
Tout le monde est invité à nous mettre en vedette sur GitHub :
Système d'apprentissage causal distribué à lien complet OpenASCE : https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
Grand graphe de connaissances basé sur un modèle OpenSPG : https://github.com/OpenSPG/openspg
Système d'apprentissage de graphes à grande échelle OpenAGL : https://github.com/TuGraph-family/TuGraph-AntGraphLearning
Les 25 et 26 avril, la conférence mondiale sur les technologies d'apprentissage automatique s'est tenue au Hyatt Regency Global Harbor Hotel à Shanghai ! Wang Qinlong, responsable du DLRover open source chez Ant Group, a prononcé un discours d'ouverture sur « l'auto-guérison des défauts de formation du DLRover : améliorer de manière significative l'efficacité de la puissance de calcul de la formation à l'IA à grande échelle » lors de la conférence, expliquant comment s'auto-réparer rapidement échecs lors d'opérations de formation de modèles à grande échelle de kilocalories. Wang Qinlong a présenté les principes techniques et les cas d'utilisation derrière DLRover, ainsi que les effets pratiques de DLRover sur les grands modèles communautaires.

Wang Qinlong, qui est engagé depuis longtemps dans la recherche et le développement de l'infrastructure d'IA chez Ant, a dirigé la construction des projets de tolérance aux pannes élastiques et d'expansion et de contraction automatiques de la formation distribuée Ant. Il a participé à plusieurs projets open source, tels que ElasticDL et DLRover, un contributeur dynamique Open Source 2023 de l'Open Atomic Foundation et un ingénieur exceptionnel T-Star 2022 d'Ant Group. Actuellement, il est l'architecte du projet open source Ant AI Infra DLRover, qui se concentre sur la création de systèmes de formation distribués à grande échelle stables, évolutifs et efficaces.
Formation et défis sur les grands modèles
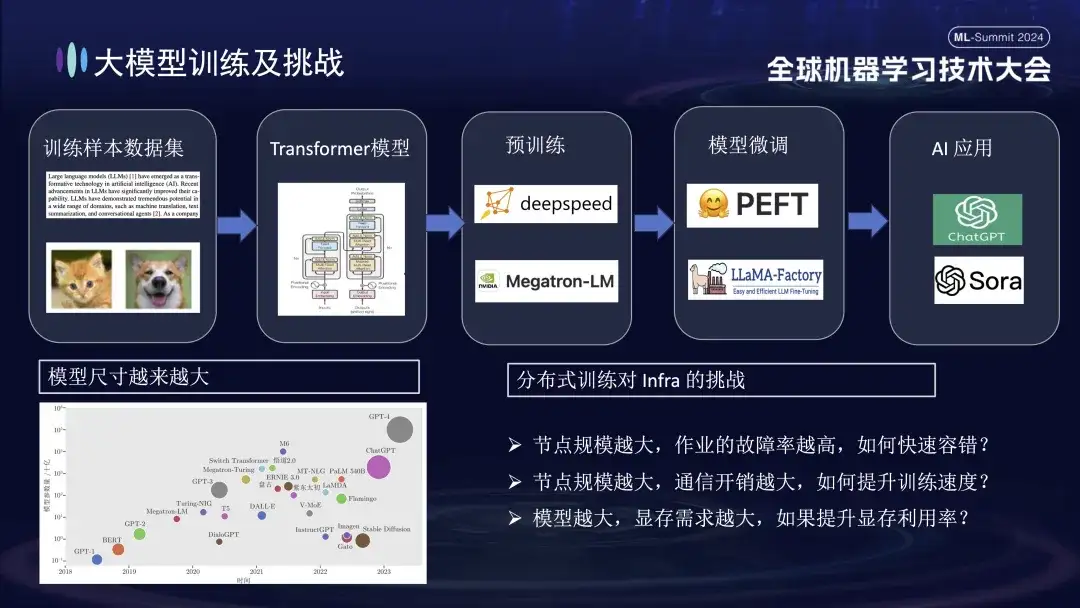
Le processus de base de la formation d'un grand modèle est illustré dans la figure ci-dessus. Il nécessite la préparation d'échantillons de données de formation, la construction du modèle Transformer, la pré-formation, le réglage fin du modèle et enfin la création d'une application d'IA utilisateur. Alors que les grands modèles passent d'un milliard de paramètres à un billion de paramètres, la croissance de l'échelle de formation a entraîné une augmentation des coûts de cluster et a également affecté la stabilité du système. Les coûts élevés d'exploitation et de maintenance entraînés par un système à si grande échelle sont devenus un problème urgent qui doit être résolu lors de la formation de grands modèles.
- Plus la taille du nœud est grande, plus le taux d'échec des tâches est élevé. Comment tolérer rapidement les pannes ?
- Plus la taille du nœud est grande, plus la surcharge de communication est importante. Comment améliorer la vitesse de formation ?
- Plus la taille du nœud est grande, plus les besoins en mémoire sont importants. Comment améliorer l'utilisation de la mémoire ?
Pile technologique d’ingénierie Ant AI
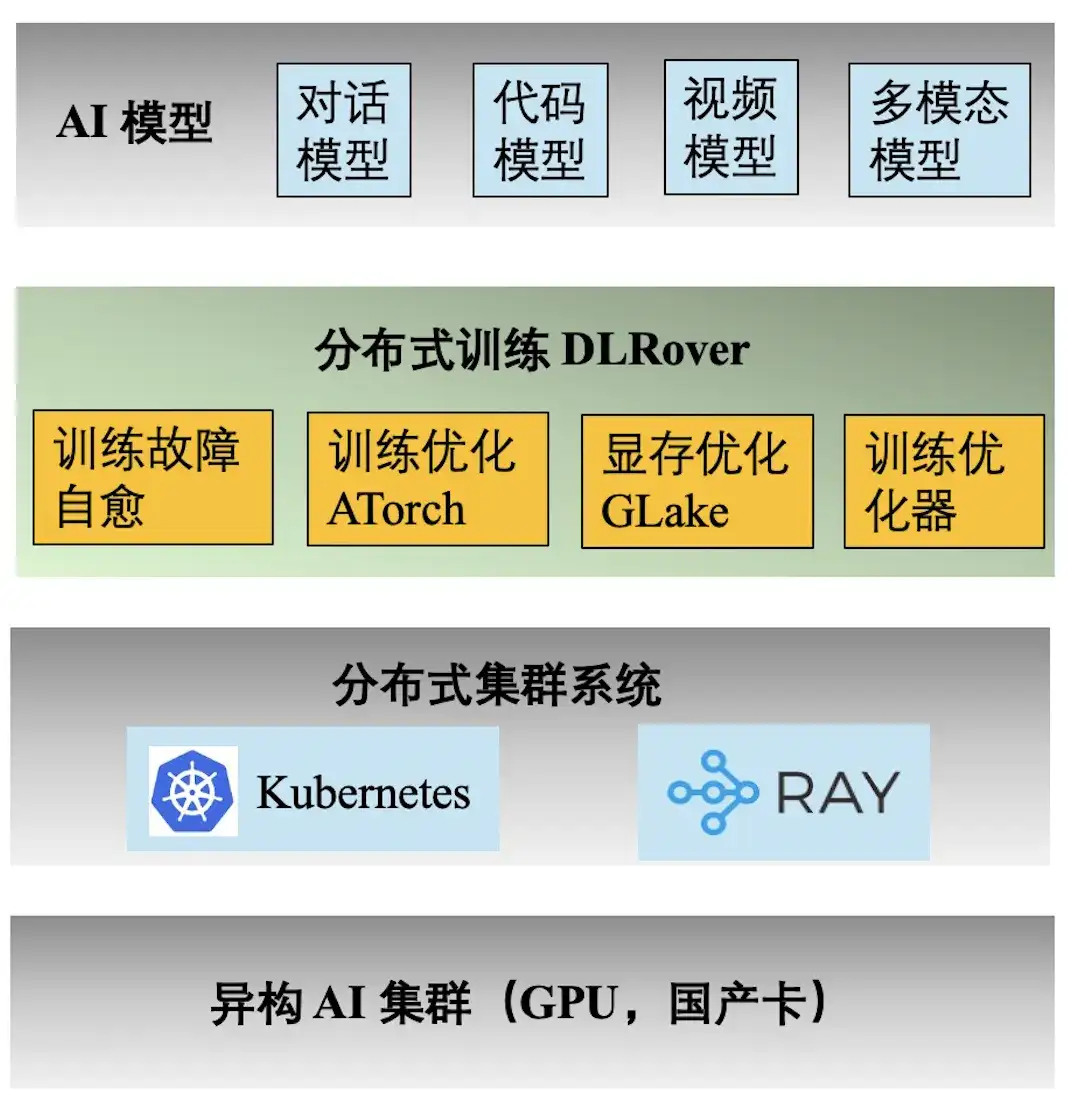
La figure ci-dessus montre la pile technologique d'ingénierie de la formation Ant AI. Le moteur de formation distribué DLRover prend en charge une variété de tâches de formation pour les modèles de dialogue, de code, de vidéo et multimodaux d'Ant. Voici les principales fonctionnalités fournies par DLRover :
- **Auto-guérison des défauts d'entraînement :** Augmentez la durée effective de l'entraînement distribué en kilocalories à >97 %, réduisant ainsi le coût en puissance de calcul des défauts d'entraînement à grande échelle ;
- ** Optimisation de la formation ATorch : ** Sélectionnez automatiquement la stratégie de formation distribuée optimale en fonction du modèle et du matériel. Augmenter le taux d'utilisation de la puissance de calcul du matériel du cluster Kcal (A100) à >60 % ;
- **Optimiseur de formation :** L'optimiseur équivaut à la navigation dans l'itération du modèle, ce qui peut nous aider à atteindre l'objectif sur le chemin le plus court. Notre optimiseur améliore l'accélération de la convergence de 1,5 fois par rapport à AdamW. Les résultats pertinents ont été publiés dans ECML PKDD '21, KDD'23, NeurIPS '23 ;
- **Mémoire vidéo et optimisation de la transmission GLake : **Pendant le processus de formation de grands modèles, de nombreux fragments de mémoire vidéo seront générés, ce qui réduit considérablement l'utilisation des ressources de mémoire vidéo. Nous réduisons les besoins en mémoire d'entraînement de 2 à 10 fois grâce à l'optimisation intégrée de la mémoire + de la transmission et à l'optimisation globale de la mémoire. Les résultats ont été publiés à ASPLOS'24.
Pourquoi les pannes entraînent un gaspillage de puissance de calcul
La raison pour laquelle Ant accorde une attention particulière au problème des échecs de formation est principalement parce que les pannes de machines pendant le processus de formation augmentent considérablement le coût de la formation. Par exemple, Meta a annoncé les données réelles de sa formation sur de grands modèles en 2022. Lors de la formation du modèle OPT-175B, il a utilisé 992 GPU A100 de 80 Go, soit un total de 124 machines à 8 cartes. Selon les prix des GPU AWS, cela coûte environ 700 000. par jour. . En raison de l'échec, le cycle de formation a été prolongé de plus de 20 jours, augmentant ainsi le coût de la puissance de calcul de plusieurs dizaines de millions de yuans.

L'image ci-dessous montre la répartition des défauts rencontrés lors de la formation de grands modèles sur des clusters Alibaba Cloud. Certains de ces défauts peuvent être résolus par le redémarrage, tandis que d'autres ne peuvent pas être réparés par le redémarrage. Par exemple, le problème de chute de carte, car la carte défectueuse est toujours endommagée après le redémarrage. La machine endommagée doit être remplacée avant que le système puisse être redémarré et restauré.
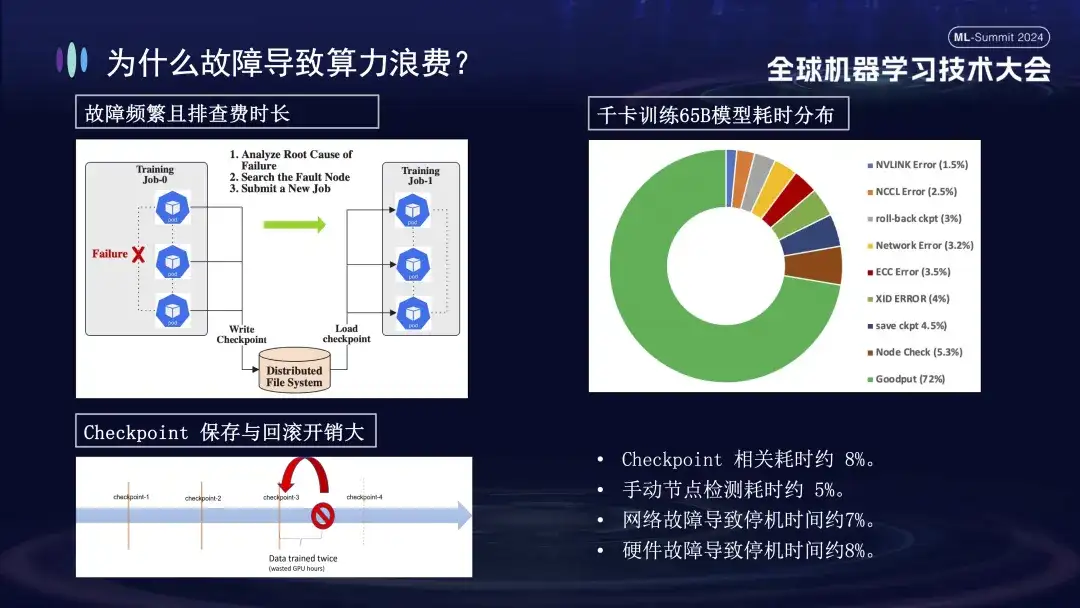
Pourquoi les échecs de formation ont-ils un si grand impact ? Tout d'abord, la formation distribuée nécessite que plusieurs nœuds fonctionnent ensemble. Si un nœud tombe en panne (qu'il s'agisse d'un problème logiciel, matériel, de carte réseau ou de GPU), l'ensemble du processus de formation doit être suspendu. Deuxièmement, après un échec de formation, le dépannage prend du temps et est laborieux. Par exemple, la méthode d'inspection manuelle couramment utilisée nécessite désormais au moins 1 à 2 heures pour une vérification unique. Enfin, la formation est avec état. Pour redémarrer la formation, vous devez récupérer de l'état de formation précédent avant de continuer, et l'état de formation doit être enregistré après un certain temps. Le processus de sauvegarde prend beaucoup de temps et une restauration en cas d'échec entraînera également un gaspillage de calculs. L'image de droite ci-dessus montre la répartition du temps de formation avant de passer en ligne pour effectuer l'auto-réparation. On peut voir que le temps pertinent de Checkpoint est d'environ 8 %, le temps de détection manuelle des nœuds est d'environ 5 % et le temps d'arrêt provoqué. par panne de réseau est d'environ 7 %, la panne matérielle provoque environ 8 % des temps d'arrêt et le temps de formation effectif final n'est qu'environ 72 %.
Présentation des fonctions d'auto-réparation des défauts d'entraînement DLRover

L'image ci-dessus montre les deux fonctions principales de DLRover dans la technologie d'auto-réparation des pannes. Tout d'abord, Flash Checkpoint peut enregistrer rapidement l'état sans arrêter le processus de formation et réaliser une sauvegarde à haute fréquence. Cela signifie qu'en cas de panne, le système peut immédiatement récupérer du point de contrôle le plus récent, réduisant ainsi la perte de données et le temps de formation. Deuxièmement, DLRover utilise Kubernetes pour implémenter un mécanisme de planification élastique intelligent. Ce mécanisme peut répondre automatiquement aux pannes de nœuds. Par exemple, si l'un d'entre eux tombe en panne dans un cluster de 100 machines, le système s'ajustera automatiquement à 99 machines pour continuer la formation sans intervention manuelle. De plus, il est compatible avec Kubeflow et PyTorchJob et renforce les capacités de surveillance de l'état des nœuds pour garantir que tout défaut est rapidement identifié et résolu dans les 10 minutes, maintenant ainsi la continuité et la stabilité des opérations de formation.
Formation élastique à la tolérance aux pannes DLRover
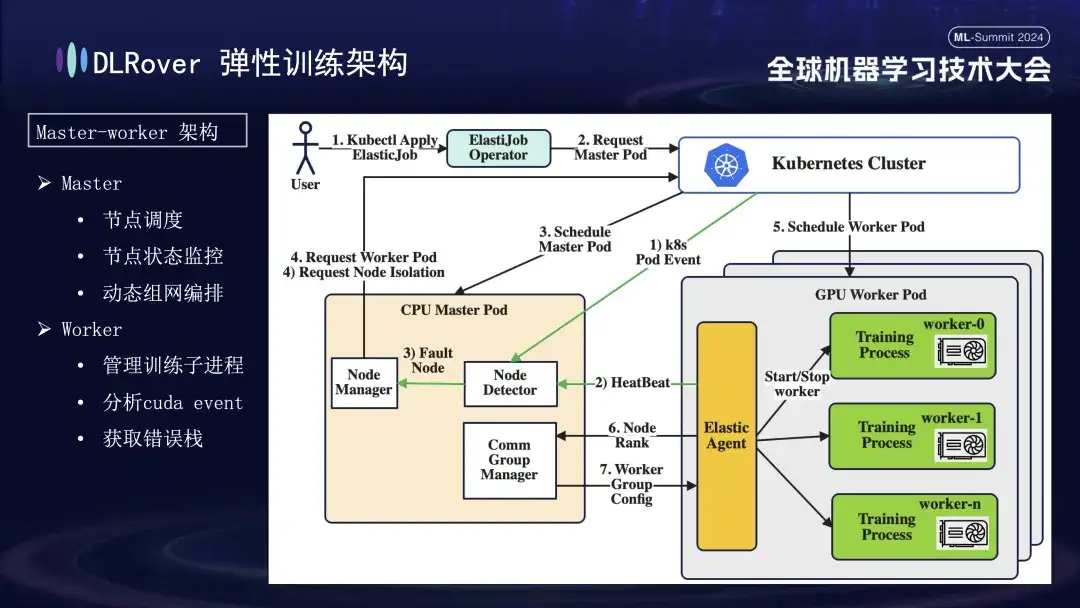
DLRover adopte une architecture maître-travailleur, ce qui n'était pas courant aux débuts de l'apprentissage automatique. Dans cette conception, le maître sert de centre de contrôle et est responsable des tâches clés telles que la planification des nœuds, la surveillance de l'état, la gestion de la configuration réseau et l'analyse du journal des pannes, sans exécuter le code de formation. Généralement déployé sur les nœuds CPU. Les travailleurs supportent la charge de formation réelle et chaque nœud exécutera plusieurs sous-processus pour utiliser les multiples GPU du nœud afin d'accélérer les tâches informatiques. De plus, afin d'améliorer la robustesse du système, nous avons personnalisé et amélioré l'Elastic Agent sur le travailleur pour permettre une détection et une localisation plus efficaces des défauts, garantissant ainsi la stabilité et l'efficacité pendant le processus de formation.
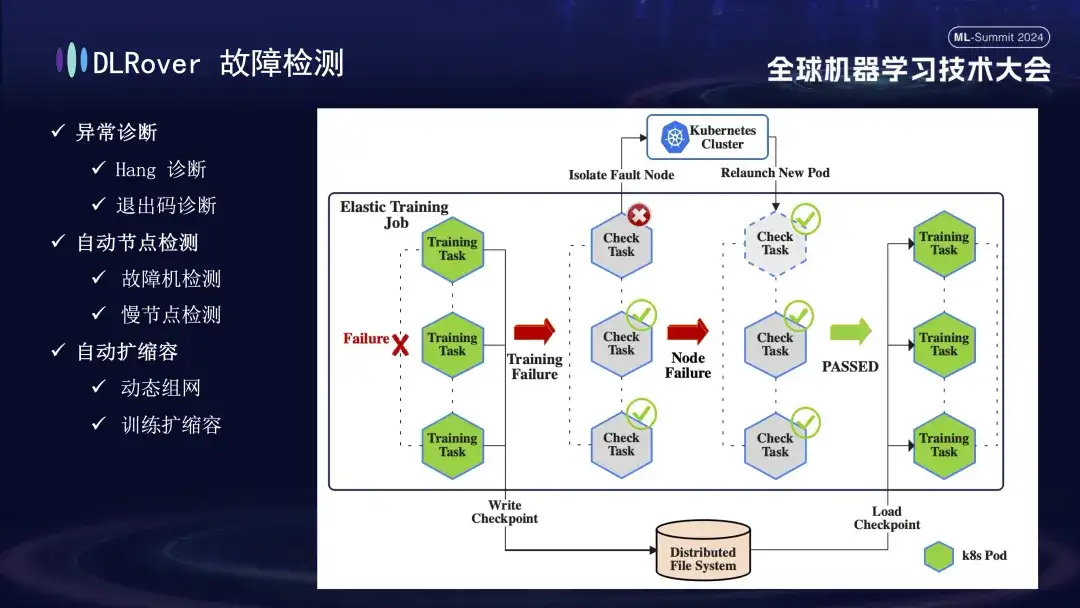
Vient ensuite le processus de détection des pannes. Lorsqu'un défaut survient pendant le processus de formation et que la tâche est interrompue, la performance intuitive est que la formation est suspendue, mais la cause et la source spécifiques du défaut ne sont pas directement apparentes, car une fois qu'un défaut se produit, toutes les machines associées s'arrêteront simultanément. . Pour résoudre ce problème, nous avons immédiatement exécuté le script de détection sur toutes les machines après la panne. Une fois qu'il est détecté qu'un nœud échoue à l'inspection, le cluster Kubernetes sera immédiatement averti pour supprimer le nœud défaillant et redéployer un nouveau nœud de remplacement. Le nouveau nœud effectue d'autres vérifications de l'état avec les nœuds existants. Une fois que tout est correct, la tâche de formation est automatiquement redémarrée. Il est à noter que si un nœud défectueux est isolé et entraîne des ressources insuffisantes, nous mettrons en œuvre une stratégie de réduction (qui sera présentée en détail plus tard). Lorsque la machine défectueuse d'origine revient à la normale, le système effectuera automatiquement des opérations d'expansion de capacité pour assurer une formation efficace et continue.
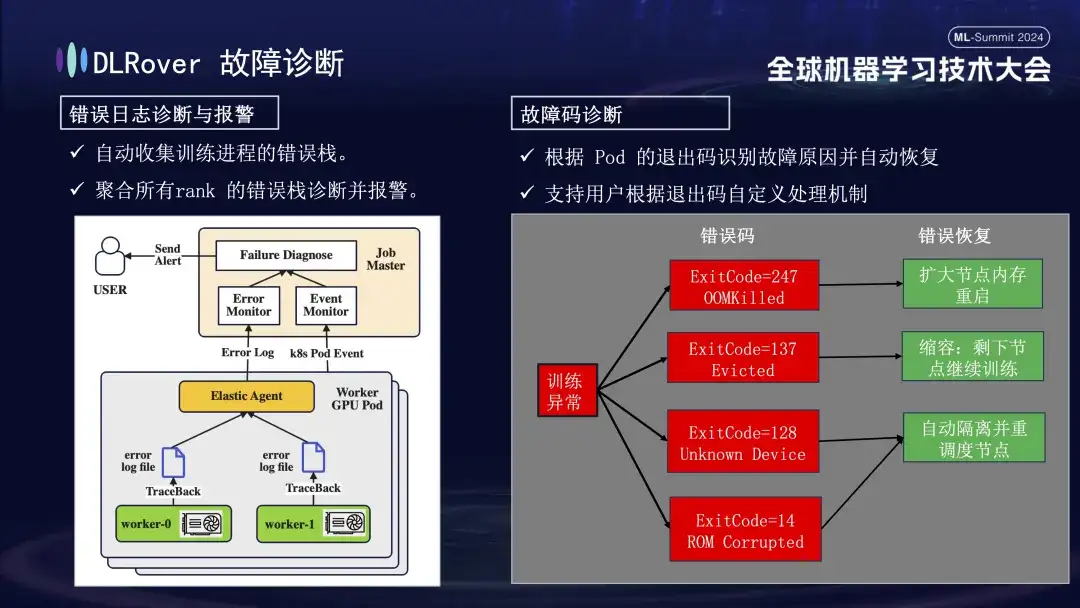
Vient ensuite le processus de diagnostic des pannes, qui utilise les méthodes complètes suivantes pour obtenir une localisation et un traitement rapides et précis des pannes :
- Tout d'abord, l'agent collecte les informations sur les erreurs de chaque processus de formation et résume ces piles d'erreurs au nœud maître. Le nœud maître analyse ensuite les données d'erreur agrégées pour identifier la machine présentant le problème. Par exemple, si un journal de la machine indique une erreur ECC, le défaut de la machine est directement déterminé et éliminé.
- De plus, le code de sortie de Kubernetes peut également être utilisé pour faciliter le diagnostic. Par exemple, le code de sortie 137 indique généralement que la plate-forme informatique sous-jacente met fin à la machine en raison d'un problème détecté. Le code de sortie 128 signifie que le périphérique n'est pas reconnu ; le pilote GPU est peut-être défectueux. Il existe également un grand nombre de défauts qui ne peuvent pas être détectés via les codes de sortie. Les plus courants incluent les délais d'attente de gigue du réseau.
- Il existe également de nombreuses défaillances, telles que des délais d'attente provoqués par des fluctuations du réseau, qui ne peuvent pas être identifiées uniquement par les codes de sortie. Nous adopterons une stratégie plus générale : quelle que soit la nature spécifique de la panne, l'objectif premier est d'identifier et de supprimer rapidement le nœud défaillant, puis d'avertir le maître pour détecter spécifiquement où se situe le problème.
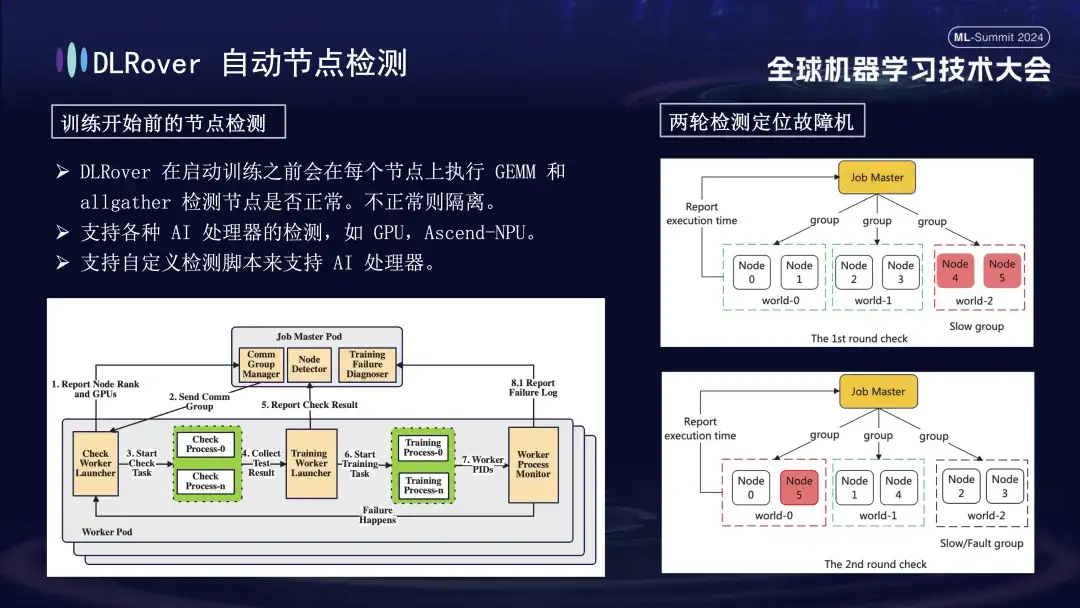
Tout d’abord, la multiplication matricielle est effectuée sur tous les nœuds. Par la suite, les nœuds sont appariés et regroupés. Par exemple, dans un pod comportant 6 nœuds, les nœuds sont divisés en trois groupes (0,1), (2,3) et (4,5), et la détection de communication AllGather est effectuée. effectué. S'il y a un échec de communication entre 4 et 5, mais que la communication dans les autres groupes est normale, on peut conclure que l'échec existe dans le nœud 4 ou 5. Ensuite, le nœud suspecté défectueux est réapparié avec le nœud normal connu pour des tests supplémentaires, par exemple en combinant 0 et 5 pour la détection. En comparant les résultats, le nœud défectueux est identifié avec précision. Ce processus d'inspection automatisé diagnostique avec précision une machine défectueuse en dix minutes.
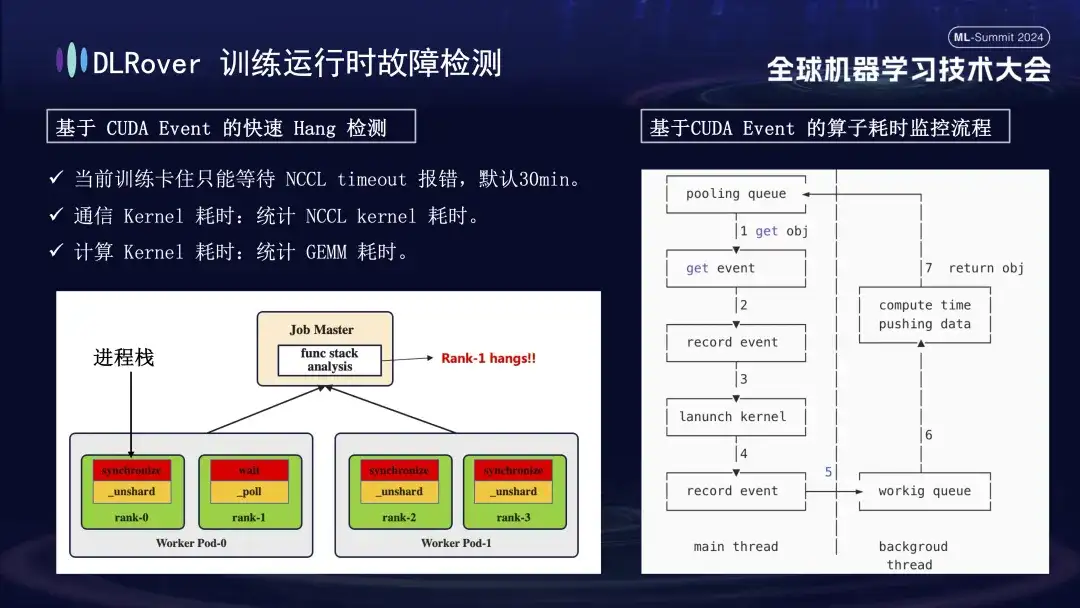
La situation d'interruption du système et de détection de pannes a déjà été évoquée, mais le problème de l'identification d'une machine bloquée doit être résolu. Le délai d'attente par défaut défini par NCCL est de 30 minutes, ce qui permet de retransmettre les données afin de réduire les faux positifs. Cependant, cela peut amener chaque carte à attendre 30 minutes en vain lorsqu'elle est réellement bloquée, ce qui entraîne d'énormes pertes cumulées. Afin de diagnostiquer avec précision le blocage, il est recommandé d'utiliser un outil de profilage affiné. Lorsqu'il est détecté que le programme est en pause, par exemple, il n'y a aucun changement dans la pile de programmes en une minute, les informations de pile de chaque carte sont enregistrées et les différences sont comparées et analysées. Par exemple, s'il s'avère que 3 rangs sur 4 effectuent l'opération de synchronisation et 1 effectue l'opération d'attente, vous pouvez localiser un problème avec le périphérique. De plus, nous avons détourné le noyau de communication et le noyau informatique clés de CUDA, inséré une surveillance des événements avant et après leur exécution et jugé si l'opération se déroulait normalement en calculant l'intervalle des événements. Par exemple, si une certaine opération n'est pas terminée dans les 30 secondes prévues, elle peut être considérée comme bloquée, et les journaux et piles d'appels pertinents seront automatiquement générés et soumis au maître pour comparaison afin de localiser rapidement la machine défectueuse.
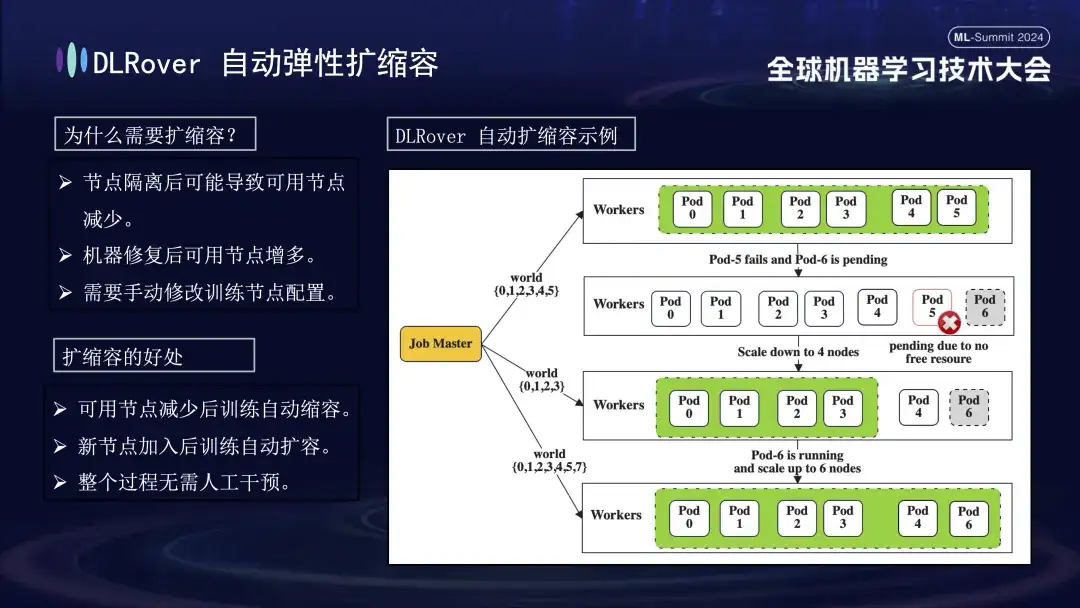
Une fois la machine défectueuse identifiée, compte tenu du coût et de l’efficacité, même s’il existait un mécanisme de sauvegarde lors de la formation précédente, le nombre était limité. À l’heure actuelle, il est particulièrement important d’introduire une stratégie d’expansion et de contraction élastique. Supposons que le cluster d'origine comporte 100 nœuds. Une fois qu'un nœud tombe en panne, les 99 nœuds restants peuvent continuer la tâche de formation ; une fois le nœud défaillant réparé, le système peut automatiquement reprendre son fonctionnement sur 100 nœuds, et ce processus ne nécessite aucune intervention manuelle. assurer un environnement de formation efficace et stable.
Point de contrôle Flash DLRover
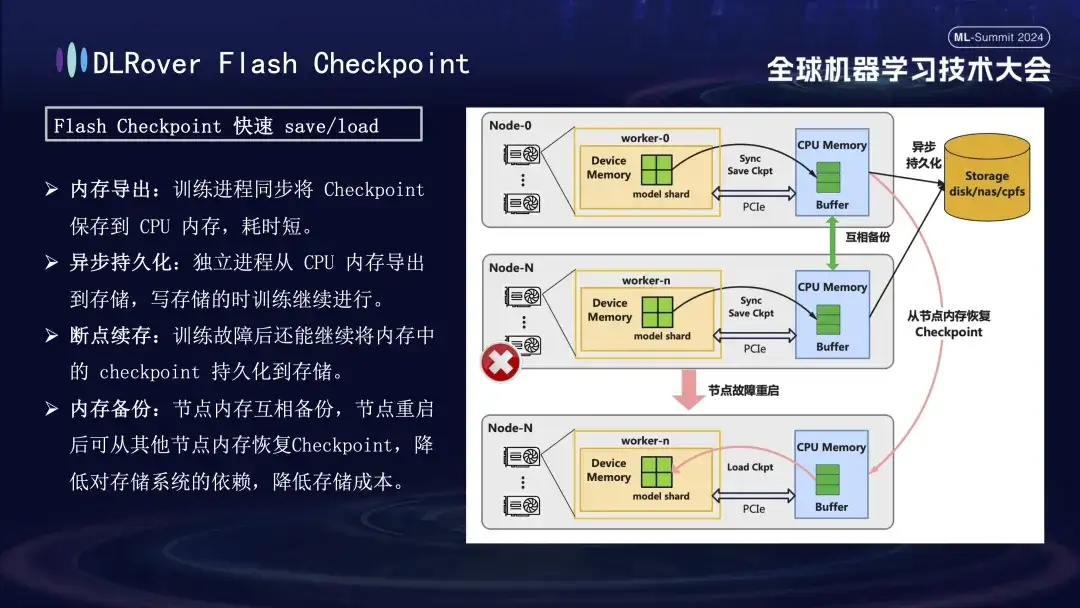
Dans le processus de récupération après échec de formation, la clé est de sauvegarder et de restaurer l'état du modèle. La méthode traditionnelle Checkpoint conduit souvent à une faible efficacité de la formation en raison du long gain de temps. Pour résoudre ce problème, DLRover a proposé de manière innovante la solution Flash Checkpoint, qui peut exporter l'état du modèle de la mémoire GPU vers la mémoire en temps quasi réel pendant le processus de formation. Elle est également complétée par un mécanisme de sauvegarde inter-mémoire pour garantir cela même si. un nœud tombe en panne, il peut restaurer rapidement l'état de formation à partir de la mémoire du nœud de sauvegarde, réduisant ainsi considérablement le temps de récupération après panne. Pour le Megatron-LM couramment utilisé, le processus d'exportation Checkpoint nécessite un processus centralisé à coordonner et à compléter, ce qui non seulement introduit une charge de communication et une consommation de mémoire supplémentaires, mais entraîne également des coûts de temps plus élevés. DLRover a adopté une approche innovante après optimisation, en utilisant une stratégie d'exportation distribuée afin que chaque nœud informatique (rang) puisse enregistrer et charger indépendamment son propre point de contrôle, évitant ainsi efficacement les besoins supplémentaires en matière de communication et de mémoire et améliorant considérablement l'efficacité.
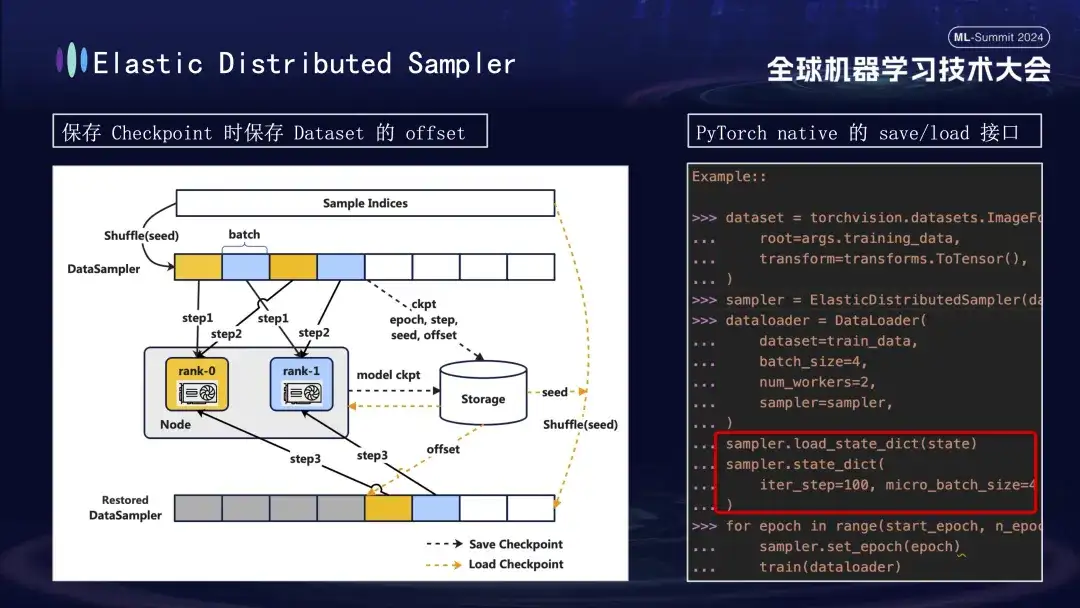
Lors de la création du modèle Checkpoint, un autre détail mérite une attention particulière. La formation du modèle est basée sur des données, en supposant que nous sauvegardons le point de contrôle à l'étape 1000 du processus de formation. Si l'entraînement est redémarré plus tard sans tenir compte de la progression des données, la réutilisation des données directement à partir de zéro entraînera deux problèmes : les nouvelles données ultérieures pourraient être manquées et les données précédentes pourraient être réutilisées. Pour résoudre ce problème, nous avons introduit la stratégie Distributed Sampler. Lors de l'enregistrement du point de contrôle, cette stratégie enregistre non seulement l'état du modèle, mais enregistre également la position de décalage de la lecture des données. De cette façon, lors du chargement du point de contrôle pour reprendre l'entraînement, l'ensemble de données continuera à être chargé à partir du point de décalage précédemment enregistré, puis avancera l'entraînement, assurant ainsi la continuité et la cohérence des données d'entraînement du modèle et évitant les erreurs de données ou les traitements répétés. .
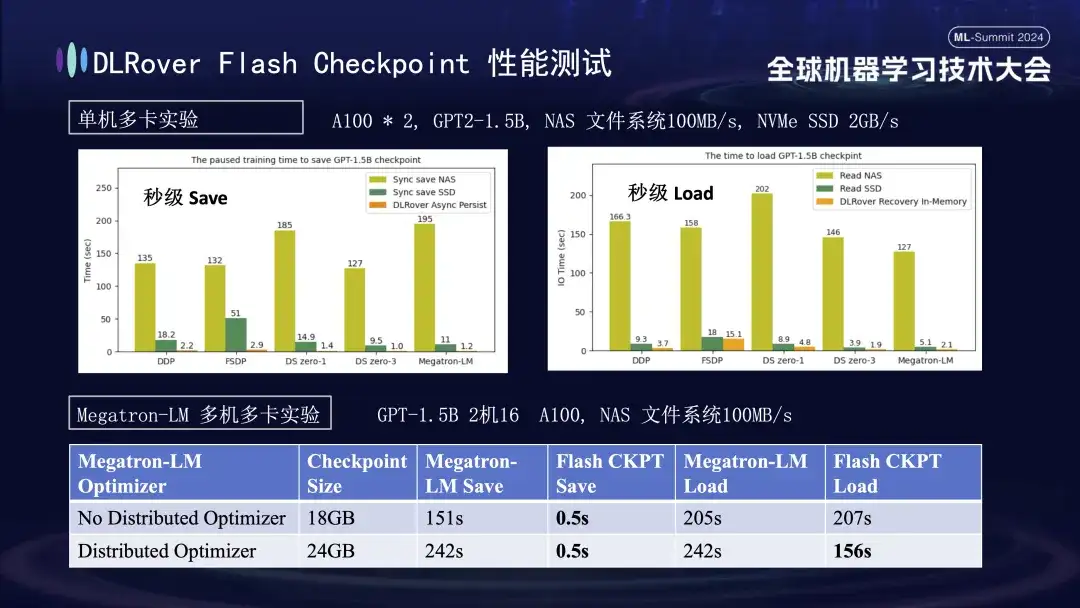
Dans le graphique ci-dessus, nous montrons les résultats expérimentaux dans un environnement multi-GPU (A100) sur une seule machine, visant à comparer l'impact de différentes solutions de stockage sur le temps de blocage provoqué par la sauvegarde de Checkpoint pendant le processus de formation. Les expériences montrent que les performances du système de stockage affectent directement l'efficacité : lors de l'utilisation d'une méthode de stockage moins efficace pour écrire directement des points de contrôle sur le disque, la formation sera considérablement bloquée et le temps sera prolongé. Plus précisément, pour un modèle Checkpoint de 1,5 Go d'une taille d'environ 20 Go, si le stockage NAS est utilisé, le temps d'écriture est d'environ 2 à 3 minutes ; Ce processus ne prend qu'environ 1 seconde en moyenne, ce qui améliore considérablement la continuité et l'efficacité de la formation.

La fonctionnalité Flash Checkpoint de DLRover est largement compatible avec les principaux frameworks de formation de grands modèles, notamment DDP, FSDP, DeepSpeed, Megatron-LM, transformers.Trainer et Ascend-DDP. Elle dispose d'API personnalisées pour chaque framework afin de garantir une utilisation extrêmement simple - Utilisateurs. il est rarement nécessaire d'ajuster le code de formation existant, cela fonctionne immédiatement. Plus précisément, les utilisateurs du framework DeepSpeed n'ont besoin que d'appeler l'interface de sauvegarde de DLRover lors de l'exécution de Checkpoint, tandis que l'intégration de Megatron-LM est encore plus simple. Ils n'ont qu'à remplacer l'instruction d'importation native de Checkpoint par la méthode d'importation fournie par DLRover. . Peut.
Pratique de formation distribuée DLRover
Nous avons mené une série d'expériences pour chaque scénario de défaillance afin d'évaluer la tolérance aux pannes du système, sa capacité à gérer des nœuds lents et sa flexibilité d'évolution vers le haut et vers le bas. Les expériences spécifiques sont les suivantes :
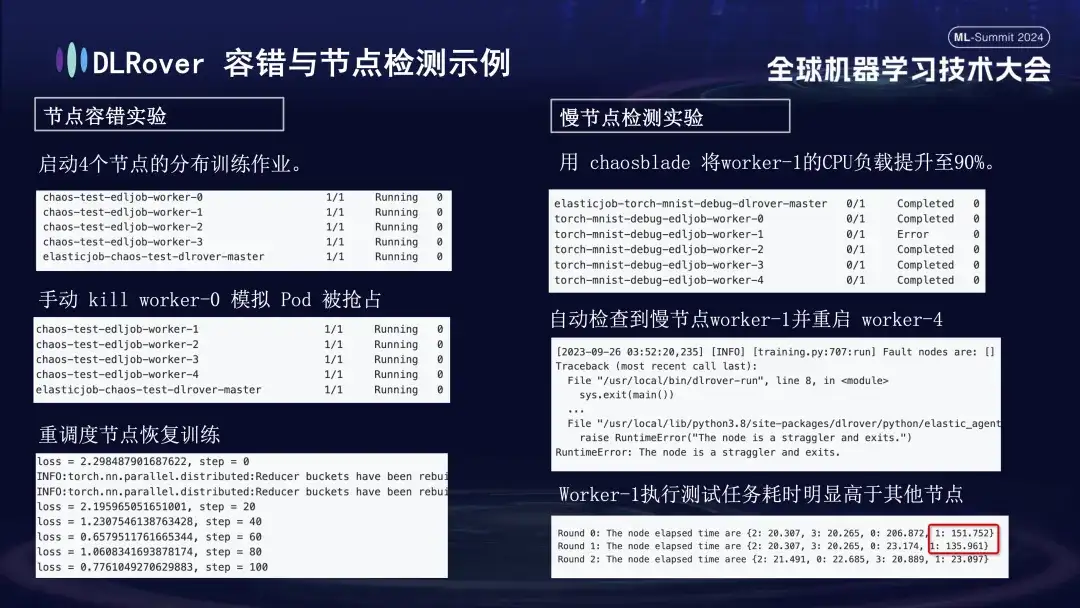
- Expérience de tolérance aux pannes de nœuds : arrêtez manuellement certains nœuds pour tester si le cluster peut récupérer rapidement ;
- Expérience de nœud lent : utilisez l'outil Chaosblade pour augmenter la charge CPU du nœud à 90 % afin de simuler une situation de nœud lent qui prend du temps ;
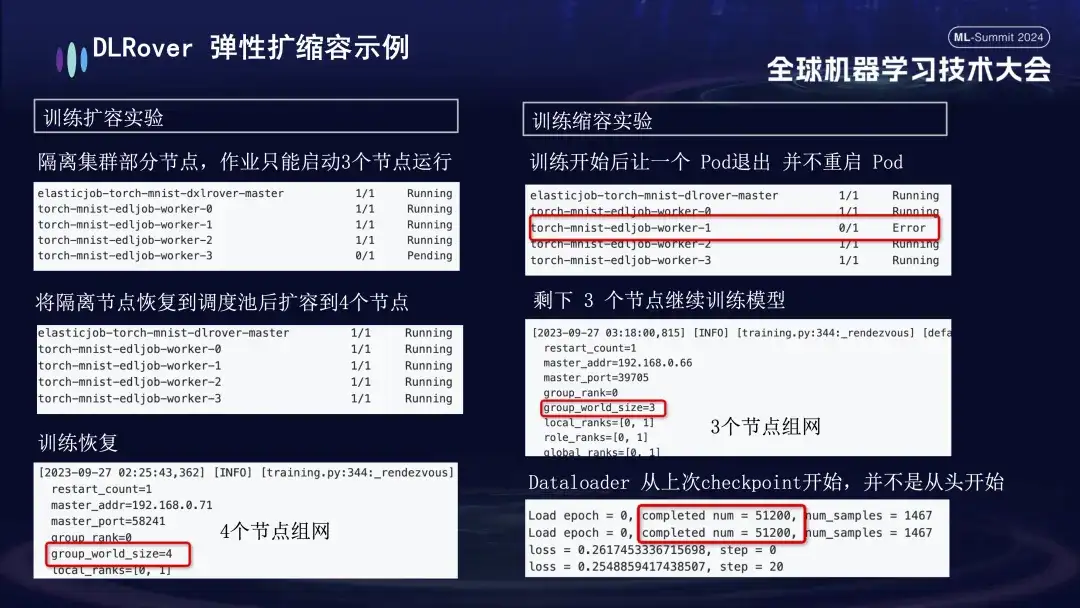
- Expérience d'expansion et de contraction : simule un scénario dans lequel les ressources de la machine sont limitées. Par exemple, si une tâche est configurée avec 4 nœuds, mais que seulement 3 sont réellement démarrés, ces 3 nœuds peuvent toujours être entraînés normalement. Après un certain temps, nous avons simulé l'isolement d'un nœud et le nombre de pods disponibles pour l'entraînement a été réduit à 3. Lorsque cette machine revient dans la file d'attente de planification, le nombre de pods disponibles peut être augmenté jusqu'à 4. À ce moment, le Dataloader poursuivra l'entraînement à partir du dernier point de contrôle au lieu de recommencer.
La pratique de DLRover dans les cartes nationales
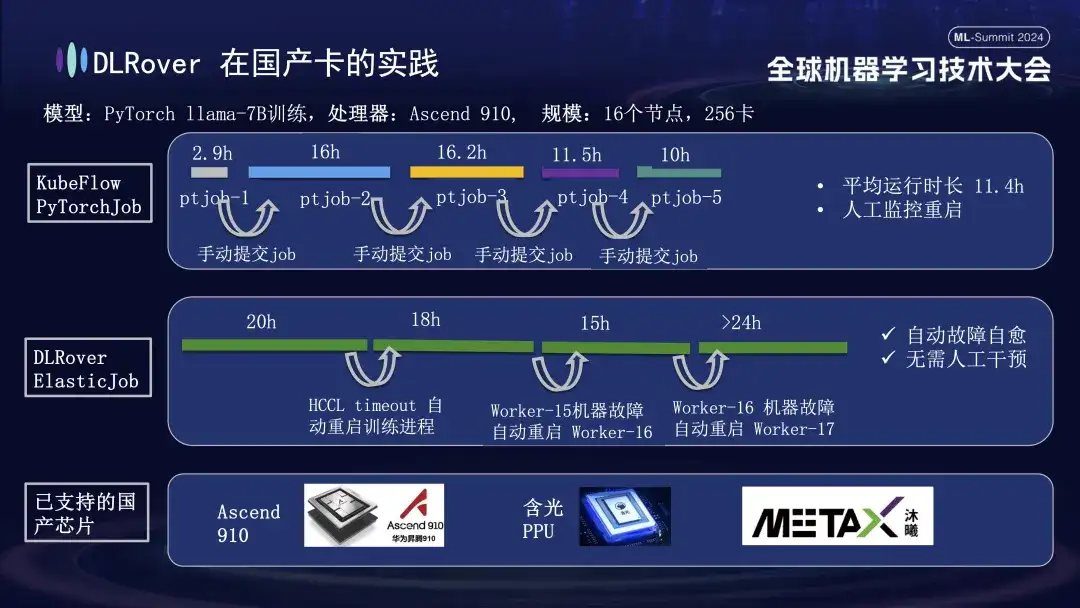
En plus de prendre en charge les GPU, l'auto-réparation des pannes DLRover prend également en charge la formation distribuée des cartes accélératrices nationales. Par exemple, lorsque nous avons exécuté le modèle LLama-7B sur la plate-forme Huawei Ascend 910, nous avons utilisé 256 cartes pour une formation à grande échelle. Au début, nous avons utilisé PyTorchJob de KubeFlow, mais cet outil n'avait pas de tolérance aux pannes, ce qui entraînait la fin automatique du processus de formation après une dizaine d'heures. Une fois cela produit, l'utilisateur devait soumettre à nouveau manuellement la tâche ; inactif. Le deuxième diagramme représente l'ensemble du processus de formation avec l'auto-réparation des erreurs de formation activée. Lorsque la formation a progressé pendant 20 heures, une défaillance du délai de communication s'est produite. À ce moment-là, le système a automatiquement redémarré le processus de formation et repris la formation. Environ quarante heures plus tard, une panne matérielle de la machine a été rencontrée. Le système a rapidement isolé la machine défectueuse et redémarré un pod pour poursuivre l'entraînement. En plus de prendre en charge Huawei Ascend 910, nous sommes également compatibles avec le PPU Hanguang d'Alibaba et coopérons avec Muxi Technology pour utiliser DLRover afin de former le modèle LLAMA2-65B sur son GPU Qianka développé indépendamment.
DLRover 1 000 cartes, 100 milliards de modèles de formation
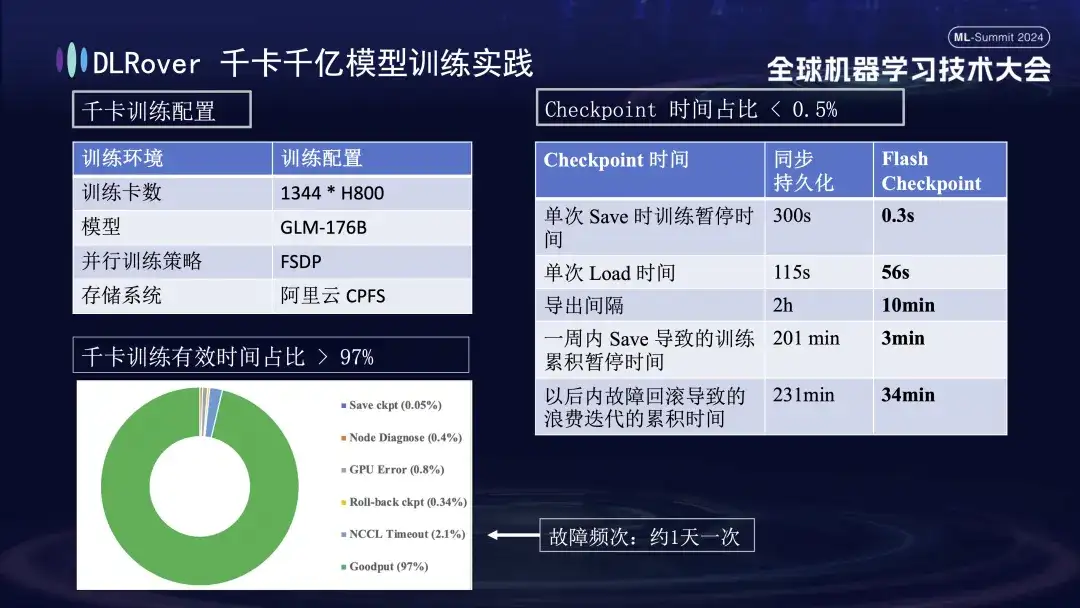
La figure ci-dessus montre l'effet pratique de l'auto-réparation des défauts de formation DLRover sur la formation kilo-carte : plus de 1 000 cartes H800 sont utilisées pour exécuter une formation de modèle à grande échelle lorsque la fréquence des défauts est d'une fois par jour, après l'auto-réparation des défauts de formation. la fonction de guérison est introduite, le temps de formation effectif représentant plus de 97 %. Le tableau de comparaison à droite montre que lors de l'utilisation du stockage FSDP hautes performances d'Alibaba Cloud, une seule sauvegarde prend encore environ cinq minutes, tandis que notre technologie Flash Checkpoint ne prend que 0,3 seconde. De plus, grâce à l'optimisation, l'efficacité des nœuds a été améliorée de près d'une minute. En termes d'intervalle d'exportation, l'opération d'exportation était initialement effectuée toutes les 2 heures, mais après le lancement de la fonction Flash Checkpoint, l'exportation à haute fréquence peut être réalisée toutes les 10 minutes. Le temps cumulé consacré aux opérations de sauvegarde au cours d’une semaine est presque négligeable. Dans le même temps, le temps de restauration est réduit d'environ 5 fois par rapport à avant.
Plan DLRover et renforcement de la communauté

DLRover a actuellement publié trois versions majeures. Il devrait publier la V0.4.0 en juin, qui publiera la détection des défauts d'exécution basée sur l'événement CUDA.
- V0.1.0 (2023/07) : tolérance aux pannes élastique et expansion et contraction automatiques de TensorFlow PS sur k8s/ray ;
- V0.2.0 (2023/09) : Détection de nœuds et tolérance élastique aux pannes pour l'entraînement synchrone PyTorch sur k8 ;
- V0.3.5 (2024/03) : Point de contrôle flash et détection des défauts de la carte nationale ;
En termes de planification future, DLRover continuera d'optimiser et d'améliorer les fonctions de DLRover dans les aspects de planification et de gestion des nœuds, de compilation et d'optimisation de lynx, de cadre d'optimisation de la formation AToch et de formation des cartes nationales :
- ** Planification et gestion des nœuds : ** Planification tenant compte de la topologie de communication, réduisant le trafic de communication des commutateurs de niveau supérieur pendant la communication AllReduce basée sur l'anneau ; collecte de métriques matérielles et prédiction des pannes ;
- **Optimisation de la compilation lynx : **Optimisation de la planification des graphiques de calcul, obtenant un chevauchement optimal de la communication et des calculs, masquant le retard de communication ; formation distribuée automatique SPMD ;
- **Cadre d'optimisation de la formation ATorch : **Optimisation de la formation RLHF ; accélération de l'initialisation de la formation distribuée ; configuration automatique de l'accélération de la formation auto_accelerate ;
- **Formation sur les cartes nationales : **Élargir les fonctions telles que l'auto-réparation des défauts et l'accélération de la formation aux cartes nationales ; fournir les meilleures pratiques pour la formation des cartes nationales ;

Le progrès technologique commence par une collaboration ouverte. Tout le monde est invité à suivre et à participer à nos projets open source sur GitHub.
DLRover:
https://github.com/intelligent-machine-learning/dlrover
GLACE :
https://github.com/intelligent-machine-learning/glake
Notre compte public WeChat « AI Infra » publiera également régulièrement des articles techniques de pointe sur l'infrastructure de l'IA, dans le but de partager les derniers résultats de recherche et informations techniques. Dans le même temps, afin de promouvoir de nouveaux échanges et discussions, nous avons également créé un groupe DingTalk. Tout le monde est invité à nous rejoindre, à poser des questions et à discuter de problèmes techniques connexes. Merci à tous!
Recommandations d'articles
