

Partager des invités :
Yang Linsan-Huixi Intelligence
À propos de Huixi Intelligence :
Huixi Intelligence est une start-up qui fabrique des puces de conduite autonome, fondée en 2022. Engagé dans la création d'une plate-forme informatique intelligente embarquée innovante, il fournit des puces de conduite intelligente haut de gamme, des chaînes d'outils ouvertes faciles à utiliser et des solutions de conduite autonome complètes pour aider les constructeurs automobiles à réaliser une production de masse de conduite autonome efficace et de haute qualité. et de livraison, et créer des capacités d'itération à faible coût, à grande échelle et automatisées, leader du voyage intelligent haut de gamme à l'ère des données.
Partagez le plan :
- Comment utiliser Alluxio dans une startup ?
- Le processus d'utilisation d'Alluxio de 0 à 1 (recherche-déploiement en production).
- Partage d'expériences pratiques.
Ce qui suit est la version texte intégral du contenu partagé
Partager le sujet :
"Application et déploiement d'Alluxio dans la formation de modèles de conduite autonome"
Boucle fermée de données de conduite autonome
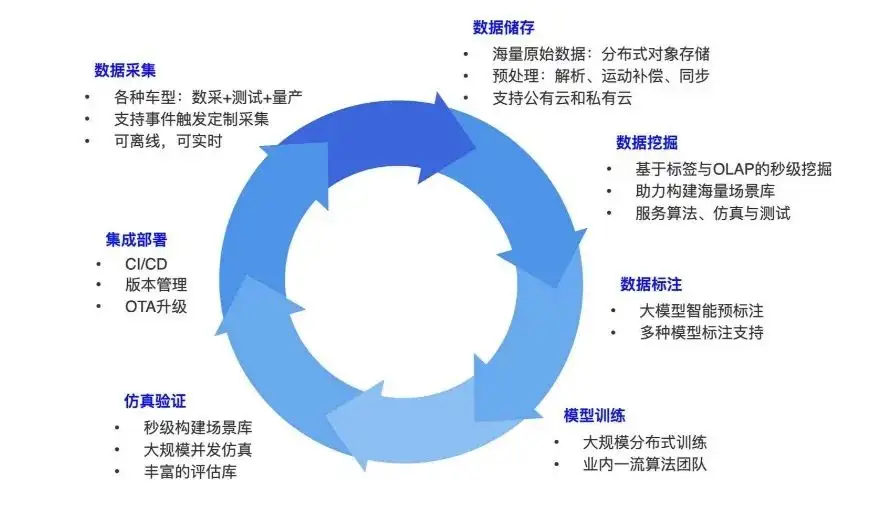
Tout d’abord, permettez-moi de vous expliquer comment créer une boucle fermée de données dans la conduite autonome. Tout le monde connaît peut-être ce processus métier. La conduite autonome inclura une variété de types de véhicules, tels que les véhicules d'exploration de données et les voitures circulant sur la route avec des algorithmes. La collecte de données consiste à collecter diverses données de la voiture autonome pendant le processus de fonctionnement : par exemple, les données de la caméra sont des images et les données du lidar sont des nuages de points.
Lorsque les données des capteurs sont collectées, une voiture peut générer plusieurs téraoctets de données chaque jour. Ce type de données est stocké dans son ensemble via le disque de base ou d'autres méthodes de téléchargement, et transféré vers le stockage objet. Une fois les données originales stockées, il y aura un pipeline pour l'analyse et le prétraitement des données, par exemple en les découpant en trames de données, une trame à la fois, et des opérations de synchronisation et d'alignement pourront être effectuées entre différentes données de capteur dans chaque trame.
Une fois l’analyse des données terminée, il est temps de creuser davantage. Créez des ensembles de données un par un. Car que ce soit en algorithme, en simulation ou en test, un ensemble de données doit être construit. Par exemple, si nous voulons des données sur une certaine nuit, un jour de pluie, à une certaine intersection ou dans certaines zones densément peuplées, nous aurons alors un grand nombre de données requises dans l'ensemble du système et nous devrons étiqueter les données. données et ajoutez quelques étiquettes. Par exemple, à la porte est de l’université Tsinghua, vous devez obtenir la longitude et la latitude de cet emplacement et analyser les POI environnants. Étiquetez ensuite les données extraites. Les annotations courantes incluent : les objets, les piétons, les types d'objets, etc.
Ces données étiquetées seront utilisées pour la formation. Les tâches typiques incluent la détection de cibles, la détection de lignes de voie ou des modèles de bout en bout plus grands. Une fois le modèle entraîné, une vérification par simulation doit être effectuée. Après vérification, déployez-le sur la voiture, exécutez les données et collectez davantage de données sur cette base. Il s’agit d’un tel cycle, enrichissant constamment les données et construisant constamment des modèles plus performants. C’est ce que doit faire l’ensemble de la boucle fermée de formation et de données, et c’est également l’élément central de la recherche et du développement actuel sur la conduite autonome.
Formation à l'algorithme : NAS
Nous nous concentrons sur la formation de modèles : la formation de modèles obtient principalement des données grâce à l'exploration de données pour générer un ensemble de données. L'ensemble de données est en interne un fichier pkl, comprenant les données, le canal et l'emplacement de stockage. Enfin, les étudiants qui s'entraînent aux algorithmes de données écriront leurs propres scripts de téléchargement pour extraire les données du stockage d'objets vers le local.
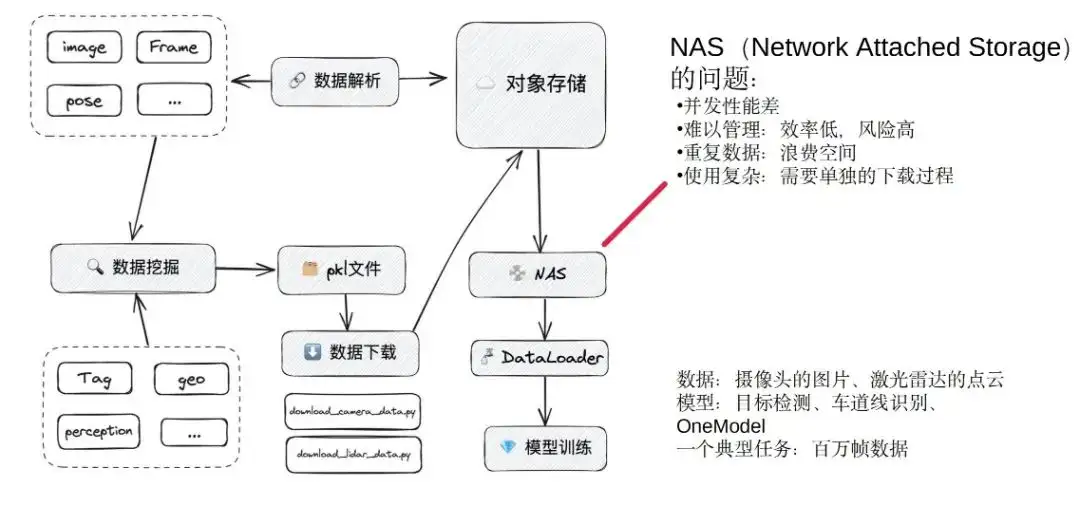
Avant de choisir Alluxio, nous utilisions le système NAS pour agir comme un cache, extrayant les données de stockage d'objets vers le NAS et enfin utilisant différents modèles pour charger les données à des fins de formation. Il s'agit du processus de formation approximatif avant d'utiliser Alluxio.
L'un des plus gros problèmes du NAS :
- Les performances de concurrence sont relativement médiocres : nous pouvons comprendre le NAS comme un grand disque dur, ce qui est tout à fait suffisant lorsque seules quelques tâches s'exécutent ensemble. Cependant, lorsque des dizaines de tâches de formation sont effectuées simultanément et que de nombreux modèles sont formés, des blocages se produisent souvent. Il fut un temps où nous étions très bloqués et l’équipe R&D se plaignait tous les jours. Il est tellement bloqué que les performances de disponibilité et de concurrence sont très mauvaises.
- Difficulté de gestion - chacun utilise son propre script téléchargé, puis télécharge les données souhaitées dans son propre répertoire. Une autre personne peut télécharger elle-même une autre pile de données et la placer dans un autre répertoire du NAS. Cela rendra difficile le nettoyage lorsque l'espace du NAS est plein. À cette époque, nous communiquions essentiellement en personne ou dans des groupes WeChat. D'une part, l'efficacité est extrêmement faible et le recours à la gestion des messages de groupe sera à la traîne. D’un autre côté, la suppression manuelle peut également entraîner certains risques. Nous avons eu des situations où les ensembles de données d'autres personnes étaient supprimés lors de la suppression des données. Cela entraînera également des erreurs dans la zone de tâches en ligne, ce qui constitue un autre problème.
- Gaspillage d'espace - Les données téléchargées par différentes personnes sont placées dans des répertoires différents. Il est possible que la même trame de données apparaisse dans plusieurs ensembles de données, ce qui entraîne une grave perte d'espace.
- C'est très compliqué à utiliser - car les formats de fichiers dans pkl sont différents, la logique de téléchargement est également différente et chacun doit écrire le programme de téléchargement séparément.
Voici quelques-unes des difficultés et des problèmes auxquels nous avons été confrontés lors de l'utilisation du NAS auparavant. Afin de résoudre ces problèmes, nous avons effectué des recherches. Après recherches, nous nous sommes concentrés sur Alluxio. J'ai trouvé qu'Alluxio peut fournir un cache relativement unifié. Le cache peut améliorer notre vitesse de formation et réduire les coûts de gestion. Nous utiliserons également le système Alluxio pour résoudre le problème des salles informatiques doubles. Grâce à un espace de noms et à des méthodes d'accès unifiés, d'une part, la conception de notre système peut être simplifiée et, d'autre part, la mise en œuvre du code deviendra également très simple.
Formation aux algorithmes introduite dans Alluxio
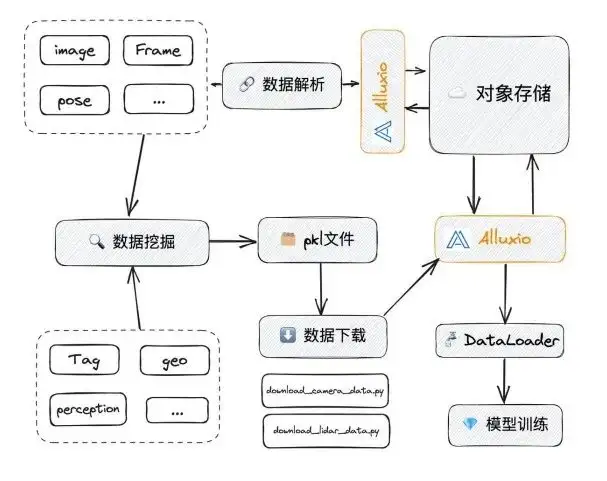
Lorsque nous remplaçons le NAS par Alluxio, Alluxio peut résoudre spécifiquement certains des problèmes que nous venons de mentionner :
- En termes de concurrence : le NAS lui-même n'est pas un système entièrement distribué, mais Alluxio l'est. Lorsque les E/S accédées par le NAS atteignent une certaine vitesse, elles se bloquent lorsqu'elles atteignent plusieurs G/s. La limite supérieure d'Alluxio est très élevée. Nous avons ci-dessous des tests spéciaux pour illustrer ce point.
- Le nettoyage ou la gestion manuelle sera très gênante : Alluixo configure la politique d'éviction du cache. Habituellement via LRU, lorsqu'il atteint un seuil (tel que 90 %), il expulse et nettoie automatiquement le cache. L'effet de ceci:
- L'efficacité est grandement améliorée ;
- Cela peut éviter les problèmes de sécurité causés par une suppression accidentelle ;
- Résolution du problème des données en double.
Dans Alluxio, un fichier dans UFS correspond à un chemin dans Alluxio. Lorsque tout le monde accède à ce chemin, il peut obtenir les données correspondantes, afin qu'il n'y ait pas de problème de données en double. De plus, l'utilisation de ce qui précède est relativement simple. Il suffit d'y accéder via l'interface FUSE et de ne plus télécharger de fichiers.
Ce qui précède résout les différents problèmes dont nous venons de parler d’un niveau logique. Parlons de l'ensemble de notre processus de mise en œuvre, de la façon de réaliser Alluxio de 0 à 1, depuis les tests POC initiaux, jusqu'à la vérification des diverses performances, jusqu'au déploiement final, à l'exploitation et à la maintenance. Quelques-unes de nos expériences pratiques.
Déploiement Alluxio : salle informatique unique
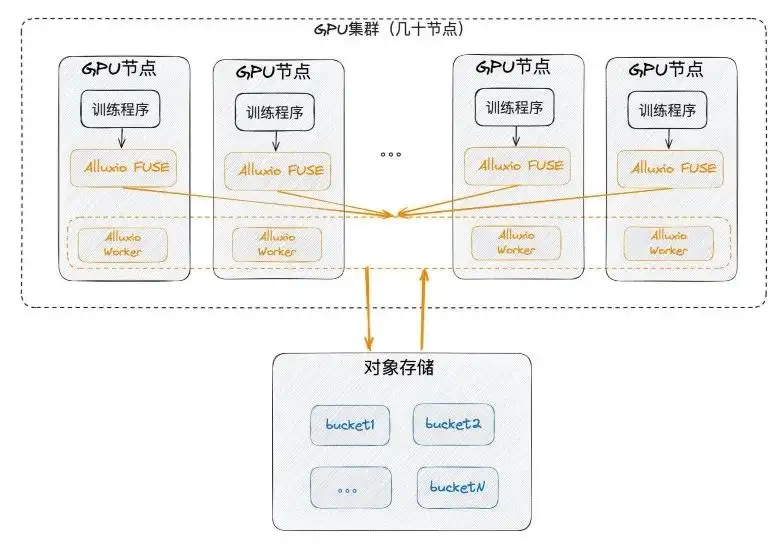
Tout d'abord, nous pouvons le déployer dans une seule salle informatique, ce qui signifie qu'il doit être proche du GPU et déployé sur le nœud GPU. Dans le même temps, le SSD, qui était rarement utilisé sur le GPU auparavant, a été utilisé pour utiliser chaque nœud, puis FUSE et les travailleurs ont été déployés ensemble. FUSE est équivalent au client et le travailleur est équivalent à un petit cluster de cache avec communication intranet pour fournir les services FUSE. Enfin, le travailleur communique avec le stockage d'objets sous-jacent lui-même.
Déploiement Alluxio : dans les salles informatiques
Mais pour diverses raisons, nous aurons toujours des salles inter-machines. Il existe désormais deux salles informatiques, et chaque salle informatique disposera des services S3 correspondants et des nœuds informatiques GPU correspondants. En gros, nous déploierons un Alluxio dans chaque salle informatique. Dans le même temps, nous devons également prêter attention à ce processus. Il peut y avoir deux magasins d'objets Alluxio dans une salle informatique. Si une autre salle informatique doit également monter S3, essayez d'établir un plan unifié pour les noms de compartiment, et ne le faites pas. surcharger les deux. Par exemple, s'il y a le bucket 1 ici et le bucket 1 là, cela posera des problèmes lors du montage d'Alluxio.
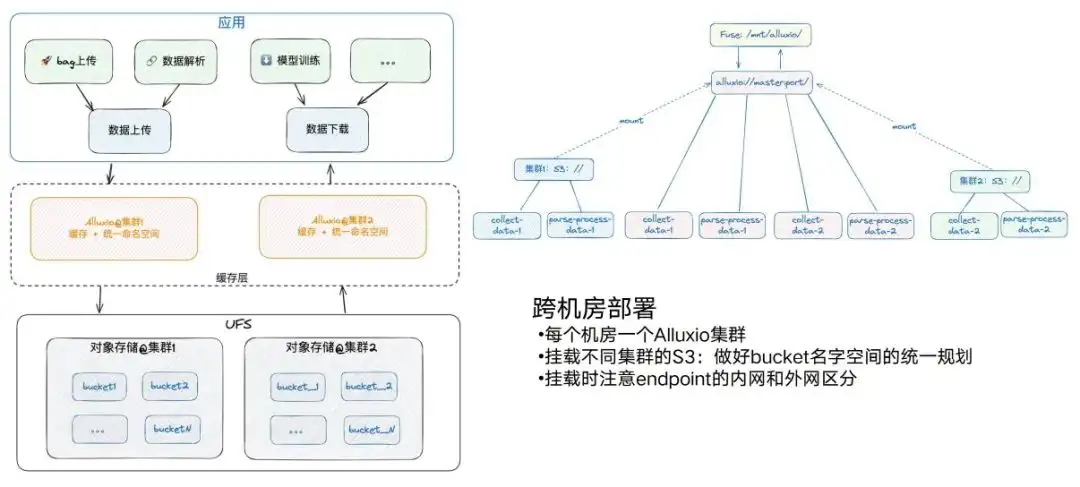
Notez également que pour les différents points de terminaison, faites attention à la distinction entre le réseau interne et le réseau externe. Par exemple, Alluxio du cluster 1 monte le réseau interne du point de terminaison du cluster 1, et le réseau externe est de l'autre côté. , les performances seront considérablement réduites. Après le montage, nous pouvons accéder aux données de différents buckets sur différents clusters via le même chemin, de sorte que l'ensemble de l'architecture deviendra très simple en termes de déploiement entre salles de machines.
Test Alluxio : fonctionnalité
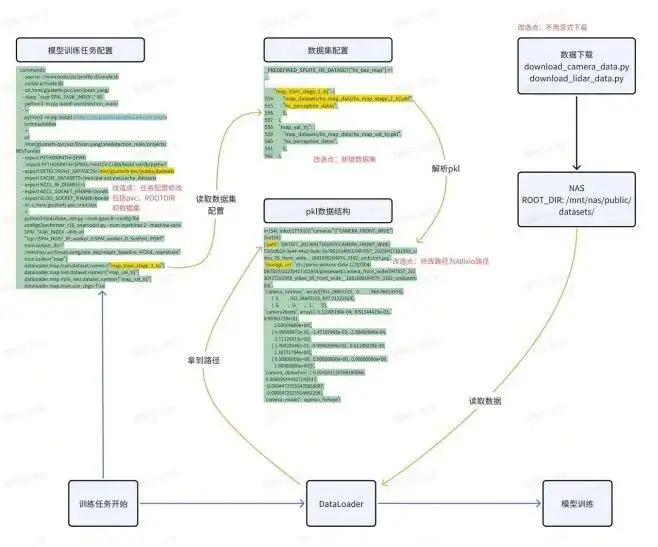
Si vous souhaitez véritablement remplacer votre NAS par Alluxio, vous devez effectuer de nombreux tests fonctionnels avant le déploiement. Le but de ce type de tests fonctionnels est de modifier le processus algorithmique existant de manière minimale afin que les étudiants en algorithme puissent également l'utiliser. Cela peut dépendre de votre situation réelle. Nous avons effectué près de 2-3 semaines de vérification POC avec Alluxio, qui impliquaient, par exemple :
- Configuration de l'accès au PVC sur K8S ;
- Comment l'ensemble de données est organisé ;
- Configuration de la soumission des travaux ;
- Remplacement des chemins d'accès ;
- L'interface de script finalement accessible.
De nombreux problèmes rencontrés ci-dessus devront peut-être être vérifiés. Au moins, nous devons sélectionner une tâche typique, puis apporter quelques modifications et enfin remplacer le NAS par Alluxio de manière relativement fluide.
Test Alluxio : performances
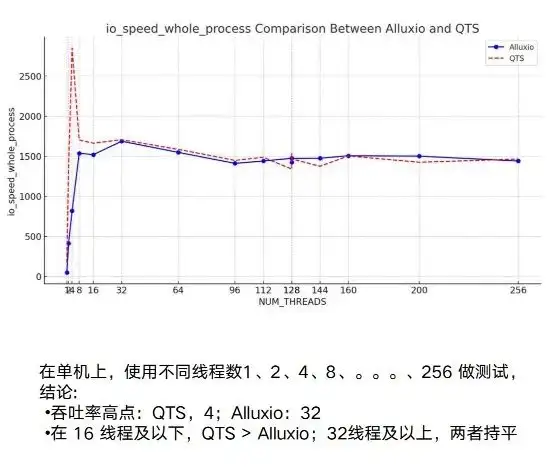
Ensuite, sur cette base, des tests de performances seront effectués. Dans ce processus, nous avons effectué des tests relativement suffisants, qu'il s'agisse d'une seule machine ou de plusieurs machines. Sur une seule machine, les performances d'Alluxio et du NAS d'origine sont fondamentalement les mêmes.
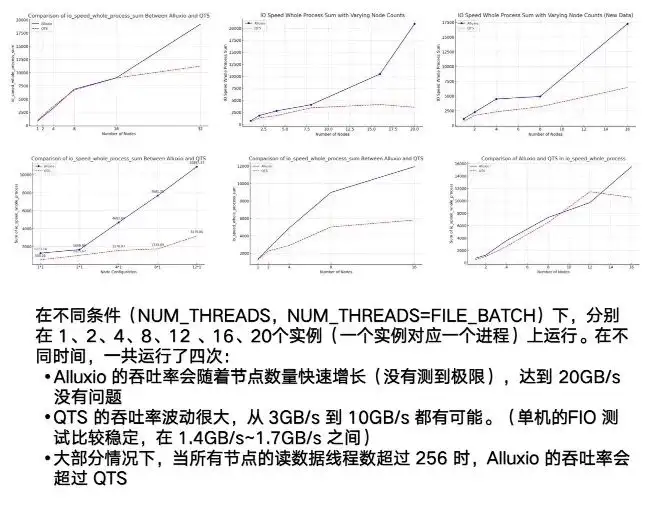
En fait, ce qui incarne véritablement les avantages d’Alluxio, ce sont ses capacités multi-hôtes et distribuées. Vous pouvez voir NAS ou notre exemple de QTS, qui a un point très évident : l'instabilité. La fluctuation entre les tests 3G et 10G sera relativement importante. En même temps, elle présente un goulot d'étranglement évident. Lorsqu'elle atteint environ 7/8G, elle est fondamentalement stable.
En fait, ce qui incarne véritablement les avantages d’Alluxio, ce sont ses capacités multi-hôtes et distribuées. Vous pouvez voir NAS ou notre exemple de QTS, qui a un point très évident : l'instabilité. La fluctuation entre les tests 3G et 10G sera relativement importante. En même temps, elle présente un goulot d'étranglement évident. Lorsqu'elle atteint environ 7/8G, elle est fondamentalement stable.
Quant à Alluxio, pendant tout le processus de test, à mesure que le nombre d'instances en cours d'exécution augmente, le nœud peut atteindre une limite supérieure très élevée. Lorsque nous l'avons fixé à 20 Go/s, il a toujours montré une tendance à la hausse. Cela montre que les performances globales simultanées et distribuées d'Alluxio sont très bonnes.
Atterrissage Alluxio : réglage des paramètres et adaptation de l'environnement
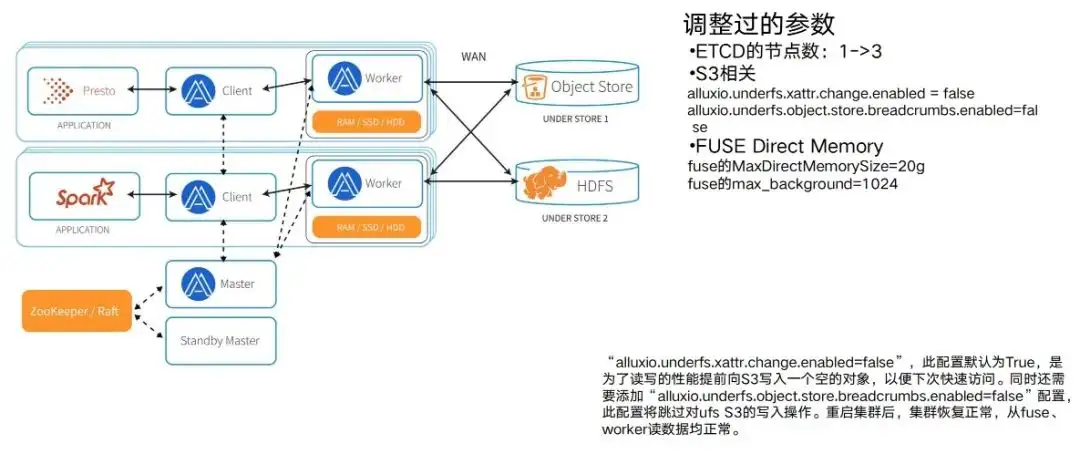
Après avoir terminé la vérification fonctionnelle et les tests de performances, il est temps de déployer réellement le cluster Alluxio. Après le déploiement, un processus d'ajustement et d'adaptation des paramètres est nécessaire. Parce que lors du test, seules quelques tâches typiques ont été utilisées. Après avoir réellement utilisé l'environnement Alluxio, vous constaterez qu'à mesure que les tâches augmentent, il y aura un processus d'ajustement et d'adaptation des paramètres. Il est nécessaire de faire correspondre les paramètres correspondants sur Alluxio avec l'environnement d'exploitation réel avant que ses performances puissent être pleinement utilisées. Par conséquent, il y aura un processus de fonctionnement, d’exploitation, de maintenance et d’ajustement des paramètres.
Nous avons suivi certains processus typiques d'ajustement des paramètres, tels que :
- Les nœuds d'ETCD sont répertoriés ici. Il vaut 1 au début, puis passe à 3. Cela garantit que c'est un ETCD qui est raccroché et que l'ensemble du cluster n'est pas raccroché.
- Il existe également des fichiers liés au S3. Par exemple, lorsqu'Alluxio sera implémenté, il permettra à S3 de générer un chemin d'accès relativement long et d'écrire des espaces par défaut dans les nœuds du chemin intermédiaire pour lui donner de meilleures performances. Mais dans ce cas, le S3 sous notre tâche de formation a un contrôle d'autorisation et ils ne sont pas autorisés à écrire ce type de données. Face à ce genre de conflit, un ajustement des paramètres est également nécessaire.
- Il existe également des fonctionnalités telles que l'intensité de concurrence que le nœud FUSE lui-même peut tolérer. Y compris la taille de la mémoire directe utilisée, cela a en fait beaucoup à voir avec l'intensité de concurrence réelle de l'ensemble de l'entreprise. En fait, cela a beaucoup à voir avec la quantité de données accessibles en même temps. Il existe également un processus d'ajustement des paramètres, etc. Différents problèmes peuvent être rencontrés dans différents environnements. C'est aussi la raison pour laquelle choisir Alluxio Enterprise Edition. Étant donné qu'Alluxio bénéficiera d'un support très important pendant la version entreprise, il peut s'adapter et coopérer en cas de problèmes 24h/24 et 7j/7. Ce n'est qu'avec des cycles mutuellement coordonnés que l'ensemble du cluster peut fonctionner plus facilement.
Implémentation Alluxio : exploitation et maintenance
Le premier camarade de classe en matière d'exploitation et de maintenance de notre équipe n'avait qu'une seule personne, qui était responsable d'une grande partie de la maintenance Infra sous-jacente et des travaux associés. Lorsque j'ai voulu déployer Alluxio, les ressources du côté de l'exploitation et de la maintenance n'étaient en fait pas suffisantes, c'était donc équivalent. pour moi, je fais également un travail à temps partiel. Du point de vue de l’exploitation et de la maintenance de quelque chose vous-même, il est important de conserver de nombreux enregistrements et connaissances sur l’exploitation et la maintenance, en particulier pour un novice. Par exemple, comment mieux résoudre le problème la prochaine fois et si vous avez déjà vécu une telle expérience.
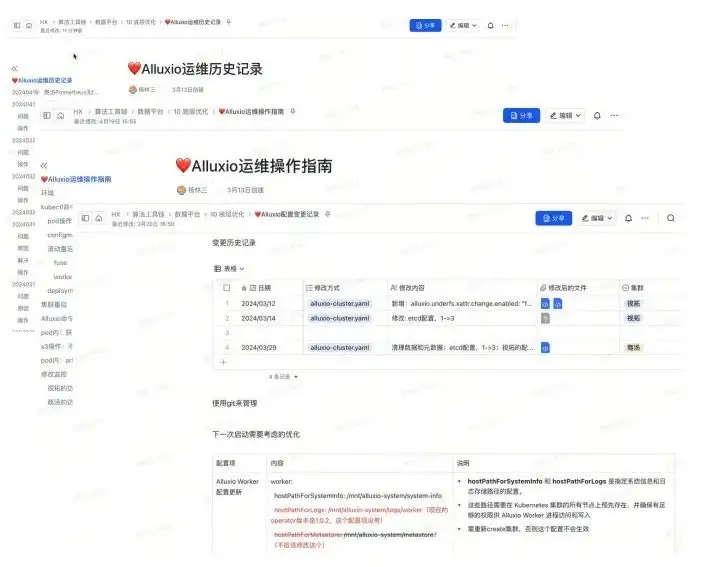
En fonction de notre environnement à cette époque, trois documents seront conservés.
- Documents d'historique d'exploitation et de maintenance : Par exemple, quels problèmes sont survenus quel jour ? Quelle est la cause profonde de ces problèmes et quelle est leur solution ? Quelles sont les opérations spécifiques ?
- Documentation d'exploitation : Par exemple, si nous exploitons et entretenons K8S, quelles sont les étapes pour le redémarrer, quelles sont les opérations, comment lire les journaux en cas de problèmes, comment dépanner et quelle tâche et quel travail doivent être exécutés pour voir les données correspondant à FUSE , surveillance, etc. Ce sont quelques opérations couramment utilisées.
- Modifications de configuration : Parce qu'Alluxio est en train d'ajuster les paramètres. À différents moments, vous pouvez rencontrer différents fichiers de configuration et fichiers yaml, et vous devrez peut-être effectuer des sauvegardes. Vous pouvez utiliser Git pour le gérer, ou vous pouvez simplement utiliser la gestion de documents. De cette façon, il est possible de remonter à la configuration actuelle et aux versions de configuration historiques.
Sur cette base, nous aurons également des constructions de support associées pour mieux utiliser Alluxio. Les étudiants en R&D pensent qu’Alluxio est assez simple à utiliser après l’avoir utilisé. Mais lorsque l’on effectue plusieurs tâches, certains besoins de construction sont révélés. Par exemple, nous devons redimensionner l'image et la réduire de 4K haute définition à 720P pour prendre en charge davantage de mise en cache des tâches.
L'ensemble de données d'entraînement est synchronisé entre les clusters pour un meilleur préchargement des données. Tout cela est centré sur la construction systématique qu’Alluxio doit faire.
Atterrissage Alluxio : progresser ensemble
Au fur et à mesure que nous continuons à utiliser Alluxio, nous trouverons également certains domaines méritant d'être améliorés. En donnant des commentaires à Alluxio, nous avons favorisé l'itération de l'ensemble du produit. Voici quelques points en particulier :
Parmi les étudiants qui développent des algorithmes, ce qui les intéresse, c'est :
- Stabilité : Il doit être stable pendant le fonctionnement. Il ne peut pas gêner la formation de l'ensemble du système à cause d'un crash dans Alluxio. Il peut y avoir ici quelques conseils d'utilisation et de maintenance, comme essayer de ne pas redémarrer FUSE autant que possible. Comme mentionné tout à l'heure, le redémarrage de FUSE signifie que son chemin d'accès échouera et qu'une erreur IO se produira lors de la lecture des fichiers de données.
- Déterminisme : par exemple, Alluxio a précédemment suggéré que les données n'ont pas besoin d'être préchargées, c'est-à-dire qu'elles n'ont pas besoin d'être lues une fois avant le pré-entraînement, mais seulement une fois au cours de la première époque. Cependant, comme R&D a un cycle de publication, il a besoin de savoir exactement combien de temps il faudra pour le précharger. S'il le lit jusqu'à la première époque, il est difficile d'estimer la durée totale de la formation. Cela s'étend également à la manière de mettre en cache une liste de fichiers. Cela impose également certaines exigences à Alluxio.
- Contrôlabilité : bien qu'Alluxio puisse fournir une expulsion et un nettoyage automatisés du cache basés sur LRU. Mais en fait, R&D espère toujours que certaines données mises en cache pourront être nettoyées de manière proactive. Alors pouvez-vous également laisser Alluxio libérer ces données en fournissant une liste de fichiers ? C'est aussi notre besoin d'utiliser Alluxio directement et de manière très contrôlable en plus de l'utilisation indirecte.
Du côté de l’exploitation et de la maintenance, certaines exigences seront également soulevées :
- Centre de configuration : Alluxio lui-même peut fournir un centre de configuration pour sauvegarder l'historique de configuration. Lorsque vous ajoutez une fonction pour implémenter des modifications aux éléments de configuration, budgétisez à l'avance l'impact de cette modification ;
- Trace suit le processus d'exécution d'une commande : Autre exigence plus réaliste. Par exemple, nous trouvons maintenant un problème : le délai d'accès à un fichier UFS en bas est relativement élevé. Quelle en est la raison ? Nous ne pourrons peut-être pas voir la raison en consultant les journaux FUSE, nous devons donc consulter les journaux des travailleurs correspondant à l'emplacement. Il s'agit en fait d'un processus très long et fastidieux, et le problème ne peut souvent pas être résolu, nécessitant le service client en ligne d'Alluxio. Alluxio peut-il ajouter une commande Trace pour tracer les problèmes fastidieux de FUSE, de travail et de lecture à partir d'UFS lors de l'accès à l'intégralité du lien ? Cela sera en fait d’une grande aide pour l’ensemble du processus d’exploitation et de maintenance ou pour le processus de dépannage.
- Surveillance intelligente : Parfois, les éléments que nous surveillons sont des éléments que nous connaissons déjà. Par exemple, s'il y a un problème avec Direct Memory, configurons un élément de surveillance. Mais la prochaine fois qu’un nouveau problème apparaîtra dans mon journal, il s’agira peut-être d’un problème caché qui se produira discrètement sans que personne ne le sache. Nous espérons surveiller automatiquement cette situation.
Nous avons fait diverses suggestions à Alluxio grâce aux commentaires sur les bons de travail. On espère qu'Alluxio pourra fournir des fonctions plus puissantes pendant le processus d'itération du produit. Rendre l'ensemble des questions de R&D, d'exploitation et de maintenance plus satisfaisantes.
résumé
Premièrement, Alluxio offre une très bonne convivialité par rapport au NAS en termes d'accélération de la mise en cache pour l'ensemble de la formation du modèle de conduite autonome. Pour nous, il s’agira également d’une amélioration d’environ 10 fois. La réduction des coûts vient de deux parties :
- Le coût d'approvisionnement du produit est faible ;
- Le NAS peut avoir 20 à 30 % de stockage redondant, ce qu'Alluxio peut résoudre.
Du point de vue de la maintenabilité, il peut nettoyer automatiquement les données, ce qui est plus rapide et plus sûr. En termes de facilité d'utilisation, il peut accéder plus facilement aux données via FUSE.
Deuxièmement, j'ai également expliqué comment Huixi déploie Alluxio de 0 à 1 et exploite et entretient un système.
Ce qui précède est mon partage, merci à tous.
