
Tout le monde est invité à nous mettre en vedette sur GitHub :
Système d'apprentissage causal distribué à lien complet OpenASCE : https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
Grand graphe de connaissances basé sur un modèle OpenSPG : https://github.com/OpenSPG/openspg
Système d'apprentissage de graphes à grande échelle OpenAGL : https://github.com/TuGraph-family/TuGraph-AntGraphLearning
Titre de l'article : PEACE : Prototype d'apprentissage augmenté, cadre transférable pour la recommandation inter-domaines
Unité organisationnelle : Ant Group
Conférence d'admission : WSDM 2024
Lien papier : https://arxiv.org/abs/2312.0191 6
L'auteur de cet article : Gan Chunjing. Les principales directions de recherche sont les algorithmes de graphes, les algorithmes de recommandation, les grands modèles de langage et l'application des graphes de connaissances. Les résultats de la recherche sont inclus dans les conférences grand public liées à l'apprentissage automatique (WSDM/SIGIR/AAAI). Le travail principal de l'équipe au cours de l'année écoulée a consisté en des modèles de recommandation pré-entraînés basés sur des graphes de connaissances, de grands modèles de langage basés sur l'amélioration des connaissances et leurs applications, y compris le cadre de réseau neuronal graphique basé sur le découplage multi-granularité dans le scénario de gestion financière. publié dans SIGIR'23 MGDL, le prototype de cadre de recommandation interdomaine de pré-formation de graphes d'entités basé sur l'apprentissage PEACE publié au WSDM'24.
arrière-plan
Avec le développement de l'écosystème des mini-programmes d'Alipay, de plus en plus de commerçants ont commencé à exploiter des mini-programmes sur Alipay. Dans le même temps, Alipay espère également parvenir à une stratégie décentralisée grâce à l'écologie des mini-programmes + l'auto-exploitation des commerçants.
Dans le processus d'auto-exploitation des commerçants, de plus en plus de petits et moyens commerçants ont besoin d'opérations numériques et intelligentes, telles que l'amélioration de l'efficacité marketing de leurs positions de domaine privé de mini-programmes grâce à des capacités de recommandation personnalisées, mais pour les petites et moyennes entreprises. entreprises marchandes de taille moyenne , le coût technique et le coût de la main-d'œuvre pour créer des capacités de recommandation personnalisées par l'IA auto-construites sont très élevés.
Dans ce contexte, nous espérons fournir aux commerçants des capacités de recommandation et de recherche personnalisées visibles mais inaccessibles basées sur les données massives sur le comportement des utilisateurs d'Ant pour aider les commerçants à créer des mini-programmes intelligents pour augmenter les revenus des commerçants sur la plate-forme Alipay et offrir aux utilisateurs une meilleure expérience personnalisée peut améliorer la fidélisation des utilisateurs dans Alipay, et il peut également accumuler des solutions techniques communes pour optimiser davantage l'expérience commerçant/utilisateur.
Il existe de nombreux cas d'application réussis dans l'industrie qui utilisent des données provenant de scénarios comportementaux riches pour améliorer l'effet de recommandation dans des scénarios à moyenne et longue traîne. Par exemple, Taobao utilise les données comportementales de première estimation pour améliorer l'effet de recommandation dans d'autres petits scénarios. scénarios. Fliggy utilise l'application et les petits scénarios d'Alipay pour améliorer l'effet de recommandation. Le terminal modélise conjointement pour améliorer l'effet de recommandation global.
Cependant, ce type de méthode est généralement confronté à plusieurs scénarios de recommandation avec des mentalités similaires et utilise des données de scénario avec des comportements riches pour améliorer l'effet de recommandation de scénarios similaires avec des comportements clairsemés, tels que Taobao, Fliggy, etc. Cependant, les super applications telles qu'Alipay incluent généralement divers mini-programmes tels que les voyages, les affaires gouvernementales, le crédit-bail, les voyages, la restauration, les nécessités quotidiennes, etc. Les différences mentales entre les utilisateurs dans les différents mini-programmes sont très grandes, ce qui nous donne un modèle apporte beaucoup défis:
- Les mini-programmes d'Alipay sont dispersés dans des secteurs verticaux avec des types d'activités très différents, tels que les affaires gouvernementales, l'alimentation, le crédit-bail, la vente au détail et la gestion financière. De manière générale, les informations ne sont pas partagées entre ces mini-programmes, et des éléments similaires peuvent ne pas avoir des attributs similaires. En transférant directement plusieurs comportements sur l'ensemble du domaine vers un scénario de classe verticale spécifique sans aligner de telles différences entre domaines, il est difficile pour le modèle d'acquérir des connaissances utiles pour la classe verticale à partir des comportements mixtes de plusieurs classes verticales, et cela peut même être le cas. provoquer une migration négative ;
- Bien que la migration point à point du comportement des utilisateurs, par exemple, l'industrie alimentaire utilise uniquement les comportements des utilisateurs liés à la restauration sur Alipay, puisse atténuer dans une certaine mesure les problèmes ci-dessus, mais chaque fois qu'une nouvelle industrie est ajoutée, une intervention manuelle est nécessaire. , ce qui est coûteux et ne peut pas réaliser l'ensemble de la chaîne. En plus de l'automatisation routière, certains commerçants espèrent également que la plate-forme Alipay pourra fournir des solutions de recommandation personnalisées plug-and-play lors de la première connexion, même en l'absence de données sur le comportement des utilisateurs. Un tel modèle n'est pas réalisable dans ce contexte.
Sur la base des défis ci-dessus, nous avons proposé PEACE, un cadre d'apprentissage par transfert multi-scénarios de pré-formation graphique basé sur l'apprentissage par prototype, basé sur le problème des grandes différences entre les domaines industriels verticaux.
Nous avons introduit le graphe d'entité et espérions utiliser le graphe d'entité comme pont pour relier les différences entre les différents domaines afin d'atténuer son impact négatif sur la modélisation. Cependant, le graphe d'entité dans l'environnement de production est généralement énorme, bien qu'il contienne un grand nombre de. Cependant, cela introduira également beaucoup de bruit. L'agrégation aveugle d'informations structurelles dans la carte d'entité réduira généralement la robustesse du modèle. Par conséquent, nous avons introduit l'apprentissage par prototype pour améliorer la représentation de l'entité et de l'utilisateur dans le processus de modélisation. pour contraindre.
Dans l'ensemble, le cadre PEACE est l'idée de conception de migration de ONE FOR ALL. Nous utilisons le comportement du domaine public multi-sources des utilisateurs dans Alipay comme entrée du modèle de pré-formation et apprenons les intérêts et les préférences des utilisateurs de plusieurs secteurs. un grâce à l'idée de représentation découplée.Dans le modèle, combiné au réseau prototype qui capture les signaux de l'industrie, il suffit de pré-former un modèle unifié pour migrer de manière adaptative les multiples intérêts des utilisateurs vers différentes industries verticales en aval pour des recommandations personnalisées ( recommandation normale + zéro-shot recommandé).
PEACE - Cadre de recommandation interdomaine de pré-formation sur les graphes d'entités basé sur l'apprentissage de prototypes
Alignement préliminaire des connaissances entre domaines basé sur un graphe d'entité
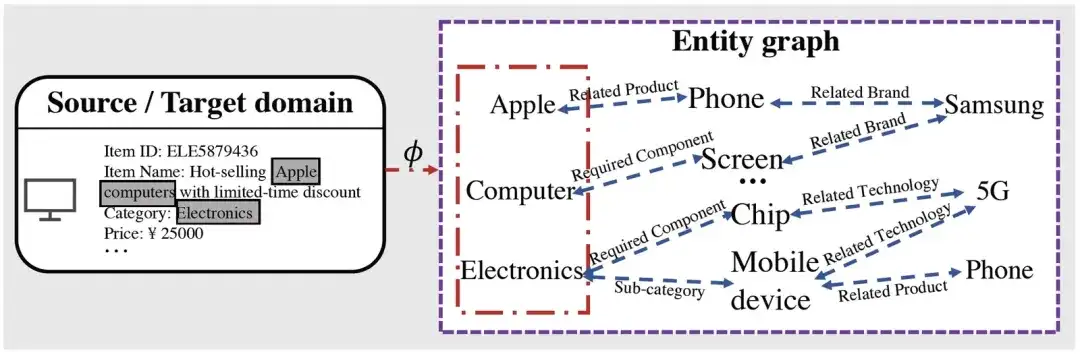

On peut voir qu'après avoir obtenu l'entité liée à l'élément correspondant via la cartographie, sur la base du processus de raisonnement graphique, nous pouvons obtenir de nombreuses informations de haut niveau liées à l'entité cartographiée. Par exemple, Apple propose des produits de téléphonie mobile et. entreprises liées aux produits de téléphonie mobile Il existe Samsung, etc., qui peuvent potentiellement raccourcir les relations avec d'autres entités liées (telles que les téléphones mobiles produits par Samsung, etc.).
cadre de modèle
Dans cette section, nous présenterons le cadre de recommandation interdomaine de pré-formation graphique PEACE proposé dans cet article. La figure suivante montre l'architecture globale de PEACE. Dans l'ensemble, afin de mieux réaliser l'alignement inter-domaines et de mieux utiliser les informations structurelles dans le graphe d'entité, notre cadre global est construit sur le module de pré-formation orienté entité afin d'améliorer encore la relation entre les utilisateurs et les entités dans le ; module de pré-formation Représentation pour la rendre plus polyvalente et transférable, nous proposons un module d'amélioration de la représentation de l'entité basé sur l'apprentissage du contraste du prototype et un module d'amélioration de la représentation de l'utilisateur basé sur le mécanisme d'attention de l'amélioration du prototype pour améliorer sa représentation sur cette base, nous définissons des objectifs d'optimisation ; et un processus de déploiement en ligne léger dans la phase de pré-formation et la phase de réglage fin . Ensuite, nous présenterons chaque module un par un.
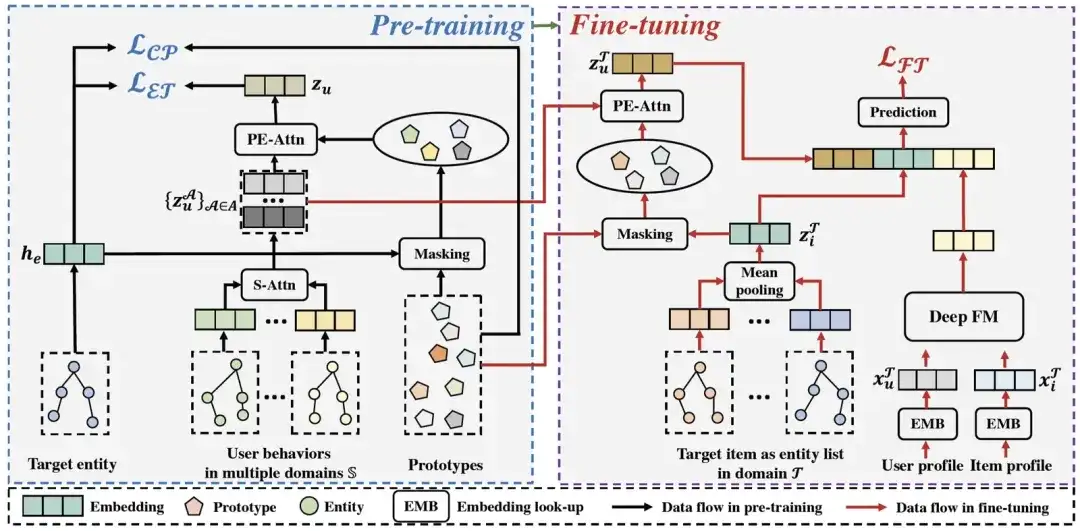
Architecture globale de la PAIX
01. Module de pré-formation orienté entité
Les plateformes de services en ligne telles qu'Alipay rassemblent une variété de petits programmes/scénarios fournis par différents fournisseurs de services. De manière générale, les informations entre ces scénarios ne sont pas interopérables et il n'y a donc pas de système de données partagé, même s'ils sont de la même marque. catégorie, les attributs des produits actuels ne peuvent pas être complètement alignés (par exemple, l'iPhone 14 vendu dans différents mini-programmes a des ID de produit et des noms de catégorie différents. Par exemple, la catégorie est constituée de produits électroniques dans un mini-programme et la catégorie est constituée d'électronique dans un autre mini programme) . Afin de réduire les différences causées par ces problèmes potentiels et leur impact sur les performances de la modélisation, et en même temps de mieux utiliser ces informations interactives, nous effectuons une pré-formation basée sur la carte d'entité, dans l'espoir d'introduire des informations granulaires sur l'entité dans de cette façon. Réalisez une pré-formation avec une généralisation plus forte.


En prenant la figure 1 comme exemple, s'il s'agit d'un élément → entité → entité, à partir de ce produit, pour Apple, nous ne pouvons savoir que ses produits associés sont le téléphone, mais grâce à la pré-formation de entité → entité → entité, nous pouvons savoir qu'Apple n'est pas seulement avec des produits associés comme le téléphone, on peut aussi savoir qu'il est lié à la société Samsung, améliorant ainsi encore la généralisation des représentations que nous avons apprises).
02. Module d'amélioration de la représentation des entités basé sur un prototype d'apprentissage contrastif

03. Module d'amélioration de la représentation des utilisateurs basé sur un prototype de mécanisme d'attention amélioré
Au cours de la phase de pré-formation, les données collectées dans le domaine source contiennent le comportement des utilisateurs dans différents scénarios. Par exemple, lorsqu'ils planifient un voyage, les utilisateurs visiteront des scénarios liés au voyage et lorsqu'ils rechercheront un emploi, ils visiteront des emplois en ligne. Dans les scénarios associés, cependant, la représentation générale de l'utilisateur apprise à l'étape précédente ne prend pas en compte le contexte lié à l'utilisateur et à la scène, ce qui rend impossible la capture de la représentation liée à la scène dans différentes scènes. pour utiliser le mécanisme d'attention pour améliorer le contexte Capture afin d'améliorer la représentation de l'utilisateur.

04. Formation et prédiction du modèle
- Lien de pré-formation du domaine source
En combinant le module de pré-formation orienté entité et le module d'amélioration de l'apprentissage du prototype, l'objectif global d'optimisation peut être défini de la manière suivante :
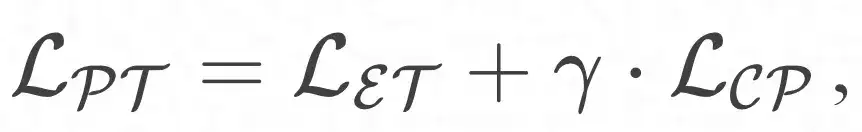

- Lien de réglage fin du domaine cible

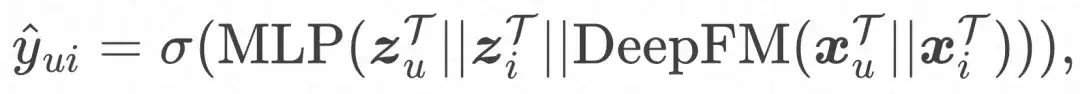
Et la fonction de perte finale :
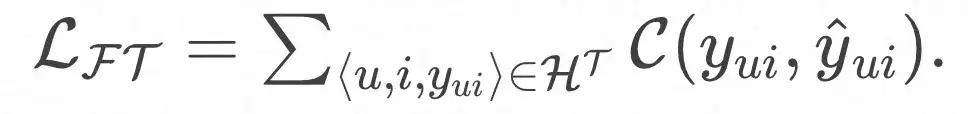

Déploiement en ligne
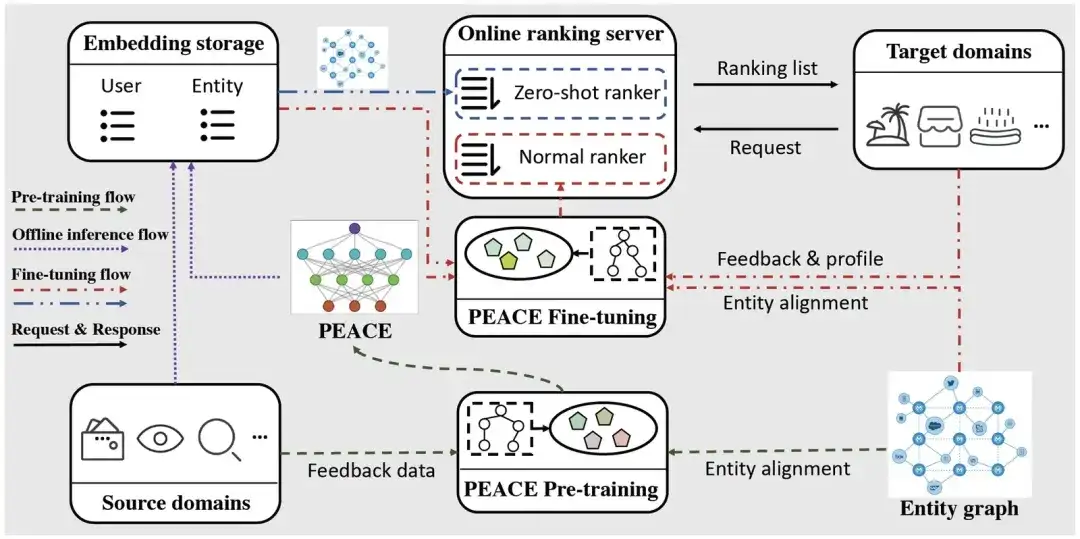
Afin d'alléger la pression sur les services en ligne, nous utilisons une méthode légère pour déployer le modèle PEACE. Le flux de déploiement est principalement divisé en trois parties :
- Flux de pré-formation : sur la base des données comportementales multi-sources et des cartes d'entités collectées, nous mettons à jour quotidiennement le modèle PEACE afin que le modèle puisse acquérir des connaissances transférables universelles et sensibles au facteur temps. Pour le modèle pré-entraîné, nous le stockons dans ModelHub pour faciliter le chargement léger des paramètres du modèle pour une utilisation en aval.
- Flux d'inférence hors ligne : afin de réduire la charge apportée par le réseau neuronal graphique au système de service en ligne, nous déduirons à l'avance les représentations de l'utilisateur et de l'entité, puis les stockerons dans la table ODPS uniquement lors du réglage fin en aval. le MLP final Le réseau est affiné sans refaire le processus de propagation des informations dans le réseau neuronal graphique, réduisant ainsi considérablement la latence des services en ligne.
- Flux de réglage fin : étant donné que les mini-programmes/services nouvellement lancés ne disposent pas de données interactives, PEACE fournit des services de recommandation à travers les deux étapes suivantes :
- Pour le scénario de démarrage à froid, en effectuant directement le produit interne des représentations de l'utilisateur et des éléments, nous pouvons obtenir la préférence de l'utilisateur pour différents éléments et les trier directement ;
- Pour les scénarios de démarrage non à froid dans lesquels une certaine quantité de données a été accumulée, nous affinons en fonction de la représentation utilisateur/élément pré-entraînée et des informations de base utilisateur/élément, puis utilisons le modèle affiné pour les services en ligne.
Analyse d'efficacité
Expérience hors ligne
01. Présentation des données
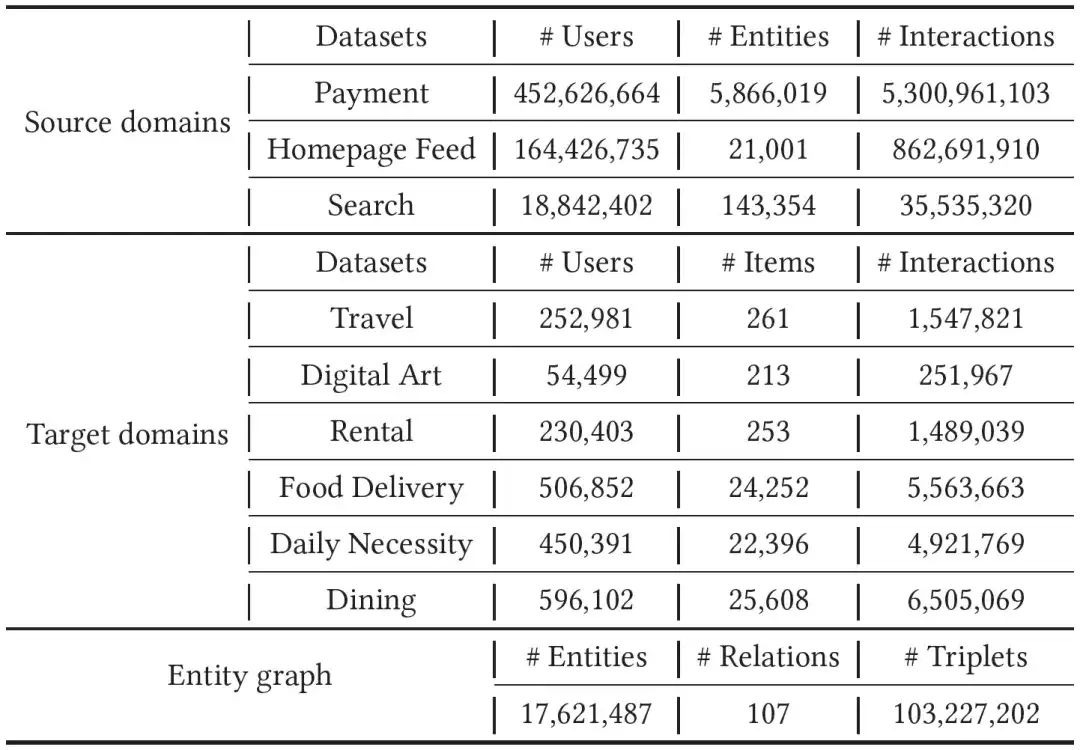
Nous avons collecté les factures Alipay, les empreintes et les données de recherche d'un mois en tant que données de domaine source. Pour le domaine cible, nous avons mené des expériences sur six types de mini-programmes, à savoir la location, les voyages, les collections numériques, les nécessités quotidiennes, la gastronomie et la livraison de nourriture. .Expérimentez, étant donné que les données du domaine cible sont plus rares que celles du domaine source, nous avons collecté des données comportementales au cours des deux derniers mois pour la formation du modèle. Afin de combler les énormes différences entre les différents domaines, nous avons introduit un graphe d'entités comportant des dizaines de millions de nœuds, des centaines de relations et des milliards d'arêtes. Des données spécifiques peuvent être trouvées dans le tableau ci-dessous.
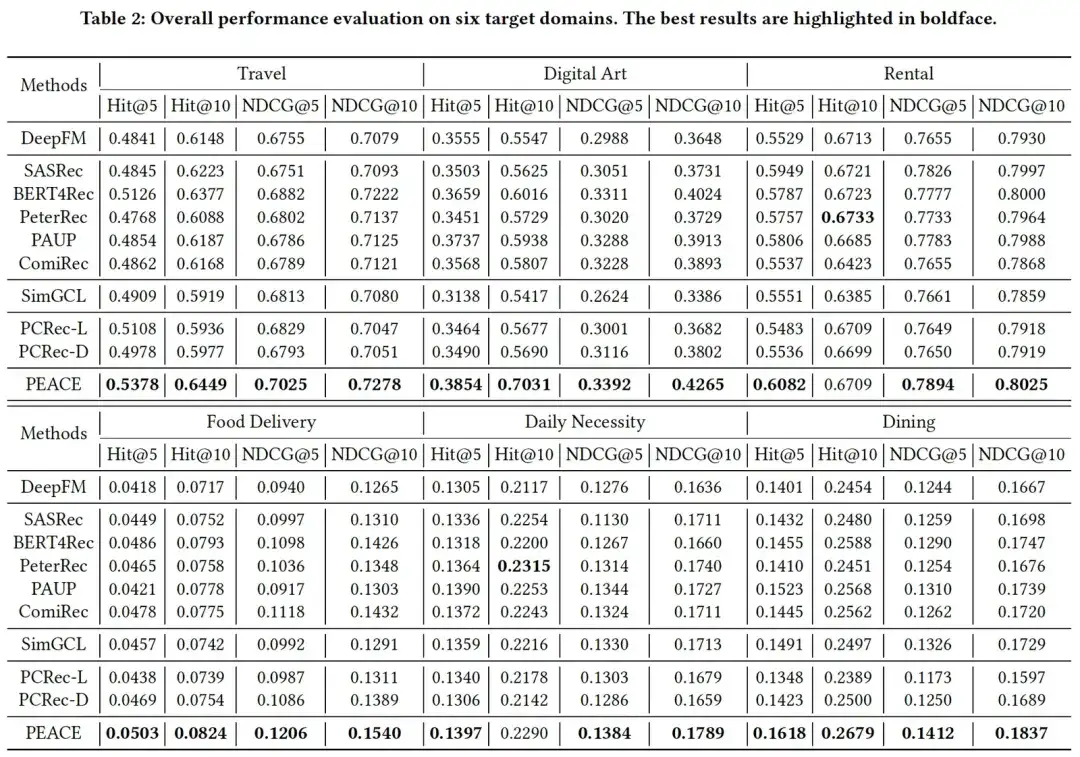
02. Expérience d'efficacité
En combinant les résultats expérimentaux dans les deux tableaux, nous pouvons constater que, globalement, les résultats expérimentaux montrent :
- PEACE a réalisé des améliorations significatives par rapport à la référence dans les scénarios de démarrage à froid et de démarrage non à froid, ce qui démontre l'efficacité de la combinaison de mécanismes de pré-formation basés sur la granularité des entités et d'amélioration basée sur l'apprentissage des prototypes ;
- Dans la plupart des cas, le modèle pré-entraîné + affiné présente une plus grande amélioration que le DeepFM de base sans pré-entraînement, ce qui illustre l'efficacité de l'introduction de données multi-sources pour la pré-entraînement. Cependant, dans certains cas, certaines performances. du modèle n'est pas aussi bon que le DeepFM de base, et il existe un certain degré de transfert négatif, ce qui illustre encore l'importance des méthodes de pré-formation ;
- Dans de nombreux cas, les modèles de recommandation inter-domaines basés sur gnn n'ont pas obtenu de bons résultats expérimentaux. Cela est en grande partie dû à l'énorme bruit dans le graphe d'entités. Depuis que nous avons introduit l'apprentissage des prototypes dans le modèle PEACE, la méthode de classification crée des entités similaires. ont des distances similaires dans l'espace de représentation, tandis que la distance entre les différentes entités est plus étendue, atténuant ainsi l'impact négatif de ces bruits sur le modèle.
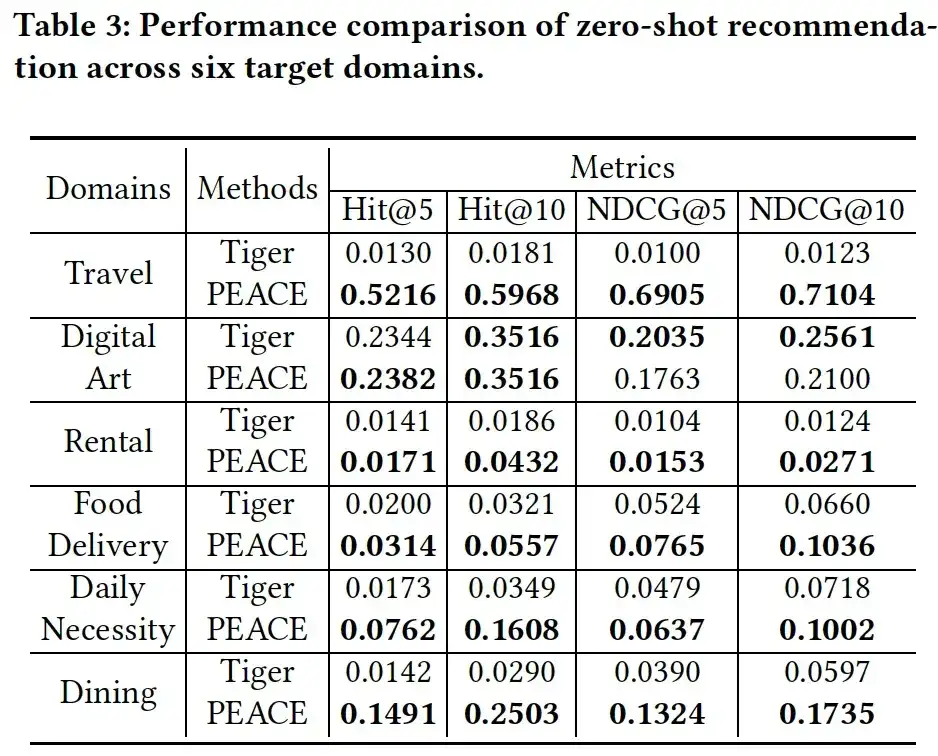
03. Analyse d'ablation
Afin de vérifier davantage le rôle de chaque module dans le modèle PEACE, nous avons préparé les trois variantes suivantes pour évaluer l'efficacité de chaque module :
- PEACE w/o GL, le module d'apprentissage des graphes lorsque les représentations d'entités sont supprimées ;
- PEACE sans CPL, c'est-à-dire suppression du module d'apprentissage du prototype basé sur la comparaison ;
- PEACE sans PEA, qui supprime le module de mécanisme d'attention basé sur l'amélioration du prototype. Comme le montre la figure 4, lorsqu'un module est supprimé, les performances du modèle diminuent considérablement, ce qui illustre le caractère indispensable de chaque module dans le modèle. De plus, on peut voir que les performances de PEACE sans CPL sont au pire ; cela illustre l’importance de l’apprentissage par prototype pour capturer les connaissances générales transférables.
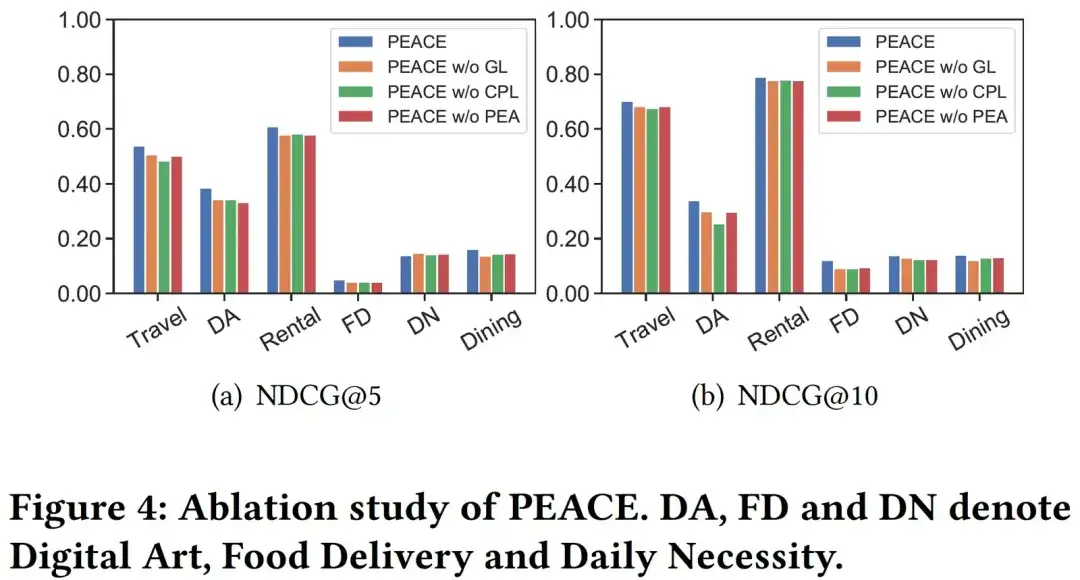
04. Analyse visuelle
Afin d'analyser plus explicitement l'effet du module CPL, nous avons sélectionné au hasard 6000 entités dans la carte d'entités et leurs représentations d'entités apprises grâce aux modèles PEACE sans CPL et PEACE pour les visualiser. Voici différentes couleurs correspondant aux différents prototypes appartenant. à différentes entités. De la figure 5, nous pouvons voir que par rapport à la représentation d'entité apprise par PEACE sans CPL, la représentation apprise par le modèle PEACE complet a une meilleure cohérence dans les résultats de clustering, ce qui illustre le module CPL et son Le prototype appris peut bien aider le Le modèle réduit la distance entre les entités similaires dans l'espace de représentation, aidant ainsi mieux le modèle à acquérir des connaissances plus robustes et universelles.
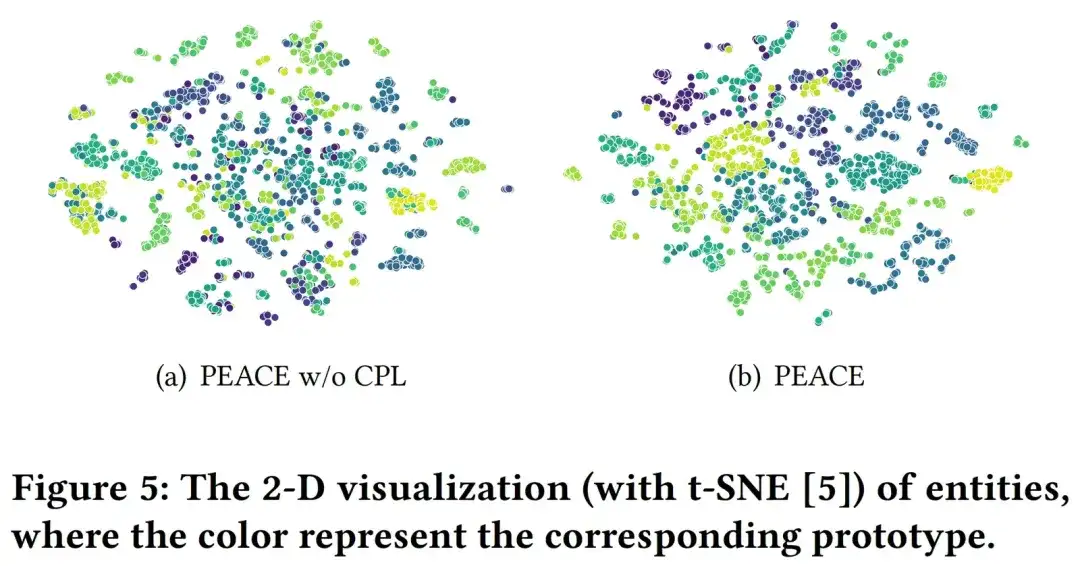
Expériences en ligne et mise en œuvre commerciale
Afin de mieux vérifier l'effet du modèle dans l'environnement de production réel, nous avons mené des expériences AB en ligne raffinées chez plusieurs commerçants de différentes catégories verticales, dans plusieurs scénarios, le modèle PEACE a obtenu des résultats efficaces par rapport à la promotion de base. Dans l'ensemble, le modèle de recommandation de pré-formation et d'apprentissage par transfert basé sur PEACE a été entièrement appliqué comme modèle de base à plus de 50 commerçants pour fournir des recommandations personnalisées après avoir été vérifié par des effets ab sur les commerçants clés.
Recommandations d'articles
OpenSPG v0.0.3 est publié, ajoutant l'extraction de connaissances unifiée de grands modèles et la visualisation de graphiques open source ! Ant Group et l'Université du Zhejiang lancent conjointement OneKE, un cadre d'extraction de connaissances open source à grande échelle
Suivez-nous
OpenSPG :
Site officiel : https://spg.openkg.cn
Github : https://github.com/OpenSPG/openspg
OpenASCE :
https://openasce.openfinai.org/ GitHub
: [https://github.com/Open-All-Scale-Causal-Engine/OpenASCE ]