
저자|Cheng Wei, MetaAPP 빅데이터 R&D 엔지니어
ByConity는 ByteDance의 오픈 소스 클라우드 기반 데이터 웨어하우스로 탄력적인 리소스 확장 및 축소, 읽기-쓰기 분리, 리소스 격리, 강력한 데이터 일관성 등에 대한 데이터 웨어하우스 사용자의 요구 사항을 충족하는 동시에 탁월한 쿼리, 쓰기 성능도 제공합니다.
MetaApp은 중국의 선도적인 게임 개발 및 운영업체로, 모바일 정보의 효율적인 배포에 중점을 두고 모든 연령대를 위한 가상 세계를 구축하는 데 전념하고 있습니다. 2023년 기준으로 MetaApp의 등록 사용자 수는 2억 명이 넘고, 20만 개 이상의 게임을 협업했으며, 누적 배포량은 10억 개가 넘습니다.
MetaApp은 오픈소스 초기에 ByConity에 주목했으며 이를 프로덕션 환경에서 테스트하고 출시한 최초의 사용자 중 하나였습니다. MetaApp 빅데이터 R&D팀은 오픈소스 데이터 웨어하우스 프로젝트의 역량을 이해한다는 아이디어로 ByConity에 대한 사전 테스트를 진행했습니다. 스토리지-계산 분리 아키텍처와 뛰어난 성능, 특히 로그 분석 시나리오에서의 뛰어난 성능, 대규모 데이터에 대한 복잡한 쿼리 지원, MetaApp을 유치하여 ByConity에 대한 심층 테스트를 수행했으며 결국 프로덕션 환경에서 ClickHouse를 완전히 대체하여 리소스 비용을 절감했습니다 . 50% 이상.
본 글에서는 주로 MetaApp 데이터 분석 플랫폼의 기능, 비즈니스 시나리오에서 직면하는 문제와 해결 방법, ByConity를 비즈니스에 도입하는 데 도움이 되는 내용을 소개합니다.
MetaApp OLAP 데이터 분석 플랫폼 아키텍처 및 기능
비즈니스가 성장하고 정교한 운영이 도입됨에 따라 제품은 실시간 데이터를 쿼리 및 분석하고 소규모 그룹에 대한 AB 실험을 수행하여 운영 전략을 신속하게 조정해야 하는 필요성을 포함하여 데이터 부서에 대한 더 높은 요구 사항을 제시했습니다. 새로운 기능의 유효성 검증 데이터 조회 시간과 난이도를 줄여 비전문가도 독립적으로 데이터를 분석하고 탐색할 수 있습니다. MateApp은 비즈니스 요구 사항을 충족하기 위해 이벤트 분석, 전환 분석, 사용자 정의 유지, 사용자 그룹화, 행동 흐름 분석 및 기타 기능을 통합하는 OLAP 데이터 분석 플랫폼을 구현했습니다 .
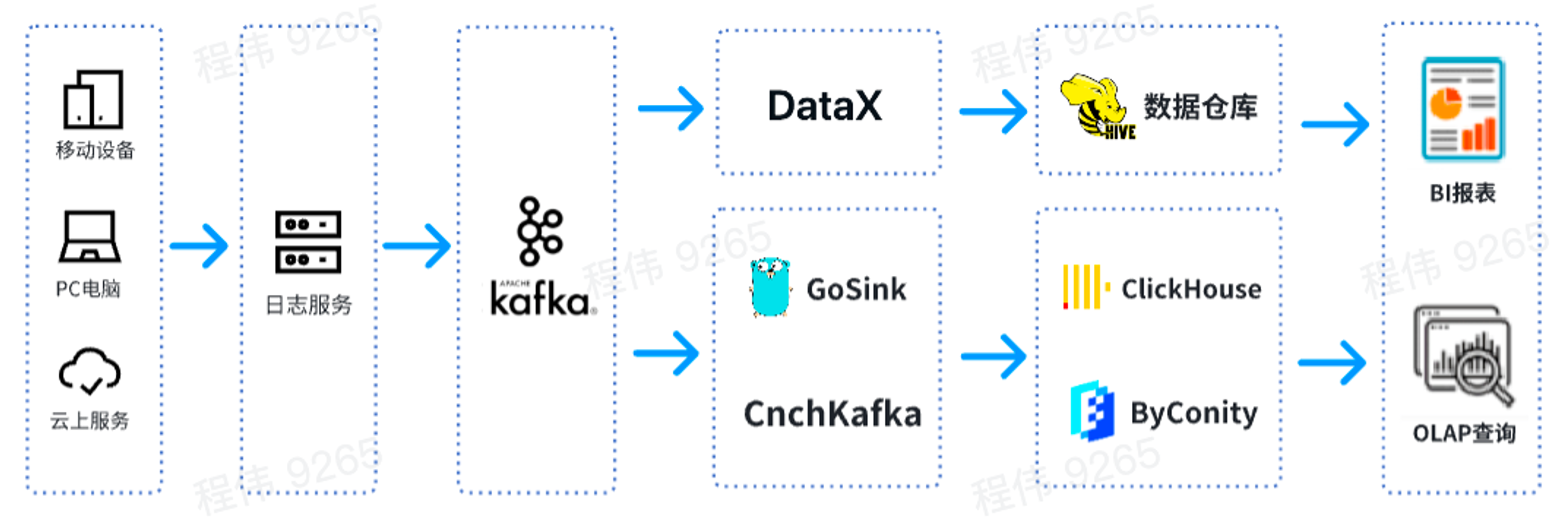
이는 일반적인 OLAP 아키텍처로 두 부분으로 나누어져 있습니다. 하나는 오프라인이고 다른 하나는 실시간입니다.
오프라인 시나리오 에서는 DataX를 사용하여 Kafka 데이터를 Hive 데이터 웨어하우스에 통합한 다음 BI 보고서를 생성합니다. BI 보고서는 Superset 구성 요소를 사용하여 결과를 표시합니다.
실시간 시나리오 에서 한 라인은 데이터 통합을 위해 GoSink를 사용하고 GoSink 데이터를 ClickHouse에 통합하고, 다른 라인은 CnchKafka를 사용하여 데이터를 ByConity에 통합합니다. 마지막으로 쿼리를 위해 OLAP 쿼리 플랫폼을 통해 데이터를 얻습니다.
ByConity와 ClickHouse의 기능 비교
ByConity 는 ClickHouse 코어를 기반으로 개발된 오픈 소스 클라우드 네이티브 데이터 웨어하우스이며 스토리지-계산 분리 아키텍처를 채택합니다. 둘 다 다음과 같은 특징을 가지고 있습니다.
- 쓰기 속도는 매우 빠르고, 대량의 데이터 쓰기에 적합하며, 쓰기 데이터 양은 50MB - 200MB/s에 달할 수 있습니다.
- 쿼리 속도는 매우 빠릅니다. 대용량 데이터의 경우 쿼리 속도는 2~30GB/s에 도달할 수 있습니다.
- 높은 데이터 압축률, 낮은 저장 비용, 압축률은 0.2~0.3에 도달할 수 있습니다.
ByConity는 ClickHouse의 장점을 가지고 있으며 ClickHouse와의 좋은 호환성을 유지하며 읽기-쓰기 분리, 탄력적인 확장 및 축소 , 강력한 데이터 일관성 측면에서 향상되었습니다 . 둘 다 다음 OLAP 시나리오에 적용 가능합니다.
- 데이터세트는 수십억 또는 수조 행에 달할 정도로 클 수 있습니다.
- 데이터 테이블에 많은 열이 포함되어 있습니다.
- 특정 열만 쿼리
- 결과는 밀리초 또는 초 단위로 반환되어야 합니다.
이전 공유에서 ByConity 커뮤니티는 [사용 관점에서] 두 가지를 비교했습니다.
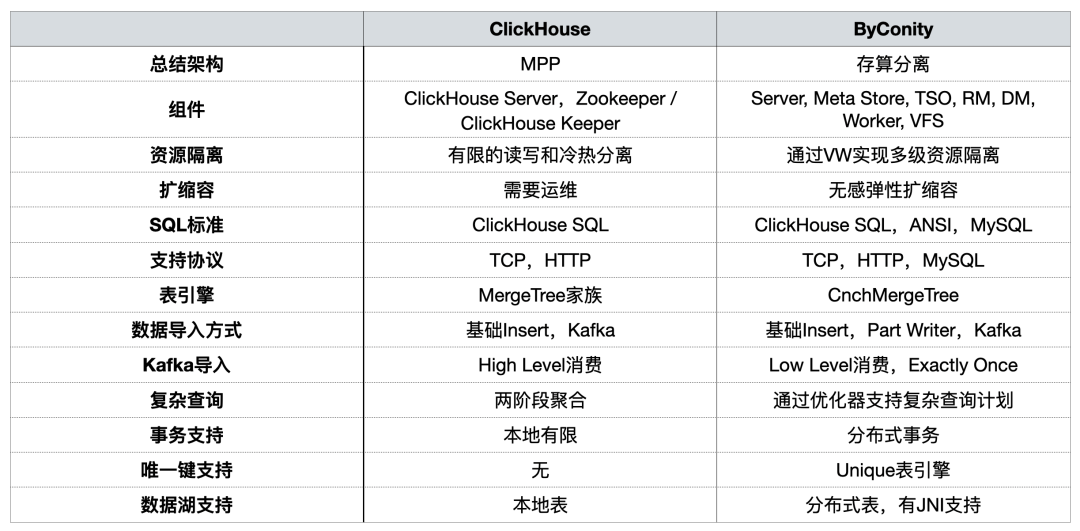
OLAP 플랫폼 을 구축하는 동안 우리는 주로 리소스 격리, 용량 확장 및 축소 , 복잡한 쿼리 및 분산 트랜잭션 지원 에 중점을 두었습니다 .
ClickHouse를 사용할 때 발생하는 문제
문제 1: 읽기 및 쓰기 통합은 리소스를 쉽게 점유할 수 있으며 안정적인 읽기/쓰기를 보장할 수 없습니다.
업무량이 많은 기간에는 데이터 쓰기가 많은 양의 IO 및 CPU 리소스를 차지하므로 쿼리가 영향을 받게 됩니다(쿼리 시간이 길어집니다). 데이터 쿼리도 마찬가지입니다.
문제 2: 확장/축소가 번거롭고 시간이 오래 걸린다
- 긴 확장/축소 시간: 머신이 IDC에 있고 프라이빗 클라우드에 속하기 때문에 노드 추가 주기가 매우 길다는 것이 문제 중 하나입니다. 노드 수요가 발행된 시점부터 실제로 좋은 노드가 추가되기까지 1~2주가 소요되며 이는 비즈니스에 영향을 미칩니다.
- 빠르게 확장 및 축소할 수 없음: 확장 후 데이터를 재배포해야 합니다. 그렇지 않으면 노드 압력이 매우 높아집니다.
문제 3: 운영 및 유지 관리가 번거롭고 업무량이 많은 기간에는 SLA를 보장할 수 없습니다.
- 종종 비즈니스 노드 오류로 인해 데이터 쿼리가 느려지고 데이터 쓰기가 지연됩니다(몇 시간에서 며칠까지).
- 비즈니스 피크 기간에는 리소스 부족이 심각하여 단기간에 리소스를 확장할 수 없습니다. 우선순위가 높은 서비스를 제공하기 위해 일부 서비스의 데이터를 삭제하는 방법밖에 없습니다.
- 경기가 좋지 않은 기간에는 많은 리소스가 유휴 상태가 되어 비용이 부풀려집니다. IDC에 속해 있지만 IDC 기계 구매에도 비용 통제가 적용되며 노드 확장은 무제한이 될 수 없습니다. 또한 정상적인 사용 중에 일정한 비용 소비가 있습니다.
- 클라우드 리소스와 상호 작용할 수 없습니다.
ByConity 도입 후 개선 사항
우선, 바이코니티의 읽기와 쓰기 컴퓨팅 자원을 분리함으로써 읽기와 쓰기 작업이 상대적으로 안정적으로 이루어질 수 있습니다. 읽기 작업이 충분하지 않은 경우 클라우드 리소스를 사용하여 확장하는 것을 포함하여 해당 리소스를 확장하여 부족함을 보완할 수 있습니다.
둘째, 확장 및 축소는 상대적으로 간단하며 분 단위로 수행할 수 있습니다. HDFS/S3 분산 스토리지를 사용하고 컴퓨팅과 스토리지가 분리되어 있어 확장 후 데이터 재배포가 필요하지 않고 확장 후 바로 사용할 수 있다.
또한 클라우드 네이티브 배포와 운영 및 유지 관리가 비교적 간단합니다.
- HDFS/S3의 구성 요소는 상대적으로 성숙하고 안정적이며 용량 확장 및 축소, 성숙한 재해 복구 솔루션을 갖추고 있으며 문제를 신속하게 해결할 수 있습니다.
- 피크 비즈니스 기간에는 신속한 리소스 확장을 통해 SLA를 보장할 수 있습니다.
- 업무량이 적은 기간에는 스토리지/컴퓨팅 리소스를 줄여 비용을 줄일 수 있습니다.
ByConity의 사용 및 운영
ByConity 클러스터 사용량
현재 우리 플랫폼은 비즈니스 시나리오에서 ByConity를 안정적으로 사용하고 있습니다. 잇따른 마이그레이션을 통해 ByConity는 ClickHouse 클러스터의 데이터를 완전히 인수하고 안정적으로 서비스를 제공하기 시작했습니다. 클라우드에서 S3와 K8을 사용하여 ByConity 클러스터를 구축했습니다. 또한 평일 오전 10시에 확장하고 오후 8시에 축소할 수 있는 예약 확장 및 축소 솔루션을 사용했습니다. 낮. . 계산에 따르면, 이 방법은 연간 및 월간 구독을 직접 사용하는 것과 비교하여 약 40%-50% 정도 리소스를 절감합니다. 또한 비용 절감과 서비스 안정성 향상이라는 목적을 달성하기 위해 프라이빗 클라우드 + 퍼블릭 클라우드 결합 도 추진하고 있습니다.
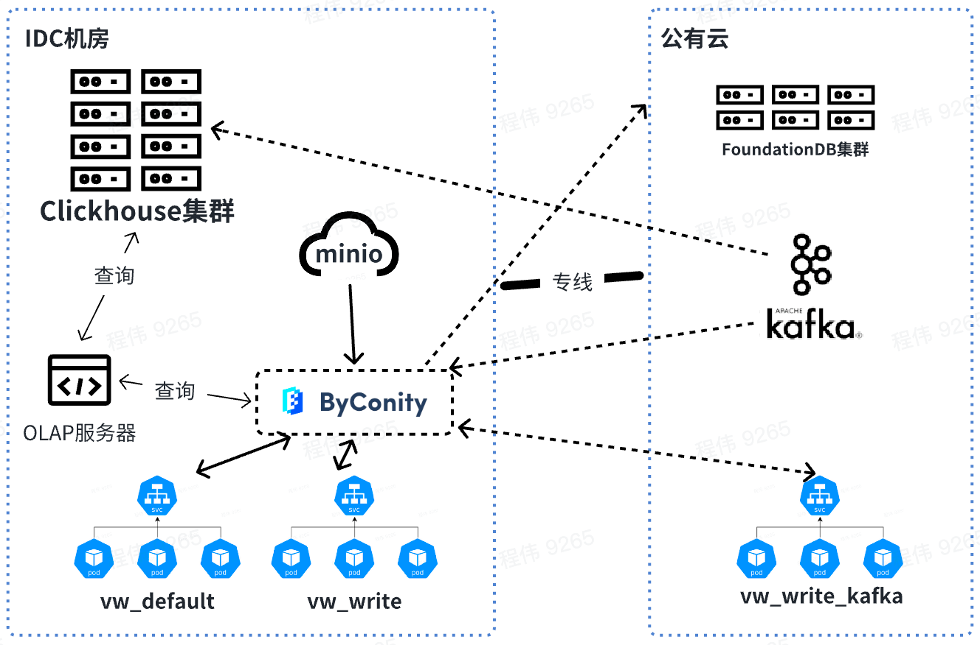
아래 그림은 OLAP 서버를 사용하여 오프라인 IDC 컴퓨터실의 ClickHouse 클러스터와 ByConity에 대한 공동 쿼리를 수행하는 현재 사용량을 보여줍니다. 단기적으로 ClickHouse 클러스터는 ClickHouse에 부분적으로 의존하는 기업을 위한 전환으로 계속 사용될 것입니다.
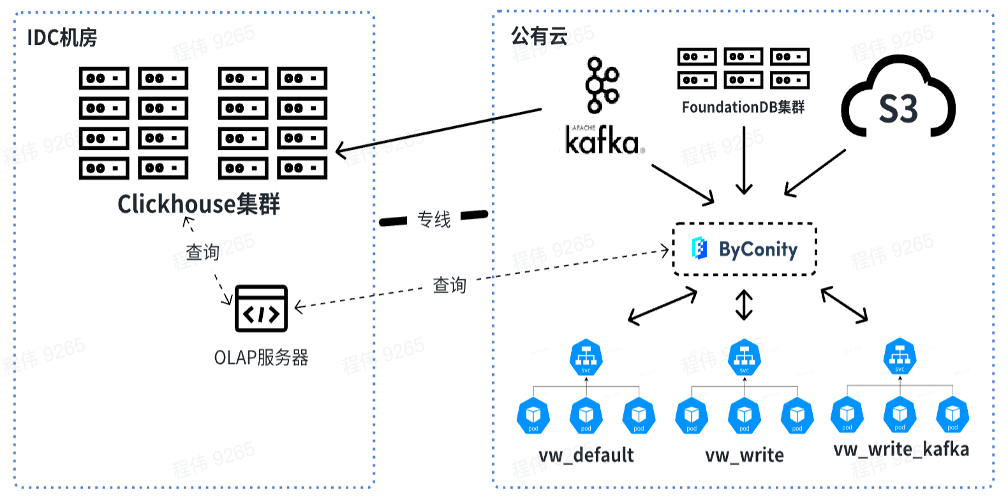
앞으로는 오프라인에서 데이터를 쿼리하고 병합하고 Kafka가 소비하는 리소스는 온라인에서 사용됩니다. 리소스 확장 시 vw_default 및 vw_write의 리소스를 온라인으로 확장하고 퍼블릭 클라우드 리소스를 합리적으로 활용하여 리소스 부족 문제를 해결할 수 있습니다. 동시에 비즈니스 피크가 낮은 기간에는 용량을 줄여 퍼블릭 클라우드 소비를 줄입니다.
비즈니스 데이터에서 ByConity와 ClickHouse 쿼리 비교
테스트 데이터 세트 및 리소스 구성
- 데이터 항목 수: 날짜별로 분할, 하루에 40억 항목, 10일 동안 총 400억 항목
- 표 형식 데이터: 열 2,800개
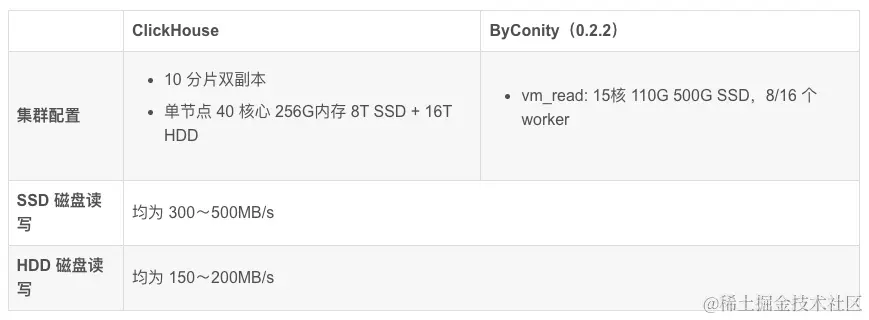
위의 표에서 볼 수 있듯이:
ClickHouse 클러스터 쿼리에 사용되는 리소스는 400개 코어 및 2560G 메모리입니다.
ByConity 8 작업자 클러스터 쿼리에 사용되는 리소스는 120개 코어 및 880G 메모리입니다.
ByConity 16 작업자 클러스터 쿼리에 사용되는 리소스는 240개 코어 및 1760G 메모리입니다.
비즈니스 SQL 쿼리 결과 요약
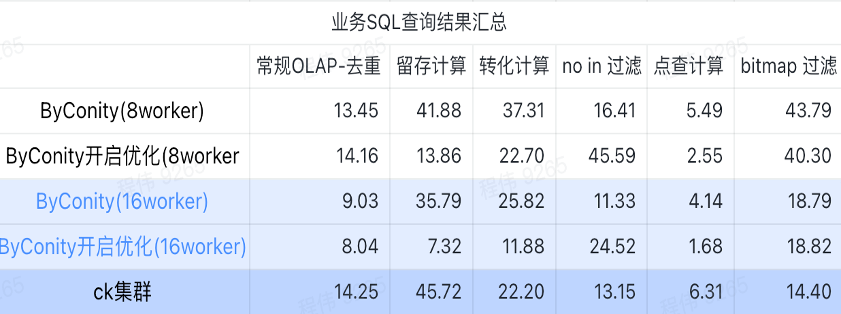
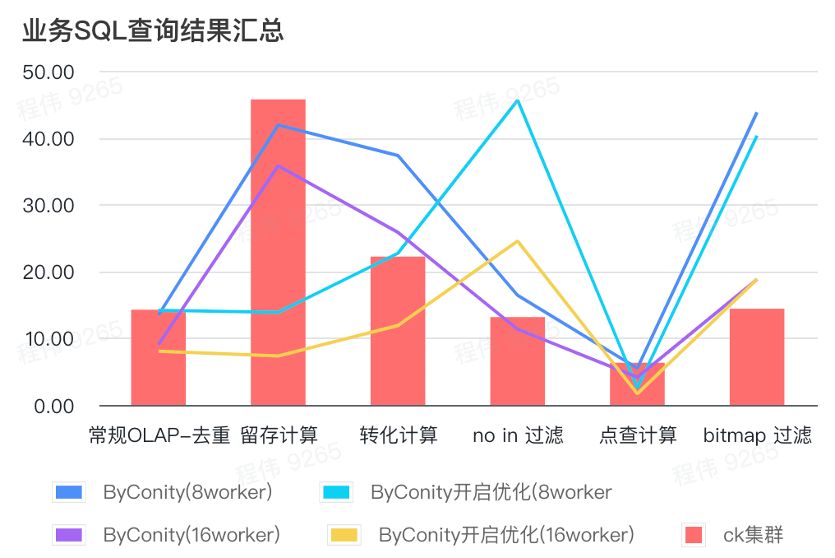
여기 요약에서는 다음과 같이 평균값을 사용합니다.
- 기존 OLAP - 중복제거, 보존, 변환, 열거는 상대적으로 적은 리소스 비용(120C, 880G)으로 ClickHouse 클러스터(400C, 2560G)와 동일한 쿼리 효과를 얻을 수 있으며, 리소스 확장(240C, 1760G)을 통해 두 배로 늘릴 수 있습니다. ) 쿼리 속도를 두 배로 늘리는 효과를 얻습니다. 더 높은 쿼리 속도가 필요한 경우 더 많은 리소스를 확장할 수 있습니다.
- 필터링이 아닌 경우 ClickHouse 클러스터(400C, 2560G)와 유사한 효과를 얻으려면 적당한 리소스 비용(240C, 1760G)이 필요할 수 있습니다.
- 비트맵은 ClickHouse 클러스터와 유사한 효과를 얻으려면 더 많은 리소스 비용이 필요할 수 있습니다.
일반 쿼리/이벤트 분석 쿼리
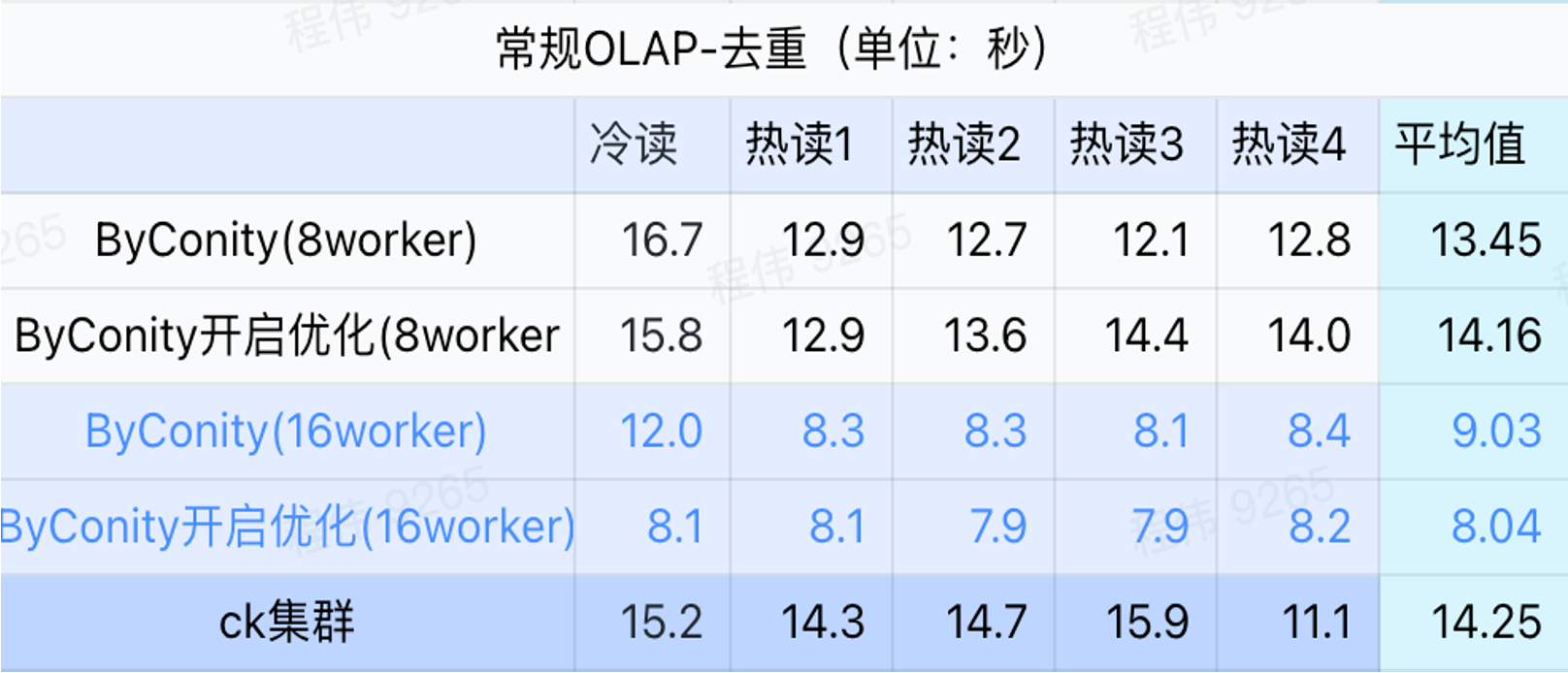
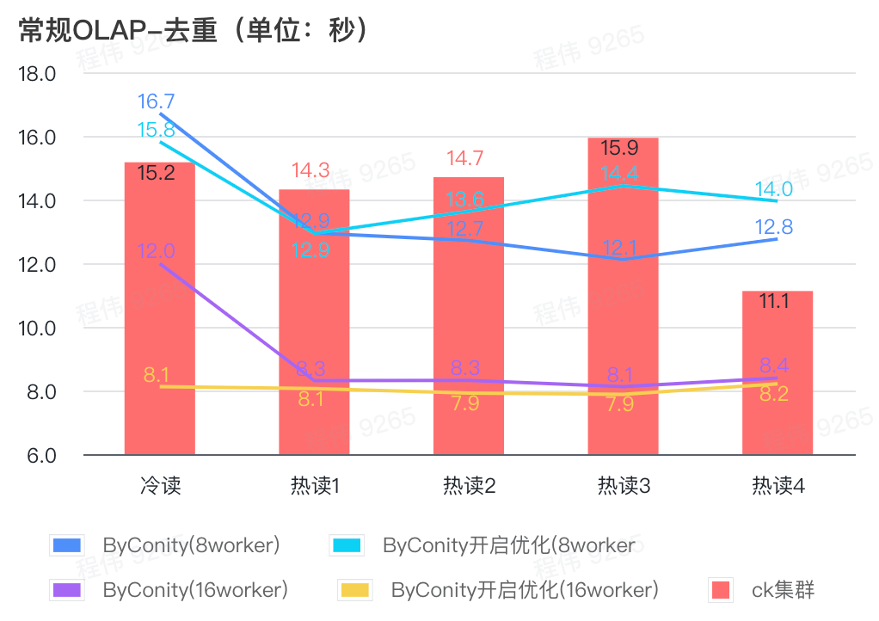
위 그림에서 볼 수 있듯이:
- 중복 제거 쿼리 시나리오에서는 ByConity 최적화를 활성화하는 것과 최적화를 활성화하지 않는 것 사이에는 큰 차이가 없습니다.
- 8명의 작업자(120C 880G)는 기본적으로 ClickHouse에 가까운 쿼리 시간을 달성합니다.
- 중복 제거 시나리오에서는 컴퓨팅 리소스를 확장하여 쿼리 속도를 가속화할 수 있습니다.
보유 계산
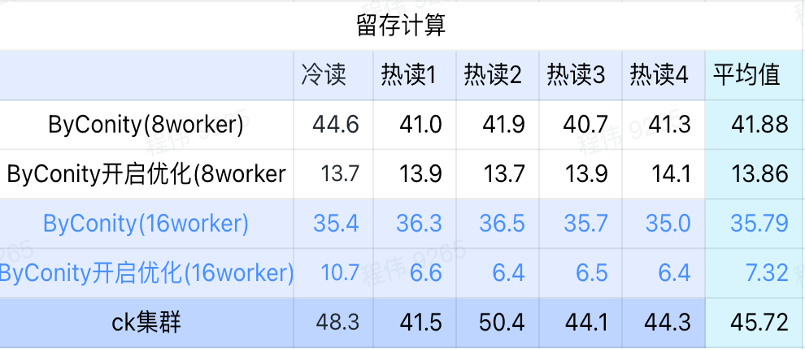
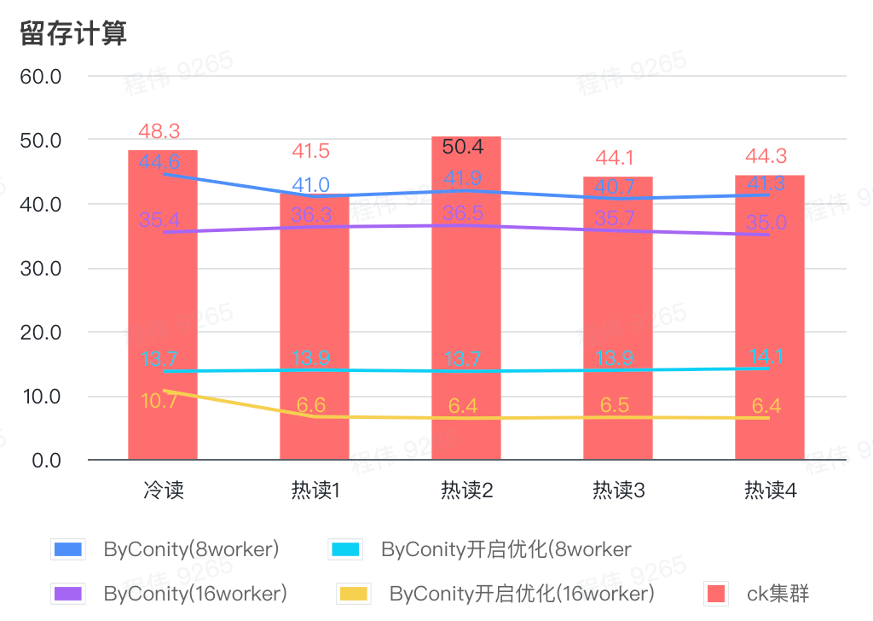
위 그림에서 볼 수 있듯이:
- 보유 컴퓨팅 시나리오에서 ByConity가 최적화를 켠 후 쿼리 시간은 최적화를 켜지 않은 쿼리 시간의 33%입니다.
- 8 작업자(120C 880G) 최적화가 켜진 쿼리 시간은 쿼리 시간의 30%입니다.
- 보유 컴퓨팅 시나리오에서는 컴퓨팅 리소스 확장 + 최적화를 통해 쿼리 속도를 CK 쿼리 시간의 16%까지 가속화할 수 있습니다.
전환 계산
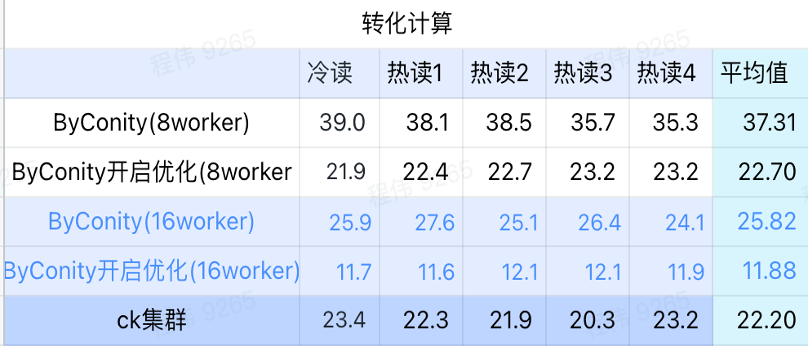
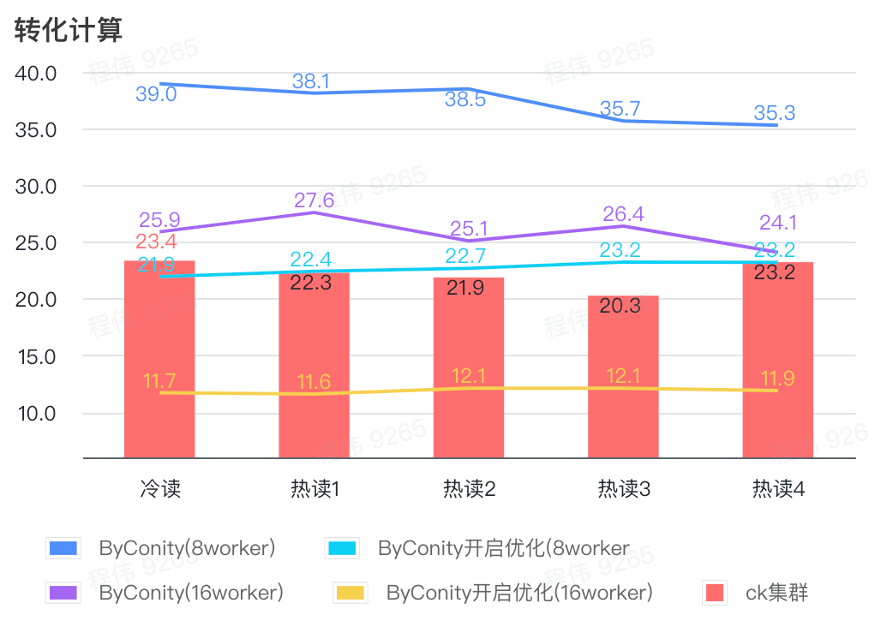
위 그림에서 볼 수 있듯이:
- 전환 계산 시나리오에서 최적화를 위해 ByConity를 활성화한 후 쿼리 시간은 최적화되지 않은 쿼리 시간의 60%입니다.
- 최적화가 활성화된 작업자 8명(120C 880G)의 쿼리 시간은 ClickHouse 쿼리 시간에 가깝습니다.
- 컴퓨팅 시나리오를 변환하면 컴퓨팅 리소스 + 최적화를 확장하여 쿼리 속도를 ClickHouse 쿼리 시간의 53%까지 가속화할 수 있습니다.
필터에 없음
필터링에 포함되지 않음은 주로 사용자 그룹화 시나리오 및 사용자 태그 지정 시나리오에 사용됩니다.

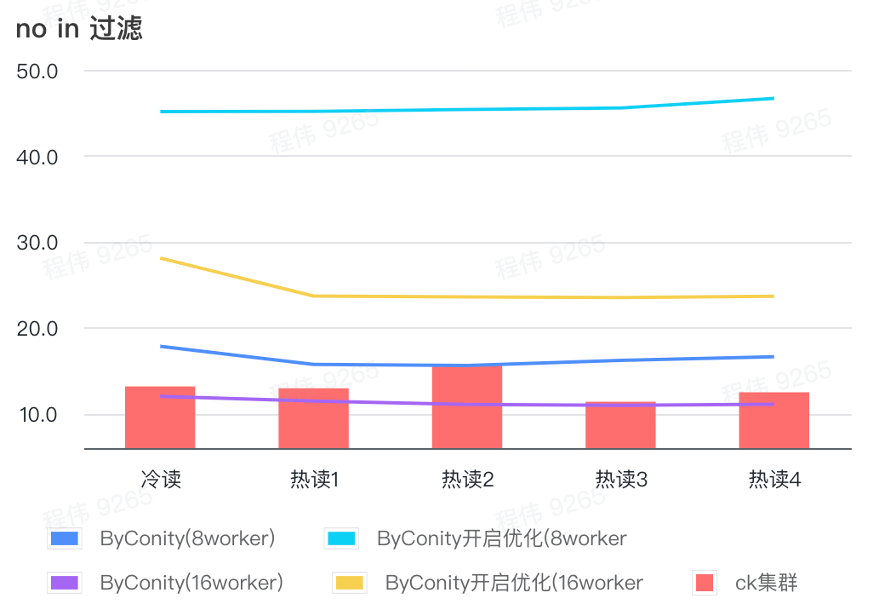
위 그림에서 볼 수 있듯이:
- 필터링이 없는 시나리오에서는 최적화가 켜진 ByConity가 최적화가 켜지지 않은 ByConity보다 나쁘기 때문에 이 시나리오에서는 최적화를 켜지 않는 방법을 직접 사용합니다.
- 최적화되지 않은 8 작업자(120C 880G) 쿼리 시간은 ClickHouse 쿼리 시간보다 느리지만 많지는 않습니다.
- 필터링 시나리오에서는 컴퓨팅 리소스를 확장하여 쿼리 속도를 ClickHouse 쿼리 시간의 86%까지 가속화할 수 있습니다.
클릭 계산 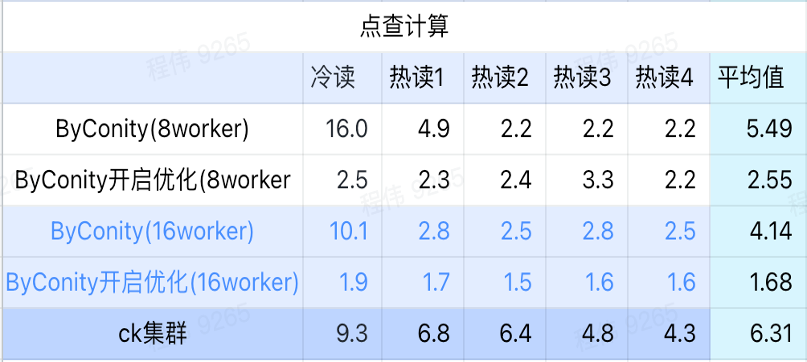
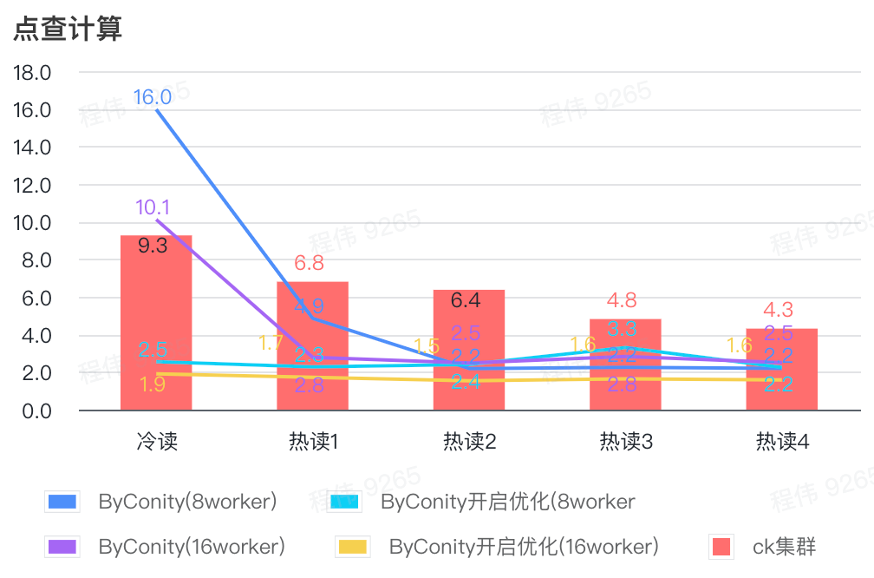
위 그림에서 볼 수 있듯이:
- 장면을 확인한 후 ByConity를 켜고 최적화하는 것이 ByConity를 켜지 않는 것보다 낫습니다.
- 최적화되지 않은 8명의 작업자(120C 880G)의 쿼리 시간은 ClickHouse 쿼리 시간에 가깝습니다.
- 클릭스루 시나리오에서는 컴퓨팅 리소스를 확장하고 최적화를 켜면 쿼리 속도가 ClickHouse 쿼리 시간의 26%까지 가속화될 수 있습니다.
비트맵 쿼리
비트맵 쿼리는 AB 테스트에서 더 많이 사용되는 시나리오입니다.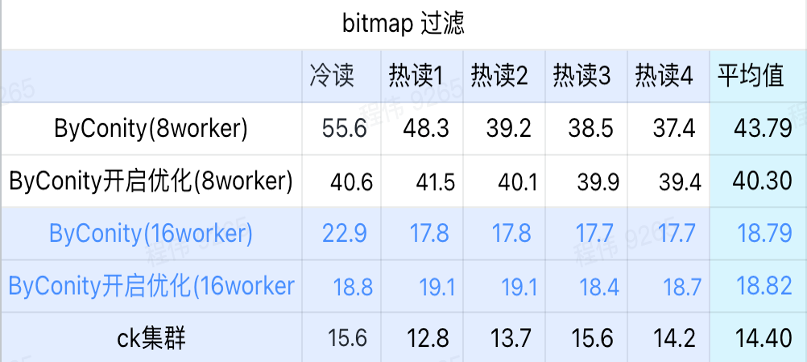
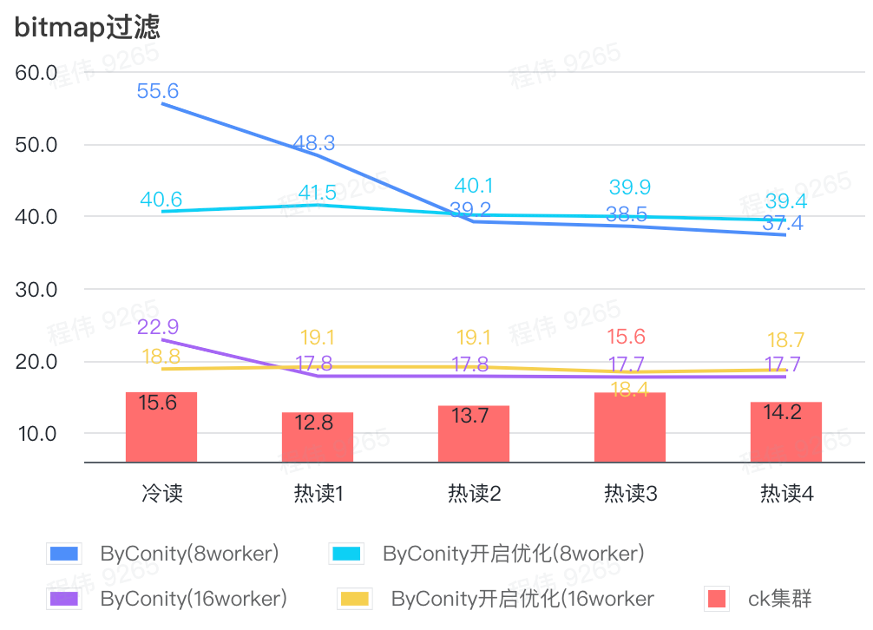
위 그림에서 볼 수 있듯이:
- 비트맵 필터링 장면에서는 ByConity 최적화를 사용하지 않는 것보다 ByConity 최적화를 켜는 것이 더 좋습니다.
- 최적화되지 않은 8 작업자(120C 880G) 쿼리 시간은 ClickHouse 쿼리 시간보다 훨씬 느립니다.
- 리소스를 16개 작업자(240C 1769G)로 확장하는 비트맵 필터링 장면은 ClickHouse 쿼리보다 느립니다.
ByConity 전체 마이그레이션 후 이익
자원 감소
다음은 CPU의 차이를 계산하지 않은 것이며, 데이터는 참고용일 뿐입니다.
ByConity를 사용하여 전체 마이그레이션 후
- 쿼리와 병합 리소스 소모를 비교하면 CPU 소모가 이전 대비 약 75% 감소한 것으로 나타났습니다.
- 데이터 쓰기 리소스를 비교하면 CPU 소모가 이전보다 약 35% 감소합니다.
- 고정 자원의 절반만 구매하면 되며, 나머지 절반은 근무일(오전 10시~오후 8시)의 유연성에 따라 자원 전체 구매에 비해 비용이 약 25% 절감됩니다.
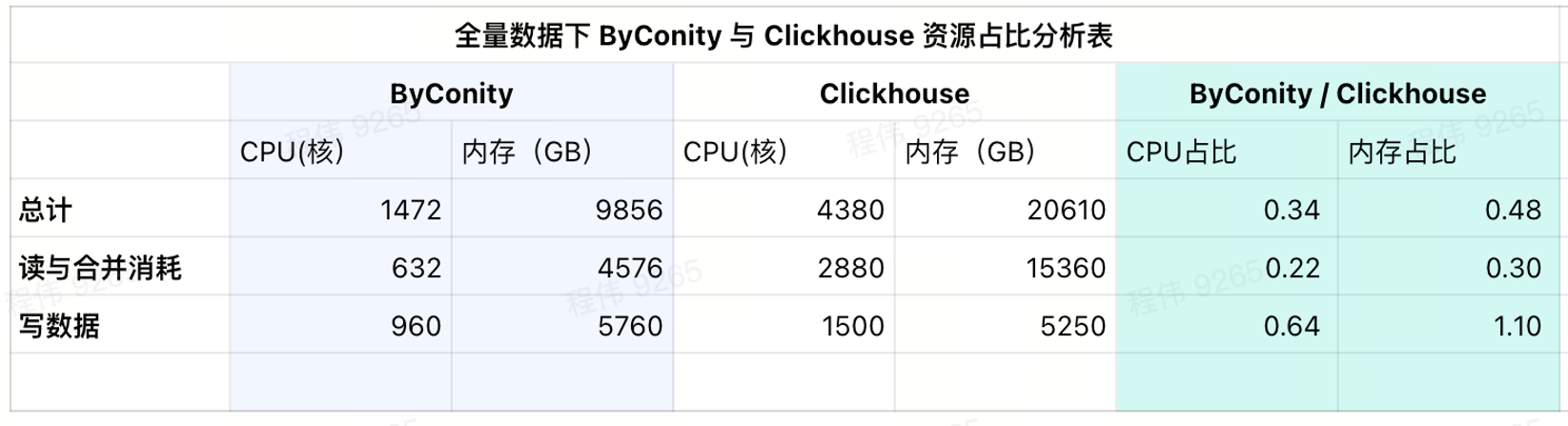
현재 사용량 소비
현재 결과표에서 볼 수 있듯이 바이코니티의 CPU 비율과 메모리 비율은 클릭하우스 대비 각각 34%, 48% 수준이다.
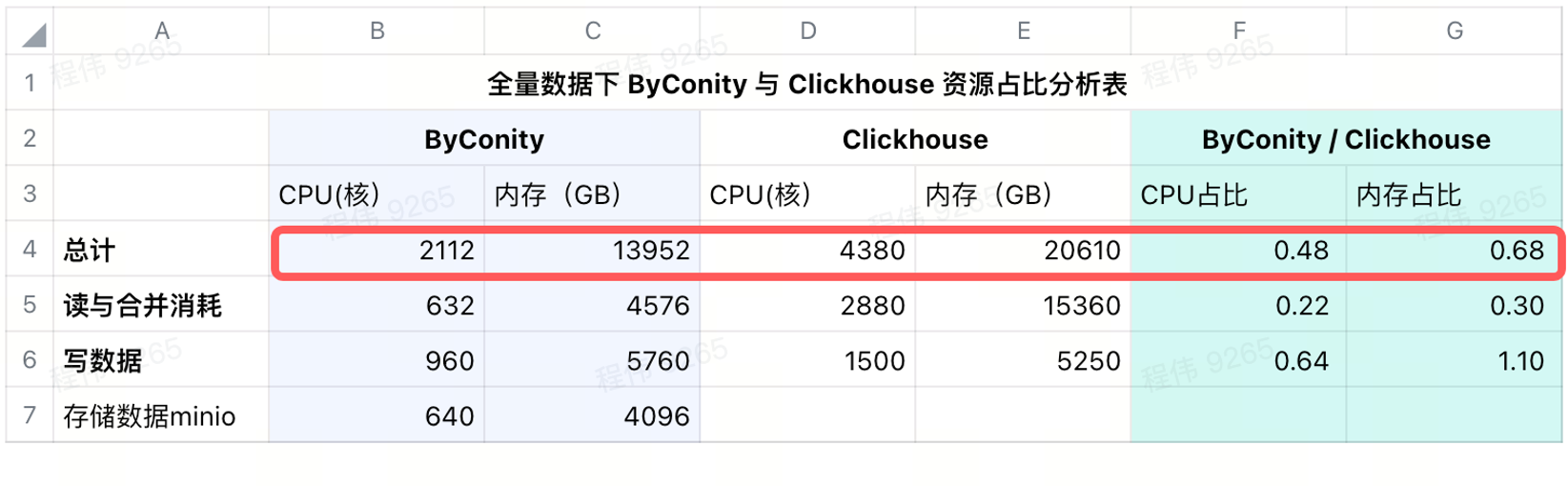
원격 스토리지 추가 후 소비
IDC의 데이터 저장용으로 minio를 사용하고 있으며, 640코어 CPU, 4096G 메모리, 16노드, 40코어 단일 노드, 256G, 36T 디스크를 사용하고 있습니다. 이러한 비용을 ByConity에 추가한 후에도 ByConity의 CPU 및 메모리 비율은 여전히 그렇습니다. ClickHouse보다 각각 48%, 68% 더 낮습니다. 리소스 사용량 측면에서 연간 및 월별 기준으로 계산하면 ByConity는 수요에 따라 시작 및 중지되면 비용이 약 25% 절감된다고 할 수 있습니다. 자원 전체를 구매하는 것과 비교됩니다 .
운영 및 유지관리 비용 절감
- 구성 데이터를 작성하는 더 쉬운 방법. 기존에 저희가 특별히 구성한 쓰기 서비스는 부품이 너무 많은 등의 문제가 자주 발생했습니다.
- 피크 쿼리 확장이 더 쉽습니다. Pod 수만 추가하면 빠르게 용량을 확장할 수 있습니다. "왜 30분 동안 확인했는데 데이터가 나오지 않습니까?"라고 묻는 사람은 없습니다.
ClickHouse를 ByConity로 교체하기 위한 제안
- 귀하의 기업 내 ByConity 플랫폼에서 SQL이 정상적으로 실행되는지 테스트해 보세요. 호환되면 기본적으로 실행됩니다. 개별 사례에 사소한 문제가 있는 경우 커뮤니티에 문제를 제기하여 빠른 피드백을 받을 수 있습니다.
- 테스트 클러스터의 리소스를 제어하고, 데이터 세트 크기를 테스트하고, ByConity 클러스터와 ClickHouse 클러스터의 쿼리 결과를 비교하여 기대에 부합하는지 확인합니다. 예상되는 경우 교체를 계획할 수 있습니다. 계산에 더 집중된 작업의 경우 ByConity가 더 나은 성능을 발휘할 수 있습니다.
- 테스트 데이터 세트의 크기, 소비된 S3 및 HDF 공간, 대역폭, QPS 컴퓨팅 리소스 사용량을 기반으로 전체 데이터 양의 저장 및 컴퓨팅에 필요한 리소스가 평가됩니다.
- ByConity 또는 ClickHouse 클러스터에 동시에 데이터를 입력하고 일정 시간 동안 듀얼 런닝을 시작하여 듀얼 러닝 중에 발생하는 문제를 해결합니다. 예를 들어 우리 회사의 자원이 부족할 경우 업무에 맞게 먼저 ByConity 클러스터를 구축하고 업무의 특정 부분으로 이동한 후 업무에 맞춰 점진적으로 교체할 수 있습니다. IDC 리소스는 이러한 데이터의 일부를 오프라인으로 마이그레이션할 수 있습니다.
- 이중 실행에 문제가 없으면 ClickHouse 클러스터 구독을 취소할 수 있습니다.
이 프로세스 중에는 몇 가지 고려 사항이 있습니다.
- S3 및 HDFS 원격 스토리지의 읽기 대역폭과 QPS는 더 높을 수 있으며 특정 준비가 필요합니다. 예를 들어 초당 최대 읽기 및 쓰기 대역폭은 쓰기 2.5GB/읽기 6GB이고 초당 최대 QPS는 2~6k입니다.
- 작업자 노드의 대역폭이 가득 차면 쿼리 병목 현상도 발생합니다.
- 기본 노드(즉, 읽기 컴퓨팅 노드)의 캐시 디스크를 적절하게 더 크게 구성할 수 있으므로 쿼리 중 S3의 대역폭 압력을 줄이고 쿼리 속도를 높일 수 있습니다.
- 캐시되지 않은 데이터가 발견되면 콜드 스타트 문제가 발생할 수 있습니다. ByConity는 이에 대한 몇 가지 운영 제안도 있는데, 이는 자체 비즈니스와 더욱 통합되어야 합니다. 예를 들어, 콜드 스타트 문제의 이 부분을 완화하기 위해 아침에 사전 확인을 사용합니다.
향후 계획
앞으로는 ByConity 데이터 레이크 솔루션의 테스트 및 구현을 추진할 예정입니다. 또한 데이터 지표 관리와 데이터 웨어하우스 이론을 결합하여 쿼리의 80%가 데이터 웨어하우스에 속하도록 할 것입니다. 누구나 체험에 참여할 수 있습니다.
GitHub |https://github.com/ByConity/ByConity

ByConity Assistant를 추가하려면 QR 코드를 스캔하세요.
동료 치킨 "오픈 소스" deepin-IDE 및 마침내 부트스트랩을 달성했습니다! 좋은 친구, Tencent는 Switch를 "생각하는 학습 기계"로 전환했습니다. Tencent Cloud의 4월 8일 실패 검토 및 상황 설명 RustDesk 원격 데스크톱 시작 재구성 웹 클라이언트 WeChat의 SQLite 기반 오픈 소스 터미널 데이터베이스 WCDB의 주요 업그레이드 TIOBE 4월 목록: PHP 사상 최저치로 떨어졌고 FFmpeg의 아버지인 Fabrice Bellard는 오디오 압축 도구인 TSAC를 출시했으며 Google은 대규모 코드 모델인 CodeGemma를 출시했습니다 . 오픈소스라서 너무 좋아요 - 오픈소스 사진 및 포스터 편집기 도구