
著者:金雪峰
背景
静的グラフ上で大規模な言語モデルを実行すると、次のような多くの利点があります。
-
オペレーターフュージョンの最適化/グラフ全体の実行によってもたらされるパフォーマンスの向上。Ascend の場合は、グラフ全体のシンク実行を使用してさらにパフォーマンスを向上させることもでき、グラフシンク全体の実行はホスト側のデータ処理実行の影響を受けません。パフォーマンスは安定して良好です。
-
静的メモリ オーケストレーションにより、高いメモリ使用率が可能になり、断片化がなく、バッチ サイズが増加するため、トレーニング パフォーマンスが向上します。
-
実行シーケンスを自動的に最適化し、良好な通信と計算の同時実行性を実現します。
-
……
ただし、静的イメージ上で大規模な言語モデルを実行する場合にも課題があります。最も顕著なのはコンパイルのパフォーマンスです。
ニューラル ネットワーク モデルのコンパイル プロセスでは、Python で表現された nn コードが実際にデータフロー計算グラフに変換されます。
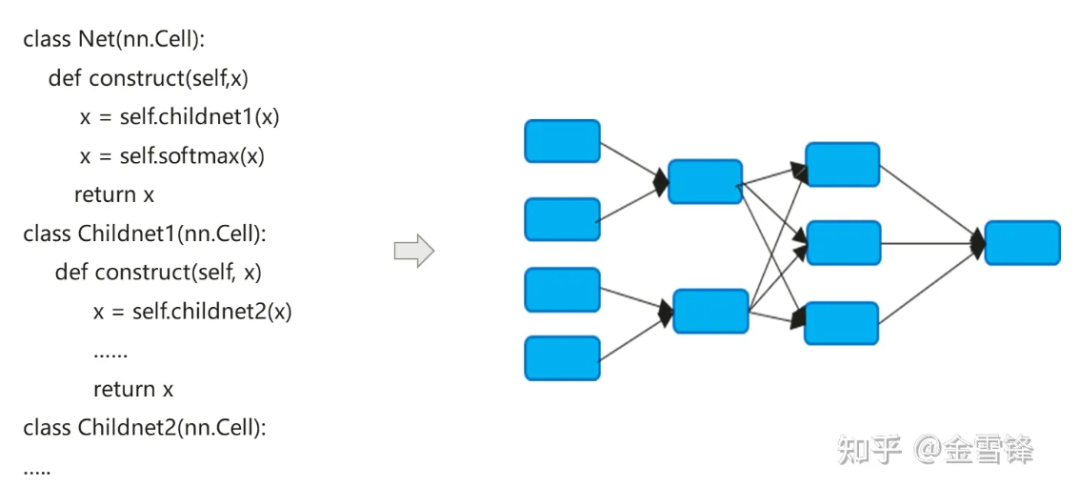
ニューラル ネットワーク モデルのコンパイル プロセスは、従来のコンパイラーとは少し異なります。デフォルトの Inline メソッドは、階層コード式を最終的にフラットな計算グラフに拡張するためによく使用されます。一方で、コンパイルの最適化の機会を最大化します。一方、自動微分と実行ロジックも簡素化できます。
デフォルトでは、Inline 後に形成される計算グラフにはすべての計算ノードが含まれ、ノードにはサブ計算グラフ パーティションがなくなり、定数フォールディング、ノード融合、並列解析など、より大規模なインプロセス最適化を実行できます。など、メモリ割り当てをより適切に実現し、プロシージャ間で呼び出す際のメモリ アプリケーションとパフォーマンスのオーバーヘッドを削減できます。繰り返し呼び出されるコンピューティング ユニットの場合でも、AI 分野のコンパイラーは、プログラム サイズの拡大と実行可能コードの増加という代償を払いながらも、同じインライン戦略を使用して、コンパイル最適化手法を最大限に活用して実行時のパフォーマンスを向上させることができます。
上記の説明からわかるように、インライン最適化は実行時のパフォーマンスを向上させるのに非常に役立ちますが、それに応じて、過剰なインラインはコンパイル時間の負担ももたらします。サブ計算グラフがグラフ全体に統合されると、全体的な観点から見ると、コンパイラーが処理しなければならない計算グラフ ノードの数が急速に増加しています。コンパイラは一般に、最適化メソッドを整理および配置するためにパス メカニズムを使用します。さまざまな最適化メソッドがパスの形式で直列に接続され、処理プロセスが計算グラフの各ノードを通過します。処理パスの数は、ノードとパスのマッチングおよび変換プロセスによって異なります。場合によっては、処理を完了するまでに複数のパスが必要になります。一般に、パスの数が M で、コンピューティング グラフ ノードの数が N の場合、コンパイルと最適化のプロセス全体の時間は、M * N の値に直接関係します。大規模な言語モデルの時代になると、この問題は 2 つの主な理由で顕著になります。1 つは、大規模な言語モデルのモデル構造が深く、多数のノードがあることです。2 つ目は、大規模な言語モデルをトレーニングする場合です。パイプライン並列処理を有効にすると、モデルの規模とノード数がさらに減少します。元のグラフ サイズが O の場合、パイプライン並列処理を有効にすると、単一ノード グラフのサイズは (O/X)*Y になります。ここで、X はパイプラインのステージ数、Y はマイクロバッチの数です。実際の構成プロセスでは、Y は X よりもはるかに大きくなります。たとえば、X は 16 で、Y は通常 64 ~ 192 に設定されます。このように、パイプライン並列化が有効になった後、グラフ コンパイルの規模はさらに元のサイズの 4 ~ 12 倍に増加します。

数百億の言語モデルからなる特定の 13B ネットワークを例にとると、計算グラフ内の計算ノードの数は 135,000 に達し、1 回のコンパイル時間は 3 時間近くになることがあります。
**1.**最適化のアイデア
大規模なモデル言語モデルの下では、これらの層は Transformer ブロックのスタックであり、特にパイプライン並列処理がオンになっている場合、各マイクロ バッチの層はまさにその層であることがわかりました。同じ。そこで、これらの Layer 構造を Inline や Inline なしであらかじめ保持しておくことで、例えばマイクロバッチを境界として、マイクロバッチのサブグラフ構造を保持すれば、コンパイルのパフォーマンスが飛躍的に向上するのではないかと考えます。理論的には、コンパイル時間は元の Y の 1 倍になります (Y はマイクロ バッチの数です)。
モデルに記述されたコードに特有の、同じレイヤーを再利用する方法は、通常、ループまたは反復呼び出しであることがわかります。レイヤーは、反復プロセス内の順次構造の項目 (多くの場合、サブグラフ) に対応します。ループを使用するか、同じコンピューティング ユニットを複数回呼び出すことを繰り返します。以下のコードに示すように、ブロックはレイヤーまたはマイクロ バッチ サブグラフに対応します。
class Block(nn.Cell):
def __init__(self, config):
.......
def construct(self, x, attention_mask, layer_past):
......
class GPT_Model(nn.Cell):
def __init__(self, config):
......
for i in range(config.num_layers):
self.blocks.append(Block)
......
self.num_layers = config.num_layers
def construct(self, input_ids, input_mask, layer_past):
......
present_layer = ()
for i in range(self.num_layers):
hidden_states, present = self.blocks[i](...)
present_layer = present_layer + (present,)
......
したがって、ループ本体を頻繁に呼び出されるサブグラフと見なし、それを Lazy Inline としてマークしてインライン処理を延期するようにコンパイラーに指示すると、コンパイルのほとんどの段階でパフォーマンスの向上が得られます。たとえば、ニューラル ネットワークが同じサブグラフ構造を周期的に呼び出す場合、コンパイル フェーズではサブグラフを展開しません。その後、コンパイルの最後にインライン最適化がトリガーされ、必要な最適化と変換パス処理が実行されます。このように、コンパイラにとっては、ほとんどの場合、インライン展開されたコードではなく、より小規模なコードになるため、コンパイルのパフォーマンスが大幅に向上します。
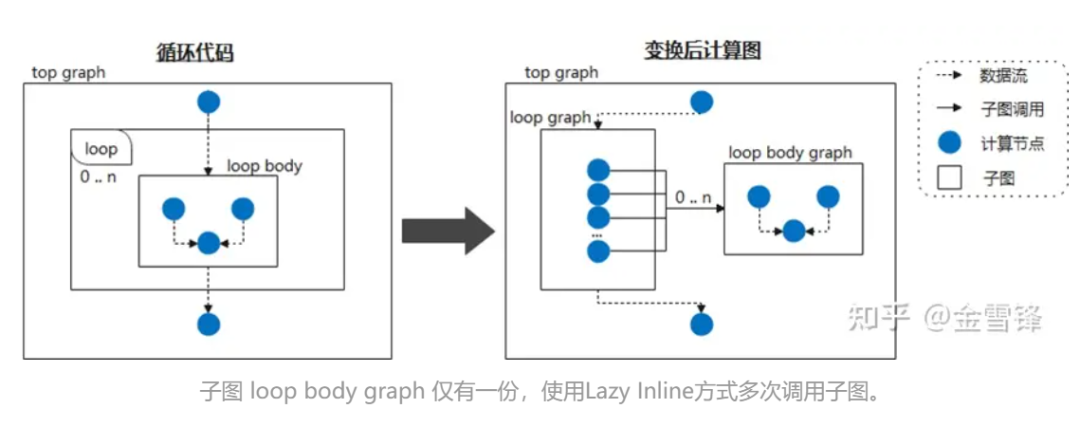
特定の実装中に、関連する Layer クラスに @lazy-inline のようなマークを付けて、マークされた Layer がループ本体内で呼び出されるか、または他の方法で呼び出されるかにかかわらず、インライン展開中には組み込まれません。実行前までは実行されません。
**2. **マインドスポアの実践
Lazy Inline の原理や考え方は複雑ではないようですが、既存の AI グラフのコンパイル メカニズムは一般に完全なコンパイル機能をサポートする種類のコンパイラではないため、この機能を実現するのは依然として非常に困難です。
幸いなことに、MindSpore のグラフ コンパイラは、IR を設計する際に、サブ関数呼び出し、クロージャ、その他の機能を含む汎用性を考慮しています。
① セルインスタンスを再利用可能な計算グラフにコンパイル
Cell は MindSpore ニューラル ネットワークの基本的な構成要素であり、すべてのニューラル ネットワークの基本クラスです。Cell は、conv2d、relu、batch_norm などの単一のニューラル ネットワーク ユニットであることも、1 つのニューラル ネットワークを構築するユニットの組み合わせであることもできます。通信網。 GRAPH_MODE (静的グラフ モード) では、Cell が計算グラフにコンパイルされます。
ネットワークをカスタマイズする必要がある場合は、Cell クラスを継承し、__init__ をオーバーライドしてメソッドを構築する必要があります。 Cell クラスは __call__ メソッドをオーバーライドします。 Cell クラスのインスタンスが呼び出されると、コンストラクター メソッドが実行されます。構築メソッドでネットワーク構造を定義します。
次の例では、畳み込み計算機能を実装するための簡単なネットワークを構築します。ネットワーク内の演算子は __init__ で定義され、construct メソッドで使用されます。この場合のネットワーク構造は、Conv2d -> BiasAdd です。
この構築方法では、x が入力データ、出力がネットワーク構造を計算した結果になります。
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Parameter
from mindspore.common.initializer import initializer
from mindspore._extends import lazy_inline
class MyNet(nn.Cell):
@lazy_inline
def __init__(self, in_channels=10, out_channels=20, kernel_size=3):
super(Net, self).__init__()
self.conv2d = ops.Conv2D(out_channels, kernel_size)
self.bias_add = ops.BiasAdd()
self.weight = Parameter(initializer('normal', [out_channels, in_channels, kernel_size, kernel_size]))
def construct(self, x):
output = self.conv2d(x, self.weight)
output = self.bias_add(output, self.bias)
return output
@Lazy_Inline は Cell::__init__ のデコレーターであり、その機能は、__init__ のすべてのパラメーターを Cell の cell_init_args 属性値に生成することです (self.cell_init_args = type(self).__name__ + str(arguments))。 cell_init_args 属性は、MindSpore コンパイルにおける Cell インスタンスの一意の識別子として機能します。 cell_init_args 値が同じということは、Cell クラス名と初期化パラメーターの値が同じであることを示します。
construct(self, x) は、Cell クラスと同じネットワーク構造を定義します。ネットワーク構造は、入力パラメーター self と x に依存します。 Self には重みなどのパラメータが含まれます。これらの重みはランダムに初期化されるか、トレーニングの結果であるため、これらの重みは Cell インスタンスごとに異なります。他の自己属性は __init__ パラメーターによって決定され、__init__ パラメーターは @lazy_inline によって計算され、Cell インスタンスの識別 cell_init_args を取得します。したがって、Cell インスタンスのコンパイル計算グラフ construct(self, x) は、construct(x, self. cell_init_args, self.trainable_parameters() ) に変換されます。
同じ Cell クラスで cell_init_args パラメータが同じ場合、これらのニューロン インスタンスを再利用可能ニューロン インスタンスと呼び、このニューロン インスタンスに対応する計算グラフを再利用可能計算グラフ reuse_construct(X, self. trainable_parameters()) と呼びます。各 Cell インスタンスの計算グラフは次のように変換できると推測できます。
def construct(self, x)
Reuse_construct(x, self.trainable_parameters())
再利用可能な計算グラフの導入後は、同じ cell_init_args を持つニューロン セル (再利用可能な計算グラフ) を 1 回構成してコンパイルするだけで済みます。ネットワーク内のセルが多いほど、パフォーマンスが向上する可能性があります。しかし、これらのセルの計算グラフが小さすぎるか大きすぎる場合、演算子の融合、メモリの多重化、グラフ全体のシンク、複数グラフの呼び出しなどの特定の機能の最適化が不十分になります。 。
したがって、MindSpore バージョンは現在、どの Cell コンパイル ステージが再利用可能な計算グラフを生成するかの手動による識別のみをサポートしています。後続のバージョンでは、再利用可能な計算グラフを生成するための自動戦略が計画されます。これには、セルに含まれる演算子の数、セルの使用回数、再利用可能な計算グラフを生成するかどうかを考慮するためのその他の要素など、最適化の提案が含まれます。
以下では、抽象的かつ単純化した説明のために GPT 構造を使用しています。
class Block(nn.Cell):
@lazy_inline
def __init__(self, config):
.......
def construct(self, x, attention_mask, layer_past):
......
class GPT_Model(nn.Cell):
def __init__(self, config):
......
for i in range(config.num_layers):
self.blocks.append(Block(config, None))
......
self.num_layers = config.num_layers
def construct(self, input_ids, input_mask, layer_past):
......
present_layer = ()
for i in range(self.num_layers):
hidden_states, present = self.blocks[i](...)
present_layer = present_layer + (present,)
......
GPT は複数のブロック層で構成されており、これらのブロックの初期化パラメーターはすべて同じ Config であるため、これらのブロックの構造は同じであり、コンパイラーによって内部で次の構造に変換されます。
def Reuse_Block(x, attention_mask, layer_past,block_parameters) :
......
具体的Block 实例的计算图如下:
def construct(self, x, attention_mask, layer_past):
return Reuse_Block(x, attention_mask, layer_past,
self. trainable_parameters())
この構造では、コンパイル プロセスの前半では、独立した計算グラフとなり、全体の計算グラフにはインライン化されず、最後の少量のパス最適化のみが大きな計算グラフにインライン化されます。
②L****azy Inlineと自動微分・並列・再計算等の機能の組み合わせ
Lazy Inline のソリューションを採用すると、元のプロセスにある程度の影響があり、主に自動微分、並列処理、再計算といった関連する調整が必要になります。
自動微分を行うには、call関数と同様のforwardノードが出現し、微分処理を提供する必要があります。
並列プロセスの場合、重要なことは、パイプラインの並列パス処理を非全体像のシナリオに適応させる必要があるということです。これは、以前のパイプラインの切断は全体像に基づいていたためですが、現在は共有サブグラフに基づいて切断する必要があるためです。具体的な計画は、まずステージに応じて色を付け、共有セル内のノードをステージに応じて分割し、現在のプロセスのステージに対応するノードのみを保持し、Send/Recv オペレータを挿入してノードを分割することです。共有セルの外側では、ステージ ノードは、現在のプロセスの対応するノードも保持し、共有セル内の Send/Recv オペレーターを共有セルから取り出します。
再計算プロセスについては、古い再計算プロセスは、再計算された連続演算子ブロックを検索することにより、ユーザーの再計算設定に従って再計算が必要な演算子と再計算パラメータを決定します。計算された演算子の実行が依存する演算子。 Lazy Inline の後、連続する再計算演算子が異なるサブグラフに存在する可能性があり、順方向ノードと逆方向ノードの間に接続関係が見つからないため、グラフ演算子全体に基づく元の検索戦略は失敗します。
私たちの適応計画は、自動微分後に再計算されたセルまたは演算子を処理することです。自動微分プロセスは、Cell によって生成されたサブグラフまたは単一演算子のクロージャを生成します。これは順方向出力と逆伝播関数を返します。また、各クロージャと元の順方向部分の間の関係も取得します。この情報により、ユーザーの再計算設定に基づいて、各クロージャーが基本単位として使用され、Cell と演算子が均一に処理され、元の前方部分が元のグラフにコピーされ、依存関係を引き継ぐことができます。バックプロパゲーション関数の取得により、最終的にグラフ全体の Inline に依存しない再計算スキームを実現できます。
③バックエンド 処理と影響
フロントエンドで Lazy Inline をオンにした後に生成された IR は、サブグラフ シンキングを通じてデバイス上で実行される前にバックエンドに送信されます。ただし、Lazy Inline の後でも、メモリ再利用とストリーム割り当てに最適な方法を使用できないこと、コンパイル中のコンパイル高速化のためにグラフの内部キャッシュを使用できないことなど、サブグラフ シンキングの実行にはいくつかの問題が残ります。 、グラフ間の最適化(メモリの最適化、通信の融合、オペレータの融合など)やその他の問題を実行できないこと。
最適なパフォーマンスを達成するために、バックエンドは Lazy Inline の IR をバックエンド シンキングの実行に適した形式に処理する必要があります。主に行うべきことは、自動微分によって生成された Partial 演算子を通常のサブグラフ呼び出しに変換し、キャプチャされた変数を通常のパラメータとして渡します。これにより、グラフ全体を沈め、ネットワーク全体を実行できます。
グラフ シンク プロセス全体において、これらの呼び出しには 2 つの処理方法があります。グラフでのインラインと実行シーケンスでのインラインです。グラフ上でインライン化すると、グラフが拡張され、その後のコンパイル速度が遅くなります。ただし、実行シーケンスのインライン化により、メモリの再利用中、および実行シーケンスの一部のメモリ ライフ サイクルが特に長くなります。最後にはメモリが足りません。
最終的に採用した処理方法は、最適化パス、演算子の選択、演算子のコンパイルなどの実行シーケンスのインライン処理を再利用することで、グラフのサイズを可能な限り小さくし、バックエンドに影響を与えるグラフ ノードが多すぎないようにすることでした。グラフの時間の編集。シーケンス最適化、ストリーム割り当て、メモリ再利用などの処理を実行する前に、これらの呼び出しが実際のノードにインラインで行われ、最適なメモリ再利用効果が得られます。さらに、グラフをインライン化した後のメモリと通信の最適化、冗長計算の削除などにより、メモリとパフォーマンスの低下をゼロにすることが可能です。
現時点では、すべてのグラフ間レベルの最適化を実現することはできません。単一点識別は Inline の後のステージにのみ配置でき、実行順序の最適化、ストリーム割り当て、メモリ再利用の時間を節約することはできません。
④ 効果の実感
大規模モデルのコンパイル パフォーマンスの最適化では、Lazy Inline ソリューションを使用してコンパイル パフォーマンスを 3 ~ 8 倍向上させます。100 億の大規模モデルの 13B ネットワークを例に挙げると、Lazy Inline ソリューションを適用した後、計算グラフのコンパイル スケールは 130,000 以上から低下しました。ノード数が 20,000 以上になると、コンパイル時間が 3 時間から 20 分に短縮され、コンパイル結果のキャッシュと組み合わせることで、全体的な効率が大幅に向上しました。
⑤利用 制限と次のステップ
1. Cell Cell インスタンスの識別子は、Cell クラス名と __init__ パラメーターの値に基づいて生成されます。これは、init のパラメータが Cell のすべてのプロパティを決定し、コンストラクト合成の開始時の Cell プロパティが init 実行後のプロパティと一致するという前提に基づいています。そのため、合成に関連する Cell のプロパティは変更できません。 init が実行された後。
2. 構築関数パラメータにはデフォルト値を設定できません。既存の MindSpore バージョンに構築関数パラメータのデフォルト値がある場合、それが使用されるたびに新しい計算グラフに特化され、後続のバージョンでは元の特化メカニズムが最適化されます。
3. Cell は複数の共有 Cell_X インスタンスで構成され、各 Cell_X は複数の共有 Cell_Y インスタンスで構成されます。 Cell_X と Cell_Y の init が両方とも @lazy_inline として装飾されている場合、最も外側の Cell_X のみを再利用された計算グラフにコンパイルでき、内側の Cell_Y の計算グラフは依然として Inline です。後続のバージョンでは、このマルチレベルの遅延インラインをサポートする予定です。機構。
顧客が高い結合性と低い結合性でコードを作成できるようにすることも、MindSpore フレームワークによって追求される目標の 1 つです。たとえば、使用時には、レイヤー インデックスと値を含むこの Block:: __init__ パラメーターがあります。他のパラメータは同じであるため、各レイヤのインデックスが異なるため、微妙な違いによりブロックが再利用できなくなります。たとえば、特定の GTP バージョン コードには次のコードが存在します。
class Block (nn.Cell):
"""
Self-Attention module for each layer
Args:
config(GPTConfig): the config of network
scale: scale factor for initialization
layer_idx: current layer index
"""
def __init__(self, config, scale=1.0, layer_idx=None):
......
if layer_idx is not None:
self.coeff = math.sqrt(layer_idx * math.sqrt(self.size_per_head))
self.coeff = Tensor(self.coeff)
......
def construct(self, x, attention_mask, layer_past=None):
......
ブロックを再利用可能にするには、ブロックを最適化し、レイヤー インデックスに関連する計算を抽出し、それらを Construct のパラメーターとして使用して元の構成に入力し、ブロックの初期パラメーターが同じになるようにします。
上記のコードセグメントを次のコードセグメントに変更し、Init と Layer Index に関連する部分を削除し、coeff パラメーターを追加して構築します。
class Block (nn.Cell):
def __init__(self, config, scale=1.0):
......
def construct(self, x, attention_mask, layer_past, coeff):
......
Shengsi MindSpore の今後のバージョンでは、このような微妙に異なるブロックを特定し、最適化と改善のためにこれらのブロックに対する最適化の提案を提供する予定です。
1990 年代生まれのプログラマーがビデオ移植ソフトウェアを開発し、1 年足らずで 700 万以上の利益を上げました。結末は非常に懲罰的でした。 Google は、Flutter、Dart、Python チームの中国人プログラマーの「35 歳の呪い」に関係する人員削減を認めた 。Microsoft は 、 無力な中年者にとっては幸運なおもちゃでもある。強力で GPT-4.5 の疑いがある; Tongyi Qianwen オープンソース 8 モデルWindows 1.0 が 3 か月以内に正式に GA Windows 10 の市場シェアは 70% に達し、Windows 11 GitHub がAI ネイティブ開発ツール GitHub Copilot Workspace JAVAをリリースOLTP+OLAP を処理できる唯一の強力なクエリです。これが最高の ORM です。