
皆さんも GitHub でスターを付けてください:
分散型フルリンク因果学習システム OpenASCE: https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
大規模なモデル駆動型ナレッジ グラフ OpenSPG: https://github.com/OpenSPG/openspg
大規模グラフ学習システム OpenAGL: https://github.com/TuGraph-family/TuGraph-AntGraphLearning
4月25日と26日、上海のハイアット リージェンシー グローバル ハーバー ホテルで、グローバル機械学習テクノロジー カンファレンスが開催されました。 Ant Group のオープンソース DLRover 責任者である Wang Qinlong 氏は、カンファレンスで「DLRover トレーニング障害の自己修復: 大規模 AI トレーニングのコンピューティング電力効率の大幅な向上」に関する基調講演を行い、障害を迅速に自己修復する方法を共有しました。 Wang Qinlong 氏は、DLRover の背後にある技術原則と使用例、および大規模なコミュニティ モデルに対する DLRover の実際的な効果を紹介しました。

Ant で AI インフラストラクチャの研究開発に長年従事してきた Wang Qinlong 氏は、Ant 分散トレーニングの柔軟なフォールト トレランスと自動拡張および収縮プロジェクトの構築を主導しました。彼は、ElasticDL や DLRover などの複数のオープンソース プロジェクトに参加しており、Open Atomic Foundation の 2023 年の Vibrant Open Source Contributor、および Ant Group の 2022 T-Star Outstanding Engineer に選ばれています。現在、彼は Ant AI Infra オープンソース プロジェクト DLRover のアーキテクトであり、安定性、スケーラブル、効率的な大規模分散トレーニング システムの構築に重点を置いています。
大規模モデルのトレーニングと課題
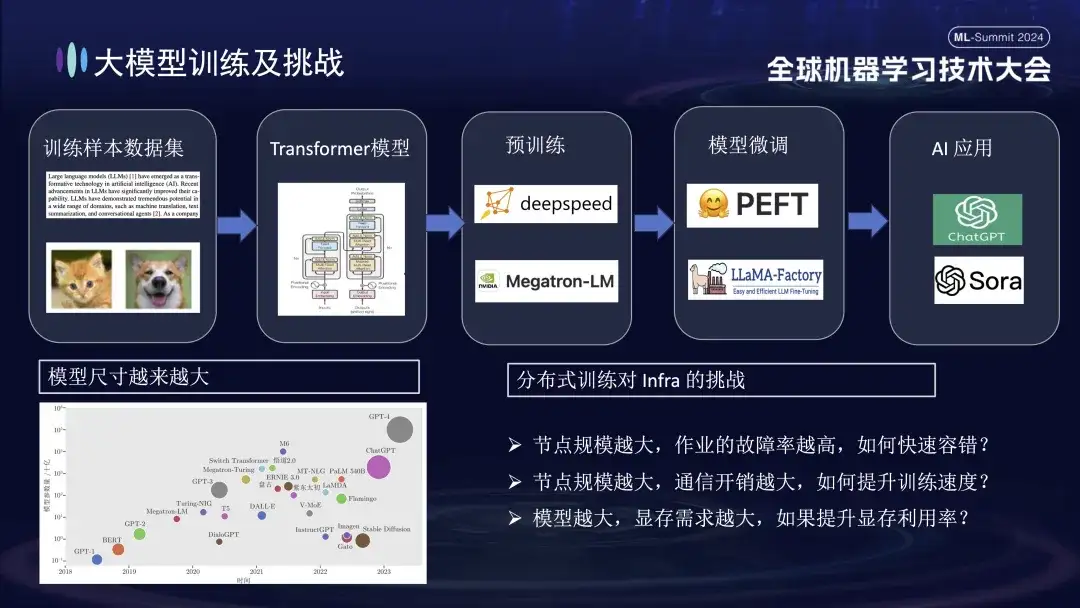
大規模モデルのトレーニングの基本プロセスは、上の図に示されています。これには、トレーニング サンプル データ セットの準備、Transformer モデルの構築、事前トレーニング、モデルの微調整、そして最後にユーザー AI アプリケーションの構築が必要です。大規模なモデルが 10 億パラメータから 1 兆パラメータに移行するにつれて、トレーニング規模の増大によりクラスタ コストが急増し、システムの安定性にも影響を与えています。このような大規模システムによってもたらされる高額な運用保守コストは、大規模モデルの学習中に解決する必要がある緊急の問題となっています。
- ノードのサイズが大きくなるほど、ジョブの失敗率が高くなります。障害を迅速に許容するにはどうすればよいですか?
- ノードのサイズが大きくなると、通信のオーバーヘッドが大きくなります。トレーニング速度を向上させるにはどうすればよいですか?
- ノード サイズが大きくなるほど、メモリ要件も大きくなります。メモリ使用率を改善するにはどうすればよいですか?
Ant AI エンジニアリング テクノロジー スタック
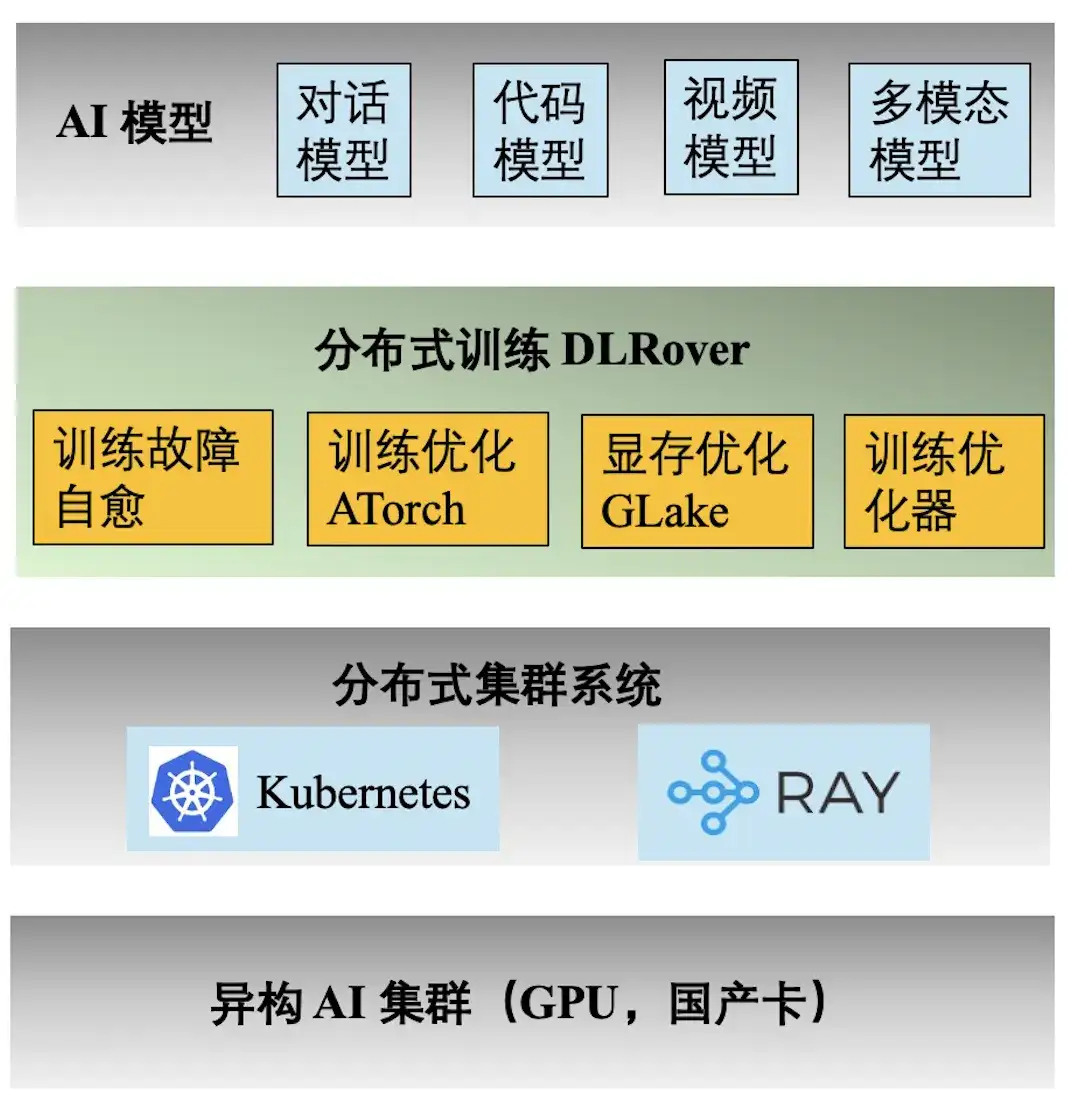
上の図は、Ant AI トレーニングのエンジニアリング テクノロジー スタックを示しています。分散トレーニング エンジン DLRover は、Ant の対話、コード、ビデオ、およびマルチモーダル モデルのさまざまなトレーニング タスクをサポートしています。 DLRover が提供する主な機能は次のとおりです。
- **トレーニング障害の自己修復:** キロカロリー分散トレーニングの有効時間を 97% 以上に延長し、大規模なトレーニング障害の計算能力コストを削減します。
- **トレーニング最適化 ATorch:** モデルとハードウェアに基づいて最適な分散トレーニング戦略を自動的に選択します。 Kcal (A100) クラスター ハードウェアの計算能力利用率を 60% 以上に増加します。
- **トレーニング オプティマイザー:** オプティマイザーはモデル反復のナビゲーションに相当し、最短経路で目標を達成するのに役立ちます。当社のオプティマイザーは、AdamW と比較して収束加速を 1.5 倍向上させます。関連する結果は ECML PKDD '21、KDD'23、NeurIPS '23 で発表されました。
- **ビデオ メモリと伝送の最適化 GLake: **大規模なモデルのトレーニング プロセス中に、大量のビデオ メモリ フラグメントが生成され、ビデオ メモリ リソースの使用率が大幅に削減されます。統合されたメモリ + 送信の最適化とグローバル メモリの最適化により、トレーニング メモリ要件を 2 ~ 10 分の 1 に削減します。結果は ASPLOS'24 で発表されました。
なぜ障害がコンピューティングパワーの浪費につながるのか
Ant がトレーニングの失敗の問題に特に注意を払う理由は、主にトレーニング プロセス中のマシンの故障によりトレーニング コストが大幅に増加するためです。たとえば、Meta は 2022 年の大規模モデル トレーニングの実際のデータを発表しました。OPT-175B モデルのトレーニングでは、992 台の 80GB A100 GPU が使用され、合計 124 台の 8 カード マシンが使用されました。AWS GPU の価格によれば、コストは約 700,000 です。一日あたり。この障害により、トレーニング サイクルが 20 日以上延長され、計算能力コストが数千万元増加しました。

下の図は、Alibaba Cloud クラスターで大規模なモデルをトレーニングするときに発生する障害の分布を示しています。これらの障害の中には、再起動によって解決できるものもありますが、再起動によって修復できないものもあります。たとえば、再起動後も障害のあるカードがまだ損傷しているため、カードの落下の問題が考えられます。システムを再起動して復元するには、損傷したマシンを交換する必要があります。
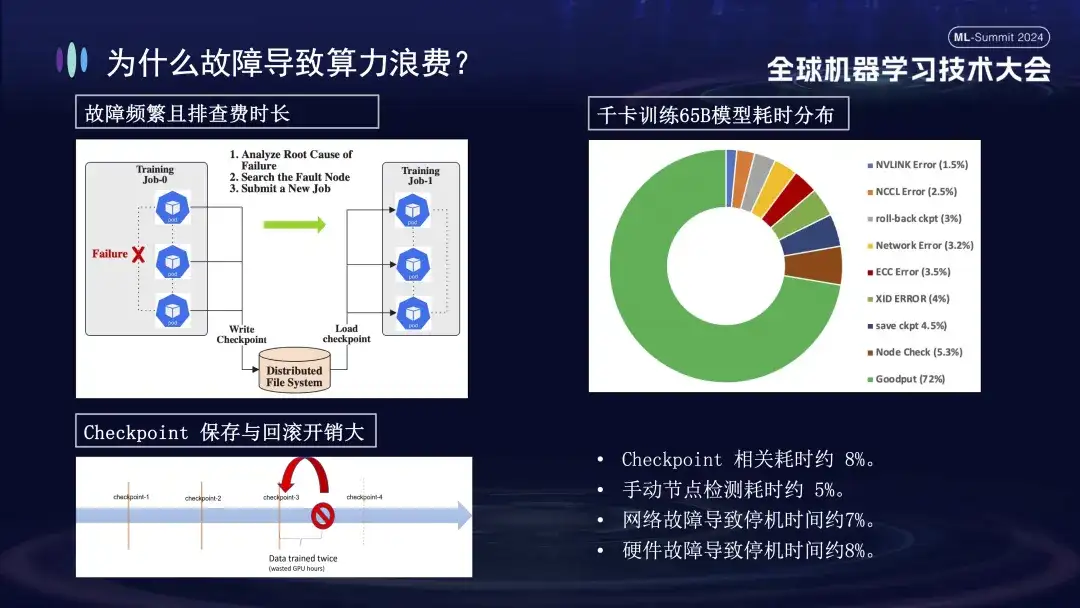
トレーニングの失敗がこれほど大きな影響を与えるのはなぜでしょうか?まず、分散トレーニングでは複数のノードが連携して動作する必要があります。いずれかのノードに障害が発生した場合 (ソフトウェア、ハードウェア、ネットワーク カード、または GPU の問題のいずれか)、トレーニング プロセス全体を中断する必要があります。第 2 に、トレーニングの失敗が発生した後のトラブルシューティングには時間がかかり、労力がかかります。たとえば、現在一般的に使用されている手動検査方法では、1 回のチェックに少なくとも 1 ~ 2 時間かかります。最後に、トレーニングはステートフルです。トレーニングを再開するには、続行する前に前のトレーニング状態から回復する必要があり、一定期間後にトレーニング状態を保存する必要があります。保存処理に時間がかかり、ロールバックに失敗すると無駄な計算も発生します。上の右の図は、自己修復を実行するためにオンラインにする前のトレーニング時間の分布を示しています。チェックポイントの関連時間が約 8%、手動ノード検出の時間が約 5% であり、ダウンタイムが発生していることがわかります。ネットワーク障害によるダウンタイムは約 7%、ハードウェア障害によるダウンタイムは約 8%、最終的な有効トレーニング時間はわずか約 72% です。
DLRover トレーニング障害自己修復機能の概要

上の図は、障害自己修復テクノロジにおける DLRover の 2 つのコア機能を示しています。まず、Flash Checkpoint はトレーニング プロセスを停止することなく状態を迅速に保存し、高頻度のバックアップを実現します。これは、障害が発生した場合に、システムが最新のチェックポイントから即座に回復できることを意味し、データ損失とトレーニング時間を削減します。次に、DLRover は Kubernetes を使用して、インテリジェントで柔軟なスケジューリング メカニズムを実装します。このメカニズムは、ノードの障害に自動的に対応できます。たとえば、100 台のマシンのクラスターで障害が発生した場合、システムは自動的に 99 台のマシンに調整され、手動介入なしでトレーニングを続行します。さらに、Kubeflow および PyTorchJob と互換性があり、ノードの健全性監視機能を強化して、障害を迅速に特定して 10 分以内に対応し、トレーニング操作の継続性と安定性を維持します。
DLRover の柔軟なフォールト トレランス トレーニング
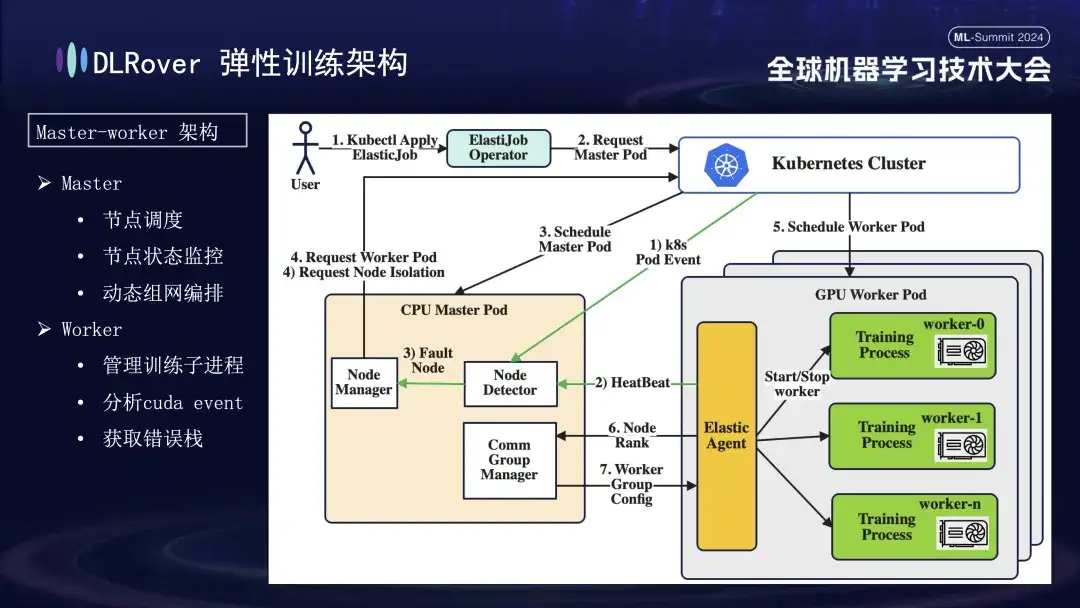
DLRover は、機械学習の初期には一般的ではなかったマスターワーカー アーキテクチャを採用しています。この設計では、マスターがコントロール センターとして機能し、トレーニング コードを実行せずに、ノードのスケジューリング、ステータス監視、ネットワーク構成管理、障害ログ分析などの主要なタスクを担当します。通常は CPU ノードにデプロイされます。実際のトレーニング負荷はワーカーが負担し、各ノードは複数のサブプロセスを実行してノードの複数の GPU を利用してコンピューティング タスクを高速化します。さらに、システムの堅牢性を強化するために、ワーカー上の Elastic Agent をカスタマイズおよび強化し、より効果的な障害の検出と位置特定を可能にし、トレーニング プロセス中の安定性と効率を確保しました。
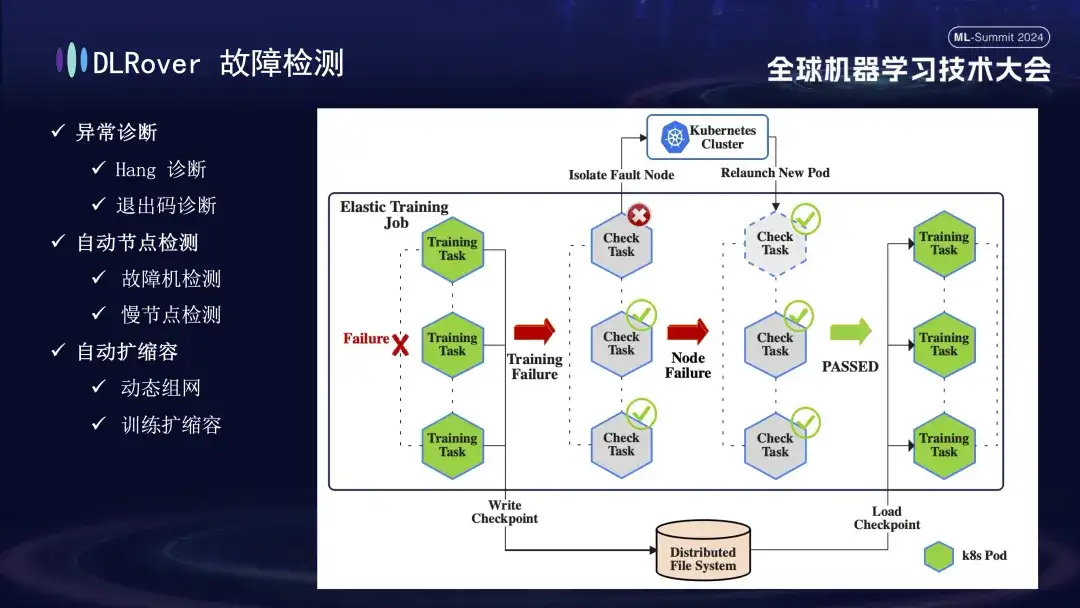
次に障害検出処理です。トレーニング プロセス中に障害が発生し、タスクが中断された場合、直感的にはトレーニングが中断されますが、障害が発生すると、関連するすべてのマシンが同時に停止するため、障害の具体的な原因と原因は直接明らかではありません。 。この問題を解決するために、障害発生後すぐにすべてのマシンで検出スクリプトを実行しました。ノードが検査に不合格であることが検出されると、障害が発生したノードを削除し、新しい代替ノードを再デプロイするように Kubernetes クラスターにただちに通知されます。新しいノードは、既存のノードでさらなるヘルスチェックを完了し、すべてが正しい場合は、トレーニング タスクが自動的に再開されます。なお、障害ノードが切り離されてリソース不足が発生した場合には、削減戦略を実施します(詳細は後述)。元の障害のあるマシンが正常に戻ると、システムは自動的に能力拡張操作を実行し、効率的かつ継続的なトレーニングを保証します。
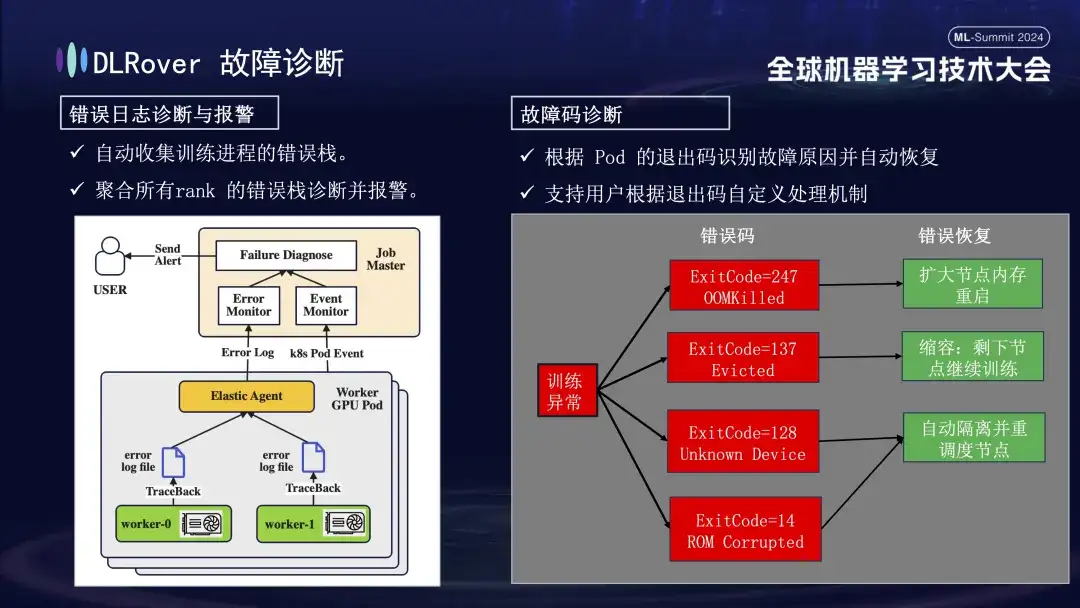
次は障害診断プロセスです。このプロセスでは、次の包括的な方法を使用して、迅速かつ正確な障害の特定と処理を実現します。
- まず、エージェントは各トレーニング プロセスからエラー情報を収集し、これらのエラー スタックをマスター ノードに要約します。次に、マスター ノードは集約されたエラー データを分析して、問題のあるマシンを特定します。たとえば、マシンのログに ECC エラーが示されている場合、マシンの障害が直接特定され、除去されます。
- さらに、Kubernetes の終了コードは、診断を支援するためにも使用できます。たとえば、終了コード 137 は、問題が検出されたために基盤となるコンピューティング プラットフォームがマシンを終了することを示します。終了コード 128 は、デバイスが認識されないことを意味します。 GPUドライバーに問題がある可能性があります。終了コードでは検出できない障害も多数あります。一般的な障害には、ネットワーク ジッター タイムアウトなどがあります。
- また、ネットワーク変動によるタイムアウトなど、終了コードだけでは特定できない障害も多くあります。より一般的な戦略を採用します。障害の具体的な性質に関係なく、主な目標は、障害のあるノードを迅速に特定して削除し、問題がどこにあるのかを具体的に検出するようにマスターに通知することです。
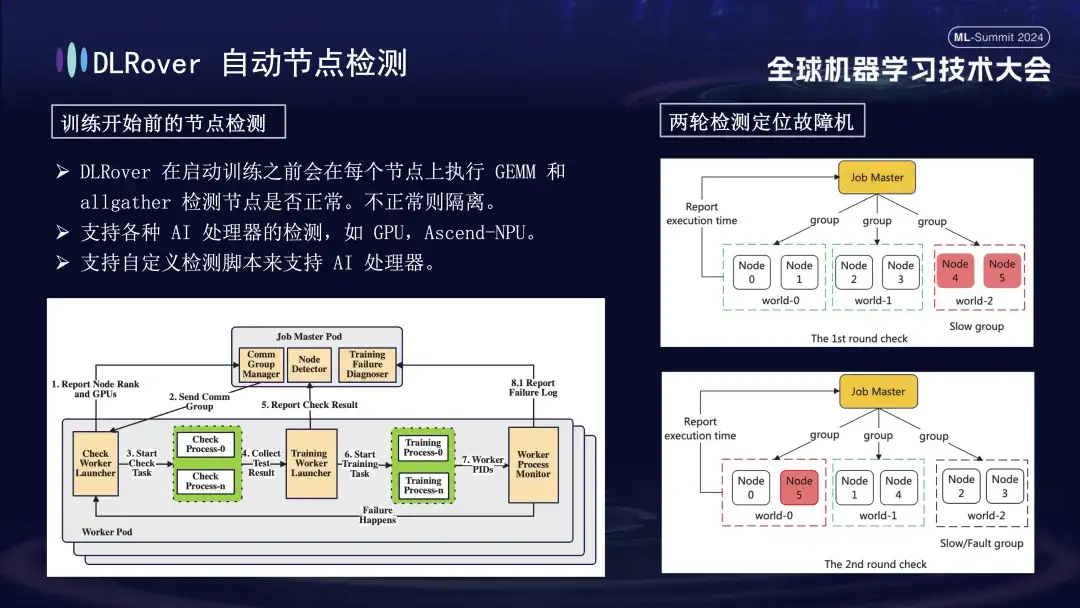
まず、すべてのノードで行列の乗算が実行されます。次に、ノードがペアリングされ、グループ化されます。たとえば、6 つのノードを持つ Pod では、ノードは 3 つのグループ (0,1)、(2,3)、および (4,5) に分割され、AllGather 通信の検出が行われます。実行されました。 4 と 5 の間で通信障害が発生しているが、他のグループの通信は正常である場合、障害はノード 4 または 5 にあると結論付けることができます。次に、障害が疑われるノードは、さらなるテストのために、たとえば、検出のために 0 と 5 を組み合わせて、既知の正常なノードと再ペアリングされます。結果を比較することで、障害が発生したノードを正確に特定します。この自動検査プロセスでは、10 分以内に故障したマシンを正確に診断します。
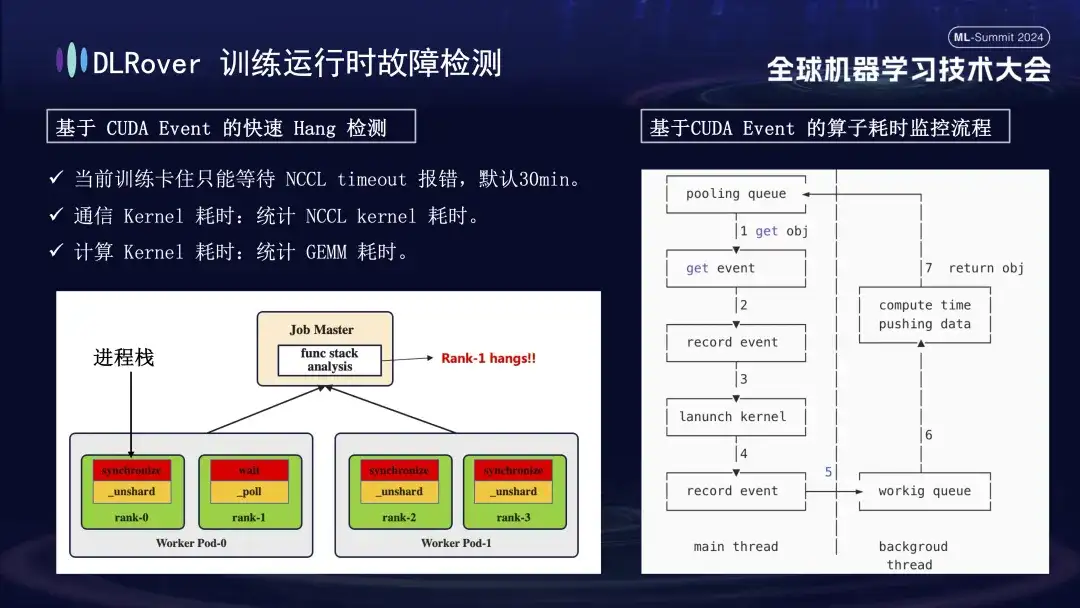
システムの中断と障害検出の状況については以前に説明しましたが、マシンのスタックを特定するという問題は解決する必要があります。 NCCL によって設定されたデフォルトのタイムアウトは 30 分で、誤検知を減らすためにデータを再送信できます。ただし、これにより、カードが実際にスタックしたときに各カードが無駄に 30 分間待機することになり、結果的に膨大な累積損失が発生する可能性があります。スタックを正確に診断するには、洗練されたプロファイリング ツールを使用することをお勧めします。例えば、番組の一時停止を検知した場合、1分以内に番組スタックに変化がなかった場合、各カードのスタック情報を記録し、その差分を比較・分析する。たとえば、4 つのランクのうち 3 つが同期操作を実行し、1 つが待機操作を実行していることが判明した場合、デバイスの問題を特定できます。さらに、主要なCUDA通信カーネルと計算カーネルを乗っ取り、その実行前後にイベント監視を挿入し、イベント間隔を計算することで正常に動作しているかどうかを判定しました。たとえば、特定の操作が予想される 30 秒以内に完了しない場合、その操作はスタックしていると見なされ、関連するログとコール スタックが自動的に出力され、比較のためにマスターに送信され、障害のあるマシンを迅速に特定します。
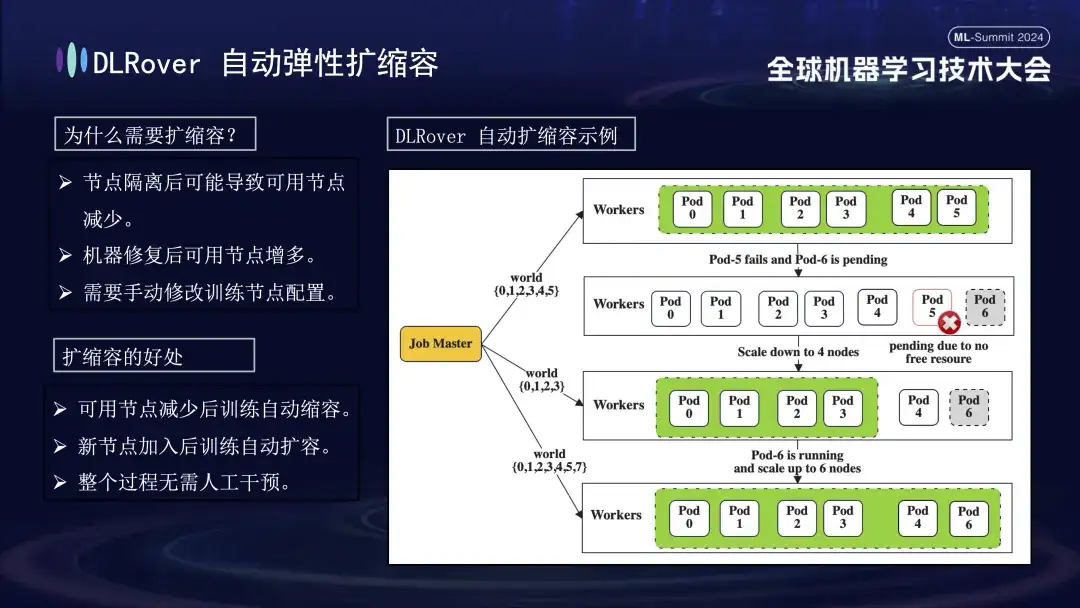
障害のあるマシンが特定された後は、コストと効率を考慮して、以前のトレーニングでバックアップの仕組みはありましたが、その数は限られていました。現時点では、弾力的な拡大と縮小の戦略を導入することが特に重要です。元のクラスターに 100 個のノードがあると仮定します。ノードに障害が発生すると、残りの 99 個のノードがトレーニング タスクを続行できます。障害が発生したノードが修復された後、システムは自動的に 100 個のノードまで動作を再開でき、このプロセスには手動の介入は必要ありません。効率的で安定したトレーニング環境を確保します。
DLRover フラッシュ チェックポイント
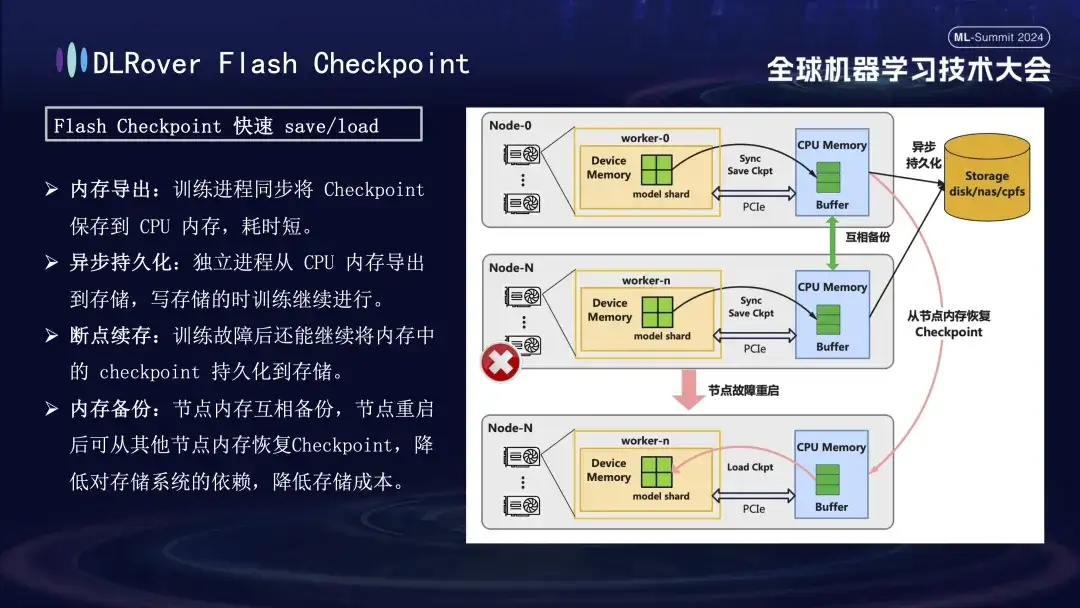
障害回復のトレーニングのプロセスで重要なのは、モデルの状態を保存して復元することです。従来のチェックポイント方法では、多くの場合、時間が節約されるため、トレーニング効率が低くなります。この問題を解決するために、DLRover は革新的にフラッシュ チェックポイント ソリューションを提案しました。これは、トレーニング プロセス中にほぼリアルタイムでモデルのステータスを GPU メモリからメモリにエクスポートできます。また、メモリ間バックアップ メカニズムによって補完され、たとえノードに障害が発生した場合、バックアップ ノード メモリからトレーニング ステータスを迅速に復元できるため、障害回復時間が大幅に短縮されます。一般的に使用される Megatron-LM の場合、チェックポイントのエクスポート プロセスは調整して完了するための集中プロセスを必要とし、これにより通信負荷とメモリ消費が増加するだけでなく、時間コストも高くなります。 DLRover は、最適化後に革新的なアプローチを採用し、分散エクスポート戦略を使用して、各コンピューティング ノード (ランク) が独自のチェックポイントを個別に保存およびロードできるようにすることで、追加の通信とメモリの要件を効果的に回避し、効率を大幅に向上させます。
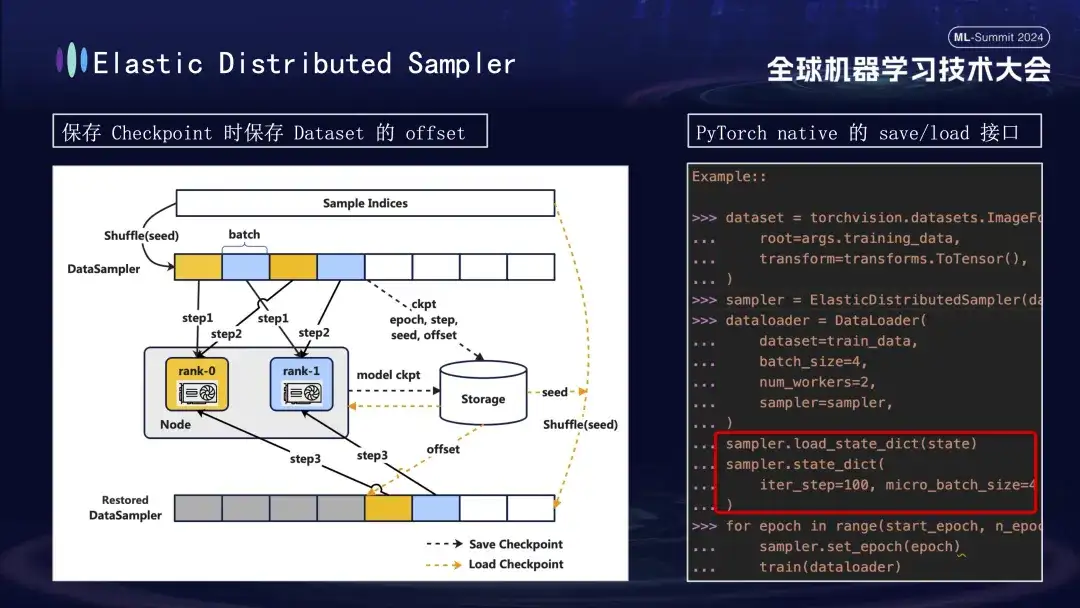
モデルのチェックポイントを作成するときは、注意すべき点がもう 1 つあります。モデルのトレーニングは、トレーニング プロセスのステップ 1000 でチェックポイントを保存すると仮定して、データに基づいて行われます。データの進行状況を考慮せずに後でトレーニングを再開した場合、データを最初から直接再利用すると、後続の新しいデータが失われる可能性と、以前のデータが再利用される可能性があるという 2 つの問題が発生します。この問題を解決するために、分散サンプラー戦略を導入しました。チェックポイントを保存するとき、この戦略はモデルのステータスを記録するだけでなく、データ読み取りのオフセット位置も保存します。このようにして、トレーニングを再開するためにチェックポイントをロードするときに、以前に保存したオフセット ポイントからデータ セットが引き続きロードされ、トレーニングが進められるため、モデル トレーニング データの連続性と一貫性が確保され、データ エラーや繰り返し処理が回避されます。 。
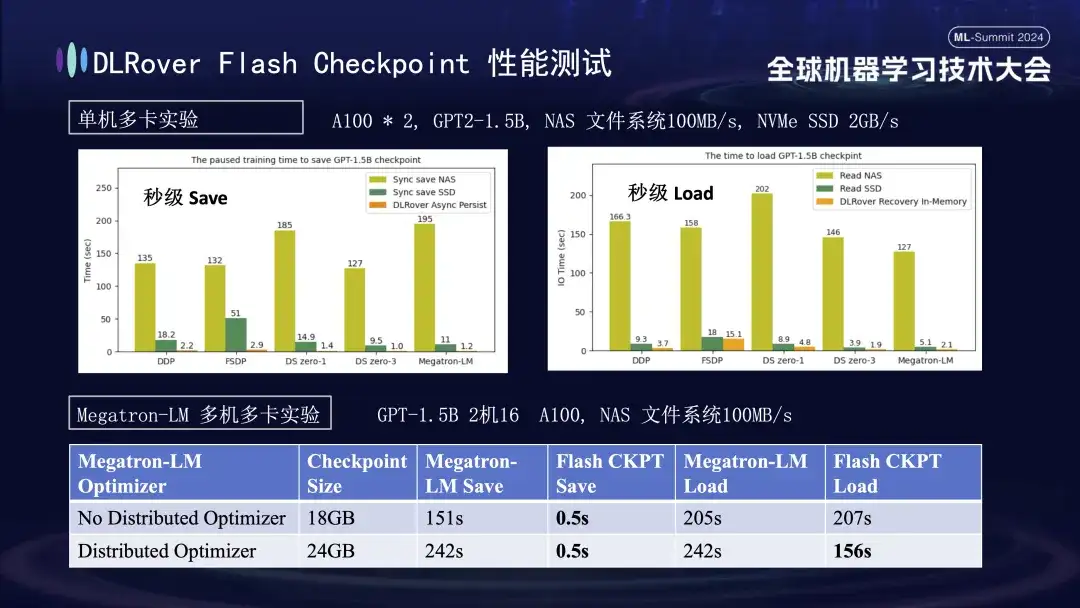
上のグラフでは、単一マシンのマルチ GPU (A100) 環境での実験結果を示しています。これは、トレーニング プロセス中のチェックポイントの保存によって発生するブロック時間に対する、さまざまなストレージ ソリューションの影響を比較することを目的としています。実験では、ストレージ システムのパフォーマンスが効率に直接影響することが示されています。効率の低いストレージ方法を使用してチェックポイントをディスクに直接書き込むと、トレーニングが大幅にブロックされ、時間が延長されます。具体的には、サイズが約 20GB の 1.5B モデル Checkpoint の場合、NAS ストレージを使用する場合、書き込み時間は約 2 ~ 3 分になります。つまり、メモリにデータを非同期に一時的に保存することで、書き込み時間は大幅に短縮されます。このプロセスにかかる時間は平均して約 1 秒だけであり、トレーニングの継続性と効率が大幅に向上します。

DLRover の Flash Checkpoint 機能は、DDP、FSDP、DeepSpeed、Megatron-LM、transformers.Trainer および Ascend-DDP などの主要な主流の大規模モデル トレーニング フレームワークと広く互換性があり、各フレームワークに合わせてカスタマイズされた API を備えているため、ユーザーは非常に使いやすくなります。既存のトレーニング コードを調整する必要はほとんどなく、すぐに機能します。具体的には、DeepSpeed フレームワークのユーザーは、Checkpoint の実行時に DLRover の保存インターフェイスを呼び出すだけで済みます。一方、Megatron-LM の統合は、ネイティブの Checkpoint インポート ステートメントを DLRover が提供するインポート メソッドに置き換えるだけで済みます。 。 できる。
DLRover の分散トレーニングの実践
システムの耐障害性、低速ノードの処理能力、スケールアップとスケールダウンの柔軟性を評価するために、各障害シナリオに対して一連の実験を実施しました。具体的な実験内容は以下の通りです。
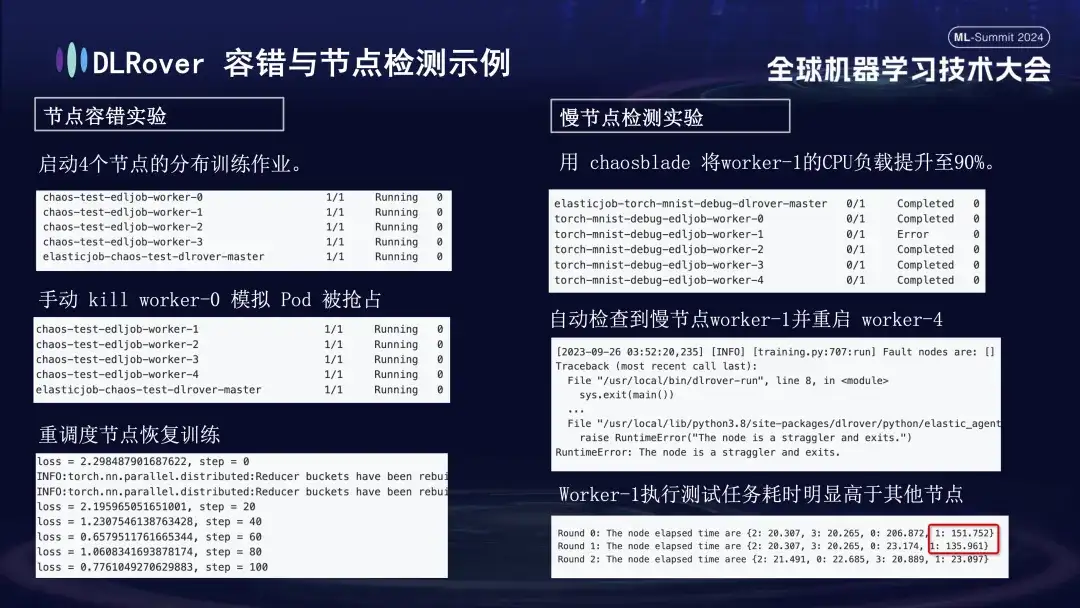
- ノードのフォールト トレランス実験: 一部のノードを手動でシャットダウンして、クラスターが迅速に回復できるかどうかをテストします。
- 低速ノードの実験: Chaosblade ツールを使用してノードの CPU 負荷を 90% に増やし、時間のかかる低速ノードの状況をシミュレートします。
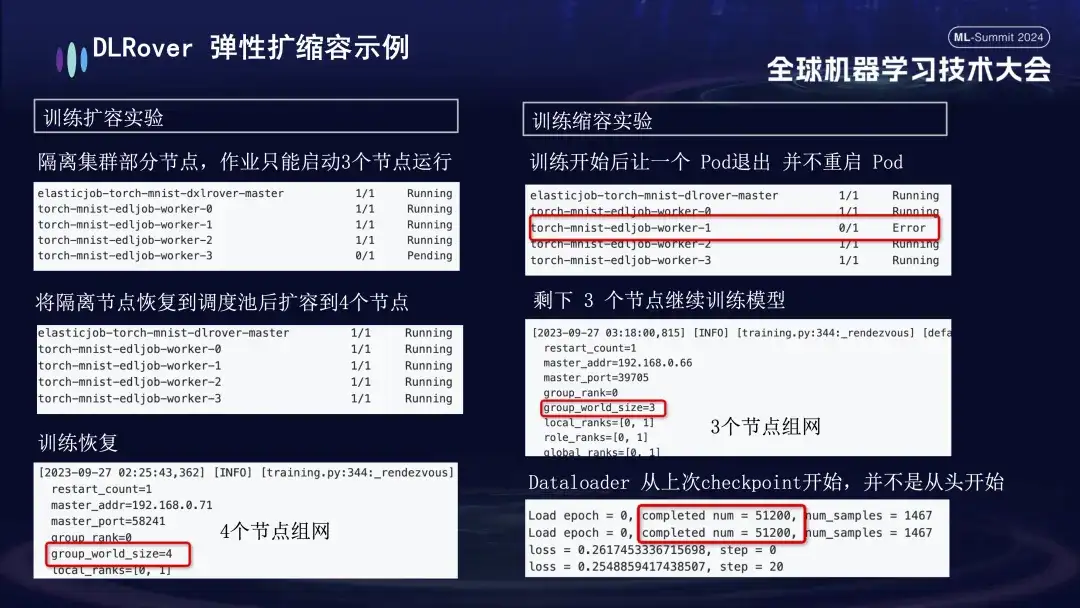
- 膨張と収縮の実験: マシン リソースが不足しているシナリオをシミュレートします。たとえば、ジョブが 4 つのノードで構成されているが、実際に開始されるのは 3 つのノードだけである場合でも、これら 3 つのノードは通常どおりトレーニングできます。一定の時間が経過した後、ノードの分離をシミュレートしたところ、トレーニングに使用できるポッドの数が 3 に減りました。このマシンがスケジューリング キューに戻ると、使用可能なポッドの数を 4 に増やすことができます。この時点で、データローダーは最初からやり直すのではなく、最後のチェックポイントからトレーニングを続行します。
国内カードにおける DLRover の実践
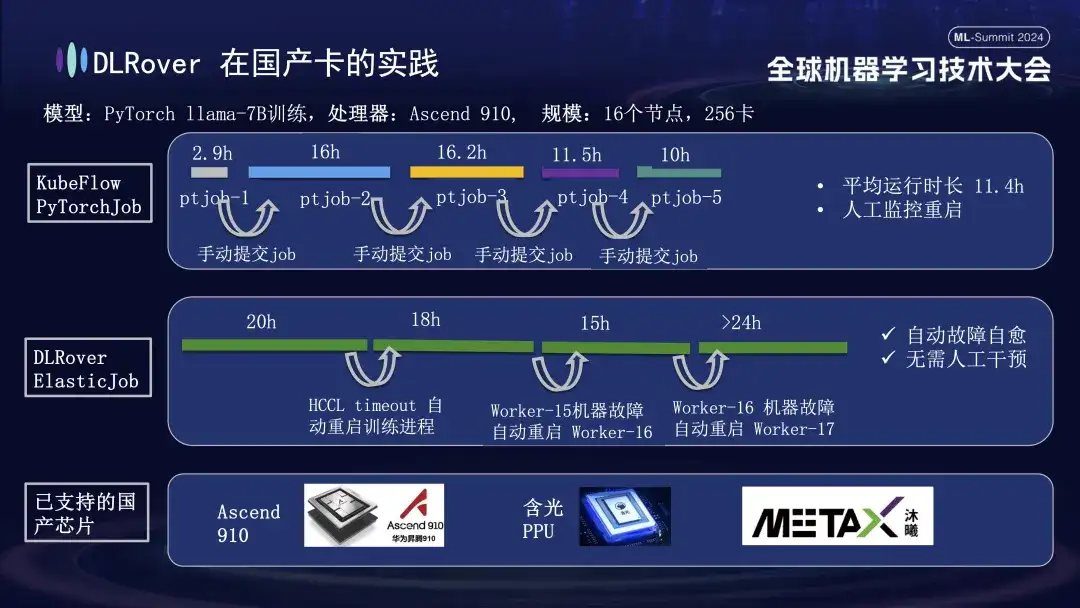
DLRover 障害自己修復機能は、GPU のサポートに加えて、国内アクセラレータ カードの分散トレーニングもサポートします。たとえば、LLama-7B モデルを Huawei Ascend 910 プラットフォームで実行したとき、大規模なトレーニングに 256 枚のカードを使用しました。最初は KubeFlow の PyTorchJob を使用していましたが、このツールには耐障害性がなかったため、トレーニング プロセスが約 10 時間続いた後に自動的に終了してしまい、ユーザーはタスクを手動で再送信する必要がありました。そうしないと、クラスター リソースが失われます。アイドル。 2 番目の図は、トレーニング障害の自己修復が有効になっているトレーニング プロセス全体を示しています。トレーニングが 20 時間進行したときに、通信タイムアウト障害が発生しました。この時点で、システムはトレーニング プロセスを自動的に再開し、トレーニングを再開しました。約 40 時間後、マシンのハードウェア障害が発生しました。システムは障害のあるマシンをすぐに隔離し、トレーニングを続行するためにポッドを再起動しました。 Huawei Ascend 910のサポートに加えて、AlibabaのHanguang PPUとも互換性があり、Muxi Technologyと協力してDLRoverを使用して独自に開発したQianka GPUでLLAMA2-65Bモデルをトレーニングします。
DLRover 1,000 枚のカード、1,000 億個のモデルのトレーニング実践
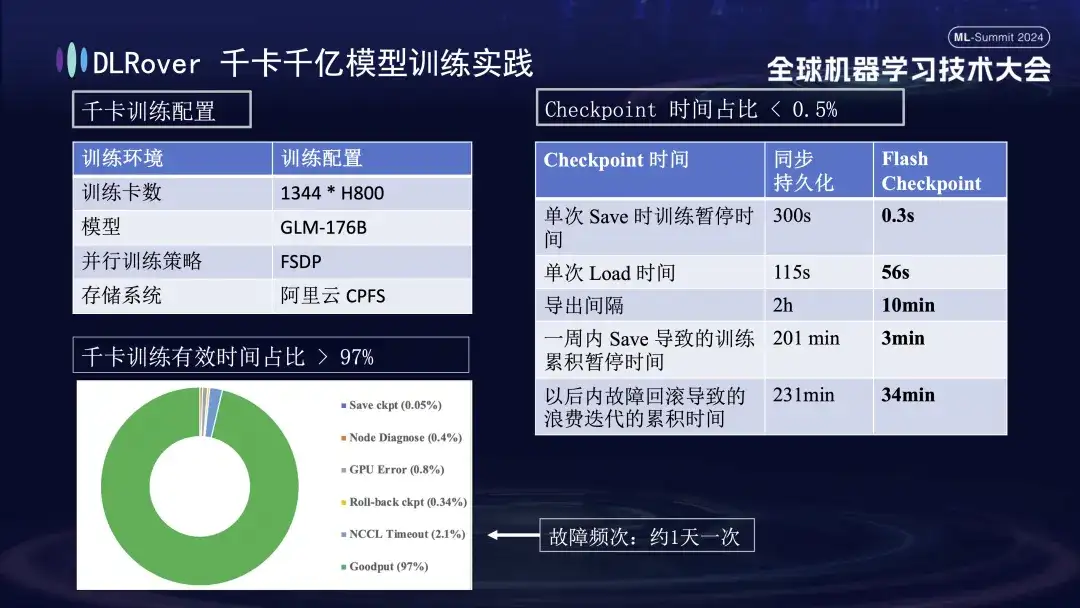
上の図は、キロカード トレーニングに対する DLRover トレーニング障害自己修復の実際の効果を示しています。障害頻度が 1 日 1 回の場合、トレーニング障害自己修復の後に、1,000 枚を超える H800 カードが使用されます。ヒーリング機能の導入により、効果的なトレーニング時間は97%以上を占めます。右側の比較表は、Alibaba Cloud の高性能ストレージ FSDP を使用した場合でも、1 回の保存に約 5 分かかるのに対し、Flash Checkpoint テクノロジーでは完了までにわずか 0.3 秒しかかからないことを示しています。さらに、最適化によりノード効率が 1 分近く向上しました。エクスポート間隔については、当初は2時間ごとにエクスポートを行っていましたが、Flash Checkpoint機能の開始後は10分ごとの高頻度エクスポートが可能になりました。 1 週間以内に保存操作に費やされる累積時間は、ほとんど無視できます。同時にロールバック時間は従来に比べて約5倍に短縮されました。
DLRover 計画とコミュニティ構築

DLRover は現在 3 つのメジャー バージョンをリリースしており、6 月には CUDA イベントに基づいたランタイム障害検出をリリースする V0.4.0 がリリースされる予定です。
- V0.1.0(2023/07): k8s/ray 上の TensorFlow PS の弾性フォールト トレランスと自動拡張と縮小。
- V0.2.0(2023/09): k8s での PyTorch 同期トレーニングのノード検出と柔軟なフォールト トレランス;
- V0.3.5(2024/03): フラッシュ チェックポイントと国内カード障害検出。
将来の計画に関して、DLRover は、ノードのスケジューリングと管理、Lynx のコンパイルと最適化、トレーニング最適化フレームワーク AToch、および国内カード トレーニングの面で DLRover の機能の最適化と改善を継続します。
- **ノードのスケジューリングと管理: **通信トポロジを認識したスケジューリングにより、リングベースの AllReduce 通信中のトップレベル スイッチの通信トラフィックを削減します。ハードウェア メトリック収集と障害予測。
- **コンパイル最適化 lynx: **計算グラフのスケジューリングの最適化、最適な通信と計算のオーバーラップを実現し、通信遅延を隠蔽します。
- **トレーニング最適化フレームワーク ATorch: **RLHF トレーニングの最適化、分散トレーニングの初期化高速化、auto_accelerate;
- **国内カード トレーニング: **障害の自己修復やトレーニングの高速化などの機能を国内カードに拡張し、国内カード トレーニングのベスト プラクティスを提供します。

技術の進歩はオープンなコラボレーションから始まります。GitHub 上のオープンソース プロジェクトをフォローして参加することは誰でも歓迎されます。
DLローバー:
https://github.com/intelligent-machine-learning/dlrover
グレーク:
https://github.com/intelligent-machine-learning/glake
当社の WeChat パブリックアカウント「AI Infra」でも、AI インフラストラクチャに関する最先端の技術記事を定期的に公開し、最新の研究結果や技術的洞察の共有を目指します。同時に、さらなる交流と議論を促進するために、ここで誰でも参加して質問したり、関連する技術的な問題について議論したりできる DingTalk グループも設立しました。皆さん、ありがとうございました!
記事の推奨事項
AI トレーニングのコンピューティング電力効率の向上: Ant DLRover 障害自己修復テクノロジーの革新的な実践
AIインフラのアーキテクトを紹介:高速大型モデル「レーシングカー」の「車輪を変える」人
[オンライン リプレイ] NVIDIA GTC 2024 カンファレンス | AI エンジニアリング コストを削減するには?トレーニングから推論までの Ant のフルスタックの実践
