

この記事の著者:
タリク・ベネット、ベイナン・ワン、ホープ・ワン
この記事では、人工知能 (AI) におけるデータ アクセスの課題について説明し、「一般的に使用されている NAS/NFS が最良の選択ではない可能性がある」ことを明らかにします。
1. 初期の人工知能/機械学習アーキテクチャ
Gartner の調査によると、大規模言語モデル (LLM) は大きな注目を集めていますが、ほとんどの組織はまだ大規模モデルの使用の初期段階にあり、運用段階に入っているのは一部の組織だけです。
初期段階での AI プラットフォームの構築の焦点は、プロジェクトのパイロットと概念実証を実施できるようにシステムを稼働させることです。これらの初期のアーキテクチャ、つまり実稼働前アーキテクチャは、モデルのトレーニングと展開の基本的なニーズを満たすように設計されています。現在、多くの組織がすでにこのタイプの初期 AI アーキテクチャを実稼働環境に使用しています。
データとモデルが増大するにつれて、このような初期の AI アーキテクチャは非効率になることがよくあります。企業はクラウド上でモデルをトレーニングしており、プロジェクトが拡大するにつれて、データとクラウドの使用量が 12 か月以内に大幅に増加すると予想されます。多くの組織は、現在のメモリ サイズに一致するデータ ボリュームから始めますが、より大きな負荷に備える必要があることを認識しています。
企業は、既存のテクノロジー スタックまたはグリーンフィールド展開を使用することを選択できます。この記事では、既存のテクノロジー スタックを使用する方法、または追加のハードウェアを購入して、よりスケーラブルで機敏でパフォーマンスの高いテクノロジー スタックを設計する方法に焦点を当てます。
2. データアクセスにおける課題
AI/ML アーキテクチャの進化に伴い、モデル トレーニング データ セットのサイズは大幅に増大し続けており、GPU の計算能力と規模も急速に増加しています。コンピューティング、ストレージ、ネットワークに加えて、データ アクセスも将来を見据えた AI プラットフォームの構築におけるもう 1 つの重要な要素であると私たちは考えています。

データ アクセスとは、コンピューティング エンジンがモデルのトレーニングと展開用のデータを取得するのに役立つ、データ サービス、バックアップ ストレージ (NFS、NAS)、高性能キャッシュ (Alluxio など) などのテクノロジーを指します。
データ アクセスの焦点はスループットとデータ読み込み効率です。これは、GPU リソースが不足している AI/ML アーキテクチャにとってますます重要になっています。データ読み込みを最適化することで、GPU アイドル待機時間を大幅に短縮し、GPU 使用率を向上させることができます。したがって、高パフォーマンスのデータ アクセスがアーキテクチャ導入の主な目標である必要があります。
企業が初期の AI アーキテクチャでモデル トレーニング タスクを拡張するにつれて、いくつかの一般的なデータ アクセスの課題が浮上しています。
1
モデルのトレーニング効率が予想より低い:データ アクセスのボトルネックにより、トレーニング時間はコンピューティング リソースに基づいた推定よりも長くなります。スループットの低いデータ ストリームは、GPU に十分なデータを提供しません。
2
データ同期に関するボトルネック:ストレージからローカル GPU サーバーにデータを手動でコピーまたは同期すると、準備するデータ キューの構築に遅れが生じます。
3
同時実行性とメタデータの問題:大規模なジョブが並行して起動されると、共有ストレージで競合が発生する可能性があります。バックエンド ストアでのメタデータ操作が遅い場合、遅延が増加します。
4
パフォーマンスの低下または GPU 使用率の低下:高性能 GPU インフラストラクチャには巨額の投資が必要であり、データ アクセスが非効率になると、GPU リソースがアイドル状態になり、十分に活用されなくなります。
さらに、これらの課題は、データ チームが管理する必要がある他の多くの問題によってさらに複雑になります。これらの問題には、高性能 GPU クラスターのニーズを満たすことができないストレージ I/O 速度の遅さが含まれます。手動のデータのコピーと同期に依存すると、データ チームが GPU サーバーにデータが配信されるのを待つ間のレイテンシーが増加します。データ アクセスの課題は、ハイブリッド インフラストラクチャまたはマルチクラウド環境における複数のデータ サイロのアーキテクチャの複雑さによってもさらに悪化します。
これらの問題により、最終的にはアーキテクチャのエンドツーエンド効率が期待を下回る結果になります。
データ アクセスに関連する課題には、多くの場合 2 つの共通の解決策があります。
より高速なストレージを購入する:多くの企業は、より高速なストレージ オプションを導入することで、データ アクセスの遅さの問題を解決しようとしています。クラウド ベンダーは高性能ストレージを提供し、プロのハードウェア ベンダーはパフォーマンスを向上させるために HPC ストレージを販売します。
オブジェクト ストレージ上に NAS/NFS を追加する: S3、MinIO、Ceph などのオブジェクト ストレージにバックアップとして集中型 NAS または NFS を追加することは一般的な方法であり、チームがデータを共有ファイル システムに統合し、ユーザーとワークロードのコラボレーションと共有を簡素化するのに役立ちます。さらに、成熟した NAS ベンダーが提供するデータの一貫性、可用性、バックアップ、スケーラビリティなどの関連データ管理機能を利用することもできます。
ただし、上記の 2 つの一般的な解決策では、実際には問題が解決されない可能性があります。
より高速なストレージと一元化された NFS/NAS により、徐々にパフォーマンスが向上しますが、欠点もあります。
1
ストレージの高速化はデータの移行を意味し、データの信頼性の問題につながりやすい
専用ストレージが提供する高いパフォーマンスを活用するには、データを既存のストレージから新しい高性能ストレージ階層に移行する必要があります。これにより、データがバックグラウンドで移行されます。大規模なデータ セットを移行すると、転送時間が延長され、移行中のデータの破損や損失などのデータの信頼性の問題が発生する可能性があります。チームがデータ同期が完了するのを待っている間、操作を一時停止するとサービスが中断され、プロジェクトの進行が遅くなる可能性があります。
2
NFS/NAS: メンテナンスとボトルネック
追加のストレージ層として、NFS/NAS のメンテナンス、安定性、拡張性の課題が残ります。 NFS/NAS からローカル GPU サーバーにデータを手動でコピーすると、バックアップの繰り返しにより遅延が増加し、リソースが無駄になります。並列ジョブによって引き起こされる読み取り需要の急増により、NFS/NAS サーバーと相互接続されたサービスがクラスター化される可能性があります。さらに、リモート NFS/NAS GPU クラスターにおけるデータ同期の問題は依然として存在します。
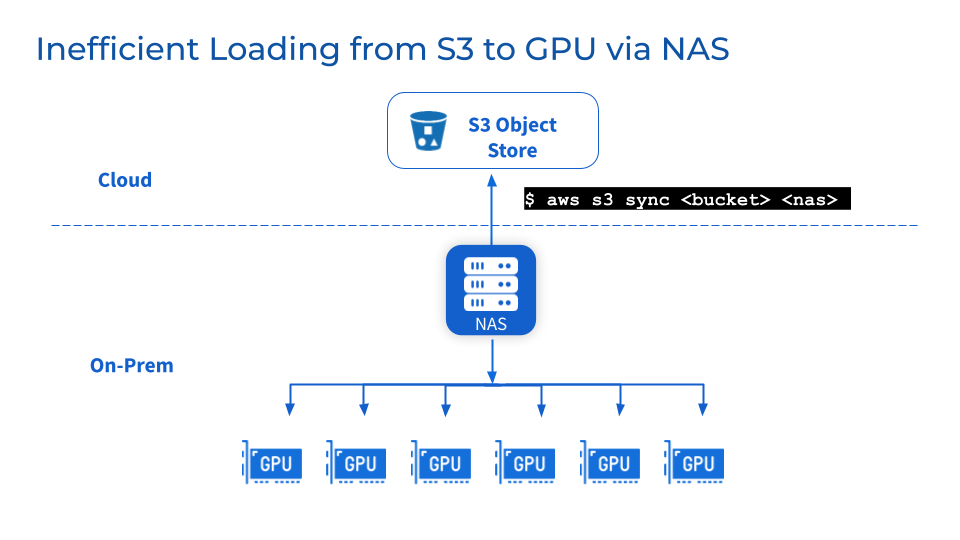
3
ビジネス上の理由でサプライヤーを変更する必要がある場合はどうすればよいですか?
企業は、コストの最適化や契約上の理由により、サプライヤーを切り替える場合があります。マルチクラウド環境の柔軟性には、ベンダー ロックインなしで大規模なデータ セットを簡単に移植できる機能が必要です。ただし、ペタバイト規模のデータ ストレージを移動すると、大幅なダウンタイムやモデル開発の中断が発生する可能性があります。
つまり、既存のソリューションは、短期的には役に立ちますが、AI/ML のデータ ニーズの急激な増加に対応できるスケーラブルで最適化されたデータ アクセス アーキテクチャを提供することはできません。
3. Alluxio が提供するソリューション
Alluxio は、コンピューティング ソースとデータ ソースの間にデプロイできます。データ抽象化と分散キャッシュを提供して、AI/ML アーキテクチャのパフォーマンスとスケーラビリティを向上させます。
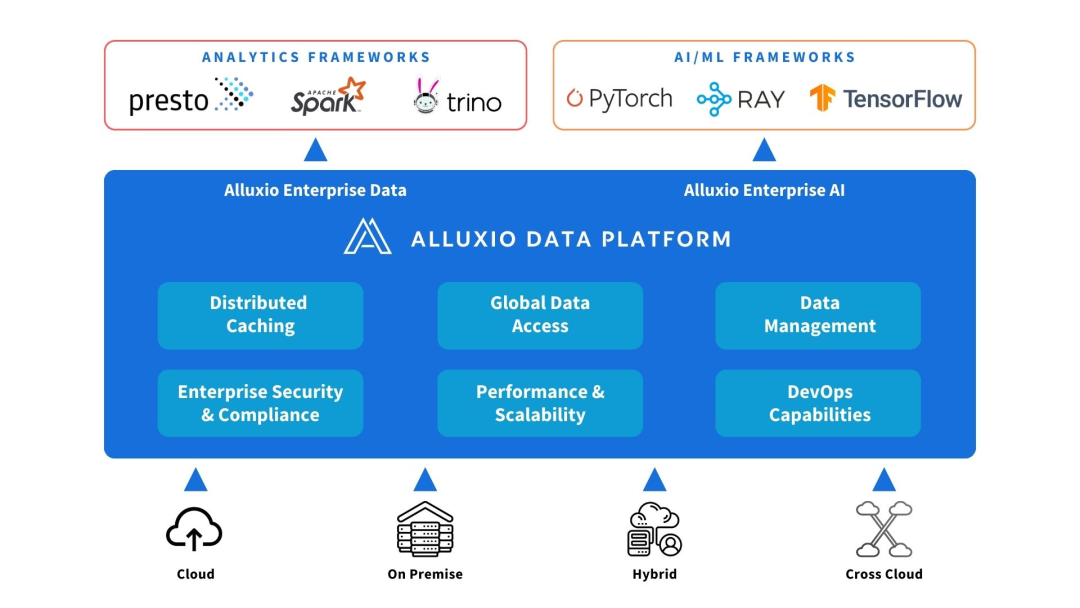
Alluxio は、データ量、モデルの複雑さの増加、GPU クラスターの拡大に伴い、初期の AI アーキテクチャがスケーラビリティ、パフォーマンス、データ管理において直面する課題の解決に役立ちます。
1
容量を増やす
Alluxio は、単一ノードの制限を超えて拡張し、クラスター メモリやローカル SSD が対応できるよりも大きなトレーニング データ セットに対応します。さまざまなストレージ システムを接続し、ペタバイト レベルのデータ レイクをマウントするための統合データ アクセス レイヤーを提供します。 Alluxio は、頻繁に使用されるファイルとメタデータをコンピューティングに近いメモリ層と SSD 層にインテリジェントにキャッシュするため、データ セット全体をコピーする必要がなくなります。
2
データ管理の削減
Alluxio は、自動分散キャッシュを通じて GPU クラスター間のデータの移動とストレージを簡素化します。データ チームは、ローカルのステージング ファイルにデータを手動でコピーしたり同期したりする必要はありません。 Alluxio クラスターは、複雑なワークフロー操作を行うことなく、ホット ファイルまたはオブジェクトをコンピューティング ノードに近い場所に自動的にキャプチャできます。 Alluxio は、ノードあたり 5,000 万以上のオブジェクトがあってもワークフローを簡素化します。
3
性能を上げる
Alluxio はワークロードを高速化するように構築されており、GPU スループットを制限する従来のストレージの I/O ボトルネックを排除します。分散キャッシュにより、データ アクセス速度が桁違いに向上します。ネットワーク経由でリモート ストレージにアクセスする場合と比較して、Alluxio はメモリおよび SSD レベルでローカル データ アクセスを提供するため、GPU の使用率が向上します。
つまり、Alluxio は、AI/ML データ拡張シナリオで GPU リソースの使用を最大限に活用できる、高性能でスケーラブルなデータ アクセス レイヤーを提供します。
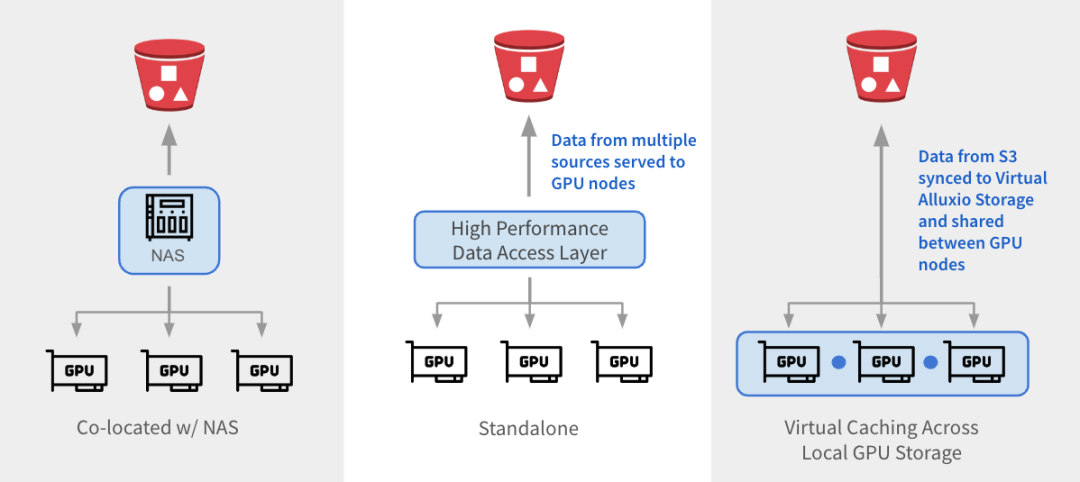
Alluxio は 3 つの方法で既存のアーキテクチャと統合できます。
1
与 NAS 并置:Alluxio 作为透明缓存层与现有 NAS并置部署,增强 I/O 性能。Alluxio将NAS中的活跃数据缓存在跨GPU节点的本地 SSD 中。作业将读取请求重新定向到Alluxio上的SSD缓存,绕过NAS,从而消除NAS瓶颈。写入操作通过 Alluxio 对 SSD 进行低延迟写入,然后异步持久化保存到 NAS中。
2
独立数据访问层:Alluxio 作为专用的高性能数据访问层,整合来自 S3、HDFS、NFS 或本地数据湖等多个数据源的数据,为GPU节点提供数据访问服务。Alluxio 将不同的数据孤岛统一在一个命名空间下,并将存储后端挂载为底层存储。经常访问的数据会被缓存在 Alluxio Worker节点的SSD中,从而加速GPU对数据的本地访问。
3
跨GPU存储的虚拟缓存:Alluxio充当跨本地GPU存储的虚拟缓存。S3中的数据会被同步到虚拟 Alluxio存储并在GPU节点之间共享,无需在节点之间手动拷贝数据。
1
参考架构
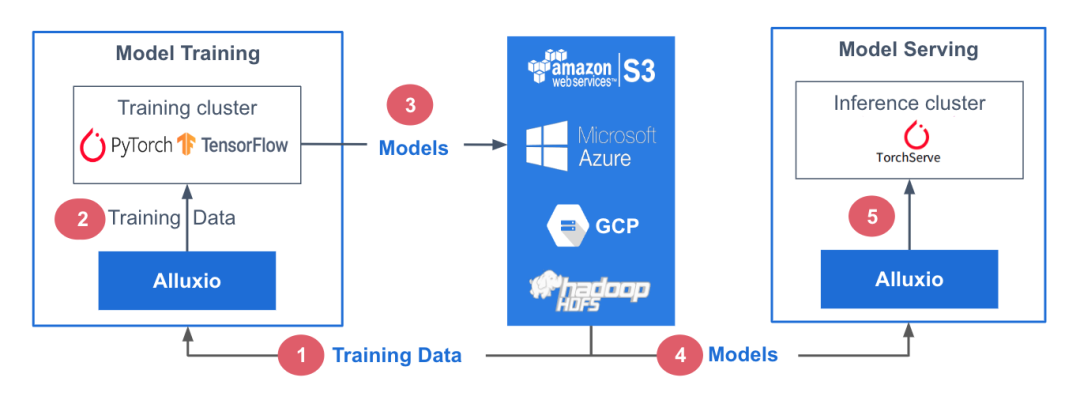
在此参考架构中,训练数据存储在中心化数据存储平台AWS S3中。Alluxio可帮助实现模型训练集群对训练数据的无缝访问。PyTorch、TensorFlow、scikit-learn和XGBoost等ML训练框架都在CPU/GPU/TPU集群上层执行。这些框架利用训练数据生成机器学习模型,模型生成后被存储在中心化模型库中。
在模型服务阶段,使用专用服务/推理集群,并采用TorchServe、TensorFlow Serving、Triton 和 KFServing等框架。这些服务集群利用Alluxio从模型存储库中获取模型。模型加载后,服务集群会处理输入的查询、执行必要的推理作业并返回计算结果。
训练和服务环境都基于Kubernetes,有助于增强基础设施的可扩展性和可重复性。
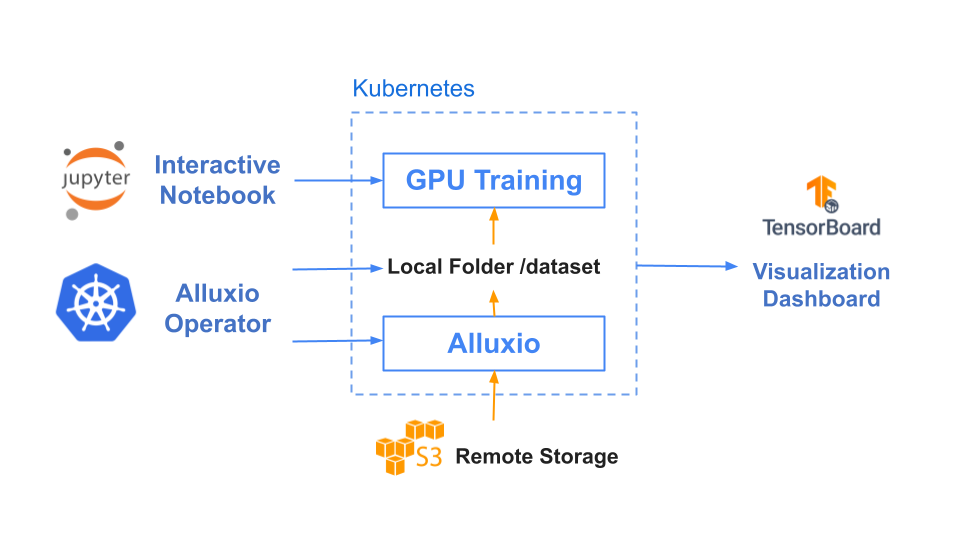
2
基准测试结果
在本基准测试中,我们用计算机视觉领域的典型应用场景之一——图片分类任务作为示例,其中我们以ImageNet的数据集作为训练集,通过ResNet来训练图片分类模型。
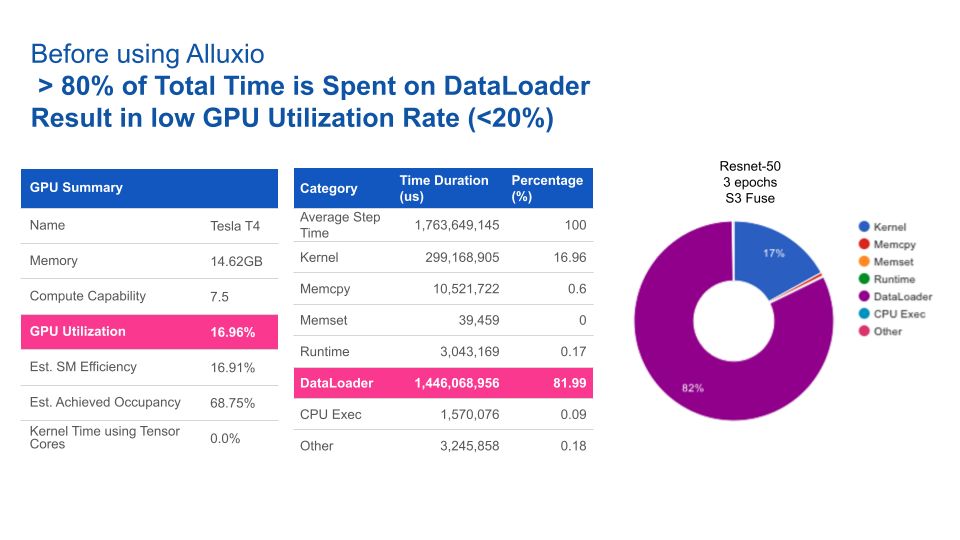
基于Resnet-50上3个epochs性能基准测试的结果,使用Alluxio比使用S3-FUSE的速度快5倍。一般来说,提高数据访问性能可缩短模型训练的总时间。
|
|
Alluxio |
S3 - FUSE |
|
Total training time (3 epochs) |
17 minutes |
85 minutes |
使用Alluxio后,GPU利用率得到大幅提升。Alluxio将数据加载时间由82%缩短至1%,从而将GPU利用率由17%提升至93%。
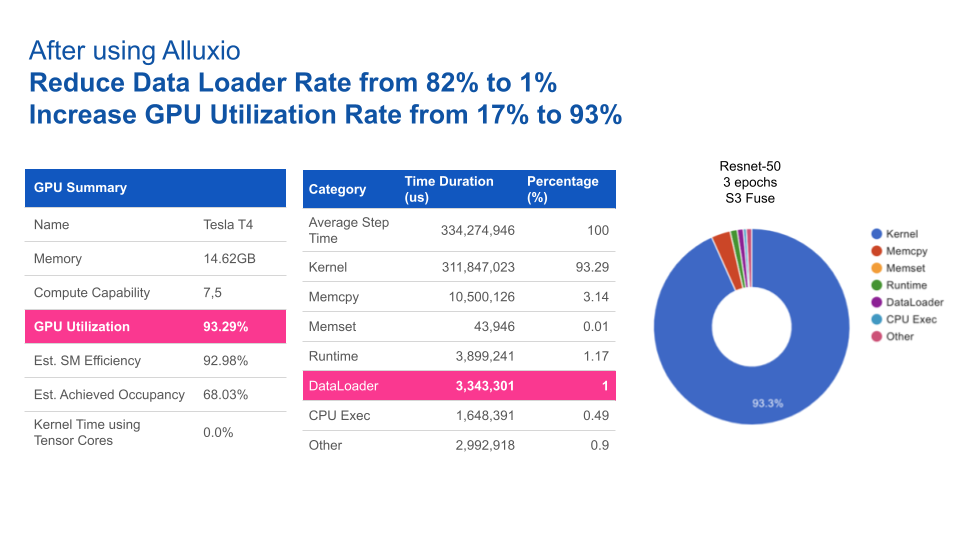
四、结论
随着AI/ML学习架构从早期的预生产架构向着可扩展架构发展,数据访问始终是瓶颈。仅靠添加更快的存储硬件或中心化NAS/NFS无法完全消除性能不达标以及影响系统操作的管理问题。
Alluxio提供了一种专为优化AI/ML任务数据流而设计的软件解决方案。与传统存储方案相比,其优势包括:
1
优化数据加载:Alluxio智能地加速训练任务和模型服务的数据访问,从而将GPU利用率最大化。
2
维护需求低:无需在节点或集群之间手动拷贝数据。Alluxio通过其分布式缓存层处理热文件传输。
3
支持扩展:当数据量大到需要扩展更多节点的情况下,Alluxio也能维持性能稳定。Alluxio通过使用SSD扩展内存,可缓存任何大小的文件,避免拷贝全部文件。
4
更快的切换:Alluxio将底层存储抽象化,使得数据团队能够轻松地在云厂商、本地或多云环境中迁移数据。数据迁移无需替换硬件,也不会导致停机。
部署Alluxio后,企业通过针对数据访问进行优化的数据架构,可以构建出性能卓越、可扩展的数据平台,从而加速模型开发,满足不断增长的数据需求。
✦
【近期热门】
✦

✦
【宝典集市】
✦






本文分享自微信公众号 - Alluxio(Alluxio_China)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。