
Auteur : Huan Xiang
Manbang Group, en tant qu'entreprise de plateforme « Internet + Logistique », répond aux besoins d'expédition des expéditeurs d'un côté et se connecte aux chauffeurs de camion de l'autre côté pour améliorer l'efficacité de la logistique du fret. Elle sera cotée à la bourse américaine en 2021, devenant ainsi la première plateforme numérique de fret à être cotée. Selon le rapport annuel de l'entreprise, en 2021, plus de 3,5 millions de chauffeurs de camion ont exécuté plus de 128,3 millions de commandes sur la plateforme, atteignant une valeur totale de transaction de 262,3 milliards de yuans GTV, représentant plus de 60 % de la part de la plateforme de fret numérique de la Chine. En octobre 2022, la MAU de la version pilote de Yunmanman a atteint 9,4921 millions, et la MAU de la version pilote de Wagonmanman était de 3,9991 millions ; la MAU de la version propriétaire de Yunmanman était de 2,1868 millions et la MAU de la version propriétaire cargo de Wagonbang. était de 637 800. (Le contenu suivant est compilé et publié par Zikui et Congyan)
La croissance des entreprises remet en question la stabilité des services
Le groupe Manbang a construit sa propre passerelle de microservices dans l'environnement de production commerciale, qui est responsable de la planification du trafic nord-sud, de la protection de la sécurité et de la gouvernance des microservices. En même temps, en tenant compte de la capacité multiactive de reprise après sinistre, il fournit également des services tels. comme les appels prioritaires dans la même salle informatique, les appels inter-salles informatiques de reprise après sinistre, etc. En tant que composant frontal de l'architecture des microservices, la passerelle des microservices sert d'entrée de trafic pour tous les microservices. Lorsqu'une demande client arrive, elle atteint d'abord l'ALB (équilibrage de charge), puis est dirigée vers la passerelle interne, puis est acheminée vers le module de service métier spécifique via la passerelle.
Par conséquent, la passerelle doit utiliser un centre d'enregistrement de services pour découvrir dynamiquement toutes les instances de microservices déployées dans l'environnement de production actuel. Lorsque certaines instances de service ne sont pas en mesure de fournir des services en raison de pannes, la passerelle peut également travailler avec le centre d'enregistrement de services pour transférer automatiquement. demandes vers des instances saines. Sur les instances de service, le basculement et l'élasticité sont obtenus, et un cadre auto-développé est utilisé pour coopérer avec le centre d'enregistrement des services afin de réaliser des appels interservices. En même temps, un centre de configuration auto-construit est utilisé. pour mettre en œuvre la gestion de la configuration et la poussée des changements. Le groupe Manbang a été le premier à adopter l'open source Eureka et ZooKeeper pour créer un centre d'enregistrement de services et un centre de configuration, cette structure a également bien entrepris la croissance rapide des activités du groupe Manbang au début.
Cependant, à mesure que le volume d'affaires augmente, il y a de plus en plus de modules d'affaires et le nombre d'instances d'enregistrement de services augmente de manière explosive . Les problèmes de stabilité du cluster de centres d'enregistrement de services Eureka auto-construit et du cluster ZooKeeper dans cette architecture sont devenus de plus en plus évidents. .
Pendant l'exploitation et la maintenance, les étudiants du groupe Manbang ont découvert que lorsque le nombre d'instances d'enregistrement de service dans le cluster Eureka auto-construit atteignait plus de 2 000, en raison de la synchronisation des informations d'enregistrement d'instance entre les nœuds du cluster Eureka, certains nœuds ne pouvaient pas les gérer, ce qui Des problèmes surviennent lorsque les nœuds ne parviennent pas à fournir des services et finissent par provoquer des échecs ; des GC fréquents dans le cluster ZooKeeper provoquent des instabilités dans les appels interservices et les versions de configuration, affectant en outre la stabilité globale, car ZooKeeper n'a aucune authentification ni authentification d'identité. capacités activées par défaut, le stockage de configuration est confronté à des risques de sécurité, ces problèmes posent également de grands défis au développement stable et durable de l'entreprise.
Migration fluide de l'architecture d'entreprise
Dans le contexte commercial ci-dessus, les étudiants de Manbang ont choisi de migrer de toute urgence vers le cloud, en utilisant les produits Alibaba Cloud MSE Nacos et MSE ZooKeeper pour remplacer les clusters Eureka et Zookeeper d'origine. Cependant, comment pouvons-nous également réaliser des mises à niveau d'architecture rapides et à faible coût. que l'entreprise lors de la migration vers le cloud ? Qu'en est-il de la migration fluide et sans perte du trafic ?
Sur ce point, MSE Nacos a atteint une compatibilité totale avec le protocole natif open source Eureka. Le noyau est toujours piloté par Nacos. La couche d'adaptation métier mappe un par un le modèle de données Eureka InstanceInfo et le modèle de données Nacos (Service et Instance). Tout cela est totalement transparent pour les entreprises : le groupe Manbang a repris le cluster Eureka auto-construit.
Cela signifie que le côté métier d'origine n'a pas besoin d'être modifié au niveau du code. Il vous suffit de modifier la configuration du point de terminaison de l'instance de serveur connectée par le client Eureka au point de terminaison de MSE Nacos. Son utilisation est également très flexible. Vous pouvez continuer à utiliser le protocole Eureka natif pour utiliser l'instance MSE Nacos en tant que cluster Eureka, ou vous pouvez utiliser les protocoles doubles Nacos et client Eureka pour coexister. Les informations d'enregistrement de service de différents protocoles prennent en charge mutuellement. conversion, assurant ainsi la connectivité des appels de microservices d'entreprise.
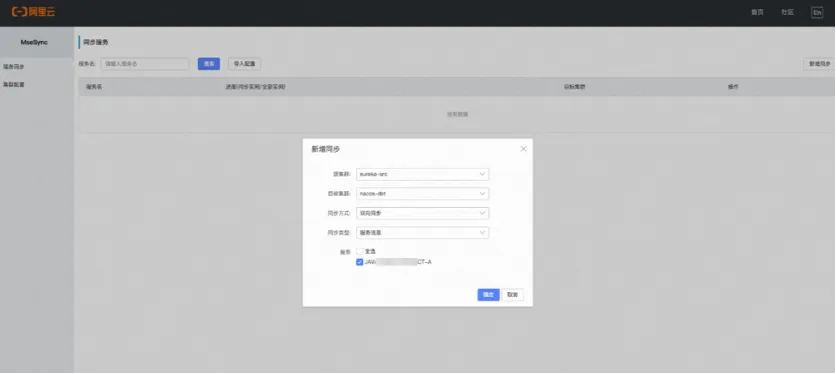
De plus, au cours du processus de migration vers le cloud, MSE a officiellement fourni la solution MSE-Sync, qui est un outil de migration optimisé prenant en charge la synchronisation des données basé sur l'open source Nacos-Sync. Il prend en charge la synchronisation bidirectionnelle, les services d'extraction automatique et le mode en un clic. fonctions de synchronisation. Grâce à MSE-Sync, les étudiants de Manbang peuvent facilement migrer en un seul clic les données de stock d'enregistrement de service en ligne existantes sur le cluster Eureka d'origine auto-construit vers le nouveau cluster MSE Nacos. également migré en un clic. Il sera continuellement et automatiquement synchronisé avec le nouveau cluster, garantissant ainsi que les informations de l'instance d'enregistrement du service de cluster des deux côtés sont toujours complètement cohérentes avant la migration réelle du flux d'affaires. Une fois la vérification de synchronisation des données réussie, remplacez la configuration d'origine du point de terminaison Eureka Client, republiez et mettez à niveau, puis migrez avec succès vers le nouveau cluster MSE Nacos.
Résoudre le goulot d'étranglement des performances de l'architecture de cluster native Eureka
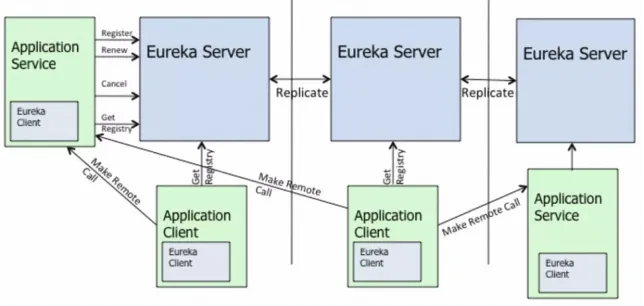
Lorsque le groupe Manbang a trouvé la mise à niveau de l'architecture technique de coopération de l'équipe MSE, la demande la plus importante était de résoudre le problème initial de la haute pression pour synchroniser les informations d'enregistrement des services entre les clusters Eureka . C'est parce qu'Eureka Server est une étoile peer-to-peer traditionnelle. Au modèle AP de synchronisation, les rôles de chaque nœud de serveur sont égaux et complètement équivalents. Pour chaque changement (enregistrement/désenregistrement/renouvellement de battement de cœur/changement d'état du service, etc.), une tâche de synchronisation correspondante sera générée pour la synchronisation de toutes les données de l'instance. De cette manière, le nombre de tâches de synchronisation augmente en corrélation directe avec la taille du cluster et le nombre d'instances.
Grâce à la pratique, les étudiants du groupe Manbang ont découvert que lorsque l'échelle d'enregistrement des services de cluster atteignait plus de 2 000, ils ont constaté que le taux d'occupation du processeur et la charge de certains nœuds étaient très élevés, et qu'ils feignaient parfois la mort de temps en temps, provoquant une nervosité commerciale. Ceci est également mentionné dans la documentation officielle d'Eureka. Le modèle de réplication de diffusion d'Eureka open source entraîne non seulement sa propre vulnérabilité architecturale, mais affecte également l'évolutivité horizontale globale du cluster.
L'algorithme de réplication limite l'évolutivité : Eureka suit un modèle de réplication par diffusion, c'est-à-dire que tous les serveurs répliquent les données et les battements de cœur vers tous les pairs. Ceci est simple et efficace pour l'ensemble de données contenu par eureka, mais la réplication est implémentée en relayant tous les appels HTTP qu'un serveur reçoit tels quels vers tous les pairs. Cela limite l'évolutivité car chaque nœud doit supporter toute la charge d'écriture sur eureka.
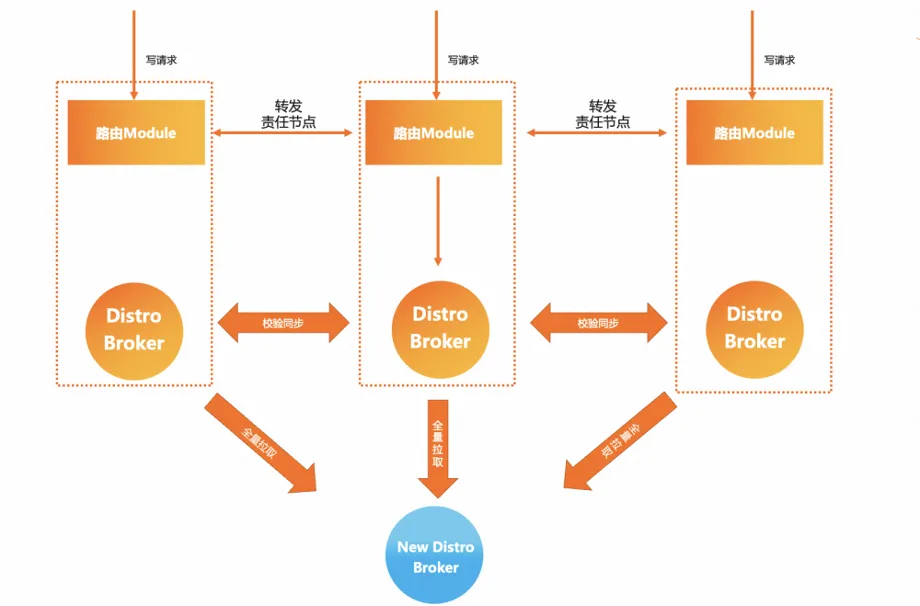
MSE Nacos a pris ce problème en considération dans la sélection de l'architecture et a proposé une meilleure solution, qui est le protocole Distro de modèle AP auto-développé. Sur la base du maintien du modèle de synchronisation en étoile, Nacos enregistre les données d'instance pour tous les services de hachage et de données logiques. le partitionnement est effectué et un nœud de responsabilité de cluster est attribué à chaque donnée d'instance de service. Chaque nœud de serveur est uniquement responsable de la logique de synchronisation et de renouvellement de sa propre partie des données. Dans le même temps, la granularité de la synchronisation des données entre les clusters est importante. relativement L'Eureka est également plus petit. L'avantage de ceci est que même dans les déploiements à grande échelle et les données d'instance de service volumineuses, la quantité de tâches de synchronisation entre les clusters peut être relativement contrôlable , et plus la taille du cluster est grande, plus l'amélioration des performances apportée par ce modèle est évidente.
L'optimisation itérative continue poursuit la performance ultime
Après que MSE Nacos et MSE ZooKeeper ont terminé l'activité complète du centre d'enregistrement de microservices du groupe Manbang, ils ont continué à optimiser de manière itérative dans les versions mises à niveau ultérieures et ont continué à optimiser les performances du serveur dans les moindres détails grâce à un grand nombre de tests de comparaison de tests de performance pour optimiser les performances. expérience commerciale, les points d'optimisation de la version mise à niveau seront analysés et introduits un par un.
Enregistrement du service, haute disponibilité, protection contre la reprise après sinistre
Native Nacos fournit des fonctions de haut niveau : protection push . Le consommateur du service (Consumer) s'abonne à la liste d'instances du fournisseur de services (Provider) via le centre d'enregistrement lorsque le centre d'enregistrement change ou rencontre une urgence, ou le fournisseur de services et le. centre d'enregistrement Lorsque le lien entre les centres est instable en raison du réseau, du processeur et d'autres facteurs, cela peut provoquer des exceptions d'abonnement, obligeant les consommateurs de services à obtenir une liste d'instances de fournisseur de services vide.
Afin de résoudre ce problème, vous pouvez activer la fonction de protection push sur le client Nacos ou le serveur MSE Nacos pour améliorer la disponibilité de l'ensemble du système. Nous avons également introduit cette fonction de stabilité dans la prise en charge du protocole pour Eureka. Lorsque les données du serveur MSE Nacos sont anormales, lorsque le client Eureka extrait les données du serveur, il recevra par défaut une prise en charge de la protection contre la reprise après sinistre pour garantir une utilisation professionnelle lorsque vous le faites. Ainsi, vous n'obtiendrez pas de liste d'instances de fournisseurs de services qui ne répondent pas aux attentes, provoquant des échecs commerciaux.
De plus, MSE Nacos et MSE ZooKeeper fournissent également plusieurs mécanismes de garantie de haute disponibilité . Si le côté commercial a des exigences plus élevées en matière de fiabilité et de sécurité des données, vous pouvez choisir de déployer avec pas moins de 3 nœuds lors de la création d'une instance. Lorsqu'une des instances échoue, la commutation entre les nœuds est terminée en quelques secondes et le nœud défaillant quitte automatiquement le cluster. Dans le même temps, chaque région MSE contient plusieurs zones de disponibilité. Le délai de réseau entre les différentes zones de la même région est très faible (dans les 3 ms). , , le trafic sera basculé vers une autre zone de disponibilité B dans un court laps de temps. Le côté commercial n'a pas connaissance de l'ensemble du processus, et le niveau du code d'application n'en a pas conscience et aucune modification n'est requise. Ce mécanisme nécessite uniquement la configuration d'un déploiement multi-nœuds, et MSE vous aidera automatiquement à déployer sur plusieurs zones de disponibilité pour une reprise après sinistre dispersée.
Prise en charge du client Eureka pour extraire progressivement des données
Après la migration des étudiants de Manbang vers MSE Nacos, le problème initial de la suspension de l'instance de serveur et de son incapacité à fournir des services a été bien résolu. Cependant, il a été constaté que la bande passante du réseau de la salle informatique était trop élevée et qu'elle était parfois pleine. pendant les périodes de pointe de service. Plus tard, il a été découvert que la raison en était que chaque fois que le client Eureka extrayait les informations d'enregistrement du service de MSE Nacos, il ne prenait en charge que l'extraction complète et des milliers de niveaux de données étaient extraits régulièrement, ce qui entraînait une augmentation du nombre de FGC à le niveau de la passerelle.
Afin de résoudre ce problème, MSE Nacos a lancé un mécanisme d'extraction incrémentiel pour les informations d'enregistrement du service Eureka. En conjonction avec l'ajustement de l'utilisation du client, le client n'a besoin d'extraire la totalité des données qu'une seule fois après le premier démarrage, et ensuite seulement. doit extraire la quantité totale de données en fonction des données incrémentielles. Les données sont utilisées pour maintenir la cohérence des données locales et des données du serveur, et les extractions périodiques à grande échelle ne sont plus nécessaires. La quantité de données incrémentielles modifiées dans un environnement de production normal est très importante. petit, ce qui peut réduire considérablement la pression sur la bande passante d’exportation. Après la mise à niveau vers cette version optimisée, les étudiants de Manbang ont constaté que la bande passante avait soudainement chuté de 40 Mo/s avant la mise à niveau à 200 Ko/s, et que le problème de la bande passante complète avait été résolu.

Test de stress complet pour optimiser les performances du serveur
L'équipe MSE a ensuite effectué un test de contrainte de performances à plus grande échelle sur le scénario du cluster MSE Nacos pour Eureka, et a utilisé divers outils d'analyse des performances pour identifier les goulots d'étranglement des performances sur les liaisons commerciales, et a procédé à une optimisation accrue des performances et à une optimisation des fonctions d'origine. réglage des paramètres de performance au niveau.
- La mise en cache est introduite pour les informations d'enregistrement de données complètes et incrémentielles côté serveur, et le fait que des modifications se soient produites est déterminé sur la base du hachage de données côté serveur. Dans les scénarios où le serveur Eureka lit plus et écrit moins, il peut réduire considérablement la surcharge de performances des calculs du processeur pour générer les résultats renvoyés.
- Il a été constaté que le StringHttpMessageConverter natif de SpringBoot présentait un goulot d'étranglement en termes de performances lors du traitement des retours de données à grande échelle, et EnhancedStringHttpMessageConverter a été fourni pour optimiser les performances de transmission des données de chaîne.
- Le retour de données côté serveur prend en charge le mode fragmenté.
- Le nombre de pools de threads Tomcat est ajusté de manière adaptative en fonction de la configuration du conteneur.
Après que Manbang Group ait terminé la mise à niveau itérative de la version ci-dessus, divers paramètres côté serveur ont également obtenu d'excellents résultats d'optimisation :
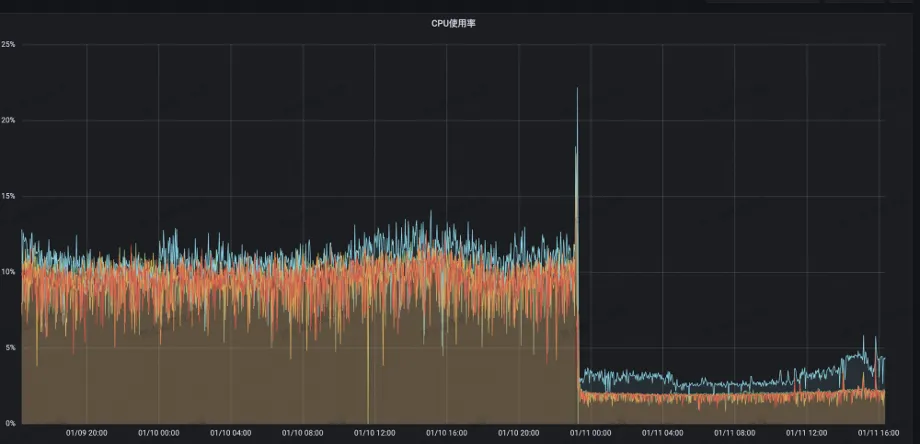
L'utilisation du processeur du serveur a chuté de 13 % à 2 %
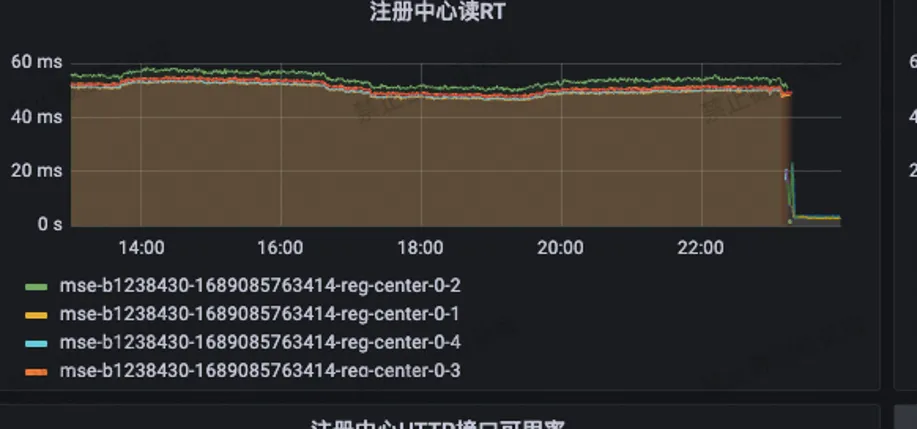
La lecture RT du centre d'enregistrement a été réduite de 55 ms d'origine à moins de 3 ms.

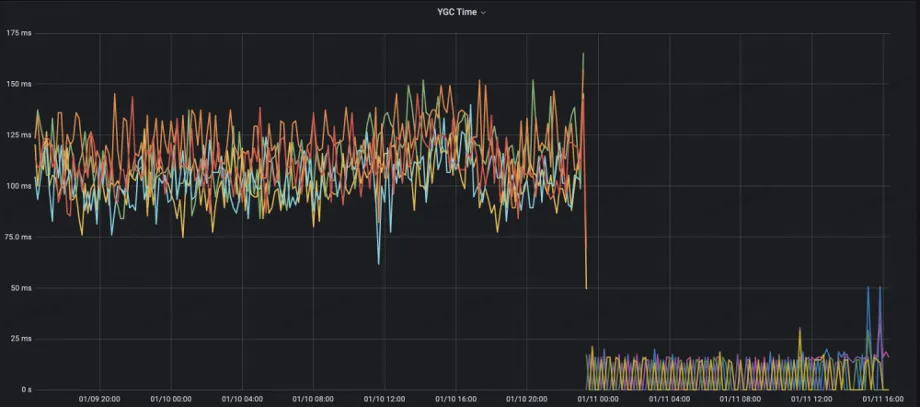
Le nombre de YGC côté serveur a été réduit de 10+ à 1.
Temps YGC réduit de 125 ms d'origine à moins de 10 ms
L'optimisation du bypass assure la stabilité du cluster sous haute pression
Après que les étudiants de Manbang aient migré vers MSE ZooKeeper pendant un certain temps, un GC complet s'est à nouveau produit dans le cluster, ce qui a rendu le cluster instable. Après une enquête d'urgence de MSE, il a été constaté que la raison était due à un indicateur statistique des métriques lié à la surveillance. ZooKeeper a été enregistré sur le nœud actuel pendant le calcul. Les données de surveillance sont entièrement copiées et l'échelle de surveillance est très grande dans un scénario de gang complet. La surveillance de copie de calcul de métriques génère une grande quantité de fragments de mémoire dans un tel scénario, ce qui entraîne le problème. le cluster final étant incapable d'allouer des ressources mémoire qualifiées, et in fine le Full GC.
Afin de résoudre ce problème, MSE ZooKeeper prend des mesures de rétrogradation pour les métriques non importantes afin de garantir que ces métriques n'affecteront pas la stabilité du cluster. Pour les métriques de copie de surveillance, il adopte une stratégie d'acquisition dynamique pour éviter les problèmes de fragmentation de la mémoire causés par les calculs de copie de données. Après avoir appliqué cette optimisation, le temps et le nombre de cluster Young GC sont considérablement réduits.
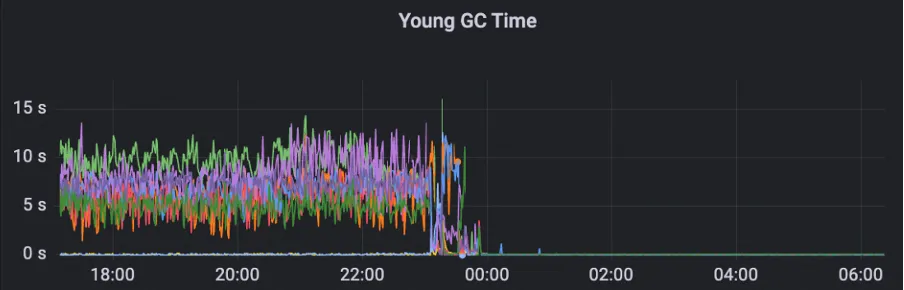

Après optimisation, le cluster peut gérer en douceur 200 W QPS et le GC est stable.
Optimisation continue des paramètres pour trouver le meilleur équilibre entre latence et débit
Après que les étudiants de Manbang aient migré leur ZooKeeper auto-construit vers MSE ZooKeeper, ils ont constaté que lorsque l'application a été publiée, le retard du client dans la lecture des données dans ZooKeeper était trop important et le délai de configuration de lecture au démarrage de l'application, entraînant un délai de démarrage de l'application. Afin de résoudre ce problème, l'analyse des tests de résistance ciblés de MSE ZooKeeper montre que dans un scénario de service complet, ZooKeeper doit gérer un grand nombre de requêtes lorsque l'application est publiée, et les objets générés par les requêtes provoquent de fréquents Young GC dans l'existant. configuration.
En réponse à ce scénario, l'équipe MSE a ajusté la configuration du cluster à travers plusieurs séries de tests de résistance pour trouver le point d'intersection optimal entre le délai de demande et le TPS. Dans le but de répondre aux exigences de délai, l'équipe MSE a exploré les performances optimales du cluster. et garanti le délai de demande de 20 ms. Sous le niveau QPS quotidien de 10 W du cluster, le processeur est réduit de 20 % à 5 % et la charge du cluster est considérablement réduite.
post-scriptum
Dans le contexte d'une concurrence féroce dans le secteur du fret numérique et d'un développement technologique rapide, le groupe Manbang a réussi à mettre à niveau sa propre architecture technique, en migrant en douceur du centre d'enregistrement Eureka auto-construit vers la plate-forme MSE Nacos, plus efficace et plus stable. Cela représente non seulement la ferme détermination du groupe Manbang en matière d’innovation technologique et d’expansion commerciale, mais démontre également ses projets de grande envergure pour le développement futur. Le groupe Manbang considère la stabilité et les hautes performances de l'architecture des microservices comme au cœur de sa transformation numérique. L'amélioration significative des performances et de la stabilité apportée par la nouvelle architecture du centre d'enregistrement offre un soutien solide à Manbang, permettant à la plate-forme d'être mieux préparée à gérer une activité en croissance. exigences et avoir le pouvoir de faire face à tous les défis qui pourraient surgir à l’avenir.
Il convient de mentionner que la réponse agile du groupe Manbang tout au long du processus de migration et l'exécution professionnelle de son équipe technique ont également accéléré le rythme de la mise à niveau de l'architecture. La transformation réussie de la plateforme commerciale renforce non seulement la confiance des utilisateurs dans les services de Manbang, mais offre également une expérience précieuse à d'autres entreprises. À l'avenir, Manbang continuera à travailler en étroite collaboration avec MSE pour améliorer encore la stabilité, l'évolutivité et les performances de l'architecture technique, continuer à établir des références pour le secteur et promouvoir la transformation numérique de l'ensemble du secteur logistique.
Au cours de ce processus de migration, l'entreprise a pu migrer en douceur et sans perte et les performances ont été considérablement améliorées, ce qui a prouvé l'excellente performance et la fiabilité de MSE dans le domaine des centres d'enregistrement de services. Je crois qu'avec l'évolution continue du MSE, sa recherche continue de facilité d'utilisation et de stabilité apportera sans aucun doute une énorme valeur commerciale à un plus grand nombre d'entreprises et jouera un rôle de plus en plus important dans le processus de numérisation des entreprises.
En outre, MSE prend également entièrement en charge les fonctions de gouvernance des microservices, notamment la protection du trafic, la publication en niveaux de gris de liens complets, etc. En appliquant des règles de limitation de courant entièrement configurées depuis la passerelle d'entrée jusqu'au backend, les risques de stabilité du système causés par un trafic soudain sont efficacement résolus, garantissant le fonctionnement continu et stable du système, et les entreprises peuvent se concentrer davantage sur le développement de leur activité principale. Le cas réussi du groupe Manbang a posé une nouvelle étape pour l'industrie. Nous sommes impatients de voir davantage d'entreprises réaliser des réalisations plus brillantes dans leur parcours numérique.
Message du CTO de Manbang, Wang Dong (Dongtian) : Comprendre et utiliser pleinement les capacités du cloud peut libérer l'équipe technique de Manbang des investissements continus au niveau inférieur, se concentrer sur la stabilité du système et l'efficacité de l'ingénierie de niveau supérieur, et obtenir de meilleurs résultats de la niveau architectural. ROI élevé.
Activités recommandées :

Cliquez ici pour vous inscrire à la première session d'architecture d'applications natives d'IA du Feitian Technology Salon.
L'équipe chinoise d'IA de Microsoft a fait ses valises et s'est rendue aux États-Unis, impliquant des centaines de personnes. Combien de revenus un projet open source inconnu peut-il rapporter ? Huawei a officiellement annoncé que la position de la station miroir open source de l'Université des sciences et technologies de Yu Huazhong a été ajustée. L'accès au réseau externe a été officiellement ouvert. Les fraudeurs ont utilisé TeamViewer pour transférer 3,98 millions ! Que doivent faire les fournisseurs de postes de travail à distance ? La première bibliothèque de visualisation frontale et fondateur du célèbre projet open source de Baidu, ECharts - un ancien employé d'une société open source bien connue qui "est allée à la mer" a annoncé la nouvelle : après avoir été interpellé par ses subordonnés, le technicien Le leader est devenu furieux et grossier et a licencié l'employée enceinte. OpenAI a envisagé d'autoriser l'IA à générer du contenu pornographique. Microsoft a déclaré à la Fondation Rust qu'elle avait fait un don de 1 million de dollars américains. Veuillez me dire quel est le rôle de time.sleep(6) ici. ?