
지난 2024년 봄 컨퍼런스에서 Kangaroo Cloud는 데이터 스택 제품의 V6.2 버전 의 새로운 릴리스를 출시했습니다. 그 중 데이터 스택 V6.2의 핵심 기능인 EasyMR은 빅데이터 생태계에 대한 캥거루클라우드의 심층적인 이해와 지속적인 혁신을 상징한다.
EasyMR (이하 EMR로 통칭)은 Hadoop, Hive, Spark, Flink, HBase 등의 오픈 소스 구성 요소를 기반으로 Kangaroo Cloud가 구축한 탄력적 컴퓨팅 엔진 으로, 안전하고 안정적이며 탄력적으로 확장 가능하며 저렴한 비용으로 빅 데이터를 제공합니다. 데이터 저장 및 컴퓨팅 서비스 . 이 중 자체 개발한 EasyManager 기업급 빅데이터 운영 및 유지 관리 플랫폼은 Hadoop 클러스터의 생성, 관리, 배포, 운영 및 유지 관리, 모니터링 기능을 원스톱으로 지원하여 효율적인 데이터 센터 솔루션을 제공합니다.
기업의 증가하는 데이터 처리 및 분석 요구에 직면하여 EMR6.2 버전은 사용자에게 더 나은 빅 데이터 운영 및 유지 관리 서비스와 컴퓨팅 성능 최적화를 제공할 것입니다. 다음은 사용자가 이 혁신적인 제품을 완전히 이해할 수 있도록 EMR6.2 버전의 4가지 주요 기능 최적화에 대한 자세한 소개입니다.
완전히 새로워지고 업그레이드된 UI: 간단하고 편안한 대화형 경험
Kangaroo Cloud는 사용자 경험의 중요성을 이해하고 있으므로 EMR6.2 버전에서는 UI 인터페이스를 포괄적으로 새로 고치고 업그레이드했습니다. 새로운 인터페이스 디자인은 사용자에게 직관적이고 편안한 대화형 경험을 제공하는 것을 목표로 단순하면서도 우아한 스타일을 따릅니다. 초보자든 숙련된 사용자든 복잡한 빅 데이터 클러스터를 빠르게 시작하고 쉽게 관리할 수 있습니다.
또한 사용자가 클러스터 운영 및 유지 관리 중에 보다 원활한 운영 경험을 즐길 수 있도록 인터페이스의 응답 속도와 운영 유창성을 최적화했습니다.
차별화된 구성: 다양한 요구 충족
EMR6.2 버전에는 인스턴스 그룹 차별화 구성 기능이 도입되어 사용자가 특정 요구 사항에 따라 클러스터 구성을 맞춤 설정할 수 있습니다. 사용자는 EMR 클러스터의 여러 노드에서 독립적인 인스턴스 그룹을 구축 하고 인스턴스 그룹에 특정 구성 매개변수를 설정하여 더 나은 성능, 리소스 활용도 및 작업 예약을 달성할 수 있습니다.
비용에 민감한 스타트업이든 더 높은 성능 요구 사항이 있는 대기업이든 EMR6.2는 다양한 사용자의 요구 사항을 충족할 수 있는 유연한 구성 옵션을 제공할 수 있습니다.
인스턴스 그룹에 대해 차별화된 구성 전략을 구현하면 다음과 같은 구체적인 이점이 있지만 이에 국한되지는 않습니다.
● 자원 할당
차별화된 구성은 컴퓨팅, 스토리지, 네트워크 리소스 등 여러 수준을 포괄하는 다양한 작업의 고유한 요구 사항에 따라 세분화된 리소스 할당을 효과적으로 구현할 수 있습니다. 클러스터의 모든 작업이 적절한 리소스에 의해 지원되도록 리소스 낭비를 방지하고 리소스 활용도를 향상시킵니다.
●작업 스케줄링 최적화
다양한 유형의 작업 또는 작업의 경우 특성에 따라 다양한 구성 매개변수를 설정하여 작업 예약 및 실행 효율성을 최적화할 수 있습니다.
● 내결함성 및 안정성
차별화된 구성을 통해 클러스터의 내결함성과 안정성을 향상시킬 수 있습니다. 노드나 인스턴스 그룹의 중요도와 부하에 따라 다양한 내결함성 메커니즘 과 결함 처리 전략을 설정하여 비정상적인 상황에서도 클러스터가 안정적인 작동을 유지할 수 있도록 할 수 있습니다.
● 비용 관리
차별화된 구성은 비용 관리에도 도움이 될 수 있습니다. 비즈니스 요구 사항과 예산 제약에 따라 클러스터의 다양한 인스턴스 그룹을 합리적으로 구성하여 리소스 낭비를 방지하고 운영 및 유지 관리 비용을 줄이며 성능과 비용 간의 균형을 찾을 수 있습니다.
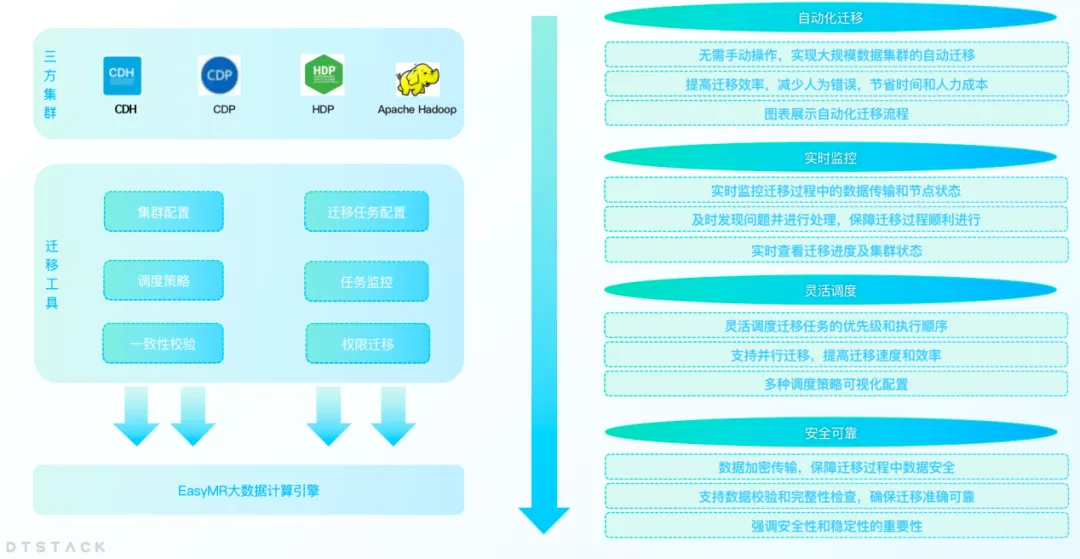
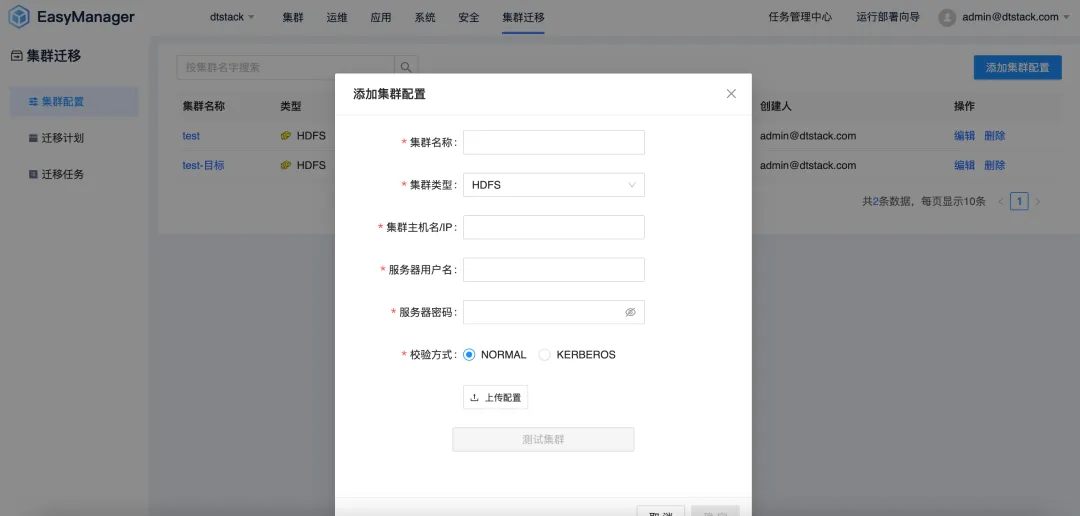
클러스터 마이그레이션: 업무 중단 없이 원활한 전환
기업의 비즈니스가 발전함에 따라 데이터 양이 증가하면 데이터 센터 용량 부족이나 데이터 센터 변경과 같은 문제가 발생하는 경우가 많습니다. 동시에, 현지화 대체의 맥락에서 CDH, HDP, CDP와 같은 비혁신 플랫폼을 현지화된 빅데이터 플랫폼으로 마이그레이션하는 기업이 점점 더 많아지고 있습니다. 따라서 EMR은 기업이 데이터 센터 마이그레이션을 효율적으로 완료할 수 있도록 빅 데이터 클러스터 마이그레이션 기능을 출시했습니다 .
클러스터 마이그레이션 기능을 사용 하면 사용자는 데이터 손실이나 비즈니스 중단에 대한 걱정 없이 서로 다른 데이터 센터 또는 클라우드 서비스 간에 빅 데이터 클러스터를 원활하게 마이그레이션할 수 있습니다. 이 기능을 통해 기업은 변화하는 시장 요구에 맞춰 IT 인프라를 보다 유연하게 조정할 수 있습니다.
엔진 업그레이드 공개: 성능 도약, 새로운 경험
가장 흥미로운 점은 EMR6.2 버전이 컴퓨팅 엔진 성능 에서 획기적인 발전을 이루었다는 것 입니다. 기존 Spark 및 Flink 컴퓨팅 엔진을 최적화했을 뿐만 아니라 데이터 처리 속도와 컴퓨팅 효율성을 향상시키기 위한 새로운 알고리즘과 기술을 도입했습니다. 이는 사용자가 더 복잡한 데이터 분석 작업을 더 짧은 시간에 완료할 수 있어 의사결정 속도가 빨라지고 기업 경쟁력이 향상된다는 의미다.
● Spark3는 Z 순서 색인 최적화를 지원합니다.
Z - Order는 다차원 데이터를 하나의 차원으로 압축할 수 있는 기술입니다. 데이터 조각의 경우 여러 필드를 데이터의 여러 차원으로 정렬하여 다차원 데이터를 매핑할 수 있습니다. 1차원 데이터.
구체적으로 z값은 일정한 규칙을 통해 구성되는데 , 이때 z값은 1차원 데이터를 기준으로 정렬할 수 있습니다. 아래 그림과 같이:
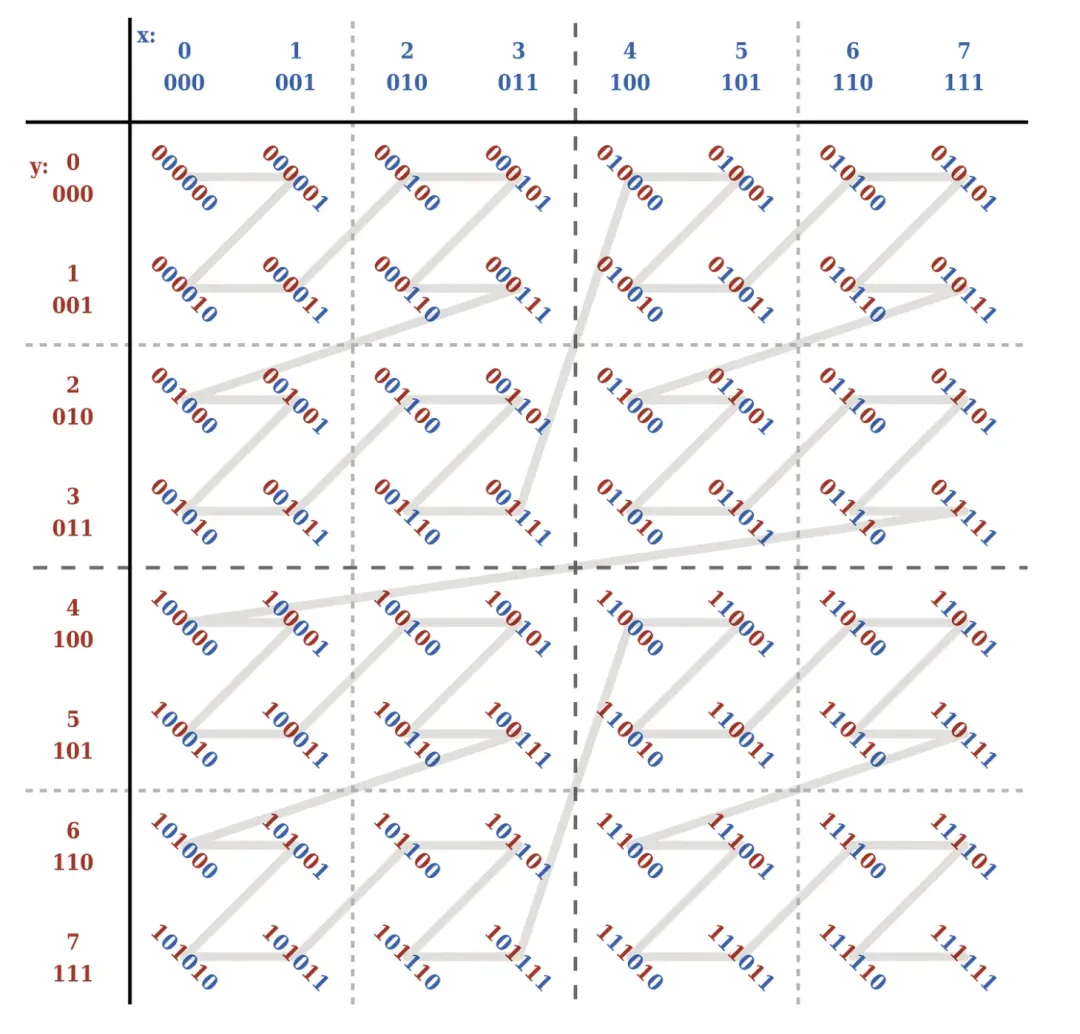
Spark SQL에서 Kangaroo Cloud는 Z-Order 인덱스를 지원하는 OPTIMIZE XX ZORDER BY 구문을 추가하여 INSERT INTO 테이블, INSERT OVERWRITE 테이블, CREATE TABLE 테이블 AS SELECT, DISTINCT 및 기타 SQL의 Z-Order 인덱스 최적화를 실현했습니다.
Spark3는 Z 순서 최적화를 지원하여 데이터 처리 및 쿼리 효율성을 크게 향상시키고 IO 오버헤드를 줄이며 작업 실행을 가속화합니다. 특히 대규모 데이터 세트와 복잡한 쿼리 작업을 처리해야 하는 시나리오에서는 Z 순서 최적화가 중요한 역할을 할 수 있습니다. 파일 압축률 문제를 해결하면서 Z 순서 최적화를 사용한 후 파일 압축률이 수동 최적화에 비해 약 20% 증가했으며, 오픈 소스 Spark3에 비해 약 10배 증가했습니다. 작업 성능도 거의 30% 향상되어 오프라인 작업의 성능과 효율성이 크게 향상되었습니다.
● Flink 작업별 작업 핫 업데이트
실제 생산 작업에서는 실시간 작업 매개 변수 변경 이나 작업자 및 기능 조정이 자주 발생합니다. 일반적으로 현재 작업을 먼저 취소한 다음 CheckPoint를 선택하여 복원하거나 다시 실행하는 데 약 3~5분 정도 소요됩니다. 잠깐만요. 작업 개발 시간이 너무 낭비되는군요.
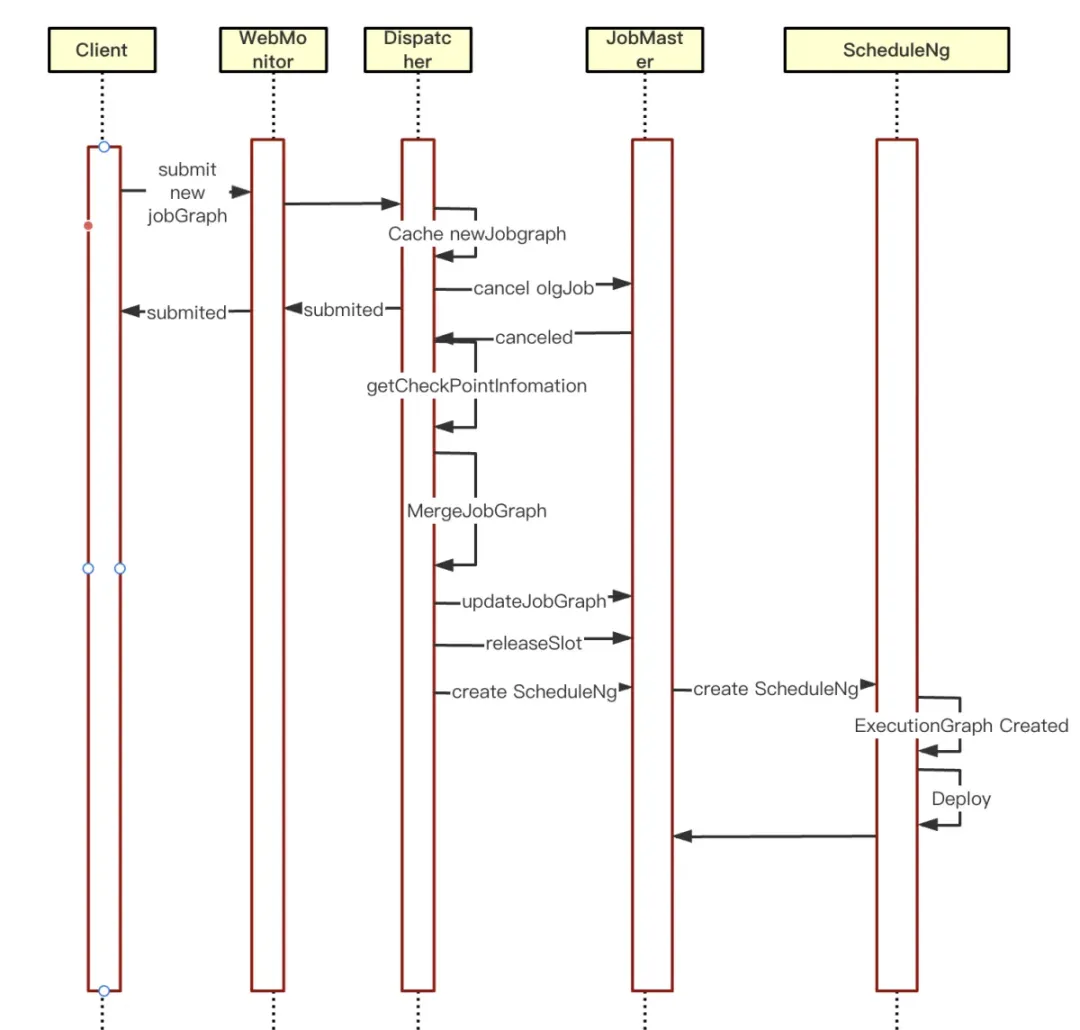
기존 Per-Job 모드에서 작업 업데이트로 인해 발생하는 서비스 중단 문제를 해결하기 위해 작업 안정성 및 시스템 가용성을 향상하고 프로덕션 환경에서 비즈니스 연속성 및 고가용성에 대한 요구 사항을 충족합니다. Kangaroo Cloud Engine 팀은 관련 탐색 및 소스 코드 개선을 수행하고 작업별 작업 취소의 비동기 콜백에서 작업의 핫 재시작을 최적화했습니다 .
① 먼저 현재 새로운 JobGraph 캐시가 있는지 확인합니다. 캐시가 있으면 핫 리스타트 로직을 입력합니다.
② 취소된 작업의 CheckPoint 정보를 얻어서 새로운 JobGraph에 채워 넣습니다.
③JobGrap을 JobMaster로 업데이트하고 JobGraph의 캐시 정보를 삭제합니다.
④JobMaster에서 SloyPool이 관리하는 리소스를 삭제합니다.
⑤JobMaster는 ScheduleNg를 다시 생성 하고 실행을 예약합니다. 그러면 새로운 JobGraph 예약 실행이 시작됩니다.
Flink 작업별 핫 업데이트 최적화는 개발 효율성을 크게 향상시키고 가동 중지 시간을 줄이며 애플리케이션 유연성과 안정성을 향상시킵니다. 신속한 반복과 동적 조정이 필요한 실시간 애플리케이션의 경우 최고의 효율성 경험을 제공합니다.
향상된 개발 효율성: 개발자는 지루한 중지 및 재시작 프로세스를 거치지 않고 코드를 신속하게 테스트하고 반복할 수 있으므로 개발 주기가 빨라지고 더 자주 릴리스될 수 있습니다.
· 가동 중지 시간 감소: 핫 업데이트는 애플리케이션 가동 중지 시간을 최소화하여 서비스 가용성을 높입니다. 이는 업무상 중요한 실시간 애플리케이션에 특히 중요합니다.
· 동적으로 매개변수 조정: 병렬 처리 또는 운영자 매개변수 와 같은 작업 구성 매개변수는 작업을 다시 시작하지 않고도 동적으로 조정될 수 있으므로 실시간 데이터 흐름이나 로드 조건에 따라 유연한 조정이 가능합니다.
● 기타 기능 개발
또한 엔진 측면에서는 Spark Ranger 도킹 , Spark 구체화 뷰 최적화 , Flink Session 모드 클래스 로딩 격리 등의 기능을 개발하여 엔진의 컴퓨팅 성능을 향상하는 동시에 엔진의 작업 보안 및 확장성을 향상시켰습니다.
요약하다
요약하자면, EMR6.2 의 출시는 빅데이터 서비스 분야에서 Kangaroo Cloud의 또 다른 중요한 이정표입니다. 포괄적인 UI 새로 고침 및 업그레이드, 차별화된 구성, 클러스터 마이그레이션 및 엔진 업그레이드를 포함한 네 가지 주요 기능의 최적화를 통해 EMR6.2는 사용자에게 보다 강력하고 유연하며 효율적인 빅 데이터 컴퓨팅 엔진 플랫폼을 제공 하여 기업의 데이터 관리 및 A를 지원합니다. 분석의 질적 도약.
"산업 지표 시스템 백서" 다운로드 주소: https://www.dtstack.com/resources/1057?src=szsm
"Dutstack 제품 백서" 다운로드 주소: https://www.dtstack.com/resources/1004?src=szsm
"데이터 거버넌스 산업 실무 백서" 다운로드 주소: https://www.dtstack.com/resources/1001?src=szsm
빅데이터 제품, 산업 솔루션, 고객 사례에 대해 더 알고 싶거나 상담하고 싶은 분들은 Kangaroo Cloud 공식 홈페이지( https://www.dtstack.com/?src=szkyzg )를 방문해 주세요.
Linus는 커널 개발자가 탭을 공백으로 대체하는 것을 막기 위해 스스로 노력했습니다. 그의 아버지는 코드를 작성할 수 있는 몇 안되는 리더 중 한 명이고, 둘째 아들은 오픈 소스 기술 부서의 책임자이며, 막내 아들은 오픈 소스 코어입니다. 기고자 Robin Li: 자연 언어 는 새로운 범용 프로그래밍 언어가 될 것입니다. 오픈 소스 모델은 Huawei에 비해 점점 더 뒤쳐질 것입니다 . 일반적으로 사용되는 5,000개의 모바일 애플리케이션을 Hongmeng으로 완전히 마이그레이션하는 데 1년이 걸릴 것입니다. 타사 취약점. 기능, 안정성 및 개발자의 경험이 크게 개선된 Quill 2.0 이 출시되었습니다. Ma Huateng과 Zhou Hongyi는 "원한을 제거하기 위해" 공식적으로 출시되었습니다. Laoxiangji의 소스는 코드가 아닙니다. Google이 대규모 구조 조정을 발표한 이유는 매우 훈훈합니다.