
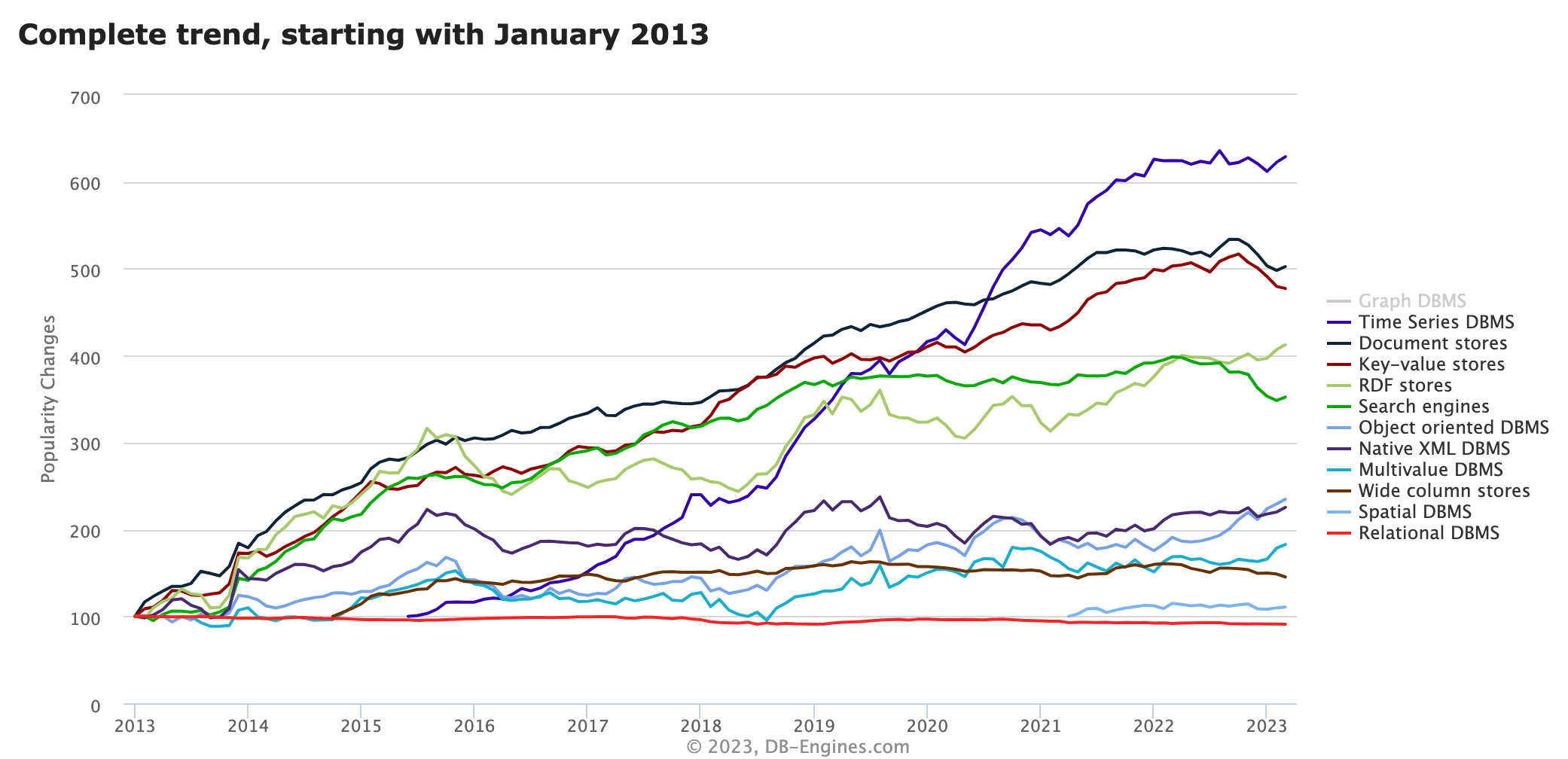
Au cours des dernières années, la popularité croissante de l’Internet des objets (IoT) et le besoin de données en temps réel ont conduit à une croissance significative de l’adoption des bases de données de séries chronologiques (TSDB). Selon le classement de DB-Engines, la popularité de TSDB dépasse celle de tout autre type de base de données, juste derrière le SGBD Graph .
En tant qu'outil important pour le stockage, la gestion et l'analyse des données de séries chronologiques, la demande de bases de données de séries chronologiques (TSDB) continuera probablement d'augmenter à l'avenir. Si vous ne savez pas encore grand-chose à ce sujet, cet article présentera en détail ce qu'est une base de données de séries chronologiques et pourquoi vous avez besoin d'une base de données pour les données de séries chronologiques.
Qu'est-ce que les données de séries chronologiques
En parlant de la popularité des bases de données de séries chronologiques ces dernières années, nous devons d'abord parler des données de séries chronologiques. Pourquoi leur traitement nécessite-t-il une base de données spécialement optimisée ? Une base de données relationnelle générale ne peut-elle pas le satisfaire ?
Les données dites de séries chronologiques, d'un point de vue très populaire, sont des valeurs (Valeur) qui changent avec le temps, ces valeurs sont accompagnées de certaines balises constituées de Clé=Valeur.
Comprend généralement les trois attributs suivants (de Wikipédia) :
Des séries chronologiques
Un identifiant unique composé d'un nom (souvent appelé métrique) et d'une série d'étiquettes Key=Value (Labels, ou généralement appelés Tags).
Paire clé-valeur (horodatage, valeur)
Les paires clé-valeur composées d'horodatages et de valeurs sont naturellement triées en fonction des horodatages. Ces paires clé-valeur sont généralement appelées échantillons.
Valeur
La valeur au point 2 est généralement une valeur numérique, telle que la température, l'humidité, le processeur, l'utilisation de la mémoire, etc., mais il peut également s'agir de n'importe quelle structure de données (à la fois structurée et non structurée).
Cas de données de séries chronologiques
Par exemple, prenez une capture d’écran des prévisions météorologiques à 15 jours d’un site Web pour Yuhang :
En analysant les deux lignes de température maximale et de température minimale, les trois attributs ici sont :
- Les délais sont les suivants : a. Température maximale quotidienne + <region=Yuhang> b. Température minimale quotidienne + <region=Yuhang>.
- La séquence composée de l'horodatage et de la valeur de la température maximale est de 15 paires clé-valeur du 29/08 au 06/09, et la valeur est la température maximale quotidienne. Les températures minimales sont similaires.
- Ici, la valeur est la température, c'est-à-dire une valeur numérique. Par exemple, la température la plus élevée le 29/08 est de 36 degrés Celsius et la température la plus basse est de 25 degrés Celsius.
Outre les informations sur les prévisions météorologiques, les données de séries chronologiques existent également largement dans les domaines suivants :
Cours de l’action : Permet aux analystes boursiers et aux traders de comprendre la tendance et la direction d’un certain cours d’action.
Surveillance de la santé : Utilisé dans le domaine médical pour surveiller la fréquence cardiaque ou d'autres valeurs de santé des patients susceptibles de prendre certains médicaments.
Capteurs physiques pour l'industrie et l'Internet des objets : notamment divers capteurs de température, d'humidité, de vitesse, d'accélération, de direction, de fréquence cardiaque, d'oxygène dans le sang et autres capteurs inclus dans divers smartphones, voitures intelligentes et maisons intelligentes, etc., largement utilisés dans la fabrication , médical et autres industries. Divers capteurs génèrent des quantités massives de données sensorielles à tout moment et à intervalles fixes ou irréguliers, qui sont principalement utilisées pour la surveillance quotidienne et anormale des équipements et des corps humains, et des applications intelligentes basées sur ces explorations massives de données (telles que comme l'optimisation des lignes de production de fabrication intelligente), la conduite autonome), etc.
Capteurs logiciels : tels que la surveillance des sondes intrusives dans le DevOps traditionnel, les sondes non intrusives dans les environnements cloud natifs (telles que les solutions de sondes non intrusives actuellement populaires basées sur les sondes de plan de données eBPF et Service Mesh), divers logiciels L'objectif principal de divers indicateurs et les données intégrées doivent surveiller les applications logicielles quotidiennes et anormales pour assurer le fonctionnement continu et stable des services commerciaux. Couplées au développement actuel du domaine AIOps, des exigences plus élevées sont également mises en avant en matière d'échelle et de granularité de l'utilisation des données de séries chronologiques.
Caractéristiques des données de séries chronologiques
- Les données sont générées de manière relativement fréquente et stable , et la fréquence est généralement stable et ne change pas avec les cycles d'activité diurnes des personnes. Il existe de nombreux types de capteurs, associés à un grand nombre d'étiquettes pour les secteurs et les emplacements géographiques, l'échelle des données et les délais sont extrêmement vastes. Et l'ampleur de ces données augmente rapidement avec la popularité des appareils intelligents (appareils portables, voitures intelligentes, fabrication intelligente) et les demandes plus sophistiquées des gens pour ces applications de données.
- Les caractéristiques de modification des données sont plus similaires à celles de la méthode Append-Only . Les données sont ajoutées en continu et il existe moins de scénarios de mise à jour (mais il y a toujours des retards de données, en particulier dans les environnements réseau faibles. Les données sont généralement supprimées en fonction du délai d'expiration). . Supprimer par lots pendant une période.
- En termes d'applications de données, les plus courantes sont la surveillance quotidienne et anormale . Sur la base de ces données, des rapports de surveillance visuelle et des systèmes d'alarme sont construits, suivis de la prévision des tendances futures, c'est-à-dire de la prévision de séries chronologiques, notamment dans le domaine financier.
Pourquoi les données de séries chronologiques sont si importantes
Bien que les données de séries chronologiques ne soient pas un nouveau type de données, leur popularité et leur utilisation ont considérablement augmenté au cours des dernières années, comme l'analyse DB-Engines. Il existe plusieurs facteurs qui ne peuvent être ignorés, notamment :
- Le développement d'Internet et la numérisation de nombreuses industries . Cela conduit directement à la génération de données chronologiques massives, telles que le trafic de sites Web, les activités sur les réseaux sociaux et les relevés de capteurs.
- Développement d'algorithmes d'apprentissage automatique . Tels que le réseau neuronal récurrent (RNN) et le réseau de mémoire à long terme (LSTM), ces algorithmes conviennent à l'analyse de données de séries chronologiques, permettant aux utilisateurs d'extraire plus facilement des informations précieuses à partir de ce type de données, donnant ainsi l'opportunité aux données de séries chronologiques. pour générer davantage de valeur.
- L'essor de l'analyse prédictive . Cela fait des données de séries chronologiques un outil important pour prédire les tendances et les résultats futurs.
- besoins dans des domaines tels que la finance, les soins médicaux et les transports . Il existe un besoin croissant de prise de décision en temps réel dans ces domaines, et l’analyse des données chronologiques peut faire face à ces situations en évolution rapide.
Qu'est-ce qu'une base de données de séries chronologiques
La base de données de séries temporelles (Time Series Database) selon la définition de Wikipédia est une base de données spécifiquement optimisée pour le traitement des données de séries chronologiques. Il s'agit d'un type de base de données de domaine et est conçue pour les services de traitement de données dans des domaines commerciaux spécifiques, tels que le traitement des bases de données graphiques, le stockage des graphiques. récupération. , la base de données documentaire est utilisée pour le stockage et la récupération de documents semi-structurés, et le moteur de recherche est spécialement utilisé pour la récupération de texte non structuré.
Caractéristiques de la base de données de séries chronologiques
Pour répondre aux caractéristiques et aux défis liés aux données de séries chronologiques décrites ci-dessus, TSDB utilise un certain nombre de techniques. Certaines de ces caractéristiques typiques comprennent :
Arbre de fusion structuré en journaux (arbre LSM)
LSM-tree est une structure de données basée sur disque optimisée pour les charges de travail lourdes en écriture qui permet une ingestion et un stockage efficaces des données en fusionnant et en compressant les données dans une série de niveaux. Cela réduit l'amplification d'écriture et offre de meilleures performances d'écriture par rapport aux arbres B traditionnels.
partitionnement basé sur le temps
Les bases de données de séries chronologiques partitionnent généralement les données en fonction d'intervalles de temps, ce qui rend les requêtes plus rapides et plus efficaces et facilite la conservation et la gestion des données. Cette approche permet de séparer les données récentes et fréquemment consultées des données plus anciennes et moins fréquemment consultées, optimisant ainsi les performances de stockage et de requête.
compression des données
Les bases de données de séries chronologiques utilisent diverses techniques de compression telles que le codage delta, la compression Gorilla ou le codage par dictionnaire pour réduire les besoins en espace de stockage. Ces techniques exploitent des modèles temporels et basés sur des valeurs dans les données de séries chronologiques pour permettre un stockage efficace sans perte de fidélité des données.
Fonctions et agrégations basées sur le temps intégrées
Les bases de données de séries chronologiques fournissent une prise en charge native des fonctions temporelles telles que les moyennes mobiles, les pourcentages et les agrégations temporelles. Ces fonctionnalités intégrées permettent aux utilisateurs d'effectuer des analyses de séries chronologiques complexes plus efficacement et avec moins de temps de calcul par rapport aux bases de données traditionnelles.
Pourquoi choisir une base de données de séries chronologiques
De l’introduction ci-dessus, nous avons également une réponse préliminaire aux raisons pour lesquelles nous avons besoin d’une base de données dans le domaine spécifique des bases de données de séries chronologiques.
En fonction des caractéristiques, de l'échelle et de l'application des données de séries chronologiques, la base de données de séries chronologiques peut effectuer des optimisations ciblées : le stockage adopte un algorithme de compression personnalisé, le format de stockage adopte un format de stockage mixte ligne-colonne optimisé pour l'écriture de masse de séries chronologiques et les scénarios de requêtes ; opérateurs de requête Introduire davantage de fonctions de synchronisation liées aux fenêtres temporelles, optimiser le protocole de requête pour les modèles de synchronisation et adopter une stratégie d'expiration plus flexible pour la suppression des données .
Ces optimisations spécifiques à un domaine peuvent conférer aux bases de données de séries chronologiques de grands avantages par rapport aux bases de données à usage général en termes de capacités de domaine, de performances, de coût, de stabilité et d'autres dimensions.
Résumer
Les bases de données de séries chronologiques ont été largement utilisées dans l'Internet des objets, l'analyse de données financières, les systèmes de surveillance et d'alarme, la gestion de l'énergie, les applications de soins de santé et d'autres secteurs sensibles au « facteur temps ». En utilisant des bases de données de séries chronologiques pour analyser et prédire les données de séries chronologiques, les entreprises peuvent obtenir des informations précieuses à partir des données, prenant ainsi des décisions plus éclairées et obtenant des avantages concurrentiels uniques.
Cependant, les bases de données de séries chronologiques et les bases de données relationnelles ne sont pas incompatibles. Étant donné que les systèmes d'entreprise utilisent encore largement les bases de données relationnelles, comment les données de séries chronologiques et les données commerciales peuvent-elles être plus facilement et mieux combinées pour générer une plus grande valeur commerciale ? La base de données des séries doit être résolue.
À propos de Greptime :
Greptime Greptime Technology s'engage à fournir des services efficaces de stockage et d'analyse de données en temps réel pour les domaines qui génèrent de grandes quantités de données de séries chronologiques, tels que les voitures intelligentes, l'Internet des objets et l'observabilité, aidant ainsi les clients à exploiter la valeur profonde des données. Il existe actuellement trois produits principaux :
-
GreptimeDB est une base de données de séries chronologiques écrite en langage Rust. Elle est distribuée, open source, native du cloud et hautement compatible. Elle aide les entreprises à lire, écrire, traiter et analyser des données de séries chronologiques en temps réel tout en réduisant les coûts de stockage à long terme.
-
GreptimeCloud peut fournir aux utilisateurs des services DBaaS entièrement gérés, qui peuvent être hautement intégrés à l'observabilité, à l'Internet des objets et à d'autres domaines.
-
GreptimeAI est une solution d'observabilité adaptée aux applications LLM.
-
La solution intégrée véhicule-cloud est une solution de base de données de séries chronologiques qui approfondit les scénarios commerciaux réels des constructeurs automobiles et résout les problèmes commerciaux réels après la croissance exponentielle des données sur les véhicules de l'entreprise.
GreptimeCloud et GreptimeAI ont été officiellement testés. Bienvenue pour suivre le compte officiel ou le site officiel pour les derniers développements ! Si vous êtes intéressé par la version entreprise de GreptimDB, vous êtes invités à contacter l'assistant (recherchez greptime sur WeChat pour ajouter l'assistant).
Site officiel : https://greptime.cn/
GitHub : https://github.com/GreptimeTeam/greptimedb
Documentation : https://docs.greptime.cn/
Twitter : https://twitter.com/Greptime
Slack : https://www.greptime.com/slack
LinkedIn : https://www.linkedin.com/company/greptime
Un programmeur né dans les années 1990 a développé un logiciel de portage vidéo et en a réalisé plus de 7 millions en moins d'un an. La fin a été très éprouvante ! Des lycéens créent leur propre langage de programmation open source en guise de cérémonie de passage à l'âge adulte - commentaires acerbes des internautes : s'appuyant sur RustDesk en raison d'une fraude généralisée, le service domestique Taobao (taobao.com) a suspendu ses services domestiques et repris le travail d'optimisation de la version Web Java 17 est la version Java LTS la plus utilisée Part de marché de Windows 10 Atteignant 70 %, Windows 11 continue de décliner Open Source Daily | Google soutient Hongmeng pour prendre le relais des téléphones Android open source pris en charge par Docker ; Electric ferme la plate-forme ouverte Apple lance la puce M4 Google supprime le noyau universel Android (ACK) Prise en charge de l'architecture RISC-V Yunfeng a démissionné d'Alibaba et prévoit de produire des jeux indépendants pour les plates-formes Windows à l'avenir