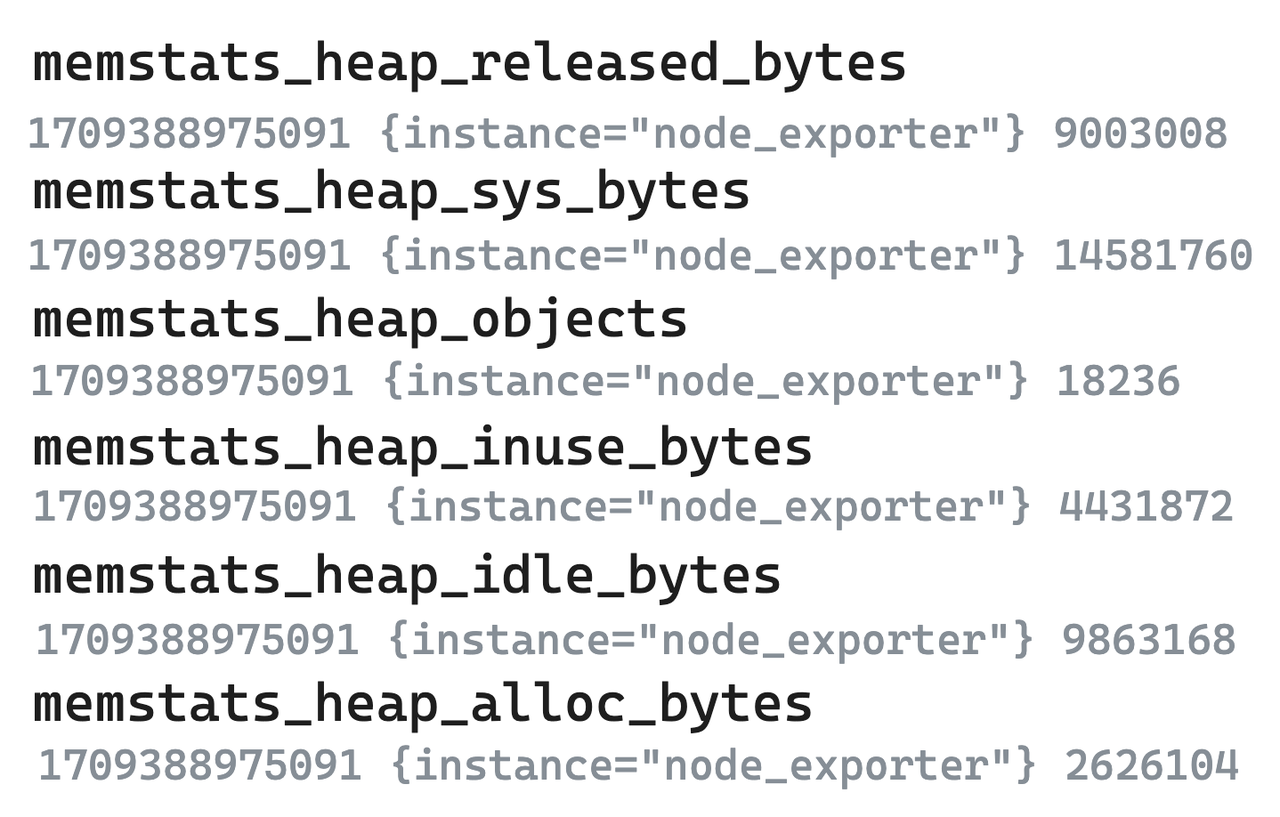
-
Légende - Données métriques brutes
- Les métriques suivantes des six exportateurs de nœuds sont prises comme exemples. Dans les systèmes de modèles à valeur unique représentés par Prometheus, même les indicateurs hautement corrélés doivent être divisés en plusieurs et stockés séparément.
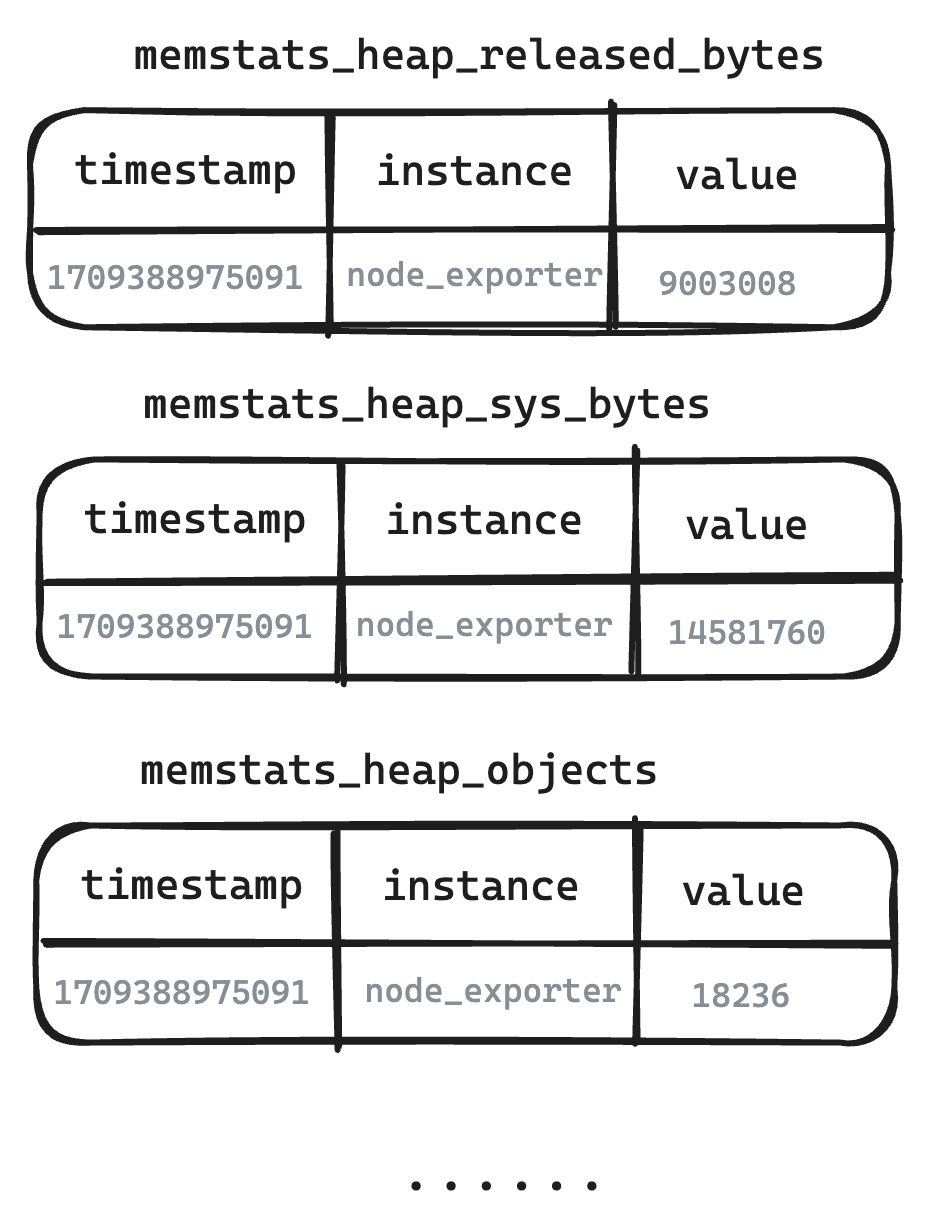
-
Légende – Tableau logique du point de vue de l'utilisateur
- Metric Engine restaure de manière authentique la structure des métriques, et ce que les utilisateurs voient est la structure écrite des métriques.
-
Légende - la table physique qui stocke la perspective
- Au niveau de la couche de stockage, Metric Engine effectue le mappage et utilise une table physique pour stocker les données associées, ce qui peut réduire les coûts de stockage et prendre en charge le stockage de métriques à plus grande échelle.
-
Légende - Prochain plan R&D : Regroupement automatique des champs
- La plupart des métriques générées dans des scénarios réels sont pertinentes. GreptimeDB peut automatiquement dériver des indicateurs associés et les fusionner, ce qui réduit non seulement le nombre de délais entre les métriques, mais est également convivial pour les requêtes associées.

-
Optimisation des coûts de stockage
Le test de coût a été effectué sur la base du backend de stockage AWS S3. Chaque donnée a été écrite pendant environ 30 minutes et le volume d'écriture total était d'environ 30 w ligne/s. Comptez le nombre de fois que chaque opération se produit au cours du processus et estimez le coût en fonction du devis d'AWS. La fonction d'index a été activée pendant le test.
Pour les devis, veuillez vous référer au niveau Standard sur https://aws.amazon.com/s3/pricing/
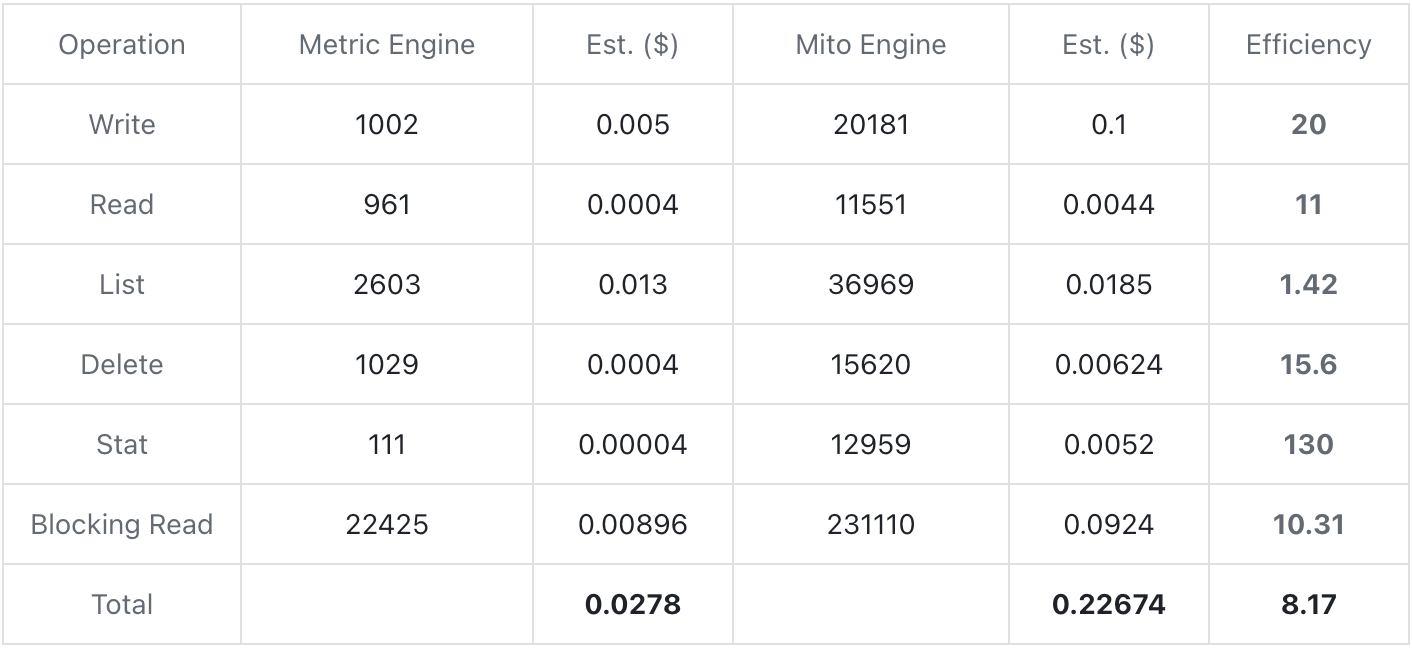
Comme le montre le tableau de test ci-dessus, Metric Engine peut réduire considérablement les coûts de stockage en réduisant le nombre de tables physiques. Le nombre d'opérations à chaque étape est réduit de plusieurs ordres de grandeur. Le coût global converti peut être réduit de plus de huit. fois par rapport au moteur Mito.
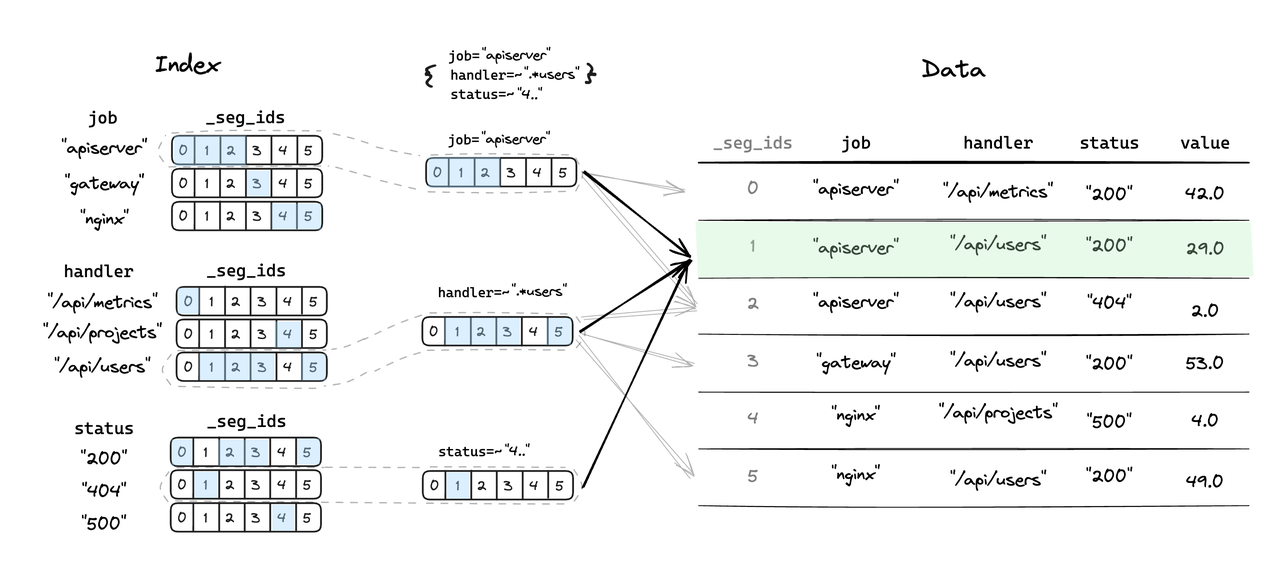
Index inversé
En tant que module d'index nouvellement introduit, Inverted Index est conçu pour localiser efficacement les segments de données impliqués dans les requêtes des utilisateurs, réduire considérablement les opérations d'E/S nécessaires à l'analyse des fichiers de données et accélérer le processus de requête. Dans le scénario de test TSBS, les performances de la scène sont améliorées de 50 % en moyenne, et dans certains scénarios, les performances sont améliorées de près de 200 %. Les principaux avantages de l’indice inversé comprennent :
- Prêt à l'emploi : le système génère automatiquement les index appropriés et les utilisateurs n'ont pas besoin de spécifier d'index supplémentaires ;
- Fonctions pratiques : prend en charge l'égalité, la plage et la correspondance régulière des valeurs multicolonnes, garantissant que les données peuvent être rapidement localisées et filtrées dans la plupart des scénarios ;
- Adaptation flexible : ajustez automatiquement les paramètres internes pour équilibrer les coûts de construction et l'efficacité des requêtes, répondant ainsi efficacement aux besoins d'indexation de différents scénarios.
- Légende - Représentation logique de l'index inversé et du processus de positionnement des données
- Les utilisateurs spécifient les conditions de filtrage dans plusieurs colonnes et, grâce au positionnement rapide de l'index inversé, la plupart des segments de données sans correspondance peuvent être éliminés, ce qui réduit le nombre de segments de données à analyser et accélère les requêtes.
Autres mises à jour
1. Les fonctions de gestion de la base de données ont été considérablement améliorées
Nous avons considérablement complété la table information_schema, en ajoutant de nouvelles informations telles que SCHEMATA et PARTITIONS. De plus, la nouvelle version introduit de nombreuses nouvelles fonctions SQL pour implémenter les opérations de gestion de base de données. Par exemple, vous pouvez désormais déclencher Region Flush, effectuer une migration de région et interroger l'état d'exécution des procédures via SQL.
2. Amélioration des performances
Dans la version v0.7, Memtable a été reconstruit pour améliorer la vitesse d'analyse des données et réduire l'utilisation de la mémoire. Dans le même temps, nous avons également apporté de nombreuses améliorations et optimisations aux performances de lecture et d’écriture du stockage objet.
Guide de mise à niveau
En raison de certains changements majeurs apportés à la nouvelle version, cette version v0.7 nécessite un temps d'arrêt pour la mise à niveau. Il est recommandé d'utiliser l'outil de mise à niveau officiel. Le processus général de mise à niveau est le suivant :
- Créer un nouveau cluster v0.7
- Fermez l'ancienne entrée de trafic du cluster (arrêtez d'écrire)
- Exporter la structure et les données de la table via l'outil de mise à niveau GreptimeDB CLI
- Importez des données vers le nouveau cluster via l'outil de mise à niveau GreptimeDB CLI
- Le trafic entrant bascule vers un nouveau cluster
Pour un guide de mise à niveau détaillé, veuillez vous référer à :
- Chinois : https://docs.greptime.cn/user-guide/upgrade
- Anglais : https://docs.greptime.com/user-guide/upgrade
perspectives d'avenir
Notre prochaine étape majeure aura lieu en avril, lorsque la v0.8 sera lancée. Cette version présentera GreptimeFlow, une solution de calcul de flux optimisée spécialement conçue pour effectuer des opérations d'agrégation continue dans les flux de données GreptimeDB. Compte tenu du besoin de flexibilité, GreptimeFlow peut être intégré à la couche informatique GreptimeDB et déployé ensemble, ou il peut être déployé en tant que service indépendant.
En plus des mises à niveau continues au niveau fonctionnel, nous continuons également à optimiser les performances de la version v0.7. Bien que les performances de la v0.7 aient été grandement améliorées par rapport à avant, il existe encore un certain écart entre celle-ci et certaines solutions traditionnelles dans des scénarios observables. Ce sera également notre prochaine direction clé d’optimisation.
Bienvenue pour lire la feuille de route GreptimeDB 2024 pour avoir une compréhension complète de notre plan de mise à jour de version tout au long de l'année. Vous êtes également invités à participer aux contributions au code, aux commentaires et aux discussions sur les fonctions et les performances. Unissons-nous pour assister à la croissance et à l'amélioration continues de GreptimeDB.
À propos de Greptime :
Greptime Greptime Technology s'engage à fournir des services efficaces de stockage et d'analyse de données en temps réel pour les domaines qui génèrent de grandes quantités de données de séries chronologiques, tels que les voitures intelligentes, l'Internet des objets et l'observabilité, aidant ainsi les clients à exploiter la valeur profonde des données. Il existe actuellement trois produits principaux :
-
GreptimeDB est une base de données de séries chronologiques écrite en langage Rust. Elle est distribuée, open source, native du cloud et hautement compatible. Elle aide les entreprises à lire, écrire, traiter et analyser des données de séries chronologiques en temps réel tout en réduisant les coûts de stockage à long terme.
-
GreptimeCloud peut fournir aux utilisateurs des services DBaaS entièrement gérés, qui peuvent être hautement intégrés à l'observabilité, à l'Internet des objets et à d'autres domaines.
-
GreptimeAI est une solution d'observabilité adaptée aux applications LLM.
-
La solution intégrée véhicule-cloud est une solution de base de données de séries chronologiques qui approfondit les scénarios commerciaux réels des constructeurs automobiles et résout les problèmes commerciaux réels après la croissance exponentielle des données sur les véhicules de l'entreprise.
GreptimeCloud et GreptimeAI ont été officiellement testés. Bienvenue pour suivre le compte officiel ou le site officiel pour les derniers développements ! Si vous êtes intéressé par la version entreprise de GreptimDB, vous êtes invités à contacter l'assistant (recherchez greptime sur WeChat pour ajouter l'assistant).
Site officiel : https://greptime.cn/
GitHub : https://github.com/GreptimeTeam/greptimedb
Documentation : https://docs.greptime.cn/
Twitter : https://twitter.com/Greptime
Slack : https://www.greptime.com/slack
LinkedIn : https://www.linkedin.com/company/greptime
Un programmeur né dans les années 1990 a développé un logiciel de portage vidéo et en a réalisé plus de 7 millions en moins d'un an. La fin a été très éprouvante ! Des lycéens créent leur propre langage de programmation open source en guise de cérémonie de passage à l'âge adulte - commentaires acerbes des internautes : s'appuyant sur RustDesk en raison d'une fraude généralisée, le service domestique Taobao (taobao.com) a suspendu ses services domestiques et repris le travail d'optimisation de la version Web Java 17 est la version Java LTS la plus utilisée Part de marché de Windows 10 Atteignant 70 %, Windows 11 continue de décliner Open Source Daily | Google soutient Hongmeng pour prendre le relais des téléphones Android open source pris en charge par Docker ; Electric ferme la plate-forme ouverte Apple lance la puce M4 Google supprime le noyau universel Android (ACK) Prise en charge de l'architecture RISC-V Yunfeng a démissionné d'Alibaba et prévoit de produire des jeux indépendants pour les plates-formes Windows à l'avenir