마이크로서비스는 불멸입니다. 정책 엔진 프로젝트의 공유 변수 구현에 대한 자세한 설명
기타
2024-04-17 00:51:49
독서 시간: null
배경
1. 공유변수의 제안
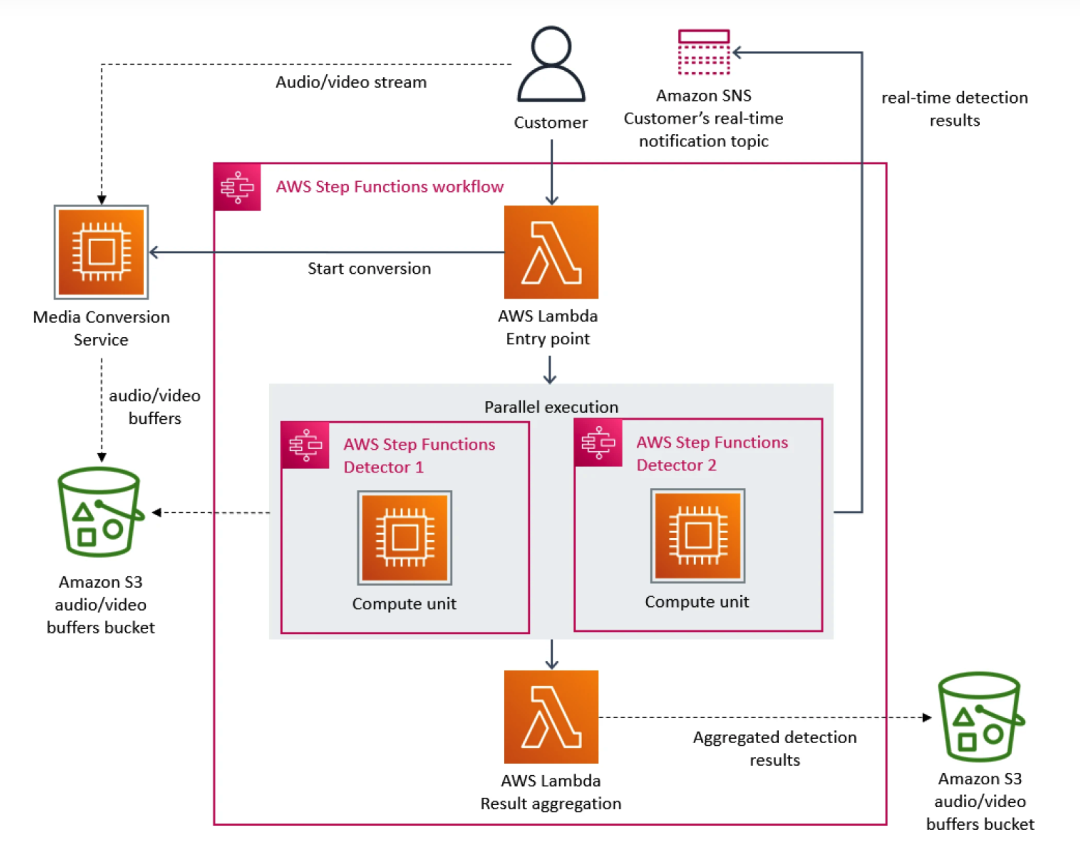
얼마 전 Amazon Prime Video 팀의 사례 연구는 개발자 커뮤니티에서 소란을 일으켰습니다. 기본적으로 스트리밍 플랫폼으로서 Prime Video는 고객에게 매일 수천 개의 라이브 스트림을 제공합니다. 고객이 콘텐츠를 원활하게 수신할 수 있도록 Prime Video는 고객이 시청한 모든 스트림에서 품질 문제를 식별하는 모니터링 도구를 구축해야 했으며 이로 인해 매우 높은 확장성 요구 사항이 적용되었습니다.
이에 프라임비디오팀은 마이크로서비스 아키텍처를 우선시했다. 마이크로서비스는 단일 애플리케이션을 여러 모듈로 분해할 수 있기 때문에 도구의 독립적인 개발 및 배포 문제를 해결할 뿐만 아니라 애플리케이션에 대한 더 높은 가용성, 안정성 및 기술적 다양성을 제공합니다. 궁극적으로 Prime Video의 서비스는 세 부분으로 구성됩니다. 미디어 변환기는 오디오 및 비디오 스트림을 감지기의 오디오 및 비디오 버퍼로 보냅니다. 결함 감지기는 결함이 발견되면 실시간 알림을 보냅니다. 서비스 프로세스의 조정.
서비스에 더 많은 플로우가 추가될수록 과도한 비용이 발생하는 문제가 나타나기 시작합니다. AWS Step은 기능 상태 전환을 기준으로 사용자에게 요금을 부과하기 때문에 많은 수의 스트림을 처리해야 할 경우 대규모로 인프라를 실행하는 오버헤드가 매우 비싸져 모든 빌딩 블록의 총 비용이 너무 높아서 Prime Video를 사용할 수 없게 됩니다. 팀이 초기 대규모 솔루션을 받아들이지 못하게 되었습니다. 결국 Prime Video 팀은 인프라를 재구성하고 마이크로서비스에서 모놀리식 아키텍처로 마이그레이션하여 인프라 비용을 90% 절감했습니다.
이번 사건을 통해 우리는 분산 아키텍처에도 단일 서비스 아키텍처에 비해 단점이 있다는 사실을 더욱 깨닫게 되었습니다. 예를 들어 Prime Video 팀은 문제에 직면했습니다. 분산 아키텍처는 모놀리식 아키텍처와 같은 변수를 공유할 수 없기 때문에 기본 서비스가 동일한 요청을 더 많이 처리하게 되어 비용이 치솟게 됩니다. 이러한 딜레마는 iQiyi의 해외 아키텍처, 특히 전략 엔진의 호출 관계에도 존재합니다.
2. iQiyi 해외 전략 엔진 호출 관계
2.1 정책 엔진 호출 관계 소개
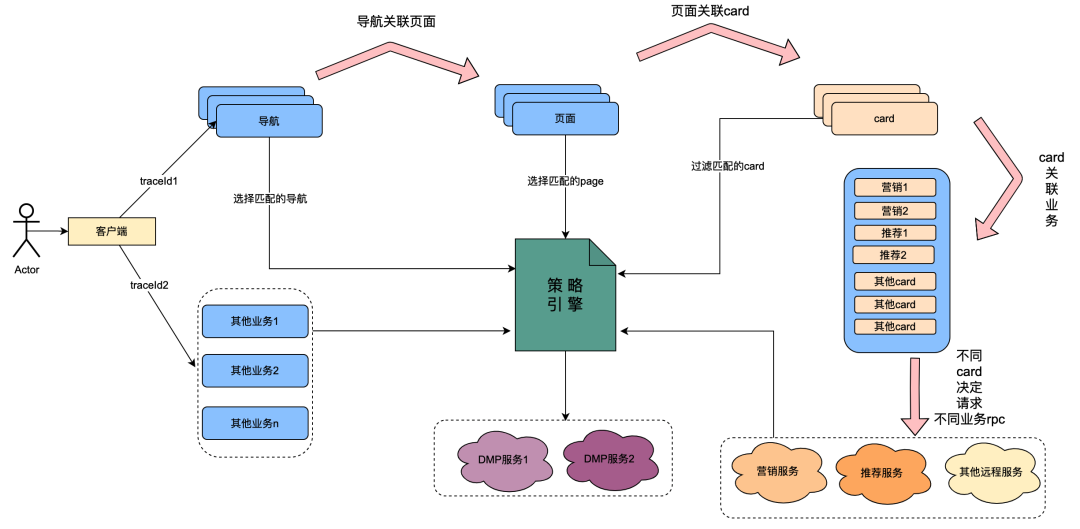
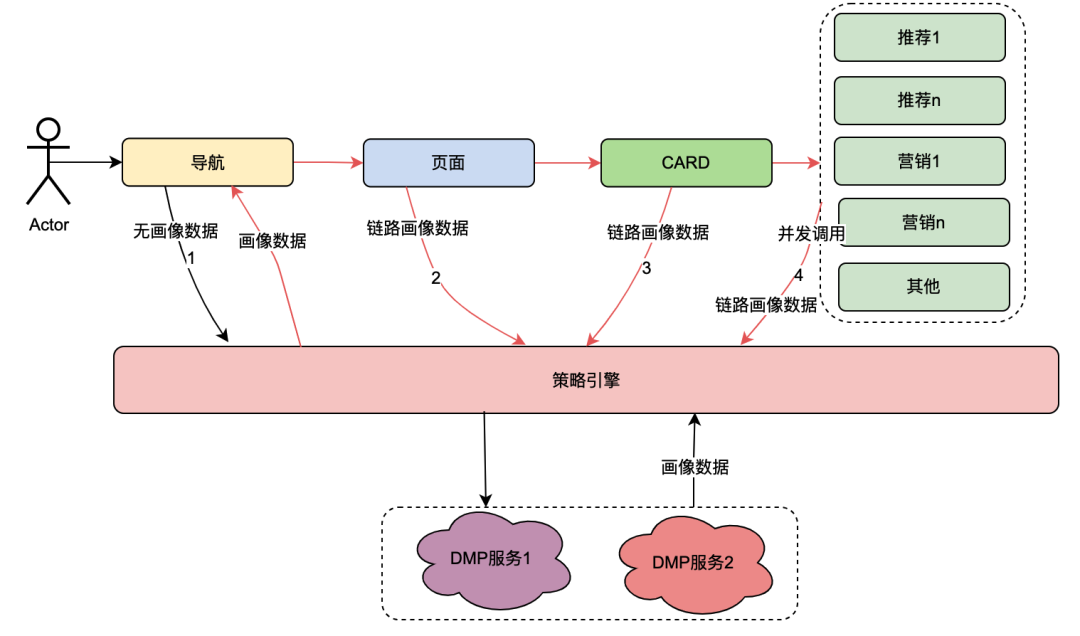
그 중 카드는 페이지 내 각 열의 세분화 모듈입니다. 일반적으로 TV 시리즈, 영화 등의 열은 하나의 카드입니다. 마케팅을 통해 얻은 마케팅 데이터, 추천을 통해 얻은 콘텐츠, 칩에서 얻은 프로그램 콘텐츠 등 각 카드의 데이터 소스는 다릅니다. 예를 들어 페이지는 탐색 아래에 연결되고, 카드는 페이지 아래에 연결되며, 카드의 특정 비즈니스 데이터는 카드 아래에 연결됩니다.
정책 엔진은 사람들의 그룹을 식별하기 위한 매칭 서비스입니다. 예를 들어 현재 일본 골드 회원, 남성, 7일 미만의 회원 만료일 및 일본 애니메이션 선호도를 포함하는 그룹 정책이 구성되어 있습니다. 정책 엔진 서비스는 사용자가 위 그룹 정책에 속하는지 여부를 식별할 수 있습니다.
" 무엇이든 가능 "이라는 기술 혁신 이후 탐색, 페이지, 카드 및 카드 내 데이터의 사용자 프로필 차원을 사용자 정의하는 기능이 달성되었습니다. 일반적인 구현은 다음과 같습니다. 클라이언트가 요청을 시작할 때 먼저 탐색 API를 요청합니다. 탐색 데이터 구성 배경에서 운영 학생들은 다양한 탐색 데이터를 구성했으며 각 탐색 데이터는 정책과 연결되었습니다. 탐색 API는 내부적으로 모든 탐색 데이터를 얻은 다음 탐색 관련 정책과 사용자 uid 및 장치 ID를 입력 매개변수로 사용하여 정책 엔진을 요청하고 탐색 API가 일치하는 정책을 반환합니다. 요구 사항을 충족하는 정책이 포함된 탐색이 데이터가 반환되므로 다양한 사용자 초상화가 다양한 탐색 데이터를 볼 수 있는 기능이 실현됩니다. 페이지, 카드, 카드 내의 데이터는 거의 동일한 방식으로 구현됩니다.
위 내용을 통해 정책 엔진의 호출 링크는 다음과 같은 특징을 가지고 있다는 것을 요약할 수 있습니다.
(1) 페이지를 여는 사용자의 한 번의 작업은 여러 정책 엔진 서비스를 연속적으로 호출합니다.
(2) 정책 엔진 인터페이스 성능은 사용자 경험에 직접적인 영향을 미칩니다. 여러 페이지 비즈니스 서비스에 대한 요청을 연결합니다.
(3) 전략 엔진 데이터는 강력한 실시간성을 요구합니다. 사용자가 멤버십을 구매한 후 즉시 회원 관련 전략과 연결되어야 합니다.
2.2 직면한 딜레마
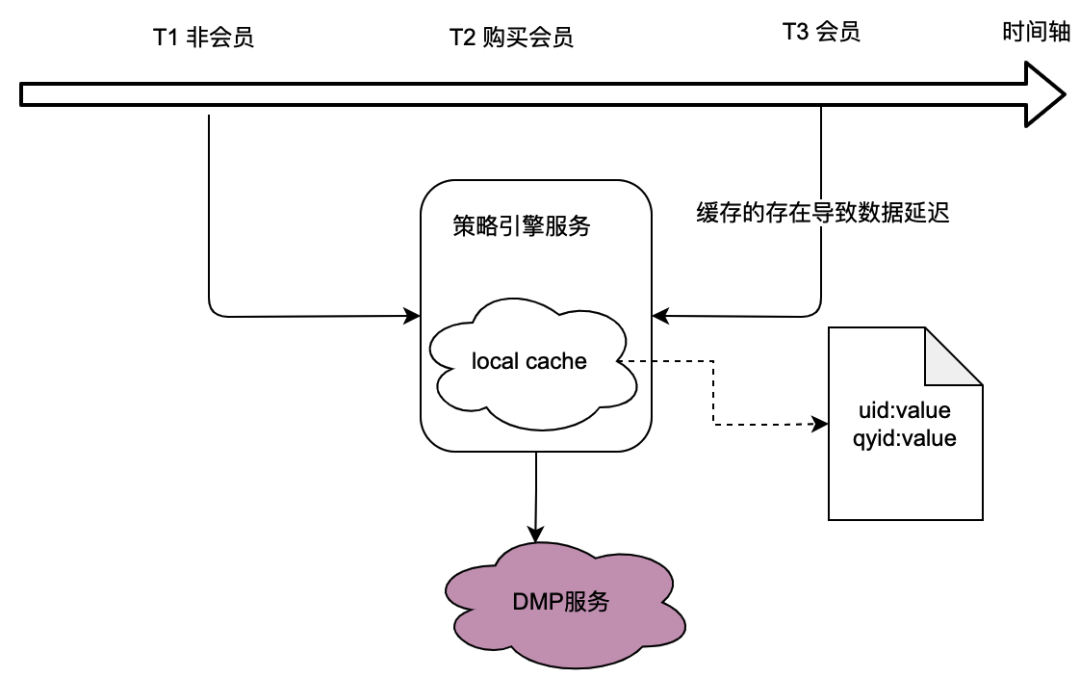
이전 섹션의 호출 관계에서 볼 수 있듯이 기본 서비스인 정책 엔진은 많은 비즈니스 당사자의 트래픽을 처리하며 정책 엔진은 군중 정책이 일치하는지 확인하기 위해 사용자 초상화 데이터를 가져와야 합니다. Turn은 DMP(데이터 관리 플랫폼) 서비스에 크게 의존합니다. DMP 서비스로의 트래픽을 줄이기 위해 로컬 캐싱 솔루션을 고려했습니다.
그러나 이에 대한 문제는 명백합니다. 즉, 실시간 데이터 요구 사항을 충족할 수 없다는 것입니다 . 사용자가 멤버십을 구매하고 DMP 서비스에서 반환하는 인물 데이터가 변경되면 로컬 캐싱 지연으로 인해 사용자가 최신 정책 관련 데이터를 볼 수 없는 것은 당연히 용납할 수 없는 일입니다.
또한 분산 캐싱 솔루션도 고려했습니다. 사용자 ID를 키로 사용하는 경우 문제점은 로컬 캐시와 동일하므로 실시간 요구 사항을 충족할 수 없습니다.
따라서 데이터의 실시간 요구 사항을 충족하면서 DMP 서비스에 대한 트래픽을 최적화하는 방법은 전체 정책 엔진 프로젝트의 최적화를 위한 과제입니다.
공유변수의 시작
1. 개요
딜레마의 핵심은 분산 서비스가 변수를 공유할 수 없다는 것입니다. 사용자의 페이지 열기 동작에는 여러 백엔드 요청이 수반되며 이러한 여러 백엔드 요청과 연결된 사용자 프로필 데이터는 실제로 하나입니다. 즉, DMP 서비스에서 얻은 프로필 데이터는 동일해야 합니다. 다음으로 정책 엔진의 호출 링크에 대한 추상 분석을 수행하여 어떤 기능을 가지고 있는지 확인합니다.
2. 정책 엔진 호출 링크 분석
정책 엔진의 호출 관계는 1.2.1 장 정책 엔진 호출 관계 소개에서 소개되었습니다. 이번에는 주로 호출 링크를 추상적으로 분류합니다.
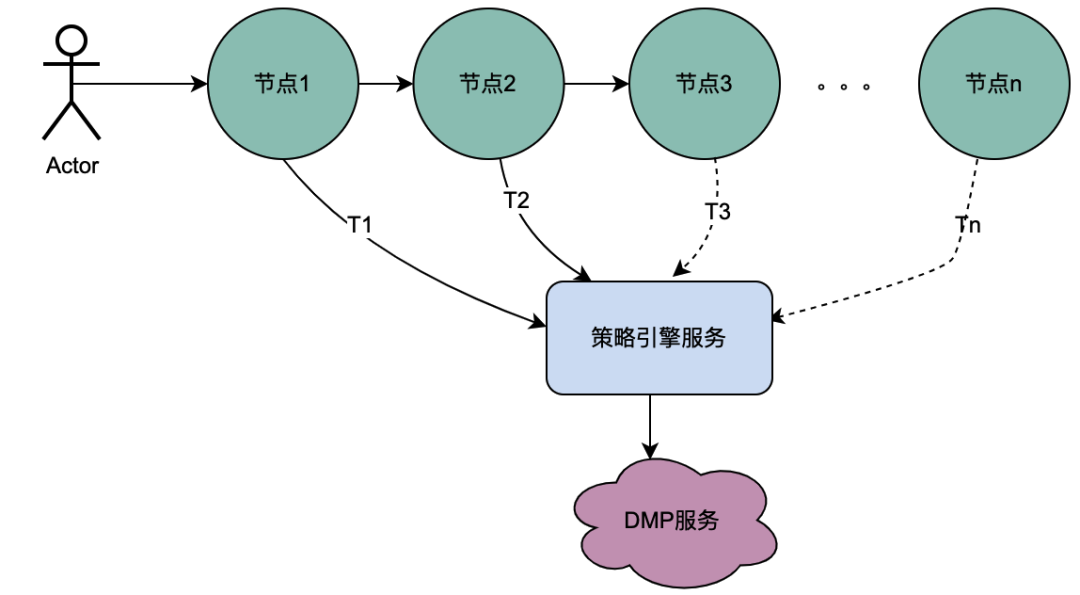
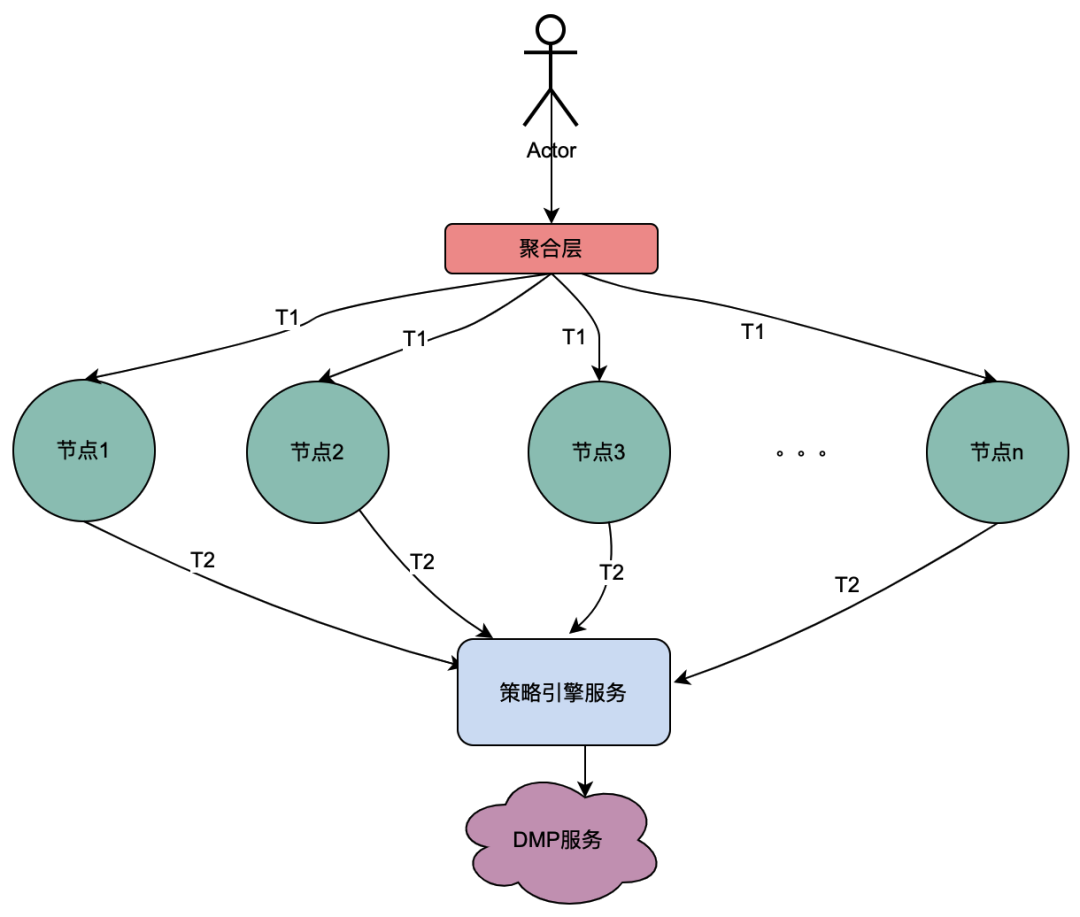
2.1 직렬 호출 시나리오
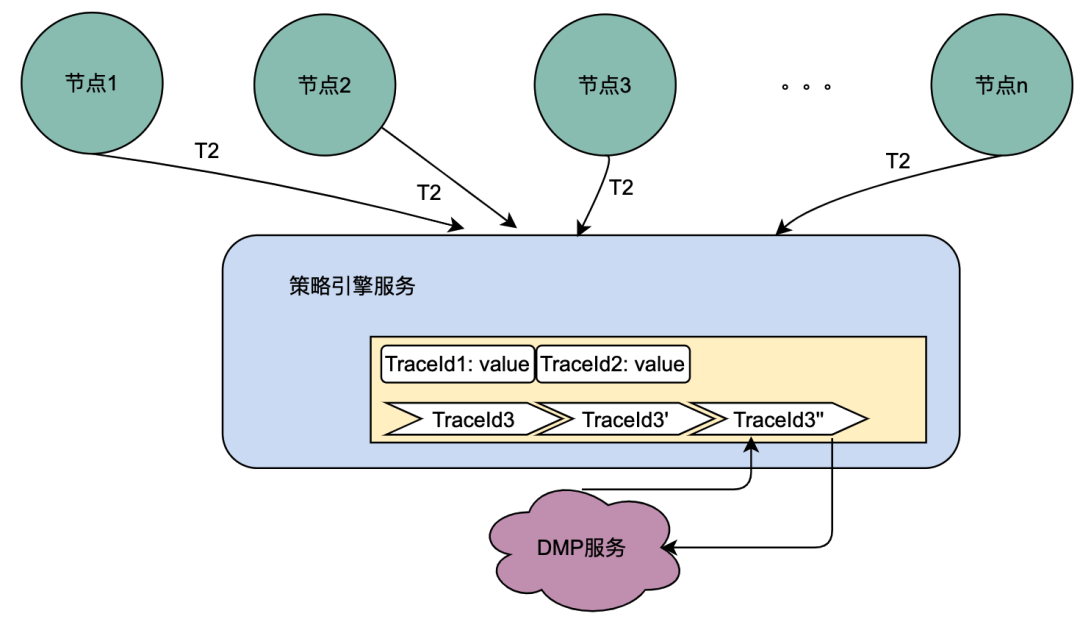
위 그림에서 볼 수 있듯이 사용자는 요청을 시작 하고 여러 노드 서비스를 통과합니다. 노드 서비스는 직렬 관계에 있으며 각 노드는 정책 엔진 서비스에 의존하여 사용자의 초상화를 얻어야 합니다. 그리고 당연히 T1에서 Tn까지의 요청은 모두 동일한 사용자로부터 발생하며 DMP 서비스에서 얻은 데이터는 동일해야 합니다. 그러면 공유 변수 개념을 사용하면 DMP에 대한 요청이 발생합니다. T1에서 Tn까지의 서비스는 1개의 요청으로 최적화될 수 있습니다. 여기서는 DMP 서비스에서 얻은 인물 데이터를 분산 공유 변수라고 명명합니다 .
2.2 병렬 호출 시나리오
위의 직렬 호출 체인과 달리 T1부터 Tn까지의 직렬 호출은 시간 순서대로 이루어지며 T1 호출은 T2 호출보다 먼저 이루어져야 합니다. 병렬 호출에는 시간 순서가 없습니다. 즉, 동일한 사용자가 요청을 시작하고 집계 계층 비즈니스가 동시에 종속 서비스에 대한 요청을 시작할 수 있으며 종속 서비스는 정책 엔진에 따라 다릅니다. 동일한 사용자가 시작한 요청은 동시에 정책 엔진에 여러 번 실행됩니다. 그런 다음 여러 요청이 대기열에 배치되고 첫 번째 요청이 실제로 DMP 서비스를 요청하고 나머지 요청이 첫 번째 요청의 데이터를 위해 대기열에서 대기하는 경우 n 요청을 1개의 요청으로 최적화할 수 있습니다. 여기서는 DMP 서비스에서 얻은 인물 데이터를 로컬 공유 변수라고 부릅니다 .
분산 공유 변수 소개
1. 원리개요
사용자가 페이지를 열면 클라이언트는 탐색을 요청한 다음 기능 페이지, 특정 카드 및 기능 카드 데이터를 차례로 가져옵니다. 모든 링크에는 정책 엔진 서비스가 포함됩니다. 일반적인 상황에서 클라이언트 요청은 정책 엔진에 대한 여러 호출을 트리거하므로 DMP 서비스에 대한 여러 호출이 발생합니다. 그러나 분명히 이것은 동일한 사용자의 요청이며 DMP 서비스에 대한 이러한 요청으로 얻은 사용자 초상화 데이터는 동일해야 합니다.
위의 분석을 바탕으로 분산 공유 변수의 원리를 간단히 설명하면 [Navigation]이 처음으로 초상화 데이터를 얻을 때 해당 내용을 요청 링크에 넣고 전체의 TraceId와 유사하게 전달한다는 것입니다. 링크. 이렇게 하면 [Page]와 같은 다운스트림이 정책 엔진에 다시 요청하면 DMP 서비스를 요청하지 않고 링크 컨텍스트 TraceContext에서 링크 데이터를 직접 얻을 수 있습니다. CARD의 경우 페이지 사업도 마찬가지다.
TraceContext는 요청을 통해서만 전달될 수 있다는 점을 언급할 가치가 있습니다. 이러한 방식으로 링크 데이터가 저장되면 [Navigation]이 정책 엔진 데이터를 얻은 후에만 초상화 데이터가 링크 컨텍스트 TraceContext에 배치될 수 있습니다.
如果导航没有关联策略数据,无需请求策略引擎,但是后面的页面、CARD等又关联了策略引擎,那该怎么处理呢?我们参考了TraceId的处理方式,在每个调用策略引擎服务的节点(不同业务如页面、CARD等)进行判断是否有链路数据,如果没有,则获取策略引擎数据后放置进去,如果有则忽略。这样就保证最前置的节点拿到画像数据后,进行向后传递,减少后续节点对于DMP服务的流量。很明显,这些逻辑有一些业务侵入性,所以我们将调用策略引擎的方式优化为SDK调用,在SDK内部做了一些统一的逻辑处理,让业务调用方无感知。
2、全链路追踪 — 基于SkyWalking
skywalking 是分布式系统的应用程序性能监视工具,专为微服务、云原生架构和基于容器化技术(docker、K8s、Mesos)架构而设计,它是一款优秀的 APM(Application Performance Management)工具。skywalking 是观察性分析平台和应用性能管理系统。提供分布式追踪、服务网格遥测分析、度量聚合和可视化一体化解决方案。对于为什么选择skywalking,除去skywalking本身的优势以外,业务上的理由是爱奇艺海外项目目前已经接入SkyWalking,开发成本最低,维护更加便利。所以,使用skywalking传递分布式共享变量只需要引入一个Maven依赖,调用其特有的方法,就可以将数据进行链路传递。
分布式共享变量的方案会增加网络传递数据的大小,增加网络开销;当链路数据足够大的时候甚至会影响服务响应性能。因此控制链路数据大小、链路数据的控制和评估链路数据对网络性能造成影响是尤为重要的。下面将详细介绍。
3、链路传输优化 — 压缩解压缩
3.1 压缩基本原理
目前用处最为广泛的压缩算法包括Gzip等大多是基于DEFLATE,而DEFLATE 是同时使用了 LZ77 算法与哈夫曼编码(Huffman Coding)的一种无损数据压缩算法。其中 LZ77 算法是先通过前向缓冲区预读取数据,然后再向滑动窗口移入(滑动窗口有一定的长度), 不断寻找能与字典中短语匹配的最长短语,然后通过标记符标记,依次来缩短字符串的长度。哈夫曼编码主要是用较短的编码代替较常用的字母,用较长的编码代替较少用的字母,从而减少了文本的总长度,其较少的编码通常使用构造二叉树来实现。
3.2 压缩选型
由于BI获取的用户画像TAG固定且个数较少,因此这里选择DMP数据作为实验对比数据。以下是不同场景下压缩大小对比数据

方案3得到的数据最小,因此选择方案3作为分布式共享变量的压缩方案。
4、数据大小导致的网络消耗分析和极端情况控制
4.1 背景概述
这种方案也存在一些弊端,即需要把用户画像数据通过网络传递,显然这增加了网络开销。理论上,网络数据量与传输速度成正比,但是在工程实践中,带宽肯定是有上限的,因此,对于DMP画像数据存入大小进行压测试验,以确定分布式共享变量对于网络性能的影响。
4.2 压测方案
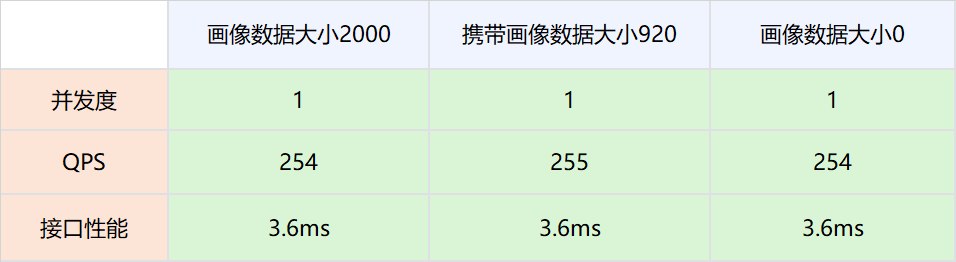
1.测试网络,画像数据不被策略引擎使用,策略引擎依然请求DMP服务。
实验组是请求策略引擎服务的时候带入压缩后的画像数据,对照组是请求策略引擎服务的时候不带入压缩后的画像数据。调整并发值,比较在不同QPS场景下两者的接口性能。
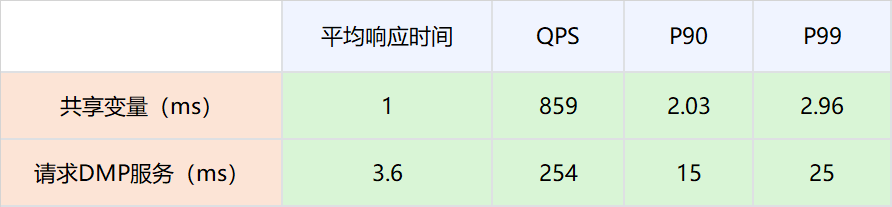
2.分布式共享变量的画像数据被策略引擎使用,策略引擎在有分布式共享变量画像数据的时候,不再请求DMP服务。
4.3结论
-
网络链路上存放数据大小在2000以下,对网络性能的影响可以忽略不计。
-
因为分布式共享变量的存在而减少对DMP服务的请求,接口性能可以有比较大的提升。具体数值为P99从25ms提升到2.96ms。
4.4 极端情况控制
因为DMP数据与用户行为相关,比如一个用户在海外站点所有站点都有购买会员的行为,那么其DMP画像数据就会很大。为了防止这种极端情况所以在判断压缩后的用户画像数据足够大的时候,将自动舍弃,而不是放入网络当中,防止大数据对整个网路数据的性能损耗。
5、线上运行情况
5.1 性能优化
|
|
|
|
|
|
|
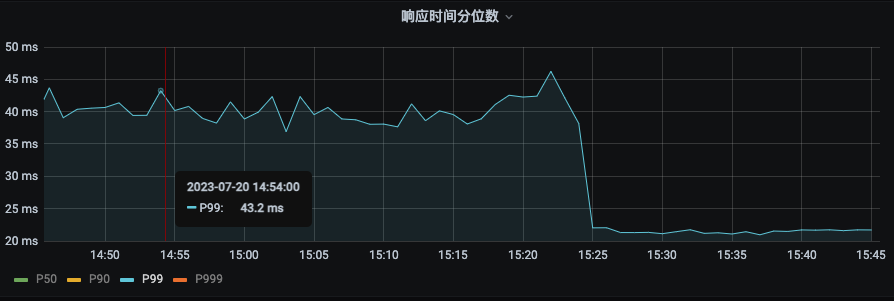
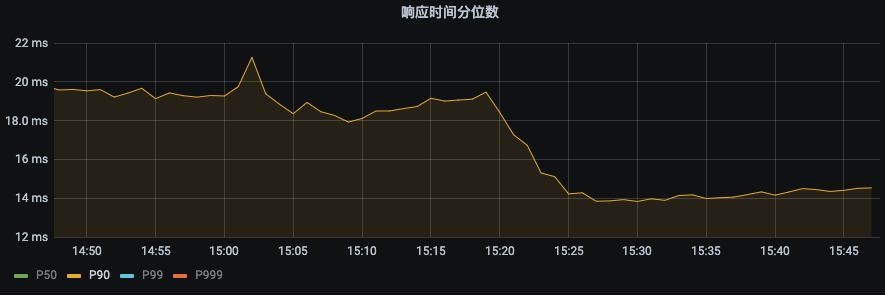
P99 由之前的43ms下降到22ms。下降幅度 48.8%
|
P90由之前19ms下降到14ms,下降幅度26.3%
|
5.2 对DMP服务的流量优化
|
|
|
|
|
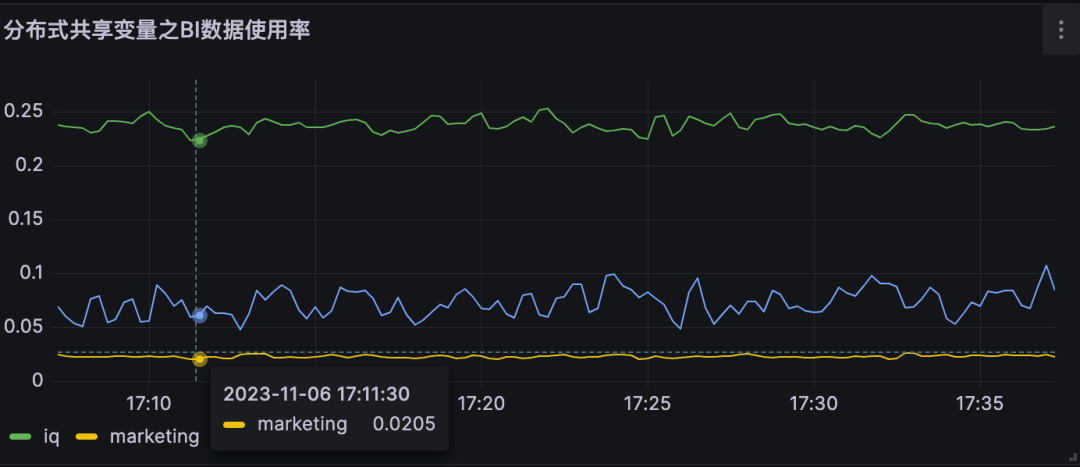
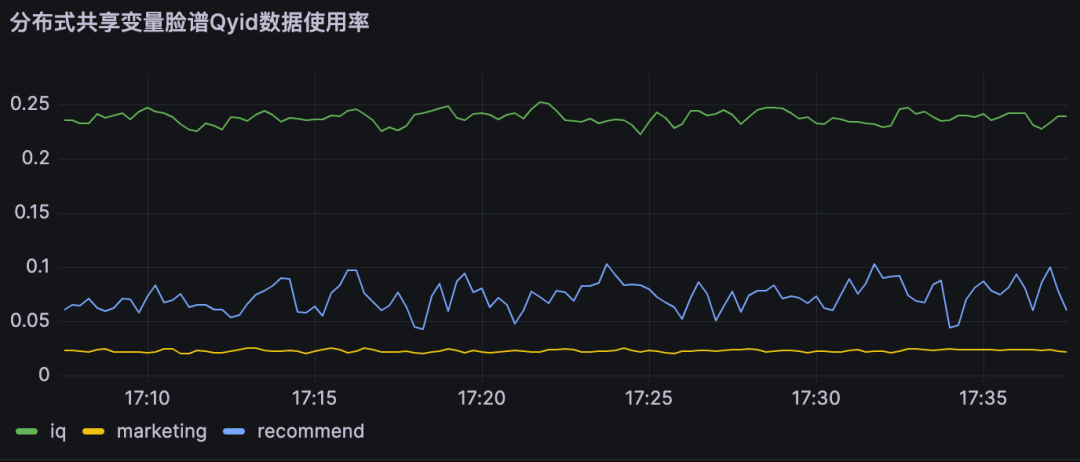
分布式共享变量使用率即为对不同DMP服务优化流量。
A业务节约大约25%的流量,B业务节约约10% 的流量,
|
|
|
|
|
6、结论
分布式共享变量在满足数据实时性要求的前提下,减少了对DMP服务的流量,同时提高了策略引擎服务的接口性能,具体优化指标见上节。
本地共享变量介绍
1、原理概述
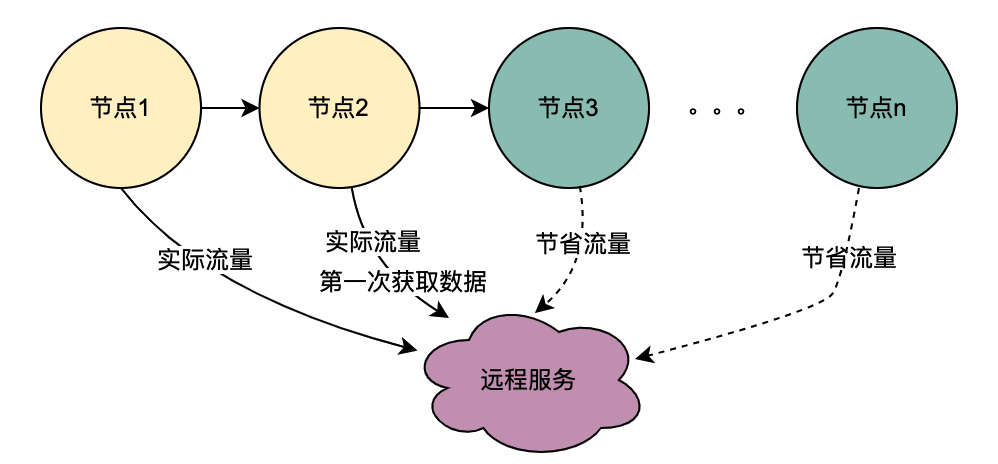
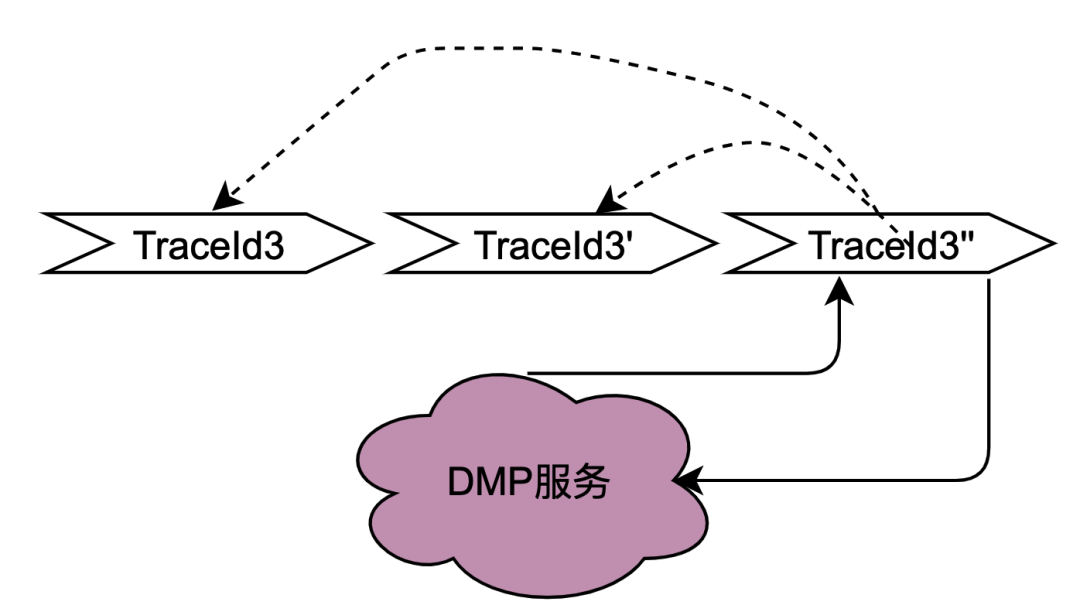
在2.2.2 并行调用场景章节对本地共享变量解决的调用场景进行了阐述,主要解决的是同一个用户并发请求策略引擎带来的多次请求DMP服务问题。如何区分是同一个用户的同一次请求呢?答案是TraceId。在一个请求下,TraceId一定是相同的,如果TraceId相同,那么策略引擎则可以认为是同一个用户的一次请求。
如上图,如果同时多个TraceId3的请求到达策略引擎,将这些请求放入队列,只要其中一个去获取用户画像数据(此处为TraceId3''),其余的请求TraceId3和TraceId3'在队列中等待TraceId3''的结果拿来用即可。
这种思路可以很好的优化并发请求的数据,符合策略引擎调用特性。实现起来有点类似AQS,开发落地有一些难点,比如Trace3''什么时候去请求DMP服务,当拿到数据后,后面仍然有其他trace3进来该如何处理,等待多少时间?这么一思考,这个组件的实现将会耗费我们很多的开发时长,那么有没有现成的中间件可以用呢?答案是本地缓存框架。
无论是本地缓存Caffeine 还是Guava Cache,有相同key的多个请求,只有一个key会请求下游服务,而其他请求会等待拿现成的结果。另外存放的时间可以通过配置缓存的失效时间来确定,至于失效时间的计算方法,将在下面章节会介绍。
2、网关层Hash路由方式的支持
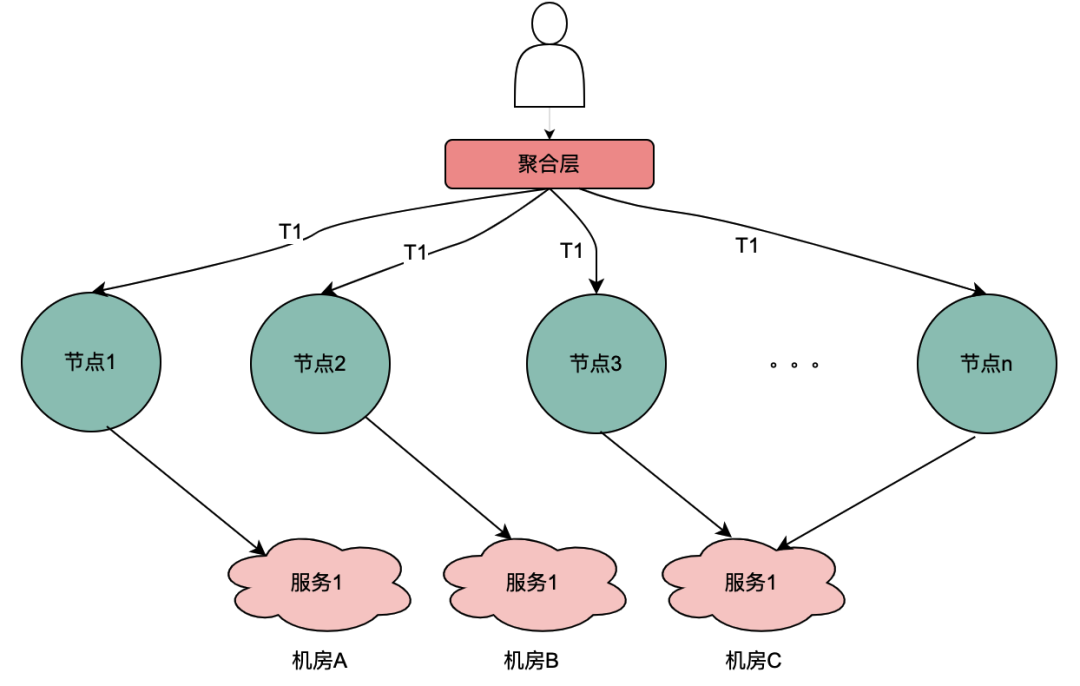
目前,主流的服务一般都是多机房多机器部署,这样有水平扩展能力可以应对业务增长带来的流量增加的问题。但同一个用户的同一个请求,很可能到不同的服务实例,这样上一次获取到的本地缓存数据在下一次请求当中就无法获取。
如上图,同一个用户的同一次请求,被聚合层并发请求到不同业务节点1到节点n。由于策略引擎服务是多实例部署,那么不同节点的请求可能到不同实例,那么本地共享变量的命中率就会大大降低,对DMP服务的流量节约数据就会小很多。因此,需要一个方案使得用户的多次请求能到同一个机房的同一个实例。
最终落地的方案是网关支持按照业务自定义字段Hash路由。策略引擎使用qyid进行hash路由,即同一个设备的所有请求到策略引擎服务,那么路由到的机器实例一定是同一个。这样可以很好的提升本地共享变量的命中率。这里提一下,相比轮询请求,字段Hash方式存在如流量偏移的问题,需要配合服务实例流量的监控和报警,避免某些实例流量过多而导致不可用。由于和本次主题无关,实例流量的监控和报警在这里就不做介绍。
3、本地共享变量个数和有效时间设计
和本地缓存不同,本地共享变量的最大个数和过期时间与命中率不成正比,这和具体业务指标相关。
假设策略引擎服务QPS10000,服务实例有50台,那么每台实例的QPS是200,即一台服务实例每秒的请求是200个。只需要保证,同一个TraceId的一批请求,在个数区间内不被淘汰,在时间区间内不被过期即可。我们通过网关日志查找历史上同一个traceId的请求时间戳,几乎都在100ms内。
那么过期时间设置为1s,最大个数设置为200个就可以保证绝大多数同一个TraceId的批次请求,只有一个请求下游服务,其余从缓存获取数据。我们为此也进行了实验,设置不同的过期时间和缓存最大个数,结论和以上分析完全一致。
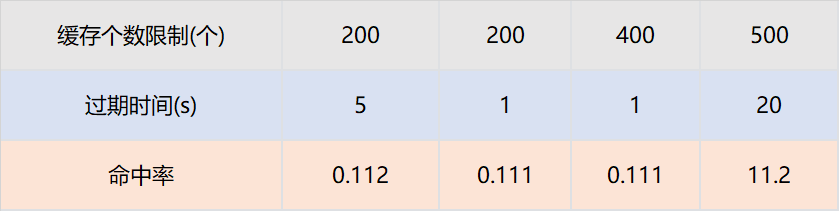
本地共享变量命中率与接口QPS和相同TraceId并发时间相关。
4、结论
-
对于DMP服务1,优化流量15.8%。对于DMP服务2,优化流量 16.7%。对于DMP服务3,优化流量16.2%。
-
与分布式共享变量一样,本地共享变量同样可以满足数据实时性要求,即不会存在1.2.2 遇到的困境 所遇到的缓存导致的数据实时性不够的问题。
总结和展望
本次优化是比较典型的技术创新项目。是先从社区看到一篇技术博客,然后想到爱奇艺海外遇到相同痛点问题的的项目,从而提出优化因为微服务导致的策略引擎对于DMP服务流量压力的目标。
在落地过程中,遇到使用本地缓存进行优化而无法克服数据实效性问题的挑战。最终沉下心分析策略引擎的调用链路,将调用链路一分为二:串行调用和并行调用,最终提出了共享变量的解决方案。因为串行调用和并行调用的特点迥异,依次针对两者进行分期优化,其中第一期通过分布式共享变量优化了串行调用DMP服务的流量,在第二期通过本地共享变量优化了并行调用DMP服务的流量。
参考文章:

也许你还想看
低代码、中台化:爱奇艺号微服务工作流实践
揭秘内存暴涨:解决大模型分布式训练OOM纪实
分布式系统日志打印优化方案的探索与实践
本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
출처my.oschina.net/u/4484233/blog/10924140