はじめに: ArcGraph は、クラウドネイティブ アーキテクチャと統合されたインベントリと分析を備えた分散グラフ データベースです。この記事では、ArcGraph が限られたメモリの下でグラフ解析にどのように柔軟に対応できるかを詳しく説明します。
01 はじめに
グラフ解析技術が広く普及している現在、学界や大手グラフデータベースメーカーはグラフ解析技術の高性能指標の改良に熱心に取り組んでいます。しかし、高性能コンピューティングを追求する過程では、メモリ使用量を増やして計算を高速化する「空間と時間のトレード」という手法が採用されることが多い。ただし、外部メモリ グラフ コンピューティングは現段階ではまだ成熟しておらず、グラフ分析は依然としてフルメモリ コンピューティングに依存しているため、メモリが不足している場合、グラフ分析タスクは大容量メモリに大きく依存します。実行されません。
これまでの多くの顧客事例から、顧客がグラフ分析に投資するハードウェア リソースは通常固定かつ限定されており、テスト環境のリソースは本番環境よりも限られていることがわかっています。グラフ分析に対する顧客の適時性要件は通常、T+1 であり、これは典型的なオフライン分析要件です。したがって、顧客はグラフ コンピューティング エンジンに対して、T+1 を満たす限り、高いアルゴリズムのパフォーマンスを追求するのではなく、CPU やメモリなどのリソースの需要を削減することを期待しています。これは、ほとんどのグラフ コンピューティング エンジンにとって大きな課題です。 CPU 要件は制御が比較的簡単ですが、メモリ要件は短い開発サイクル内で大幅に最適化するのが困難です。
ArcGraph も上記の課題に直面していますが、顧客配信の実践における継続的な要約と洗練を通じて、当社のグラフ コンピューティング エンジンは時間と空間で処理のバランスをとる柔軟性を備えています。現在、ArcGraph の内蔵グラフ コンピューティング エンジンは、グラフ分析パフォーマンス指標の点で業界をリードしており、現在も最適化と改善が続けられています。次に、エンジンの基礎となるデータ構造や上位レベルのアルゴリズムの呼び出しなど、さまざまな観点から、ArcGraph が限られたメモリの下で時間と空間を巧みに交換してグラフ分析に対処する方法を説明します。
02 ポイントIDタイプの選択
ArcGraph グラフ計算エンジンは、string、int64、および int32 の 3 つのポイント ID タイプをサポートします。文字列ポイント型のサポートにより、ソース データとの互換性が向上しますが、文字列から int64 ポイント ID へのマッピング テーブルをメモリ内に保持する必要があるため、int64 と比較してメモリ使用量が増加します。指定されたポイント タイプが int64 の場合、ArcGraph はソース データ内の文字列タイプのポイント ID から int64 マッピング テーブルを生成し、外部メモリに配置します。マップされた int64 タイプのポイント エッジ データのみがメモリに保持されます。計算が完了すると、マッピング テーブルがメモリに読み込まれ、文字列 ID が復元されます。したがって、int64 型のポイント ID を使用すると、外部メモリとメモリの間でマッピング テーブルを交換するための余分な時間が増加しますが、全体的なメモリ使用量も大幅に削減されます。節約されるメモリ サイズは、元のポイントの長さとポイントによって異なります。 ID。データ量。
さらに、ArcGraph グラフ計算エンジンは int32 もサポートしており、ソース データ ポイントの総数が 4,000 万未満のシナリオでは、int64 と比較してメモリ使用量をさらに約 30% 削減できます。
以下は、ArcGraph の実行グラフ アルゴリズム API でグラフ ロード ポイント ID タイプを指定する例です。
curl -X 'POST' 'http://myhost:18000/graph-computing?reload=true&use_cache=true' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"algorithmName": "pagerank",
"graphName": "twitter2010",
"taskId": "pagerank",
"oid_type": "int64",
"subGraph": {
"edgeTypes": [
{
"edgeTypeName": "knows",
"props": [],
"vertexPairs": [
{
"fromName": "person",
"toName": "person"
}
]
}
],
"vertexTypes": [
{
"vertexTypeName": "person",
"props": []
}
]
},
"algorithmParams": {
}
}'
03 Variant エンコーディングをオンにする
Variant エンコーディングは、整数の圧縮とエンコードに使用され、可変長エンコーディング方法です。 int32 を例にとると、通常値を格納するには 4 バイトが必要です。従来の Variant エンコードでは、各バイトの最後の 7 ビットがデータを表すために使用され、最上位ビットはフラグ ビットです。


- 最上位ビットが 0 の場合、現在のバイトまでの最後の 7 ビットがすべてのデータであり、それ以降のバイトはデータと関係がないことを意味します。たとえば、上図の整数 1 は、00000001 を表すのに 1 バイトのみを必要とし、後続のバイトは整数 1 のデータには属しません。
- 最上位ビットが 1 の場合、後続のバイトがまだデータの一部であることを意味します。たとえば、上の図の整数 511 は、11111111 00000011 を表すために 2 バイトが必要で、後続のバイトは 131071 のデータです。
この考え方を使用すると、32 ビット整数を 1 ~ 5 バイトで表すことができます。同様に、64 ビット整数は 1 ~ 10 バイトで表現できます。実際の使用シナリオでは、特に 64 ビット整数の場合、小さな数値の使用率が大きな数値の使用率よりもはるかに高くなります。したがって、Variant エンコーディングは通常、大幅な圧縮効果を実現できます。 Variant エンコーディングには多くのバリエーションがあり、オープン ソースの実装も多数あります。
ArcGraph グラフ計算エンジンは、メモリ内エッジ データ ストレージ (主に CSR/CSC) を圧縮するための Variant エンコーディングの使用をサポートしています。 Variant エンコーディングをオンにすると、エッジ データが占有するメモリを大幅に削減でき、実測では最大約 50% になります。同時に、エンコードとデコードによるパフォーマンスの損失も約 20% に達します。したがって、有効にする前に、使用シナリオと顧客のニーズを明確に理解し、メモリの節約によるパフォーマンスの低下が許容範囲内であることを確認する必要があります。
以下は、ArcGraph のグラフ読み込み API でグラフ計算を有効にするための Variant コーディング例です。
curl -X 'POST' 'http://localhost:18000/graph-computing/datasets/twitter2010/load' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"oid_type": "int64",
"delimeter": ",",
"with_header": "true",
"compact_edge": "true"
}'
04 パーフェクトハッシュマップをオンにする
Perfect HashMap と他の HashMap の違いは、Perfect Hash Function (PHF) を使用することです。関数 H は、N 個のキー値を M 個の整数にマッピングします (M>=N)。H(key1)≠H(key2)∀key1, key2 を満たす場合、この関数は完全なハッシュ関数です。 M=N の場合、H は Minimal Perfect Hash Function (略して MPHF) です。このとき、N 個のキー値は N 個の連続する整数にマッピングされます。
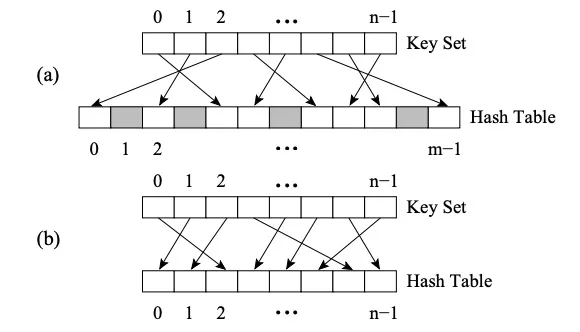 画像 (a) は PHF、画像 (b) は MPHF
画像 (a) は PHF、画像 (b) は MPHF
上の図は、2 レベルのハッシュの FKS 戦略です。まず、データは第 1 レベルのハッシュを通じて T 空間にマッピングされ、次に競合するデータがランダムに選択され、新しいハッシュ関数を使用して S 空間にマッピングされます。S 空間のサイズ m は競合するデータの 2 乗です。データ (たとえば、T2 に 3 つの数値が衝突する場合、それらは m が 9 である S2 空間にマッピングされます) このとき、衝突を回避するハッシュ関数を見つけるのは簡単です。ハッシュ関数を適切に選択すると、1 レベルのハッシュ処理中の衝突が軽減されるため、予想される記憶域スペースは O(n) になります。
ArcGraph グラフ計算エンジンは、元のポイント ID から内部ポイント ID へのマッピングをメモリ内に維持します。内部ポイントは、データ圧縮とベクトル化の最適化に便利な連続長整数型です。マッピングは基本的にハッシュマップですが、ArcGraph は基礎となる実装に関して 2 つのメソッドを提供します。
- Flat HashMap - 構築速度が速いという利点がありますが、頻繁なハッシュ衝突を減らすために通常より大きなメモリ空間が必要になるという欠点があります。
- 完璧なハッシュマップ - 利点は、最悪の場合でも O(1) 効率のクエリを保証するために使用するメモリを少なくできることですが、欠点は、すべてのキーを事前に知っておく必要があり、構築時間が長いことです。
したがって、Perfect HashMap をオンにすると、時間を空間と交換するという目的も達成できます。テストによると、オリジナルポイントから内部ポイントIDまでのマッピングセットでは、通常、Perfect HashMapのメモリ使用量はFlat HashMapの1/5程度しかありませんが、それに応じて構築時間は2~3倍かかります。
以下は、ArcGraph のグラフ読み込み API でグラフ計算を可能にする Perfect HashMap の例です。
curl -X 'POST' 'http://localhost:18000/graph-computing/datasets/twitter2010/load' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"oid_type": "int64",
"delimeter": ",",
"with_header": "true",
"compact_edge": "true",
"use_perfect_hash": "true"
}'
05 最適化アルゴリズムの実装と結果処理
アルゴリズムの実装レベルでのメモリ使用量は、アルゴリズムの特定のロジックに依存します。これにより、時間をスペースと交換するという目的を達成できるようになります。
アルゴリズム内のマルチスレッドと ThreadLocal オブジェクトの使用を適切に削減します。アルゴリズムには、一時的なポイントエッジ コレクションのストレージが含まれることが多く、これらのストレージがマルチスレッド ロジックで使用される場合、スレッドの数が増えると全体のメモリが増加します。同時スレッドの数を適切に減らすか、ThreadLocal ラージ オブジェクトの使用を減らすと、メモリの削減に役立ちます。 内部メモリと外部メモリ間のデータ交換を適切に増加させます。アルゴリズムの特定のロジックに従って、一時的に使用されていないラージ オブジェクトは外部メモリにシリアル化され、オブジェクトが使用されるときはストリーミング方式でメモリに読み込まれ、複数のラージ オブジェクトが同時に大量のメモリを占有することを回避します。時間。
上記 2 点を具体化したアルゴリズムの実装例を以下に示します。
void IncEval(const fragment_t& frag, context_t& ctx,
message_manager_t& messages) {
...
...
if (ctx.stage == "Compute_Path"){
auto vertex_group = divide_vertex_by_type(frag);
//此处采用单线程for循环而非多线程并行处理,意在防止多个path_vector同时占内存导致OOM。
for(int i=0; i < vertex_group.size(); i++){
//此处path_vector是每个group中任意两点间的全路径,可理解为一个超大对象
auto path_vector = compute_all_paths(vertex_group[i]);
//拿到该对象后不会在当前stage使用,所以先序列化到外存中。
serialize_path_vector(path_vector, SERIALIZE_FOLDER);
}
...
...
}
...
...
if (ctx.stage == "Result_Collection"){
//在当前stage中,将之前stage生成的多个序列化文件合并为一个文件,并把文件路径返回。
auto result_file_path = merge_path_files(SERIALIZE_FOLDER);
ctx.set_result(result_file_path);
...
...
}
...
...
}
計算が完了すると、結果は外部メモリに書き込まれ、グラフ計算エンジンの関連メモリが解放されます。一部のシナリオでは、結果処理プログラムはグラフ コンピューティング クラスター サーバー上で実行され、グラフ コンピューティングの結果を読み取り、さらに処理します。グラフ計算エンジンのメモリが計算結果を公開していない場合、最悪の場合、現在のサーバのメモリに結果データのコピーが2つ存在することになります。大量のデータを含むシナリオでは、結果データのコピーが非常に大量のメモリを占有します。したがって、このタイプのシナリオでは、計算結果を外部メモリに書き込み、タイムリーにグラフ計算エンジンのメモリを解放することを優先する必要があります。
同時に、ArcGraph チームは、高パフォーマンスと低リソース使用量の「ニーズとニーズ」に引き続き挑戦し、学術および業界のパートナーと協力して、グラフを運ぶメモリとコンピューティング効率をさらに磨き上げ、さらなる技術的ブレークスルーを達成していきます。
Google: Rust への移行により、Android の脆弱性が大幅に軽減されました。Huawei は、オープンな UBMC (古いクラシック音楽プレーヤー Winamp) を2024.2.3 に正式にリリースする と発表しました。 オラクルの商標になったのですか?Open Source Daily | PostgreSQL 17; 中国の AI 企業は米国のチップ禁止を回避する方法; AI 開発者の渇望を潤せるのは誰か?スタートアップ企業「Zhihuijun」は、最新のロボット工学分野向けのランタイム開発フレームワークである AimRT、Tcl/Tk 9.0 をオープンソース化し、Meta をリリースし、Llama 3.2 マルチモーダル AI モデルをリリースしました