
Auteur : Mu Yan
Rencontrez-vous les problèmes suivants lors de la configuration du pipeline YAML ?
- Lorsque des scénarios de tâches similaires sont exécutés par lots dans un seul pipeline, plusieurs tâches avec une logique similaire doivent être définies dans YAML. Plus il y a de tâches, plus la configuration YAML du pipeline est longue, plus le code est répété dans YAML et plus le code est réutilisable. est faible et la lisibilité est mauvaise ;
- Les administrateurs gèrent plusieurs pipelines de manière unifiée. L'architecture technologique multi-application est similaire au processus de R&D. Lorsque seuls quelques paramètres de construction et de déploiement sont incohérents, chaque pipeline doit modifier les paramètres différenciés indépendamment, ce qui entraîne des coûts de configuration élevés. chaque pipeline est configuré indépendamment, une gestion et un contrôle unifiés ne peuvent pas être obtenus, une mauvaise maintenabilité ;
- Le pipeline YAML est un fichier statique et la logique d'exécution des tâches est corrigée lors de l'enregistrement du pipeline. Cependant, le processus d'exécution du pipeline de certains scénarios de R&D doit être clarifié au moment de l'exécution et ne peut pas être configuré à l'avance. Le pipeline ordinaire YAML ne peut pas satisfaire ce scénario.
À cet égard, le pipeline Yunxiao Flow YAML introduit une syntaxe de modèle, qui prend en charge l'utilisation de langages de modèles pour restituer dynamiquement le pipeline YAML, qui peut répondre aux scénarios de configuration par lots de plusieurs tâches avec une logique identique ou similaire, répondre à la génération dynamique. des scénarios de plusieurs tâches à la demande et aident à réduire la duplication du code YAML du pipeline, à orchestrer de manière flexible le multitâche.
Quelle est la syntaxe du modèle
Le modèle est un langage de modèle utilisé pour définir et restituer du texte. Il peut être combiné avec des variables, des instructions conditionnelles, des structures de boucles, etc., afin que les fichiers YAML puissent générer diverses sorties de configuration basées sur le contexte ou des sources de données externes. Le rendu dynamique génère un pipeline YAML. lors de l'exécution. .
Le Cloud Effect Pipeline présente le moteur de modèle et spécifie le mode modèle via la première ligne de commentaires YAML dans le pipeline. Il prend en charge l'utilisation du langage de modèle défini et suit la syntaxe native, il prend en charge l'utilisation de variables définies comme paramètres pour le template=truepipeline. pipeline de rendu. Les scénarios applicables typiques sont les suivants.{{ }}go templatevariables
Scénarios d'utilisation de base de la syntaxe du modèle
Scénario 1 : Scénario de test de compatibilité multi-systèmes d'exploitation et versions multi-SDK
Dans certains scénarios de tests de compatibilité, si vous devez tester votre code sur n systèmes d'exploitation différents et m versions de SDK différentes, vous devez alors définir n * m tâches dans votre pipeline. La logique d'exécution de chaque tâche est en fait la même. Dans ce scénario, lorsqu'il existe de nombreux scénarios nécessitant des tests de compatibilité, le pipeline YAML sera très long, avec beaucoup de code répété, ce qui le rendra difficile à maintenir et lorsque la logique d'exécution du Job sera modifiée, il faudra la modifier ; n * m fois.
Une fois la syntaxe du modèle introduite, les scénarios de compatibilité peuvent être extraits dans des variables et la syntaxe de plage peut être utilisée pour parcourir les scénarios et générer plusieurs tâches par lots, réduisant ainsi considérablement la quantité de code YAML lorsque la logique d'exécution de la tâche est modifiée. une seule modification est nécessaire.
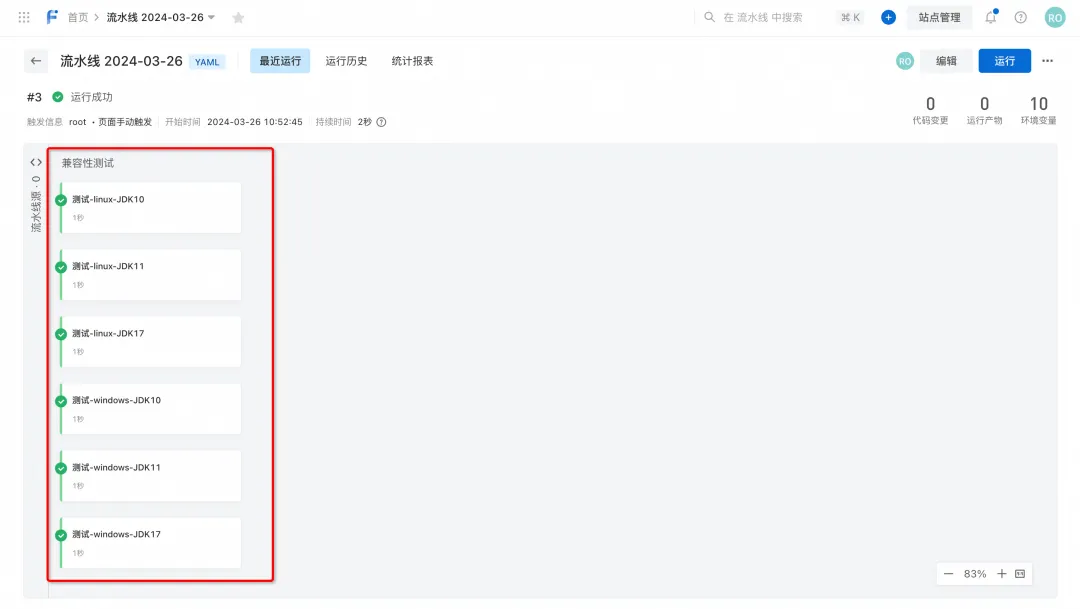
Par exemple, dans le code suivant, nous parcourons 2 systèmes d'exploitation ["linux", "windows"] et 3 versions du JDK ["10", "11", "17"], en utilisant la boucle range du template, c'est très Idéalement, 6 tâches avec la même logique sont générées.
# template=true
variables:
- key: osList
type: Object
value: ["linux", "windows"]
- key: jdkVersionList
type: Object
value: ["10", "11", "17"]
stages:
build_stage:
name: 兼容性测试
jobs: # 双层循环,生成 2*3 个Job
{{ range $os := .osList}}
{{ range $jdk := $.jdkVersionList}}
{{ $os }}_JDK{{ $jdk }}_job:
name: 测试-{{ $os }}-JDK{{ $jdk }}
my_step:
name: 执行命令
step: Command
with:
run: |
echo 'test on {{ $os }}-JDK{{ $jdk }}"
{{ end }}
{{ end }}
L'effet courant du pipeline est le suivant :
Scénario 2 : Créer et déployer dynamiquement plusieurs applications à la demande
Dans le scénario de publication conjointe de plusieurs applications sous un même système, une modification des exigences métier n'impliquera que certaines applications sous le système, et chaque version ne déclenchera que la construction et le déploiement de certaines applications. Dans ce cas, l'utilisation d'une configuration de fichier YAML statique ne peut pas répondre à la génération dynamique de scénarios de tâches de construction et de déploiement d'applications.
Une fois la syntaxe du modèle introduite, l'application peut être extraite dans des variables et la syntaxe de plage peut être utilisée pour parcourir la configuration. Selon l'entrée de la liste d'applications pendant l'exécution du pipeline, plusieurs tâches de construction et de déploiement d'applications peuvent être générées dynamiquement. demande.
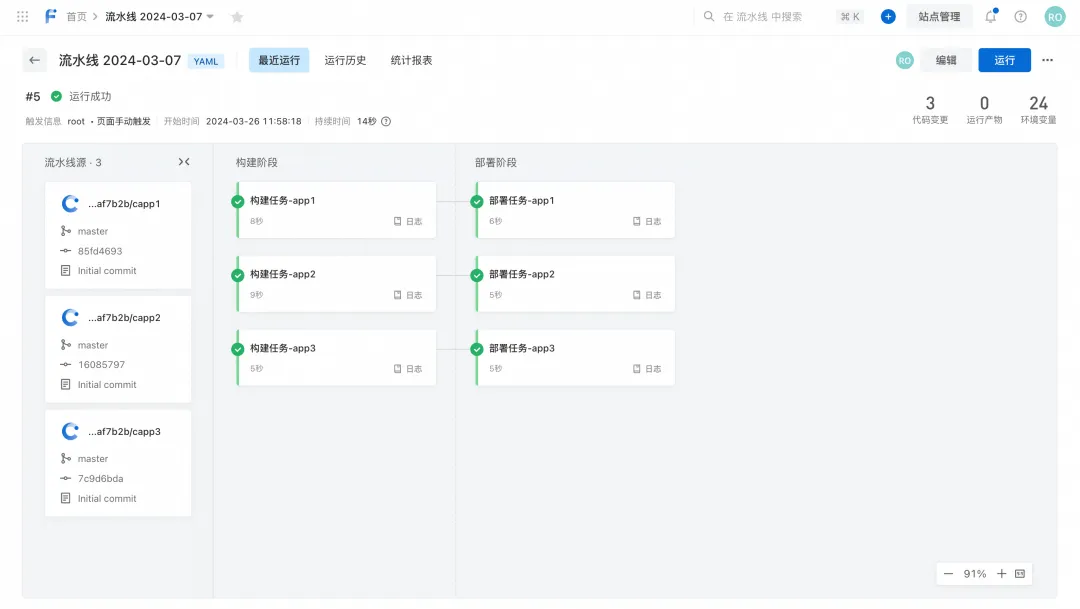
Comme le montre l'exemple suivant, nous avons configuré plusieurs sources de code d'application, plusieurs tâches de création d'applications et plusieurs tâches de déploiement d'applications en fonction de l'application. Plusieurs applications peuvent être déterminées dynamiquement pour être déployées en fonction des noms d'application de la variable d'environnement d'entrée d'exécution.
# template=true
variables:
- key: appnames
type: Object
value: ["app1", "app2", "app3"]
sources:
{{ range $app := .appnames }}
repo_{{ $app }}:
type: codeup
name: 代码源名称-{{ $app }}
endpoint: https://yunxiao-test.devops.aliyun.com/codeup/07880db8-fd8d-4769-81e5-04093aaf7b2b/c{{ $app }}.git
branch: master
certificate:
type: serviceConnection
serviceConnection: wwnbrqpihykbiko4
{{ end }}
defaultWorkspace: repo_app1
stages:
build_stage:
name: 构建阶段
jobs:
{{ range $app := .appnames }}
build_job_{{ $app }}:
name: 构建任务-{{ $app }}
sourceOption: ['repo_{{ $app }}']
steps:
build_{{ $app }}:
step: Command
name: 构建-{{ $app }}
with:
run: "echo start build {{ $app }}\n"
{{ end }}
deploy_stage:
name: 部署阶段
jobs:
{{ range $app := .appnames }}
deploy_job_{{ $app }}:
name: 部署任务-{{ $app }}
needs: build_stage.build_job_{{ $app }}
steps:
build_{{ $app }}:
step: Command
name: 部署-{{ $app }}
with:
run: "echo start deploy {{ $app }}\n"
{{ end }}
L'effet courant du pipeline est le suivant :
Comment utiliser la syntaxe des modèles dans Yunxiao
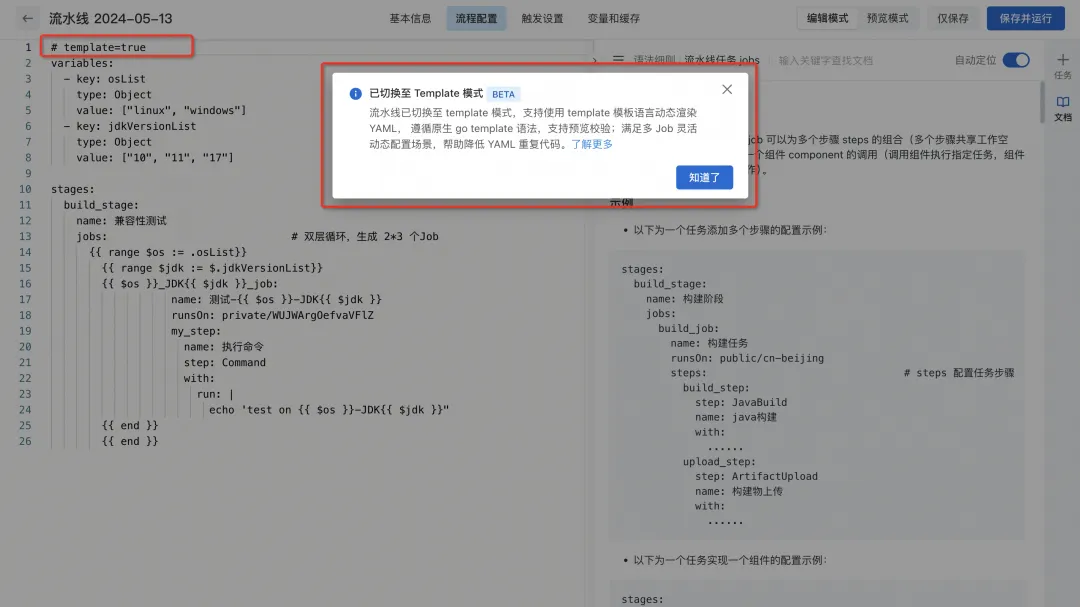
1) Accédez à la page d'édition YAML du pipeline et passez en mode modèle en commentant #template=true sur la première ligne.
2) Après être passé en mode modèle, le pipeline de définition de langage de modèle {{ }} est pris en charge.
-
Utiliser les variables d'environnement définies par des variables comme paramètres de rendu : utilisez les variables d'environnement définies par des variables comme paramètres de rendu de modèle, prenant en charge plusieurs types de variables d'environnement String, Number, Boolean et Object. Prend en charge l'écrasement des variables d'environnement portant le même nom au moment de l'exécution.
-
Suivez la syntaxe du modèle go natif : le mode modèle de pipeline Yunxiao Flow suit la syntaxe du modèle go natif. Pour plus de détails, voir : https://pkg.go.dev/text/template. La syntaxe couramment utilisée est la suivante :
{{/* a comment */}} // 注释
{{pipeline}} // 引用
{{if pipeline}} T1 {{end}} // 条件判断
{{if pipeline}} T1 {{else}} T0 {{end}}
{{if pipeline}} T1 {{else if pipeline}} T0 {{end}}
{{range pipeline}} T1 {{end}} // 循环
{{range pipeline}} T1 {{else}} T0 {{end}}
{{break}}
{{continue}}
- De plus, la syntaxe du modèle de pipeline Yunxiao Flow prend en charge les fonctions d'extension suivantes pour répondre à des scénarios d'orchestration plus flexibles.
# add:整数相加函数,参数接收两个及两个以上 Integer
{{ add 1 2 }} // 示例返回:3
{{ add 1 2 2 }} // 示例返回:5
# addf:浮点数相加函数,参数接收两个及两个以上 Number
{{ add 1.2 2.3 }} // 示例返回:3.5
{{ add 1.2 2.3 5 }} // 示例返回:8.5
# replace:字符串替换函数,接收三个参数:源字符串、待替换字符串、替换为字符串
{{ "Hallo World" | replace "a" "e" }} // 示例返回:Hello World
{{ "I Am Henry VIII" | replace " " "-" }} // 示例返回:I-Am-Henry-VIII
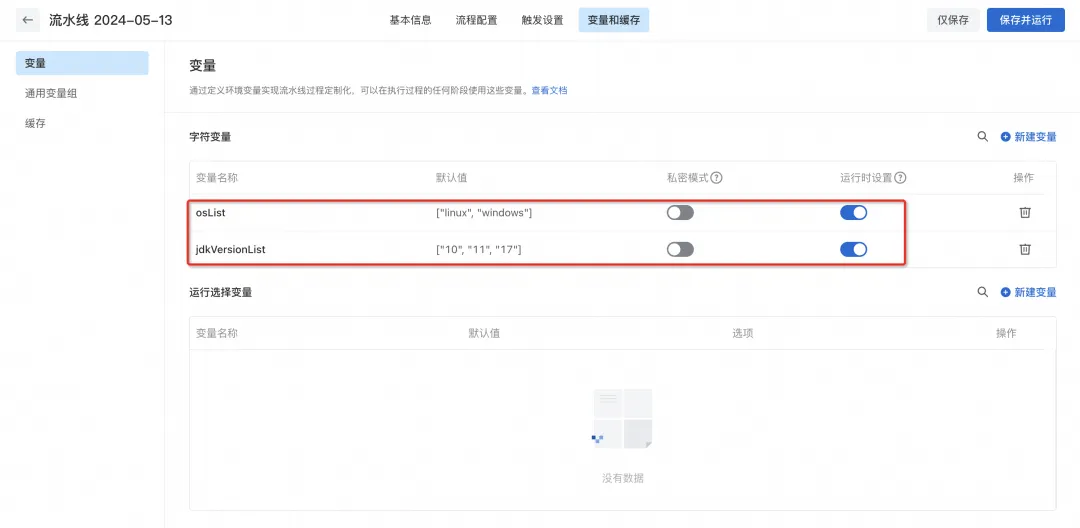
3) Configurez les variables d'environnement lorsque le pipeline est en cours d'exécution, qui sont utilisées pour restituer dynamiquement YAML avant l'exécution du pipeline.
4) Cliquez sur « Mode Aperçu » pour prendre en charge l'utilisation de variables pour le pré-rendu afin de vérifier si le pipeline répond aux attentes.
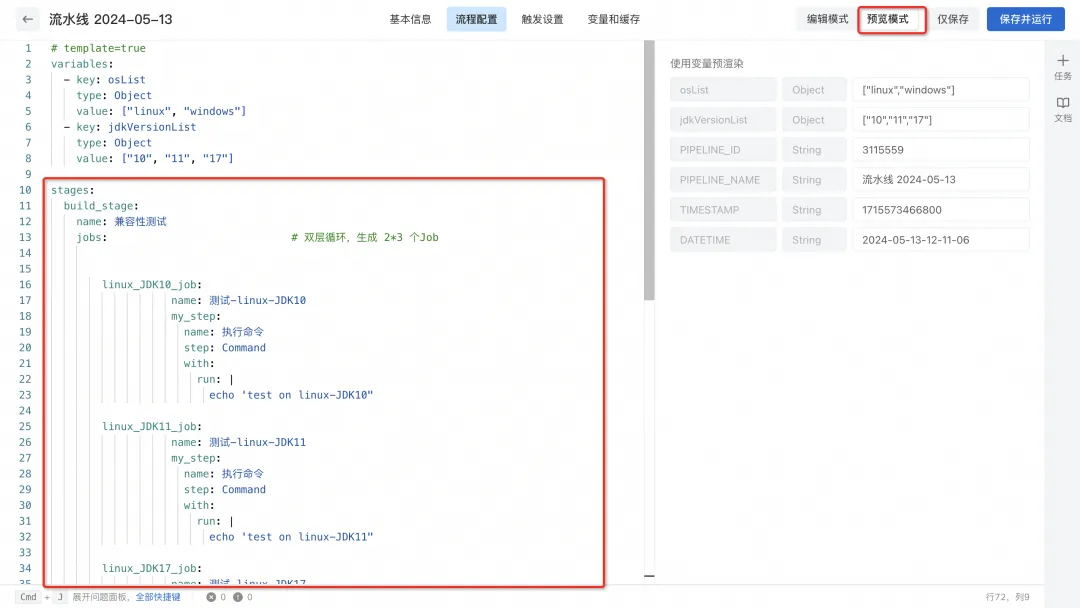
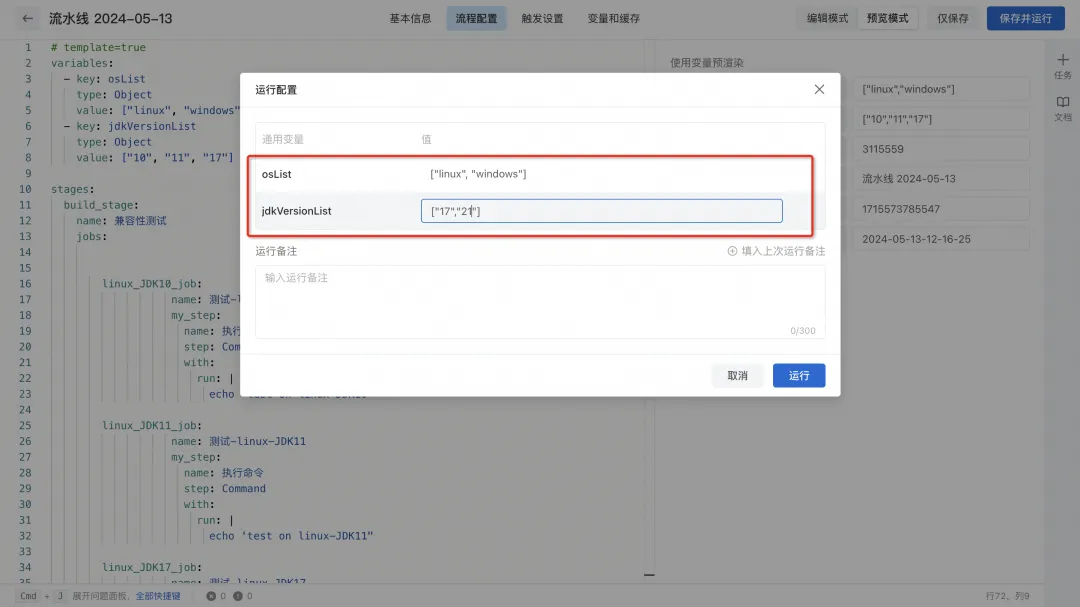
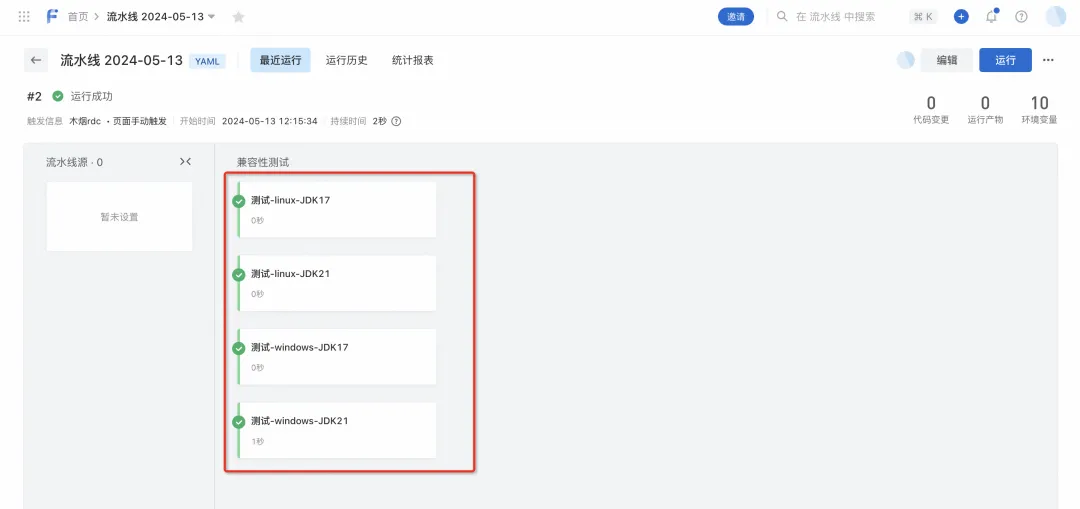
5) Après avoir confirmé qu'il est correct, enregistrez et déclenchez l'exécution du pipeline. Vous pouvez modifier les variables d'exécution selon vos besoins, restituer dynamiquement le pipeline YAML en fonction des variables d'environnement d'exécution et générer dynamiquement des tâches. Si la version du JDK est modifiée en ["17", "21"] et que le système d'exploitation reste ["linux", "windows"], 4 jobs seront générés dynamiquement.
Cliquez ici pour utiliser Cloud Effect Pipeline Flow gratuitement ou pour en savoir plus.
L'équipe chinoise d'IA de Microsoft a fait ses valises et s'est rendue aux États-Unis, impliquant des centaines de personnes. Combien de revenus un projet open source inconnu peut-il rapporter ? Huawei a officiellement annoncé que la position de la station miroir open source de l'Université des sciences et technologies de Yu Huazhong a été ajustée. L'accès au réseau externe a été officiellement ouvert. Les fraudeurs ont utilisé TeamViewer pour transférer 3,98 millions ! Que doivent faire les fournisseurs de postes de travail à distance ? La première bibliothèque de visualisation frontale et fondateur du célèbre projet open source de Baidu, ECharts - un ancien employé d'une société open source bien connue qui "est allée à la mer" a annoncé la nouvelle : après avoir été interpellé par ses subordonnés, le technicien Le leader est devenu furieux et grossier et a licencié l'employée enceinte. OpenAI a envisagé d'autoriser l'IA à générer du contenu pornographique. Microsoft a déclaré à la Fondation Rust qu'elle avait fait un don de 1 million de dollars américains. Veuillez me dire quel est le rôle de time.sleep(6) ici. ?