
皆さんも GitHub でスターを付けてください:
分散型フルリンク因果学習システム OpenASCE: https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
大規模なモデル駆動型ナレッジ グラフ OpenSPG: https://github.com/OpenSPG/openspg
大規模グラフ学習システム OpenAGL: https://github.com/TuGraph-family/TuGraph-AntGraphLearning
論文タイトル: PEACE: Prototype lEarning Augmented transferable Framework for Cross-domain rEcommendation
組織単位: Ant Group
入学カンファレンス: WSDM 2024
論文リンク: https://arxiv.org/abs/2312.0191 6
この記事の著者: ガン チュンジン。主な研究方向は、グラフ アルゴリズム、推奨アルゴリズム、大規模言語モデル、およびナレッジ グラフの応用です。研究結果は、主流の機械学習関連カンファレンス (WSDM/SIGIR/AAAI) に含まれています。過去 1 年間のチームの主な作業は、ナレッジ グラフに基づく事前トレーニングされた推奨モデル、知識強化に基づく大規模言語モデル、および財務管理シナリオにおける多重粒度デカップリングに基づくグラフ ニューラル ネットワーク フレームワークを含むそのアプリケーションでした。 SIGIR'23 MGDL で公開されました。WSDM'24 で公開された、プロトタイプの学習ベースのエンティティ グラフ事前トレーニング クロスドメイン レコメンデーション フレームワーク PEACE です。
背景
Alipayのミニプログラムエコシステムの発展に伴い、ますます多くの加盟店がAlipayでミニプログラムを運営し始めています。同時に、Alipayはミニプログラムエコシステムと加盟店のセルフオペレーションを通じて分散型戦略を達成したいと考えています。
加盟店による自主運営の過程で、ますます多くの中小規模の加盟店が、パーソナライズされた推奨機能を通じてミニ プログラムのプライベート ドメイン ポジションのマーケティング効率を向上させるなど、デジタルでインテリジェントな運営を必要としています。中規模の小売企業では、AI によるパーソナライズされたレコメンデーション機能を自社で構築するための技術コストと人件費が非常に高くなります。
これに関連して、私たちは、Ant の膨大なユーザー行動データに基づいて、目に見えるがアクセスできないパーソナライズされた推奨機能と検索機能を販売者に提供し、販売者がインテリジェントなミニ プログラムを作成できるようにして、Alipay プラットフォームで販売者の収益を増やし、ユーザーにより良いエクスペリエンスを提供したいと考えています。 Alipay でのユーザー維持を強化し、販売者/ユーザー エクスペリエンスをさらに最適化するための共通の技術ソリューションを蓄積することもできます。
業界では、行動豊かなシナリオのデータを使用して、ミッドテールおよびロングテールのシナリオでのレコメンデーション効果を向上させる、成功したアプリケーション事例が数多くあります。たとえば、淘宝網では、最初の推測の行動データを使用して、他の小規模なシナリオでのレコメンデーション効果を向上させています。 Fliggy はアプリと Alipay の小さなシナリオを使用して、端末が共同でモデルを作成し、全体的な推奨効果を向上させます。
ただし、このタイプの方法は通常、同様の考え方を持つ複数のレコメンデーションシナリオに直面し、豊富な動作を含むシナリオデータを使用して、淘宝網、Fliggyなどのまばらな動作を持つ同様のシナリオのレコメンド効果を向上させます。しかし、AlipayなどのスーパーAPPには通常、旅行、政務、リース、旅行、ケータリング、日用品などのさまざまなミニプログラムが含まれています。さまざまなミニプログラムにおけるユーザー間の精神的な違いは非常に大きく、これがモデルを提供します。課題:
- Alipay のミニ プログラムは、政府関連、食品、リース、小売、財務管理など、さまざまな業種の垂直産業に点在しており、一般に、これらのミニ プログラム間では情報が共有されず、類似したアイテムは類似した属性を持たない場合があります。このようなクロスドメインの差異を調整することなく、ドメイン全体にわたる複数の動作を特定の垂直クラスのシナリオに直接転送すると、モデルが複数の垂直クラスの混合動作から垂直クラスにとって有用な知識を学習することは困難であり、場合によっては、マイナスの移民をもたらす。
- たとえば、食品業界は Alipay でのユーザーのケータリング関連行動のみを使用する、ポイントツーポイントのユーザー行動の移行により、上記の問題をある程度軽減できますが、新しい業界が追加されるたびに手動介入が必要になります。これにはコストがかかり、チェーン全体を実現することはできません。道路の自動化に加えて、一部の販売者は、ユーザーの行動データがない場合でも、初めて接続するときに、Alipay プラットフォームがプラグアンドプレイのパーソナライズされた推奨ソリューションを提供できることを期待しています。このようなモデルはこの設定では実現できません。
上記の課題に基づいて、垂直産業ドメイン間の大きな差異の問題に基づいて、プロトタイプ学習に基づくグラフ事前学習マルチシナリオ転移学習フレームワークである PEACE を提案しました。
私たちはエンティティ グラフを導入し、モデリングへの悪影響を軽減するために、異なるドメイン間の差異を結び付けるブリッジとしてエンティティ グラフを使用したいと考えていました。ただし、運用環境のエンティティ グラフには、多数の要素が含まれているにもかかわらず、通常は巨大になります。ただし、エンティティ マップ内の構造情報を無差別に集約すると、通常、モデルの堅牢性が低下します。そのため、モデリング プロセスでエンティティ表現とユーザーを改善するためにプロトタイプ学習を導入しました。制約すること。
全体として、PEACE フレームワークは ONE FOR ALL の移行設計アイデアです。Alipay でのユーザーのマルチソース パブリック ドメインの行動を事前トレーニング モデルの入力として使用し、複数の業界からユーザーの興味や好みを学習します。 1 つは、分離された表現のアイデアによるもので、業界のシグナルを捕捉するプロトタイプ ネットワークと組み合わせたモデルで、ユーザーの複数の関心を下流のさまざまな垂直業界に適応的に移行して、パーソナライズされたレコメンデーションを実現するための統合モデルを事前トレーニングするだけで済みます。ノーマル推奨+ゼロショット推奨)。
PEACE - プロトタイプ学習に基づくエンティティ グラフの事前トレーニング クロスドメイン推奨フレームワーク
エンティティ グラフに基づく予備知識とドメイン間の調整
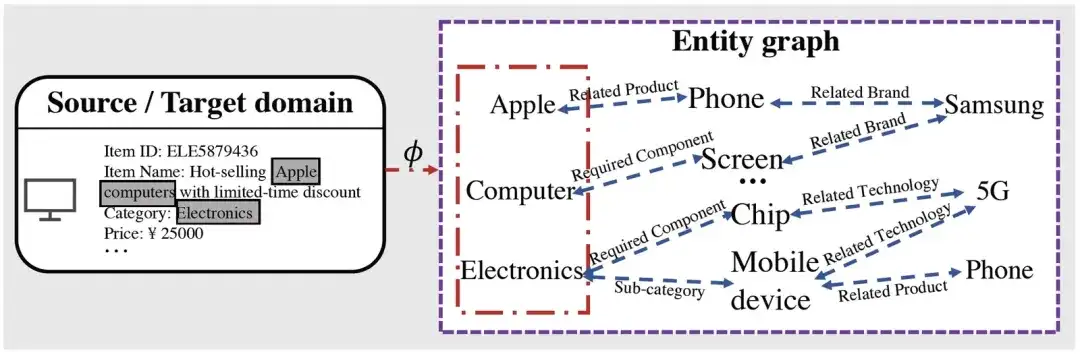

マッピングを通じて対応する項目に関連するエンティティを取得した後、グラフ推論プロセスに基づいて、マッピングされたエンティティに関連する多くの高レベルの情報を取得できることがわかります。たとえば、Apple には携帯電話製品があります。携帯電話製品に関連する企業にはサムスンなどがあり、他の関連事業体(サムスン製携帯電話など)との関係が悪化する可能性があります。
モデルフレームワーク
このセクションでは、この記事で提案したグラフ事前トレーニング クロスドメイン レコメンデーション フレームワーク PEACE を紹介します。次の図は PEACE の全体的なアーキテクチャを示しています。全体として、クロスドメインの調整をより適切に実現し、エンティティ グラフの構造情報をより効果的に利用するために、全体的なフレームワークはエンティティ指向の事前トレーニング モジュールに基づいて構築されており、ユーザーとエンティティ間の関係がさらに改善されます。事前トレーニングモジュール表現をより汎用性と転送可能にするために、プロトタイプのコントラスト学習に基づいたエンティティ表現強化モジュールと、その表現を強化するプロトタイプ強化アテンションメカニズムに基づいたユーザー表現強化モジュールを提案します。これに基づいて、最適化目標を定義します。事前トレーニング段階と微調整段階での軽量のオンライン展開プロセス。次に各モジュールを一つずつ紹介していきます。
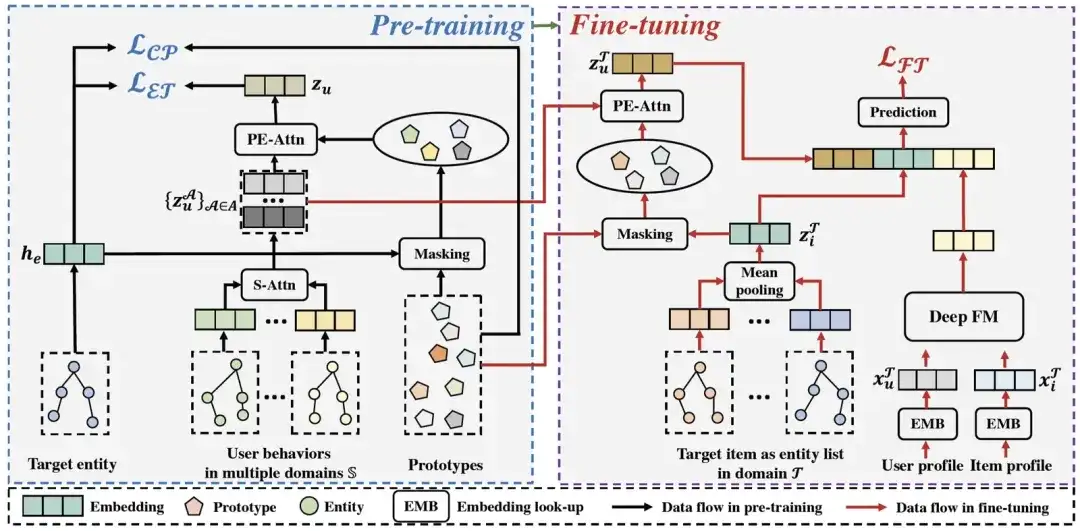
PEACEの全体的なアーキテクチャ
01. エンティティ指向の事前トレーニング モジュール
Alipay などのオンライン サービス プラットフォームは、異なるサービス プロバイダーが提供するさまざまな小さなプログラム/シナリオを収集します。一般に、これらのシナリオ間の情報は相互運用性がなく、同じブランドであっても、共有されるデータ システムはありません。カテゴリ、現在の製品の属性を完全に一致させることはできません (たとえば、異なるミニ プログラムで販売される iPhone 14 は、異なる製品 ID とカテゴリ名を持ちます。たとえば、あるミニ プログラムではカテゴリが電子製品であり、別のミニ プログラムではカテゴリがエレクトロニクスであるなど)別のミニプログラム)。これらの潜在的な問題によって引き起こされる違いとモデリングのパフォーマンスへの影響を軽減すると同時に、このインタラクティブな情報をより有効に活用するために、エンティティマップに基づいて事前トレーニングを実行し、エンティティの粒度の高い情報を導入したいと考えています。このようにして、より強力な汎化を伴う事前トレーニングを実現します。


図 1 を例にとると、この製品を起点としてアイテム→エンティティ→エンティティの場合、Apple の場合、その関連製品は Phone であることしかわかりませんが、エンティティ→エンティティ→エンティティの事前トレーニングによって、 Apple が Phone のような関連製品だけでなく、Samsung 社とも関連していることを知ることができ、それによって私たちが学んだ表現の一般化がさらに向上します)。
02. プロトタイプ対照学習に基づくエンティティ表現強化モジュール

03. プロトタイプの強化されたアテンションメカニズムに基づくユーザー表現強化モジュール
トレーニング前の段階では、ソース ドメインで収集されたデータには、さまざまなシナリオでのユーザーの行動が含まれています。たとえば、旅行の計画を立てるとき、ユーザーは旅行関連のシナリオにアクセスし、仕事を探すときはオンラインの求人にアクセスします。ただし、前のステップで学習したユーザー一般表現では、ユーザーとシーンに関連するコンテキストが考慮されていないため、さまざまなシーンでシーン関連表現をキャプチャすることができなくなります。アテンション メカニズムを使用してコンテキストを改善し、ユーザー表現を強化します。

04. モデルのトレーニングと予測
- ソースドメインの事前トレーニングリンク
エンティティ指向の事前トレーニング モジュールとプロトタイプ学習強化モジュールを組み合わせることで、全体の最適化目標を次の方法で定義できます。
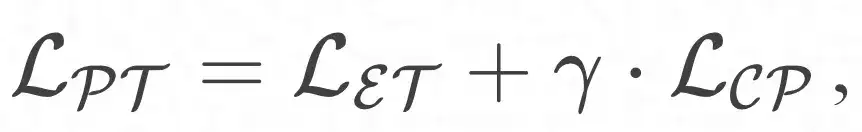

- ターゲット ドメインの微調整リンク

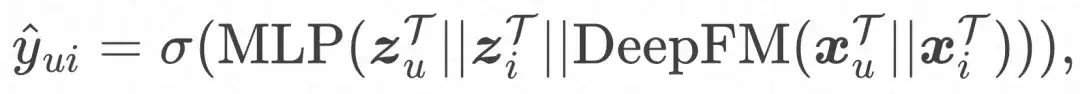
そして最終的な損失関数は次のようになります。
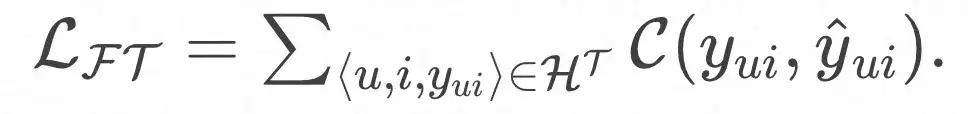

オンライン導入
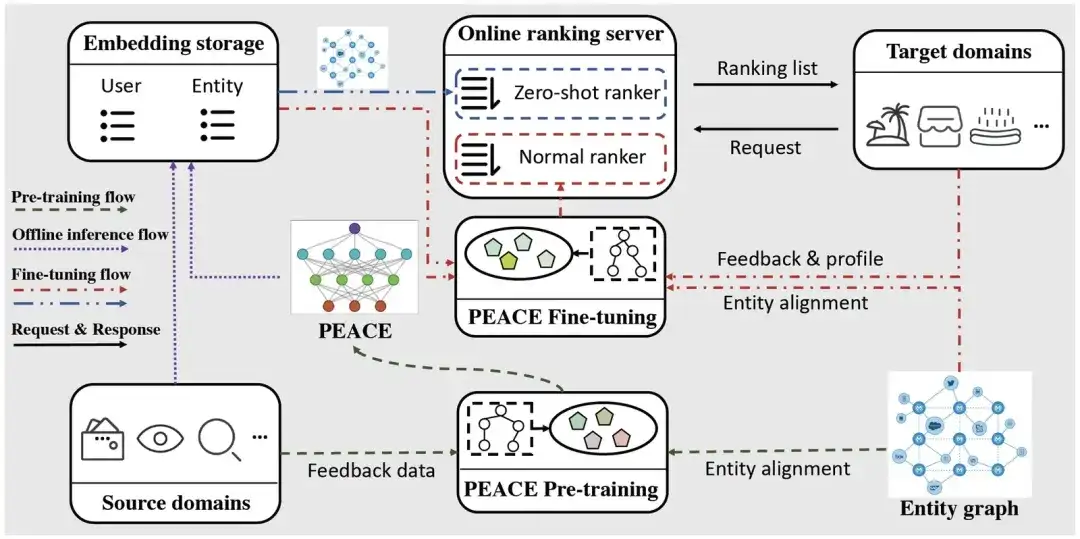
オンライン サービスへの負担を軽減するために、PEACE モデルの展開には軽量な方法が使用されます。展開フローは主に 3 つの部分に分かれています。
- 事前トレーニング フロー: 収集されたマルチソースの行動データとエンティティ マップに基づいて、PEACE モデルを毎日更新して、モデルが時間に敏感で普遍的に移転可能な知識を学習できるようにします。事前トレーニングされたモデルの場合は、ダウンストリームで使用するためのモデル パラメーターの軽量読み込みを容易にするために、ModelHub に保存します。
- オフライン推論フロー: グラフ ニューラル ネットワークによってオンライン サービス システムにもたらされる負荷を軽減するために、ユーザーとエンティティの表現を事前に推論し、ダウンストリームの微調整中にのみ ODPS テーブルに格納します。最終的な MLP グラフ ニューラル ネットワークでの情報伝播プロセスをやり直すことなくネットワークが微調整されるため、オンライン サービスの遅延が大幅に短縮されます。
- 微調整フロー: 新しく開始されたミニ プログラム/サービスにはインタラクティブなデータがないため、PEACE は次の 2 つのステップを通じてレコメンデーション サービスを提供します。
- コールド スタート シナリオの場合、ユーザーとアイテムの表現の内積を直接実行することで、さまざまなアイテムに対するユーザーの好みを取得し、それらを直接並べ替えることができます。
- 一定量のデータが蓄積されているコールド スタート以外のシナリオでは、事前トレーニングされたユーザー/アイテムの表現とユーザー/アイテムの基本情報に基づいて微調整し、オンライン サービスに微調整されたモデルを使用します。
効果分析
オフライン実験
01. データ紹介
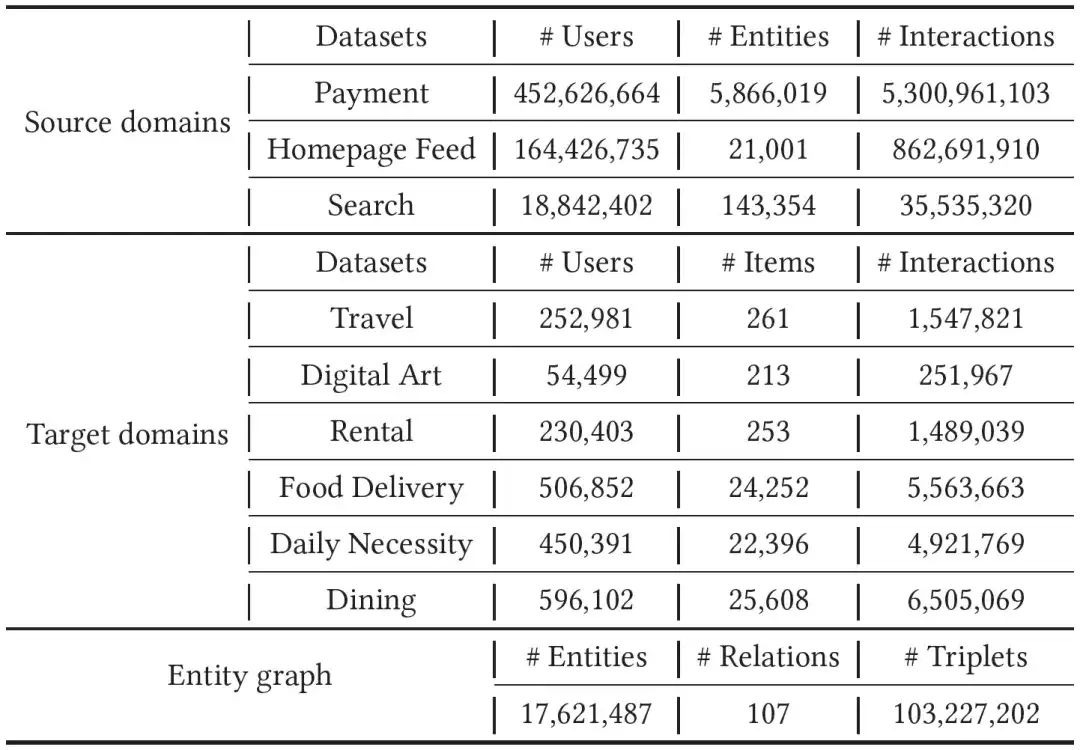
ソースドメインデータとして、1か月分のAlipay請求書、足跡、検索データを収集し、対象ドメインについて、レンタル、旅行、デジタルコレクション、日用品、グルメ、フードデリバリーの6種類のミニプログラムで実験を実施した。実験では、ターゲット ドメインのデータがソース ドメインよりも希薄であるため、モデルのトレーニングのために過去 2 か月間の行動データを収集しました。異なるドメイン間の大きな違いを埋めるために、数千万のノード、数百の関係、数十億のエッジを含むエンティティ グラフを導入しました。具体的なデータは以下の表にあります。
02. 効果実験
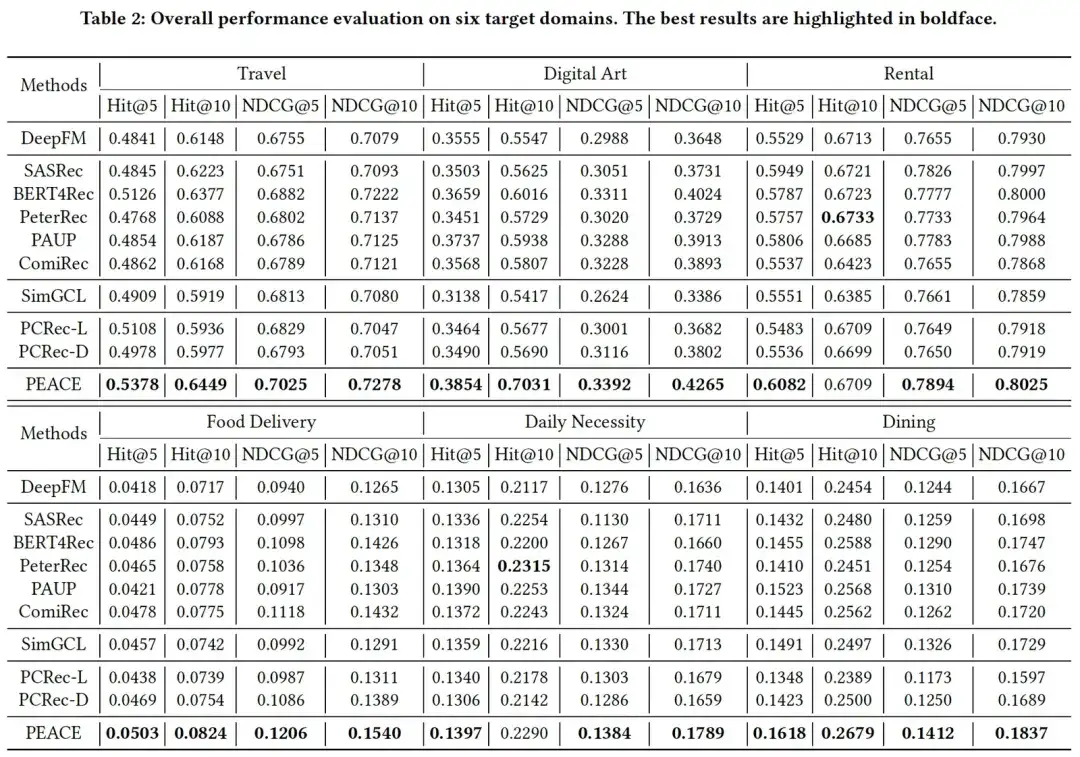
2 つの表の実験結果を組み合わせると、全体として実験結果は次のことを示していることがわかります。
- PEACE は、コールド スタート/非コールド スタートの両方のシナリオでベースラインと比較して大幅な改善を達成しました。これは、エンティティ粒度ベースの事前トレーニングとプロトタイプ学習ベースの強化メカニズムの組み合わせの有効性を示しています。
- ほとんどの場合、事前トレーニングと微調整されたモデルは、事前トレーニングなしのベースライン DeepFM よりも大幅に向上しています。これは、事前トレーニングにマルチソース データを導入することの有効性を示しています。ただし、場合によっては、パフォーマンスが低下する場合もあります。モデルのパフォーマンスはベースライン DeepFM ほど良くなく、ある程度の負の転移があり、これは事前トレーニング方法の重要性をさらに示しています。
- 多くの場合、gnn に基づくクロスドメイン推奨モデルは良好な実験結果を達成できませんでしたが、これは主に、クラス メソッドで類似したエンティティを作成する PEACE モデルにプロトタイプ学習を導入したためです。表現空間内では同様の距離を持ちますが、異なるエンティティ間の距離はより遠くまで引き伸ばされるため、モデルに対するこれらのノイズの悪影響が軽減されます。
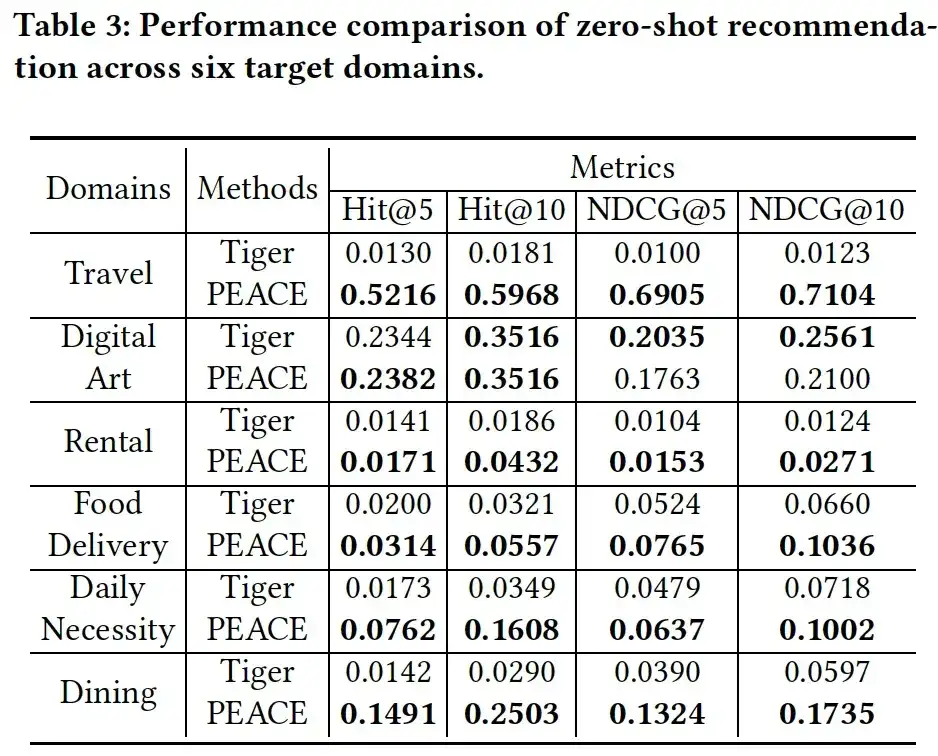
03. アブレーション分析
PEACE モデルにおける各モジュールの役割をさらに検証するために、各モジュールの有効性を評価するために次の 3 つのバリエーションを用意しました。
- PEACE w/o GL、エンティティ表現が削除された場合のグラフ学習モジュール。
- CPL なしの PEACE、つまり、比較ベースのプロトタイプ学習モジュールの削除。
- PEA なしの PEACE。プロトタイプの機能強化に基づいてアテンション メカニズム モジュールを削除します。図 4 からわかるように、いずれかのモジュールが削除されると、モデルのパフォーマンスが大幅に低下します。これは、モデル内の各モジュールが不可欠であることを示しています。さらに、CPL なしの PEACE のパフォーマンスは最悪の場合、低下することがわかります。これは、一般的な移転可能な知識を獲得する際のプロトタイプ学習の重要性を示しています。
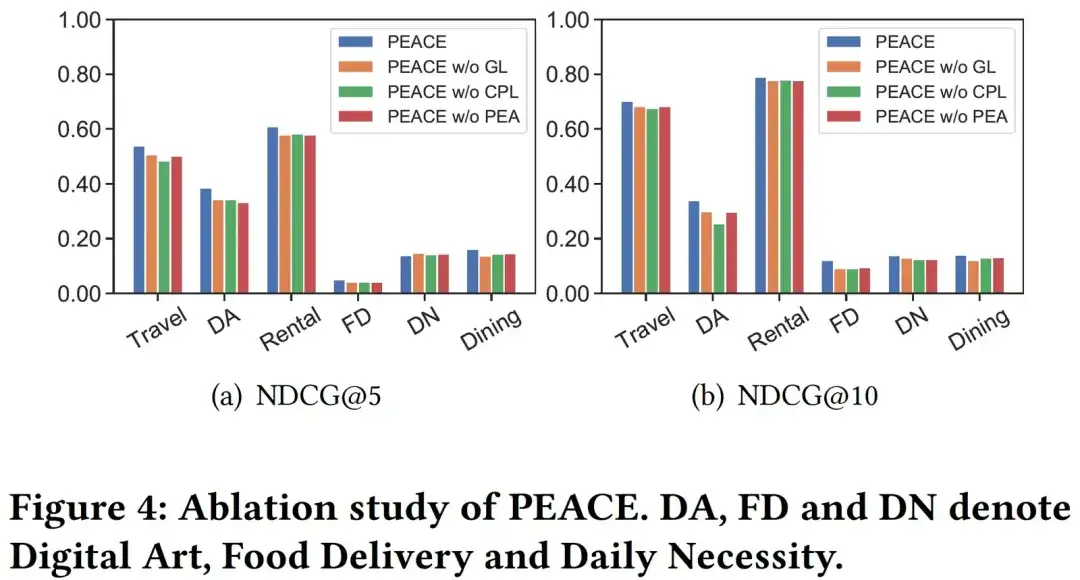
04. 視覚的分析
CPL モジュールの効果をより明確に分析するために、エンティティ マップ内の 6000 個のエンティティと、それらを視覚化するために CPL および PEACE モデルを使用しない PEACE を通じて学習したエンティティ表現をランダムに選択しました。ここではさまざまな色が、所属するさまざまなプロトタイプに対応しています。さまざまなエンティティに。図 5 から、CPL なしで PEACE によって学習されたエンティティ表現と比較して、完全な PEACE モデルによって学習された表現は、クラスタリング結果の一貫性が優れていることがわかります。これは、CPL モジュールとその学習されたプロトタイプが、モデルは表現空間内の同様のエンティティ間の距離を縮め、それによってモデルがより堅牢で普遍的な知識を学習するのに役立ちます。
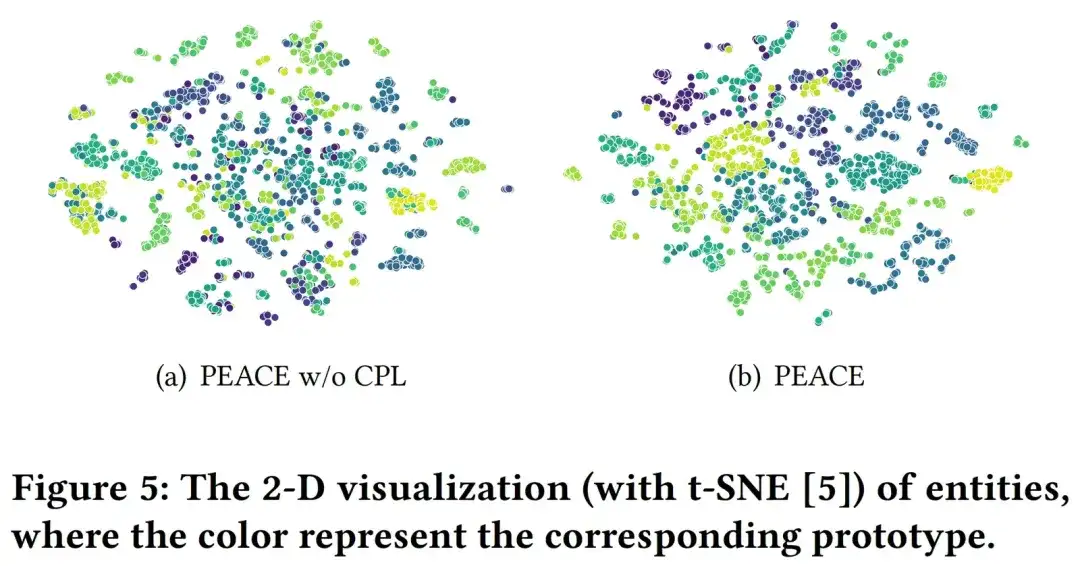
オンライン実験と事業化
実際の本番環境でのモデルの効果をより適切に検証するために、さまざまな垂直カテゴリの複数の加盟店で洗練されたオンライン AB 実験を実施しましたが、PEACE モデルはベースラインのプロモーションと比較して効果的な結果を達成しました。全体として、PEACE ベースの事前トレーニング + 転移学習レコメンデーション モデルは、ベースライン モデルとして 50 以上のマーチャントに完全に適用され、主要マーチャントに対する ab 効果によって検証された後、パーソナライズされた推奨事項を提供しています。
記事の推奨事項
OpenSPG v0.0.3 がリリースされ、大規模モデルの統合知識抽出とグラフ視覚化のオープンソースが追加されました。 Ant Group と浙江大学が共同で、オープンソースの大規模モデル知識抽出フレームワークである OneKE をリリース
【スピーチレビュー】OpenSPG+TuGraphに基づくナレッジグラフの進化と推論演習
論文ダイジェスト | GPT-RE: 大規模言語モデルに基づく関係抽出のためのコンテキスト学習
私たちに従ってください
OpenSPG:
公式ウェブサイト: https://spg.openkg.cn
Github: https://github.com/OpenSPG/openspg
OpenASCE:
官网:https://openasce.openfinai.org/
GitHub:[https://github.com/Open-All-Scale-Causal-Engine/OpenASCE ]