원문은 제 개인 블로그 에서 가져왔습니다 .
1. 전제조건
서버는 GPU 서버입니다. 내가 사용하는 GPU 서버로 이동하려면 여기를 클릭하세요 . 저는 NVIDIA A 100 그래픽 카드와 4GB 비디오 메모리로 귓속말을 만들었습니다.
Python 버전은 3.8~3.11 사이여야 합니다.
다음 명령을 입력하여 사용된 Python 버전을 확인하십시오.
python3 -V
2. 아나콘다 설치
Anaconda를 설치하는 이유는 무엇입니까?
서로 다른 프로젝트에서 사용하는 라이브러리의 버전 충돌을 줄이기 위해 Anaconda를 사용하여 가상 Python 환경을 만들 수 있습니다.
시스템에 해당하는 설치 프로그램을 찾으십시오.
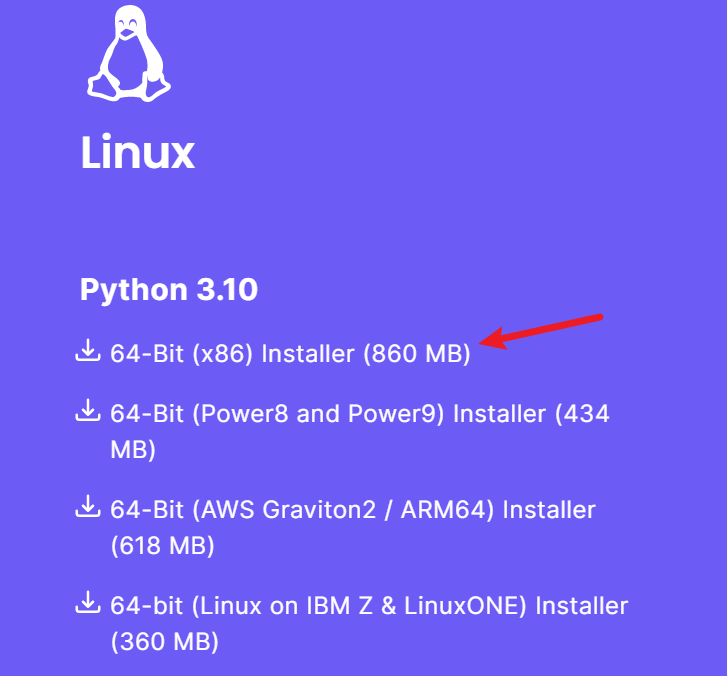
다운로드가 완료되면 스크립트를 직접 실행할 수 있습니다.
bash 脚本.sh
다음과 같은 방법으로 스크립트를 실행할 수도 있습니다.
chmod +x 脚本.sh
./脚本.sh
설치가 완료되면 SSH에 다시 연결해야 합니다.
설치가 성공했는지 확인하려면 다음 명령을 사용할 수 있습니다.
conda -V
3. FFmpeg 설치
apt install ffmpeg
Enter를 입력 하면 ffmpeg설치가 성공했음을 나타내는 프롬프트 메시지를 볼 수 있습니다.
4. 그래픽 카드 드라이버 설치
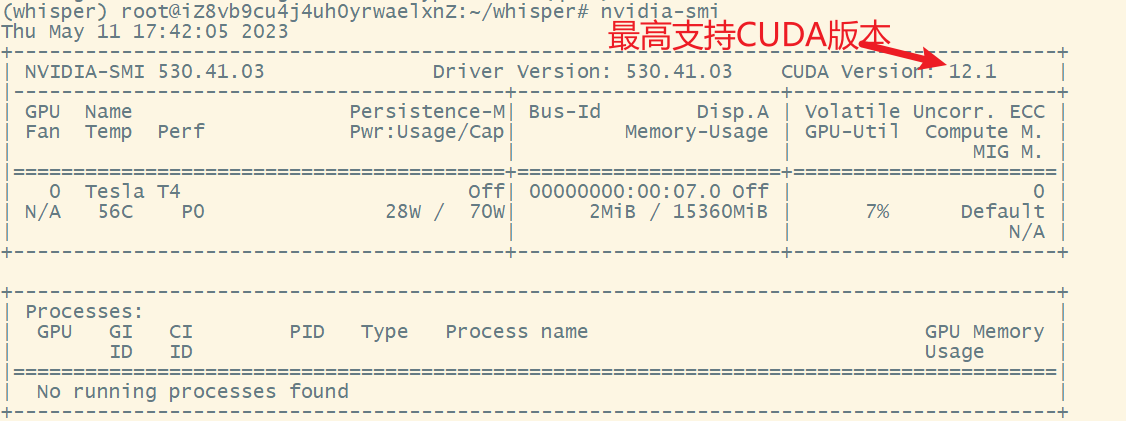
먼저 nvidia-smi그래픽 카드 정보를 보기 위해 엔터를 치고 프롬프트 메시지가 있으면 그래픽 카드 드라이버가 설치된 것입니다.
그래픽 카드 드라이버가 설치되어 있지 않은 경우 다음 두 가지 설치 방법이 있습니다.
4.1 방법 1
ubuntu-drivers devices 설치할 수 있는 그래픽 드라이버 보기
apt install nvidia-driver-530 권장 그래픽 드라이버 설치
nvidia-smi 그래픽 카드 정보 보기
4.2 방법 2
NVIDIA해당 그래픽 카드 드라이버를 다운로드하려면 공식 드라이버 다운로드 웹 사이트 로 이동하십시오 .
자세한 내용은 이 기사를 참조하십시오 .
5. 쿠다 설치
다운로드한 CUDA 버전은 nvidia-smi에서 볼 수 있는 CUDA 버전 이하이어야 하며 마음대로 다운로드할 수 없습니다.
공식 명령에 따라 설치하십시오.
편집 ~/.bashrc, 끝에 다음 명령을 추가하십시오.
export PATH=/usr/local/cuda-12.1/bin${
PATH:+:${
PATH}}
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-12.1/lib64
cuda-12.1참고: 위의 내용을 직접 설치한 CUDA 버전으로 변경 해야 합니다 .
재장전
source ~/.bashrc
sudo ldconfig
CUDA가 설치되어 있는지 확인하십시오.
nvcc -V
설치 과정에서 보고된 오류가 없지만 이 명령을 입력한 후 버전 정보가 출력되지 않으면 환경 변수가 구성되지 않았거나 잘못 구성된 것입니다.
6. cuDNN 설치(선택 사항)
cuDNN을 다운로드하려면 NVIDIA 계정을 등록해야 하며 해당 커뮤니티 가입을 확인하고 동의해야 합니다. 그렇지 않으면 다운로드할 수 없습니다. 그리고 이 다운로드는 이전에 인증을 받아야 하므로 서비스에서 직접 다운로드할 수 없습니다. 그렇지 않으면 다운로드하는 것은 웹 페이지일 뿐이므로 먼저 로컬 컴퓨터에 다운로드한 다음 서버를 통해 서버에 업로드해야 합니다. rz 또는 scp 명령.
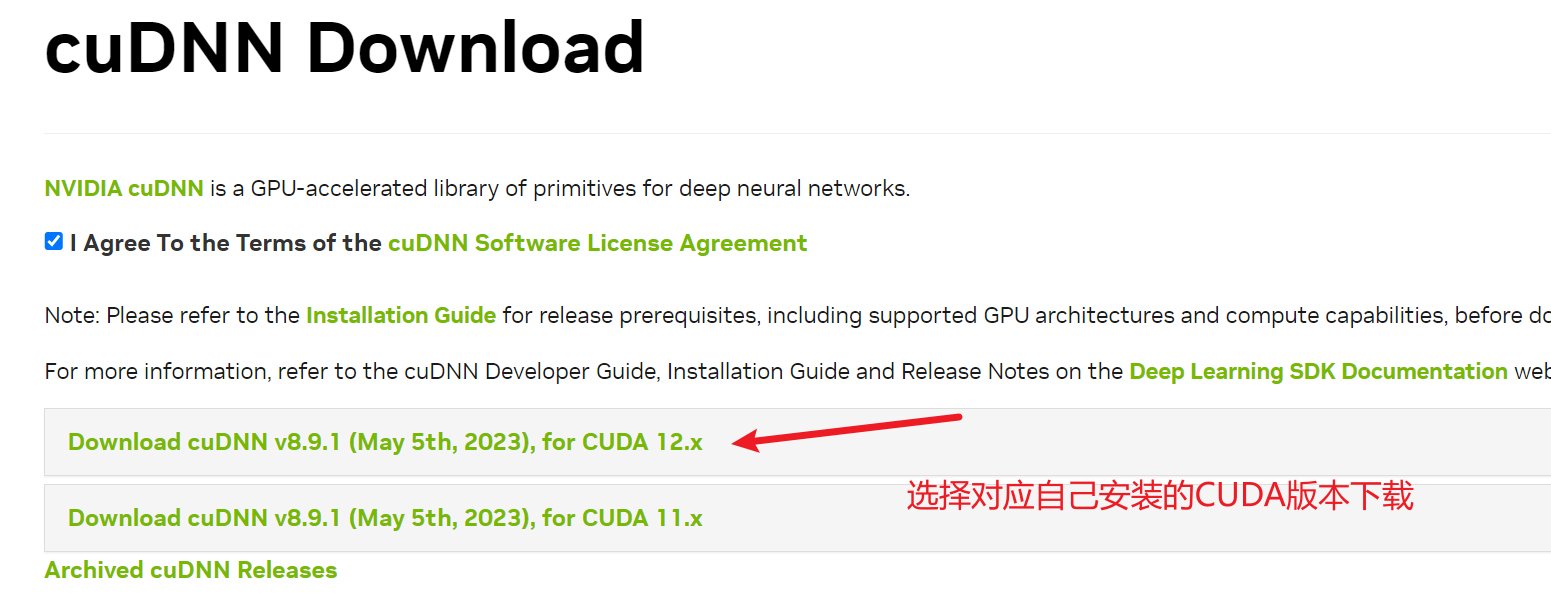
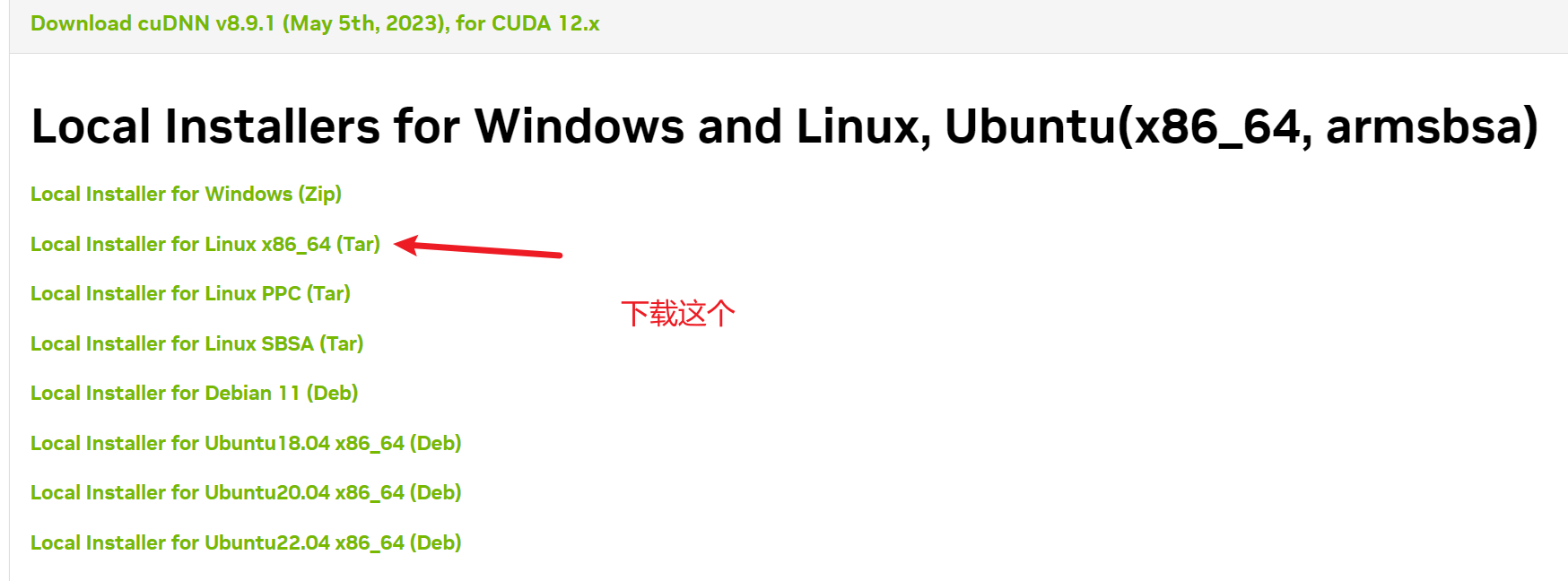
다운로드가 완료되면 CUDA 디렉토리에 압축을 풉니다.
tar -xvf 文件名
cd 文件夾
sudo cp include/* /usr/local/cuda-12.1/include
sudo cp lib/libcudnn* /usr/local/cuda-12.1/lib64
sudo chmod a+r /usr/local/cuda-12.1/include/cudnn*
sudo chmod a+r /usr/local/cuda-12.1/lib64/libcudnn*
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
7. 파이토치 설치
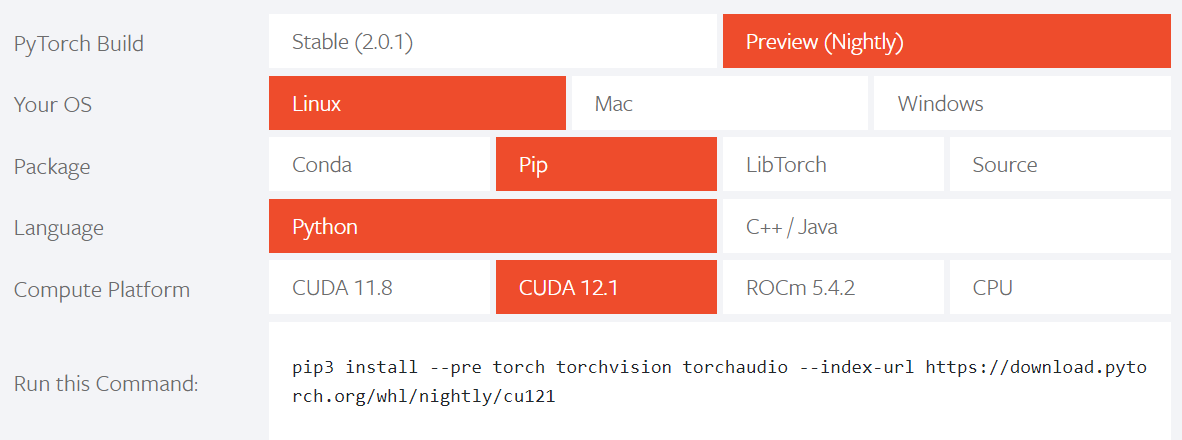
참고: 설치된 버전은 CUDA 버전과 일치해야 합니다.
설치할 때 공식 명령을 직접 복사하십시오.
그런 다음 다음 명령을 사용하여 설치가 성공했는지 확인할 수 있습니다.
python
import torch
torch.__version__
torch.cuda.is_available()
마지막 문장이 핵심입니다. True를 반환해야만 Whisper가 그래픽 카드를 사용하여 전사할 수 있고, 그렇지 않으면 CPU를 사용하여 전사할 수 있습니다. 마지막 문장이 False를 반환하면 설치한 PyTorch 버전에서 사용된 CUDA 버전이 서버에 이미 설치된 CUDA 버전과 일치하지 않을 수 있습니다.
8. 위스퍼 설치
설치하기 전에 conda를 사용하여 가상 환경을 만들어야 합니다.
conda create -n whisper python=3.10
가상 환경을 활성화합니다.
conda activate whisper
가상 환경을 종료합니다.
conda deactivate
가상 환경을 확인하십시오.
conda env list
가상 환경을 삭제합니다.
conda remove -n whisper --all
먼저 가상 환경을 활성화한 후 다음 명령어를 입력하여 설치합니다.
pip install -U openai-whisper
오류가 없으면 다음 명령을 입력하고 정보 출력이 표시되면 설치가 성공한 것입니다.
whisper -h
9. 귓속말 사용
처음 사용할 때는 상대적으로 느리고 모델을 다운받아야 함 사용하는 모델이 클수록 전사 속도가 느리고 전사 정확도가 높음 Whisper는 스페인어가 인식 정확도가 가장 높고, 그 다음이 이탈리아어 , 그 다음에는 영어만, 북경어에 대한 인식은 중간에 있습니다.
다음은 Whisper 사용법에 대한 간략한 설명입니다.
whisper 你要转录的音视频文件 --model large --language Chinese
whisper -h더 많은 사용법을 볼 수 있습니다 .