
Cet article est le premier d'une série célébrant le deuxième anniversaire de CloudWeGo.
Le partage d'aujourd'hui est principalement divisé en trois parties. La première est la mise à niveau des capacités de Kitex. Jetons un coup d'œil à certains progrès en termes de
performances
,
de fonctionnalités
et
de facilité d'utilisation
au cours de l'année écoulée. Le deuxième est l'avancement des projets de coopération communautaire, notamment deux projets clés, l'interopérabilité
Kitex-Dubbo
et l'intégration du centre de configuration . La troisième est de vous donner quelques spoilers sur certaines des choses que nous faisons actuellement et prévoyons de faire.
Mise à niveau des capacités
performance
En septembre 2021, nous avons publié un article «
ByteDance Go RPC Framework Kitex Performance Optimization Practice
», qui peut être trouvé sur le site officiel de CloudWeGo. Cet article présente comment éditer via la bibliothèque réseau auto-développée Netpoll et le Thrift Decoder auto-développé. fastCodec pour optimiser les performances de Kitex.
Depuis lors, il a été très difficile d'améliorer les performances sur le lien de requête principal de Kitex. En fait, nous devons travailler dur pour éviter la dégradation des performances de Kitex tout en ajoutant constamment de nouvelles fonctionnalités.
Malgré cela, nous n’avons jamais cessé d’essayer d’optimiser les performances du Kitex. Au sein de Byte, nous expérimentons et promouvons déjà certaines améliorations de performances sur les liens principaux, que nous vous présenterons plus tard.
Appel généralisé basé sur DynamicGo
Tout d’abord, nous présenterons une optimisation des performances qui a été publiée : les appels généralisés basés sur DynamicGo.
L'appel générique
est une fonctionnalité avancée de Kitex. Il peut utiliser Kitex Generic Client pour appeler directement l'API du service cible sans pré-générer de code SDK (c'est-à-dire Kitex Client).
Par exemple, les outils de test d'interface interne de ByteDance, les passerelles API, etc. utilisent le client généralisé de Kitex, qui peut recevoir une requête HTTP (le corps de la requête est au format JSON), la convertir en Thrift Binary et l'envoyer au serveur Kitex.
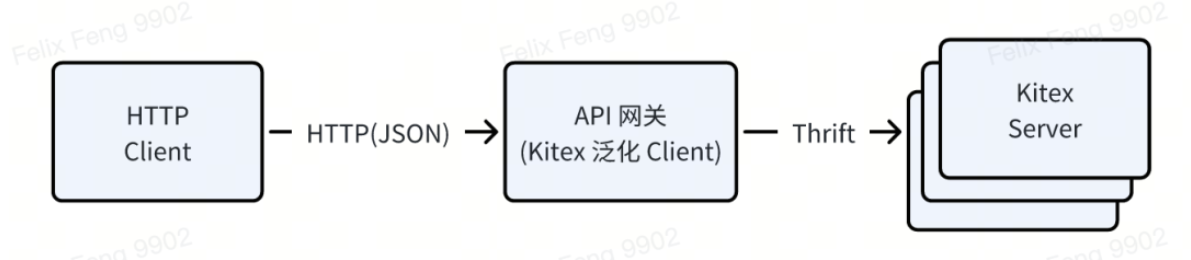
Le plan de mise en œuvre consiste à s'appuyer sur un
map[string]interface{}
conteneur générique, à convertir d'abord json en map lors de la demande, puis à terminer la conversion map -> thrift basée sur Thrift IDL, la réponse est traitée en sens inverse.
-
L'avantage est qu'il est très flexible et ne nécessite pas de code statique pré-généré. Vous n'avez besoin que d'IDL pour demander le service cible ;
-
Cependant, le prix est médiocre. Un tel conteneur générique repose sur le GC et la gestion de la mémoire de Go, ce qui est très coûteux. Il nécessite non seulement d'allouer une grande quantité de mémoire, mais nécessite également plusieurs copies de données.
Par conséquent, nous avons développé DynamicGo (page d'accueil :
http://github.com/cloudwego/dynamicgo
), qui peut être utilisé pour améliorer les performances de conversion de protocole. Il y a une introduction très détaillée dans l'introduction du projet. Ici, je ne vous présenterai que son idée de conception principale : sur
la base du flux d'octets d'origine
,
le traitement et la conversion des données
sont effectués in situ .
Grâce à la technologie de pooling, Dynamicgo n'a besoin de pré-allouer de la mémoire qu'une seule fois et utilise des jeux d'instructions SIMD tels que SSE et AVX pour l'accélération, obtenant ainsi des améliorations considérables des performances.
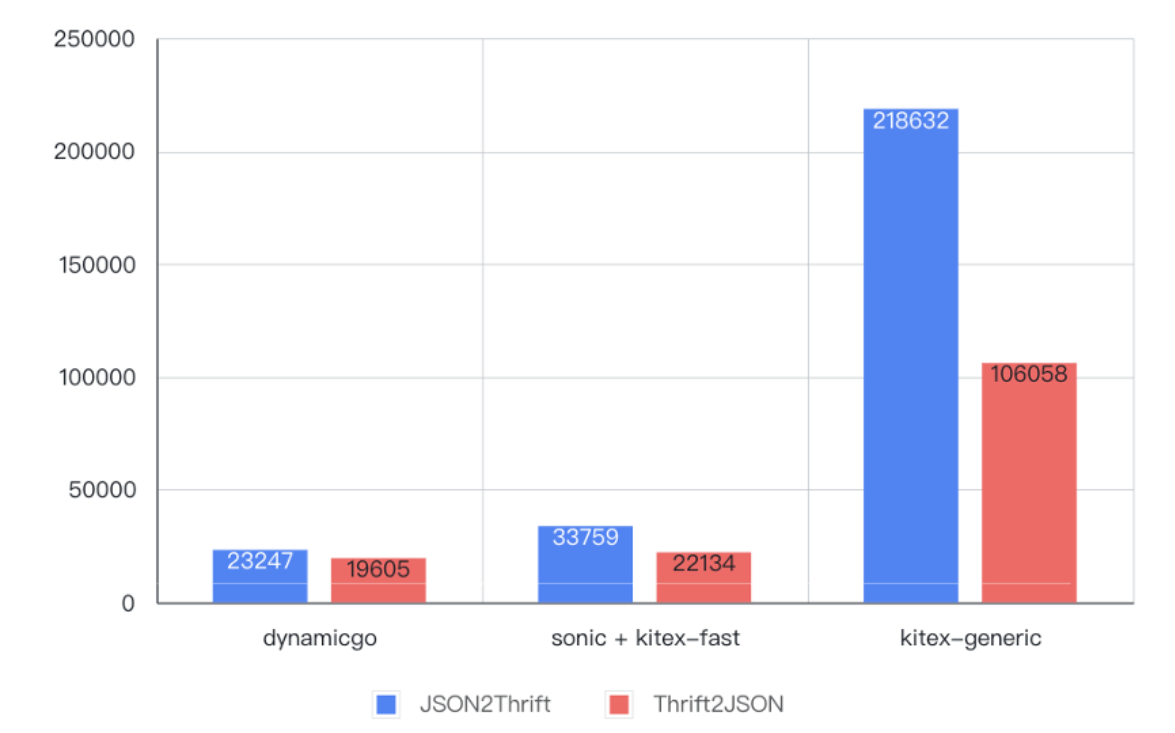
Comme le montre la figure ci-dessous, par rapport à l'implémentation originale de l'appel généralisé, dans le test d'encodage et de décodage de données de 6 Ko, les performances ont été améliorées de
4 à 9 fois
, encore
meilleures que
le code statique pré-généré.
Le principe actuel est très simple : générer un descripteur de type basé sur l'analyse IDL et effectuer le processus de conversion de protocole suivant
-
Lire une paire clé/valeur à partir du flux d'octets JSON à chaque fois ;
-
Recherchez le champ Thrift correspondant à la clé selon le descripteur IDL ;
-
Terminez le codage de Value conformément à la spécification de codage Thrift du type correspondant et écrivez-le dans le flux d'octets de sortie ;
-
Bouclez ce processus jusqu'à ce que l'intégralité du JSON soit traitée.
En plus d'optimiser la conversion du protocole JSON/Thrift, DynamicGo fournit également la méthode Thrift DOM pour optimiser les performances des scénarios d'orchestration de données. Par exemple, une équipe commerciale de Douyin doit effacer les données illégales dans la requête, mais uniquement dans un certain champ de la requête ; l'utilisation de l'API Thrift DOM de DynamicGo est très appropriée et peut améliorer les performances de 10 fois. Pour plus de détails, veuillez vous référer à . Documentation de DynamicGo. Elle ne sera pas développée ici.
Frugal - Un codec Thrift hautes performances basé sur JIT
Frugal est un codec Thrift hautes performances basé sur la technologie de compilation
JIT .
Les codecs par défaut officiels de Thrift et Kitex sont basés sur l'analyse de Thrift IDL et la génération du code Go d'encodage et de décodage correspondant. Grâce à la technologie JIT, nous pouvons générer dynamiquement des codes d'encodage et de décodage avec de meilleures performances au
moment de l'exécution
: générer un code machine plus compact, réduire les échecs de cache, réduire les échecs de branchement, utiliser les instructions SIMD pour accélérer et utiliser des appels de fonction basés sur les registres (Go par défaut est basé sur sur pile).
Voici les indicateurs de performance des tests d’encodage et de décodage :

Comme on peut le constater, les performances de Frugal sont nettement supérieures à celles des méthodes traditionnelles.
Outre les avantages en termes de performances, il existe également des avantages supplémentaires car aucun code codec n'est généré.
D'une part ,
l'entrepôt est plus concis
.Nous avons un projet où le code généré est de 700 Mo. Après le passage à frugal, il ne fait que 37 Mo, soit environ 5 % de la taille d'origine. La pression sur la maintenance de l'entrepôt est considérablement réduite. , et beaucoup de code ne sera pas généré après modification de l'IDL. Code qui ne peut pas réellement être révisé. Par contre,
la vitesse de chargement de l'EDI et
la vitesse de compilation
du projet peuvent également être considérablement améliorées.
En fait, Frugal est sorti l’année dernière, mais la couverture médiatique de la première version à l’époque n’était pas suffisante. Cette année, nous nous sommes concentrés sur l'optimisation de sa stabilité et avons résolu tous les problèmes connus. La version v0.1.12 récemment publiée peut être utilisée de manière stable dans les opérations de production. Par exemple, dans le secteur d'activité e-commerce ByteDance, le QPS maximal d'un certain service est d'environ 25K. Il a été entièrement basculé vers Frugal et fonctionne de manière stable depuis plusieurs mois.
Frugal prend actuellement en charge Go1.16 ~ Go1.21, ne prend actuellement en charge que l'architecture AMD64 et prendra également en charge l'architecture ARM64 à l'avenir ; nous pourrions utiliser Frugal comme codec par défaut de Kitex dans une future version.
Fonction
Kitex a été mis à niveau de la v0.4.3 à la v0.7.2 au cours de l'année écoulée. Il existe plus de 40 demandes d'extraction liées aux fonctionnalités, couvrant
les outils de ligne de commande
,
gRPC
, l'encodage et le décodage
Thrift
, les tentatives , les appels généralisés et les configurations de gouvernance des services
.
À bien des égards, nous nous concentrons ici sur quelques fonctionnalités plus importantes.
Solution de secours – Déclassement personnalisé pour les entreprises
La première est la fonction de repli ajoutée par Kitex dans la version v0.5.0.
Le contexte de la demande est que lorsque la requête RPC échoue et que la réponse ne peut pas être obtenue, le code métier doit souvent mettre en œuvre des stratégies de rétrogradation.
Par exemple, dans le domaine des flux d'informations, si la couche d'accès API rencontre une erreur occasionnelle (telle qu'un délai d'attente) lors de la demande de services recommandés, l'approche simple et grossière consiste à informer l'utilisateur qu'une erreur s'est produite et à le laisser réessayer, mais cela entraînera une mauvaise expérience. Une meilleure stratégie de rétrogradation consiste à essayer de renvoyer certains éléments populaires. Les utilisateurs n'en auront presque aucune idée et l'expérience sera bien meilleure.
Le problème avec l'ancienne version de Kitex est que le middleware personnalisé ne peut pas être implémenté dans le middleware après le middleware intégré tel que le disjoncteur et le délai d'attente. Le seul moyen est de modifier directement le code métier, ce qui est assez intrusif et. nécessite de modifier chaque méthode appelée, facile à manquer. Lors de l'ajout d'une logique métier qui appelle une certaine méthode, il n'existe aucun mécanisme garantissant qu'elle ne sera pas manquée.
Grâce à la nouvelle fonction de secours,
l'entreprise est autorisée à spécifier une méthode de secours lors de l'initialisation du client pour mettre en œuvre la stratégie de rétrogradation
.
Voici un exemple d'utilisation simple :

Cette méthode spécifiée lors de l'initialisation du client sera appelée avant la fin de chaque requête. Le contexte, les paramètres de la requête et la réponse de cette requête peuvent être obtenus. Sur cette base, une stratégie de rétrogradation personnalisée peut être mise en œuvre, faisant ainsi converger la mise en œuvre du client. stratégie.
Thrift FastCodec - prend en charge les champs inconnus
Dans les scénarios commerciaux réels, un lien de demande implique souvent plusieurs nœuds.
En prenant le lien A -> B -> C -> D comme exemple, une certaine structure du nœud A doit être transmise de manière transparente au nœud D via B et C. Dans l'implémentation précédente, si un nouveau champ est ajouté à A, par exemple
Extra
, je
dois utiliser le nouvel
IDL
pour régénérer le code de tous les nœuds
et le redéployer pour obtenir la valeur du champ Extra dans le nœud D. L'ensemble du processus est complexe et le cycle de mise à jour est relativement long. Si le nœud intermédiaire est un service d'une autre équipe, une coordination entre équipes est nécessaire, ce qui est très laborieux.
Dans Kitex v0.5.2, nous avons implémenté la fonctionnalité Champs inconnus dans notre fastCodec auto-développé, qui peut très bien résoudre ce problème.
Par exemple, dans le même lien A -> B -> C -> D, les codes des nœuds B et C restent inchangés (comme le montre la figure ci-dessous, lors de l'analyse, on constate qu'il y a un champ
id=2
, et le ). le champ correspondant est introuvable dans la structure. Ce
_unknownFields
champ non exporté (en fait un alias d'une tranche d'octets) est donc écrit ;

Les services A et D sont régénérés avec le nouvel IDL (comme indiqué dans la figure ci-dessous) et incluent
Extra
le champ. Par conséquent, lors de l'analyse
id=2
du champ, vous pouvez écrire dans ce
Extra
champ et le code métier peut être utilisé normalement.

De plus, nous avons également effectué une optimisation des performances sur cette fonctionnalité dans la v0.7.0, en utilisant «
aucune
sérialisation
» (copie directe des flux d'octets) pour améliorer les performances d'encodage et de décodage des champs inconnus d'environ
6 à 7
fois.
Mécanisme de livraison de session basé sur GLS
Une autre fonctionnalité qui mérite d’être présentée est également liée aux liens longs.
Au sein de Byte, nous utilisons LogID pour suivre l'intégralité de la chaîne d'appels, ce qui nécessite que tous les nœuds du lien transmettent ce ticket de manière transparente selon les besoins. Dans notre implémentation, LogID n'est pas placé dans le corps de la requête, mais est transmis de manière transparente sous forme de métadonnées.
Prenons l'exemple du lien A -> B -> C Lorsque A appelle
A_Call_B
la méthode de B, le LogID entrant sera stocké dans le paramètre d'entrée du gestionnaire
ctx
. Lorsque B demande C, l'utilisation correcte est de le transmettre
ctx
à
client
C.B_Call_C
la méthode uniquement. de cette façon, le LogID peut être transmis.

Mais la situation réelle est souvent que le code demandant le service C est empaqueté en plusieurs couches, et
la transmission transparente de ctx est facilement manquée
; la situation que nous avons rencontrée est plus gênante. La demande de service C est
complétée par un tiers. bibliothèque
et l'interface de la bibliothèque ne prend pas en charge le code entrant
ctx
, et une telle transformation de code est très coûteuse et peut nécessiter la coordination de plusieurs équipes.
Afin de résoudre ce problème, nous avons introduit un mécanisme de transfert de session basé sur GLS (goroutine local storage). Le plan spécifique est le suivant :
-
Côté serveur Kitex, après avoir reçu la requête, il sauvegarde d'abord le contexte dans GLS, puis appelle le Handler, qui est le code métier ;
-
Lors de l'appel du client dans le code métier pour envoyer une requête, vérifiez d'abord si l'entrée ctx contient le ticket attendu. Sinon, retirez-le de la sauvegarde GLS puis envoyez la requête.
Voici un exemple précis :

illustrer:
-
ContextBackupAllumez le commutateur lors de l'initialisation du serveur -
Spécifiez-en un lors de l'initialisation du client
backupHandler -
Avant chaque requête, ce gestionnaire sera appelé pour vérifier si les paramètres d'entrée incluent
LogID -
ctxS'il n'est pas inclus, lisez-le depuis la sauvegarde , fusionnez-le avecctxcelui actuel et renvoyez-le (retouruseNewCtx =truesignifie que Kitex doit utiliser ce nouveauctxpour envoyer la demande)
Après avoir activé les paramètres ci-dessus, même si le code métier utilise le mauvais contexte, l'ensemble du lien peut être connecté en série.
Enfin, introduisons le paramètre async d'initialisation du serveur, qui résout le problème de l'envoi des requêtes dans une nouvelle goroutine dans le gestionnaire. Puisqu'il ne s'agit pas de la même goroutine, le stockage local ne peut pas être partagé directement ; nous apprenons du mécanisme de coloration des goroutines de pprof et transmettons la sauvegarde
ctx
au nouveau goroutine, réalisant ainsi la possibilité de transmettre implicitement des tickets dans des scénarios
asynchrones
.
Facilité d'utilisation
En plus des hautes performances et des fonctionnalités riches, nous accordons également une grande attention à l'amélioration de la facilité d'utilisation de Kitex.
Documents |
Comme nous le savons tous, il y a deux choses que les programmeurs détestent le plus : l’une est d’écrire de la documentation, et l’autre est que les autres n’écrivent pas de documentation. Par conséquent, nous attachons une grande importance à la réduction des coûts de démarrage liés à la rédaction de documents et travaillons dur pour promouvoir la construction de documents.
Au sein de ByteDance, les documents de Kitex sont organisés sous la forme d'une base de connaissances Feishu, qui peut être mieux intégrée dans la recherche de Feishu et faciliter les demandes des employés de Byte car les documents Feishu sont faciles à mettre à jour, ils sont plus mis à jour que les documents du site officiel lorsqu'ils sont disponibles en temps opportun ; de nouvelles fonctionnalités sont développées, les documents sont souvent rédigés en premier dans la base de connaissances Feishu et certains ne sont pas synchronisés à temps avec le site officiel. Diverses raisons ont conduit à des différences croissantes entre les branches intérieures et extérieures.
C'est pourquoi, au cours des deux derniers trimestres, nous avons lancé une nouvelle série de travaux d'optimisation des documents : sur la base des commentaires des utilisateurs, nous avons réorganisé tous les documents et ajouté davantage d'exemples, nous avons traduit tous les documents en anglais et les avons synchronisés avec le site officiel. Ce travail devrait être achevé cette année. Vous pouvez déjà voir certains documents mis à jour sur le site officiel, tels que le contrôle des délais d'attente, Frugal, le traitement de panique, etc. Vous êtes invités à visiter le site officiel et à aider à détecter les bugs.
De plus, nous construisons également un mécanisme pour synchroniser automatiquement les documents internes avec le site officiel. Nous espérons qu'à l'avenir, les utilisateurs open source pourront également obtenir des documents mis à jour en temps opportun, comme les utilisateurs internes.
Autres optimisations |
En plus de la documentation, Kitex effectue également d'autres travaux liés à la convivialité.
Nous avons publié un exemple de projet "Note Service", qui démontre l'utilisation de diverses fonctionnalités telles que le middleware, la limitation de courant, la nouvelle tentative, le contrôle du délai d'attente, etc. dans l'exemple, et fournit une référence aux utilisateurs de Kitex via le code du projet réel. Vous pouvez consulter l'exemple ici : https://github.com/cloudwego/kitex-examples/tree/main/bizdemo/easy_note.
Deuxièmement, nous travaillons également dur pour améliorer l'efficacité du dépannage. Par exemple, nous avons ajouté des informations contextuelles plus spécifiques au message d'erreur en fonction des besoins quotidiens d'astreinte (telles que la raison spécifique de l'erreur de délai d'attente, le nom de la méthode de panique). et le message d'erreur du codec d'épargne. Noms de champs spécifiques, etc.) pour localiser rapidement les points problématiques spécifiques.
De plus, les outils de ligne de commande Kitex continuent de s'améliorer.
-
Par exemple, de nombreux utilisateurs professionnels développent sous Windows. Auparavant, Kitex ne pouvait pas générer de code normalement sous Windows. Par conséquent, ces utilisateurs avaient également besoin d'un environnement Linux pour les aider, ce qui était très gênant. Nous avons effectué des optimisations en fonction des commentaires de ces utilisateurs. .
-
Nous avons également implémenté un outil de découpage IDL capable d'identifier les structures qui ne sont pas référencées et de les filtrer directement lors de la génération de code. Ceci est très utile pour certains anciens projets bloqués.
projets de coopération communautaire
Au cours de la dernière année, avec le soutien de la communauté CloudWeGo, nous avons également obtenu de nombreux résultats, notamment les deux projets d'interopérabilité Dubbo et d'intégration du centre de configuration.
Dubbo | Intercommunication Dubbo
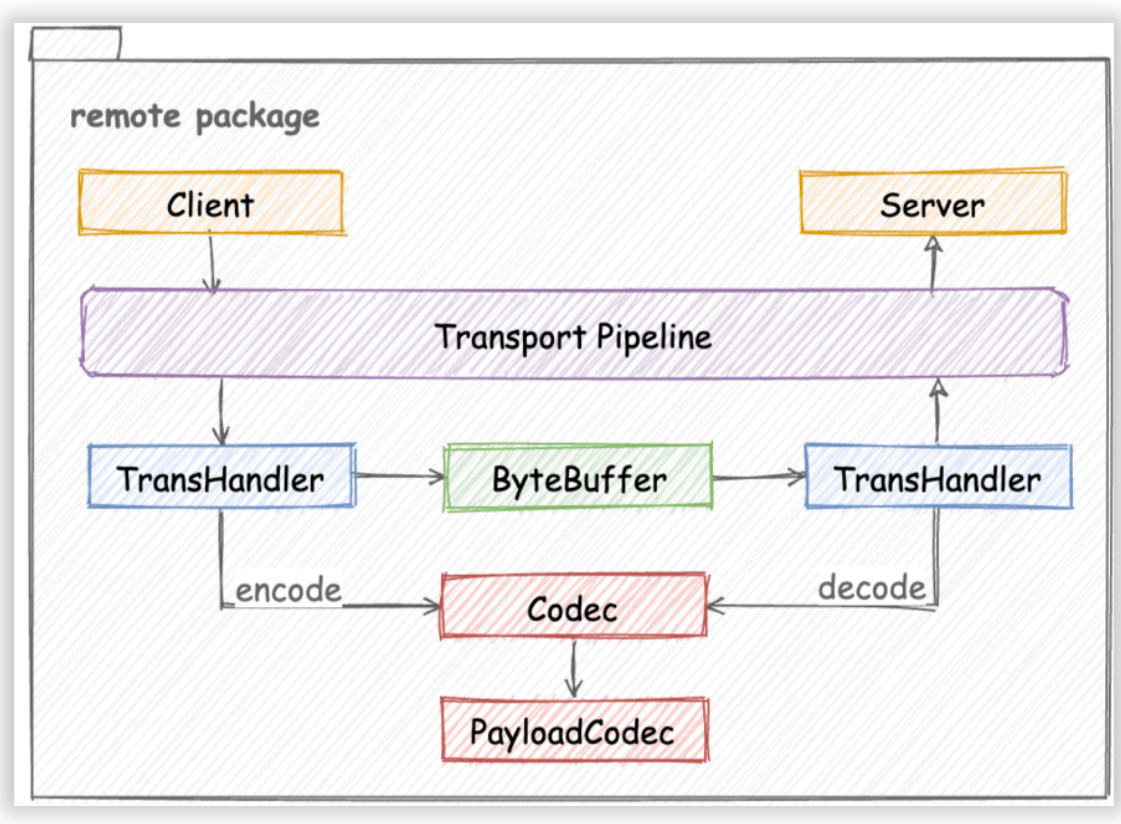
Bien que Kitex soit à l'origine un framework Thrift RPC, sa conception architecturale présente une bonne évolutivité, comme le montre la figure, lors de l'ajout de nouveaux protocoles, le travail principal consiste à implémenter un codec de protocole correspondant (Codec ou PayloadCodec) en fonction de l'interface Codec :
Le projet d'interopérabilité Dubbo est né des besoins d'un utilisateur d'entreprise. Ils disposent de certains services périphériques implémentés par des fournisseurs utilisant Dubbo Java. Ils espèrent utiliser Kitex pour demander ces services et réduire les coûts de gestion de projet.
Ce projet a reçu le soutien enthousiaste des étudiants de la communauté et de nombreux étudiants ont participé à ce projet. En particulier, @DMwangnima, qui est responsable de l'une des tâches principales, est également développeur de la communauté Dubbo. Comme il connaît Dubbo, le processus de développement a évité de nombreux détours.
Concernant le plan de mise en œuvre spécifique, nous avons adopté une idée différente du responsable de Dubbo. Selon l'analyse du protocole hessian2, son système de types de base chevauche essentiellement Thrift, nous avons donc généré l'échafaudage du projet Kitex Dubbo-Hessian2 basé sur Thrift IDL.
Afin d'implémenter rapidement la fonction dans la première phase, nous avons directement emprunté la bibliothèque hessian2 du framework Dubbo-go pour la sérialisation et la désérialisation, et implémenté le propre DubboCodec de Kitex en nous référant à la documentation officielle de Dubbo et au code source de Dubbo-Go ;
En octobre, nous avons terminé la première version du code. L'adresse du projet est
https://github.com/kitex-contrib/codec-dubbo
. Les utilisateurs intéressés peuvent l'essayer selon le document ci-dessus. il peut être comparé à Kitex Similaire à Thrift, écrivez le Thrift IDL, utilisez la ligne de commande kitex pour générer un échafaudage (notez que le protocole doit être spécifié comme hessian2), puis spécifiez DubboCodec dans le code où le client et le serveur sont initialisés , et vous pouvez commencer à écrire du code métier.
Cela abaisse non seulement le seuil d'utilisation de l'utilisateur, mais utilise également IDL pour gérer les informations liées à l'interface, améliorant ainsi la maintenabilité.
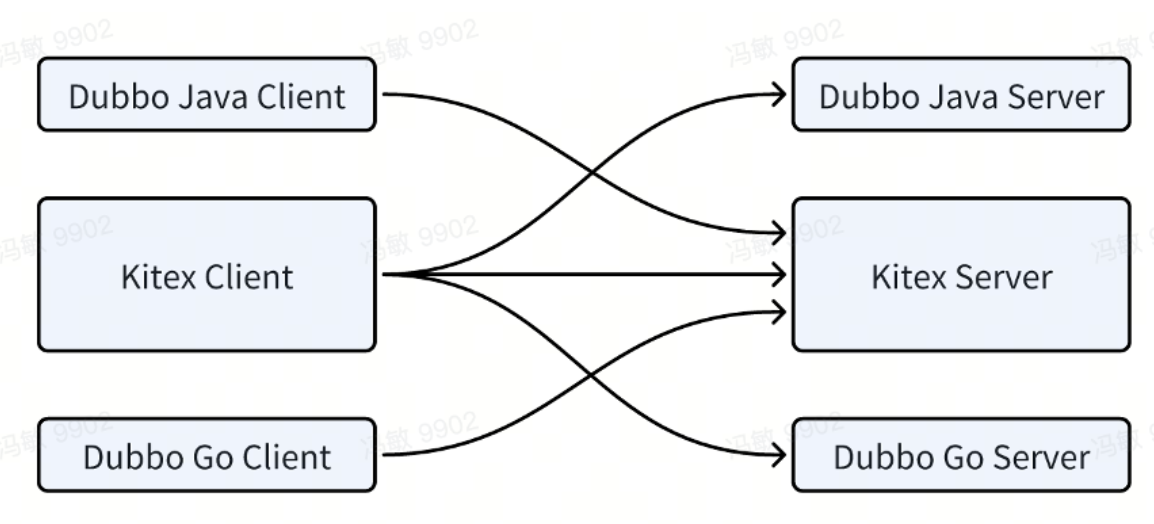
A l'heure actuelle, nous avons pu réaliser l'interopérabilité entre Kitex et Dubbo-Java, Kitex et Dubbo-Go :
Plan d'avenir:
-
La première consiste à améliorer la compatibilité avec dubbo-java et à permettre aux utilisateurs de spécifier le type Java correspondant dans les annotations IDL.
-
La seconde est la connexion avec le centre d'inscription. Bien que Kitex dispose déjà d'un module de centre d'enregistrement correspondant, le format de données spécifique n'est pas cohérent avec Dubbo. Cette zone nécessite encore quelques modifications et les travaux correspondants sont sur le point d'être terminés.
-
Enfin, il y a le problème des performances. Il y a actuellement un gros écart par rapport à Kitex Thrift. La bibliothèque dubbo-go-hessian2 étant entièrement basée sur la réflexion, il reste encore beaucoup de place pour l'optimisation des performances. Il est prévu d'implémenter FastCodec de Hessian2 pour résoudre le goulot d'étranglement des performances d'encodage et de décodage.
Au cours de l'avancement de ce projet, nous avons profondément ressenti l'impact positif de la coopération intercommunautaire. Kitex a absorbé les réalisations de la communauté Dubbo et a également découvert les domaines dans lesquels le projet Dubbo-go pourrait être amélioré. Les solutions de compatibilité et de performances mentionnées ci-dessus. devrait également bénéficier à la communauté dubbo.
Je voudrais également exprimer mes remerciements particuliers aux contributeurs de la communauté à ce projet, @DMwangnima, @Lvnszn, @ahaostudy, @jasondeng1997, @VaderKai et aux autres étudiants, pour avoir consacré une grande partie de leur temps libre à mener à bien ce projet.
Intégration de Config Center | Intégration de Config Center
Un autre projet clé de la coopération communautaire est "l'intégration du centre de configuration".
Kitex fournit des fonctionnalités de gestion de services configurables de manière dynamique, notamment le délai d'expiration du client, les nouvelles tentatives, le disjoncteur et la limitation du courant du serveur.
Ces capacités de gouvernance de services sont largement utilisées au sein de Byte. Les développeurs de microservices peuvent modifier ces configurations sur la plate-forme de configuration de gouvernance de services auto-construite de Byte. La granularité est affinée à cinq tuples et prend effet en temps quasi réel. très utile pour améliorer le SLA des microservices.
Cependant, nous avons communiqué avec les utilisateurs d'entreprise et constaté que ces fonctionnalités sont généralement très simples à utiliser, avec une granularité grossière et une rapidité médiocre. Elles peuvent uniquement être des configurations spécifiées codées en dur, ou configurées via de simples fichiers, et nécessitent un redémarrage pour prendre effet. .
Afin de permettre aux utilisateurs de mieux utiliser les capacités de gouvernance des services de Kitex, nous avons lancé le projet d'intégration du centre de configuration afin que Kitex puisse
obtenir dynamiquement les configurations de gouvernance des services
à partir du centre de configuration de l'utilisateur et prendre effet en temps quasi réel.
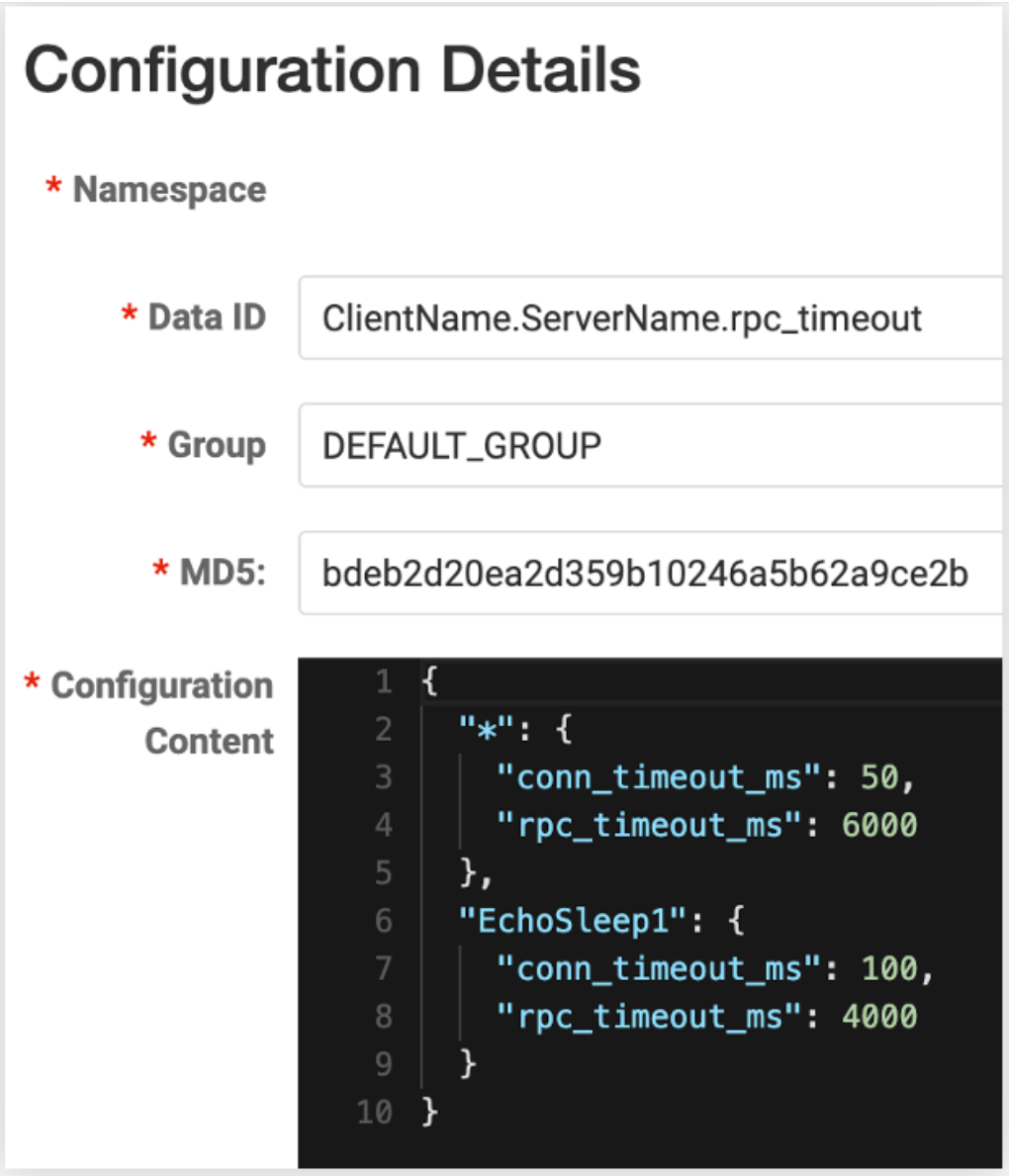
Nous avons publié la version v0.1.1 de config-nacos (remarque : elle a été mise à jour vers la v0.3.0 au moment de la publication, grâce à @whalecold pour son investissement continu en ajoutant un client au projet Kitex existant)
NacosClientSuite
. peut être facilement
réalisé. Kitex
charge la configuration de gouvernance de service correspondante à partir de
N
acos .

Puisque nous utilisons la capacité de surveillance fournie par le client nacos lui-même, nous pouvons recevoir des notifications de changement de configuration en temps quasi réel, la rapidité est donc également très élevée et il n'est pas nécessaire de redémarrer le service.
De plus, nous avons également réservé la possibilité de modifier la granularité de configuration. Par exemple, la granularité de configuration par défaut est client + serveur. Il suffit de remplir l'identifiant de données de Nacos dans ce format ; par exemple, ajoutez des salles informatiques, des clusters, etc., afin d'ajuster plus finement ces configurations.
Nous prévoyons de terminer l'intégration avec les centres de configuration communs. Vous trouverez des instructions plus détaillées dans ce numéro https://github.com/cloudwego/kitex/issues/973.
Les progrès actuels sont les suivants :
-
Des modules tels que file, apollo, etcd et zookeeper ont soumis des PR et sont en cours d'examen ;
-
le plan du consul a été soumis ;
Les camarades de classe intéressés peuvent également participer pour examiner, tester et vérifier ces modules d'extension.
perspectives d'avenir
Enfin, permettez-moi de vous donner quelques spoilers sur certaines des directions que nous essayons actuellement.
fusionner le déploiement
Déploiement d'affinité | Déploiement d'affinité
La plupart de nos optimisations précédentes concernaient le service, mais à mesure que le nombre de points d'optimisation diminuait progressivement, nous avons commencé à envisager d'autres objectifs, tels que l'optimisation de la surcharge de communication réseau des requêtes RPC.
Les plans spécifiques sont les suivants :
-
La première est la planification par affinité. En modifiant le mécanisme de planification conteneurisée, nous essayons de planifier le client et le serveur sur la même machine physique ;
-
Nous pouvons donc utiliser la communication sur une même machine pour réduire les frais généraux.
À l'heure actuelle, la communication entre machines que nous avons mise en œuvre comprend les trois types suivants :
-
Unix Domain Socket a de meilleures performances que le TCP Socket standard, mais pas beaucoup ;
-
ShmIPC (https://github.com/cloudwego/shmipc-go), communication inter-processus basée sur la mémoire partagée, peut directement omettre la transmission de données sérialisées et n'a besoin que d'indiquer au récepteur l'adresse mémoire ;
-
Enfin, il y a la « technologie noire » RPAL , qui est l'abréviation de Run Process As Library. Nous travaillons avec l'équipe du noyau de Byte pour placer deux processus dans le même espace d'adressage via un noyau personnalisé. Lorsque certaines conditions sont remplies, nous le faisons. il se peut même que vous n'ayez pas besoin de faire de sérialisation ;
À l'heure actuelle, nous avons activé cette fonctionnalité sur plus de 100 services et avons obtenu des gains de performances pour les services avec de meilleurs effets, cela peut économiser environ 5 à 10 % du processeur et réduire la consommation de temps de 10 à 70 % ; pratique Les performances dépendent de certaines caractéristiques du service, telles que la taille des paquets.
Fusion au moment de la compilation | Service en ligne
Une autre idée est la fusion au moment de la compilation.
Le point de départ de cette solution est que nous avons constaté que même si les microservices améliorent l'efficacité de la collaboration en équipe, ils augmentent également la complexité globale du système, notamment en termes de déploiement de services, d'occupation des ressources, de surcharge de communication, etc.
Nous espérons donc mettre en œuvre une solution permettant à l'entreprise d'être développée sous forme de microservices et déployée sous forme de services uniques, communément appelés avoir les deux.
Ensuite, nous avons élaboré ce plan - nous avons développé un outil capable de fusionner le dépôt git de deux microservices, d'isoler les ressources potentiellement conflictuelles via l'espace de noms, puis de le compiler dans un programme exécutable pour le déploiement.
Actuellement, au sein de ByteDance, des dizaines de services sont connectés. Le service le plus efficace peut économiser environ 80 % du processeur et réduire la latence jusqu'à 67 %. Bien entendu, les performances réelles dépendent également des caractéristiques du service, telles que la demande. Taille du sac.
Ce qui précède est notre tentative d’affinité.
Sérialisation
En termes de sérialisation, nous faisons encore quelques efforts et tentatives.
Frugal - Backend SSA
Le premier est Frugal. Comme mentionné précédemment, ses performances sont nettement meilleures que celles du code d’encodage et de décodage Thrift traditionnel, mais il peut encore être amélioré.
L'implémentation actuelle de Frugal utilise Go pour générer directement le code assembleur correspondant. Nous avons également appliqué certaines méthodes d'optimisation dans l'implémentation spécifique, telles que la génération de code plus compact, la réduction des branches, etc. Cependant, nous ne pouvons pas utiliser pleinement la technologie d'optimisation du compilateur existante en l'écrivant nous-mêmes.
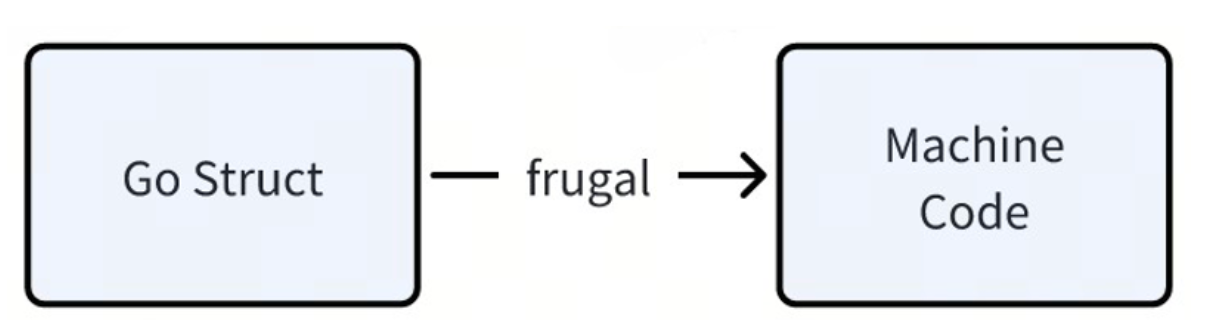
Nous prévoyons de reconstruire Frugal pour générer un LLVM IR (Intermediate Representation) conforme à SSA basé sur la structure go, afin que nous puissions utiliser pleinement les capacités d'optimisation de compilation de LLVM.

On s'attend à ce qu'après cette transformation, les performances puissent être améliorées d'au moins 30 %.
Sérialisation à la demande | Sérialisation à la demande
Une autre direction d’exploration est la sérialisation à la demande, qui peut être divisée en trois parties.
La première est avant la compilation. Nous avons actuellement publié un outil de découpage IDL qui peut identifier les types qui ne sont pas référencés ; cependant, les types référencés peuvent ne pas être nécessaires. Par exemple, deux services A et B dépendent du même type, mais l'un des champs peut être A. Obligatoire, B n’en a pas besoin. Nous envisageons d'ajouter des fonctionnalités d'annotation utilisateur à cet outil, permettant aux utilisateurs de spécifier des champs inutiles, réduisant ainsi davantage les frais de sérialisation.
La seconde est la compilation. L'idée est d'obtenir les champs qui violent réellement la référence du code métier et de les élaguer en fonction du rapport de compilation du compilateur. Le schéma spécifique et l'exactitude nécessitent encore quelques vérifications.
Enfin, après la compilation, au moment de l'exécution, l'entreprise est également autorisée à spécifier des champs inutiles, économisant ainsi les frais d'encodage et de décodage.
Résumé | Résumé
Enfin, passons en revue la situation globale :
En termes de mise à niveau des capacités,
-
Kitex a optimisé les performances des appels de généralisation via DynamicGo, et le codec Frugal hautes performances a été stabilisé et peut être utilisé dans des environnements de production ;
-
Au cours de l'année écoulée, une solution de secours a été ajoutée pour permettre aux entreprises de mettre en œuvre des stratégies de rétrogradation personnalisées, et des champs inconnus et des mécanismes de livraison de sessions ont été utilisés pour résoudre le problème de la transformation des liens longs ;
-
Nous avons également amélioré la convivialité de Kitex grâce à l'optimisation des documents, aux projets de démonstration, à l'amélioration de l'efficacité du dépannage et aux outils de ligne de commande améliorés ;
En termes de coopération communautaire,
-
Nous prenons en charge le protocole hessian2 de Dubbo via le projet d'interopérabilité Kitex-Dubbo, qui peut interopérer avec les frameworks Dubbo Java et Dubbo-Go, et il existe des optimisations ultérieures qui peuvent également renvoyer à la communauté Dubbo ;
-
Dans le projet d'intégration du centre de configuration, nous avons publié l'extension Nacos pour faciliter l'intégration des utilisateurs, et continuons actuellement à promouvoir l'amarrage d'autres centres de configuration ;
Il existe encore quelques pistes d’exploration pour l’avenir.
-
En termes de déploiement fusionné, grâce au déploiement, à la compilation et à la fusion d'affinité, nous pouvons non seulement conserver les avantages des microservices, mais également profiter des avantages de certains monolithes qui ne servent pas de services ;
-
En termes de sérialisation, nous continuons d'optimiser Frugal et d'obtenir des capacités de sérialisation à la demande à travers tous les aspects de la compilation avant, pendant et après la compilation ;
Ce qui précède est la revue et les perspectives de Kitex à l'occasion du deuxième anniversaire de CloudWeGo. J'espère que cela sera utile à tout le monde, merci.
{{o.name}}
{{m.nom}}