
Open-Sora はオープンソース コミュニティで静かに更新されました。 1 つのレンズで最大 720p の解像度で最大 16 秒のビデオ生成がサポートされ、任意のアスペクト比のテキストから画像、テキストからビデオ、画像からビデオ、ビデオからビデオ、および長さ無制限のビデオ生成を処理できるようになりました。ニーズ。効果を試してみましょう。
横画面のクリスマス雪景色を生成してBサイトに投稿

再度縦画面を作成してDouyinを作成します

ワンショットで 16 秒の長いビデオを生成することもできるので、誰もが脚本作りに夢中になることができます。

遊び方?GitHub へのアクセス: github.com/hpcaitech/Open-Sora
さらに素晴らしいのは、Open-Sora の最新バージョンが依然としてオープンソースであり、ウェアハウスには最新のモデル アーキテクチャ、最新のモデルの重み、マルチタイム/解像度/アスペクト比/フレーム レートのトレーニング プロセス、データ収集が含まれていることです。前処理の完全なプロセス、すべてのトレーニングの詳細、デモの例、詳細な入門チュートリアル。
1. テクニカルレポートの包括的な解釈
最近、Open-Sora の作者チームは最新版のテクニカル レポート [1] を GitHub 上で正式にリリースしました。以下では、このテクニカル レポートを使用して、機能、アーキテクチャ、トレーニング方法、データ収集、前処理などを解釈します。側面を一つずつ。
1.1 最新機能の概要
Open-Sora のこのアップデートには主に次の主要な機能が含まれています。
- 長いビデオの生成をサポートします。
- ビデオ生成解像度は最大 720p に達します。
- 単一のモデルで、あらゆるアスペクト比、さまざまな解像度と継続時間、テキストから画像、テキストからビデオ、画像からビデオ、ビデオからビデオ、および無制限のビデオ生成のニーズをサポートします。
- マルチタイム/解像度/アスペクト比/フレーム レート トレーニングをサポートする、より安定したモデル アーキテクチャ設計を提案しました。
- 最新の自動データ処理プロセスはオープンソースです。
1.2 時空拡散モデル
Open-Sora のこのアップグレードでは、モデルのトレーニングの安定性と全体的なパフォーマンスの向上を目的として、バージョン 1.0 の STDiT アーキテクチャに重要な改善が加えられました。現在のシーケンス予測タスクでは、チームは大規模言語モデル (LLM) のベスト プラクティスを採用し、時間的注意における正弦波位置エンコーディングをより効率的な回転位置エンコーディング (RoPE 埋め込み) に置き換えました。
さらに、トレーニングの安定性を高めるために、SD3 モデル アーキテクチャを参照し、さらに QK 正規化技術を導入して半精度トレーニングの安定性を高めました。複数の解像度、異なるアスペクト比、およびフレーム レートのトレーニング要件をサポートするために、著者のチームが提案した ST-DiT-2 アーキテクチャは、位置エンコーディングを自動的にスケールし、異なるサイズの入力を処理できます。
1.3 多段階トレーニング
技術レポートによると、Open-Sora はマルチステージ トレーニング方法を使用しており、各ステージは前のステージの重みに基づいてトレーニングを継続します。この多段階トレーニングでは、単一段階のトレーニングと比較して、段階的にデータを導入することで高品質のビデオ生成という目標をより効率的に達成します。
- 初期段階: ほとんどのビデオは 144p の解像度を使用し、トレーニング用に写真と 240p および 480p のビデオが混合されます。トレーニングは約 1 週間続き、合計ステップ サイズは 81k です。
- 第 2 段階: トレーニング時間 1 日、ステップ サイズ 22k で、ほとんどのビデオ データの解像度を 240p および 480p に高めます。
- 第 3 段階: 480p および 720p にさらに強化され、トレーニング期間は 1 日で、4k ステップのトレーニングが完了します。多段階のトレーニング プロセス全体は約 9 日間で完了しました。
1.0 と比較して、最新バージョンではビデオ生成の品質が多面的に向上しています。
1.4 統合された画像生成ビデオ/ビデオ生成フレームワーク
著者チームは、Transformer の特性に基づいて、DiT アーキテクチャを簡単に拡張して、画像から画像、およびビデオからビデオのタスクをサポートできると述べました。彼らは、画像とビデオの条件付き処理をサポートするマスキング戦略を提案しました。異なるマスクを設定することで、グラフィック ビデオ、ループ ビデオ、ビデオ拡張、ビデオ自動回帰生成、ビデオ接続、ビデオ編集、フレーム挿入などのさまざまな生成タスクをサポートできます。
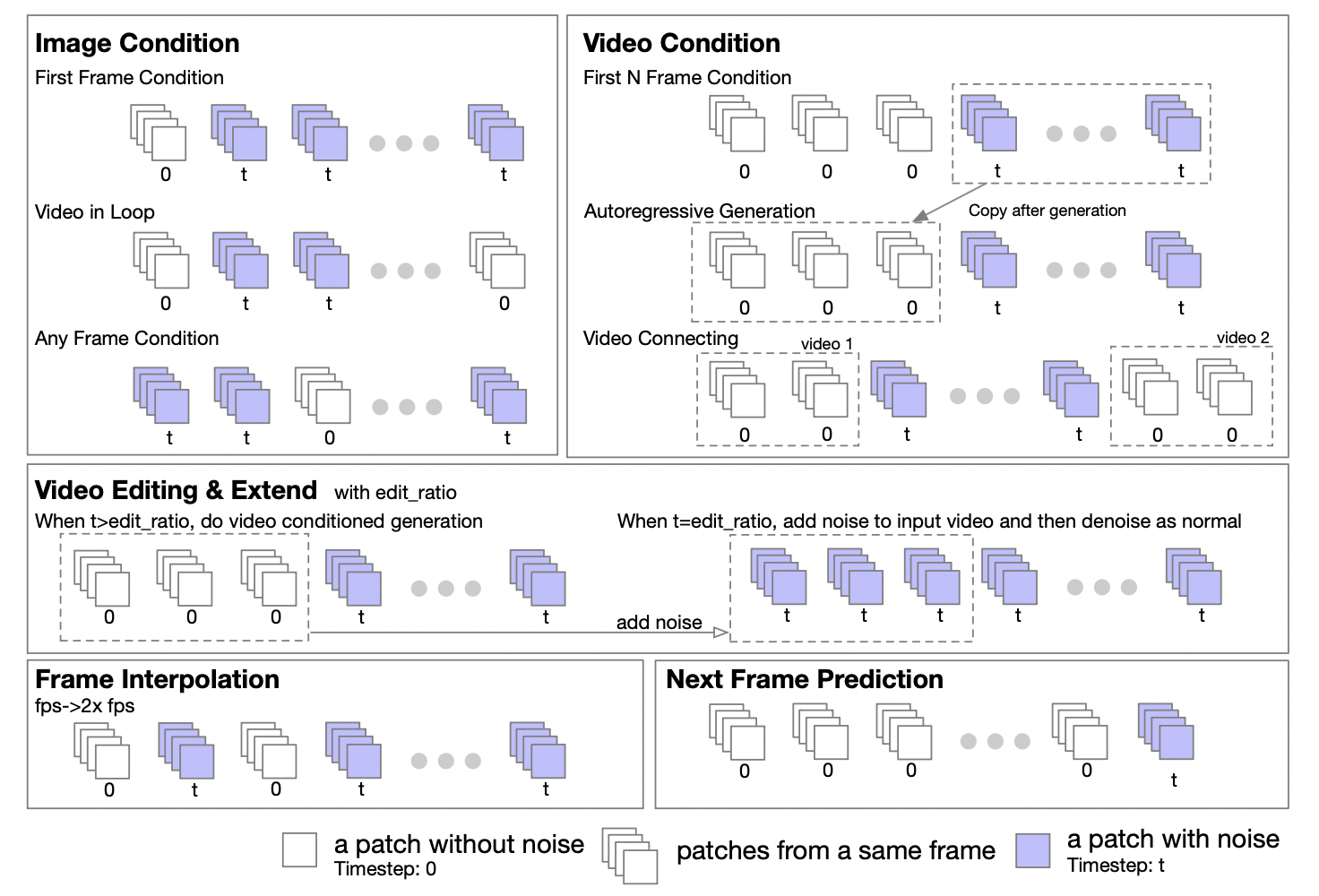
UL2[2] メソッドに触発されて、彼らはモデルのトレーニング段階でランダム マスキング戦略を導入しました。具体的には、トレーニング プロセス中にフレームをランダムに選択してマスクを解除します。これには、最初のフレーム、最初の k フレーム、次の k フレーム、任意の k フレームなどのマスク解除が含まれますが、これらに限定されません。このレポートでは、Open-Sora 1.0 での実験に基づいて、50% の確率でマスキング戦略を適用すると、モデルがわずか数ステップで画像調整を適切に学習できることも明らかになりました。 Open-Sora の最新バージョンでは、マスキング戦略を使用してゼロから事前トレーニングする方法が採用されました。
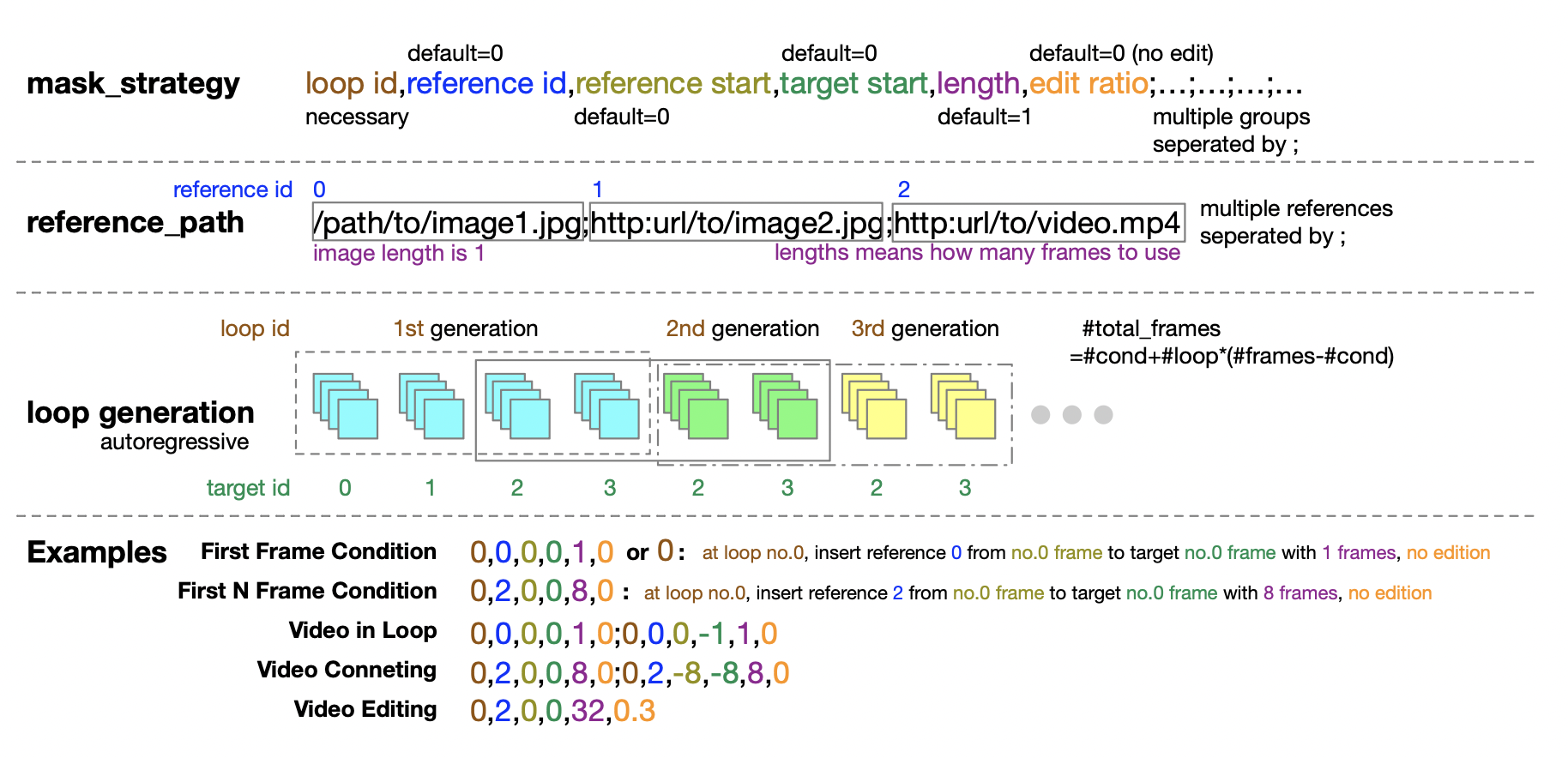
さらに、作成者チームは、推論段階のマスキング ポリシー設定に関する詳細なガイダンスも提供しています。5 つの数値のタプル形式により、マスキング ポリシーを定義する際に優れた柔軟性と制御が提供されます。
1.5 マルチタイム/解像度/アスペクト比/フレーム レート トレーニングをサポート
OpenAI Sora の技術レポート [3] では、元のビデオの解像度、アスペクト比、長さを使用したトレーニングにより、サンプリングの柔軟性が向上し、フレームと構成が改善される可能性があると指摘しています。これに関して、著者チームはバケット化戦略を提案しました。
具体的にはどうやって実装すればいいのでしょうか?著者が公開した技術レポートを詳しく読んだところ、いわゆるバケットが(解像度、フレーム数、アスペクト比)の3つであることがわかりました。これらは、最も一般的なビデオ アスペクト比タイプをカバーするために、さまざまな解像度のビデオのアスペクト比の範囲を事前定義します。各トレーニング サイクルepochが開始される前に、データセットを再シャッフルし、サンプルの特性に基づいて対応するバケットにサンプルを割り当てます。具体的には、各サンプルを、解像度とフレーム長がそのビデオ特徴以下のバケットに入れます。
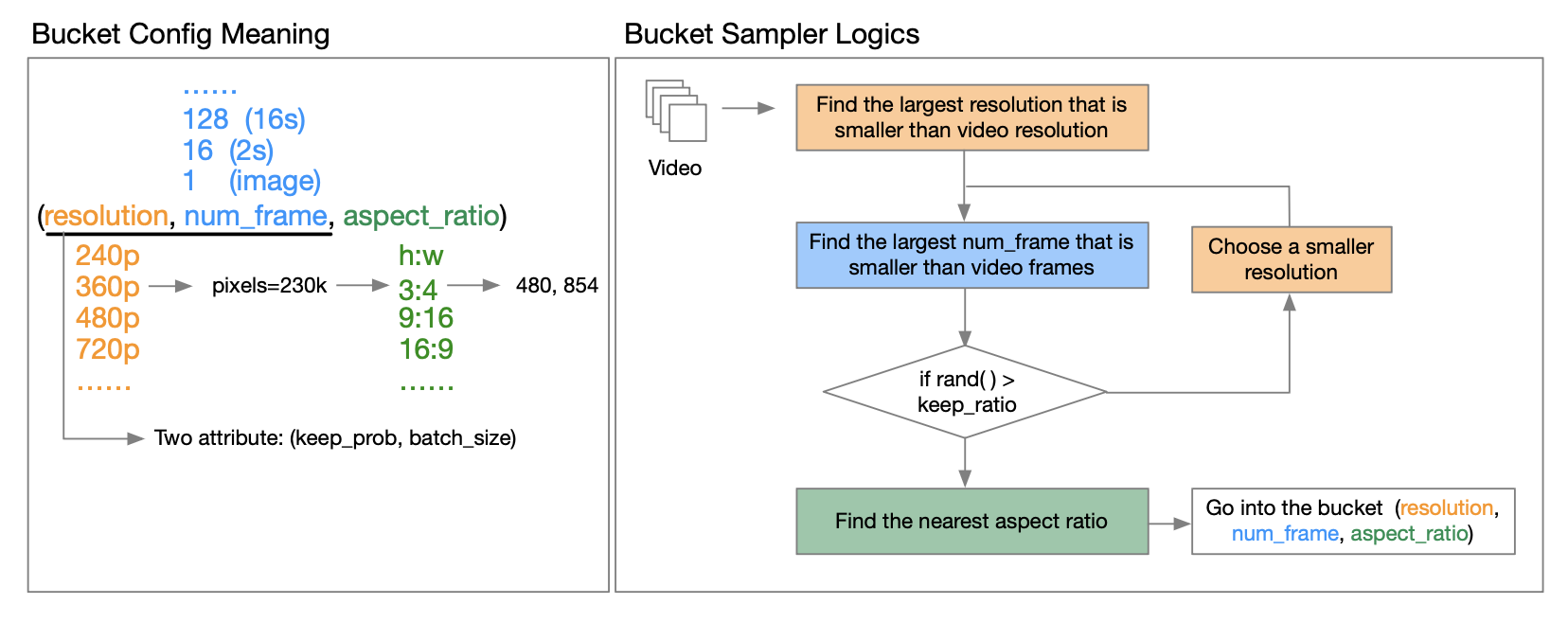
計算リソース要件を削減するために、それぞれに2 つの属性 (解像度、フレーム数) を導入しkeep_prob、計算コストを削減し、多段階トレーニングを可能にします。batch_sizeこれにより、さまざまなバケットのサンプル数を制御し、各バケットの適切なバッチ サイズを検索して GPU 負荷のバランスをとることができます。これについては技術レポートで詳しく説明されていますので、興味のある方は GitHub の技術レポートを読んで詳細をご覧ください。
GitHub アドレス: github.com/hpcaitech/Open-Sora
1.6 データ収集と前処理プロセス
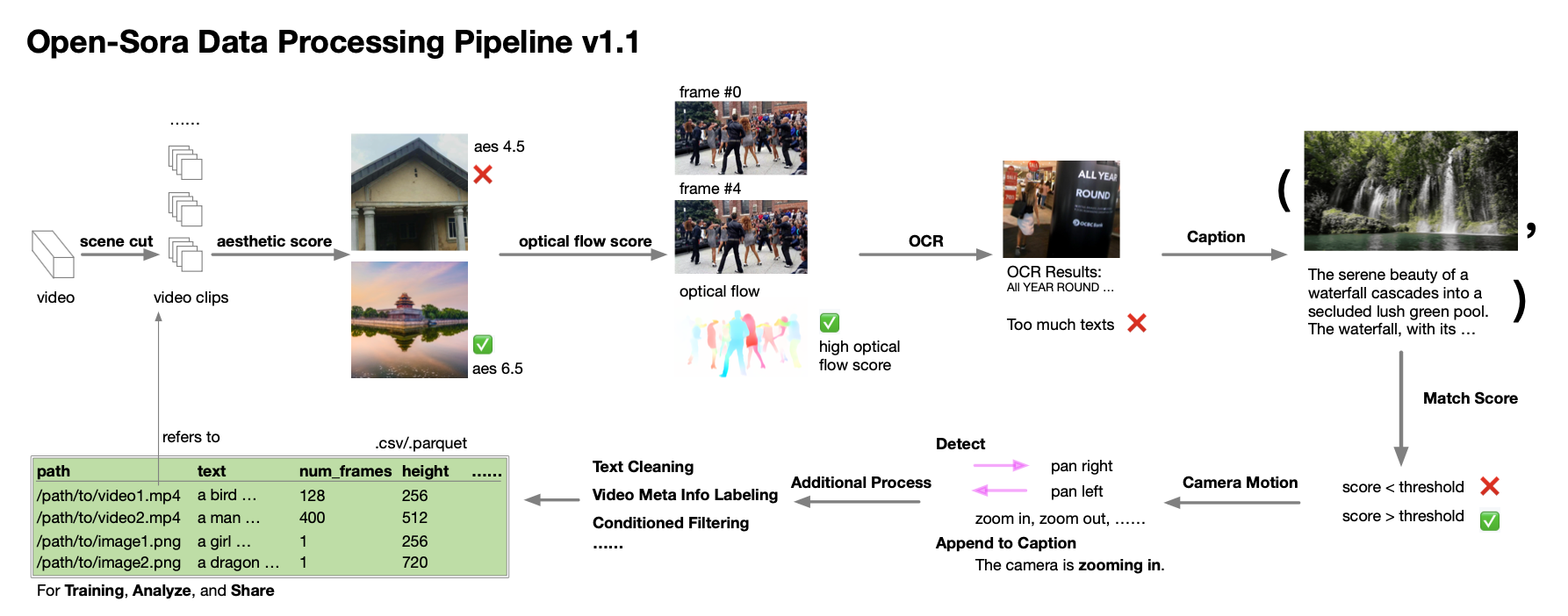
著者チームは、データの収集と処理に関する詳細なガイダンスも提供します。技術レポートによると、Open-Sora 1.0 の開発プロセス中に、高性能モデルを育成するにはデータの量と質が非常に重要であることに気づき、データセットの拡張と最適化に取り組みました。彼らは、特異値分解 (SVD) 原理に従い、シーンのセグメンテーション、字幕処理、多様性のスコアリングとフィルタリング、さらにデータセットの管理システムと仕様をカバーする自動データ処理プロセスを確立しました。
同様に、彼らはデータ処理関連のスクリプトを無私にオープンソース コミュニティに共有します。興味のある開発者は、これらのリソースを技術レポートやコードと組み合わせて使用し、独自のデータセットを効率的に処理および最適化できるようになりました。
2. 総合的な性能評価
技術的な詳細についてはここまで述べましたが、Open-Sora の最新のビデオ生成効果を楽しんでリラックスしましょう。
Open-Sora の今回のアップデートで最も目を引くのは、テキストの説明を通じて頭の中にあるシーンをキャプチャし、動くビデオに変換できることです。あなたの心に浮かんだイメージや想像力を永久に記録し、他の人と共有できるようになりました。ここで、著者は出発点としていくつかの異なるプロンプトを試しました。
2.1 風景
たとえば、著者は冬の森でのツアーのビデオを生成しようとしました。雪が降って間もなく、松の木は白い雪で覆われ、白い雪の結晶がきれいな層に散らばっていました。

あるいは、静かな夜、あなたは無数のおとぎ話に描かれているような暗い森の中にいて、空いっぱいの明るい星の下で深い湖が輝いています。

賑やかな島を上空から見下ろす夜景はさらに美しく、温かみのある黄色の光とリボンのような青い水が人々をゆっくりとした休暇の時間へと誘います。

街は交通量が多く、高層ビルや夜遅くまで灯りの残る路面店はまた違った趣があります。

2.2 自然生物
Open-Sora は風景だけでなく、さまざまな自然生物も復元できます。小さな赤い花でも、

ゆっくりと頭を回すカメレオンであっても、Open-Sora はよりリアルなビデオを生成できます。

2.3 さまざまな解像度/アスペクト比/再生時間
また、作成者はさまざまなプロンプト テストを試し、さまざまなコンテンツ、さまざまな解像度、さまざまなアスペクト比、さまざまな長さを含む、参考のために生成された多数のビデオを提供しました。



また、著者は、Open-Sora が 1 つの簡単なコマンドだけでマルチ解像度のビデオ クリップを生成し、クリエイティブな制限を完全に打ち破ることができることも発見しました。



2.4 土生ビデオ
Open-Sora に静止画像を供給して、短いビデオを生成させることもできます。

Open-Sora では、2 つの静止画を巧みに接続することもできます。下のビデオをクリックすると、午後から夕暮れまでの光と影の変化を体験できます。

2.5 ビデオ編集
別の例として、元のビデオを簡単なコマンドで編集して、元々は明るかった森に大雪が降りかかるようにしたいとします。


2.6 高解像度画像の生成
Open-Sora が高解像度画像を生成できるようにすることもできます。

Open-Sora のモデルの重みがオープン ソース コミュニティで無料で公開されていることは注目に値します。動画のつなぎ合わせ機能にも対応しているので、ストーリー性のあるショートショートストーリーを無料で作成して、あなたの創造性を現実にする機会があることを意味します。
重量のダウンロード アドレス: github.com/hpcaitech/Open-Sora
3. 現状の限界と将来の計画
Open-Sora は、Sora のような Vincent ビデオ モデルの再現において大きな進歩を遂げていますが、作成者チームは、現在生成されているビデオは、生成プロセス中のノイズの問題、時間の不足など、多くの面でまだ改善の必要があることも謙虚に指摘しました。一貫性、キャラクター生成の品質の低さ、美的スコアの低さ。
これらの課題について、作者チームは、より高いビデオ生成基準を達成するために、次のバージョンの開発でそれらを優先的に解決すると述べています。興味のある方は引き続き注目してください。 Open-Sora コミュニティがもたらす次の驚きを楽しみにしています。
GitHub アドレス: github.com/hpcaitech/Open-Sora
参考文献:
[1] https://github.com/hpcaitech/Open-Sora/blob/main/docs/report_02.md
[2] テイ、イーら。 「Ul2: 言語学習パラダイムの統一」 arXiv プレプリント arXiv:2205.05131 (2022)。
[3] https://openai.com/research/video-generation-models-as-world-simulators
私はオープンソース紅蒙を諦めることにしました 、オープンソース紅蒙の父である王成露氏:オープンソース紅蒙は 中国の基本ソフトウェア分野における唯一の建築革新産業ソフトウェアイベントです - OGG 1.0がリリースされ、ファーウェイがすべてのソースコードを提供します。 Google Readerが「コードクソ山」に殺される Fedora Linux 40が正式リリース 元Microsoft開発者:Windows 11のパフォーマンスは「ばかばかしいほど悪い」 馬化騰氏と周宏毅氏が「恨みを晴らす」ために握手 有名ゲーム会社が新たな規制を発行:従業員の結婚祝いは10万元を超えてはならない Ubuntu 24.04 LTSが正式リリース Pinduoduoが不正競争の罪で判決 賠償金500万元