

Cet article présente principalement les technologies connexes de l'IA générative, en particulier l'application du réseau neuronal convolutif (CNN) dans le domaine de la reconnaissance d'images. Cet article est le deuxième de la série,

Si vous comprenez l’introduction aux réseaux de neurones et à l’apprentissage profond dans l’article précédent, il devrait être relativement facile d’acquérir progressivement une compréhension plus approfondie des concepts et principes liés à l’IA.
J'espère que le dernier article pourra donner une impression à tout le monde : l'IA n'est pas aussi compliquée qu'on le pense. L’IA peut traiter d’énormes quantités d’informations, mais elle ne dispose pas d’un mécanisme extrêmement complexe difficile à comprendre pour les humains. Car ce n'est que si le mécanisme est relativement simple que moins d'énergie peut être consommée, la vitesse de calcul peut être rapide et plus d'informations peuvent être traitées. Il en va de même dans la nature. Si le mécanisme du cerveau était plus compliqué qu’il ne l’est aujourd’hui, le cerveau serait probablement épuisé.
Sans plus tarder, nous avons vu dans le dernier article que le réseau neuronal le plus basique peut être utilisé en même temps pour reconnaître des chiffres manuscrits, nous avons également constaté que si le réseau neuronal n'« apprend » pas bien et n'a pas une compréhension abstraite ; Selon les lois générales du problème, des problèmes surgiront. Le surapprentissage est souvent lié à deux facteurs : les données et le modèle. Dans cet article, nous parlerons de l'expérience dans le domaine de la reconnaissance d'images pour faire face au surapprentissage, et expliquerons également comment les réseaux de neurones et l'apprentissage profond peuvent être étendus à d'autres domaines tels que le traitement du langage naturel.

Comme mentionné ci-dessus, les réseaux de neurones peuvent être utilisés pour la reconnaissance d'images. Puisqu’il s’agit de reconnaissance d’images, peut-on combiner les méthodes connues de l’infographie pour améliorer l’effet du deep learning ? La réponse est oui. Le réseau neuronal convolutif est un tel réseau qui optimise considérablement l'effet et l'efficacité de la reconnaissance d'images en combinant des méthodes graphiques.
▐Principe du réseau neuronal convolutif
-
Fonctionnalités de capture - opération de convolution (convolution) : la couche de convolution scanne l'intégralité de l'image pour mettre en valeur les caractéristiques de base telles que les bords et la texture de l'objet à travers un filtre similaire à celui du traitement d'image. Cela peut être considéré comme l'étape consistant à « tracer des lignes » pour capturer des caractéristiques locales dans l'image en vue d'une reconnaissance ultérieure. -
Simplifier et mettre en valeur - Pooling : après les fonctionnalités extraites par convolution, la couche de pooling permet de réduire la taille des données de fonctionnalités, ce qui simplifie simultanément la complexité de l'image et les exigences de calcul. La mise en commun des couches revient à omettre délibérément certains des détails les moins importants d'un tableau afin de mettre en valeur les contours et la structure globale. -
Répétez ce processus pour augmenter le niveau d'abstraction : les réseaux de neurones convolutifs ont souvent plus d'une opération de convolution et de pooling. Grâce à une série de circonvolutions et de regroupements répétés, le réseau filtre et combine progressivement des caractéristiques simples en formes et motifs plus complexes, semblable au processus des enfants qui dessinent des lignes aux formes pour compléter des personnages. -
Synthèse des fonctionnalités - couche entièrement connectée : tout comme les enfants finiront par placer la tête, le corps et les membres dans la position appropriée pour compléter l'image d'une personne, le réseau neuronal convolutif utilise des couches entièrement connectées basées sur les caractéristiques abstraites à plusieurs niveaux. travaux de consolidation et de classement. La couche entièrement connectée prend en compte l'ensemble des caractéristiques au niveau de l'image et apprend les relations complexes entre elles pour compléter le processus depuis les caractéristiques jusqu'à la reconnaissance finale de la cible (telle que l'identification de la personne sur l'image). Tout le monde connaît la couche de liaison complète, qui est le réseau neuronal composé de la couche dense mentionnée ci-dessus.
-
Après plusieurs séries d'opérations de convolution, les objets qui doivent être traités par la couche suivante entièrement connectée (la même que le réseau neuronal mentionné ci-dessus) sont passés de pixels et de couleurs sans « sémantique réaliste » évidente à des bords, des contours, des textures, etc. qui ont certaines fonctionnalités de « sémantique réaliste », ce qui améliore considérablement la précision de la reconnaissance d'images. -
L'opération de convolution augmente d'un niveau la plus petite unité à traiter par la couche entièrement connectée (c'est comme si vous n'écriviez pas d'instructions ligne par ligne lors de l'écriture du code, mais utilisiez des chaînes pour organiser les capacités atomiques). L'opération de pooling est également relativement réduite au traitement des images, ces deux-là peuvent théoriquement améliorer l'efficacité (par rapport à d'autres méthodes de précision similaire).
▐Les moyens graphiques dans les réseaux de neurones convolutifs – filtres
Alors, quel type de méthode graphique le réseau de neurones convolutifs combine-t-il ? Nous pouvons examiner le noyau de convolution (noyau) dans le réseau neuronal convolutif, appelé filtre en graphique. Les étudiants familiers avec Photoshop ou GIMP doivent connaître, par exemple, les quatre filtres suivants (vecteur 3x3 sur l'image) :
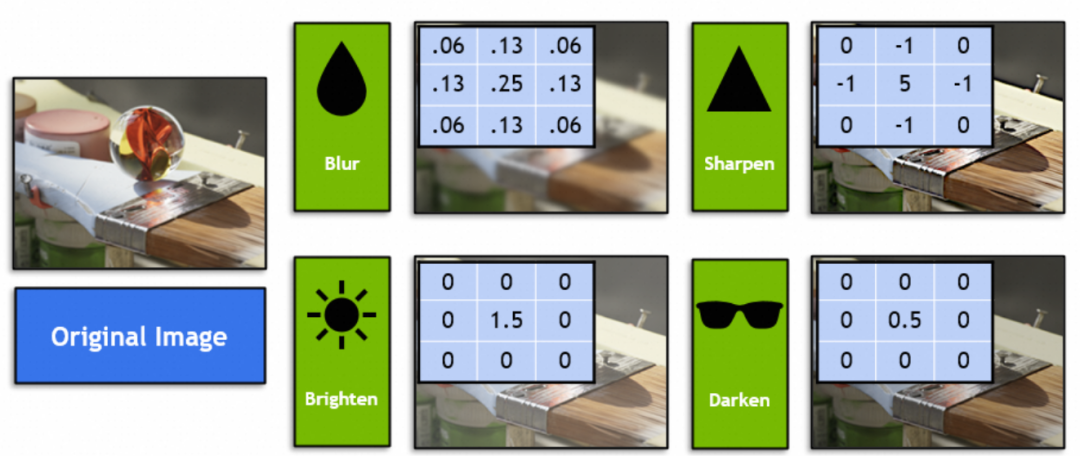
En mathématiques, les filtres sont des opérations vectorielles d'algèbre linéaire : chaque vecteur 3x3 de l'image originale est multiplié et additionné par le vecteur 3x3 du filtre. Par exemple, ce vecteur de filtre dans l'image obtient un flou en mélangeant 9 pixels adjacents au point central :
Données empiriques : dans les réseaux de neurones convolutifs, le choix d'un noyau de convolution de taille 3x3 peut obtenir de bons résultats.
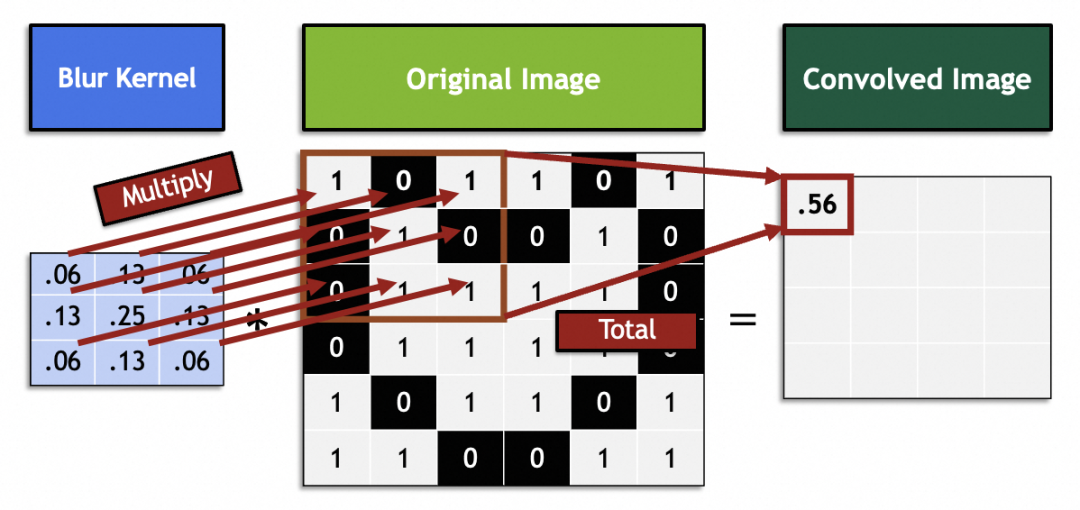
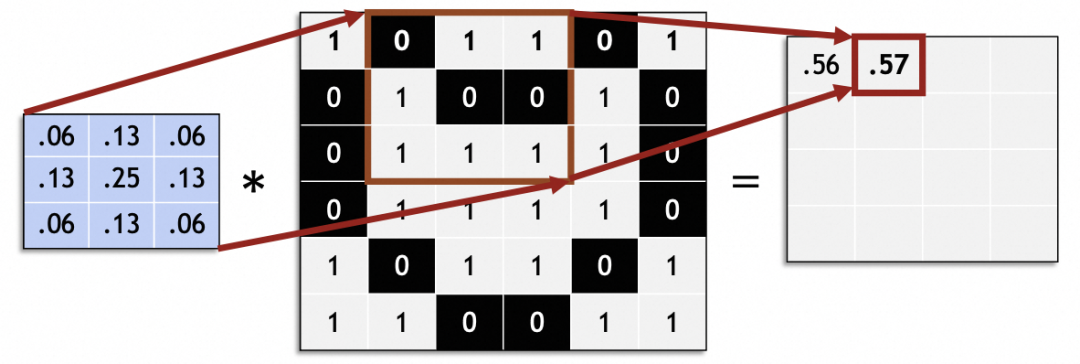
Traitez l'intégralité de l'image originale en la faisant glisser et générez une nouvelle image :
Dans un réseau neuronal convolutif, la taille du pas glissant (foulée) est généralement de 1. Des valeurs autres que 1 peuvent causer des problèmes tels que la taille de l'image originale ne peut pas être divisée uniformément par la foulée.
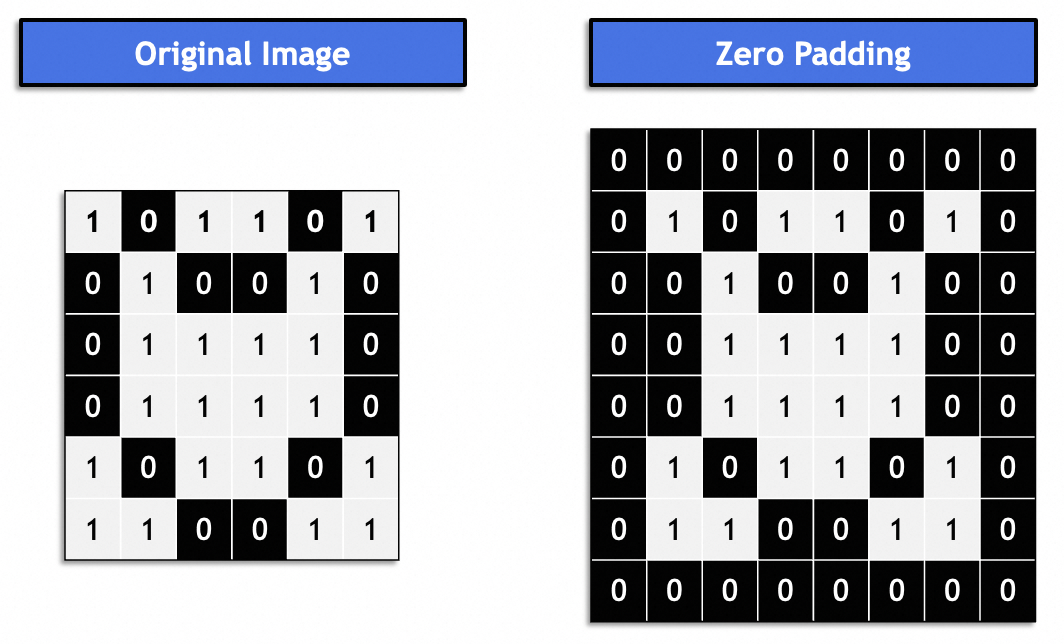
Généralement, il s'agit du "même remplissage" et l'image résultante reste cohérente avec l'image d'origine. Généralement rempli de 0.
Alors, quel problème les noyaux de convolution ou les filtres sont-ils utilisés pour résoudre ? Nous pouvons jeter un œil aux noyaux de convolution ci-dessous. Ils utilisent des valeurs vectorielles spécifiques pour améliorer les bords verticaux et horizontaux de l'image originale. Comme le montre la figure, le noyau de convolution peut en effet être utilisé pour extraire des fonctionnalités de l'image originale :

Enfin, comment les filtres graphiques sont-ils appliqués aux réseaux de neurones ?
Tout d'abord, le vecteur du noyau de convolution et le vecteur d'image d'origine sont multipliés et additionnés (réactivés), ce qui est similaire aux paramètres neuronaux et à l'entrée multipliée, additionnée et réactivée. Le noyau de convolution peut être exprimé par les neurones du réseau neuronal.
Deuxièmement, contrairement aux valeurs vectorielles connues des filtres de flou, de netteté et de bord horizontal et vertical données ci-dessus, les valeurs vectorielles du noyau de convolution peuvent être entraînées et entraînées et sont utilisées pour capturer dynamiquement les caractéristiques d'entrée et les paramètres des neurones. L'usage est cohérent.
En fait, un noyau de convolution est un neurone dans la couche de convolution. Semblable aux neurones de couche entièrement connectés, ses paramètres sont également des poids d'entrée + des constantes de biais, où le nombre de poids d'entrée est égal au nombre d'entrées. Parce que les images d'entrée sont des images empilées, le nombre de poids d'entrée est x * y * n, La constante de biais. est fixé à 1, et il y en a x * y * n + 11 au total. Comme le montre l'image de ce noyau 3x3 à 2 piles, son nombre de paramètres est de 3 * 3 * 2 + 1 = 19.
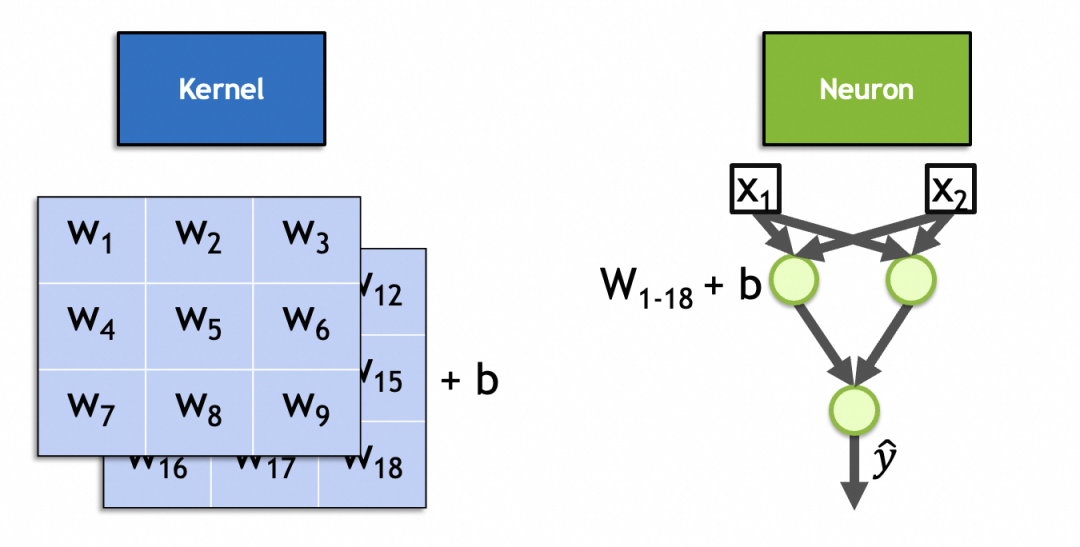
▐Processus de calcul du réseau neuronal convolutif
Le calcul du réseau neuronal convolutif est le même que celui du réseau neuronal précédent, propagation vers l'avant et propagation vers l'arrière, qui ne sera pas décrit en détail.
Dans l'image ci-dessous, l'image d'entrée est l'image d'entrée, taille 28x28, 1 pile (1 couche de niveaux de gris) ; notez que les images empilées ne sont pas des couches de réseau, mais la sortie de la couche convolutive ; des images d'image, qui sont aplaties en un tableau unidimensionnel (vecteur d'image aplati sur la figure) à travers la couche d'aplatissement pour être utilisées par le réseau de couches entièrement connecté suivant (la couche entièrement connectée a été discutée ci-dessus).
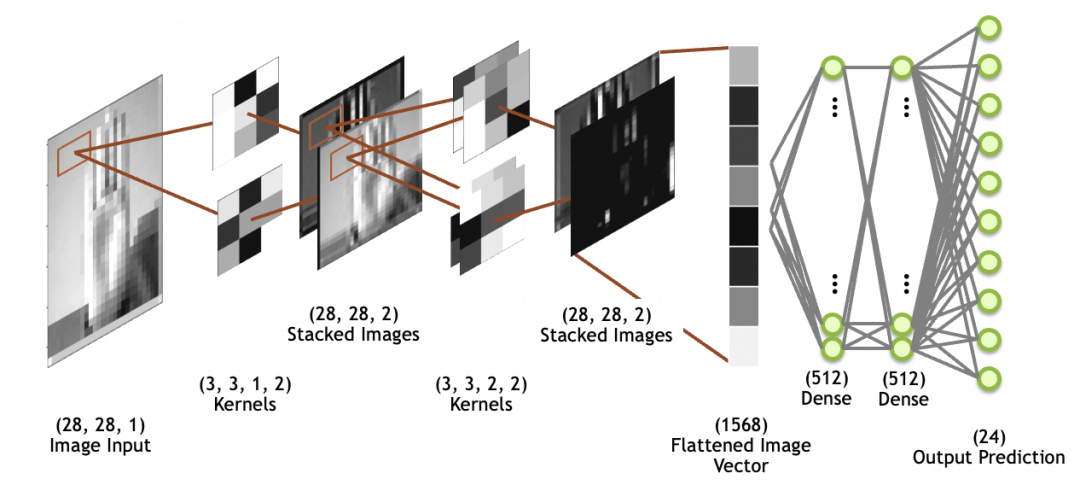
convolution
Notez que contrairement à la sortie neuronale de la couche entièrement connectée (Dense), qui est une valeur numérique, le neurone du noyau de convolution est à chaque fois multiplié et activé pour obtenir un nombre. En combinant les deux directions et en glissant continuellement, une carte bidimensionnelle peut enfin être obtenue. être obtenu.
输入是
x * y * N
的堆叠图像。其中,x=28,y=28(
28 * 28 * N
)。卷积层每个神经元因为要和输入相乘,所以也是N叠,假设神经元采用
3 * 3
大小,则每个神经元是
3 * 3 * N
。输出经过padding,每叠大小和输入保持一致,
28 * 28
。输出堆叠图像的每一叠为输入堆叠图像x单个神经元的结果,所以叠数和卷积层神经元个数一致。假设卷积层有M个神经元,则输出堆叠图像为
28 * 28 * M
。这里强调一下,卷积层每个神经元的叠数=输入图像的叠数。输出图像的叠数=卷积层神经元的个数。
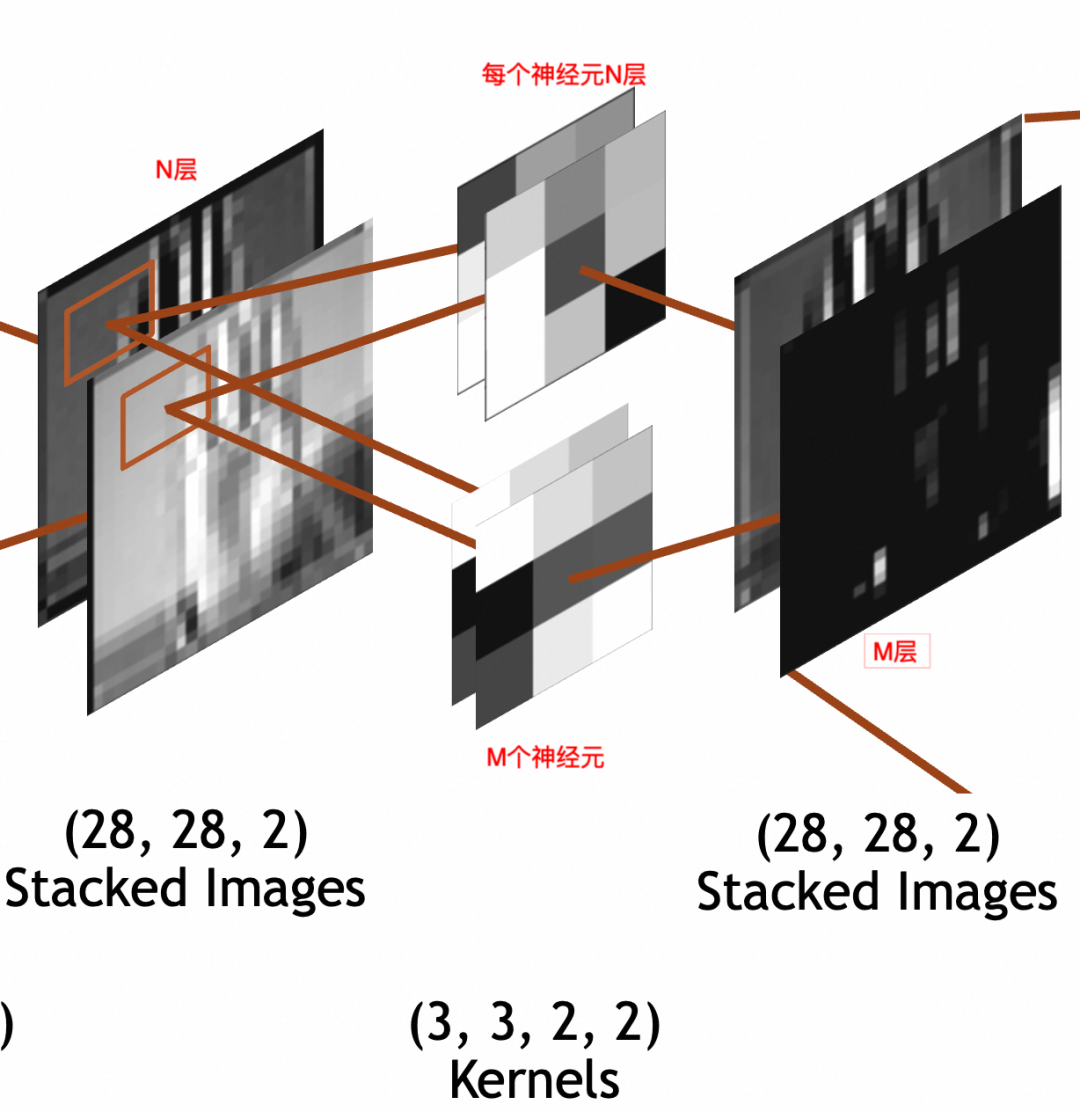
3 * 3 * N
的卷积核,每次要和N叠输入图像的
3 * 3
部分相乘,所以权重参数(weights)个数为
3 * 3 * N
,此外还通过一个偏置(bias)整体左右移。所以总参数个数为
3 * 3 * N + 1
,激活结果计算公式还是和上文普通神经元一样
output = activation_function(W * X + b)
。
为了神经网络整体处理方便,网络的输入图像、中间的堆叠图像都被统一成了 x * y * Z三维数组结构,但是两者关于叠/层的语义是不同的。输入图像的语义是图像的图层,不管是灰阶图像的1层,RGB的3层,还是RGBA的4层,是有现实关联性的。堆叠图像的各层分别是输入图像和单个神经元计算的结果,是一个特征,相互之间没有关联性,比如一层可能是纵边特征,另一层可能是横边特征。
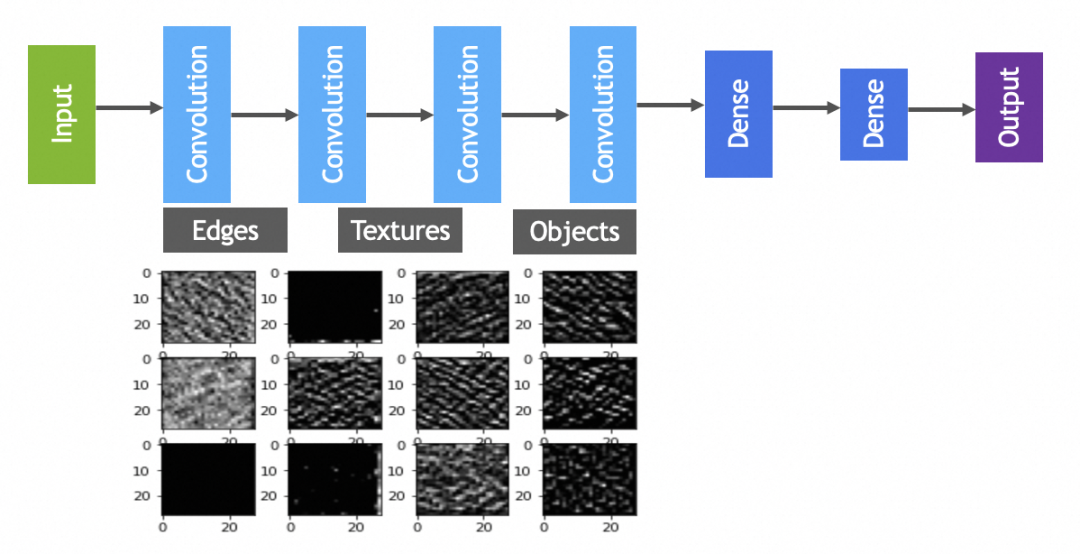
讲原理时已经提到过,一般会有多轮卷积,主要目的分别是从原图提取最小的特征,从最小特征中提取中等特征,……,如下图所示:
池化
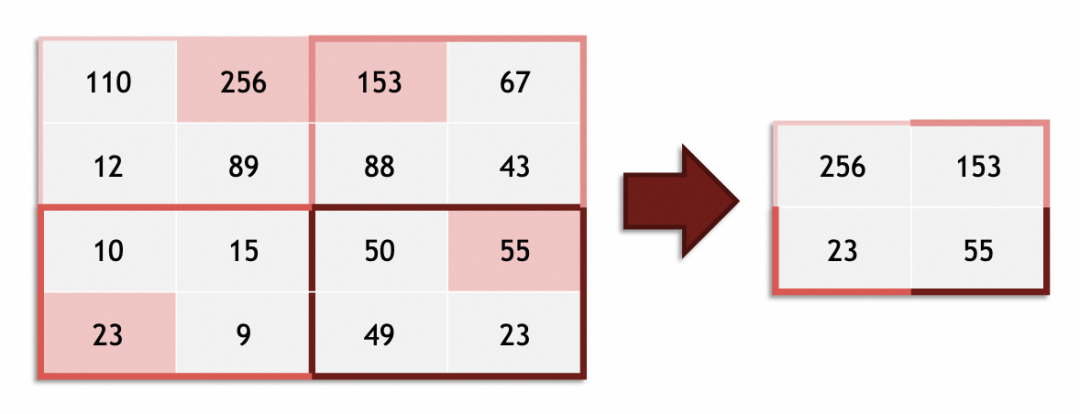
池化层的作用,主要是通过缩小图像,丢弃次要特征,保留主要特征:
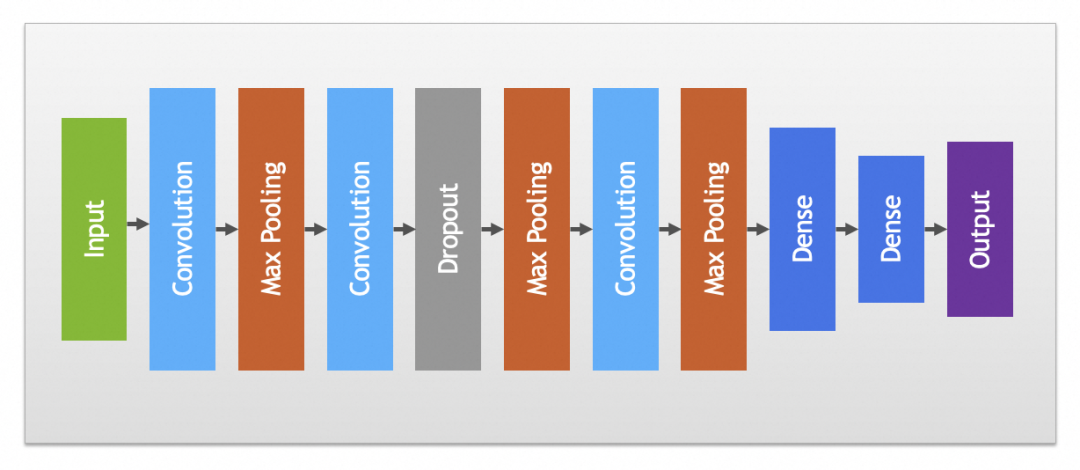
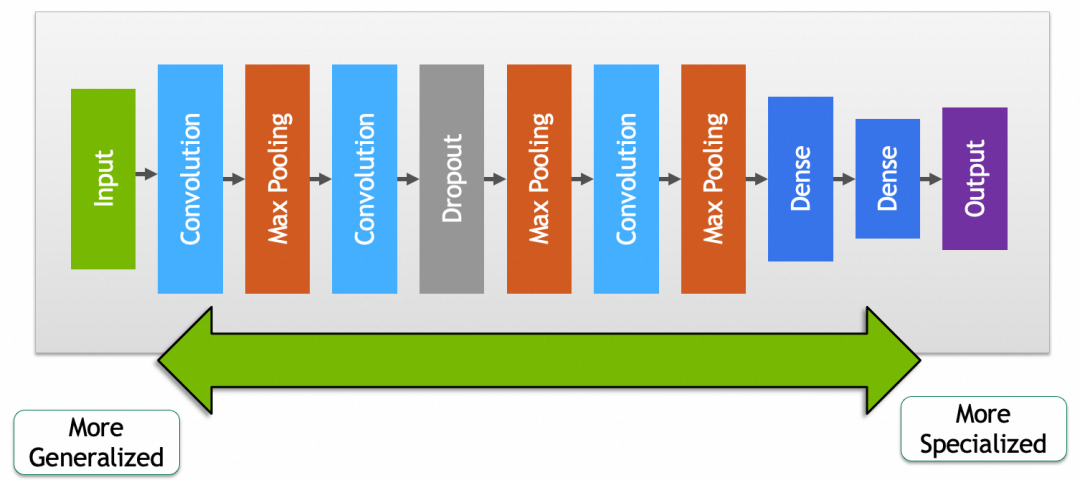
实践中卷积和池化层一般会搭配使用,完整卷积神经网络如下图:
其它
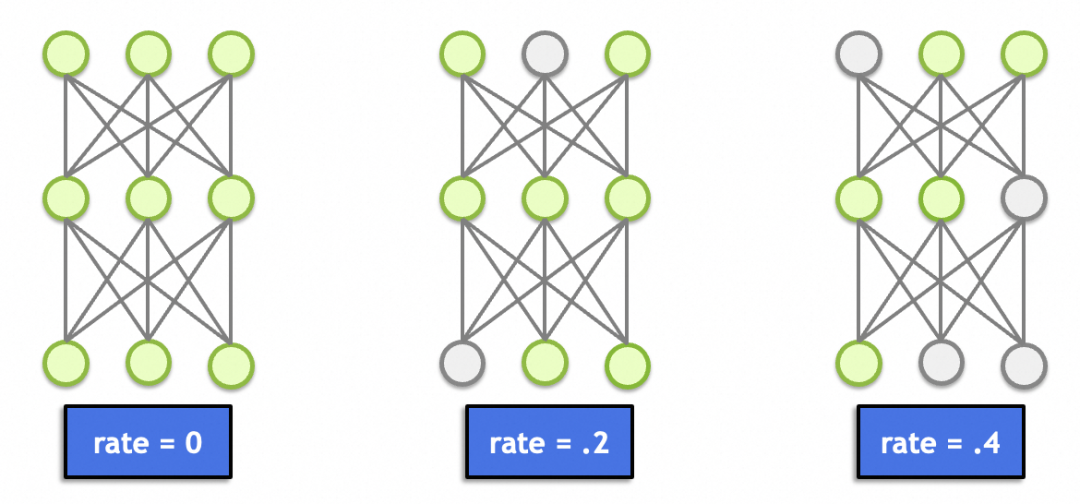
这里面还有一个丢弃层(Dropout),这个理论上跟图形学、图像处理没啥关系。主要作用是随机丢弃一定比例节点的输入(置0),避免因为节点过多(总参数过多、记忆能力太强)导致记忆效应,产生过拟合。
▐ 卷积神经网络实例讲解
本文卷积神经网络讲解的实例是对美国手语的识别,因为是手语照片,相对上文手写文字的案例来讲干扰因素过多,比如背景、衣服、掌纹等,所以采用普通神经网络过拟合比较严重。后面可以看到,改用卷积神经网络后,结果提升了不少。
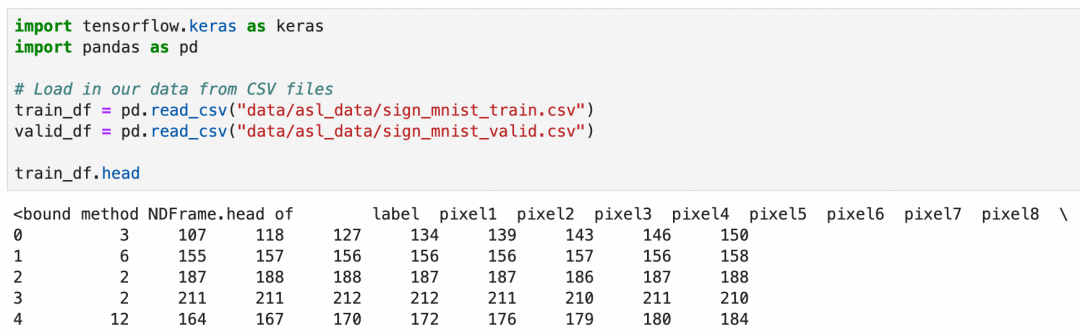
美国手语一共26个字母,其中2个字母带动作,这里只识别24个静止的字母。这次的数据集是使用csv文件存储的,可以加载后查看一下数据概貌:
csv文件一共785列,第一列是label,值是1-24,表示24种字母。第2到785列分别存放的灰阶值,值是0-255,表示从黑到白的颜色。
处理一下加载的值,将标签存入y_train和y_valid,784个像素值保留到x_train和x_valid:
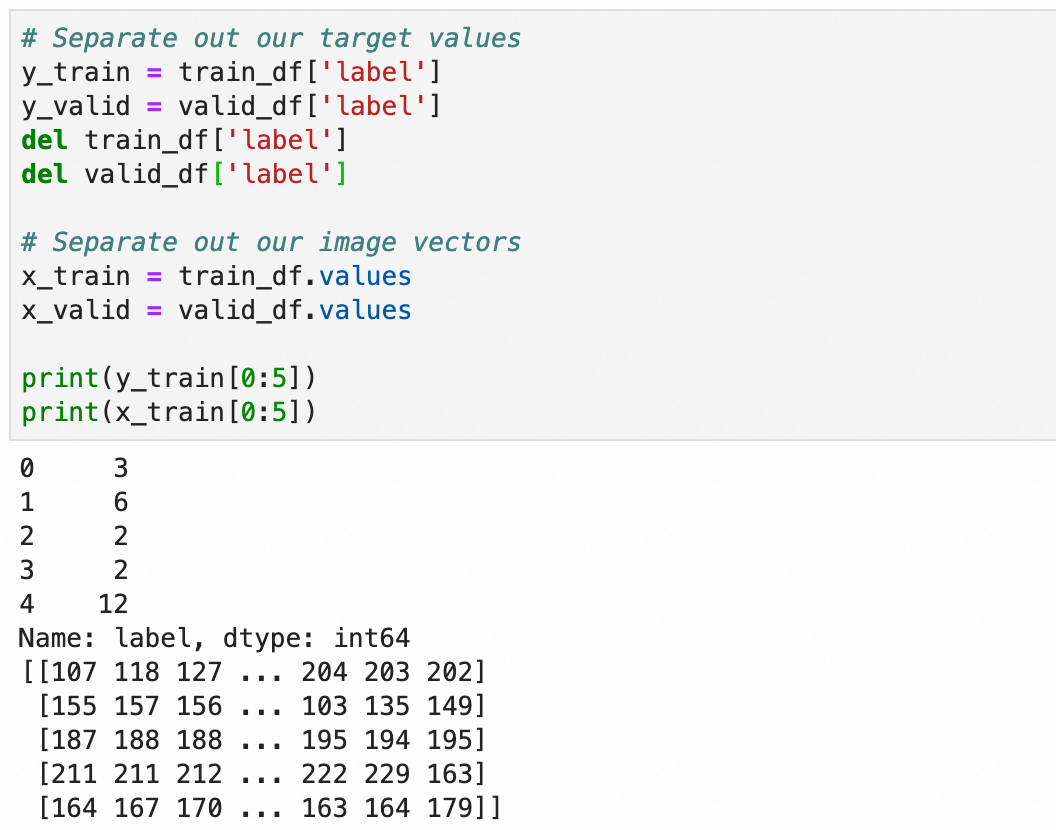
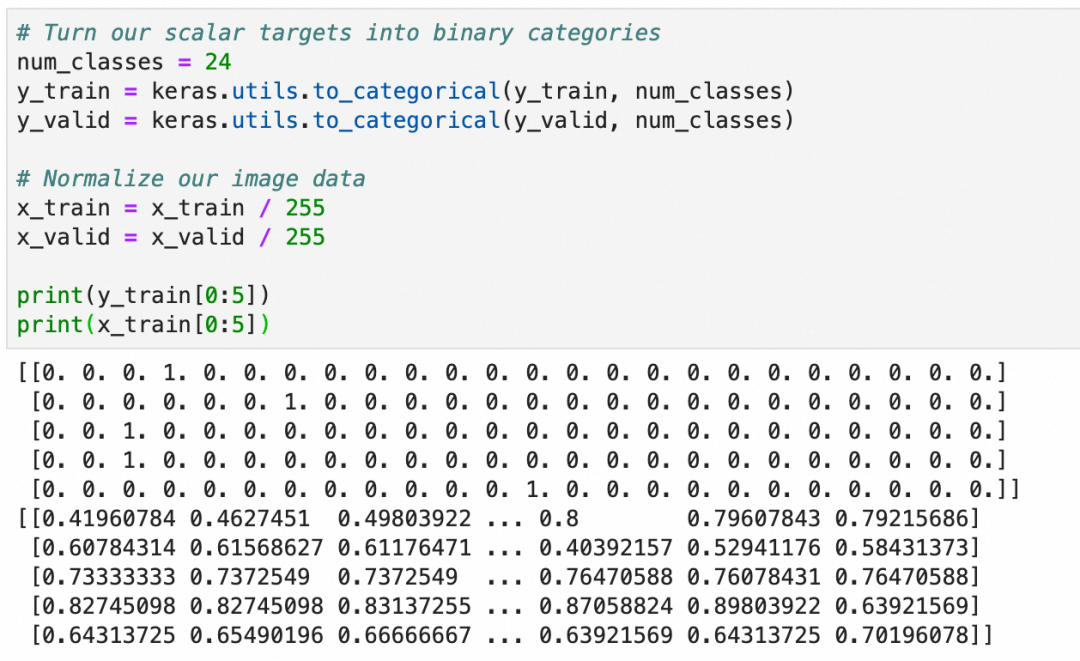
和上文一致,将y转成one-hot编码,用于分类算法,x转成0.0-1.0之间的浮点数:


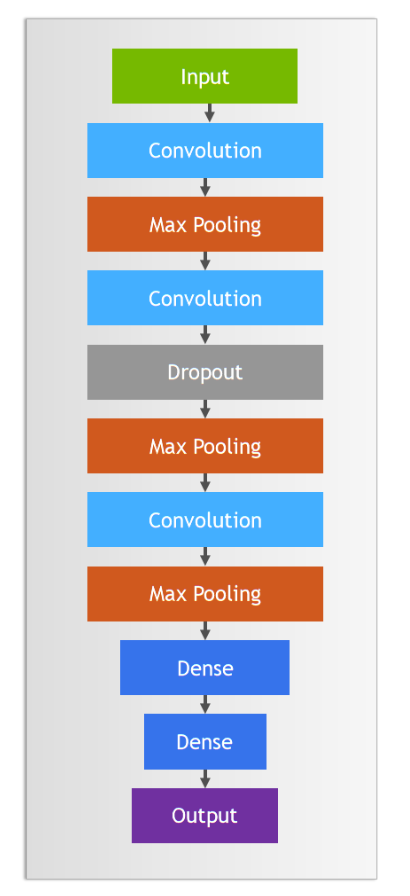
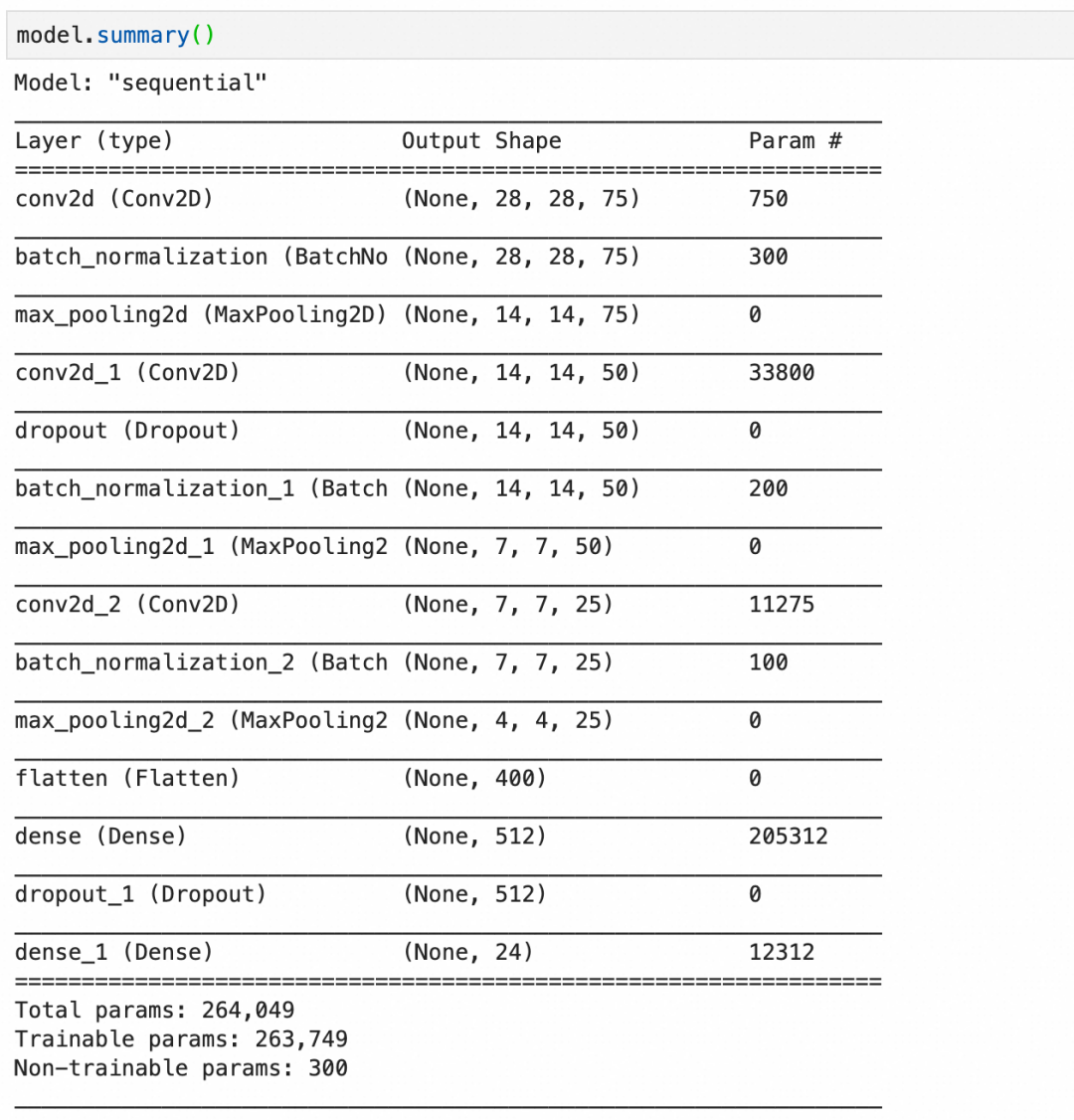
构建语句,其中:
Conv2D(75, (3, 3), stride=1, padding="same", activation="relu", input_shape=(28, 28, 1))创建一个卷积层,输入是28*28*1,75个神经元,每层大小3*3,因为输入是1层,所以每个神经元只有1层。BatchNormalization()创建一个批量标准化层,标准化上层输出平均激活值接近于0,激活值的标准差接近于1。MaxPool2D((2, 2), strides=2, padding="same")创建一个池化层,每2*2像素保留1像素,即长宽各缩小1倍。Dropout(0.2)创建一个丢弃层,丢弃20%输入。

第1层,卷积层,75个神经元,每个神经元 3*3*1+1 个参数,一共750个参数。
第2层,批量标准化层,75层输入,每层4个参数,其中2个可训练参数:缩放和偏移,还有2个不可训练参数,存储本批数据的统计值。一共300个参数。
第3层,池化层,池化层都是运算,没有参数。
第4层,卷积层,50个神经元,每个神经元3*3*75+1个参数(每个神经元有75层,分别对应输入的75层),一共33800个参数。
第5层,丢弃层,丢弃层只有运算,没有参数。
第11层,flatten层,只有转化,没有参数。
最后,总的参数个数里,有300个不可训练参数,这是由3个批量标准化层的不可训练参数加在一起构成。

本卷积神经网络校验集的准确度最后能到92%左右,算是比较好的结果:
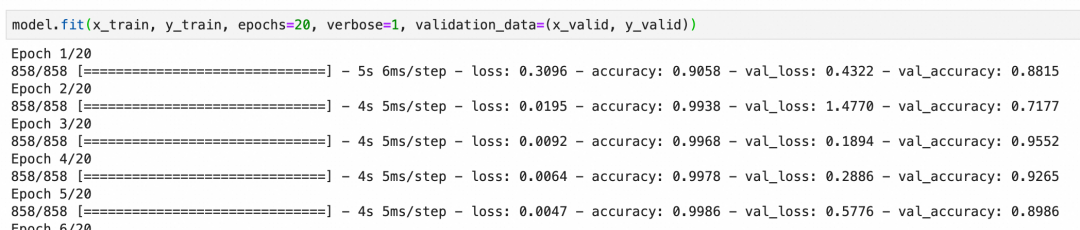

上面一章我们看了如何通过优化模型来降低过拟合,下面我们来看看如何通过数据增强来提升整体准确度。
数据增强通俗的理解就是通过丰富训练集数据、增加样本数量,减少模型对具体实例的“记忆”、增加模型抽象一般规律的能力。比如我们要训练识别狗的图片,能提供的训练样本当然是越全越好,即需要很多正例(比如金毛、边牧等不同品种的狗),也需要尽可能多的反例(比如猫、狼)。
道理很好理解,但是准备足够多样的训练样本是一件很费事的事情。数据增强是深度学习框架提供的一套工具,通过对现有训练集进行细微变化,比如(适度的)缩放、旋转、位移等等,来批量生产新的训练样本。
需要注意的是,需要根据数据集的特征来决定要进行怎样的变化,比如上一章的手语图片,样本是可以左右翻转的,因为左撇子的手势刚好左右翻转,但是垂直翻转则没有意义;同理,上文中的手写数字,则既不能垂直翻转,也不能左右翻转。
另外,样本的变化也要注意范围,因为网络接收的图片尺寸从一开始就是确定的,这些变化不会改变接收图片的尺寸。比如图片放大缩小,超出图片大小的部分会被裁剪,缺失的部分会被填充。所以,需要考虑变化后的图片是否还有意义,比如手语图片过分放大,放大到只剩一根手指,细节部分是清晰了,但是整体已经完全看不出所代表的手语字母了。
本章不涉及原理,因为这符合人们的一般理解。重点讲一下数据增强的过程:
第1步,还是上一章所用的训练集和模型不变。
train_df = pd.read_csv(...)...model = Sequential()model.add(...)...model.compile(...)
第2步,准备数据增强用的图像数据生成器:随机旋转10度、缩放10%、左右上下位移10%以内,随机水平翻转,但不垂直翻转。
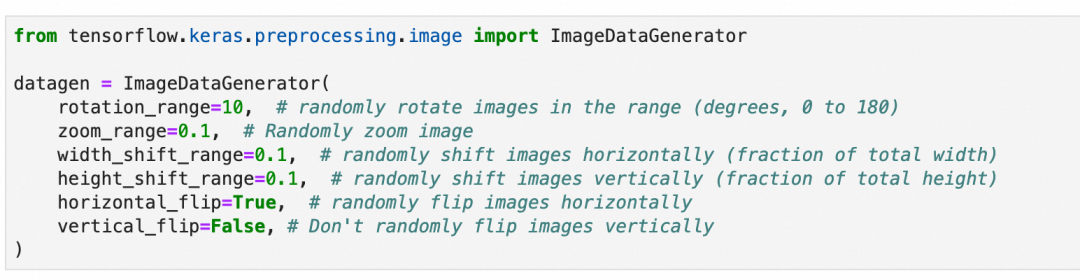
第3步,设置分批生成数据的大小:设置每批生成32张图片。

上面得到的是一个生成数据的迭代器,可以可视化一下第一批数据的样子:
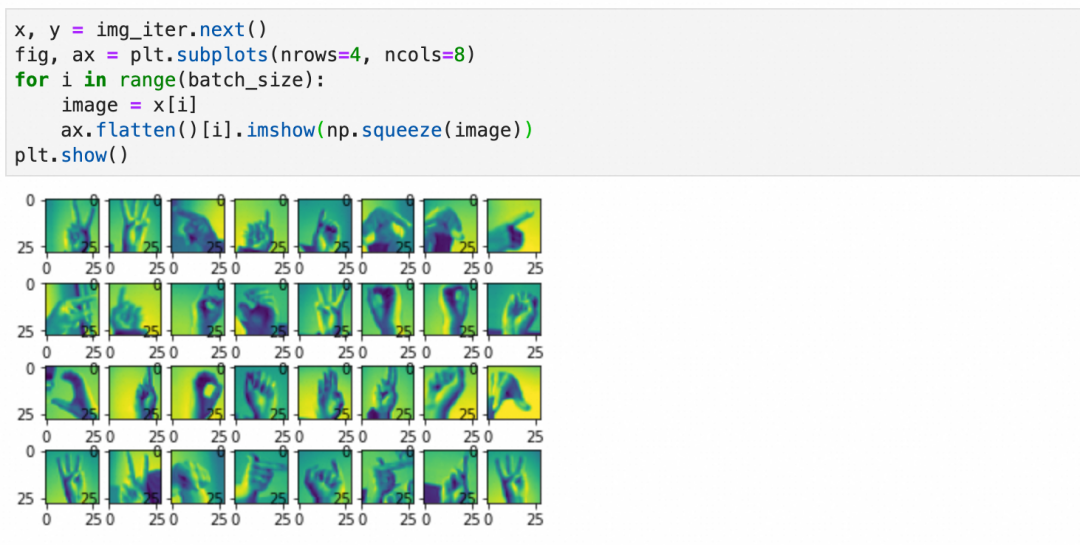
对训练样本的变化除了上面提到的旋转、缩放、位移等,还有基于原训练样本统计值的变化(本案例没用到)。
这一步是统计整个原训练样本,并记录必要的统计信息到数据生成器。

第5步,用数据生成器进行训练:
和上一章案例直接使用原始样本不同model.fit(x_train, y_train, epochs=20, verbose=1, validation_data=(x_valid, y_valid))。这里使用数据生成器生成的内容。
还是20个周期,但是每个周期里训练的样本数等于steps_per_epoch * batch_size,基于丰富度和训练时长兼顾考虑,这里采用steps_per_epoch=len(x_train)/batch_size,每周期样本数和原训练集差不多(但是都是经过数据生成器,随机变化过后的新样本)。
最后结果可以看出,准确度很快就上去了,数据增强有非常明显的效果。


▐ 迁移学习
迁移学习就是通过将已经训练好的模型的一部分摘出来,重新和其它网络层组成新的网络,从而复用网络能力和提升网络效果的过程。
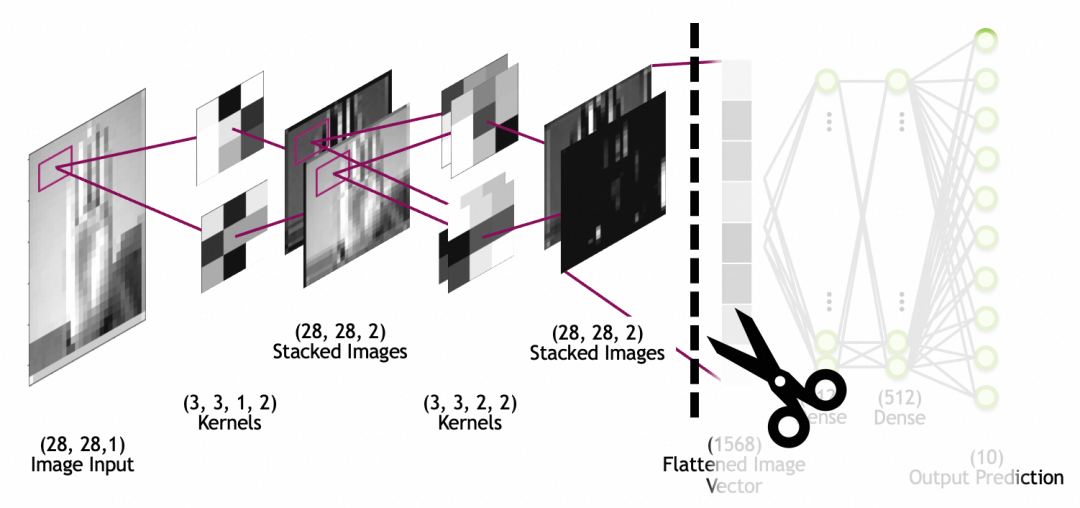
比如,我们可以拿google已经训练好的,进行动物分类的模型,拿来识别自家的猫主子,做一个自动猫门。
为什么要这么做?简单的说就是你自己的训练集不够,你给自家猫拍一千张照片来从头训练一个模型,也可能把外面的流浪猫放进来,因为你缺少足够的正负样本。
因为篇幅原因,这里不详细展开,只讲一下关键步骤。细节可以参考Transfer learning and fine-tuning官方教程:
第1步,摘取预训练模型的前半段(卷积层+池化层),去掉后半部分(include_top=False)。
第2步,拼接模型的后半段为新的、未经训练的全连接层。
第3步,设置前半部分参数不动(trainable=False),拿新的正负样本训练模型的后半段。
你会发现,有了预训练模型的前半段,很快就可以取得不错的结果。
这里我们也可以得出结论,网络前半段的参数,包含了比较通用的特征,比如一般的猫狗,网络后半段则包含了比较具体的特征,比如你家的猫主子。
▐ 微调
如果复用网络后,发现效果没有特别满意,可能是因为预训练模型和你要求解的问题没有完全匹配,或者现有模型参数里缺少一些针对性的特征。微调就是通过稍微调整一下预训练模型部分的参数,提升被复用网络效果的过程。
微调的过程很简单,前面3步保持不变,增加下面的步骤:
第4步,设置前半部分参数可训练(trainable=True),同时设置训练步长为一个非常小的值。
第5步,继续训练几个周期,这样整个网络的参数,包括预训练的前半段,和你新加入的后半段,都会按新的数据进行调整,针对特定问题的结果也会更好。
这里要注意两点:
第4步训练步长一定要小,这样每次参数的变化非常小,尽可能的保持预训练模型中的参数(一般特征)。
第3步一定要训练完成,即后半部分已经基于新数据训练过。否则,如果后半部分参数很随机,反向传播时,就算训练步长非常小,前半部分的参数也会发生非常大的波动,导致模型的基础特征被破坏。

高级神经网络不仅包括卷积神经网络,还涵盖了循环神经网络。卷积神经网络主要应用于图像识别的领域,而循环神经网络则广泛用于处理自然语言。随着Transformer模型的出现,自然语言处理的技术有了新的发展。关于自然语言处理的更多细节,将在后续关于Transformer原理的文章中详细介绍,故在此不作过多阐述。
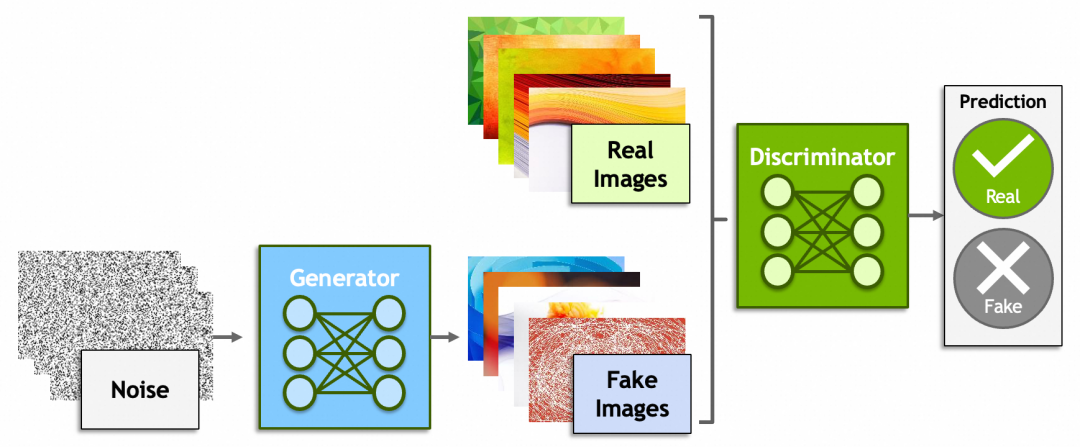
除了神经网络,深度学习里还有一些概念比较有意思,比如生成式对抗网络(Generative Adversarial Networks)、强化学习(Reinforcement Learning)。
生成式对抗网络一方是生成器(Generator)从一堆噪音里生成出假的图片,企图骗过鉴别器(Discriminator);而另一方鉴别器则尽可能的识别出真假图片。原理上还是脱离不了之前讲过的内容,鉴别器会给出一个分数,生成器会根据这个分数反向传播,修改由噪音生成图片的参数。
还记得“前GPT时代”,2022年Google研究员Blake Lemoine爆料AI有自我意识,被公司开除的新闻吗[捂脸哭]?谁说ChatGPT、MidJourney、Sora不是一些骗过了研究员、非常成功的生成式对抗网络呢?然而另一方面,就像【中文房间】描述的问题一样,哪里才是生成式对抗和真正理解的边界?大模型究竟能不能走向通用人工智能?
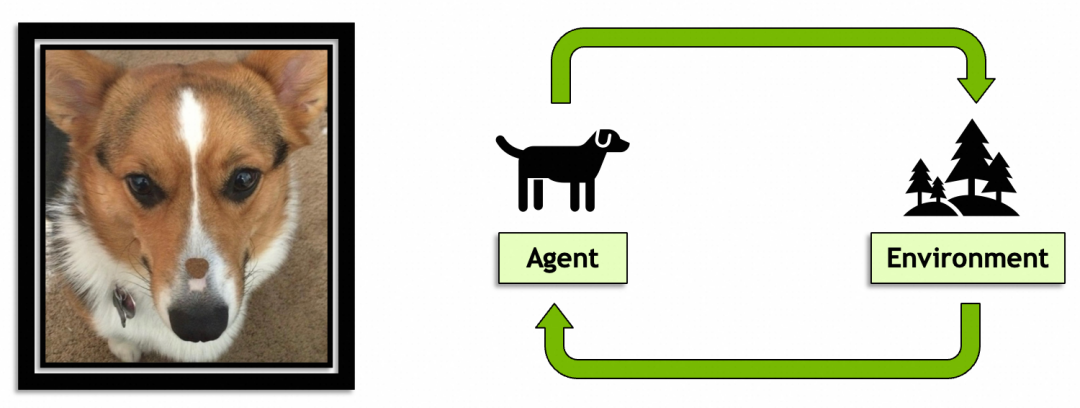
后一个概念,强化学习就是AI从环境中学习的过程和能力,目前机器人领域用得比较多。个人认为这个概念有意思是因为它是通向通用人工智能的必经之路,预计未来会扮演比较重要的角色。
本系列头两篇文章到这里就结束了,希望能激起大家学习AI原理的好奇心和勇气。个人水平有限,如果文章有什么问题,欢迎留言探讨。

团队介绍
天猫国际是中国领先的进口电商平台, 也是阿里巴巴-淘天集团电商技术体系中链路最完整且最为复杂的技术产品之一,也是淘天集团拥有最完整业务形态(平台+直营、跨境、大贸、免税等多业务模式)的业务。在这里我们参与到阿里电商体系的绝大部分核心系统(导购、商家、商品、交易、营销、履约等),同时借助区块链、大数据、AI算法等前沿技术助力业务高速增长。作为贴近业务前沿的技术团队,我们对于电商行业特性、跨境市场研究、未来交易趋势以及未来技术布局等都有着深度的理解。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。