

新世代のビジュアル生成パラダイム「VAR: Visual Auto Regressive」が登場!GPT スタイルの自己回帰モデルは、画像生成において初めて拡散モデルを上回り、大規模言語モデルと同様のScaling Laws スケーリング則とゼロショット タスク一般化能力が観察されます。
论文标题:ビジュアル自己回帰モデリング: 次スケールの予測によるスケーラブルな画像生成
VAR と呼ばれるこの新しい研究は、北京大学とByteDanceの研究者によって提案され、GitHub と Paperwithcode のホット リストに掲載されており、同業者から多くの注目を集めています。
現在、エクスペリエンス Web サイト、論文、コード、モデルがリリースされています。
- 体験サイト:https://var.vision/
- 論文リンク: https://arxiv.org/abs/2404.02905
- オープンソースコード: https://github.com/FoundationVision/VAR
- オープンソース モデル: https://huggingface.co/FoundationVision/var
背景の紹介
自然言語処理では、GPT や LLaMa シリーズなどの大規模言語モデルを例とした自己回帰モデルが大きな成功を収めています。特に、スケーリング則 とゼロショット タスクの一般化性は非常に印象的なゼロショット タスクの一般化を実現します。 、当初は「汎用人工知能 AGI」につながる可能性を示していました。
ただし、画像生成の分野では、自己回帰モデルは一般に拡散モデルに遅れをとっています。DALL -E3、Stable Diffusion3、 SORAなど、最近人気のあるモデルはすべて Diffusion ファミリーに属しています。さらに、ビジュアル生成の分野に「スケーリング則」があるかどうか、つまり、モデルまたはトレーニングのオーバーヘッドが残っている状態で、テストセットのクロスエントロピー損失が予測可能なべき乗則の下降傾向を示すことができるかどうかはまだ不明です。探求されます。
GPT 形式的自己回帰モデルの強力な機能とスケーリング則は、画像生成の分野では「ロックされている」ようです。

自己回帰モデルは、生成効果リストの多くの拡散モデルより遅れています。
研究チームは、自己回帰モデルとスケーリング則の能力の「ロックを解除する」ことに焦点を当て、画像モダリティの固有の性質から出発し、人間の画像処理の論理シーケンスを模倣し、新しい「視覚的自己回帰」生成パラダイム、VAR、Visual AutoRegressive を提案しました。モデリング 、GPT スタイルの自己回帰ビジュアル生成は、効果、速度、およびスケーリング機能の点で Diffusion を初めて上回り、ビジュアル生成の分野におけるスケーリング則の先駆けとなりました。

VAR 手法の核心: 人間の視覚を模倣し、画像の自己回帰シーケンスを再定義する
人間が画像や絵を認識するとき、まず概要を把握し、次に詳細を掘り下げる傾向があります。粗いものから細かいものへ、全体の把握から部分の微調整まで、このような考え方は非常に自然です。
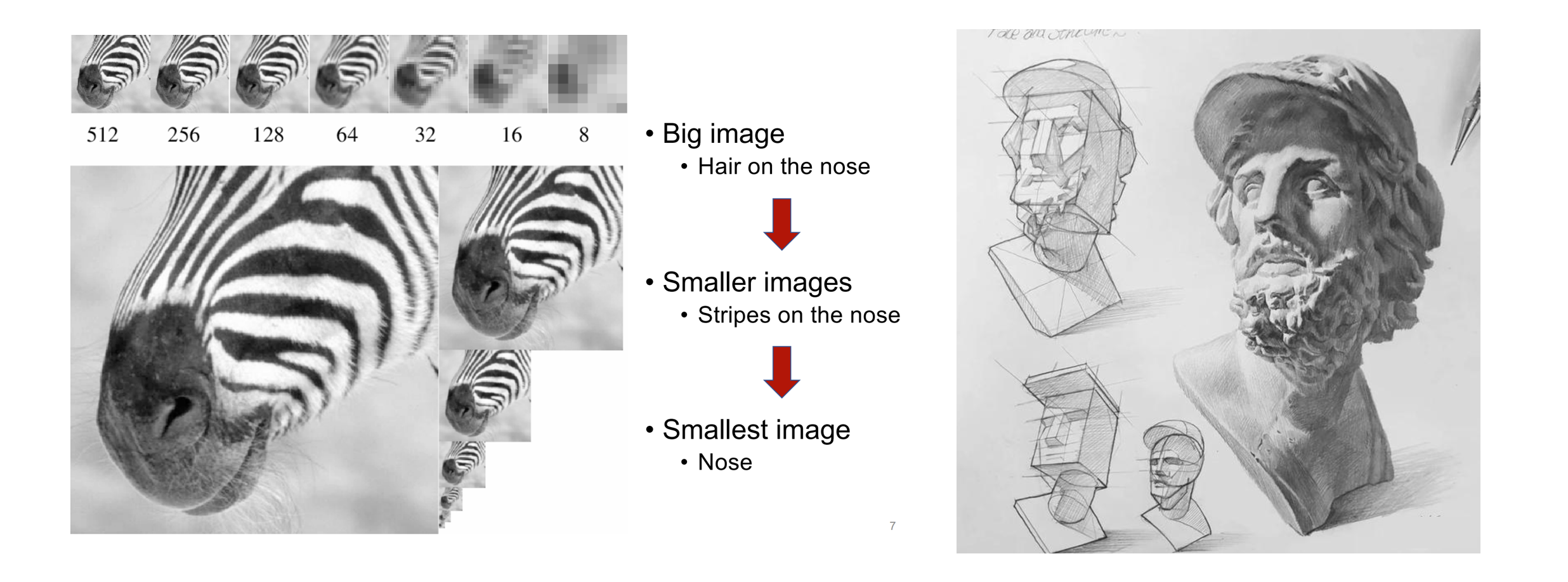
人間の絵の認識(左)と絵画の作成(右) の粗いものから細かいものまでの論理的順序
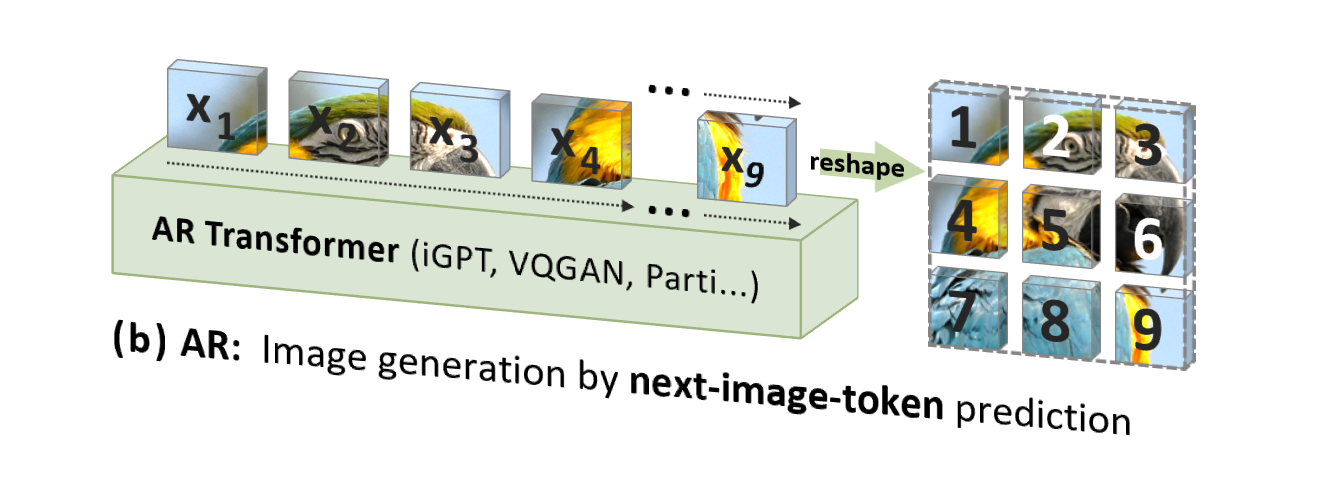
ただし、従来の画像自動回帰 (AR) は、人間の直感とは一致しない (ただしコンピューター処理には適している) 順序、つまりトップダウンの行ごとのラスター順序を使用して、画像トークンを 1 つずつ予測します。 :
VAR は「人間指向」であり、人間の知覚または人間が作成した画像の論理シーケンスを模倣し、全体から詳細までのマルチスケール シーケンスを使用してトークン マップを徐々に生成します。
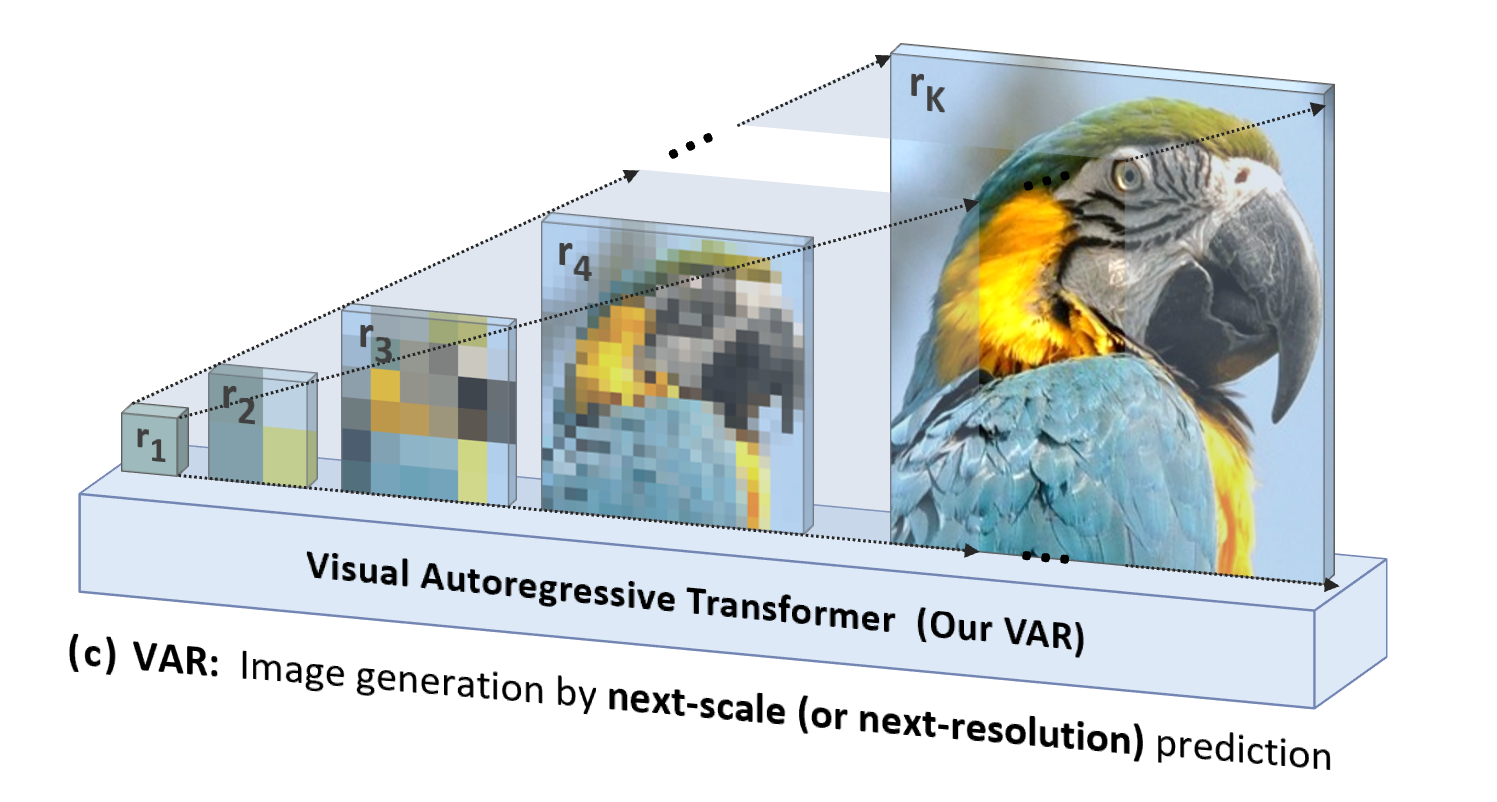
より自然で人間の直感に沿っていることに加えて、VAR によってもたらされるもう 1 つの重要な利点は、生成速度が大幅に向上することです。自己回帰の各ステップ (各スケール内) で、すべてのイメージ トークンが一度に並行して生成されます。スケール それは自己回帰です。これにより、モデル パラメーターと画像サイズが同等の場合、VAR は従来の AR よりも数十倍高速になります。さらに、実験では、VAR が AR よりも優れたパフォーマンスとスケーリング機能を発揮することも観察しました。
VAR 手法の詳細: 2 段階のトレーニング
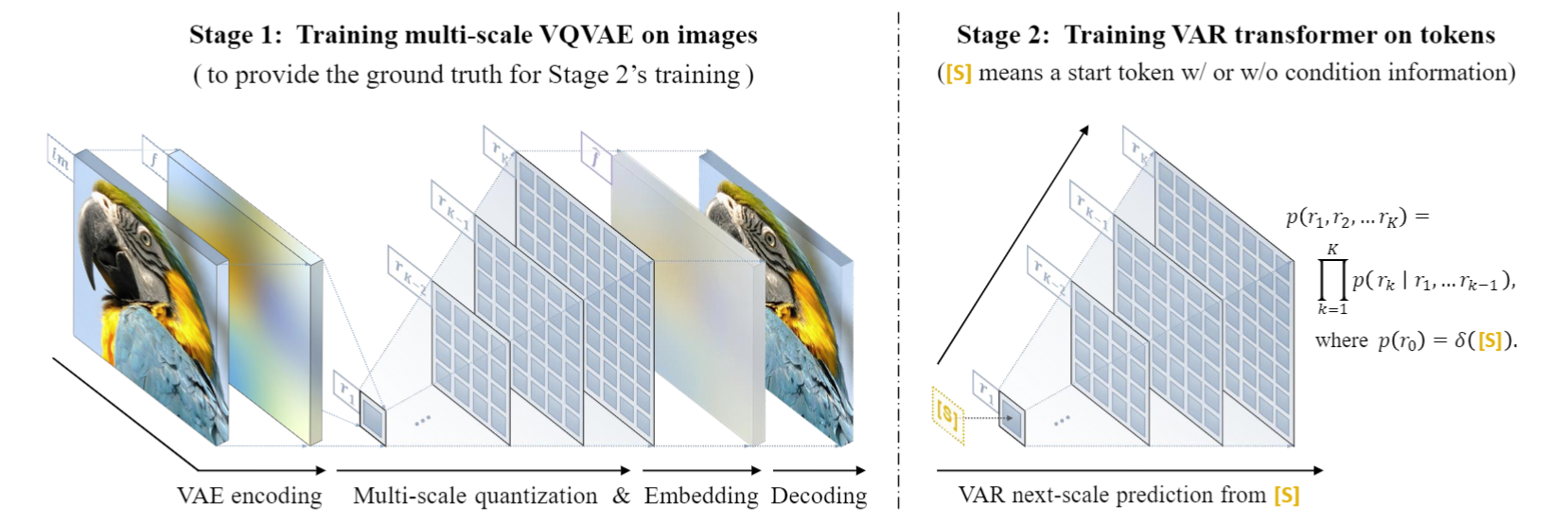
VAR は、第 1 段階でマルチスケール量子化自動エンコーダー(マルチスケール VQVAE) をトレーニングし、第 2 段階でGPT-2 構造 (AdaLN と組み合わせた) と一致する自己回帰トランスフォーマーをトレーニングします。
左の図に示すように、VQVAE のトレーニング前編の詳細は次のとおりです。
- 離散コーディング: エンコーダは、ピクチャを離散トークン マップ R=(r1, r2, ..., rk) に変換します。解像度は小さいものから大きいものまであります。
- 連続化: r1 から rk は、最初に埋め込み層を通じて連続特徴マップに変換され、次に rk に対応する最大解像度まで均一に補間され、合計されます。
- 連続デコード: 合計された特徴マップはデコーダを通過して再構成された画像を取得し、3 つの損失 (再構成 + 知覚 + 対立) の混合を通じてトレーニングされます。
右の図に示すように、VQVAE トレーニングが完了すると、自己回帰 Transformer トレーニングの第 2 段階が実行されます。
- 自己回帰の最初のステップは、開始****トークン [S]から最初の1x1トークン マップを予測することです。
- 後続の各ステップで、VAR はすべての過去のトークン マップに基づいて、次に大きなスケールのトークン マップを予測します。
- トレーニング段階では、VAR は標準のクロスエントロピー損失を使用して、これらのトークン マップの確率予測を監視します。
- テスト段階では、サンプリングされたトークン マップがシリアル化、補間、合計され、VQVAE デコーダーを使用してデコードされて、最終的に生成されたイメージが取得されます。
著者は、VAR の自己回帰フレームワークはまったく新しいものであり、その特定のテクノロジーは、RQ-VAE の残留 VAE、StyleGAN と DiT の AdaLN、PGGAN のプログレッシブ トレーニングなどの一連の古典的なテクノロジーの長所を吸収していると述べました。 VAR は実際には巨人の肩の上に立っており、自己回帰アルゴリズム自体の革新に焦点を当てています。
実験効果の比較
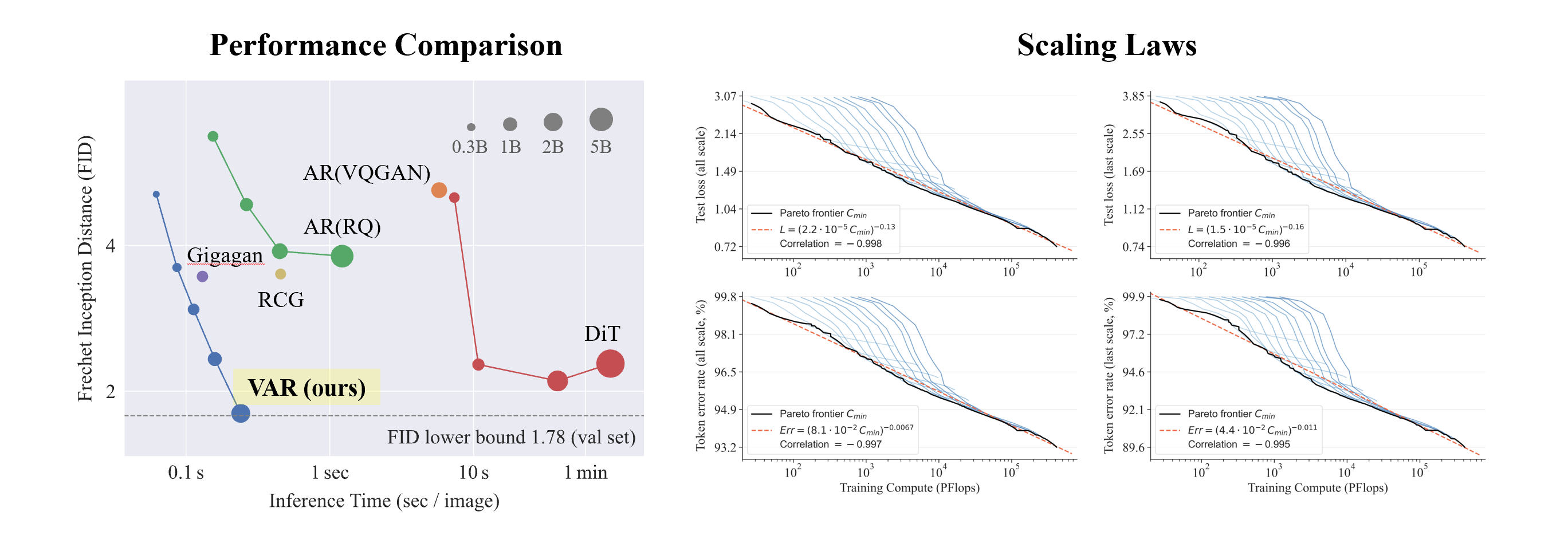
Conditional ImageNet 256x256 および 512x512 での VAR 実験:
- VAR は AR の効果を大幅に改善し、AR が Diffusion に後れを取る状況を改善しました。
- VAR は10 の自己回帰ステップのみを必要とし、その生成速度は AR や拡散を大幅に上回り、GAN の効率にさえ近づきます。
- VAR を2B/3Bにスケールアップすることにより、VAR は SOTA レベルに到達し、新しい生成モデルの潜在的なファミリーを示しています。

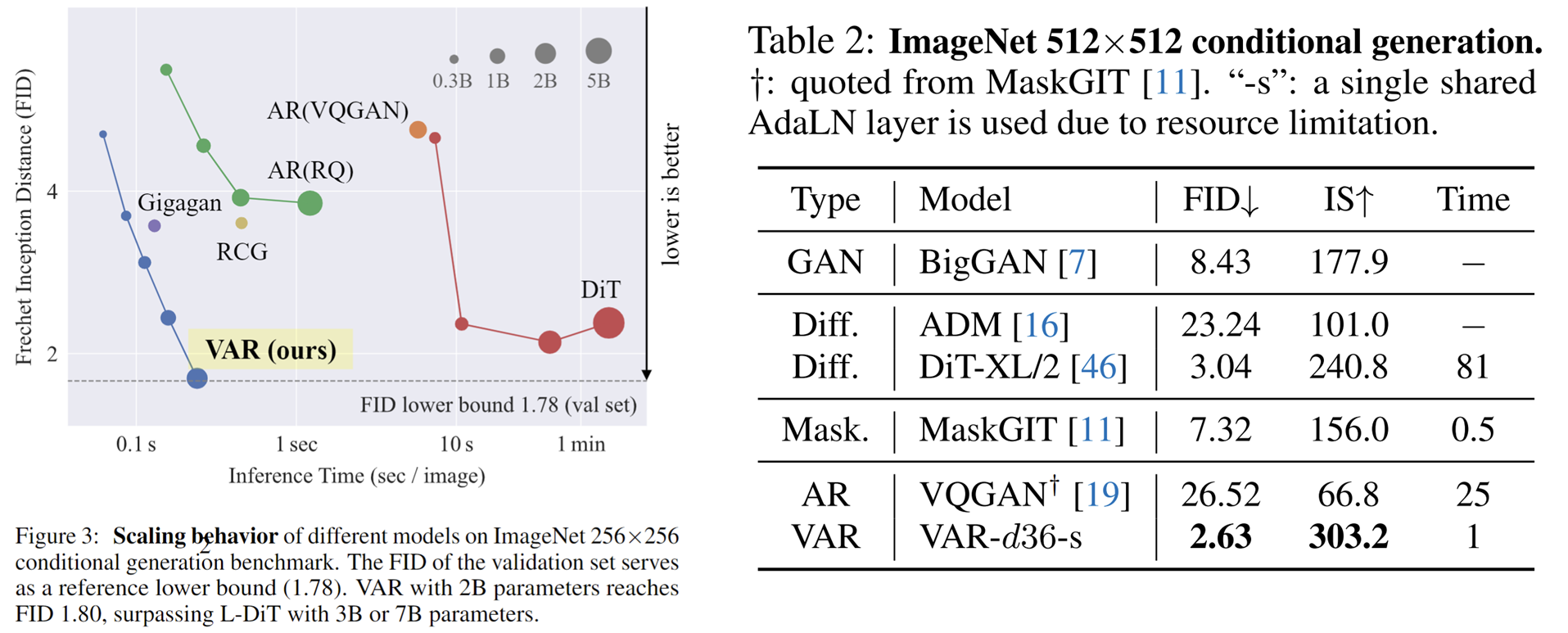
興味深いのは、SORA および Stable Diffusion 3 の基礎モデルである Diffusion Transformer (DiT)と比較して、VAR が次のことを示していることです。
- より良い結果:スケールアップ後、VAR は最終的に FID=1.80 に達し、理論上の FID 下限である 1.78 (ImageNet 検証セット) に近づき、DiT の最適値 2.10 よりも大幅に優れています。
- 高速化: VAR は256 の画像を0.3 秒未満で生成できます。これは、512 の場合の45 倍、DiT の81 倍の速度です。
- より優れたスケーリング機能: 左の図に示すように、DiT の大規模モデルは3B および 7B に成長した後に飽和を示し、VAR が 20 億パラメーターに拡張される一方で、パフォーマンスは向上し続けました。ついにFID下限に到達しました
- より効率的なデータ利用: VAR は350エポック トレーニングのみを必要とし、これは DiT の1400エポック トレーニングよりも多くなります。
DiT よりも効率的、高速、スケーラブルであるというこれらの証拠は、次世代のビジュアル生成インフラストラクチャ パスにさらなる可能性をもたらします。
スケーリング則の実験
スケーリング則は、大規模な言語モデルの「最高の宝石」と言えます。関連する研究によると、自己回帰大規模言語モデルをスケールアップするプロセスにおいて、テスト セットのクロス エントロピー損失 L は、モデル パラメーターの数 N、トレーニング トークンの数 T、および計算オーバーヘッドに応じて予想通り減少することが判明しました。 Cmin .べき乗則の関係を明らかにします。
スケーリング則により、小さなモデルに基づいて大規模なモデルのパフォーマンスを予測できるようになり、コンピューティングのオーバーヘッドとリソース割り当てが節約されるだけでなく、自己回帰 AR モデルの強力な学習能力も反映され、テスト セットのパフォーマンスは N、T、および に応じて向上します。分。
実験を通じて、研究者らは、VAR が LLMと ほぼ同じべき乗則スケーリング則を示すことを観察しました。研究者らは 12 サイズのモデルをトレーニングし、スケーリング モデル パラメータの数は 1,800 万から 20 億の範囲で、総計算量は 6 に及びました。桁が大きいため、トークンの最大合計数は 3,050 億に達し、L と Cmin の間のテスト セット損失 L またはテスト セット エラー率と N が滑らかなべき乗則の関係を示し、適合性が良好であることが観察されます。 :
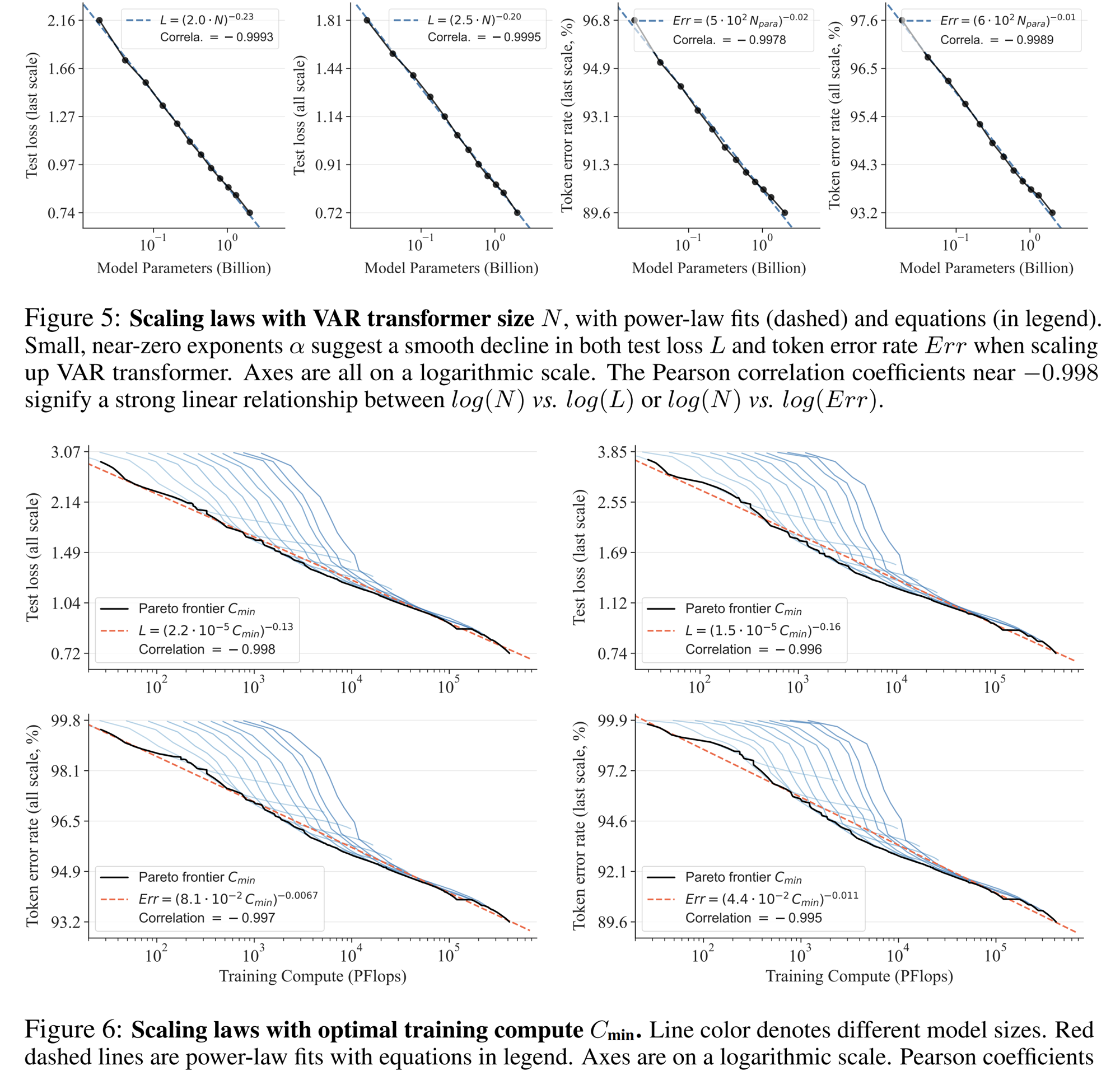
モデルのパラメーターと計算量をスケールアップする過程で、モデルの生成能力が徐々に向上していることがわかります (以下のオシロスコープのストライプなど)。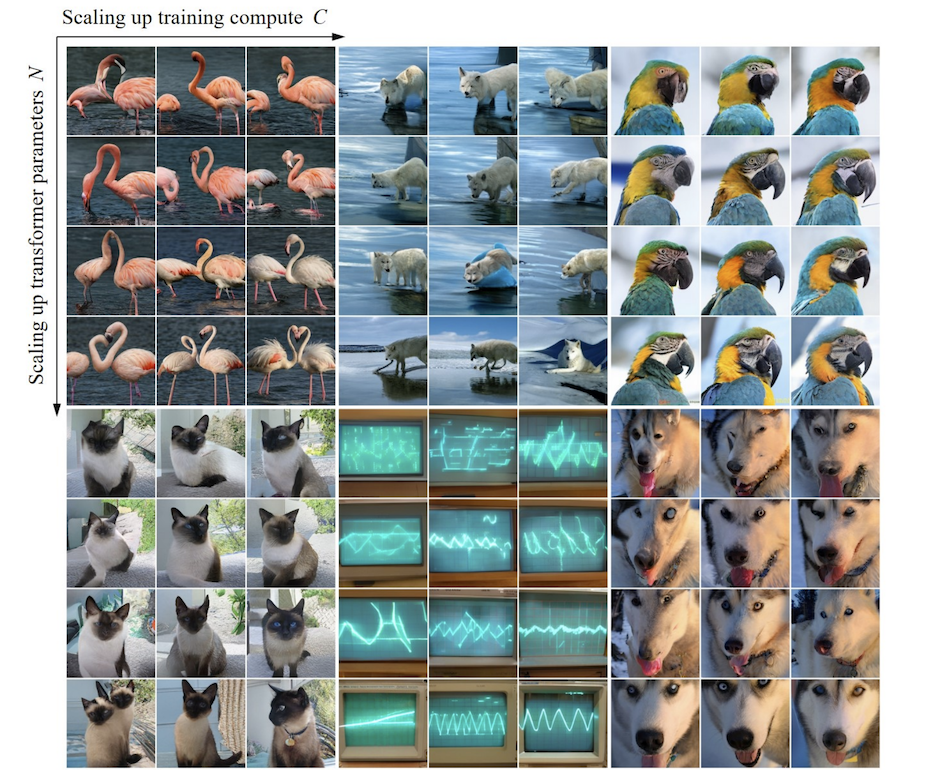
ゼロショット実験
教師強制メカニズムを使用して特定のトークンを強制的に変更しないようにできるという自己回帰モデルの優れた特性のおかげで、VAR は特定のゼロサンプル タスクの一般化機能も示します。条件付き生成タスクでトレーニングされた VAR Transformer は、画像補完 (インペイント)、画像外挿 (アウトペイント)、画像編集 (クラス条件編集) など、微調整なしで一部の生成タスクに一般化できます。 )、一定の結果を達成しました。
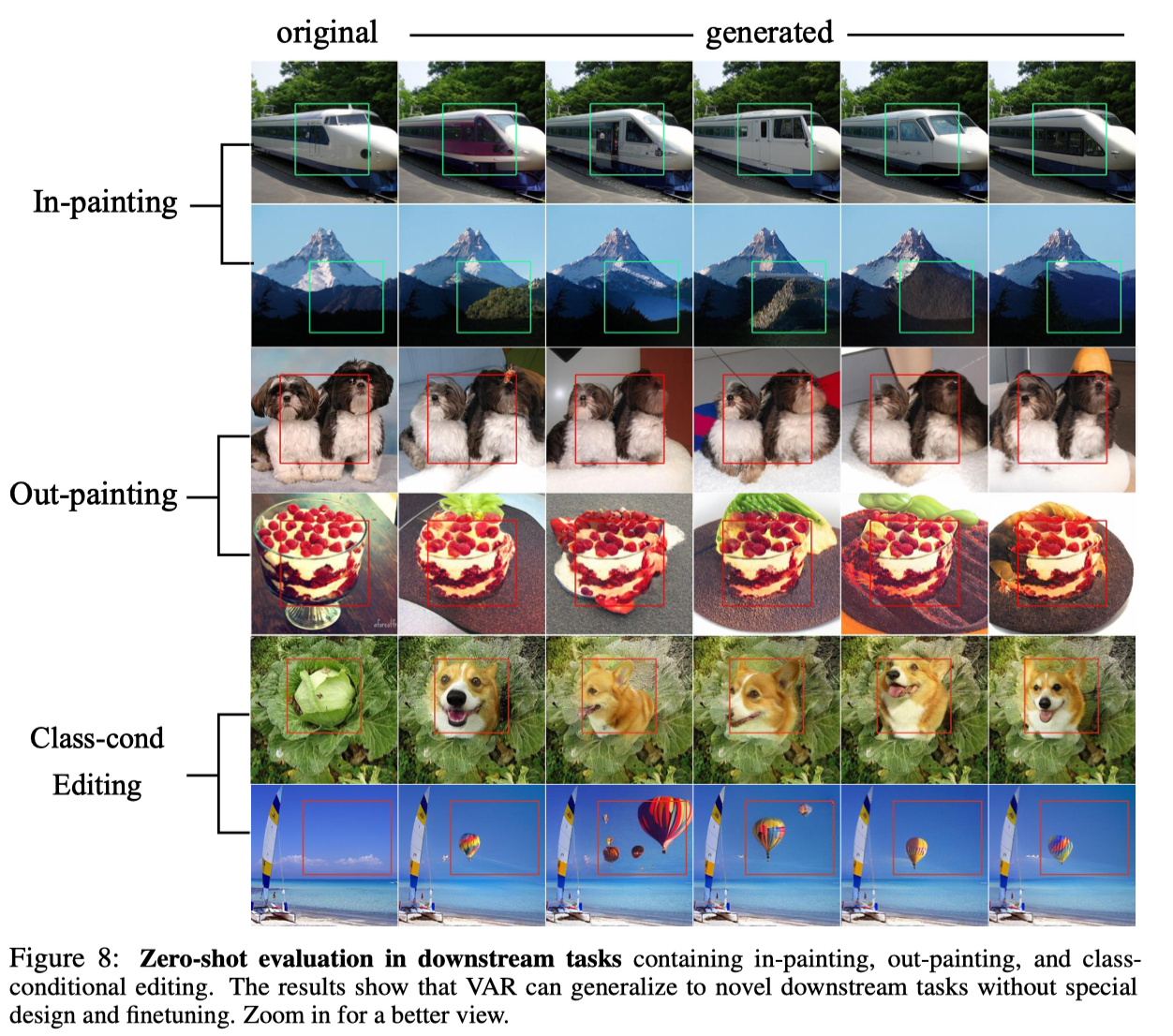
結論は
VAR は、画像の自己回帰シーケンス、つまり、粗いものから細かいもの、全体的な輪郭から局所的な微調整までのシーケンスを定義する方法について、新しい視点を提供します。このような自己回帰アルゴリズムは直感と一致していますが、良い結果をもたらします。VAR は自己回帰モデルの速度と生成品質を大幅に向上させ、多くの面で初めて自己回帰モデルが拡散モデルを上回ります。同時に、VAR はLLM と同様のスケーリング則とゼロショット一般化可能性を示します。著者らは、VAR のアイデア、実験結果、およびオープンソースが、画像生成分野における自己回帰パラダイムの使用に関するコミュニティの探求に貢献し、将来的には自己回帰に基づく統合マルチモーダル アルゴリズムの開発を促進できることを期待しています。
Bytedance 商用化 - GenAI チームについて
ByteDance Commercialization-GenAI チームは、高度な生成人工知能テクノロジーの開発と、テキスト、画像、ビデオを含む業界をリードする技術ソリューションの作成に重点を置いており、生成 AI を使用して自動クリエイティブ ワークフローを実現することで、広告主に広告主を提供し、クリエイティブの効率と推進力を向上させます。価値。
チームのビジュアル生成および LLM の方向性に関するさらに多くのポジションが募集されています。ByteDance の採用情報に注目してください。
仲間のニワトリがDeepin-IDE を 「オープンソース」化し、ついにブートストラップを達成しました。 いい奴だ、Tencent は本当に Switch を「考える学習機械」に変えた Tencent Cloud の 4 月 8 日の障害レビューと状況説明 RustDesk リモート デスクトップ起動の再構築 Web クライアント WeChat の SQLite ベースのオープンソース ターミナル データベース WCDB がメジャー アップグレードを開始 TIOBE 4 月リスト: PHPは史上最低値に落ち、 FFmpeg の父であるファブリス ベラールはオーディオ圧縮ツール TSAC をリリースし 、Google は大規模なコード モデル CodeGemma をリリースしました 。それはあなたを殺すつもりですか?オープンソースなのでとても優れています - オープンソースの画像およびポスター編集ツール