[The principle of computer composition] study notes - general catalog
[31] GPU (below): Why does deep learning need to use GPU?
introduction
With a graphics accelerator such as 3dFx's Voodoo or NVidia's TNT, the CPU does not need to deal with pixel-by-pixel primitive processing, rasterization, and fragment processing. And 3D games are also developed from this era.
The image below is a variation of polygon modeling for the Tomb Raider game. This change was brought about by the advancement of graphics cards in the past 20 years from 1996 to 2016.

1. The Birth of Shader and Programmable Graphics Processor [GPU Development History]
1. Introduction of Programable Function Pipeline
-
The emergence of accelerator cards: vertex processing is still done in the CPU , so graphics rendering is still subject to the performance of the CPU [no matter how good the GPU is, if the CPU is not good, it will not work]
-
In 1999, NVidia introduced the GeForce 256 graphics card with vertex processing . However, the GPU has no programmable capability, and the programmer needs to change the configuration of the accelerator card to achieve different rendering effects.
-
The GPU needs programmability: in some special steps of the entire rendering pipeline (Graphics Pipeline), the algorithm or operation of the processing can be customized .
Starting with Direct3D 8.0 in 2001, Microsoft introduced the concept of Programable Function Pipeline for the first time.
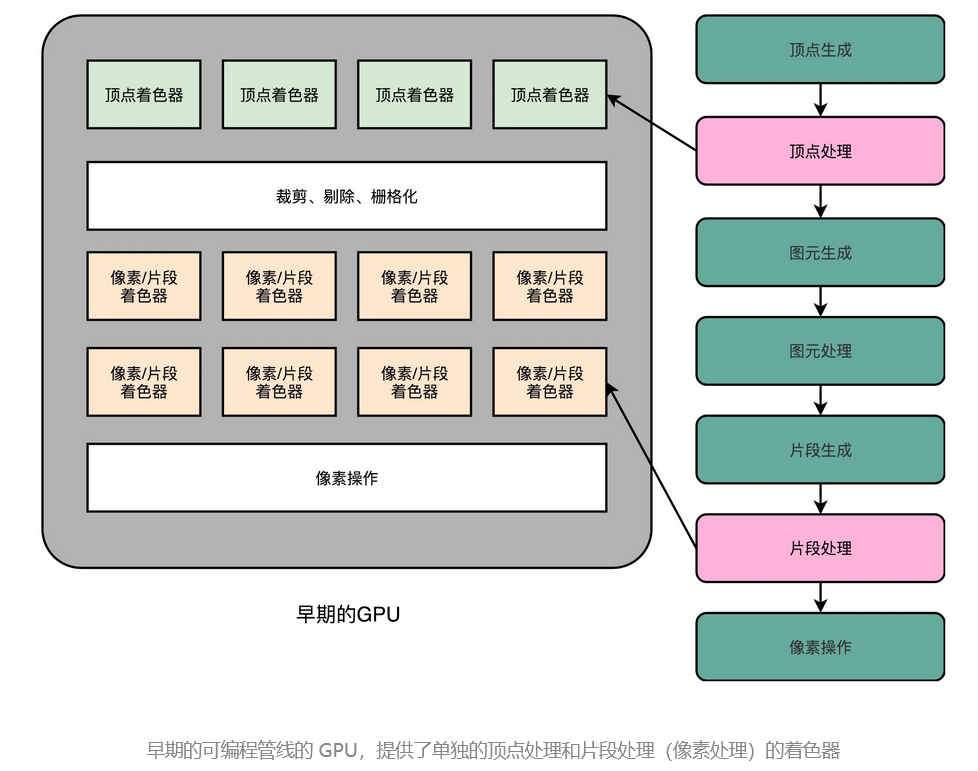
2. The emergence of shaders
The programmable pipeline at the beginning is limited to the vertex processing (Vertex Processing) and fragment processing (Fragment Processing) part. Compared with the fixed configuration that can only be provided through graphics interfaces such as graphics cards and Direct3D, programmers can finally start to show their talents in graphics effects.
These programmable interfaces, we call them Shader , the Chinese name is the shader . The reason why they are called "shaders" is that these "programmable" interfaces can only modify the program logic of vertex processing and fragment processing at the beginning. What we do with these interfaces is mainly the processing of lighting, brightness, color, etc. , so it is called shader.
Although the instruction sets of Vertex Shader and Fragment Shader are the same, the hardware circuits are separated [which can reduce the complexity of hardware design], which will cause waste [one is running, the other does nothing], and the GPU cost is higher.
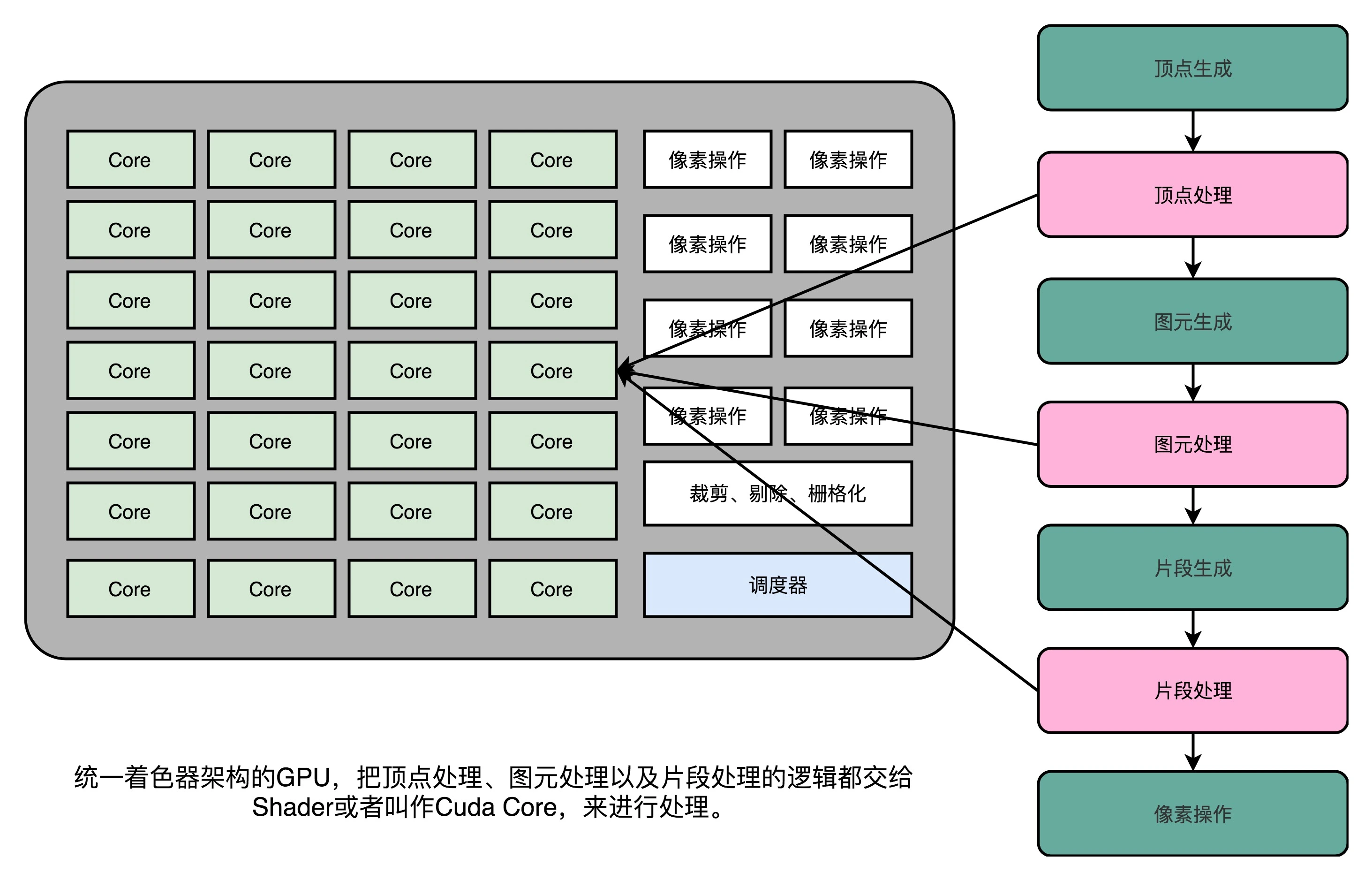
3. The emergence of Unified Shader Architecture
Since the instruction set used by everyone is the same , it is better to put many identical Shader hardware circuits in the GPU , and then through unified scheduling , the tasks of vertex processing, primitive processing, and fragment processing are handed over to these Shaders for processing. , keeping the entire GPU as busy as possible . This design is ourThe Design of Modern GPUs,that isUnified Shader Architecture.
Interestingly, such a GPU did not appear in the PC first, but came from a game console, Microsoft's XBox 360. Later, this architecture was used in ATI and NVidia graphics cards. At this time, the role of "shader" has little to do with its name, but has become the name of a general abstract computing module.
[GPU is used to do various general-purpose calculations (the hotness of deep learning)]
just becauseShader becomes a "universal" module, only then the GPU is used for various general-purpose computing , that is, GPGPU (General-Purpose Computing on Graphics Processing Units, general-purpose graphics processor) . It is precisely because GPUs can be used for various general-purpose calculations that the past 10 years haveThe boom in deep learning.
2. The three core ideas of modern GPUs
After talking about the evolutionary history of modern GPUs, let's take a look at why modern GPUs are so fast in graphics rendering and deep learning.
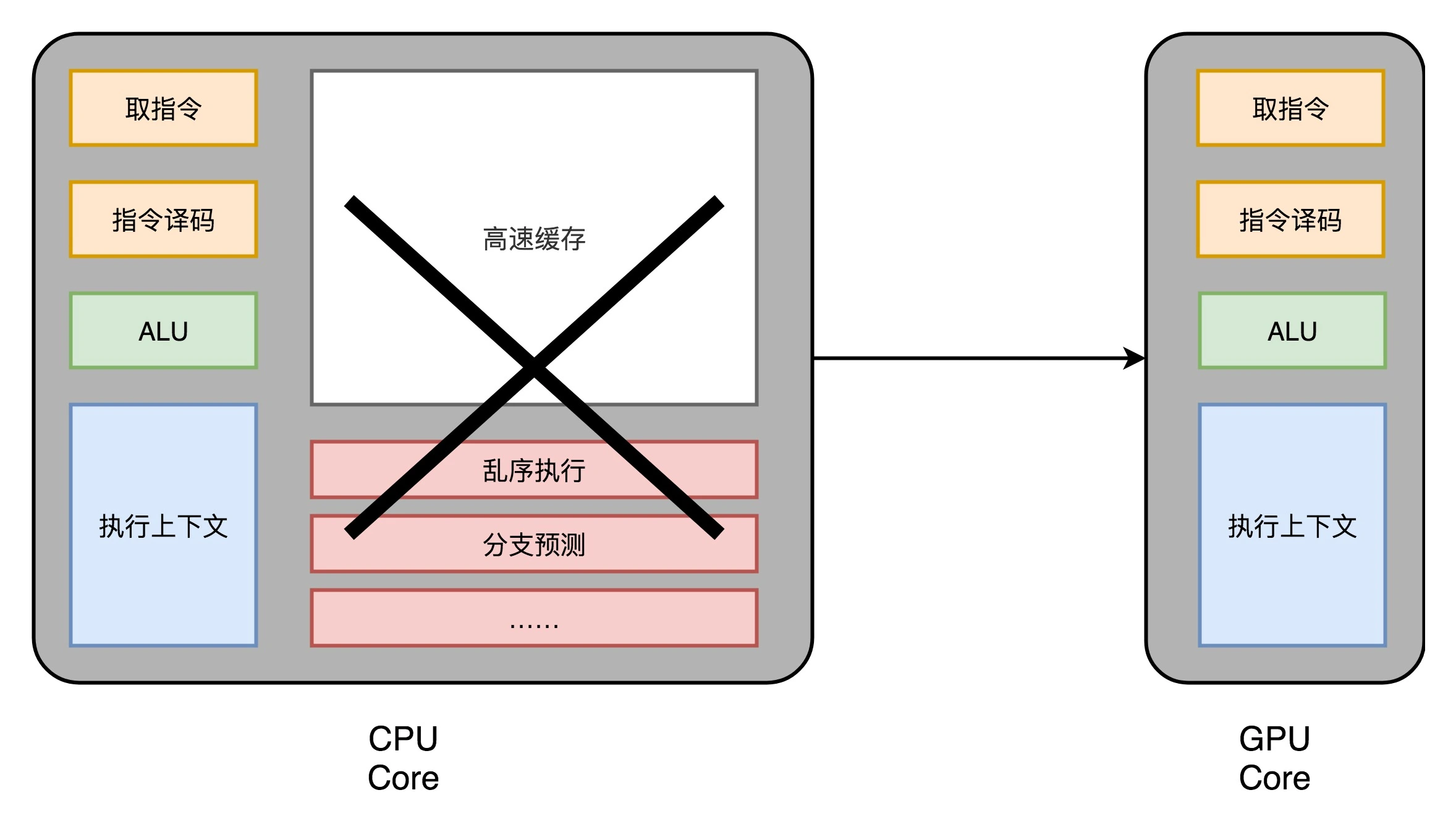
1. Chip slimming [reduce redundant circuits (circuits that deal with various risks)]
[CPU is mainly used to handle out-of-order execution, branch prediction, cache part -> calculation function will not have a greater improvement]
Let's start by reviewing the modern CPUs that have spent a lot of time talking about. The transistors in modern CPUs are becoming more and more complex . In fact, they are no longer used to realize the core function of "computing", but are used to handle out-of-order execution, branch prediction, and we will later store in memory. Speaking of the cache part .
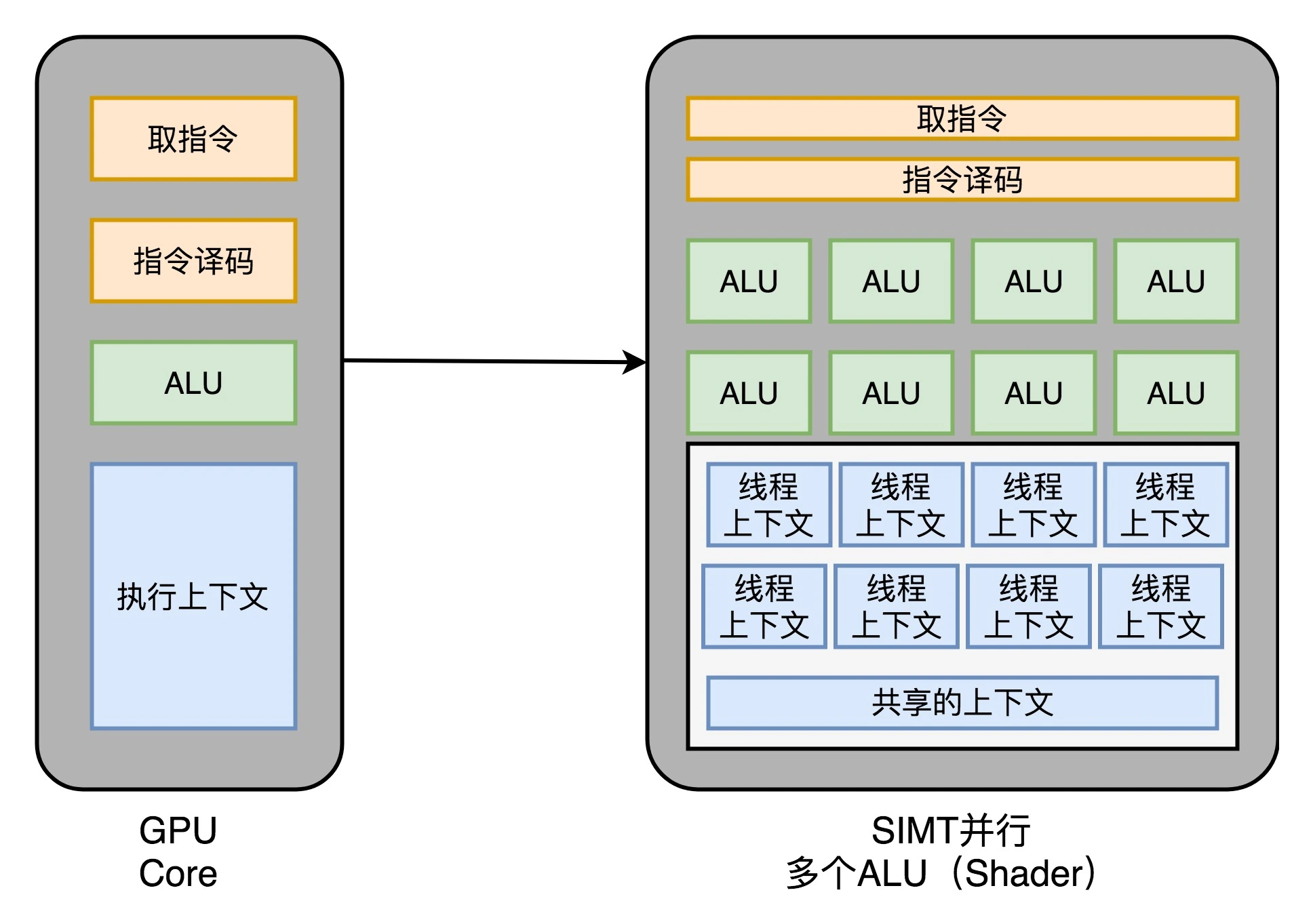
In the GPU, these circuits are a bit redundant, and the entire processing process of the GPU is a stream processing (Stream Processing) process. Because there are not so many branch conditions or complex dependencies , we can remove these corresponding circuits in the GPU and make a small downsizing, leaving only instruction fetching, instruction decoding, ALU and what is needed to perform these calculations. Registers and caches are just fine. Generally speaking, we will abstract these circuits into three parts , as shown in the figure below(1) Instruction Fetch and Instruction Decode, (2) ALU and (3) Execution Context.
2. Multi-core parallelism and SIMT [multiple parallel ALUs]
In this way, our GPU circuit is much simpler than the CPU . Therefore, we can plug a lot of such parallel GPU circuits into a GPU to implement calculations, just like a multi-core CPU in a CPU. Unlike the CPU, we do not need to implement any multi-threaded computing separately . becauseGPU operations are naturally parallel.
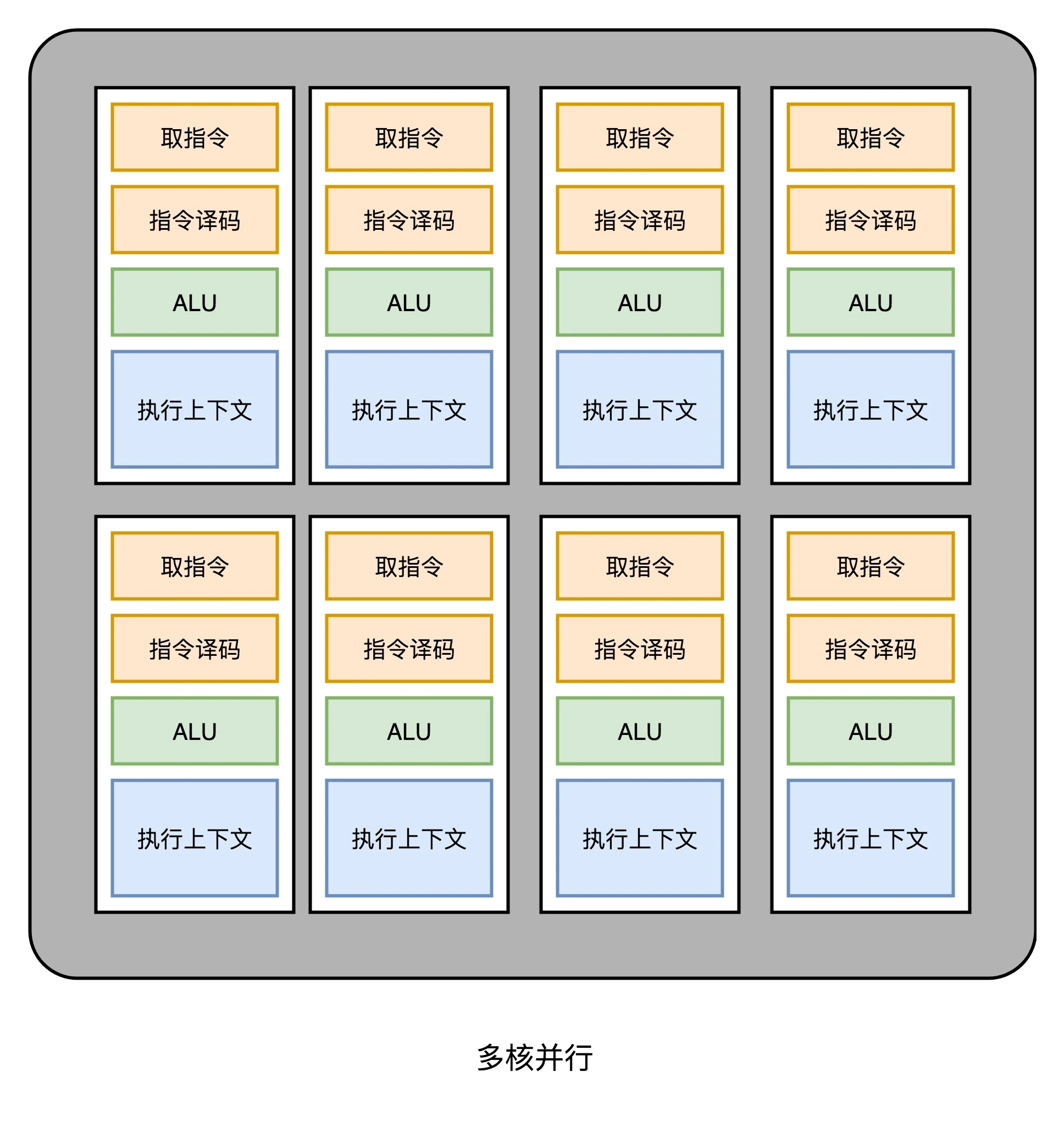 We have actually seen in the previous lecture that whether it is processing vertices in the polygon or processing each pixel in the screen, the calculation of each point is independent . So, simply adding a multi-core GPU can achieve parallel acceleration . However, this acceleration is not enough. Engineers feel that there is still room for further squeezing of performance.
We have actually seen in the previous lecture that whether it is processing vertices in the polygon or processing each pixel in the screen, the calculation of each point is independent . So, simply adding a multi-core GPU can achieve parallel acceleration . However, this acceleration is not enough. Engineers feel that there is still room for further squeezing of performance.
[Introduction of SIMT (Single Instruction, Multiple Threads)]
As we mentioned in Lecture 27, there is a processing technology called SIMD in the CPU. This technique means that when doing vector calculations, the instructions to be executed are the same, but the data of the same instruction is different. In the GPU rendering pipeline, this technique can be very useful.
Whether it is linear transformation of vertices, or lighting and coloring of adjacent pixels on the screen, the same instruction flow is used for calculation . Therefore, the GPU borrows the SIMD in the CPU and uses a method calledSIMT (Single Instruction, Multiple Threads) technology. SIMT is more flexible than SIMD. In SIMD, the CPU takes out multiple data of a fixed length at one time, puts it in the register, and usesan instructionto execute . SIMT, on the other hand, can send multiple pieces of data todifferent threadsto deal with .
The instruction flow executed in each thread is the same, but it may go to different conditional branches according to different data . In this way, the same code and the same process may execute different specific instructions. This thread goes to the conditional branch of if, and the other thread goes to the conditional branch of else.
Therefore, our GPU design can be further evolved , that is, in the stage of instruction fetching and instruction decoding, the fetched instructions can be given to multiple different ALUs for parallel operations . In this way, in the core of one of our GPUs, more ALUs can be put down, and more parallel operations can be performed at the same time.
3. "Hyperthreading" in GPU [more execution context]
Although the GPU is mainly based on numerical calculation. However, since it is already a "general computing" architecture, conditional branches such as if...else cannot be avoided in the GPU. However, in the GPU we don't have the branch prediction circuitry of the CPU. These circuits have already been cut off by us when the "chips are thinned" above.
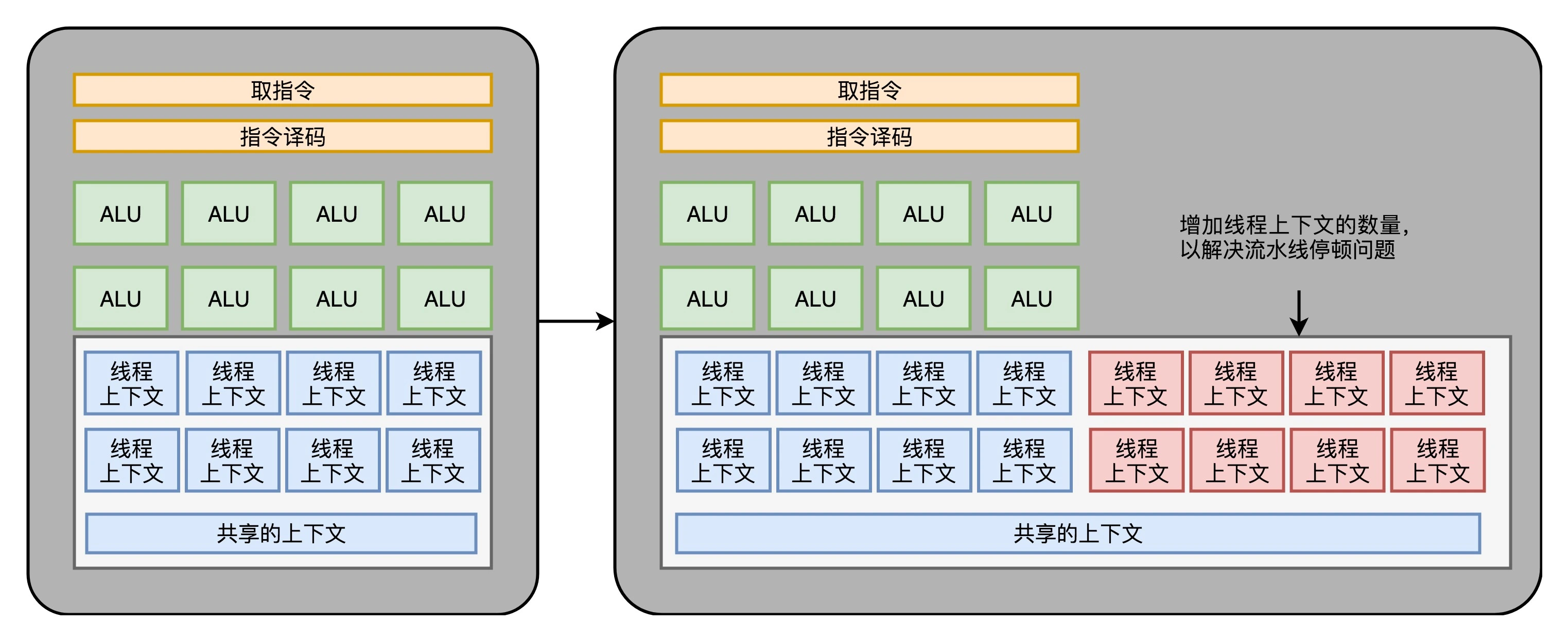
Therefore, the instructions in the GPU may encounter a "pipeline stall" problem similar to that of the CPU . When you think of pipeline stalls, you should be able to recall that we talked about hyperthreading technology in CPUs before. On the GPU, we can also do similar things, that is, when we encounter a pause, schedule some other computing tasks to the current ALU .
Like hyperthreading, since we want to schedule a different task, we need to provide more execution context for this task . Therefore, the number of execution contexts in a Core needs to be more than ALU .
3. The performance difference of GPU in deep learning [compared with CPU]
With chip thinning, SIMT, and more execution contexts, we have a GPU that's better at parallelizing brute force . Such chips are also suitable for our deep learning usage scenarios today.
On the one hand, the GPU is a framework that can perform **"general computing", and we can implement different algorithms on the GPU through programming .
On the other hand, the current deep learning calculations are all calculations of large vectors and matrices and massive training samples . In the whole calculation process, there is no complex logic and branching , which is very suitable for a parallel and powerful architecture such as GPU.
1. Instance calculation [It takes some time to clarify what each value of the calculation represents]
When we look at the technical specifications of the NVidia 2080 graphics card , we can figure out how much computing power it has.
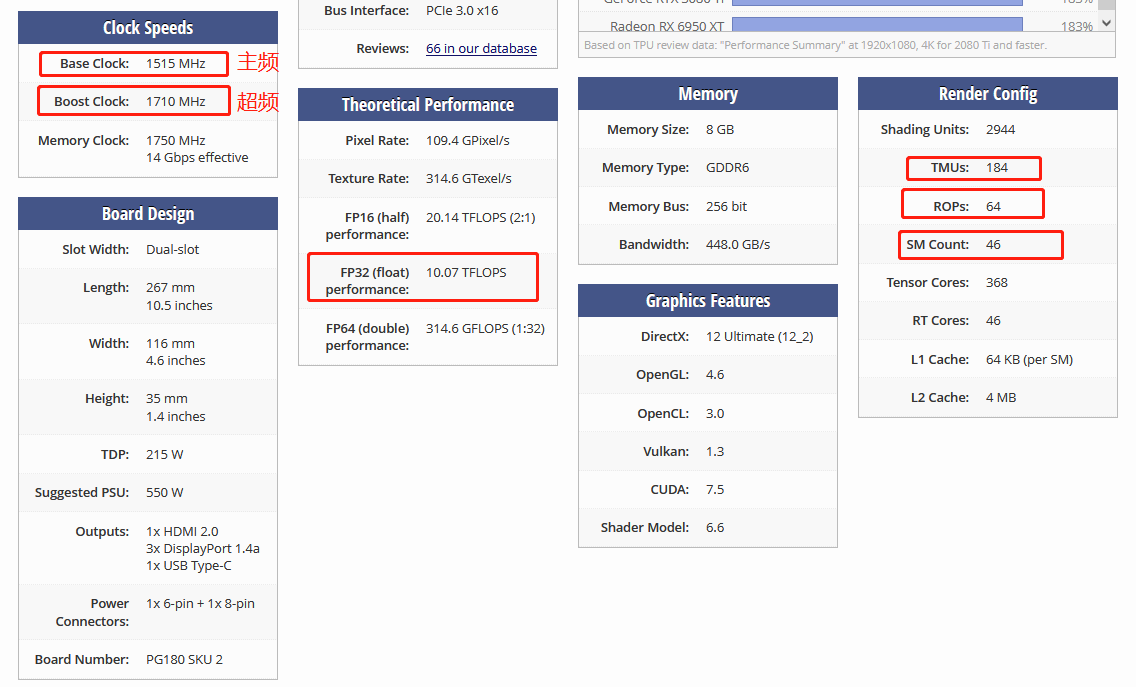
The 2080 has a total of 46 SMs (Streaming Multiprocessors), which are equivalent to the GPU Core in the GPU, so you can think of it as a 46-core GPU with 46 rendering pipelines for fetching and decoding instructions. There are 64 Cuda Cores in each SM . You can think that the Cuda Core here is the number of ALUs or the number of Pixel Shaders we mentioned above . There are 2944 Shaders in 46x64 . Then, there are 184 TMUs . TMU is Texture Mapping Unit, which is the calculation unit used for texture mapping. It can also be considered as another type of Shader .

 The main frequency of the 2080 is 1515MHz , if it is automatically overclocked (Boost) , it can reach 1700MHz . The NVidia graphics card, according to the design of the hardware architecture, can execute two instructions per clock cycle [How is this done?] . Therefore, the ability to do floating-point arithmetic is:
The main frequency of the 2080 is 1515MHz , if it is automatically overclocked (Boost) , it can reach 1700MHz . The NVidia graphics card, according to the design of the hardware architecture, can execute two instructions per clock cycle [How is this done?] . Therefore, the ability to do floating-point arithmetic is:
(2944 + 184)× 1700 MHz × 2 = 10.06 TFLOPS
【doubt】I actually calculated it to be 10.63 TFLOPS: 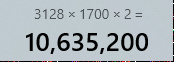 , where is the problem?
, where is the problem?
Check the official technical specifications, it is exactly 10.07TFLOPS.
2. Compare CPU performance—>Conclusion
So, what is the performance of the latest Intel i9 9900K ? Less than 1TFLOPS【How to calculate? ? ?] . The price of 2080 graphics card and 9900K is similar .
Therefore, in the actual process of deep learning, the time spent using GPU can often be reduced by one to two orders of magnitude . And large-scale deep learning model calculations are often multi-card parallel, which takes days or even months. At this time, it is obviously not suitable to use the CPU.
Today, with the introduction of GPGPU,GPU is not only a graphics computing device, but also a good tool for numerical computing. Likewise, the rapid development of GPUs has brought about the boom in deep learning over the past 10 years .
4. Summary [Key points of personal summary]
-
1. The history of GPU development
-
- Accelerator card (vertex processing is still done on CPU, image rendering is limited by CPU performance )
-
- Graphics cards with vertex processing : NVidia unveils GeForce 256 graphics cards
-
- Introduction of Programable Function Pipeline : Direct3D 8.0 in 2001 [first introduced by Microsoft]
-
- Programmable pipeline at the beginning: limited to vertex processing and fragment processing. The programmable interface is called Shader , that is, shader. At this time, the hardware circuits are separated, which will cause waste of resources [one is running, the other does nothing]
-
- Unified Shader Architecture [design of modern GPU] appeared: Shader hardware circuits are unified , any task of graphics rendering is uniformly scheduled by GPU, and then processed by Shader.
- [Application of GPU to deep learning] Because Shader becomes a "universal" module , it can be used for various general-purpose calculations , namelyGPGPU(General-Purpose Computing on Graphics Processing Units, general graphics processor). It is precisely because GPUs can be used for various general-purpose calculations that deep learning has become popular in the past 10 years .
-
-
2. The three core ideas of modern GPUs
-
- Chip slimming [reduce redundant circuits (circuits that deal with various risks)]
-
- Multi-core parallelism and SIMT (Single Instruction, Multiple Threads) [multiple parallel ALUs]
-
- "Hyperthreading" in GPU [More Execution Contexts]
-
-
3. The advantages of GPU in deep learning[Must understand: the process of instance calculation]
[The principle of computer composition] study notes - general catalog