
OpenAI が ChatGPT-4o をリリースしました。これは、人間とコンピューターの対話が新しい時代に入ったことを意味します。 Chat-GPT4o は、テキスト、ビジョン、オーディオにわたってエンドツーエンドでトレーニングされた新しいモデルであり、すべての入力と出力が同じニューラル ネットワークによって処理されます。これはまた、GenAI が非構造化データを接続し、非構造化データ間のクロスモーダル インタラクションがますます容易になっているということをすべての人に伝えています。
IDC の予測によると、2025 年までに全世界データの 80% 以上が非構造化データとなり、ベクトル データベースは非構造化データを処理するための重要なコンポーネントとなります。ベクター データベースの歴史を振り返ると、2019 年に Zilliz が初めて Milvus を立ち上げ、ベクター データベースの概念を提案しました。 2023 年の大規模言語モデル (LLM) の爆発的な増加により、ベクトル データベースが舞台裏から表舞台に正式に押し上げられ、急速な開発の流れに追いつきました。
関連する技術者として、技術開発の点でベクター データベースの進歩のスピードをはっきりと感じており、ベクター データベースが単純な ANNS から徐々に進化していく様子を目の当たりにしています ( https://zilliz.com.cn/glossary/%E8%BF% 91% E4%BC%BC%E6%9C%80%E8%BF%91%E9%82%BB%E6%90%9C%E7%B4%A2%EF%BC%88anns%EF%BC%89)シェルはより多様かつ複雑になります。本日はベクトルデータベースの開発の方向性について技術的な観点からお話したいと思います。
技術開発の方向性は製品の変化する傾向に従う必要があり、後者は需要によって決まります。したがって、ユーザーニーズの変化する状況に従うことは、技術変化の方向性と目的を見つけるのに役立ちます。 AI テクノロジーが成熟するにつれて、ベクター データベースの使用は実験から実稼働へ、補助製品から主要製品へ、小規模アプリケーションから大規模展開へと徐々に移行してきました。これにより、多数のさまざまなシナリオや問題が発生し、これらの問題を解決するための対応するテクノロジーも促進されます。以下では、コストとビジネス ニーズの 2 つの側面から説明します。
01. コスト
AIGC 時代のホットおよびコールド ストレージの必要性
コストは、ベクトル データベースの広範な使用に対する最大の障害の 1 つです。このコストは次の 2 つの点から生じます。
-
ストレージ: 低遅延を確保するために、ほとんどのベクトル データベースはすべてのデータをメモリまたはローカル ディスクにキャッシュする必要があります。この AI の時代では、AI の量は数百億のオーダーになることが多く、これは数百テラバイトまたは数百テラバイトのリソース消費を意味します。
-
コンピューティングの場合、大規模なデータ セットの分散サポートのエンジニアリング要件を満たすために、データを多くの小さなフラグメントに分割する必要があります。各シャードを個別に取得して回避する必要があるため、より大きなクエリ計算増幅の問題が発生します。数百億のデータを 10G シャードに分割すると、シャード数は 10,000 となり、計算は 10,000 倍になります。
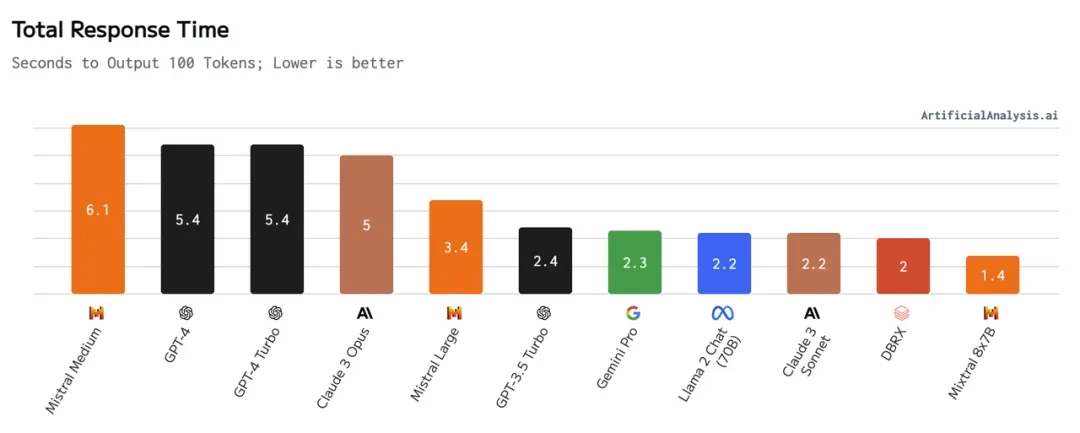 主流の LLM の応答時間、出典: https://artificialanalysis.ai/models
主流の LLM の応答時間、出典: https://artificialanalysis.ai/models
AIGC によってもたらされる RAG ウェーブでは、単一の RAG ユーザー (または ToC プラットフォームの単一テナント) は遅延に対する感度が非常に低くなります。その理由は、ベクトル データベースのレイテンシが数ミリ秒から数百ミリ秒であるのに比べ、リンクの核となる大規模モデルのレイテンシは一般に 2 番目のレベルを超えるためです。さらに、クラウド オブジェクト ストレージのコストは、ローカル ディスクやメモリのコストよりもはるかに低くなります。次のことを実現するテクノロジーのニーズが高まっています。
-
ストレージの観点から見ると、クエリを実行する場合、データはコールド ストレージとして最も安価なクラウド オブジェクトに配置され、必要に応じてノードにロードされ、クエリを提供するためにホット ストレージに変換されます。
-
計算の観点から見ると、各クエリに必要なデータは、ホット ストレージに侵入されないように、グローバル データに拡張せずに事前に絞り込まれます。
このテクノロジーは、許容可能な遅延内でユーザーがコストを大幅に削減するのに役立ちます。これは、Zilliz Cloud (https://zilliz.com.cn/cloud) が現在立ち上げを準備しているソリューションでもあります。
ハードウェアの反復によってもたらされるチャンス
ハードウェアはすべての基盤であり、ハードウェアの開発はベクトル データベース技術の開発の方向性を直接決定します。これらのハードウェアをさまざまなシナリオにどのように適応させて活用するかが、開発の非常に重要な方向性となっています。
- コスト効率の高い GPU
ベクトル検索はコンピューティング集約型のアプリケーションであり、過去 2 年間で、コンピューティングの高速化に GPU を使用する研究がますます増えています。高価な固定観念に反して、アルゴリズム レベルが段階的に成熟していることと、ベクトル取得シナリオがメモリ レイテンシの低い安価な推論カードに適しているという事実により、GPU ベースのベクトル取得は優れたコスト パフォーマンスを示します。
 CPU: m6id.2xlarge T4: g4dn.2xlarge A10G: g5.2xlarge トップ 100 リコール: 98% データセット: https://github.com/zilliztech/VectorDBBench
CPU: m6id.2xlarge T4: g4dn.2xlarge A10G: g5.2xlarge トップ 100 リコール: 98% データセット: https://github.com/zilliztech/VectorDBBench
テストには GPU インデックス作成をサポートする Milvus を使用しましたが、コストはわずか 2 ~ 3 倍でしたが、インデックス構築とベクトル取得の両方で数倍から数十倍のパフォーマンスの差が見られました。高スループットのシナリオをサポートするためでも、インデックス構築を高速化するためでも、ベクトル データベースの使用コストを大幅に削減できます。
- 変わり続けるARM
主要なクラウド ベンダーは、AWS の Graviton や GCP の Ampere など、ARM アーキテクチャに基づいた独自の CPU を絶えず投入しています。 AWS Graviton3 で関連テストを実施したところ、x86 と比較して、より優れたパフォーマンスを提供しながら、より低価格のハードウェアを提供できることがわかりました。さらに、これらの CPU は非常に急速に進化しています。たとえば、2022 年の Graviton3 の発売後、AWS は 2023 年にコンピューティング能力が 30% 向上し、メモリ帯域幅が 70% 向上した Graviton4 をリリースしました ( https://press.aboutamazon. com/2023/11/aws-unveils-next-generation-aws-designed-chips)。
- 強力なディスク
ほとんどのデータをディスクに保存すると、ベクトル データベースの容量が大幅に増加し、ほとんどの場合、このレベルで十分であり、ディスクのコストはメモリの数十パーセントまたは 1 パーセントになります。
モデル側の双方向ラッシュ
モデルはベクトルを生成し、ベクトル データベースはベクトルの保存とクエリをサポートします。全体としては、ベクトルデータベース側のコスト削減を追求するとともに、モデル側でもベクトルサイズの削減を図っています。
たとえば、ベクトルの次元では、ベクトルに導入された従来の次元削減スキームがクエリの精度に大きな影響を与えます。また、OpenAI によってリリースされた ext-embedding-3-large ( https://openai.com/index/ new -embedding-models-and-api-updates/) モデルは、パラメーターを通じて出力ベクトルの次元を制御できますが、ベクトルの次元は小さくなりますが、ダウンストリーム タスクのパフォーマンスにはほとんど影響しません。ベクトル データ型に関しては、Cohereの最近のブログ ( https://cohere.com/blog/int8-binary-embeddings)で、float、int8、および binary データ型のベクトルの同時出力のサポートが発表されました。ベクトル データベースにとって、これらの変化にどのように適応するかは、積極的に検討する必要がある方向でもあります。
02.ビジネスニーズ
ベクトル検索の精度を向上させる
検索の精度は常に重要なテーマです。プロダクション アプリケーションの普及や、RAG アプリケーションでのより高度な関連性の要件のせいで、ベクトル データベースはより高い検索品質を目指して努力しています。このプロセスでは、大きすぎるチャンクによる情報損失の問題を解決する ColBERT や、ドメイン外の情報取得の問題を解決する Sparse など、新しいテクノロジーが常に登場しています。以下の図は、Sparse、Dense、および ColBERT ベクトルの同時出力をサポートする BGE の M3-Embedding モデルの評価結果を示しています。下の表は、ハイブリッド検索に使用した検索品質の比較結果を示しています。

ベクトル データベースの場合、これらのテクノロジーをハイブリッド検索に使用して検索品質を向上させる方法も重要な開発の方向性です。
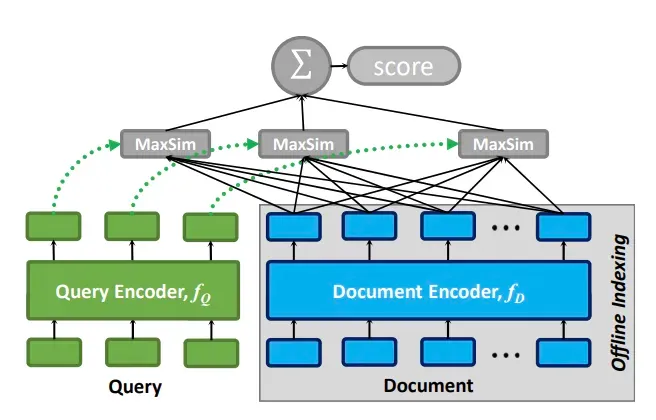
- コルバート
ColBERT は、従来のツインタワー モデルにおける大きなチャンクによって引き起こされる情報損失の問題を解決し、同時に従来の検索モデルの完全接続によって引き起こされる検索効率の問題を回避するために、ColBert が提案した検索モデルです。トークンベクトルに基づく後期インタラクションモード。 ColBERTv2 では、最終的な遅延対話モードを高速化するために、ベクトル取得も導入されています。
- まばらな
従来の密ベクトルは意味論的な情報を捉えるのに優れていますが、モデルはモデルのトレーニング中にトレーニング データ内の知識しか学習できないため、トレーニング データでカバーされていない新しい語彙や専門用語に対する密ベクトルの表現能力は限られています。そして、これは実際のアプリケーションでは非常に一般的です。一般的なモデルの微調整でこの問題はある程度解決できますが、コストが高く、リアルタイムのパフォーマンスが課題に直面します。
現時点では、従来のキーワード マッチングに基づいて BM25 によって生成されたスパース ベクトルが良好に機能します。さらに、SPLADE や BGE の M3-Embedding などのモデルは、スパース ベクトルのキーワード マッチング機能を維持しながら、より多くの情報をエンコードして、検索品質をさらに向上させようとします。
実際、業界ではキーワード検索とベクトル検索に基づくハイブリッド呼び出しシステムが長い間使用されてきました。新世代のスパース ベクトルをベクトル データベースに統合し、ハイブリッド検索機能をサポートすることが徐々にコンセンサスになってきました。 Milvus は、バージョン 2.4 でスパース ベクトル取得機能も正式にサポートしています。
オフライン シナリオ向けにベクトル データベースをさらに最適化
現在、ほぼすべてのベクトル データベースは、RAG ( https://zilliz.com.cn/blog/ragbook-technology-development)、画像検索 (https://zilliz.com.cn/ ユースケースなど)を含むオンライン シナリオに焦点を当てています。 /画像類似性検索)など。
オンライン シナリオは、少量、高頻度、および遅延に対する高い要件が特徴です。最もコスト重視でパフォーマンスが最も重要ではないシナリオでも、多くの場合、数秒レベルの遅延が必要になります。
実際、ベクトル検索は、大規模なデータ処理の多くのオフライン シナリオで重要な役割を果たします。たとえば、データ重複排除や特徴マイニングなどのバッチ処理タスクや、リコール信号の 1 つとしてベクトルの類似性を使用する検索および推奨システムでは、通常、オフラインの事前計算ステップとしてベクトル取得が使用され、特徴の更新が定期的に実行されます。これらのオフライン シナリオは、バッチ クエリ、大量のデータなどを特徴とし、タスクに要する時間は数分から数時間かかる場合もあります。
オフライン シナリオをサポートするには、ベクトル データベースで多くの新しい問題を解決する必要があります。例をいくつか示します。
-
コンピューティングの効率: 一部の検索および推奨シナリオのオフライン コンピューティング部分など、多くのオフライン シナリオでは、大量のデータに対する効率的なバッチ クエリが必要です。このシナリオでは、個々のデータの遅延は必要ありませんが、オンライン シナリオよりも全体的に高い計算効率が必要です。この種の問題をより適切にサポートするには、計算密度を高める GPU インデックス作成などの機能をサポートする必要があります。
-
大きな利益: データ マイニングでは、モデルが特定の種類のシーンを見つけるのを助けるためにベクトル検索がよく使用されます。これには通常、大量のデータを返す必要があります。これらの返された結果によって引き起こされる帯域幅の問題にどう対処するか、および大規模な topK 検索のアルゴリズムの効率が、このようなシナリオをサポートするための鍵となります。
上記の課題が解決できれば、ベクター データベースはオンライン アプリケーションだけでなく、より多くのシナリオのアプリケーションを幅広くサポートできるようになります。
より豊富なベクター データベース機能が、より多くの業界ニーズに適応します
ベクター データベースが生産現場でますます広く使用されるようになるにつれて、さまざまな使用方法が登場し、さまざまな業界でも使用されています。業界や特定のシナリオに関連性の高いこれらの要件により、ベクター データベースはさらに多くの機能をサポートできるようになります。
-
バイオ医薬品産業: バイナリ ベクトルは通常、検索用の薬物の分子式を表現するために使用されます。
-
リスク管理業界: 最も類似したベクトルではなく、最も外れ値のベクトルを見つける必要があります。
-
範囲検索機能: ユーザーは類似度のしきい値を設定し、しきい値よりも高い類似度を持つすべての結果を返すことができます。結果の数が推定できない場合でも、返された結果の関連性が高いことを保証できます。
-
Groupby 関数と Aggregation 関数: 大きな非構造化データのペア (映画、記事) の場合、通常、フレームやテキストなどのセグメント内のベクトルを生成します。これらのセグメント化されたベクトルを通じて要件を満たす結果を検索するには、ベクトル データベースが Groupby と結果を集約する機能をサポートする必要があります。
-
マルチモーダル モデルのサポート: マルチモーダル モデルへのモデル開発の傾向により、異なる分布を持つベクトルが生成され、既存のアルゴリズムでは検索ニーズを満たすことが困難になります。
前述のさまざまな業界向けの機能強化は、ベクトル データベースのダイナミックな開発特性を浮き彫りにします。ベクター データベースは継続的にアップグレードおよび最適化され、さまざまな業界の AI アプリケーションの複雑なニーズを満たすためのより豊富な機能が導入されます。
03. 概要
ベクトル データベースは過去 1 年間で急速な成熟プロセスを経験し、使用シナリオとベクトル データベース自体の機能の点で大きな発展が見られました。 AI がますます目に見える時代になると、この傾向はさらに加速するでしょう。これらの個人的な要約と分析がインスピレーションとして役立ち、ベクター データベースの開発にアイデアやインスピレーションを提供し、将来的にはさらにエキサイティングな変化を受け入れることができることを願っています。
未知のオープンソースプロジェクトはどれくらいの収益をもたらすのでしょうか? Microsoftの中国AIチームは数百人を巻き込んでまとめて米国に向かいましたが、 Yu Chengdong氏の転職は 15年間の「恥の柱」に釘付けになったと正式に発表されました。前に、しかし今日、彼は私たちに感謝しなければなりません— Tencent QQ Video は過去の屈辱を晴らしますか? 華中科技大学のオープンソース ミラー サイトが外部アクセス向けに正式にオープン レポート: 開発者の 74% にとって Django が依然として第一候補であるZed エディターは、 有名なオープンソース企業の元従業員 によって開発されました。 ニュースを伝えた: 部下から異議を申し立てられた後、技術リーダーは激怒し無礼になり、女性従業員は解雇され、妊娠した。 Alibaba Cloud が Tongyi Qianwen 2.5 を正式リリース Microsoft が Rust Foundation に 100 万米ドルを寄付