
著者紹介: Zhang Ji 氏は、システムの最下層/ネットワークの最適化を中心に、Soutui/LLM のトレーニングの最適化に従事しています。
背景
大規模モデルのパラメータ数が数十億から数兆に跳ね上がるにつれて、そのトレーニング規模の急速な拡大はクラスターコストの大幅な増加を引き起こすだけでなく、システムの安定性、特にマシン障害の頻繁な発生にも課題をもたらします。無視できない問題。大規模な分散トレーニング タスクでは、可観測性機能がトラブルシューティングとパフォーマンスの最適化の鍵となっています。したがって、大規模モデルのトレーニングの分野に従事する技術者は、必然的に次の課題に直面することになります。
- トレーニング プロセス中、ネットワークやコンピューティングのボトルネックなどのさまざまな要因により、パフォーマンスが不安定になったり、変動したり、低下したりする場合があります。
- 分散トレーニングでは、複数のノードが連携して動作します。いずれかのノードに障害が発生した場合 (ソフトウェア、ハードウェア、ネットワーク カード、GPU の問題を問わず)、トレーニング プロセス全体を中断する必要があり、トレーニングの効率に重大な影響を及ぼし、貴重な GPU リソースを浪費します。
ただし、実際の大規模なモデルのトレーニング プロセスでは、これらの問題のトラブルシューティングが困難です。主な理由は次のとおりです。
- トレーニング プロセスは同期操作であり、全体的なパフォーマンス指標を通じて、現時点でどのマシンに問題があるかを除外することは困難です。マシンが遅いと、全体的なトレーニング速度が遅くなる可能性があります。
- トレーニング パフォーマンスの低下は、多くの場合、トレーニング ロジック/フレームワークに問題はありませんが、通常は環境が原因であり、トレーニング関連のモニタリング データがない場合、タイムラインの印刷は実際には効果がなく、タイムライン ファイルを保存するためのストレージ要件も影響します。高い;
- たとえば、トレーニングがハングした場合、トーチがタイムアウトする前にすべてのスタックの印刷を完了してから分析する必要があるため、大規模なタスクに直面した場合、トーチのタイムアウト内に完了するのは困難です。
大規模な分散トレーニング運用では、トラブルシューティングとパフォーマンスの向上のために、監視可能な機能が特に重要です。大規模なトレーニングの実践において、Ant は AI トレーニングの可観測性要件を満たす xpu_timer ライブラリを開発しました。将来的には、XPU タイマーを DLRover にオープンソースにする予定です。皆さんも協力して一緒に構築してください:) xpu_timer ライブラリは、cublas/cudart ライブラリをインターセプトし、cudaEvent を使用して行列の乗算/set 通信操作の時間を計測するプロファイリング ツールです。トレーニングに加え、タイムライン分析、ハング検出、ハング スタック分析などの機能も備えており、さまざまな異種プラットフォームをサポートするように設計されています。このツールには次の機能があります。
- コードへの侵入やトレーニングのパフォーマンスの損失はなく、トレーニング プロセスに常駐させることができます。
- ユーザーには無関心、フレームワークにも無関心
- 低損失・高精度
- インジケーターの集約/配信を実行して、データのさらなる処理と分析を容易にすることができます。
- 情報ストレージの効率が高い
- 便利な対話型インターフェイス: 他のシステムとの統合を容易にし、ユーザーの操作を直接行うための使いやすい外部インターフェイスを提供し、洞察と意思決定のプロセスを加速します。
デザイン
まず、トレーニングのハングやパフォーマンスの低下の問題に対処するために、永続的なカーネル タイミングを設計しました。
- ほとんどのシナリオでは、トレーニングのハングは nccl 操作によって引き起こされます。通常、必要なのは行列の乗算と通信の設定だけです。
- 単一マシン (ECC、MCE) でのパフォーマンスの低下については、行列の乗算を記録するだけで済みます。同時に、行列の乗算を分析することで、ユーザーの行列の形状が科学的であるかどうかを確認し、各フレームワークのパフォーマンスを最大化することもできます。行列乗算を実装するときに cublas を直接使用します。
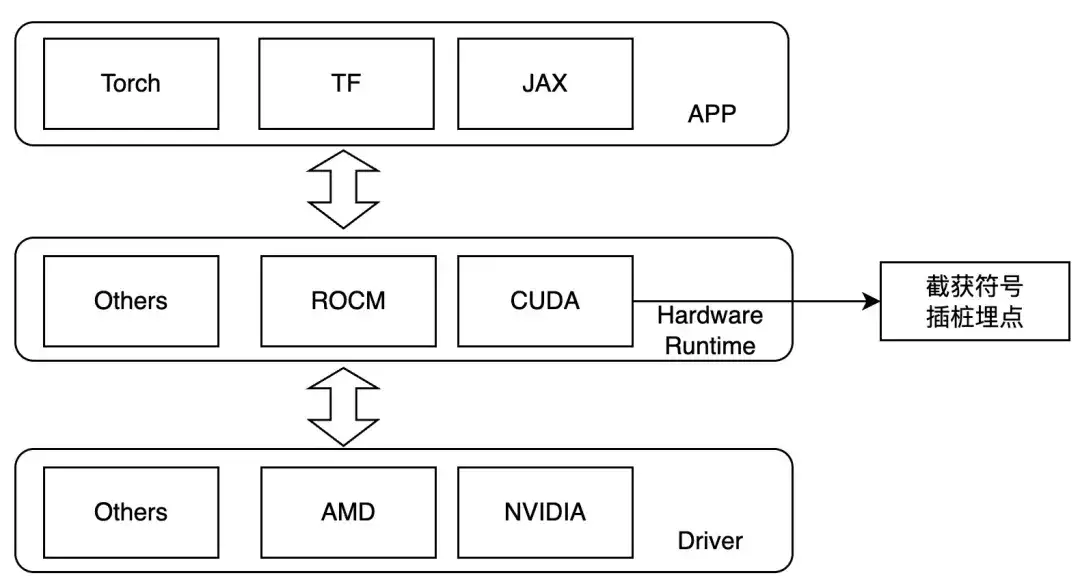
したがって、カーネル起動層でインターセプトし、実行時に LD_PRELOAD を設定して対象の操作をトレースするように設計します。この方法は、動的リンクの場合にのみ使用できます。現在、主流のトレーニング フレームワークは動的リンクです。 NVIDIA GPU の場合、次の記号に注目してください。
- ibcudart.so
- cuda起動カーネル
- cudaLaunchKernelExC
- libcublas.so
- キュブラスジェムエクス
- cublasGemmStriddBatchedEx
- キュブラス中尉マトムル
- キュブラスゲム
- cublasSgemmStrideBatched
異なるハードウェアに適応させる場合、異なるトレース機能が異なるテンプレート クラスを通じて実装されます。
ワークフロー
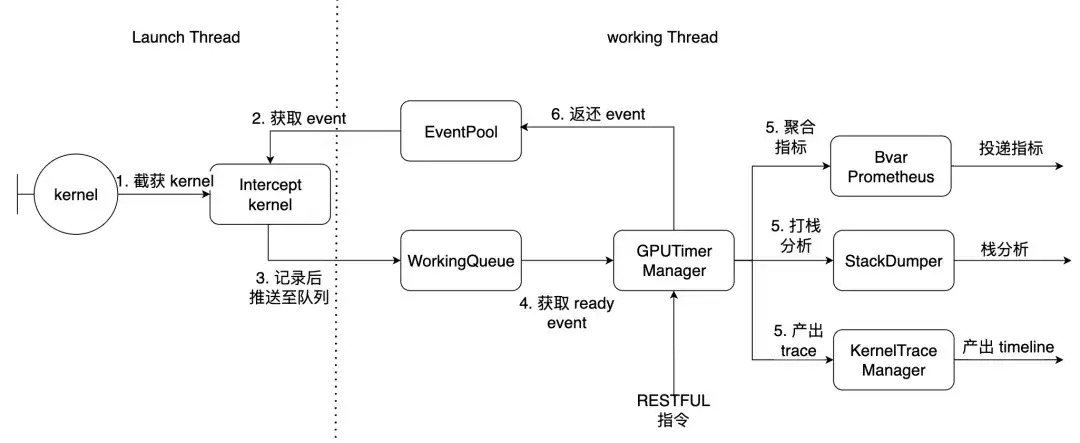
PyTorch を例にとると、Launch Thread はトーチのメイン スレッドであり、作業スレッドはライブラリ内の作業スレッドです。前述の 7 つのカーネルがここでインターセプトされます。
使い方と効果
前提条件
- NCCL は libtorch_cuda.so に静的にコンパイルされます
- torch は libcudart.so を動的にリンクします
NCCL が動的にリンクされている場合、カスタム関数オフセットを提供し、実行時に動的に解決できます。 Python パッケージをインストールすると、次のコマンド ライン ツールが使用できるようになります。
| xpu_timer_gen_syms | nccl を動的に生成および解析するためのライブラリの動的挿入関数オフセット |
| xpu_timer_gen_trace_timeline | クロムトレースの生成に使用されます |
| xpu_timer_launch | フックパッケージをマウントするために使用されます |
| xpu_timer_stacktrace_viewer | タイムアウト後にビジュアルスタックを生成するために使用されます |
| xpu_timer_print_env | libevent.so アドレスを出力し、コンパイル情報を出力します。 |
| xpu_timer_dump_timeline | タイムライン ダンプをトリガーするために使用されます |
LD_PRELOAD 用法:XPU_TIMER_XXX=xxx LD_PRELOAD=`path to libevent_hook.so` python xxx
リアルタイムの動的キャプチャ タイムライン
各ランクにはポート サービスがあり、すべてのランクに同時にコマンドを送信する必要があります。起動ポートは brpc で、各ランク トレースのデータ サイズは 32K です。生成されるタイムライン json のサイズは 150K * ワールド サイズであり、torch のタイムラインの基本的な使用量
usage: xpu_timer_dump_timeline [-h]
--host HOST 要 dump 的 host
--rank RANK 对应 host 的 rank
[--port PORT] dump 的端口,默认 18888,如果一个 node 用了所有的卡,这个不需要修改
[--dump-path DUMP_PATH] 需要 dump 的地址,写绝对路径,长度不要超过 1000
[--dump-count DUMP_COUNT] 需要 dump 的 trace 个数
[--delay DELAY] 启动这个命令后多少秒再开始 dump
[--dry-run] 打印参数
単一マシンの状況
xpu_timer_dump_timeline \
--host 127.0.0.1 \
--rank "" \
--delay 3 \
--dump-path /root/lizhi-test \
--dump-count 4000
多机情况# 如下图所示,如果你的作业有 master/worker 混合情况(master 也是参与训练的)
# 可以写 --host xxx-master --rank 0
# 如果还不确定,使用 --dry-run
xpu_timer_dump_timeline \
--host worker \
--rank 0-3 \
--delay 3 --dump-path /nas/xxx --dump-count 4000
xpu_timer_dump_timeline \
--host worker --rank 1-3 \
--host master --rank 0 --dry-run
dumping to /root/timeline, with count 1000
dump host ['worker-1:18888', 'worker-2:18888', 'worker-3:18888', 'master-0:18888']
other data {'dump_path': '/root/timeline', 'dump_time': 1715304873, 'dump_count': 1000, 'reset': False}
次のファイルは、後で対応するタイムライン フォルダーに追加されます。

次に、このファイルの下で xpu_timer_gen_trace_timeline を実行します。
xpu_timer_gen_trace_timeline 3 つのファイルが生成されます。
- merged_tracing_kernel_stack補助ファイル、フレームグラフオリジナルファイル
- Trace.json マージされたタイムライン
- tracing_kernel_stack.svg、行列乗算/nccl のコールスタック
ラマレシピ 32 カードの SF 分析の事例
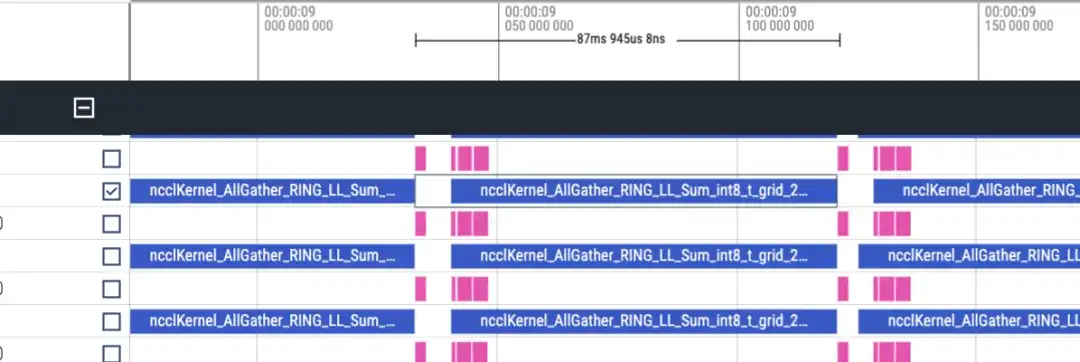
タイムラインはおおよそ次のようになります。各ランクは matmul/nccl を 2 行表示し、すべてのランクが表示されます。ここには順方向/逆方向の情報がないことに注意してください。逆方向は順方向の 2 倍の長さによって大まかに判断できます。

順方向タイムライン、約 87 ミリ秒
逆タイムライン 約 173ms
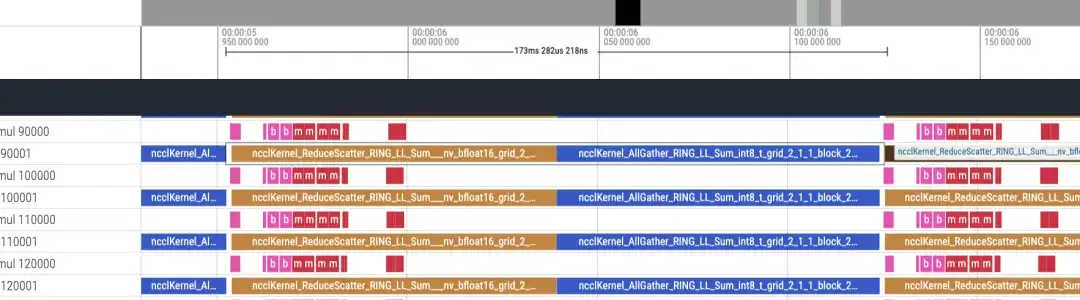
合計 48 層あり、合計時間は (173+87)*48 = 12480ms です。lmhead、埋め込みなどの処理を含めると、全体の時間は約 13 秒かかります。そしてタイムラインを見ると、通信時間が計算時間よりもはるかに長いことが分かり、ボトルネックの原因は通信であると判断できます。
ハングスタック分析
pip を使用してパッケージをインストールした後、コマンド ライン ツールを使用してパッケージを分析できます。デフォルトでは、pstack/py-spy を使用して svg イメージを Chrome にドラッグして、特定のスタック情報を出力します。対応するスタックを出力し、トレーニング プロセスの結果を標準エラー出力に出力します。 conda 経由で gdb をインストールする場合、gdb の Python API を使用してスタックを取得します。デフォルトでインストールされている gdb8.2 のアドレスは /opt/conda/bin/ である場合があります。 gdb は、NCCL タイムアウトをシミュレートする 2 枚のカード スタックです。

以下は、単一マシンでの 8 カードの llama7B sft トレーニングの例です。
Python パッケージによって提供されるツールを使用して、集計スタックのフレーム スタック グラフを生成できます。ここでは、ランク 1 なしのスタックが表示されます。これは、8 枚のカードのトレーニング中に -STOP ランク 1 を強制終了することでハングがシミュレートされているためです。停止状態。
xpu_timer_stacktrace_viewer --path /path/to/stack
运行后会在 path 中生成两个 svg,分别为 cpp_stack.svg, py_stack.svg
スタックをマージする場合、同じコールパスをマージできる、つまりスタックトレースが完全に一貫していると考えられるため、メインスレッドでスタックしているほとんどの場所は同じになりますが、いくつかのループとアクティブなスレッドがある場合、出力されるスタックのトップは一致しない可能性がありますが、同じスタックがボトムで実行されます。たとえば、Python スタックのスレッドは [email protected] でスタックします。また、フレーム グラフのサンプル数は意味を持ちません。ハングが検出されると、すべてのランクで対応するスタックトレース ファイルが生成され (ランク 1 は一時停止されているため、ファイルはありません)、各ファイルには Python/C++ の完全なスタックが含まれます。
マージされたスタックは次のとおりです。Python スタックでは、スタックのカテゴリを区別するために異なる色が使用されます。
- シアンは CPython/Python です
- 赤はC/その他のシステム関連
- 緑はトーチ/NCCL
- 黄色はC++です

Python スタックは次のとおりです。青いブロック図は特定のスタックで、命名規則は次のとおりです: func@source_path@stuck_rank|leak_rank
- func は現在の関数名です。gdb が取得できない場合は表示されます。
- source_path、プロセス内のこのシンボルの so/source アドレス
- stack_rank は、どのランク スタックがここに入るかを表します。ランク 0、1、2、3 -> 0-3 のように、連続したランク番号が開始と終了に折り畳まれます。
- Leak_rank は、どのスタックがここに入っていないのかを表し、ここのランク番号もフォールドされます。
つまり、図の意味は、rank0、rank2~7がすべて同期中のままで、rank1が入ってこないということなので、rank1に問題がある(実際には停止している)と分析できます。この情報はスタックの最上位にのみ追加されます

同様に、cpp のスタックを見ると、メインスレッドが同期でスタックし、最終的に cuda.so の取得時間でスタックしていることがわかります。これも、このスタックがなければ、ランク 1 のみであると考えられます。 __libc_start_main が配置されているスタックは、プロセスのエントリ ポイントを表します。
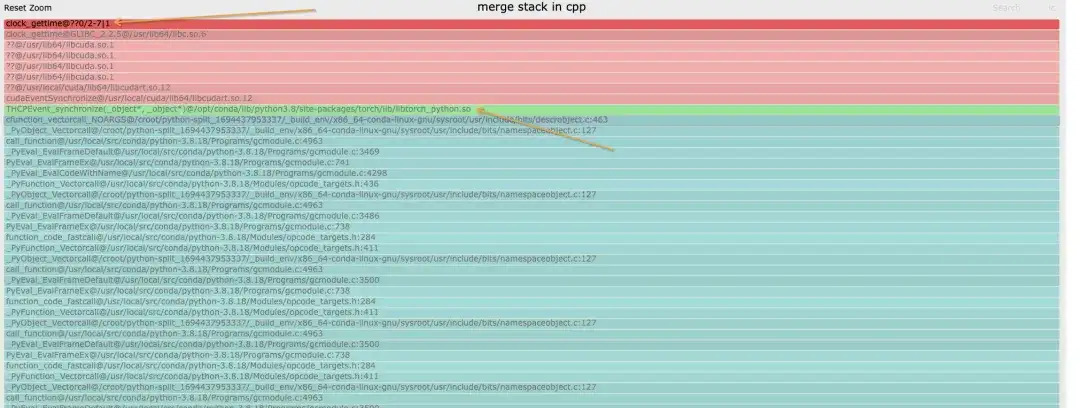
一般に、スタック内に最も深いリンクは 1 つだけであると考えられます。分岐が発生した場合、異なるランクが異なるリンクにスタックしていることがわかります。
カーネルコールスタック分析
torch タイムラインとは異なり、タイムラインにはコールスタックがありません。タイムラインを生成するとき、対応するスタック ファイル名は tracing_kernel_stack.svg です。このファイルを chrome にドラッグして確認します。
- 緑色は NCCL 動作です
- 赤いのはマットムル操作です
- シアンのものは Python スタックです

グラファナ市場の展示
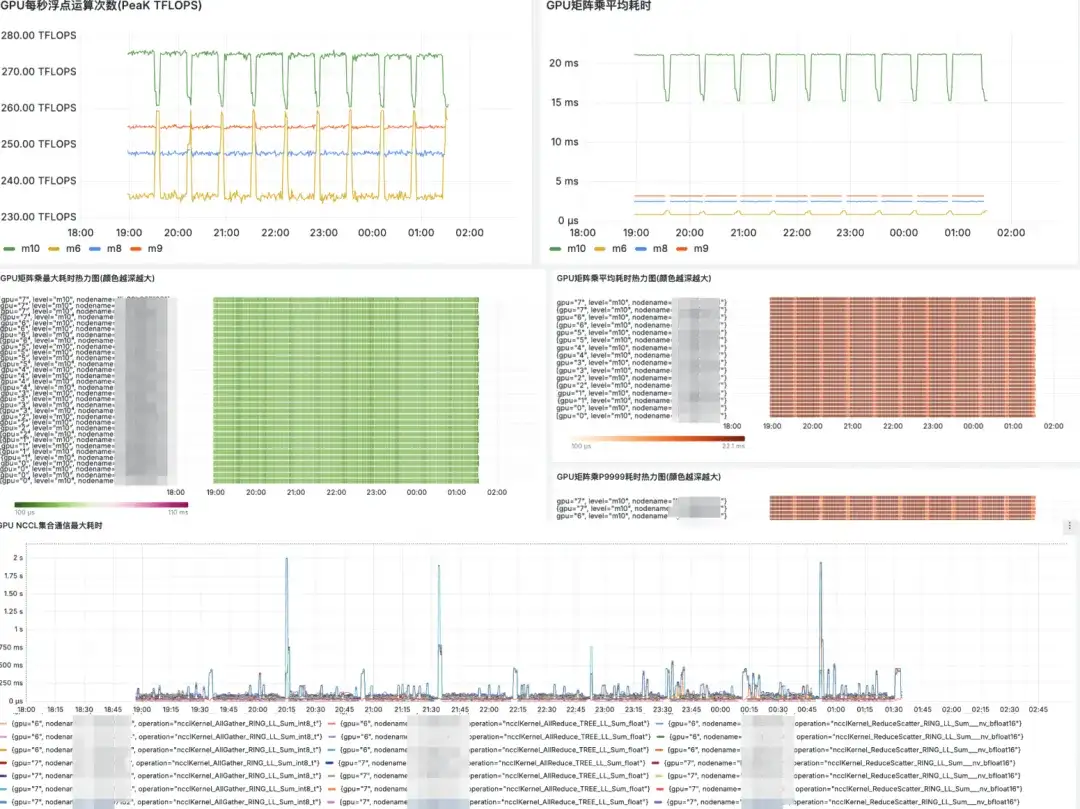
これからの計画
- NCCL/eBPF などのよりきめ細かいトレースを追加して、トレーニング中のハング問題の根本原因をより正確に分析および診断します。
- さまざまな国内グラフィックス カードを含む、より多くのハードウェア プラットフォームをサポートする予定です。
DLRoverについて
DLRover (分散ディープ ラーニング システム) は、Ant Group AI インフラ チームによって維持されているオープン ソース コミュニティであり、クラウド ネイティブ テクノロジーに基づくインテリジェントな分散ディープ ラーニング システムです。 DLRover を使用すると、開発者はハードウェア アクセラレーションや分散操作などのエンジニアリングの詳細に取り組む必要がなく、モデル アーキテクチャの設計に集中できます。また、オプティマイザーなど、トレーニングをより効率的かつインテリジェントにするための深層学習トレーニングに関連するアルゴリズムも開発します。現在、DLRover は、深層学習トレーニング タスクの自動運用とメンテナンスのための K8s と Ray の使用をサポートしています。 AI インフラテクノロジーの詳細については、DLRover プロジェクトに注目してください。
DLRover DingTalk テクノロジー交換グループに参加してください: 31525020959
DLローバースター:
https://github.com/intelligent-machine-learning/dlrover
記事の推奨事項
AI トレーニングのコンピューティング電力効率の向上: Ant DLRover 障害自己修復テクノロジーの革新的な実践
AIインフラのアーキテクトを紹介:高速大型モデル「レーシングカー」の「車輪を変える」人
[オンライン リプレイ] NVIDIA GTC 2024 カンファレンス | AI エンジニアリング コストを削減するには?トレーニングから推論までの Ant のフルスタックの実践
