머리말
예를 들어 프로그램의 성능을 향상시키기 위해 분산 캐시를 만들기 위해 모든 사람들이 자신의 프로젝트에서 redis를 사용했다고 생각합니다.
Redis를 캐시로 사용할 때 여러 가지를 고려해야 하는데, 캐시 고장, 캐시 침투, 캐시 폭주 외에 어떤 다른 문제를 고려해야 할까요?
높은 동시 쓰기
실시간 주문과 같이 동시성이 높은 상황의 경우 실시간 주문은 플래시킬과 다릅니다. 플래시킬은 인벤토리가 제한되어 있지만 실시간 스트리밍 주문은 항상 할 수 있으며 주문이 많을수록 좋습니다. 예를 들어 재고가 100,000개 있는데 이 제품이 특히 인기가 있으면 순식간에 모든 트래픽이 몰릴 수 있습니다. 우리의 인벤토리는 미리 redis에 배치되고 MySql에 액세스하지 않지만 이때 모든 요청은 redis로 전송됩니다.
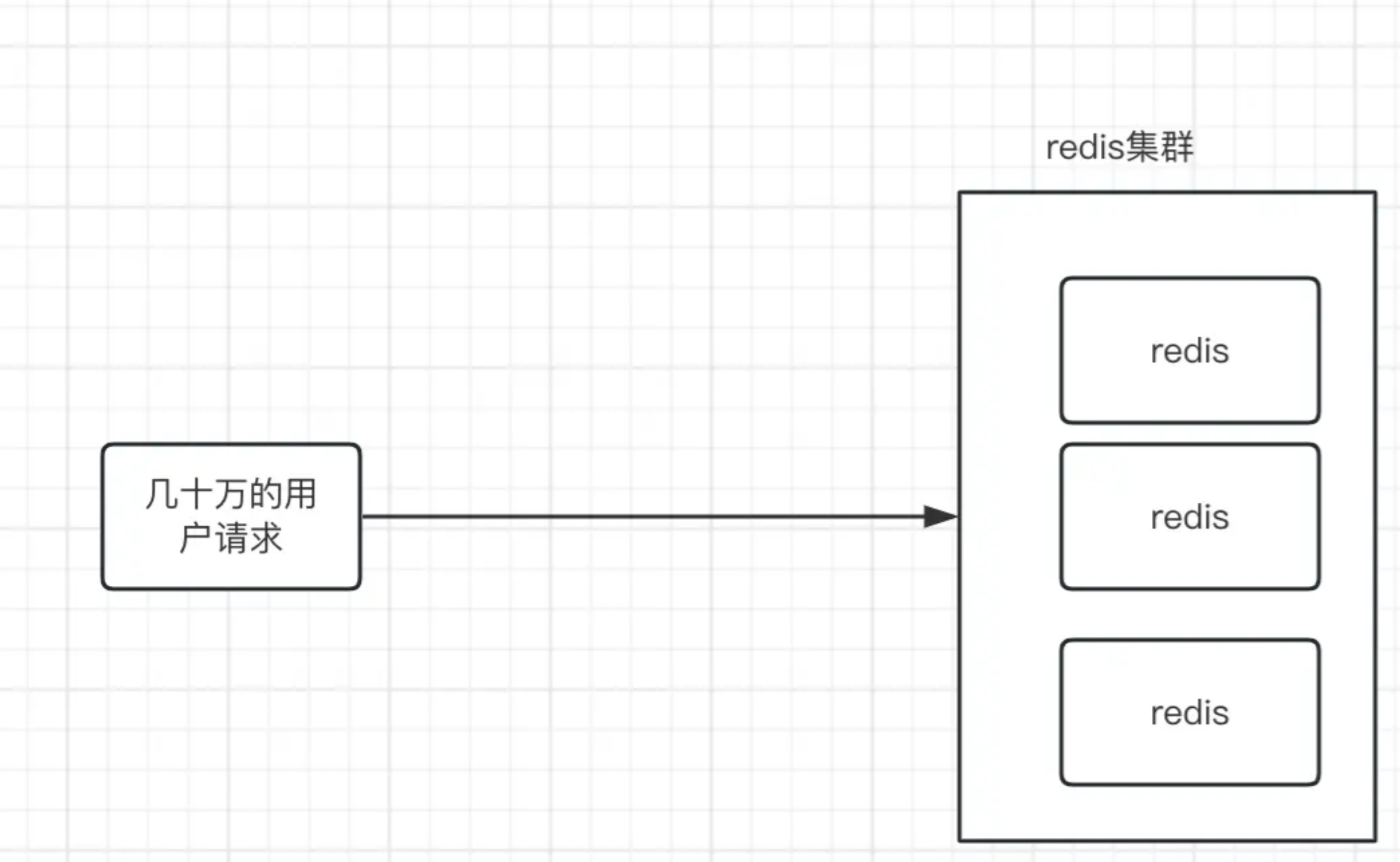
표면적으로는 문제가 없는 것 같지만, 클러스터가 있어도 하나의 키만 접근해도 결국 같은 레디스 서버에 떨어진다고 생각해본 적 있으신가요? 이 때 키가 있는 redid는 모든 요청을 전달하며 클러스터의 다른 머신은 전혀 액세스할 수 없습니다. 이때 redis가 처리할 수 있다고 확신하십니까? ? ? 현재 많은 읽기 요청이 있는 경우 redis가 처리할 수 있다고 생각하십니까?
그래서 이런 상황에서는 데이터 단편화 솔루션을 사용할 수 있는데, 예를 들어 주식이 100,000개라면 이때 Redis 서버를 10개 설정하고 각 Redis 서버에 10,000개의 주식을 넣을 수 있습니다. 사용자 ID를 모듈화하여 사용자 트래픽을 10개의 Redis 서버로 분산
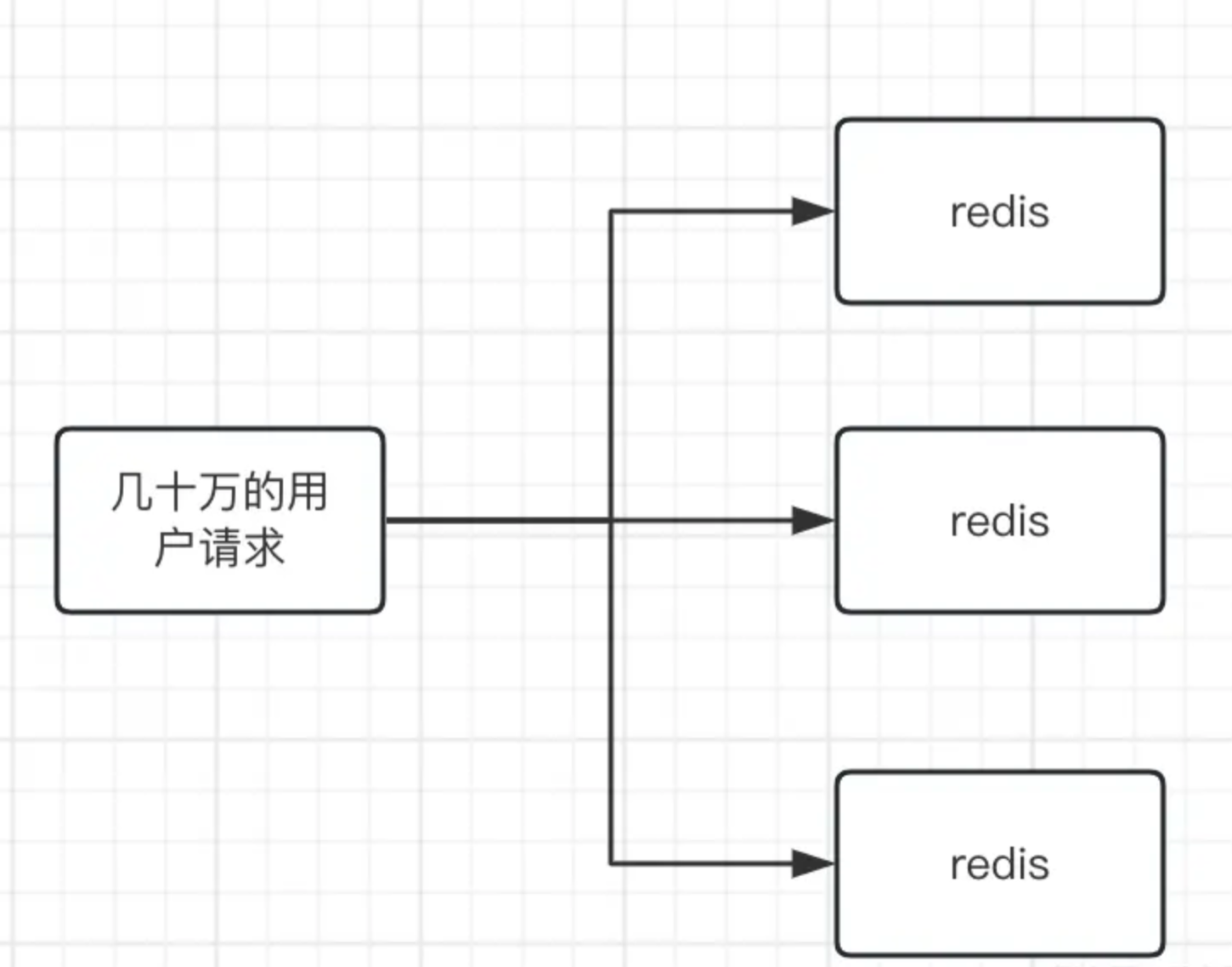
따라서 핫스팟 데이터의 경우 우리가 해야 할 일은 트래픽을 공유하고 여러 redis가 트래픽의 일부를 공유하도록 하는 것입니다. 특히 이러한 종류의 높은 동시 쓰기의 경우
높은 동시 읽기
redis를 캐시로 사용하는 것이 우리 프로젝트에서 가장 많이 사용된다고 할 수 있습니다.방문량이 많지 않기 때문에 우리의 redis 서비스는 많은 사용자의 요청을 충분히 전달할 수 있습니다.하지만 우리는 그것을 생각할 수 있습니다.reids 읽기 요청 One network IO는 10,000번이면 100,000번? 그것은 우리가 작업에서 고려해야 하는 네트워크 IO의 100,000배입니다. 이 오버헤드는 실제로 매우 크기 때문에 방문량이 너무 많으면 redis에 문제가 발생할 가능성이 높습니다.
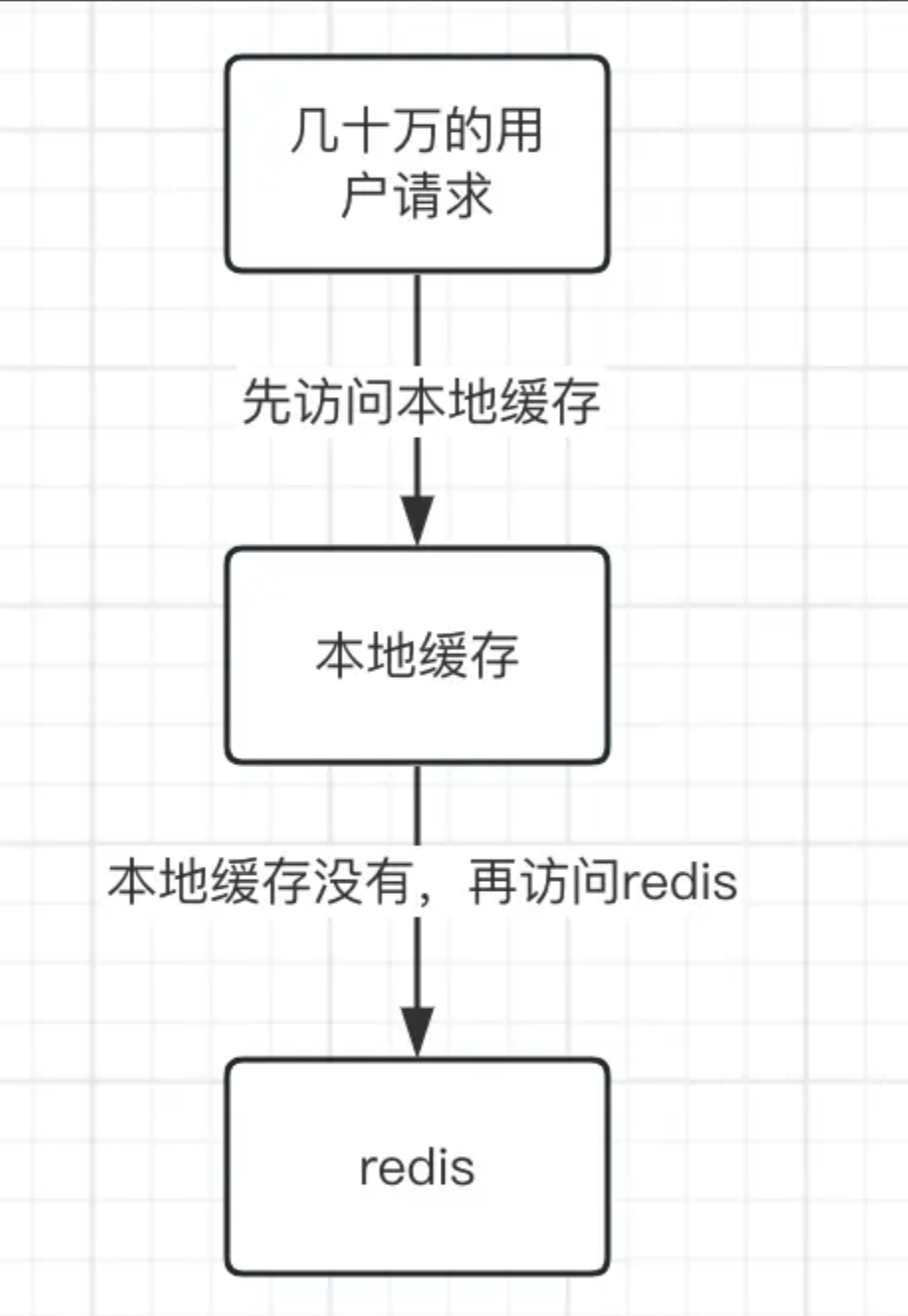
로컬 캐시 + redis 분산 캐시를 사용하여 이 문제를 해결할 수 있습니다.일부 핫 읽기 데이터 및 작은 업데이트 데이터의 경우 Guava와 같은 도구와 같은 로컬 캐시에 데이터를 저장할 수 있습니다.물론 로컬의 만료 시간은 캐시는 반드시 5초 정도로 짧게 설정해야 하며, 이때 대부분의 요청은 redis에 접근하지 않고도 로컬 캐시에 배치할 수 있습니다.
이때 로컬 캐시가 없으면 redis를 다시 방문한 다음 redis의 데이터를 로컬 캐시에 넣습니다.
다단계 캐시가 추가되면 다단계 캐시에서 데이터 일관성을 보장하는 방법과 같은 해당 문제가 발생합니다.
요약하다
완벽한 솔루션은 없으며 가장 적합한 솔루션만 있습니다. 특정 기술 솔루션을 채택하기로 결정하면 필연적으로 고려해야 할 다른 문제가 발생합니다. 캐싱을 위해 사용하지만 redis도 마찬가지입니다. . 우리 프로그램의 성능을 향상시킬 수 있지만 redis를 캐시로 사용할 때 몇 가지 상황도 고려해야 합니다 트래픽이 적은 사용자의 경우 redis를 직접 사용하는 것으로 충분하지만 In 높은 동시성 시나리오에서 솔루션이 비즈니스를 지원할 수 있습니까?