분할 된 로그
큰 파일을 처리하기 쉬운 여러 개의 작은 파일로 나눕니다.
문제 배경
단일 로그 파일이 커질 수 있고 프로그램이 시작될 때 읽을 수 있으므로 성능 병목 현상이 발생합니다. 오래된 로그는 정기적으로 정리해야하지만 큰 파일을 정리하는 것은 매우 힘듭니다.
해결책
단일 로그를 여러 개로 나누고 로그가 특정 크기에 도달하면 새 파일로 전환하여 계속 기록합니다.
//写入日志
public Long writeEntry(WALEntry entry) {
//判断是否需要另起新文件
maybeRoll();
//写入文件
return openSegment.writeEntry(entry);
}
private void maybeRoll() {
//如果当前文件大小超过最大日志文件大小
if (openSegment.
size() >= config.getMaxLogSize()) {
//强制刷盘
openSegment.flush();
//存入保存好的排序好的老日志文件列表
sortedSavedSegments.add(openSegment);
//获取文件最后一个日志id
long lastId = openSegment.getLastLogEntryId();
//根据日志id,另起一个新文件,打开
openSegment = WALSegment.open(lastId, config.getWalDir());
}
}로그가 분할 된 경우 로그 위치 (또는 로그 시퀀스 번호)가있는 파일을 빠르게 찾을 수있는 메커니즘이 필요합니다. 두 가지 방법으로 달성 할 수 있습니다.
- 각 로그 분할 파일의 이름에는 특정 시작 및 로그 위치 오프셋 (또는 로그 시퀀스 번호)이 포함됩니다.
- 각 로그 시퀀스 번호에는 파일 이름과 트랜잭션 오프셋이 포함됩니다.
//创建文件名称
public static String createFileName(Long startIndex) {
//特定日志前缀_起始位置_日志后缀
return logPrefix + "_" + startIndex + "_" + logSuffix;
}
//从文件名称中提取日志偏移量
public static Long getBaseOffsetFromFileName(String fileName) {
String[] nameAndSuffix = fileName.split(logSuffix);
String[] prefixAndOffset = nameAndSuffix[0].split("_");
if (prefixAndOffset[0].equals(logPrefix))
return Long.parseLong(prefixAndOffset[1]);
return -1l;
}파일 이름에이 정보가 포함 된 후 읽기 작업은 두 단계로 나뉩니다.
- 오프셋 (또는 트랜잭션 ID)이 주어지면 로그가이 오프셋보다 큰 파일을 가져옵니다.
- 파일에서이 오프셋보다 큰 모든 로그를 읽습니다.
//给定偏移量,读取所有日志
public List<WALEntry> readFrom(Long startIndex) {
List<WALSegment> segments = getAllSegmentsContainingLogGreaterThan(startIndex);
return readWalEntriesFrom(startIndex, segments);
}
//给定偏移量,获取所有包含大于这个偏移量的日志文件
private List<WALSegment> getAllSegmentsContainingLogGreaterThan(Long startIndex) {
List<WALSegment> segments = new ArrayList<>();
//Start from the last segment to the first segment with starting offset less than startIndex
//This will get all the segments which have log entries more than the startIndex
for (int i = sortedSavedSegments.size() - 1; i >= 0; i--) {
WALSegment walSegment = sortedSavedSegments.get(i);
segments.add(walSegment);
if (walSegment.getBaseOffset() <= startIndex) {
break; // break for the first segment with baseoffset less than startIndex
}
}
if (openSegment.getBaseOffset() <= startIndex) {
segments.add(openSegment);
}
return segments;
}예를 들면
기본적으로 RocketMQ, Kafka 및 Pulsar의 기본 스토리지 인 BookKeeper와 같은 모든 주류 MQ 스토리지는 모두 세그먼트 화 된 로그를 사용합니다.
RocketMQ :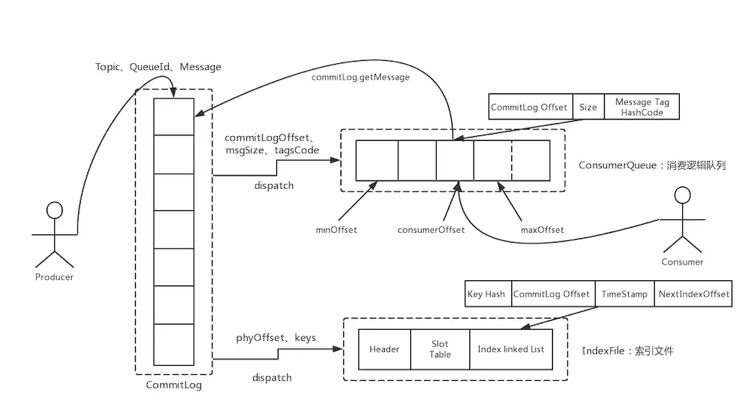
카프카 :
Pulsar 스토리지는 BookKeeper를 구현합니다.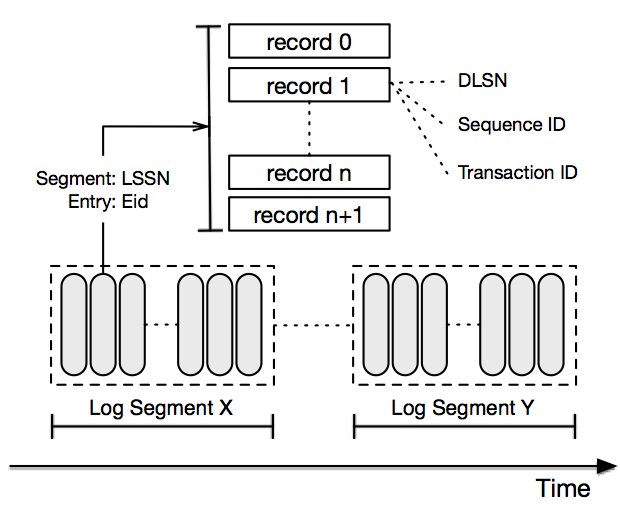
또한 일관성 프로토콜 Paxos 또는 Raft를 기반으로하는 스토리지는 일반적으로 Zookeeper 및 TiDB와 같은 세그먼트 화 된 로그를 사용합니다.
매일 한 번 스 와이프하면 쉽게 기술을 업그레이드하고 다양한 혜택을받을 수 있습니다.
