
Auteurs : Xingji, Changjun, Youyi, Liutao
Introduction au concept de mémoire de travail de conteneur WorkingSet
Dans le scénario Kubernetes, les statistiques d'utilisation en temps réel de la mémoire du conteneur (Pod Memory) sont représentées par la mémoire de travail WorkingSet (en abrégé WSS).
Le concept d'indicateur de WorkingSet est défini par Cadvisor pour les scénarios de conteneurs.
Mémoire de travail WorkingSet est également un indicateur des décisions de planification de Kubernetes pour déterminer les ressources de mémoire, y compris l'expulsion de nœuds.
Formule de calcul WorkingSet
Définition officielle : reportez-vous à la documentation du site officiel de K8s
https://kubernetes.io/docs/concepts/scheduling-eviction/node-pression-eviction/#eviction-signals
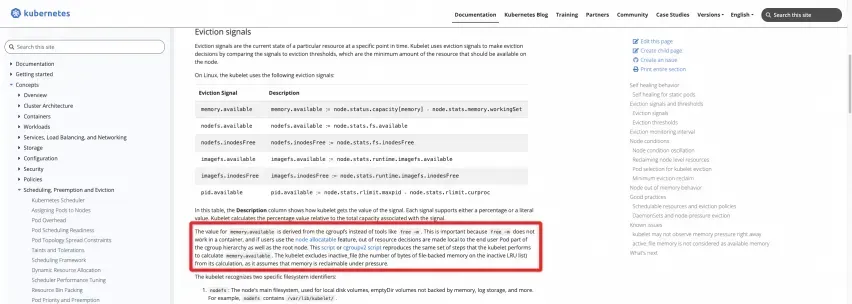
Les deux scripts suivants peuvent être exécutés sur le nœud pour calculer directement les résultats :
GroupeCV1
https://kubernetes.io/examples/admin/resource/memory-available.sh
#!/bin/bash
#!/usr/bin/env bash
# This script reproduces what the kubelet does
# to calculate memory.available relative to root cgroup.
# current memory usage
memory_capacity_in_kb=$(cat /proc/meminfo | grep MemTotal | awk '{print $2}')
memory_capacity_in_bytes=$((memory_capacity_in_kb * 1024))
memory_usage_in_bytes=$(cat /sys/fs/cgroup/memory/memory.usage_in_bytes)
memory_total_inactive_file=$(cat /sys/fs/cgroup/memory/memory.stat | grep total_inactive_file | awk '{print $2}')
memory_working_set=${memory_usage_in_bytes}
if [ "$memory_working_set" -lt "$memory_total_inactive_file" ];
then
memory_working_set=0
else
memory_working_set=$((memory_usage_in_bytes - memory_total_inactive_file))
fi
memory_available_in_bytes=$((memory_capacity_in_bytes - memory_working_set))
memory_available_in_kb=$((memory_available_in_bytes / 1024))
memory_available_in_mb=$((memory_available_in_kb / 1024))
echo "memory.capacity_in_bytes $memory_capacity_in_bytes"
echo "memory.usage_in_bytes $memory_usage_in_bytes"
echo "memory.total_inactive_file $memory_total_inactive_file"
echo "memory.working_set $memory_working_set"
echo "memory.available_in_bytes $memory_available_in_bytes"
echo "memory.available_in_kb $memory_available_in_kb"
echo "memory.available_in_mb $memory_available_in_mb"
GroupeCV2
https://kubernetes.io/examples/admin/resource/memory-available-cgroupv2.sh
#!/bin/bash
# This script reproduces what the kubelet does
# to calculate memory.available relative to kubepods cgroup.
# current memory usage
memory_capacity_in_kb=$(cat /proc/meminfo | grep MemTotal | awk '{print $2}')
memory_capacity_in_bytes=$((memory_capacity_in_kb * 1024))
memory_usage_in_bytes=$(cat /sys/fs/cgroup/kubepods.slice/memory.current)
memory_total_inactive_file=$(cat /sys/fs/cgroup/kubepods.slice/memory.stat | grep inactive_file | awk '{print $2}')
memory_working_set=${memory_usage_in_bytes}
if [ "$memory_working_set" -lt "$memory_total_inactive_file" ];
then
memory_working_set=0
else
memory_working_set=$((memory_usage_in_bytes - memory_total_inactive_file))
fi
memory_available_in_bytes=$((memory_capacity_in_bytes - memory_working_set))
memory_available_in_kb=$((memory_available_in_bytes / 1024))
memory_available_in_mb=$((memory_available_in_kb / 1024))
echo "memory.capacity_in_bytes $memory_capacity_in_bytes"
echo "memory.usage_in_bytes $memory_usage_in_bytes"
echo "memory.total_inactive_file $memory_total_inactive_file"
echo "memory.working_set $memory_working_set"
echo "memory.available_in_bytes $memory_available_in_bytes"
echo "memory.available_in_kb $memory_available_in_kb"
echo "memory.available_in_mb $memory_available_in_mb"
Montre-moi le code
Comme vous pouvez le voir, la mémoire de travail du WorkingSet du nœud correspond à l'utilisation de la mémoire du groupe de contrôle racine, moins le cache de la partie Inactve(file). De même, la mémoire de travail WorkingSet du conteneur dans le Pod correspond à l'utilisation de la mémoire du groupe de contrôle correspondant au conteneur, moins le cache de la partie Inactve(file).
Dans le kubelet du véritable runtime Kubernetes, le code réel de cette partie de la logique de l'indicateur fourni par cadvisor est le suivant :
À partir du code cadvisor [ 1] , vous pouvez voir clairement la définition de la mémoire de travail WorkingSet :
The amount of working set memory, this includes recently accessed memory,dirty memory, and kernel memory. Working set is <= "usage".
Et l'implémentation de code spécifique du calcul de WorkingSet par Cadvisor [ 2] :
inactiveFileKeyName := "total_inactive_file"
if cgroups.IsCgroup2UnifiedMode() {
inactiveFileKeyName = "inactive_file"
}
workingSet := ret.Memory.Usage
if v, ok := s.MemoryStats.Stats[inactiveFileKeyName]; ok {
if workingSet < v {
workingSet = 0
} else {
workingSet -= v
}
}
Cas de problèmes utilisateur courants liés aux problèmes de mémoire de conteneur
Dans le cadre du processus par lequel l'équipe ACK fournit un service de support pour les scénarios de conteneurs à un grand nombre d'utilisateurs, de nombreux clients ont plus ou moins rencontré des problèmes de mémoire de conteneur lors du déploiement de leurs applications métier dans des conteneurs. Après avoir rencontré un grand nombre de problèmes clients, l'équipe ACK et l'équipe du système d'exploitation Alibaba Cloud ont résumé les problèmes courants suivants rencontrés par les utilisateurs en termes de mémoire de conteneur :
FAQ 1 : Il existe un écart entre l'utilisation de la mémoire de l'hôte et l'utilisation agrégée du conteneur par nœud. L'hôte est d'environ 40 % et le conteneur est d'environ 90 %.
Très probablement, c'est parce que le pod du conteneur est considéré comme un WorkingSet, qui contient des caches tels que PageCache.
La valeur de la mémoire de l'hôte n'inclut pas le cache, le PageCache, la mémoire sale, etc., alors que la mémoire de travail inclut cette partie.
Les scénarios les plus courants sont la conteneurisation des applications JAVA, Log4J des applications JAVA et son implémentation très populaire Logback. L'Appender par défaut commencera à utiliser NIO très "simplement" et utilisera mmap pour utiliser Dirty Memory. Cela entraîne une augmentation de la mémoire cache, entraînant ainsi une augmentation de la mémoire de travail WorkingSet du pod.
Scénario de journalisation Logback d'un pod d'application JAVA
Instances provoquant une augmentation de la mémoire cache et de la mémoire WorkingSet
FAQ 2 : Lors de l'exécution de la commande top dans un Pod, la valeur obtenue est inférieure à la valeur de la mémoire de travail (WorkingSet) visualisée par le pod kubectl top.
Exécutez la commande top dans le pod En raison de problèmes tels que l'isolation de l'exécution du conteneur, l'isolation du conteneur est en fait rompue et la valeur de surveillance supérieure de l'hôte est obtenue.
Par conséquent, ce que vous voyez est la valeur de la mémoire de la machine hôte, qui n'inclut pas le cache, le PageCache, la mémoire sale, etc., tandis que la mémoire de travail inclut cette partie, elle est donc similaire à la FAQ 1.
FAQ 3 : Problème de trou noir dans la mémoire du pod
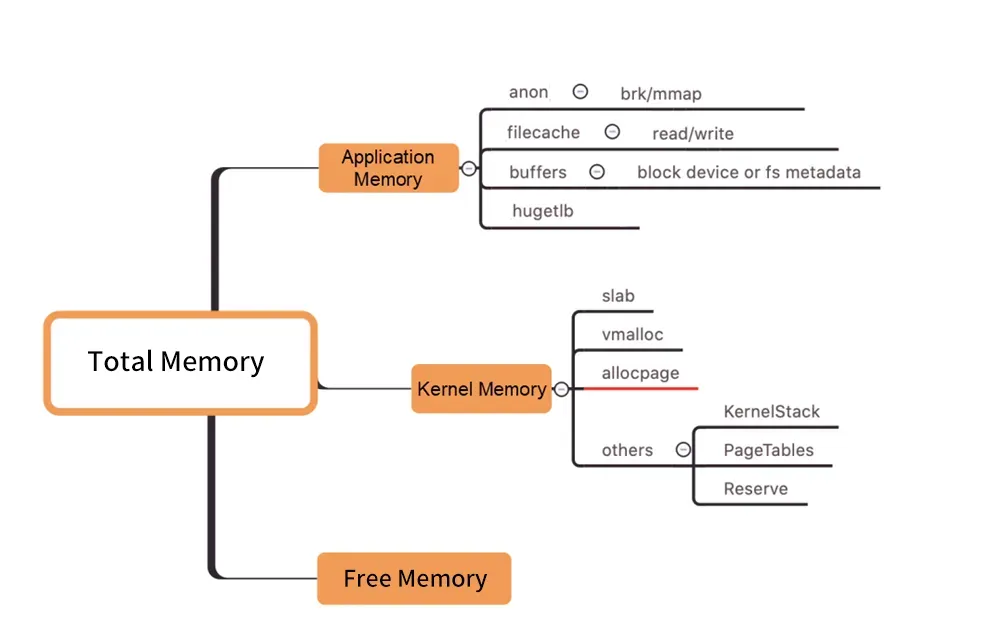
图/Distribution de la mémoire au niveau du noyau
Comme le montre la figure ci-dessus, la mémoire de travail du Pod WorkingSet n'inclut pas Inactive (anno) et les autres composants de la mémoire du Pod utilisés par les utilisateurs ne répondent pas aux attentes, ce qui peut éventuellement entraîner une augmentation de la charge de travail du WorkingSet, conduisant finalement à Node. Expulsion.
Comment trouver la véritable cause de l’augmentation de la mémoire de travail parmi les nombreux composants de la mémoire est aussi aveugle qu’un trou noir. ("Trou noir de la mémoire" fait référence à ce problème).
Comment résoudre le problème élevé de WorkingSet
Habituellement, les retards de recyclage de la mémoire s'accompagnent d'une utilisation élevée de la mémoire de travail. Alors, comment résoudre ce type de problème ?
Expansion directe
La planification de la capacité (expansion directe) est une solution générale au problème des ressources élevées.
"Trou noir de la mémoire" - que faire s'il est causé par des coûts de mémoire importants (tels que PageCache)
Cependant, si vous souhaitez diagnostiquer des problèmes de mémoire, vous devez d'abord disséquer, mieux comprendre, analyser ou, en termes humains, voir clairement quelle partie de la mémoire est détenue par qui (quel processus ou quelle ressource spécifique telle qu'un fichier). Effectuez ensuite une optimisation de convergence ciblée pour enfin résoudre le problème.
Première étape : vérifier la mémoire
Tout d'abord, comment analyser les indicateurs de mémoire de surveillance des conteneurs au niveau du noyau du système d'exploitation ? L'équipe ACK a coopéré avec l'équipe du système d'exploitation pour lancer la fonction du produit SysOM (System Observer Monitoring) de surveillance des conteneurs au niveau de la couche noyau du système d'exploitation, qui est actuellement unique à Alibaba Cloud en affichant le moniteur de mémoire du pod dans le conteneur SysOM . Dimension Surveillance du système-Pod , vous pouvez avoir un aperçu de la répartition détaillée de l'utilisation de la mémoire du Pod, comme indiqué ci-dessous :
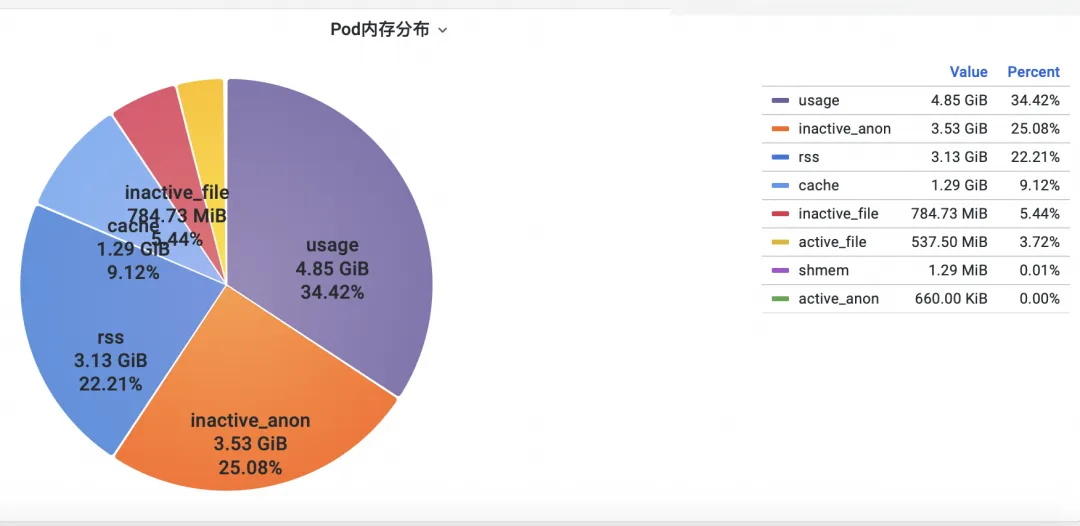
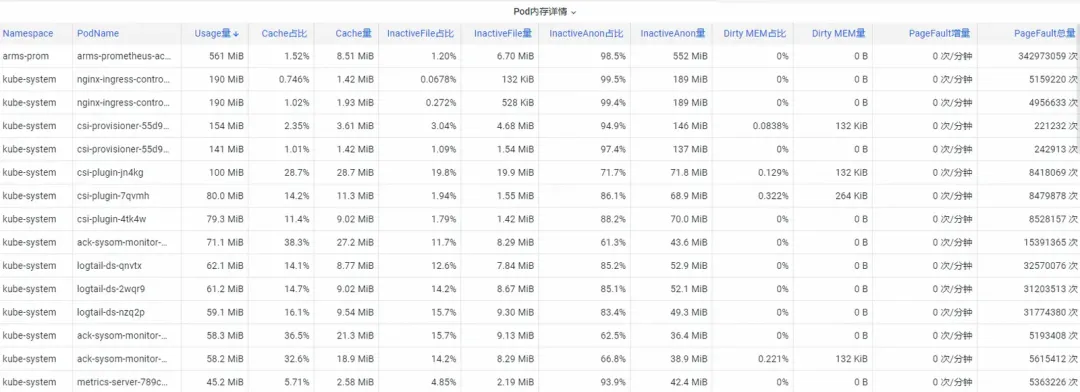
La surveillance du système de conteneur SysOM peut afficher la composition détaillée de la mémoire de chaque pod à un niveau granulaire. Grâce à la surveillance et à l'affichage de différents composants de mémoire tels que Pod Cache (mémoire cache), InactiveFile (utilisation inactive de la mémoire des fichiers), InactiveAnon (utilisation de la mémoire anonyme inactive), Dirty Memory (utilisation de la mémoire sale du système), les problèmes courants de trou noir de mémoire Pod sont découvert.
Pour Pod File Cache, vous pouvez surveiller simultanément l'utilisation de PageCache des fichiers actuellement ouverts et fermés du Pod (la suppression des fichiers correspondants peut libérer la mémoire Cache correspondante).
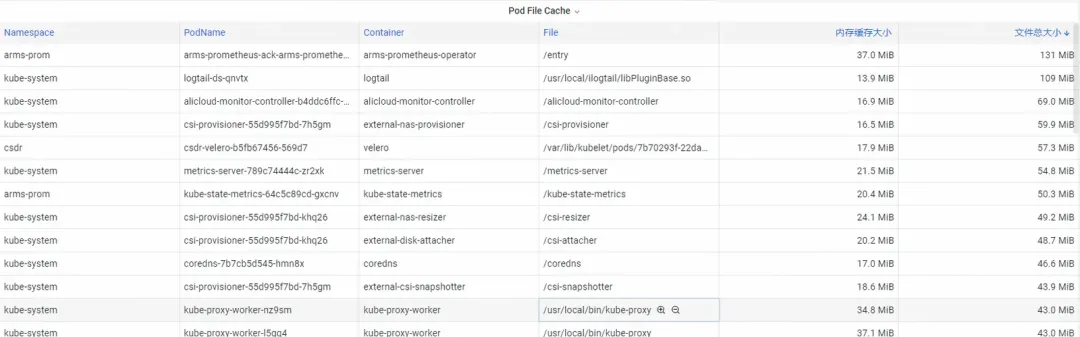
Étape 2 : Optimiser la mémoire
Il existe de nombreuses consommations de mémoire profondes que les utilisateurs ne peuvent pas facilement converger même s'ils les voient clairement. Par exemple, PageCache et autre mémoire uniformément récupérée par le système d'exploitation obligent les utilisateurs à apporter des modifications intrusives au code, telles que l'ajout de flush(. ) à l'Appender de Log4J pour appeler périodiquement sync().
https://stackoverflow.com/questions/11829922/logback-file-appender-doesnt-flush-immediately
C'est très irréaliste.
L'équipe du service de conteneurs ACK a lancé la fonction de planification fine Koordinator QoS .
Implémenté sur Kubernetes pour contrôler les paramètres de mémoire du système d'exploitation :
Lorsque la colocalisation SLO différenciée est activée dans le cluster, le système donnera la priorité à la qualité de service de la mémoire des pods LS (Latency-Sensitive) sensibles à la latence et retardera le timing des pods LS déclenchant le recyclage de la mémoire sur l'ensemble de la machine.
Dans la figure ci-dessous, memory.limit_in_bytes représente la limite supérieure d'utilisation de la mémoire, memory.high représente le seuil limite actuel de la mémoire, memory.wmark_high représente le seuil de recyclage en arrière-plan de la mémoire et memory.min représente le seuil de verrouillage de l'utilisation de la mémoire.
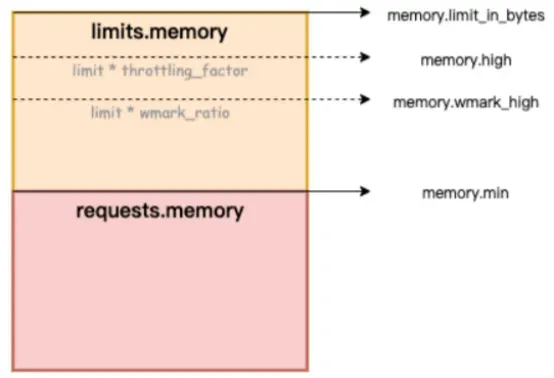
Figure/ack-koordinator fournit des capacités de garantie de qualité de service (QoS) de mémoire pour les conteneurs
Comment résoudre le problème du trou noir de la mémoire ? Alibaba Cloud Container Service utilise la fonction de planification raffinée et s'appuie sur le projet open source Koordinator, qui fournit des capacités de garantie de qualité de service QoS (Qualité de service) pour les conteneurs, améliorant ainsi l'équité de la mémoire. ressources en partant du principe d'assurer l'équité des ressources mémoire. Les performances de la mémoire de l'application au moment de l'exécution. Cet article présente la fonction QoS de la mémoire du conteneur. Pour des instructions détaillées, veuillez vous référer à QoS de la mémoire du conteneur [ 3] .
Les conteneurs ont principalement les deux contraintes suivantes lors de l'utilisation de la mémoire :
1) Limite de mémoire propre : lorsque la mémoire propre du conteneur (y compris PageCache) approche de la limite supérieure du conteneur, le recyclage de la mémoire dimensionnelle du conteneur sera déclenché. Ce processus affectera l'application de mémoire et libérera les performances des applications dans le conteneur. Si la demande de mémoire ne peut pas être satisfaite, le MOO du conteneur sera déclenché.
2) Limite de mémoire du nœud : lorsque la mémoire du conteneur est survendue (Limite de mémoire> Demande) et que la machine entière n'a pas suffisamment de mémoire, cela déclenchera le recyclage global de la mémoire dans la dimension du nœud. Ce processus a un grand impact sur les performances, et dans des cas extrêmes. , rend même toute la machine anormale. Si le recyclage est insuffisant, le conteneur sera sélectionné pour OOM Kill.
Pour résoudre les problèmes typiques de mémoire de conteneur ci-dessus, ack-koordinator fournit les fonctionnalités améliorées suivantes :
1) Niveau d'eau de recyclage en arrière-plan de la mémoire du conteneur : lorsque l'utilisation de la mémoire du pod est proche de la limite limite, une partie de la mémoire est recyclée de manière asynchrone en arrière-plan pour atténuer l'impact sur les performances causé par le recyclage direct de la mémoire.
2) Recyclage du verrouillage de la mémoire du conteneur/limitation du niveau d'eau : mettre en œuvre un recyclage de mémoire plus équitable entre les pods. Lorsque les ressources mémoire de l'ensemble de la machine sont insuffisantes, la priorité sera donnée au recyclage de la mémoire des pods présentant une surutilisation de la mémoire (Utilisation de la mémoire > Demande) pour éviter des problèmes individuels. Pods provoquant une panne globale. La qualité des ressources mémoire de la machine s'est détériorée.
3) Garantie différenciée du recyclage global de la mémoire : dans le scénario de survente de mémoire BestEffort, la priorité est donnée à garantir la qualité de fonctionnement de la mémoire des pods garantis/extensibles.
Pour plus de détails sur les capacités du noyau activées par la qualité de service de la mémoire du conteneur ACK, consultez la présentation des fonctions du noyau et de l'interface d'Alibaba Cloud Linux [ 4] .
Une fois le problème du trou noir de la mémoire du conteneur découvert lors de la première étape d'observation, la fonction de planification fine ACK peut être combinée avec la sélection ciblée de pods sensibles à la mémoire pour permettre à la fonction QoS de la mémoire du conteneur d'effectuer la réparation en boucle fermée.
Documentation de référence :
[1] Document de description de la fonction ACK SysOM
[2] Documentation sur les meilleures pratiques
[3] Communauté chinoise de lézards-dragons
https://mp.weixin.qq.com/s/b5QNHmD_U0DcmUGwVm8Apw
[4] Station internationale anglais
https://www.alibabacloud.com/blog/sysom-container-monitoring-from-the-kernels-perspective_600792
Liens connexes:
[1] Code du conseiller
[2] Implémentation de code spécifique du calcul WorkingSet par Cadvisor
[3] QoS de la mémoire du conteneur
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/memory-qos-for-containers
[4] Présentation des fonctions du noyau et des interfaces d'Alibaba Cloud Linux
https://help.aliyun.com/zh/ecs/user-guide/overview-23
L'équipe chinoise d'IA de Microsoft a fait ses valises et s'est rendue aux États-Unis, impliquant des centaines de personnes. Combien de revenus un projet open source inconnu peut-il rapporter ? Huawei a officiellement annoncé que la position de la station miroir open source de l'Université des sciences et technologies de Yu Huazhong a été ajustée. L'accès au réseau externe a été officiellement ouvert. Les fraudeurs ont utilisé TeamViewer pour transférer 3,98 millions ! Que doivent faire les fournisseurs de postes de travail à distance ? La première bibliothèque de visualisation frontale et fondateur du célèbre projet open source de Baidu, ECharts - un ancien employé d'une société open source bien connue qui "est allée à la mer" a annoncé la nouvelle : après avoir été interpellé par ses subordonnés, le technicien Le leader est devenu furieux et grossier et a licencié l'employée enceinte. OpenAI a envisagé d'autoriser l'IA à générer du contenu pornographique. Microsoft a déclaré à la Fondation Rust qu'elle avait fait un don de 1 million de dollars américains. Veuillez me dire quel est le rôle de time.sleep(6) ici. ?