

Auteur de cet article :
Tarik Bennett, Beinan Wang, Hope Wang
Cet article abordera les défis d'accès aux données dans le domaine de l'intelligence artificielle (IA) et révélera que « les NAS/NFS couramment utilisés ne sont peut-être pas le meilleur choix » .
1. Première architecture d’intelligence artificielle/apprentissage automatique
Les recherches de Gartner montrent que, bien que les grands modèles de langage (LLM) aient attiré beaucoup d'attention, la plupart des organisations en sont encore aux premiers stades de l'utilisation de grands modèles, et seules certaines sont entrées dans la phase de production.
L’objectif de la création d’une plate-forme d’IA dès les premiers stades est de faire fonctionner le système afin que les projets pilotes et les validations de principe puissent être menés. Ces premières architectures, ou architectures de pré-production, sont conçues pour répondre aux besoins fondamentaux de formation et de déploiement de modèles. Actuellement, de nombreuses organisations utilisent déjà ce type d’architecture d’IA précoce pour les environnements de production.
À mesure que les données et les modèles se développent, ces premières architectures d’IA deviennent souvent inefficaces. Les entreprises entraînent des modèles sur le cloud et, à mesure que les projets se développent, leur utilisation des données et du cloud devrait augmenter considérablement d'ici 12 mois. De nombreuses organisations commencent avec des volumes de données correspondant à la taille de leur mémoire actuelle, mais sont conscientes de la nécessité de se préparer à des charges plus importantes.
Les entreprises peuvent choisir d'utiliser une pile technologique existante ou un nouveau déploiement. Cet article se concentrera sur la façon d'utiliser votre pile technologique existante ou d'acheter du matériel supplémentaire pour concevoir une pile technologique plus évolutive, agile et performante.
2. Défis liés à l'accès aux données
Avec l'évolution de l'architecture AI/ML, la taille des ensembles de données de formation de modèles continue de croître de manière significative, et la puissance de calcul et l'échelle des GPU augmentent également rapidement. Outre l’informatique, le stockage et le réseau, nous pensons que l’accès aux données est un autre élément clé dans la construction d’une plateforme d’IA tournée vers l’avenir .

L'accès aux données fait référence à des technologies telles que les services de données, le stockage de sauvegarde (NFS, NAS) et le cache haute performance (comme Alluxio) qui aident le moteur informatique à obtenir des données pour la formation et le déploiement du modèle.
L'accès aux données se concentre sur le débit et l'efficacité du chargement des données, ce qui est de plus en plus important pour les architectures IA/ML où les ressources GPU sont rares : l'optimisation du chargement des données peut réduire considérablement le temps d'attente d'inactivité du GPU et améliorer l'utilisation du GPU. Par conséquent, un accès aux données hautes performances devrait être l’objectif principal du déploiement de l’architecture.
À mesure que les entreprises étendent les tâches de formation de modèles sur les premières architectures d’IA, certains défis courants en matière d’accès aux données sont apparus :
1
L'efficacité de la formation du modèle est inférieure aux attentes : en raison de goulots d'étranglement dans l'accès aux données, la durée de la formation est plus longue que celle estimée en fonction des ressources informatiques. Les flux de données à faible débit ne fournissent pas suffisamment de données au GPU.
2
Goulots d'étranglement liés à la synchronisation des données : la copie ou la synchronisation manuelle des données du stockage vers un serveur GPU local crée des retards dans la constitution de la file d'attente de données à préparer.
3
Problèmes de concurrence et de métadonnées : lorsque des tâches volumineuses sont lancées en parallèle, des conflits peuvent survenir sur le stockage partagé. La latence augmente lorsque les opérations de métadonnées sur le magasin principal sont lentes.
4
Performances lentes ou faible utilisation du GPU : une infrastructure GPU hautes performances nécessite un investissement énorme, et une fois l'accès aux données inefficace, cela entraînera des ressources GPU inutilisées et sous-utilisées.
En outre, ces défis sont aggravés par une multitude d’autres problèmes que les équipes chargées des données doivent gérer. Ces problèmes incluent des vitesses d'E/S de stockage lentes qui ne peuvent pas répondre aux besoins des clusters GPU hautes performances. S'appuyer sur la copie et la synchronisation manuelles des données augmente la latence pendant que l'équipe chargée des données attend que les données soient transmises au serveur GPU. Le défi de l’accès aux données est également aggravé par la complexité architecturale des multiples silos de données dans une infrastructure hybride ou des environnements multi-cloud.
Ces problèmes ont pour conséquence que l'efficacité de bout en bout de l'architecture n'est pas à la hauteur des attentes.
Les défis liés à l’accès aux données ont souvent deux solutions communes.
Achetez un stockage plus rapide : de nombreuses entreprises tentent de résoudre le problème de la lenteur de l'accès aux données en déployant des options de stockage plus rapides. Les fournisseurs de cloud proposent un stockage hautes performances, tandis que les fournisseurs de matériel professionnel vendent du stockage HPC pour améliorer les performances.
Ajouter un NAS/NFS au stockage objet : L'ajout d'un NAS ou NFS centralisé comme sauvegarde au stockage objet tel que S3, MinIO ou Ceph est une pratique courante et aide les équipes à consolider les données dans des systèmes de fichiers partagés, simplifiant ainsi la collaboration et le partage des utilisateurs et des charges de travail. De plus, vous pouvez également profiter des fonctions de gestion des données associées telles que la cohérence, la disponibilité, la sauvegarde et l'évolutivité des données fournies par les fournisseurs de NAS matures.
Cependant, ces deux solutions courantes ci-dessus ne résoudront peut-être pas réellement votre problème.
Bien qu'un stockage plus rapide et un NFS/NAS centralisé puissent progressivement améliorer les performances, ils présentent également des inconvénients.
1
Un stockage plus rapide signifie une migration des données, ce qui peut facilement entraîner des problèmes de fiabilité des données
Pour profiter des hautes performances fournies par le stockage dédié, les données doivent être migrées du stockage existant vers un nouveau niveau de stockage hautes performances. Cela entraîne la migration des données en arrière-plan. La migration de grands ensembles de données peut entraîner des temps de transfert prolongés et des problèmes de fiabilité des données, tels que la corruption ou la perte de données lors de la migration. Pendant que l'équipe attend la fin de la synchronisation des données, la suspension des opérations peut perturber le service et ralentir l'avancement du projet.
2
NFS/NAS : maintenance et goulots d'étranglement
En tant que couche de stockage supplémentaire, les défis de maintenance, de stabilité et d'évolutivité NFS/NAS demeurent. La copie manuelle des données de NFS/NAS vers un serveur GPU local augmentera la latence et gaspillera des ressources causées par des sauvegardes répétées. Les augmentations de demande de lecture provoquées par des tâches parallèles peuvent regrouper des serveurs NFS/NAS et des services interconnectés. De plus, des problèmes de synchronisation des données dans les clusters GPU NFS/NAS distants existent toujours.
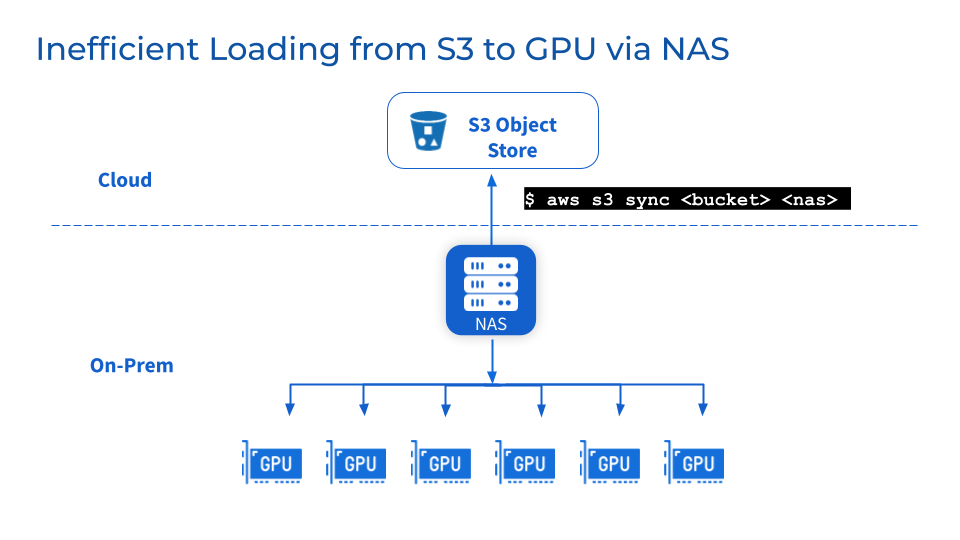
3
Que faire si je dois changer de fournisseur pour des raisons professionnelles ?
Les entreprises peuvent changer de fournisseur pour des raisons d’optimisation des coûts ou pour des raisons contractuelles. La flexibilité des environnements multi-cloud nécessite la capacité de porter facilement de grands ensembles de données sans dépendance vis-à-vis d'un fournisseur. Cependant, le déplacement d’un stockage de données à l’échelle du pétaoctet peut entraîner des temps d’arrêt importants et perturber le développement des modèles.
En bref, les solutions existantes, bien qu’utiles à court terme, ne peuvent pas fournir une architecture d’accès aux données évolutive et optimisée pour répondre à la croissance exponentielle des besoins en données de l’IA/ML.
3. Solutions proposées par Alluxio
Alluxio peut être déployé entre les sources de calcul et de données. Fournissez l’abstraction des données et la mise en cache distribuée pour améliorer les performances et l’évolutivité de l’architecture IA/ML.
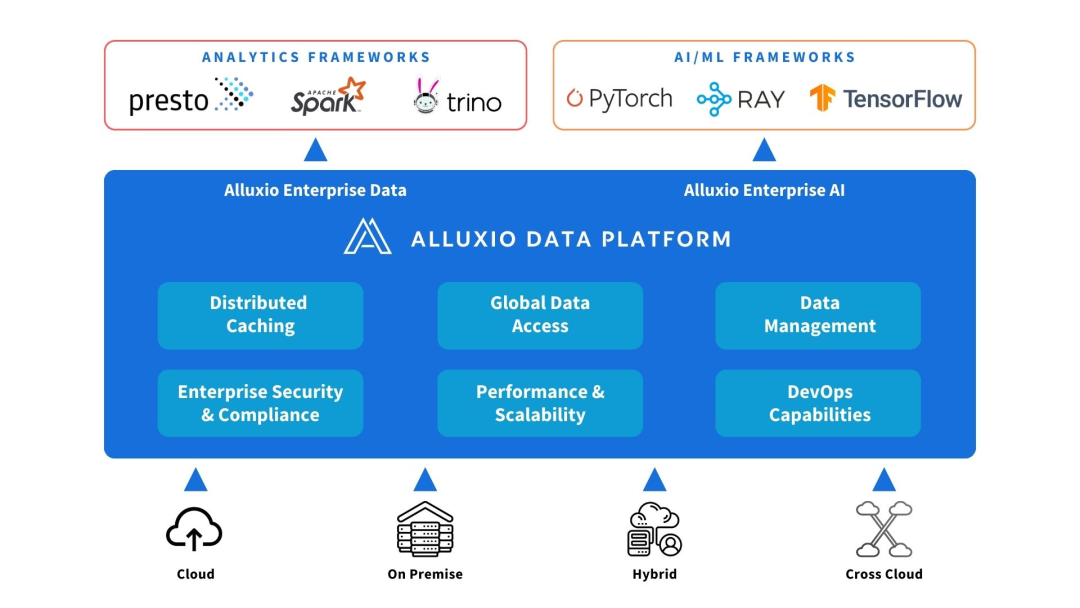
Alluxio aide à résoudre les défis rencontrés par les premières architectures d'IA en matière d'évolutivité, de performances et de gestion des données à mesure que la quantité de données, la complexité des modèles augmentent et que les clusters GPU se développent.
1
augmenter la capacité
Alluxio évolue au-delà de la limite d'un seul nœud pour prendre en charge des ensembles de données de formation plus volumineux que ce que la mémoire du cluster ou les SSD locaux peuvent gérer. Il connecte différents systèmes de stockage et fournit une couche d'accès aux données unifiée pour monter des lacs de données au niveau du pétaoctet. Alluxio met intelligemment en cache les fichiers et métadonnées fréquemment utilisés dans les niveaux de mémoire et de SSD proches du calcul, éliminant ainsi le besoin de copier l'intégralité de l'ensemble de données.
2
Réduire la gestion des données
Alluxio simplifie le mouvement et le stockage des données entre les clusters GPU grâce à la mise en cache distribuée automatisée. Les équipes chargées des données n'ont pas besoin de copier ou de synchroniser manuellement les données avec des fichiers intermédiaires locaux. Le cluster Alluxio peut capturer automatiquement des fichiers ou des objets chauds vers un emplacement proche du nœud informatique sans passer par des opérations de flux de travail complexes. Alluxio simplifie les flux de travail même avec 50 millions d'objets ou plus par nœud.
3
Améliorer les performances
Alluxio est conçu pour accélérer les charges de travail, en éliminant les goulots d'étranglement d'E/S du stockage traditionnel qui limitent le débit du GPU. La mise en cache distribuée augmente la vitesse d'accès aux données de plusieurs ordres de grandeur. Par rapport à l'accès au stockage distant via le réseau, Alluxio fournit un accès aux données locales au niveau de la mémoire et du SSD, améliorant ainsi l'utilisation du GPU.
En bref, Alluxio fournit une couche d'accès aux données hautes performances et évolutive qui peut maximiser l'utilisation des ressources GPU dans les scénarios d'expansion des données AI/ML.
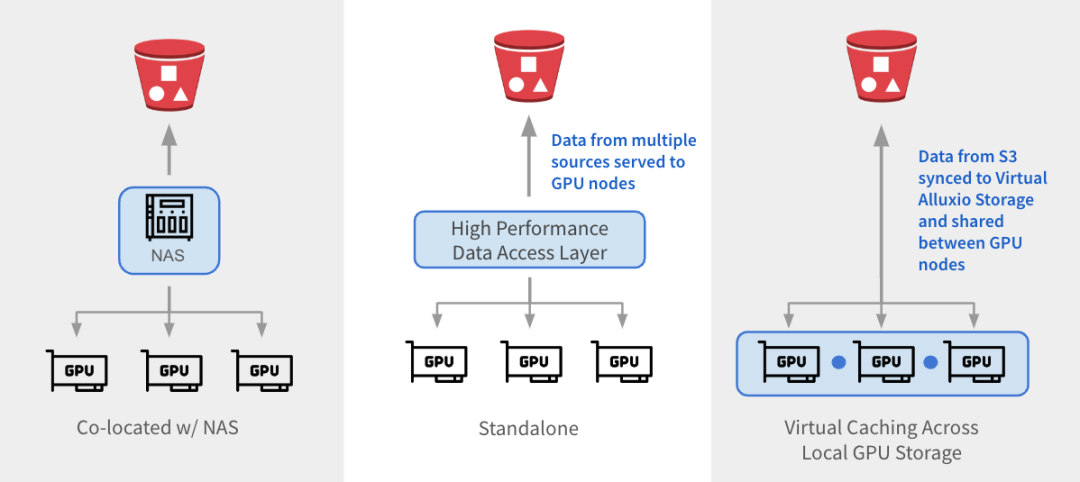
Alluxio peut être intégré aux architectures existantes de trois manières.
1
与 NAS 并置:Alluxio 作为透明缓存层与现有 NAS并置部署,增强 I/O 性能。Alluxio将NAS中的活跃数据缓存在跨GPU节点的本地 SSD 中。作业将读取请求重新定向到Alluxio上的SSD缓存,绕过NAS,从而消除NAS瓶颈。写入操作通过 Alluxio 对 SSD 进行低延迟写入,然后异步持久化保存到 NAS中。
2
独立数据访问层:Alluxio 作为专用的高性能数据访问层,整合来自 S3、HDFS、NFS 或本地数据湖等多个数据源的数据,为GPU节点提供数据访问服务。Alluxio 将不同的数据孤岛统一在一个命名空间下,并将存储后端挂载为底层存储。经常访问的数据会被缓存在 Alluxio Worker节点的SSD中,从而加速GPU对数据的本地访问。
3
跨GPU存储的虚拟缓存:Alluxio充当跨本地GPU存储的虚拟缓存。S3中的数据会被同步到虚拟 Alluxio存储并在GPU节点之间共享,无需在节点之间手动拷贝数据。
1
参考架构
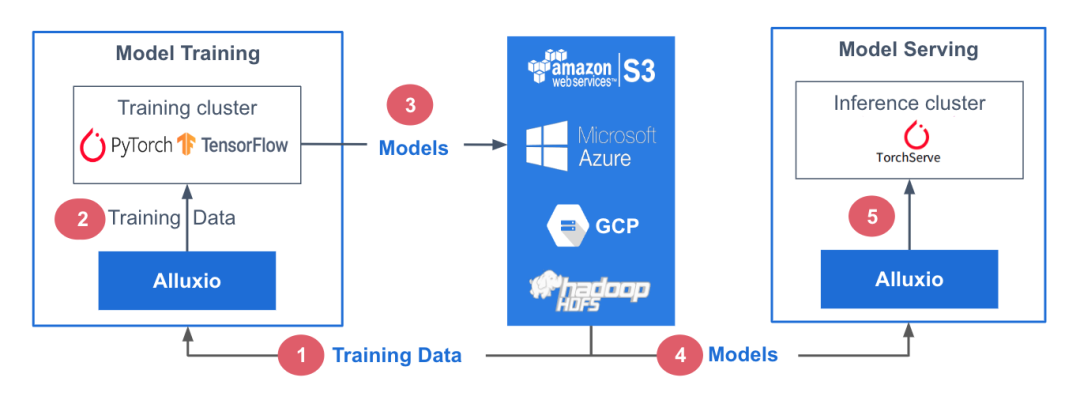
在此参考架构中,训练数据存储在中心化数据存储平台AWS S3中。Alluxio可帮助实现模型训练集群对训练数据的无缝访问。PyTorch、TensorFlow、scikit-learn和XGBoost等ML训练框架都在CPU/GPU/TPU集群上层执行。这些框架利用训练数据生成机器学习模型,模型生成后被存储在中心化模型库中。
在模型服务阶段,使用专用服务/推理集群,并采用TorchServe、TensorFlow Serving、Triton 和 KFServing等框架。这些服务集群利用Alluxio从模型存储库中获取模型。模型加载后,服务集群会处理输入的查询、执行必要的推理作业并返回计算结果。
训练和服务环境都基于Kubernetes,有助于增强基础设施的可扩展性和可重复性。
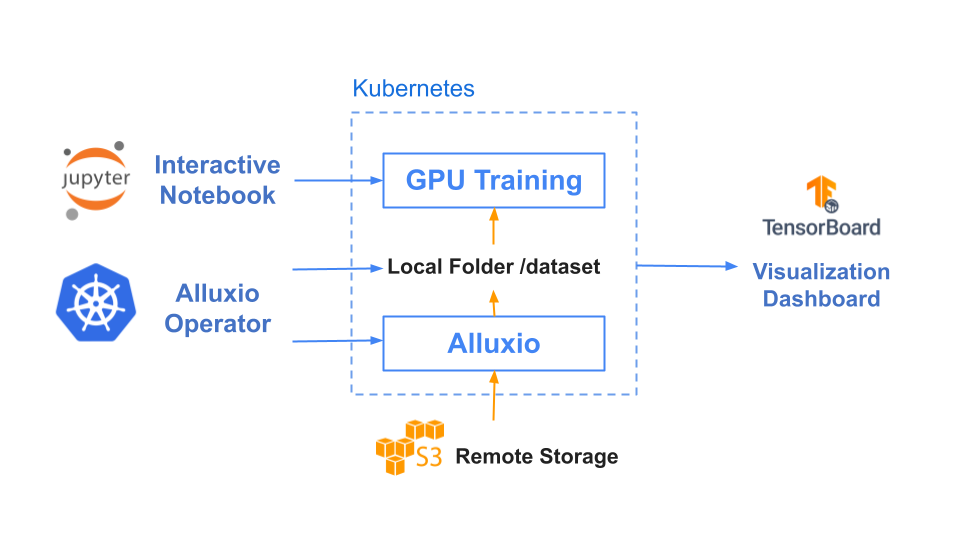
2
基准测试结果
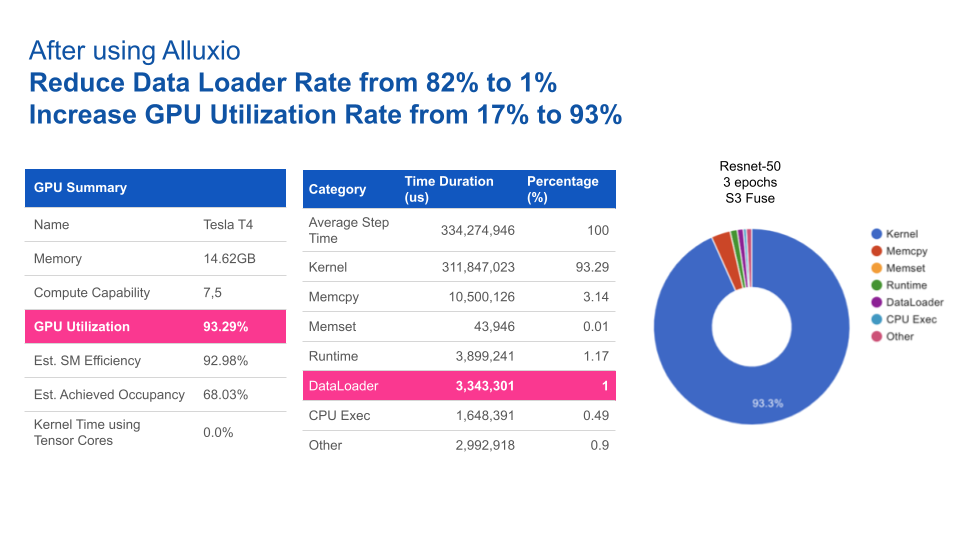
在本基准测试中,我们用计算机视觉领域的典型应用场景之一——图片分类任务作为示例,其中我们以ImageNet的数据集作为训练集,通过ResNet来训练图片分类模型。
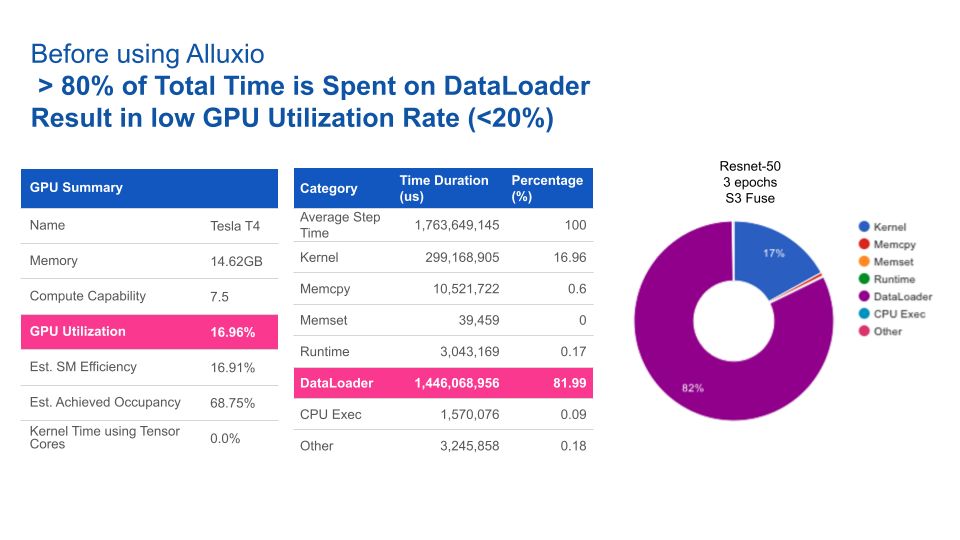
基于Resnet-50上3个epochs性能基准测试的结果,使用Alluxio比使用S3-FUSE的速度快5倍。一般来说,提高数据访问性能可缩短模型训练的总时间。
|
|
Alluxio |
S3 - FUSE |
|
Total training time (3 epochs) |
17 minutes |
85 minutes |
使用Alluxio后,GPU利用率得到大幅提升。Alluxio将数据加载时间由82%缩短至1%,从而将GPU利用率由17%提升至93%。
四、结论
随着AI/ML学习架构从早期的预生产架构向着可扩展架构发展,数据访问始终是瓶颈。仅靠添加更快的存储硬件或中心化NAS/NFS无法完全消除性能不达标以及影响系统操作的管理问题。
Alluxio提供了一种专为优化AI/ML任务数据流而设计的软件解决方案。与传统存储方案相比,其优势包括:
1
优化数据加载:Alluxio智能地加速训练任务和模型服务的数据访问,从而将GPU利用率最大化。
2
维护需求低:无需在节点或集群之间手动拷贝数据。Alluxio通过其分布式缓存层处理热文件传输。
3
支持扩展:当数据量大到需要扩展更多节点的情况下,Alluxio也能维持性能稳定。Alluxio通过使用SSD扩展内存,可缓存任何大小的文件,避免拷贝全部文件。
4
更快的切换:Alluxio将底层存储抽象化,使得数据团队能够轻松地在云厂商、本地或多云环境中迁移数据。数据迁移无需替换硬件,也不会导致停机。
部署Alluxio后,企业通过针对数据访问进行优化的数据架构,可以构建出性能卓越、可扩展的数据平台,从而加速模型开发,满足不断增长的数据需求。
✦
【近期热门】
✦

✦
【宝典集市】
✦






本文分享自微信公众号 - Alluxio(Alluxio_China)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。