
著者: Wu Jipeng、無錫西上銀行ビッグデータ技術マネージャー
編集と仕上げ: SelectDB技術チーム
はじめに: データ資産の価値変革と包括的なデジタルおよびインテリジェントなリスク管理を実現するために、無錫西上銀行のビッグデータ プラットフォームは、Hive オフライン データ ウェアハウスからApache Dorisリアルタイム データ ウェアハウスへの進化を経験し、現在アクセスできるようになりました。数百のリアルタイム テーブル、数百のデータ サービス インターフェイス、およびインターフェイス QPS は数百万レベルに達し、オフライン データ ウェアハウスの適時性の不足、高コスト、低効率の問題を解決し、クエリを 10 倍以上高速化します。 、ユーザーにタイムリーで効果的かつ安全なデータ サービスと使用エクスペリエンスを提供します。
ビッグデータ、モノのインターネット、人工知能などの新興テクノロジーが金融業界にもたらした変化に直面して、無錫西上銀行はテクノロジー能力とビッグデータ能力の開発に重点を置いています。データ資産の価値変革と包括的なデジタルおよびインテリジェントなリスク管理を実現するために、無錫西上銀行は「オンライン ビジネス、データベースのリスク管理、プラットフォームベース」の 3 つの統合テクノロジー レイアウトに基づくビッグ データ プラットフォームを確立しました。毎日大量に流入する取引記録やクレジット申請データを管理し、ユーザーポートレート、リアルタイムレポート、リアルタイムリスク管理、その他のアプリケーションの助けを借りて、よりタイムリーで効果的かつ安全な情報をユーザーに提供します。データ サービスとユーザー エクスペリエンス。
無錫西上銀行のビッグ データ プラットフォームは、Hive ベースのオフライン データ ウェアハウスから、 Apache Dorisベースのリアルタイム データ ウェアハウスに進化しました。アーキテクチャのアップグレードにより、オフライン データ ウェアハウスの適時性の不足、高コスト、低効率の問題が解決され、クエリ速度が 10 倍向上し、銀行は顧客の行動をより速く認識し、タイムリーな洞察を得ることができるようになりました。異常な取引行動を検出し、潜在的なリスクを特定して防止します。この記事では、無錫西上銀行のビッグデータ プラットフォームの進化と、リアルタイム クエリ、マーケティング サービス、リスク管理サービス、その他のシナリオにおける Apache Doris の実装について詳しく紹介します。
Hive に基づくビッグ データ オフライン データ ウェアハウス
01 需要シナリオ
無錫西商銀行は、初期段階でビッグ データ オフライン データ ウェアハウスを構築しました。これは主に、データ レポート、データ リスク管理、データ操作、アドホック クエリ、毎日のデータ取得などのシナリオに対応します。
-
データレポート: 顧客リスク、EASTレポート、1104、大規模集中、信用レポート、金利レポート、マネーロンダリング防止、基本的な財務データレポートなど。
-
データリスク管理: 融資リスク管理指標、ユーザー行動指標、不正行為防止、融資後の早期警告、融資後の管理、その他のリスク管理に関するリスク管理を含みます。
-
データ運用:BIビジネスレポート、マネジメントコックピット、外部チャネル、業界内の各種システムに定期的なバッチデータを提供します。
-
アドホック クエリと毎日のデータ取得: ビジネス ニーズに応じてデータ分析、データ開発、データ抽出を実行します。
02 アーキテクチャと問題点
初期のオフライン データ ウェアハウスでは、データは主に Oracle、MySQL、MongoDB、Elasticsearch、およびファイルから取得されていました。 Sqoop、Spark、外部データ ソース、シェルなどのツールを使用すると、データはオフラインで Hive オフライン データ ウェアハウスに抽出され、Hive の ODS、DWD、DWS、ADS を通じて階層的に処理され、最終的な出力結果は次のようなサポートを提供します。アプリケーションサービス層。
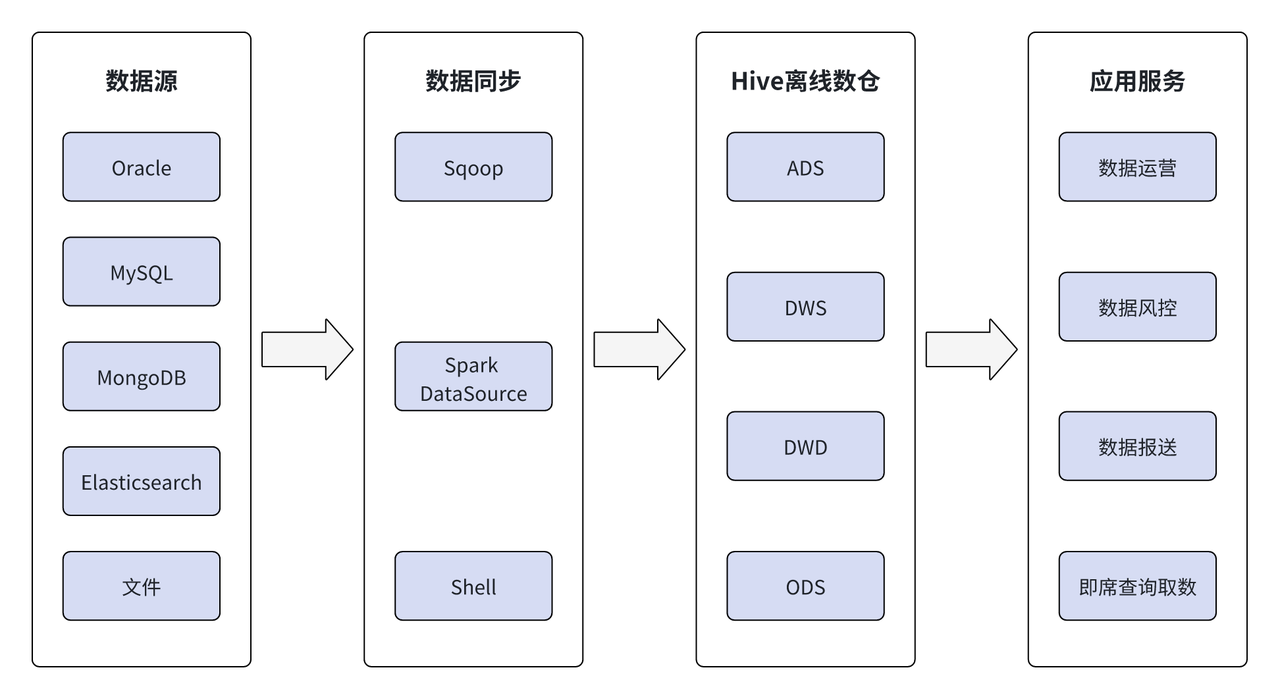
近年、無錫西上銀行の事業の発展と拡大に伴い、関連する事業部門のデータ処理に対する要求がますます高まっており、オフライン データ ウェアハウスでは新たなニーズに対応できなくなっており、これは主に次の点に反映されています。
-
データの適時性が不十分: オフライン データ ウェアハウスはオフライン抽出ソリューションを使用しており、データの適時性は T+1 ですが、レポート、データ ダッシュボード、マーケティング指標、リスク管理変数にはリアルタイムのデータ更新が必要ですが、現在のアーキテクチャではこれに対応できません。 。
-
データ クエリの効率は低く、第 2 レベルおよびミリ秒レベルでのクエリ応答が必要です。オフライン データ ウェアハウスの実行エンジンは主に Hive と Spark です。Hive が実行されると、クエリが複数の MapReduce タスクに分解され、HDFS 内のデータの読み取りと書き込みが必要になるため、実行時間は通常、クエリに重大な影響を与えます。効率。
-
高額なメンテナンス コスト: オフライン データ ウェアハウスの最下層には、LDAP、Ranger、ZooKeeper、HDFS、YARN、Hive、Spark およびその他のシステムを含む多くのテクノロジ スタックが関与しており、システム メンテナンス コストが高額になります。オンラインの HBase + Phoenix のリアルタイム ストレージやサービスもありますが、コンポーネントが比較的「重い」こと、コミュニティが活発ではないこと、一部の機能がリアルタイムのニーズを満たしていないことなどから、現在の問題を完全に解決することはできません。シナリオ。
テクノロジーの選択
オフライン データ ウェアハウスの適時性の欠如、クエリ効率の低さ、複数のテクノロジー スタックによる高いメンテナンス コストという問題点に直面しているため、リアルタイム データ ウェアハウスの構築は不可欠です。無錫西上銀行は、複数の MPP データベースについて徹底的な調査を行った結果、Apache Doris を中核としたリアルタイム データ ウェアハウス プラットフォームを構築することを決定しました。このテクノロジーの選択は、プラットフォームがデータ書き込み、クエリ、サービス レベルでのリアルタイム ビジネス分析の高い要件を確実に満たせるようにすることを目的としています。 Apache Doris を選択した理由は次のとおりです。
-
効率的なデータ更新: Apache Doris Unique Key は、大規模なバッチ データの更新、小規模なバッチ データのリアルタイム書き込み、および軽量のテーブル構造の変更をサポートします。特に大量のデータとパーティションを処理する場合、大量の変更や不正確な変更の問題を効果的に回避できるため、より便利でリアルタイムのデータ更新が可能になります。
-
低レイテンシのリアルタイム書き込み:第 2 レベルでのデータのリアルタイム書き込み、更新、削除をサポートし、主キー テーブル モデルの書き込み時間マージをサポートし、マイクロバッチの高頻度のリアルタイム書き込みを可能にします。主キー モデル データのインポート プロセスの順序性を確保するためのシーケンス列の設定。
-
優れたクエリ パフォーマンス: Apache Doris は、ベクトル化された実行エンジン、CBO クエリ オプティマイザー、MPP アーキテクチャ、インテリジェントなマテリアライズド ビューおよびその他の機能を利用して、大量のデータに対するミリ秒レベルのクエリ応答を実現し、インスタント データを満足させることができます。クエリが必要です。同時に、Apache Doris バージョン 2.0 は行と列の混合ストレージをサポートし、ポイント クエリ シナリオで数万の同時ミリ秒レベルの応答を実現できます。
-
このプラットフォームは非常に使いやすく、 MySQL プロトコルと互換性があり、豊富な API インターフェイスを提供するため、上位層アプリケーションの使用の難しさを軽減できます。同時に、Apache Doris は FE と BE の 2 つのプロセスだけで構成される合理化されたアーキテクチャを備えており、ノードの拡張と縮小が簡単で、クラスタ管理とデータ コピー管理が自動化をサポートし、導入が簡単で、使用コストが低いという特徴があります。運用とメンテナンスのコストが低い。
ビッグデータのリアルタイム データ ウェアハウスを構築するための Apache Doris の紹介
2022 年 4 月、無錫西上銀行は、リアルタイム データ ウェアハウス プラットフォームを構築するために Apache Doris を導入しました。銀行データの規模が非常に大きいことを考慮すると、リアルタイム データにアクセスしながらビジネス データベースの履歴データをすべて同期することは困難であるため、最初のリアルタイム データ構築は主にオフライン データに依存します。
まず、HDFS Broker メソッドを使用して過去のリアルタイム データを効率的に初期化し、同時に収集ツール DataPipeline を使用してデータをリアルタイムで Kafka クラスターに収集し、次に Flink がハードコードされたモードを書き込みます。データをリアルタイムで Apache Doris に書き込みます。最後に、Feiliu プラットフォームのインターフェイス サービス機能を利用して、Apache Doris が統合ストレージおよびクエリ エンジンとして使用され、各ビジネス ラインにサービスを提供します。
Feiliu プラットフォームは、将来のリアルタイム ビジネス シナリオに対応するために無錫西商銀行によって構築された統合された包括的なプラットフォームであり、主にリアルタイム収集、リアルタイム同期ツール、リアルタイムデータ ウェアハウス、リアルタイム計算およびデータ サービスが含まれています。 。
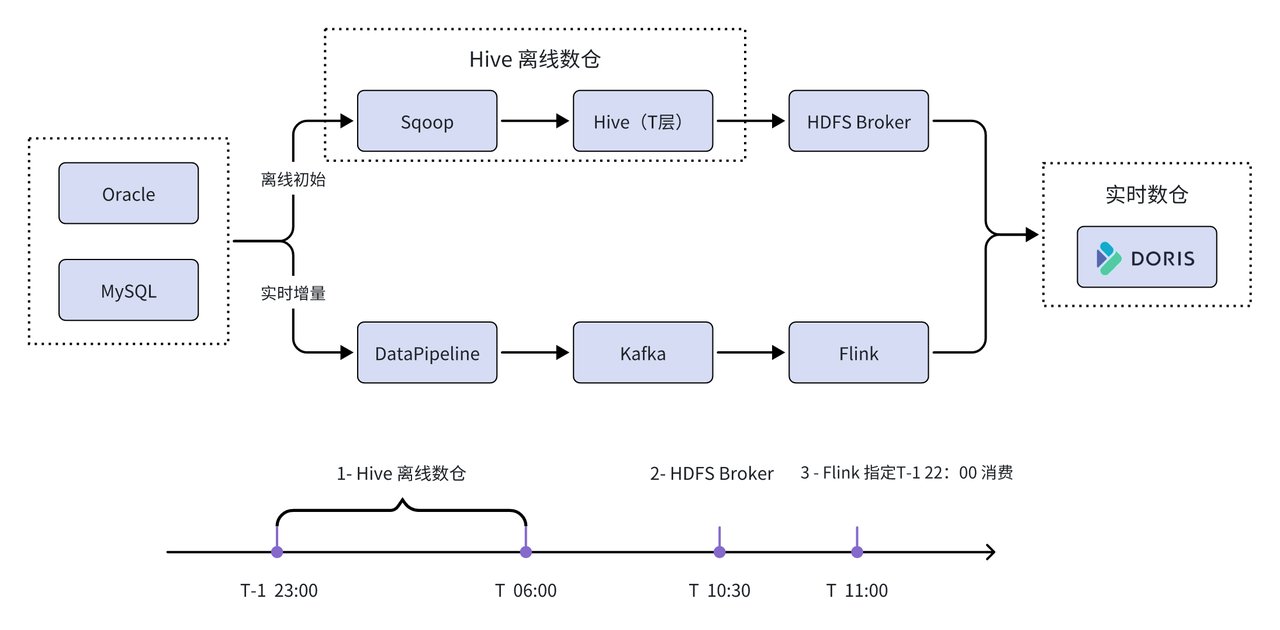
01 データフローリンクの改善
無錫西商銀行は、銀行データの特性に基づいて、Apache Doris の機能上の利点を組み合わせて、データ フロー リンクを再考し、改善しました。
-
オフラインのデータ ウェアハウスから履歴データを同期すると、リスクが最小限に抑えられます。記事では、銀行データの規模が膨大なため、全量の履歴データが Oracle と MySQL から直接同期されると、大量のデータがファイアウォールやスイッチを通過することになると述べています。他のビジネス リクエストがブロックされ、サービス タイムアウトなどの問題が発生します。これらの潜在的なリスクと問題を回避するには、まず Oracle と MySQL に基づいて Doris テーブル構造をバッチで構築し、次に HDFS ブローカーを使用してオフライン データ ウェアハウス Hive ODS レイヤーから完全な T-1 データを Doris に同期します。これにより、リスク。
-
リアルタイム増分抽出、より安全な抽出モード:リアルタイム抽出では、メイン ビジネス データベース (デフォルトではビジネス スレーブ データベース) への影響を避けるために、非常に少量のディスク IO、メモリ、CPU 消費が発生します。市の災害復旧がリアルタイムで選択されます。高い適時性が求められるビジネス ニーズの場合、メイン ビジネス データベースからデータを抽出する前に完全な評価が必要です。
-
データの一貫性を確保するために Kafka レイヤーを構築する:データの順序性と一貫性を確保するために、中間データ伝送層として Kafka レイヤーを構築します。 Datapipelineで送信されるデータのKeyはDatabase-Table-PKとして構成され、同じディメンションに従ってKafka Topicのパーティション(Partition)に順番に送信されます。 Kafka Topic のそれぞれのパーティションは順序どおりに保存されるため、下流のコンシューマーは、リアルタイム データ ウェアハウス データの精度に対する順序外れの影響を回避するためにデータを処理できます。さらに、Kafka レイヤーはデータ パブリック レイヤーとして使用でき、マーケティング、リスク管理、その他のビジネス シナリオで使用できます。
-
データは、データの損失や重複がないようにリアルタイムで書き込まれます。実際のアプリケーション シナリオでは、オフライン リンクは、T-1 日の午後 11 時から午前 6 時までオフライン データのバッチ処理を実行し、10 時に HDFS ブローカー メソッドを使用します。 T 日の時計。テーブル履歴データの初期化。リアルタイム リンクは、リアルタイム データ同期のために、Flink を使用して、午後 10 時に T-1 で消費された Kafka トピックを直接ポイントします。ただし、リアルタイム消費プロセス中に一部の重複するデータが表示されます。この問題に対処するために、重複するデータを迅速にカバーできる Apache Doris の Unique Key モデルが選択され (このモデルはデータ冪等性をサポートします)、Flink-Doris-Connector を使用してリアルタイム データ ウェアハウス リンクが改善されます。一貫したリアルタイムのデータ同期を捨てるのは難しくありません。
02 柔軟なデータサービス
正確かつ効率的なクエリ応答を提供するために、無錫西上銀行は次の 3 つの方法を採用してデータ サービスを実装しました。
-
オフライン データ クエリ: オフライン要件では、データを迅速にクエリする必要があります。無錫西商銀行は、オフライン データ ウェアハウスからリアルタイム データ ウェアハウスの Doris テーブルにデータを定期的にインポートしています。これにより、リアルタイム データ ウェアハウスでの高速クエリが可能になり、オフライン データ分析と意思決定のニーズを満たすことができます。
-
シンプルなリアルタイム要件: 複雑でないリアルタイム要件の場合、無錫西商銀行は Apache Doris の効率的なクエリ機能を使用して、「Fei Liu」プラットフォーム上でデータ サービス インターフェイスを直接構成する機能を提供します。ユーザーは、SQL に基づいて SQL を使用できます。リアルタイム データ ウェアハウスの ODS レイヤー 手動構成を実行します。このようにして、単純なリアルタイム データ クエリのニーズにすぐに応えることができます。
-
複雑なリアルタイム要件: 複雑なリアルタイム要件に対応するため、無錫西上銀行は、リアルタイム Kafka データ フローと Flink ライト コンピューティングを使用して、リアルタイム データ ウェアハウスの DWD レイヤー テーブルにデータ フローを書き込みます。 「Fei Liu」プラットフォーム テーブルの SQL が再度集約され、複雑なリアルタイム データ クエリのニーズを満たすようにデータ サービス インターフェイスが手動で構成されます。
より多様なサービスシナリオに直面する
01 数秒以内の BI レポートのクエリ応答
無錫西商銀行は、Apache Doris をベースとして、日次データ分析、日次データ取得、BI リアルタイム レポートなどの複数のシナリオのニーズを満たしています。クエリの応答時間が大幅に短縮され、クエリ結果は 1 秒以内に返されます。データ アナリストの待ち時間とサーバー リソースの消費を大幅に削減します。
たとえば、BI のリアルタイム レポートに関しては、無錫西上銀行は、リアルタイムの融資データ テーブル、リアルタイムの預金データ テーブル、口座残高テーブルなどのレポートを確立しました。 **これらのレポートには平均 253 行の SQL コードがあり、平均応答時間は 1.5 秒です。 **さらに、無錫西上銀行は、クエリのパフォーマンスとデータ モデルの設計を最適化することで、短期間で正確なリアルタイム レポートを生成し、ビジネス上の意思決定にタイムリーなデータ サポートを提供できます。
02 パーソナライズされたマーケティング計画のサポート
マーケティングデータサービスの面では、無錫西上銀行はApache Dorisをベースに顧客タグを充実させ、正確な顧客像を向上させ、純資産増加活動やアーティストブラインドボックス活動など、さまざまなマーケティング活動を実施した。リアルタイムデータの分析により、銀行はアクティブユーザーのコンバージョン状況をタイムリーに観察し、オペレーション選択戦略を迅速に調整して、「1000人に1つの顔」から「1000人に1つの顔」へのパーソナライズされたマーケティングを実現できます。顔"。
たとえば、純資産増加活動やアーティストのブラインドボックス活動などのマーケティング活動において、無錫西上銀行は、Apache Doris リアルタイム データ ウェアハウスの機能を使用して、活動データを継続的に収集、分析、フィードバックしています。ユーザーのコンバージョンをリアルタイムで観察することで、オペレーションの選択戦略を迅速に調整し、人材とアクティビティの整合性を確保できます。このパーソナライズされたマーケティング戦略により、銀行は顧客のニーズをより適切に満たし、エンゲージメント、応答率、ユーザーの定着率を高めることができます。
03 効率的なリスクの特定と制御
Apache Doris の導入により、無錫西上銀行はリスク管理特性変数と異常な取引動作をより迅速に計算できるようになりました。新規ユーザー登録を例に挙げると、ユーザーが情報を入力すると、システムはリアルタイムのリスク管理特性変数に基づいて承認戦略の結果を迅速に判断し、タイムリーに戦略モデルを最適化し、品質と精度を保証します。承認の。
無錫西商銀行は、潜在的なリスクをタイムリーに特定し、防止することもできます。例えば、銀行は短期間に大量の取引や異常な取引金額などの取引データをリアルタイムに収集・監視し、異常な取引行為や不正行為をタイムリーに検知できます。リアルタイムのデータ分析を通じて、銀行は潜在的なリスクを迅速に特定し、予防および対応するための適切な措置を講じることができます。
さらに、無錫西商銀行は、Apache Doris リアルタイム データ ウェアハウスを使用して、顧客の信用履歴と信用申請情報のリアルタイム分析を行っています。顧客の申請額が返済能力を満たしているかどうかを迅速に判断することで、銀行はタイムリーなリスク評価と意思決定を行い、信用リスクを効果的に管理することができます。
04 7日間取引フローシートのデータが自動更新されます。
実際のアプリケーション シナリオでは、トランザクション フロー シートのデータ量は非常に多く、トランザクション シリアル番号、トランザクション日付、トランザクション タイプ、トランザクション金額、その他のデータが含まれます。データをタイムリーに更新するために、無錫西商銀行は Apache Doris 動的パーティション テーブルの機能を使用することを選択しました。この機能は、パーティションを自動的に作成し、7 日を超えたトランザクション フロー データを自動的に削除して、7 日間のトランザクション フロー テーブル内のデータの自動更新を実現します。具体的な操作には次の手順が含まれます。
-
営業日を結合主キーとして疑似列を構築します。
-
ID データが
tran_date数日にわたって更新されると、コードはテーブルを返す操作を実行します。 -
データの挿入およびパーティション テーブルで対応する Date 値を見つけ、それを Update Json に結合してデータベースに更新します。

Apache Doris の動的パーティショニングおよびテーブル パーティショニング機能を利用すると、基盤となる主キーとサーバーの安定した動作を保証するだけでなく、アナリストがクエリを実行できるように、トランザクション データを自動的に更新して 7 日間のみ保持し、要件を満たすことができます。 100 万 QPS 未満で 1.5 秒のクエリ応答要件。
05 高い同時実行ポイントのクエリ
初期のマーケティングおよびリスク管理アプリケーションのシナリオは、列挙サービスをサポートするために主に 2 セットの HBase クラスターに依存していましたが、実際のアプリケーションでは、マスター/リージョンサーバーの異常終了や RIT などの問題が発生します。この問題を回避するには、Apache Doris の高い同時クエリ機能を利用し、一意キー テーブルの作成時に Merge-on-Write 戦略を有効にして、単純化された SQL 実行パスを通じて主キー クエリを完了できるようにします。必要な RPC は 1 つだけです。迅速なクエリ応答を完了します。
最後に、各ノードを 8C および 10GB で構成した 3 つのノードでのストレス テストを通じて、次の大きな利点が達成されました。
-
1 つのテーブルに 5,000 万のデータが含まれるクエリ シナリオでは、QPS は 25,000 にもなります。
-
5,000 万のデータを含む複数テーブルの読み取りおよび書き込みシナリオでは、QPS も 20,000 に達します。
-
複雑な SQL クエリの安定性も QPS 25,000 という高レベルを維持しています。
-
複数のテーブルのリアルタイム読み取りおよび書き込みシナリオでも、QPS を 25,000 で安定させることができます。
結論
現在、Apache Doris は、無錫西商銀行の数百のリアルタイム テーブル、数百のデータ サービス インターフェイス、および数百万に達するインターフェイス QPS にアクセスしています。さらに、Apache Doris は統合クエリ ゲートウェイとして、元の分レベルの応答時間と比較して、クエリ速度が 10 倍以上向上し、履歴データ分析の効率が大幅に向上します。
無錫西尚銀行は今後も Apache Doris の利点を探求し、リアルタイム シナリオでのより深い応用を推進していきます。
-
パフォーマンスの面では、同時実行性の高いクエリ、自動パーティショニングとバケット化、実行エンジン、その他の機能をさらに最適化し、データ クエリの応答効率を向上させます。
-
負荷分散に関しては、デュアル クラスタを構築してアーキテクチャ上の負荷分散を実現し、同時にアーキテクチャの早期警告およびサーキット ブレーカーのメカニズムを改善して、中断のないビジネス オペレーションを保証します。
-
クラスターの安定性の観点: Apache Doris クラスターの「分業とコラボレーション」を実現し、各クラスターがリアルタイム データ ウェアハウスの計算と保存、データ サービスのクエリの高速化などのタスクを実行できるようにします。システムの安定性と信頼性をさらに向上させます。