01 Elasticsearchの普及によるコスト問題
Elasticsearch(以下、「ES」)は、分散データベースとしても利用できる分散型検索エンジンで、ログ処理、分析、検索などのシナリオで使用されることが多く、運用保守のトラブルシューティングのレベルでは、 ELK (Elasticsearch+ Logstash+ Kibana) ソリューションは使いやすく、応答が速く、豊富なレポートを提供します; 高可用性に関しては、ES は分散型および水平展開を提供します; データ層は断片化と複数のコピーをサポートします.
ES は使いやすく、完全なエコロジーを備えており、企業で広く使用されています。これに続いて、物理的なリソースとコストが増加し、ES シナリオのコストをどのように削減するかが一般的な関心事になっています。
ESのコストを下げる方法
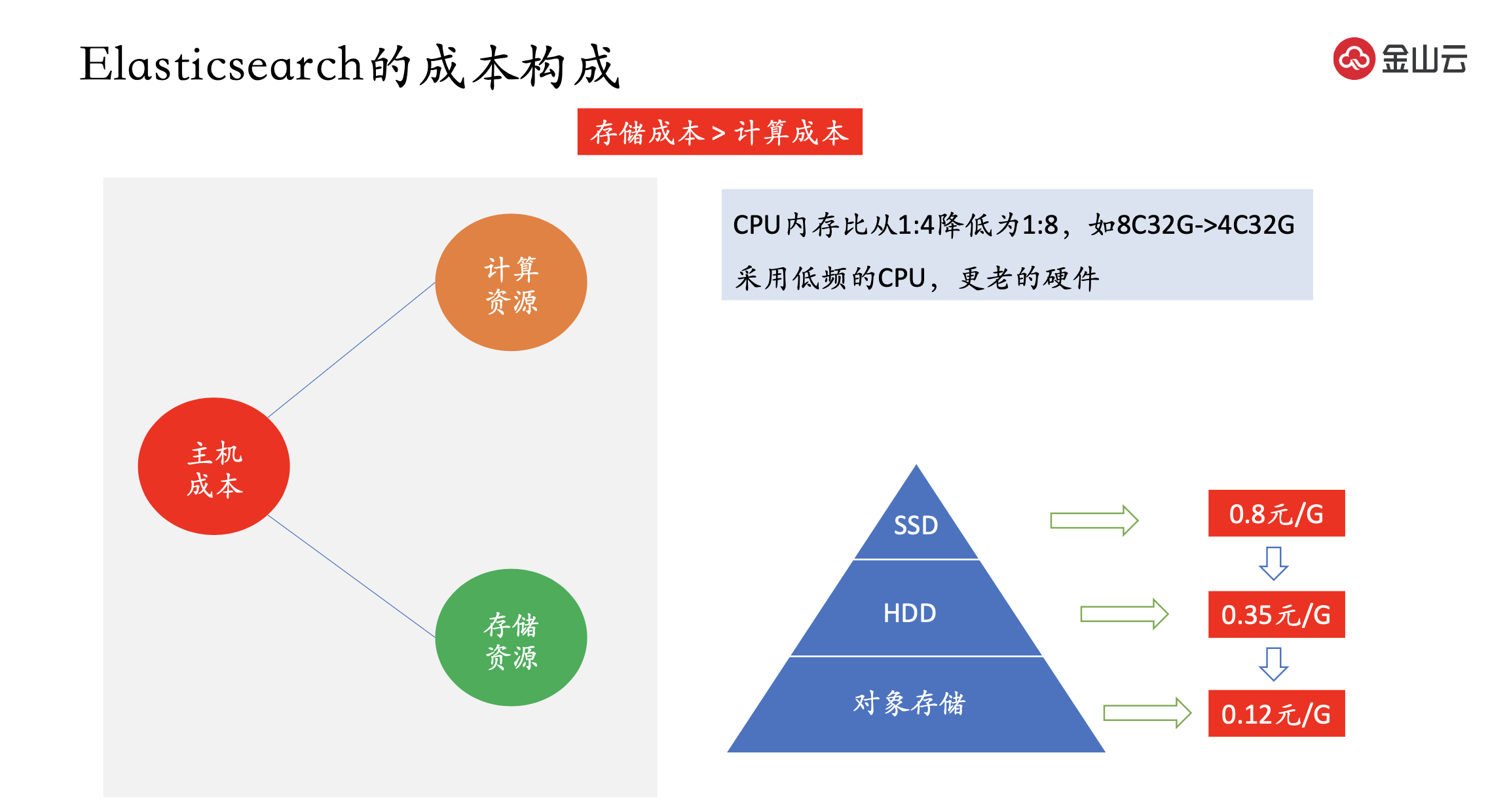
ES の主なコストはホスト コストであり、さらにコンピューティング リソースとストレージ リソースに分けられます。
コンピューティング リソースの簡単な理解は、CPU とメモリです.CPU とホストの数を減らすと、コンピューティング能力が低下するため、通常、ホット ノードとコールド ノードが使用されます.ホット ノードはハイエンド マシンを使用し、コールド ノードはローエンド マシンを使用します.エンド マシン、CPU メモリなど 8C32G->4C32G のように、比率が 1:4 から 1:8 に減少します。ただし、ES は応答速度を向上させるためにメモリに対する要求が高いため、メモリは削減されません。または、低周波数の CPU と古いハードウェアを使用します。
ストレージ コストはコンピューティング コストよりもはるかに高く、考慮すべきコストです。現在のストレージ メディアは通常 SSD と HDD で、クラウド ベンダーの SSD のコストは 0.8 元/G、HDD のコストは 0.35 元/G、オブジェクト ストレージの価格は 0.12 元/G です。ただし、最初の 2 つのデバイスはブロック デバイスであり、ファイル システムのプロトコルを提供しますが、オブジェクト ストレージは S3 プロトコルをサポートするため、相互に互換性がありません。
オブジェクトストレージと ES をどのように組み合わせるか、2 つのソリューションを調査しました。
最初の解決策は、オブジェクト ストレージの呼び出しに適応するように ES ストレージ エンジンを変更することです。この方法は ES のソース コードを変更する必要があり、チームは開発、設計、研究、最終検証に多くの人手を費やさなければならず、入出力比は非常に低くなります。
2 番目の解決策は、オブジェクト ストレージをディスクとして使用し、それをオペレーティング システムにマウントすることです。ES をホット ノードとウォーム ノードに分割します。ホットノードはホットデータを保存し、ブロックデバイスをマウントします。ウォーム ノードはオブジェクト ストレージを使用します。
02 オブジェクト ストレージ ファイル システムの選択
ファイルシステムを選択する際には、主に 3 つの考慮事項があります。1 つ目は機能、最も基本的な機能要件を最初に満たさなければならない、2 つ目はパフォーマンス、3 つ目は信頼性です。s3fs、goofys、JuiceFS を調査しました。
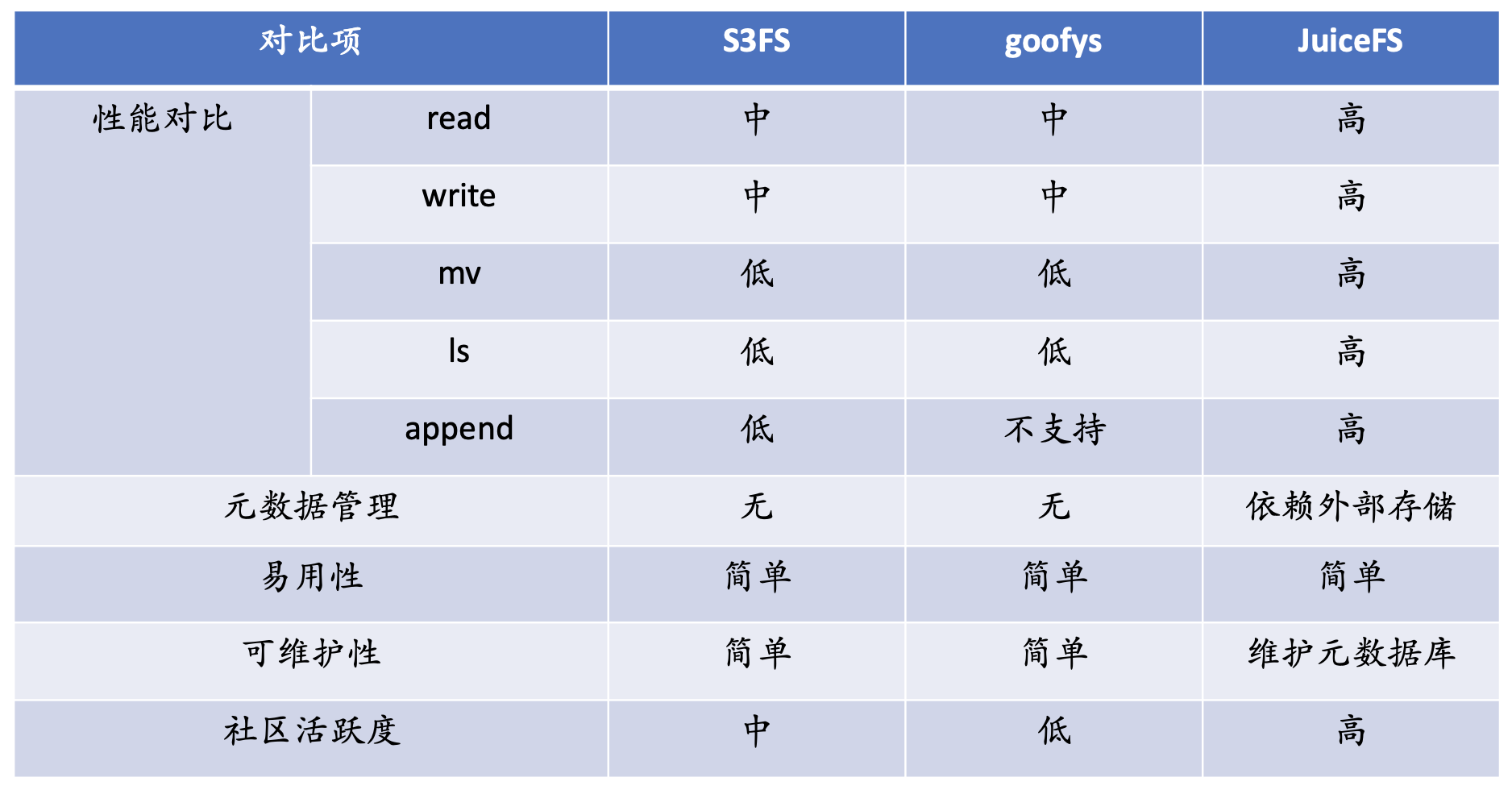
パフォーマンスに関しては、s3fs と goofys は読み取りと書き込みに関してローカル キャッシュを持たず、それらのパフォーマンスは s3 のパフォーマンスによってサポートされます. これら 2 つのファイル システムの全体的なパフォーマンスは、JuiceFS のパフォーマンスよりも低くなります.
最も明白なのは mv です. オブジェクト ストレージには名前変更操作はありません. オブジェクト ストレージでの名前変更操作はコピーと削除であり, パフォーマンス コストは非常に高くなります.
ls に関して言えば、オブジェクト ストレージのストレージ タイプはディレクトリ セマンティクスを持たない kv ストレージであるため、s3 では、ls のディレクトリ構造全体が実際にはメタデータ全体のトラバーサルであり、呼び出しコストが非常に高くなります。ビッグ データのシナリオでは、パフォーマンスが非常に低く、一部の機能はサポートされていません。
メタデータに関しては、s3fs と goofys は独自の独立したメタデータを持っていません. すべてのメタデータは s3 に依存しています. JuiceFS は独自の独立したメタデータ ストレージを持っています.
使いやすさの面では、これらの製品は非常に使いやすく、簡単なコマンドで s3 をマウントできます; 保守性の面では、JuiceFS は独自の独立したメタデータ エンジンを備えているため、メタデータを更新する必要があります。 ; コミュニティの観点からは、JuiceFS が最もコミュニティ活動が活発です。上記の包括的な考慮事項に基づいて、Kingsoft Cloud は JuiceFS を選択しました。
JuiceFS に基づくテスト
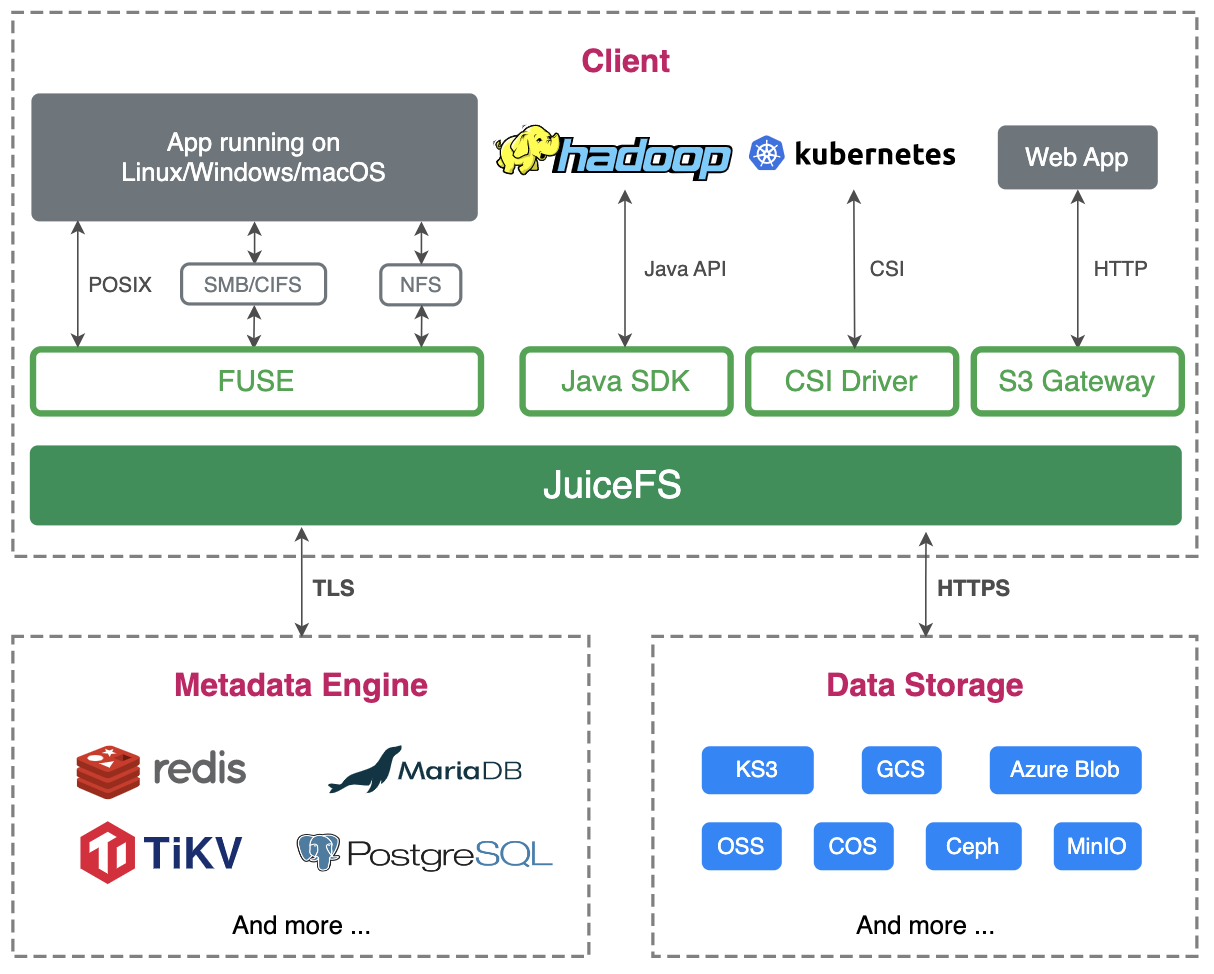
JuiceFS 製品紹介の最初の文は「ローカル ディスクのようにオブジェクト ストレージを使用する」であり、これはまさに ES を実行するときに必要な機能です。JuiceFS は多くの種類のオブジェクト ストレージを統合しており、Kingsoft Cloud の KS3 も完全に互換性があり、別のメタベースを選択するだけで済みます。
2番目の機能の検証。一般的に使用されるメタデータ データベースには、Redis、リレーショナル データベース、KV データベースなどがあります。メタベースが対応しているデータ量、応答速度、操作性の3段階で判断しています。

データ量に関しては、TiKV が間違いなく最大ですが、当初の設計意図は、各 ES クラスターを独立したメタデータ データベース インスタンスにすることでした。そのため、異なるクラスター間のメタデータは共有されず、相互に共有する必要があります。可用性、分離。
次に、応答速度に関しては、ES はコールド ノード ストレージとして JuiceFS を使用し、コールド ノードに格納されたデータ IO はメタデータ呼び出しのパフォーマンスよりも多くのパフォーマンスを消費するため、メタデータ呼び出しのパフォーマンスは重要な考慮事項ではないと考えています。
運用と保守の観点から、誰もがリレーショナルデータベースに精通しており、開発者は簡単に始めることができます. 第二に、一部の企業はRDS For MySQL製品を持っており、専門のDBAチームが運用と保守を担当しているため、最終的な選択肢はMySQLです.メタデータ エンジンとして使用されます。
JuiceFS 信頼性テスト
メタデータを選択した後、JuiceFS で信頼性テストを実施しました.JuiceFS をホストにマウントするには、次の 3 つの手順を実行するだけです。
最初のステップは、ファイル システムを作成することです。バケットを指定して、その AK、SK、およびメタデータ データベースを決定する必要があります。
2 番目のステップは、ファイル システムをディスクにマウントすることです。
3 番目のステップは、ES を JuiceFS のマウント ディレクトリにソフト リンクすることです。
当初の設計意図は JuiceFS をコールド ノードとして使用することでしたが、テストの過程で、極端な方法で JuiceFS を圧力テストしたいと考えています。2 つの極圧試験を設計しました。
1 つ目: ホット セクションに JuiceFS + KS3 をマウントし、リアルタイムで JuiceFS にデータを書き込みます。
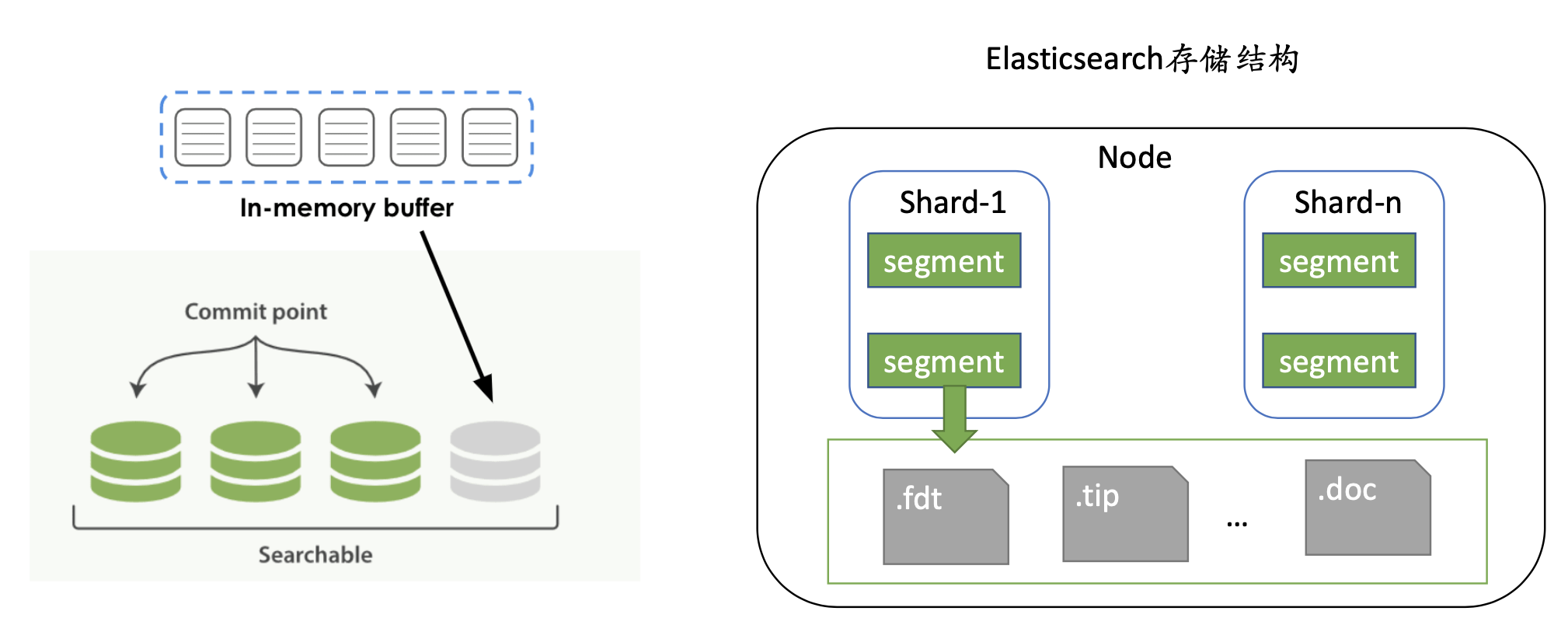
ES 書き込みプロセスは、最初にバッファ、つまりメモリに書き込みます. メモリがいっぱいになるか、インデックスによって設定された時間のしきい値に達すると、ディスクにフラッシュされ、ES セグメントがこの時点で生成されます.時間。これは一連のデータ ファイルとメタデータ ファイルで構成され、更新のたびに一連のセグメントが生成され、頻繁な IO 呼び出しが生成されます。
この圧力テストを使用して、JuiceFS の全体的な信頼性をテストします。ES 自体にいくつかのセグメントのマージがあります。これらのシナリオはウォーム ノードでは使用できないため、圧力テストには極端な方法を使用したいと考えています。
2 つ目の戦略は、ライフ サイクル管理を通じてホット データをコールド データに移行することです。
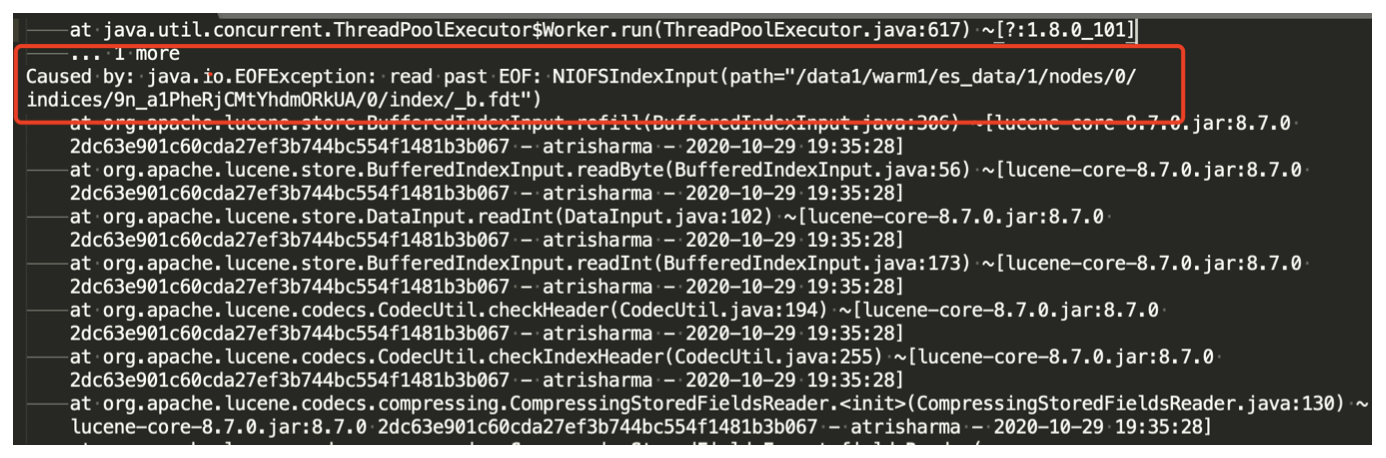
テスト中、JuiceFS1.0 はまだリリースされていません. テスト中に実際に問題が発見されました. リアルタイムの書き込みプロセス中に、データの破損が発生する可能性があります. コミュニティと通信した後、サイズを変更することで回避できます.キャッシュ:
--attr-cache=0.1 秒単位の属性キャッシュ期間 (デフォルト: 1)
--entry-cache=0.1 秒単位のファイル エントリ キャッシュ時間 (デフォルト: 1)
--dir-entry-cache=0.1 秒単位のディレクトリ エントリ キャッシュ時間 (デフォルト: 1)
これら 3 つのパラメーターのキャッシュのデフォルトは 1 で、期間を 0.1 に変更すると、インデックスの破損の問題は解決しますが、メタデータ キャッシュとデータ キャッシュの時間が短くなるため、いくつかの新しい問題が発生します。 curl などのシステム コマンドを使用して、インデックスの数またはクラスターの状態を確認するシステム コマンドを実行すると、通常の状況では、呼び出しは第 2 レベルにある可能性があり、この変更が完了するまでに数十秒かかる場合があります。
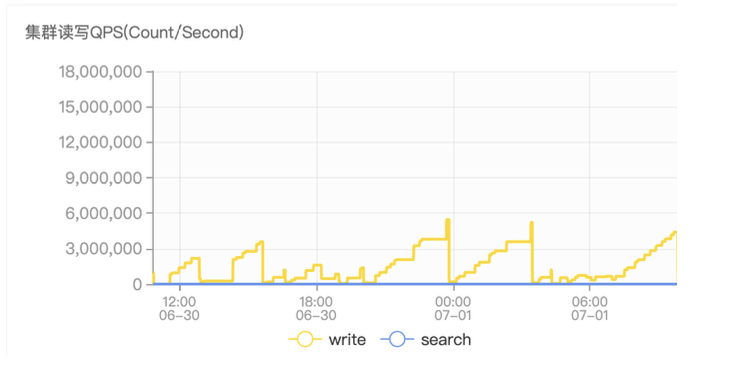
2 つ目の問題は、書き込まれた QPS が大幅に低下したことです。モニタリング グラフの書き込み QPS は非常に不安定であり、ES の実際の QPS を表していないことがわかります。これは、モニタリング グラフの QPS が 2 回取得されたドキュメントの数の差をとることによって得られるためです。 of JuiceFS にはカーネル キャッシュの問題があり、ES が古いデータを読み取る原因となっています。この問題はコミュニティに報告され、JuiceFS 1.0 の公式リリース後に解決されました。
新しいラウンドのテストを実施しました. 新しいラウンドのテストでは、3 つのホット ノード、8C16G 500G SSD、2 つのウォーム ノード、4C16G 200G SSD が特定され、テストは 1 週間続き、毎日書き込まれるデータの量は 1 TB (1 コピー) でした。 ) 、1 日後にウォーム ノードに移動します。インデックス データの破損は再び発生しませんでした.この圧力テストによって、以前に発生した問題は再発しませんでした.これは私たちに自信を与えました.次に、ES全体をこの側面に徐々に移行します.
JuiceFS データ ストレージとオブジェクト ストレージの違い
JuiceFS には独自のメタデータがあるため、オブジェクト ストレージと JuiceFS で見られるディレクトリ構造は異なります。
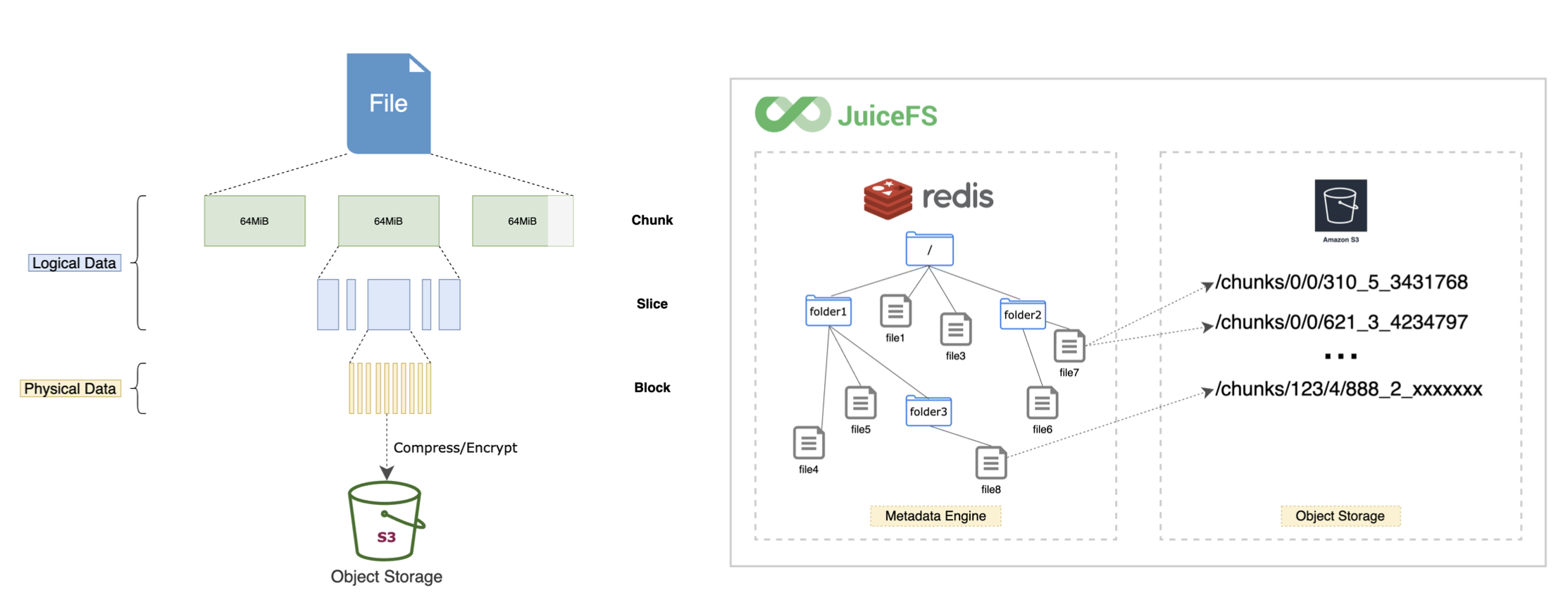
JuiceFS はチャンク、スライス、ブロックの 3 つのレイヤーに分割されているため、オブジェクト ストレージに表示されるのは、JuiceFS がファイルを分割した後のデータ ブロックです。ただし、すべてのデータは ES を介して管理されるため、ユーザーはこの点に注意を払う必要はなく、ES を介してすべてのファイル システム操作を実行するだけで済みます。JuiceFS は、オブジェクト ストレージ内のデータ ブロックを適切に管理します。
この一連のテストの後、Kingsoft Cloud は JuiceFS をログ サービス (Klog) に適用して、エンタープライズ ユーザーにワンストップのログ データ サービスを提供し、クラウド上のデータをクラウドから離れることなく直接収集できることを認識しました。ストレージ分析とアラーム; クラウドの下のデータは SDK クライアントを提供し、収集ツールを介してデータのクラウドへのリンク全体を実現し、最終的にデータを KS3 と KMR に配信してデータ処理計算を実現できます。

03 Elasticsearch ホットおよびコールド データ管理
ES には、ノード ロール、インデックス ライフサイクル管理、データ ストリームなど、一般的に使用されるいくつかの概念があります。
ノードの役割、ノードの役割。各 ES ノードには、マスター、データ、取り込みなどのさまざまな役割が割り当てられます。データノードに注目すると、旧バージョンではホットノード、ウォームノード、コールドノードの3種類に分かれていましたが、最新バージョンではフリーズノードとフリーズノードが追加されています。
インデックス ライフサイクル管理 (ILM) は、次の 4 つのフェーズに分かれています。
- hot: インデックスは頻繁に更新され、クエリが実行されています。
- ウォーム: インデックスは更新されなくなりましたが、クエリの量は平均的です。
- cold: インデックスは更新されなくなり、ほとんどクエリされません。情報は引き続き検索可能である必要がありますが、クエリが遅くても問題ありません。
- delete: インデックスは不要になり、安全に削除できます。
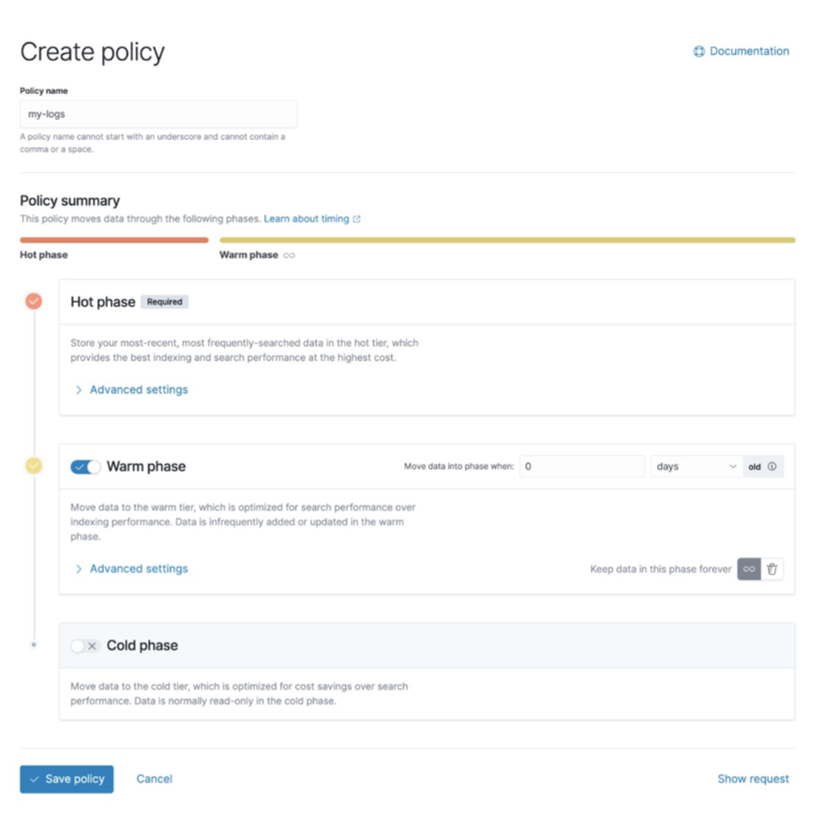
ES は公式にライフ サイクル管理ツールを提供しており、インデックスのサイズ、ドキュメントの数、および時間ポリシーに基づいて、大きなインデックスを複数の小さなインデックスに分割できます。大規模なインデックスは、管理とメンテナンスからクエリされ、そのオーバーヘッドは非常に高くなります。ライフサイクル管理機能により、インデックスをより柔軟に管理できます。
データ ストリームは、バージョン 7.9 で導入された新機能です。インデックス ライフサイクル管理に基づいて、時系列データを簡単に処理できるデータ ストリーム書き込みを実装します。
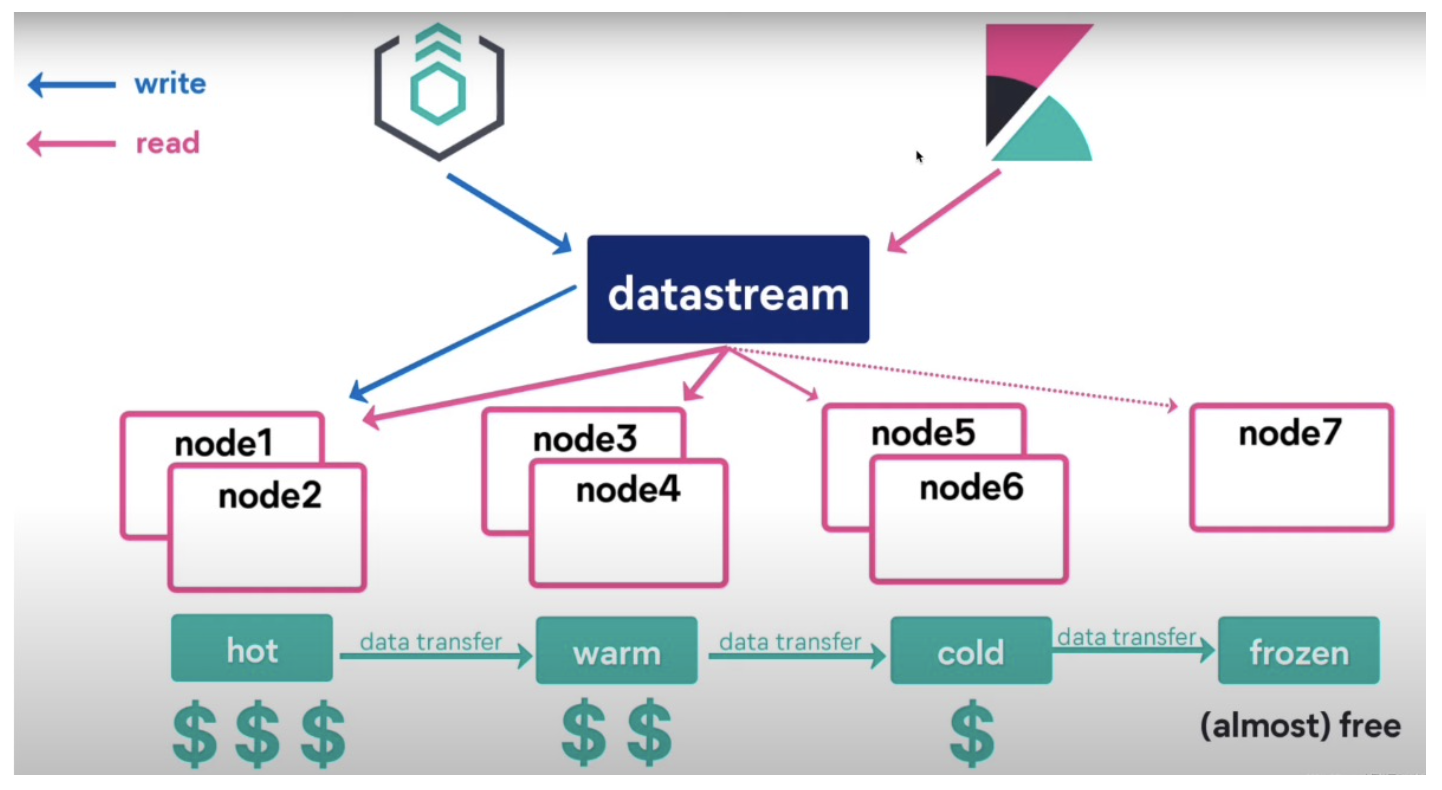
複数のインデックスをクエリする場合、これらのインデックスは通常、クエリに結合されます. エイリアスのようなもので、それ自体で異なるインデックスにルーティングできるデータストリームを使用できます. Data Stream は、時系列データのストレージ管理とクエリにより親しみやすく、これは ES のホット アンド コールド管理に一歩近づき、全体の運用と保守管理に便利です。
コールド ノードのサイズを適切に計画する
コールド データをオブジェクト ストレージに配置する場合、コールド ノードの管理が必要になります。コールド ノードは、主に次の 3 つの側面に分けられます。
1 つ目: メモリと CPU とストレージ スペース。メモリーのサイズによって、シャードの数が決まります。通常、ホット ノードで物理メモリを半分に分割します。半分は ES JVM 用で、残りの半分は Lucene 用です。Lucene は ES の検索エンジンであり、十分なメモリを割り当てることで ES のクエリ パフォーマンスを向上させることができます。したがって、それに応じて、コールド データ ノードに JVM メモリを適切に割り当て、Lucene メモリを削減できますが、JVM メモリは 31G を超えないようにする必要があります。
2 つ目: CPU とメモリの比率が、前述の 1:4 から 1:8 に減少します。JuiceFS とオブジェクト ストレージをストレージ スペースで使用することは無制限のストレージ スペースと見なすことができますが、コールド ノードでハングしているため、使用可能なスペースは無制限ですが、メモリ サイズによって制限されるため、これは無制限のストレージ スペースであると判断します。理想。さらに拡大すると、ES全体のコールドノードの安定性に比較的大きな危険が隠れています。
3つ目:収納スペース。32G メモリを例にとると、妥当なストレージ容量は 6.4 TB です。シャード数を増やすことで容量を拡張できますが、ホットノードではホットノードの安定性を考慮する必要があるため、シャード数を厳密に制御する必要があり、コールドノードではこの比率を適切に増やすことができます。
ここで考慮すべき重要な要素が 2 つあります。1 つは安定性で、もう 1 つはデータの回復時間です。JuiceFS プロセスがハングアップしたり、コールド ノードがハングアップしたり、操作やメンテナンス中にノードを再マウントする必要がある場合など、ノードがハングアップした場合、すべてのデータを ES に再ロードする必要があるため、大量のエラーが発生します。頻繁 データの読み取り要求の場合、データ量が多い場合、ES 全体の断片化回復時間は長くなります。
一般的に使用されるインデックスの断片化管理方法
管理アプローチでは、主に次の 3 つの側面を考慮します。
- シャードが大きすぎる: クラスター障害後の回復が遅い; データ書き込みのホットスポットが発生しやすく、その結果、バルク キューがいっぱいになり、拒否率が上昇します。
- シャードが小さすぎる: より多くのシャードが作成され、より多くのメタデータが占有され、クラスターの安定性が影響を受け、クラスターのスループットが低下します。
- シャードが多すぎる: セグメントが増え、IO リソースの深刻な浪費、クエリ速度の低下、より多くのメモリの消費、安定性への影響が生じます。
データを書き込むと、全体のデータ サイズが不確定になりますが、通常は、テンプレートを作成し、固定シャードのサイズを決定し、シャードの数を決定してから、マッピングとインデックスを作成します。
この時点で、2 つの問題が発生する可能性があります. 1 つ目は、フラグメントが多すぎることです. 予想されるときにどれだけのデータが書き込まれるかがわからないためです. 多くのフラグメントを作成した可能性がありますが、それ以上は作成されません.データが入ります。
2 つ目は、作成されるフラグメントの数が少なすぎるため、インデックスが大きくなりすぎることです.このとき、小さなフラグメントをマージする必要があります.データを長時間ローテーションする必要があります.いくつかの小さなセグメントを大きなセグメントにマージして、より多くの IO とメモリを消費しないようにします。同時に、いくつかの空のインデックスを削除する必要があります。空のインデックスにはデータはありませんが、メモリを占有します。妥当なフラグメントサイズを 20 ~ 50g 以内に制御することをお勧めします。
04 JuiceFSの使用効果と注意点
例としてオンライン クラスターを取り上げます。データ スケール: 毎日 5 TB の書き込み、30 日間のデータ ストレージ、1 週間のホット データ ストレージ、ノード数: 5 つのホット ノード、15 のコールド ノード。
JuiceFS を採用した後、ホット ノードは変更されず、コールド ノードの数は 15 から 10 に減少しました。同時に、JuiceFS 用に 1TB の機械式ハード ディスクをキャッシュとして使用しました。
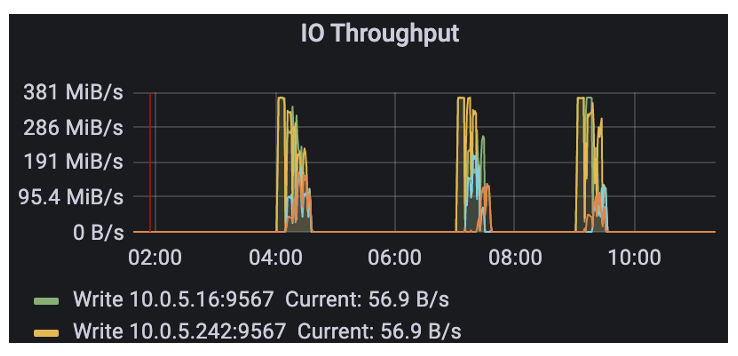
ライフサイクル管理操作全体を低ピーク時間帯に実行しているため、早朝に多数のオブジェクト ストレージ呼び出しが発生することがわかります。
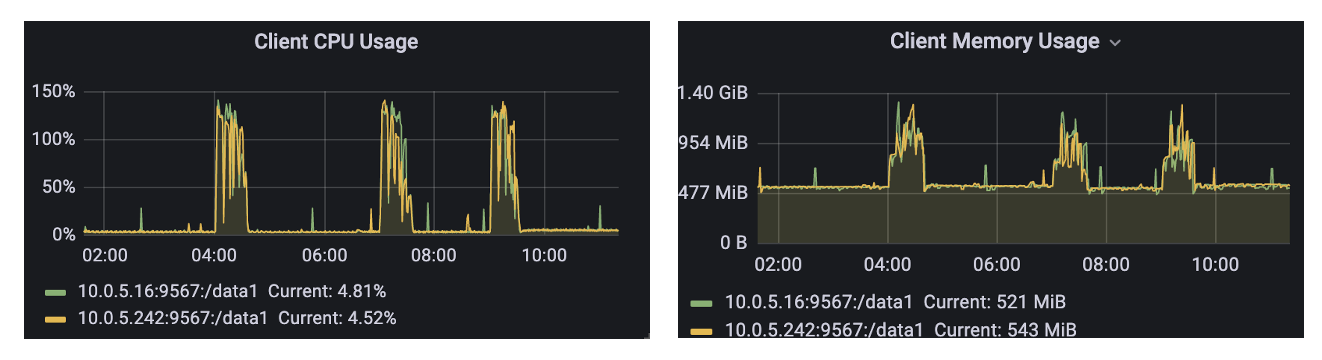
JuiceFS のメモリ使用量は通常数百 MB であり、ピーク時に呼び出されると 1.5G とその CPU 使用量を下回り、パフォーマンスは正常です。
JuiceFS を使用する際の注意事項は次のとおりです。まず、ファイル システムを共有しないでください。コールド ノードに JuiceFS をマウントするため、各マシンが見るのは全量のデータです. より使いやすい方法は、複数のファイル システムを使用することです. 各 ES ノードはファイル システムを使用します。問題。
最終的に ES のセットがファイルシステムに対応するモデルを選択しました.この慣行によってもたらされる問題は、各ノードが全量のデータを参照することであり、この時点でいくつかの誤操作が発生しやすいことです. ユーザーがRMを行いたい場合は、他のマシンのデータが削除される可能性がありますが、異なるクラスタ間でファイルシステムを共有しないこと、および同じクラスタ内でファイルシステムを共有しないことを考えると、管理と運用保守のバランスを取る必要があるため、 ES のセットは、JuiceFS ファイル システム モードに対応します。
2 番目: データを手動でウォーム ノードに移行します。インデックスのライフ サイクル管理では、ES はホット ノードからコールド ノードにデータを移行するためのいくつかの戦略を持ちます。戦略実行時は、業務のピーク時である可能性があり、このとき、ホットノードでIOが発生し、コールドノードにデータがコピーされ、ホットノードのデータがホット ノード システム全体のコストは比較的高いため、どのインデックスをいつコールド ノードに移行するかを手動で制御しています。
3 番目: 低いピーク時にインデックスを移行します。
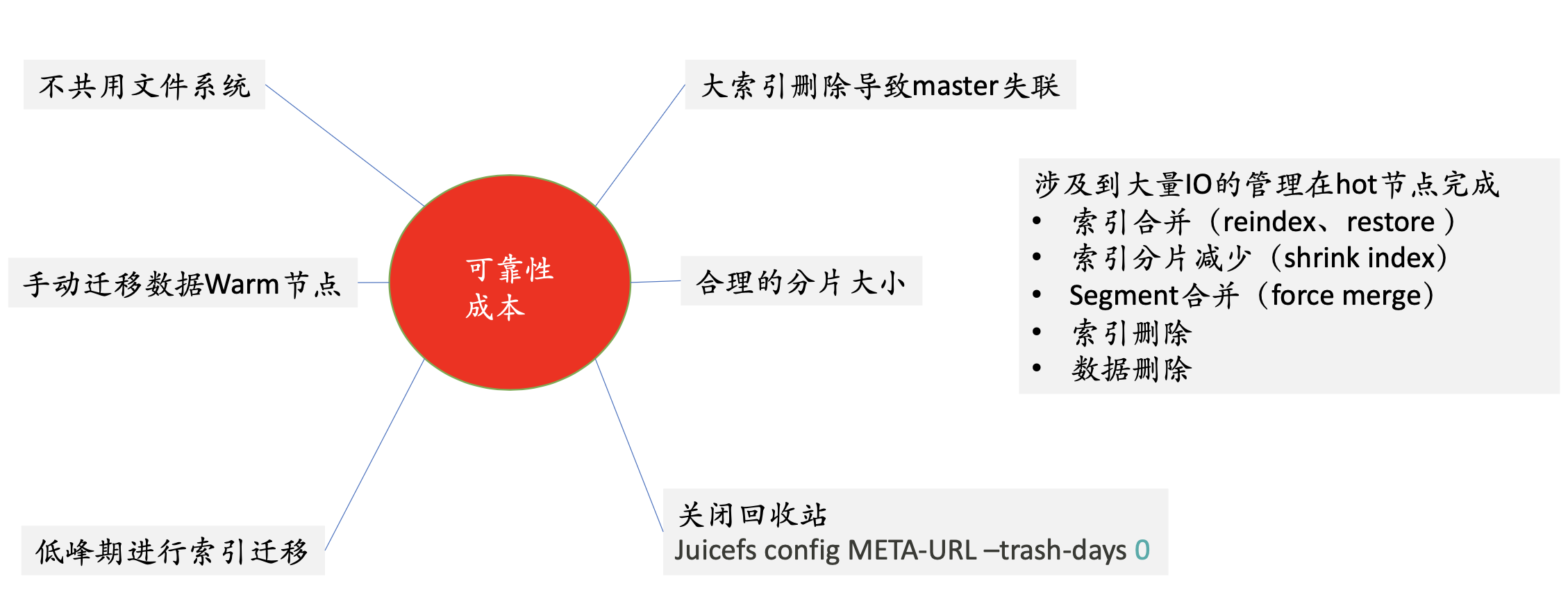
4: 大きなインデックスを避ける。大きなインデックスを削除する場合、その CPU および IO パフォーマンスはホット ノードのパフォーマンスよりも悪くなります. このとき、コールド ノードはマスターとの接続を失います. 接続が失われた後、データが再ロードされ、次にデータが再ロードされます. ES に障害が発生し、ノードに障害が発生するため、コストが非常に高くなります。
5 番目: 妥当な断片化サイズ。
** 6 番目: ごみ箱を閉じます。**オブジェクト ストレージでは、JuiceFS はデフォルトで 1 日分のデータを保存しますが、ES シナリオでは必要ありません。
ホットノードで実行する必要がある、多くの IO を含む他の操作もあります。たとえば、インデックスのマージ、スナップショットの復元、フラグメントの削減、インデックスとデータの削除などです。これらの操作がコールド ノードで発生すると、マスター ノードは接続を失います。オブジェクト ストレージのコストは比較的低いですが、頻繁な IO 呼び出しのコストが増加し、オブジェクト ストレージは put および get 呼び出しの数に応じて課金されるため、これらの大規模な操作はホット ノードに配置する必要があります。ビジネス側のコールド ストレージにのみ使用されます。ノードはいくつかのクエリを実行します。
お役に立てれば、私たちのプロジェクトJuicedata/JuiceFSに注目してください! (0ᴗ0✿)