


Invités communs : Qiu Lu, Tang Chunxu, Wang Beinan
Actuellement, les domaines de l’intelligence artificielle (IA) et de l’apprentissage automatique (ML) se développent rapidement et il devient de plus en plus critique de gérer efficacement de grands ensembles de données pendant la formation. Ray est devenu un acteur important dans ce domaine, permettant la formation d'ensembles de données à grande échelle grâce à un traitement efficace des flux de données. Ray divise les grands ensembles de données en morceaux gérables et divise les tâches de formation en tâches plus petites sans qu'il soit nécessaire de stocker l'intégralité de l'ensemble de données localement sur la machine d'entraînement. Cependant, cette approche innovante se heurte également à certains défis.
Bien que Ray facilite la formation avec de grands ensembles de données, le chargement des données reste un sérieux goulot d'étranglement. Chaque époque nécessite le rechargement de l'ensemble des données à partir du stockage distant, ce qui réduira considérablement l'utilisation du GPU et augmentera le coût de transmission des données stockées. Par conséquent, nous avons besoin d'une méthode plus optimisée pour gérer les données pendant le processus de formation et améliorer l'efficacité.
Ray utilise principalement la mémoire pour stocker des données, et son stockage d'objets en mémoire est conçu pour les données de tâches volumineuses. Cependant, cette approche se heurte à des goulots d'étranglement pour les tâches gourmandes en données, car les données requises pour les tâches volumineuses doivent être préchargées dans la mémoire de Ray avant l'exécution. Étant donné que la taille du stockage d'objets ne peut généralement pas accueillir l'ensemble de données d'entraînement, il n'est pas adapté à la mise en cache des données sur plusieurs époques d'entraînement, ce qui souligne également la nécessité d'une solution de gestion de données plus évolutive pour le framework Ray.
L'un des avantages importants de Ray est qu'il utilise le GPU pour la formation tout en utilisant le CPU pour le chargement et le prétraitement des données. Cette méthode garantit une utilisation efficace des ressources GPU, CPU et mémoire au sein du cluster Ray, mais elle entraîne également une sous-utilisation des ressources disque et un manque de gestion efficace. Une idée révolutionnaire a émergé : créer une couche d'accès aux données hautes performances pour mettre en cache et accéder aux ensembles de données de formation en gérant intelligemment les ressources de disque inefficaces sur les machines. Cela peut améliorer considérablement les performances globales de formation et réduire le coût d'accès au stockage distant.
Alluxio accélère la formation sur des ensembles de données à grande échelle en utilisant intelligemment et efficacement la capacité disque inutilisée sur les GPU et les machines CPU adjacentes pour la mise en cache distribuée. Cette approche innovante améliore considérablement les performances de chargement des données, essentielles à la formation avec des ensembles de données à grande échelle, tout en réduisant également le recours au stockage distant et les coûts de transfert de données associés.
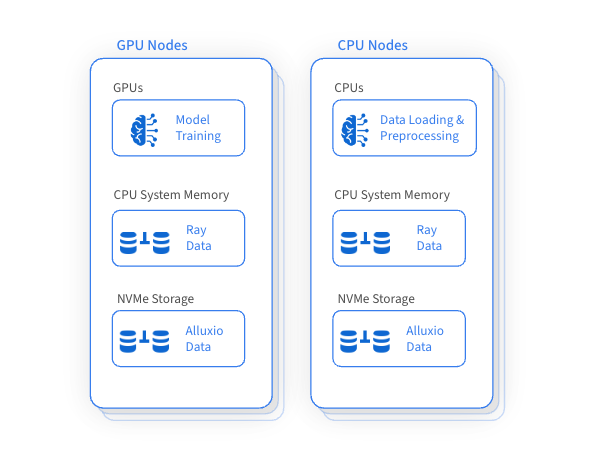
L'intégration d'Alluxio améliore les capacités de gestion des données de Ray et apporte de nombreux avantages :
√
Évolutivité
L'accès aux données et la mise en cache sont hautement évolutifs
√
Accélérer l'accès aux données
Utilise des disques hautes performances pour mettre en cache les données
Optimisé pour la lecture aléatoire à haute concurrence des formats de fichiers de stockage de colonnes tels que Parquet
zéro copie
√
fiabilité et disponibilité
Aucun point de défaillance unique
Accès robuste au stockage à distance pendant les pannes
√
Gestion flexible des ressources
Allouer et libérer dynamiquement les ressources de cache en fonction des besoins de la charge de travail
Ray peut orchestrer efficacement les flux de travail d'apprentissage automatique et s'intégrer de manière transparente aux cadres de chargement, de prétraitement et de formation des données. En tant que couche d'accès aux données hautes performances, Alluxio peut considérablement optimiser les tâches de formation et d'inférence IA/ML, en particulier lorsque les données de stockage distantes doivent être consultées à plusieurs reprises.
Ray utilise PyArrow pour charger les données et convertir le format de données au format Arrow, qui est ensuite utilisé par le flux de travail Ray à l'étape suivante. PyArrow délègue les problèmes de connexion de stockage au framework fsspec, et Alluxio sert de couche de cache intermédiaire entre Ray et les systèmes de stockage sous-jacents (tels que S3, Azure Blob Storage et Hugging Face).
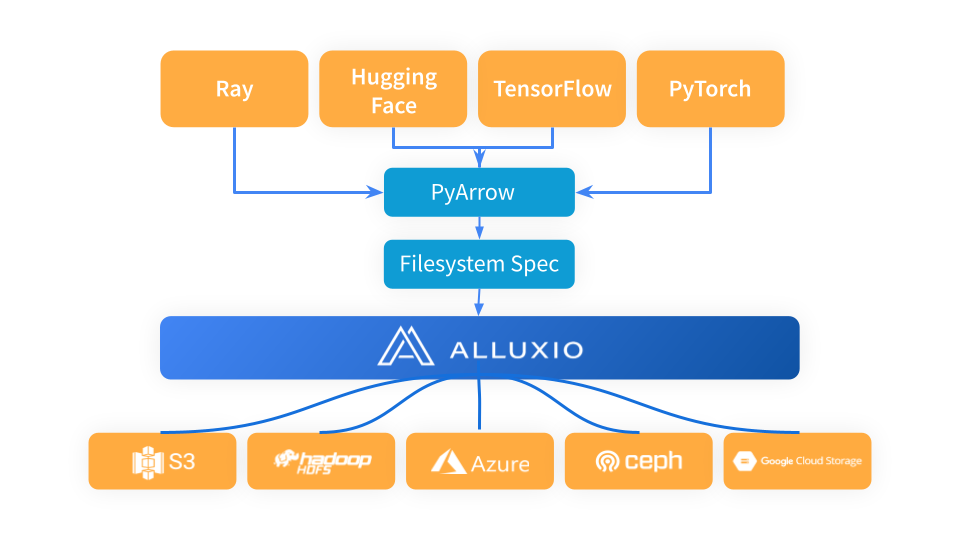
Lorsque vous utilisez Alluxio comme couche de mise en cache entre Ray et S3, importez simplement Alluxiofs, initialisez le système de fichiers Alluxio et remplacez le système de fichiers Ray par Alluxio.
# Import fsspec & alluxio fsspec implementationimport fsspecfrom alluxiofs import AlluxioFileSystemfsspec.register_implementation("alluxio", AlluxioFileSystem)# Create Alluxio filesystem with S3 as the underlying storage systemalluxio = fsspec.filesystem("alluxio", target_protocol=”s3”, etcd_host=args.etcd_host)# Ray read data from Alluxio using S3 URLds = ray.data.read_images("s3://datasets/imagenet-full/train", filesystem=alluxio)
Nous utilisons le test nocturne Ray Data de Ray Data pour comparer les performances de chargement des données d'Alluxio et de S3 dans la même région à différentes époques d'entraînement. Les résultats de référence montrent que les coûts de stockage peuvent être considérablement réduits et le débit amélioré en intégrant Alluxio à Ray.

√
Amélioration des performances d'accès aux données : nous avons observé que lorsque le stockage d'objets de Ray n'est pas affecté par la pression de la mémoire, le débit d'Alluxio est 2 fois supérieur à celui de S3 dans la même zone.
√
L'avantage est plus évident sous la pression de la mémoire : il convient de noter que lorsque le stockage objet de Ray est confronté à une pression de la mémoire, l'avantage en termes de performances d'Alluxio augmente considérablement et son débit est 5 fois supérieur à celui de S3.
Pour les tâches Ray, il est d'une grande importance stratégique d'utiliser les ressources disque inutilisées comme stockage pour le cache distribué. Cette méthode améliore considérablement les performances de chargement des données et est particulièrement utile lors de l’entraînement ou du réglage avec le même ensemble de données sur plusieurs époques. De plus, lorsque Ray est confronté à une pression de mémoire, il peut fournir des solutions pratiques pour optimiser et simplifier le processus de gestion des données dans ces scénarios.
✦
[Ajouter un assistant pour obtenir plus d'informations]
✦

✦
【Popularité récente】
✦

✦
【Marché Baodian】
✦






Cet article est partagé à partir du compte public WeChat - Alluxio (Alluxio_China).
En cas d'infraction, veuillez contacter [email protected] pour suppression.
Cet article participe au « Plan de création de sources OSC ». Vous qui lisez, êtes invités à vous joindre et à partager ensemble.