
Qu'est-ce que la haute cardinalité
La cardinalité est définie en mathématiques comme un scalaire utilisé pour représenter le nombre d'éléments dans un ensemble. Par exemple, la cardinalité d'un ensemble fini A = {a, b, c} est 3. Il existe également un concept de cardinalité pour les ensembles infinis. Aujourd’hui, nous parlons principalement du domaine de l’informatique, nous ne nous développerons pas ici.
Dans le contexte d'une base de données, il n'existe pas de définition stricte de la cardinalité, mais le consensus de tous sur la cardinalité est similaire à la définition en mathématiques : elle sert à mesurer le nombre de valeurs différentes contenues dans une colonne de données. Par exemple , un tableau de données qui enregistre les utilisateurs comporte généralement plusieurs colonnes UID, Nameet , la cardinalité deGenderDe toute évidence, aussi élevée que , et une colonne de peut contenir relativement peu de valeurs. Ainsi, dans l'exemple de la table utilisateur, on peut dire que la colonne appartient à la base haute et la colonne appartient à la base basse.UIDIDNameUIDGenderUIDGender
S'il est subdivisé en domaine de base de données de séries chronologiques, la cardinalité fait souvent référence au nombre de chronologies. Prenons comme exemple l'application d'une base de données de séries chronologiques dans le domaine observable. Services API. Pour donner l'exemple le plus simple, il existe deux étiquettes pour le temps de réponse de chaque interface du service API de différentes instances : API Routeset Instances'il y a 20 interfaces et 5 instances, la base de la chronologie est (20+1)x(5). +1)-1 = 125 ( +1en tenant compte du fait que le temps de réponse de toutes les interfaces d'une Instance ou le temps de réponse d'une interface dans toutes les Instances peut être visualisé séparément), la valeur ne semble pas grande, mais il convient de noter que l'opérateur est un produit, donc tant qu'un certain Si la cardinalité d'une étiquette est élevée, ou si une nouvelle étiquette est ajoutée, la cardinalité de la chronologie augmentera considérablement.
Pourquoi est-ce important
Comme nous le savons tous, les bases de données relationnelles telles que MySQL, que tout le monde connaît le mieux, comportent généralement des colonnes d'identification, ainsi que des colonnes communes telles que l'e-mail, le numéro de commande, etc. Ce sont des colonnes à cardinalité élevée et on en entend rarement parler. Cependant, certains problèmes surviennent du fait d’une telle modélisation des données. Le fait est que dans le domaine OLTP que nous connaissons, la cardinalité élevée n'est souvent pas un problème, mais dans le domaine du timing, elle pose souvent des problèmes en raison du modèle de données. Avant d'entrer dans le domaine du timing, nous en discutons d'abord. Jetons un coup d'œil à ce que signifie réellement un ensemble de données de base élevée.
À mon avis, en termes simples, un ensemble de données de grande qualité signifie une grande quantité de données. Pour une base de données, l'augmentation de la quantité de données aura inévitablement un impact sur l'écriture, les requêtes et le stockage. l'impact lors de l'écriture est l'index.
Cardinalité élevée des bases de données traditionnelles
Prenons l'exemple de B-tree, la structure de données la plus couramment utilisée pour créer des index dans les bases de données relationnelles. Normalement, la complexité de l'insertion et de la requête est O(logN), et la complexité spatiale est généralement O(N ). N est le nombre d’éléments, c’est-à-dire la cardinalité dont nous parlons. Naturellement, un N plus grand aura un certain impact, mais comme la complexité de l'insertion et de la requête est le logarithme népérien, l'impact n'est pas si important lorsque la taille des données n'est pas particulièrement grande.
Il semble donc que les données de base élevée n'aient aucun impact qui ne puisse être ignoré. Au contraire, dans de nombreux cas, l'indice de données de base élevée est plus sélectif que l'indice de données de base élevée. peut filtrer des données volumineuses via une condition de requête Données partielles qui ne remplissent pas les conditions, réduisant ainsi la surcharge d'E/S disque Dans les applications de base de données, il est nécessaire d'éviter une surcharge excessive d'E/S disque et réseau. Par exemple select * from users where gender = "male";, l'ensemble de données résultant sera très volumineux, et les E/S du disque et les E/S du réseau seront très volumineuses. En pratique, l'utilisation de cet indice de faible cardinalité seul n'a pas beaucoup de sens.
Cardinalité élevée des bases de données de séries chronologiques
Alors, en quoi les bases de données de séries chronologiques sont-elles différentes et provoquent des problèmes avec les colonnes de données à base de données élevée ? Dans le domaine des données de séries chronologiques, qu'il s'agisse de modélisation de données ou de conception de moteurs, le cœur tournera autour de la chronologie. Comme mentionné précédemment, le problème de cardinalité élevée dans la base de données de séries chronologiques fait référence au nombre et à la taille des chronologies. Cette taille n'est pas seulement la cardinalité d'une colonne, mais le produit de la cardinalité de toutes les colonnes d'étiquettes. , on peut comprendre que dans les bases de données relationnelles courantes, la base haute est isolée dans une certaine colonne, c'est-à-dire que l'échelle des données augmente de manière linéaire, tandis que la base haute dans les bases de données de séries chronologiques est le produit de plusieurs colonnes, ce qui n'est pas linéaire. croissance. Examinons de plus près comment la chronologie de base élevée est générée dans la base de données de séries chronologiques. Examinons d'abord le premier scénario :
Quantité de séries chronologiques
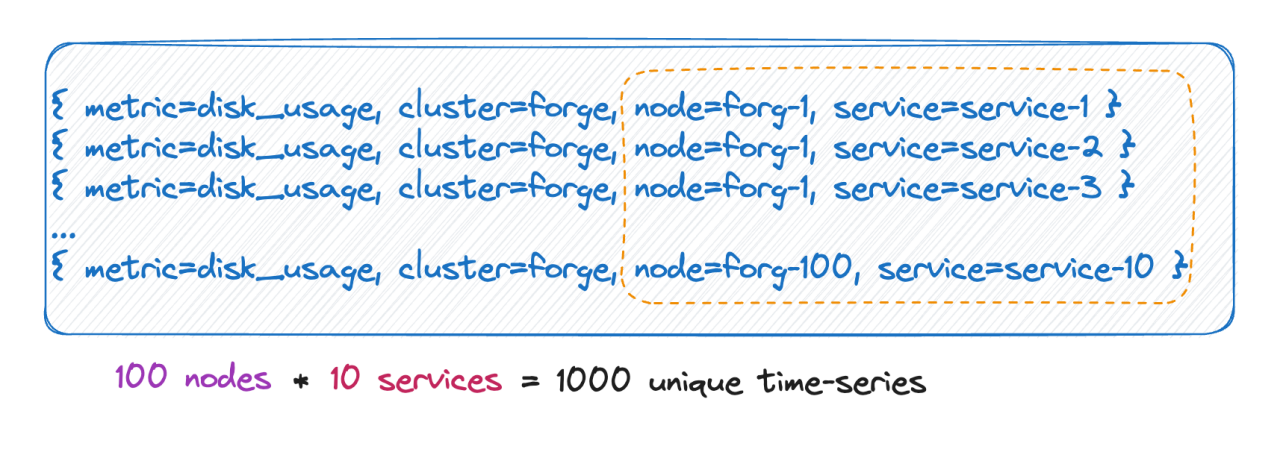
Nous savons que le nombre de chronologies est en réalité égal au produit cartésien de toutes les bases d’étiquettes. Comme le montre l'image ci-dessus, le nombre de chronologies est de 100 * 10 = 1 000 chronologies. Si 6 balises sont ajoutées à cette métrique, chaque valeur de balise a 10 valeurs et le nombre de chronologies est de 10^9, soit 100 millions. Une chronologie, vous pouvez imaginer cette ampleur.
La balise a des valeurs infinies
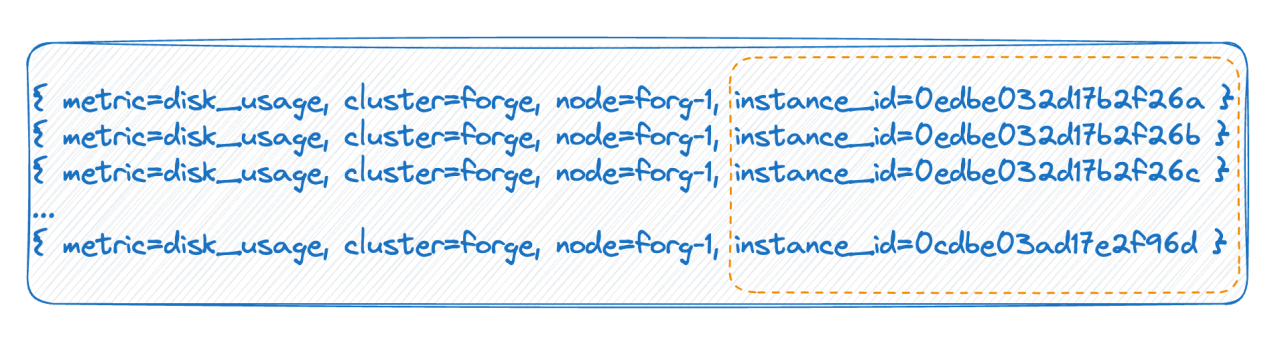
Dans le deuxième cas, par exemple, dans un environnement cloud natif, chaque pod possède un identifiant. Chaque fois qu'il est redémarré, le pod est effectivement supprimé et reconstruit, et un nouvel identifiant est généré, ce qui rend la valeur de la balise très élevée. Il y en a beaucoup, et chaque redémarrage complet entraînera un doublement du nombre de délais. Les deux situations ci-dessus sont les principales raisons de la cardinalité élevée mentionnée par la base de données de séries chronologiques.
Comment la base de données de séries chronologiques organise les données
Nous savons à quel point une cardinalité élevée se produit. Nous devons comprendre les problèmes que cela entraînera, et nous devons également comprendre comment les bases de données de séries chronologiques traditionnelles organisent les données.
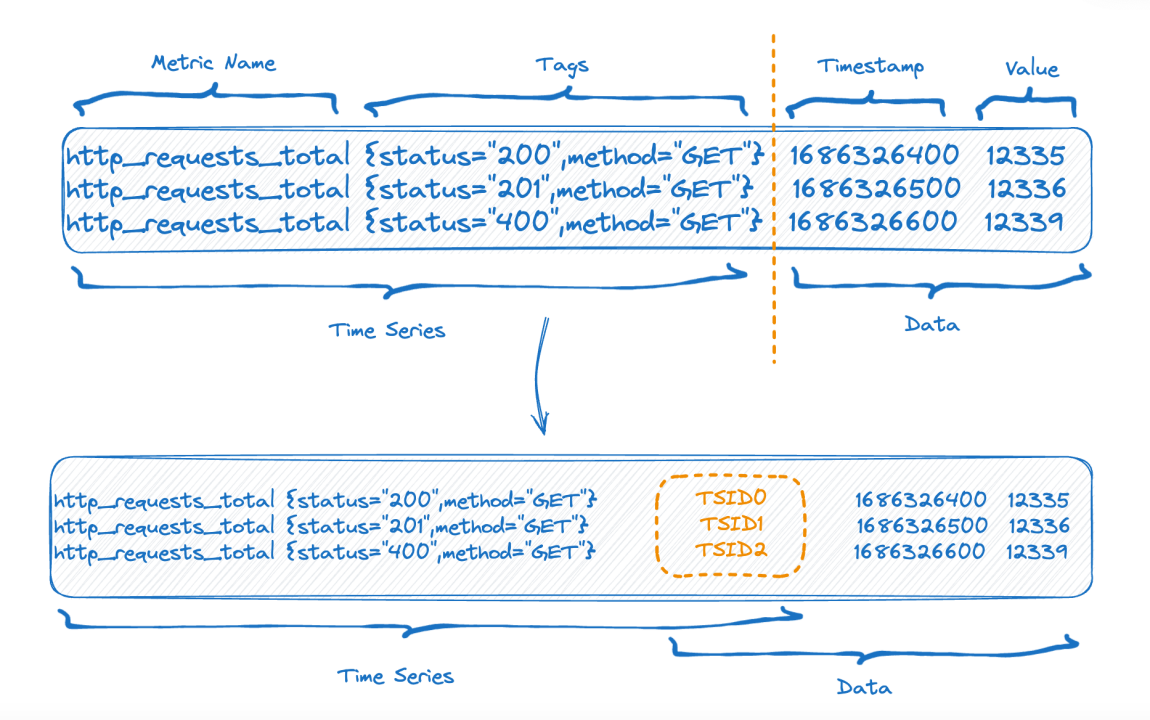
La moitié supérieure de la figure montre la représentation avant l'écriture des données, et la moitié inférieure de la figure montre la représentation logique après le stockage des données. Le côté gauche correspond aux données d'index de la partie série chronologique et le côté droit correspond aux données. partie.
Chaque série chronologique peut générer un TSID unique, et l'index et les données sont liés via le TSID. Des amis familiers ont peut-être vu cet index, il s'agit d'un index inversé.
Regardons l'image ci-dessous, qui est une représentation de l'index inversé en mémoire :
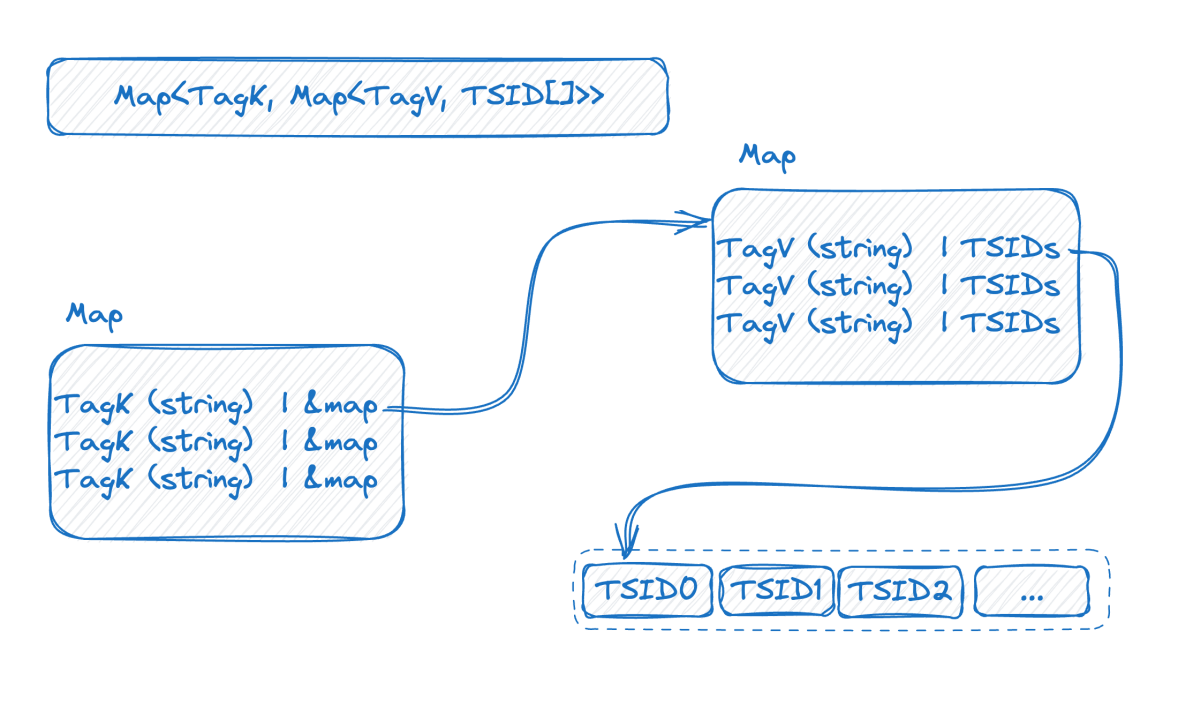
Il s'agit d'une carte à deux couches. La couche externe trouve d'abord la carte interne via le nom de la balise K dans la carte interne est la valeur de la balise et V est l'ensemble des TSID contenant la valeur de la balise correspondante.
À ce stade, combiné à l’introduction précédente, nous pouvons voir que plus la base des données de la série chronologique est élevée, plus la carte à double couche sera grande. Après avoir compris la structure de l'indice, nous pouvons essayer de comprendre comment se pose le problème de la base élevée :
Afin d'obtenir un débit d'écriture élevé, il est préférable de conserver cet index en mémoire. Une cardinalité élevée entraînera son expansion et vous ne pourrez pas l'adapter en mémoire. Si la mémoire ne peut pas être stockée, elle doit être échangée sur le disque. Après l'échange sur le disque, la vitesse d'écriture sera affectée en raison d'une grande quantité d'E/S aléatoires sur le disque. Regardons à nouveau la requête. À partir de la structure de l'index, nous pouvons deviner le processus de requête, comme les conditions de requête where status = 200 and method="get". Le processus consiste d'abord à trouver statusla carte avec la clé, à obtenir la carte interne, puis "200"à obtenir tous les ensembles TSID et à vérifier. encore une fois de la même manière. Une condition, puis le nouvel ensemble TSID obtenu après l'intersection des deux ensembles TSID est utilisé pour récupérer les données une par une selon le TSID.
On peut voir que le cœur du problème est que les données sont organisées selon la chronologie, vous devez donc d'abord obtenir la chronologie, puis trouver les données selon la chronologie. Plus une requête implique de délais, plus la requête sera lente.
Comment le résoudre
Si notre analyse est correcte et que nous connaissons la cause du problème de base élevée dans le domaine des données de séries chronologiques, il sera alors facile à résoudre. Examinons la cause du problème :
- Niveau de données : maintenance de l'index et problèmes de requête causés par C(L1) * C(L2) * C(L3) * ... * C(Ln).
- Niveau technique : les données sont organisées selon des chronologies, vous devez donc d'abord obtenir la chronologie, puis rechercher les données en fonction de la chronologie. S'il y a plus de chronologies, la requête sera plus lente.
L'éditeur discutera des solutions sous deux aspects :
Optimisation de la modélisation des données
1 Supprimez les étiquettes inutiles
Nous définissons souvent accidentellement des champs inutiles comme étiquettes, ce qui provoque une surcharge de la chronologie. Par exemple, lorsque nous surveillons l'état du serveur, nous avons souvent instance_name, ip. En fait, il n'est pas nécessaire que ces deux champs deviennent des étiquettes. L'un d'eux suffit probablement, et l'autre peut être défini comme attribut.
2. Modélisation des données basée sur des requêtes réelles
Prenons l'exemple de la surveillance des capteurs dans l'Internet des objets :
- appareils 10w
- 100 régions
- 10 appareils
S'il est modélisé dans une métrique, dans Prometheus, cela entraînera une chronologie de 10w * 100 * 10 = 100 millions. (Calcul non rigoureux) Pensez-y, la requête sera-t-elle effectuée de cette manière ? Par exemple, comment interroger la chronologie d’un certain type d’équipement dans une certaine région ? Cela semble déraisonnable, car une fois le périphérique spécifié, le type est déterminé, donc les deux étiquettes n'ont pas besoin d'être ensemble, cela peut alors devenir :
- metric_one : appareils 10 W
- métrique_deux :
- 100 régions
- 10 appareils
- metric_two : (en supposant qu'un appareil puisse être déplacé vers une autre région pour collecter des données)
- appareils 10w
- 100 régions
Le total est une chronologie de 10w + 100 10 + 10w 100 ~ 1010w, soit 10 fois moins que ci-dessus.
3. Gérez séparément les précieuses données chronologiques de base élevée
Bien sûr, si vous trouvez que votre modélisation de données est très cohérente avec la requête, mais que la chronologie ne peut toujours pas être réduite car l'échelle des données est trop grande, alors placez tous les services liés à cet indicateur principal sur une meilleure machine.
Optimisation de la technologie des bases de données de séries chronologiques
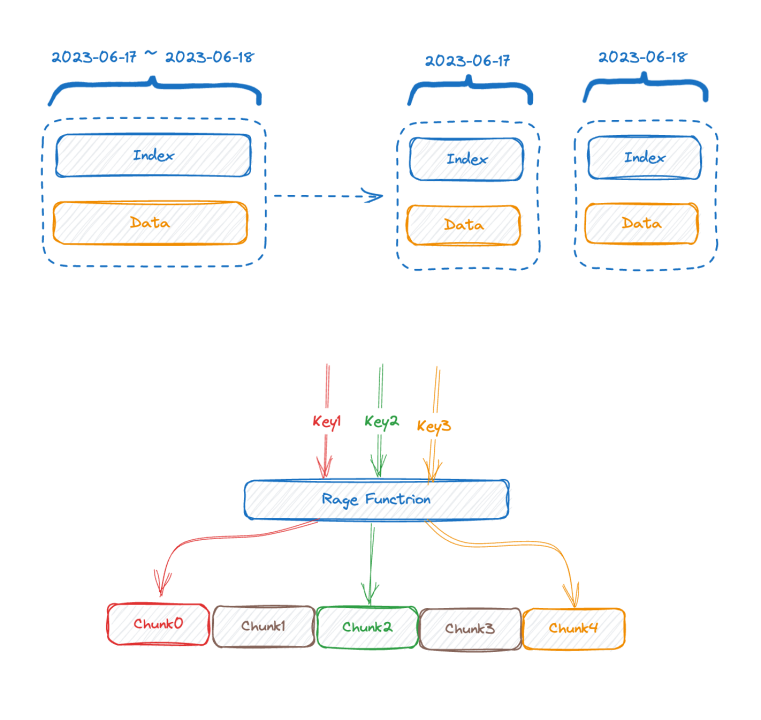
- La première solution efficace est la segmentation verticale. La plupart des bases de données de séries chronologiques traditionnelles du secteur ont plus ou moins adopté une méthode similaire pour segmenter l'index en fonction du temps, car si cette segmentation n'est pas effectuée, au fil du temps, l'index va s'étendre. de plus en plus, et finalement la mémoire ne pourra pas le stocker. S'il est divisé en fonction du temps, l'ancien morceau d'index peut être échangé sur le disque ou même sur le stockage distant. Au moins, l'écriture ne sera pas affectée.
- L'opposé de la segmentation verticale est la segmentation horizontale. Une clé de partitionnement est utilisée, qui peut généralement être une ou plusieurs balises avec la fréquence d'utilisation du prédicat de requête la plus élevée. La segmentation par plage ou par hachage est effectuée en fonction des valeurs de ces balises, ce qui est le cas. équivalent à l'utilisation de l'idée distribuée diviser pour régner résout le goulot d'étranglement sur une seule machine. Le prix est que si la condition de requête n'inclut pas de clé de partitionnement, l'opérateur ne peut pas être poussé vers le bas et les données ne peuvent être déplacées que vers le serveur. couche supérieure pour le calcul.
Les deux méthodes ci-dessus sont des solutions traditionnelles, qui ne peuvent atténuer le problème que dans une certaine mesure, mais ne peuvent pas le résoudre fondamentalement. Les deux solutions suivantes ne sont pas des solutions conventionnelles, mais sont les directions que GreptimeDB tente d'explorer. Elles ne sont que brièvement mentionnées ici sans analyse approfondie, à titre de référence uniquement :
-
Nous voudrons peut-être nous demander si les bases de données de séries chronologiques ont vraiment besoin d'index inversés. TimescaleDB utilise des index B-tree, et InfluxDB_IOx n'a pas d'index inversés. Pour les requêtes à cardinalité élevée, nous utilisons des analyses de partition couramment utilisées dans les bases de données OLAP combinées avec min-max. index. L'effet serait-il meilleur si nous effectuions une optimisation d'élagage ?
-
Indexation intelligente asynchrone. Pour être intelligent, vous devez d'abord collecter et analyser les comportements et construire de manière asynchrone l'index le plus approprié pour accélérer les requêtes dans chaque requête de l'utilisateur. Par exemple, nous choisissons des balises qui apparaissent très rarement dans les conditions de requête de l'utilisateur. Aucune inversion n'est créée pour cela. En combinant les deux solutions ci-dessus, lors de l'écriture, comme l'inversion est construite de manière asynchrone, cela n'affecte pas du tout la vitesse d'écriture.
En regardant à nouveau la requête, étant donné que les données de séries chronologiques ont des attributs temporels, les données peuvent être regroupées en fonction de l'horodatage. Nous n'indexons pas la dernière tranche temporelle. La solution consiste à effectuer une analyse approfondie et à combiner certains index min-max pour l'optimisation de l'élagage. Il est encore possible de parcourir des dizaines ou des centaines de millions de lignes en quelques secondes.
Lorsqu'une requête arrive, estimez d'abord le nombre de délais qu'elle impliquera. Si cela implique une petite quantité, utilisez l'inversion, et si cela implique beaucoup, passez directement à scanner + filtrer sans inversion.
Nous explorons encore les idées ci-dessus et ne sommes pas encore parfaits.
Conclusion
Une base élevée n'est pas toujours un problème. Parfois, une base élevée est nécessaire. Ce que nous devons faire, c'est construire notre propre modèle de données en fonction de nos propres conditions commerciales et de la nature des outils que nous utilisons. Bien sûr, les outils ont parfois certaines limitations de scénario. Par exemple, Prometheus indexe les étiquettes sous chaque métrique par défaut. Ce n'est pas un gros problème dans un scénario sur une seule machine, et ce sera également pratique à utiliser. étirée lorsqu’il s’agit de données à grande échelle. GreptimeDB s'engage à créer une solution unifiée dans des scénarios autonomes et à grande échelle. Nous explorons également des tentatives techniques pour résoudre des problèmes de base, et tout le monde est invité à en discuter.
Référence
- https://en.wikipedia.org/wiki/Cardinality
- https://www.cncf.io/blog/2022/05/23/what-is-high-cardinality/
- https://grafana.com/blog/2022/10/20/how-to-manage-high-cardinality-metrics-in-prometheus-and-kubernetes/
À propos de Greptime :
Greptime Greptime Technology s'engage à fournir des services efficaces de stockage et d'analyse de données en temps réel pour les domaines qui génèrent de grandes quantités de données de séries chronologiques, tels que les voitures intelligentes, l'Internet des objets et l'observabilité, aidant ainsi les clients à exploiter la valeur profonde des données. Il existe actuellement trois produits principaux :
-
GreptimeDB est une base de données de séries chronologiques écrite en langage Rust. Elle est distribuée, open source, native du cloud et hautement compatible. Elle aide les entreprises à lire, écrire, traiter et analyser des données de séries chronologiques en temps réel tout en réduisant les coûts de stockage à long terme.
-
GreptimeCloud peut fournir aux utilisateurs des services DBaaS entièrement gérés, qui peuvent être hautement intégrés à l'observabilité, à l'Internet des objets et à d'autres domaines.
-
GreptimeAI est une solution d'observabilité adaptée aux applications LLM.
-
La solution intégrée véhicule-cloud est une solution de base de données de séries chronologiques qui approfondit les scénarios commerciaux réels des constructeurs automobiles et résout les problèmes commerciaux réels après la croissance exponentielle des données sur les véhicules de l'entreprise.
GreptimeCloud et GreptimeAI ont été officiellement testés. Bienvenue pour suivre le compte officiel ou le site officiel pour les derniers développements ! Si vous êtes intéressé par la version entreprise de GreptimDB, vous êtes invités à contacter l'assistant (recherchez greptime sur WeChat pour ajouter l'assistant).
Site officiel : https://greptime.cn/
GitHub : https://github.com/GreptimeTeam/greptimedb
Documentation : https://docs.greptime.cn/
Twitter : https://twitter.com/Greptime
Slack : https://www.greptime.com/slack
LinkedIn : https://www.linkedin.com/company/greptime
Un programmeur né dans les années 1990 a développé un logiciel de portage vidéo et en a réalisé plus de 7 millions en moins d'un an. La fin a été très éprouvante ! Des lycéens créent leur propre langage de programmation open source en guise de cérémonie de passage à l'âge adulte - commentaires acerbes des internautes : s'appuyant sur RustDesk en raison d'une fraude généralisée, le service domestique Taobao (taobao.com) a suspendu ses services domestiques et repris le travail d'optimisation de la version Web Java 17 est la version Java LTS la plus utilisée Part de marché de Windows 10 Atteignant 70 %, Windows 11 continue de décliner Open Source Daily | Google soutient Hongmeng pour prendre le relais des téléphones Android open source pris en charge par Docker ; Electric ferme la plate-forme ouverte Apple lance la puce M4 Google supprime le noyau universel Android (ACK) Prise en charge de l'architecture RISC-V Yunfeng a démissionné d'Alibaba et prévoit de produire des jeux indépendants pour les plates-formes Windows à l'avenir