
Kangaroo Cloud 09 제품 기능 업데이트 보고서 에 오신 것을 환영합니다 . 이 보고서에서 우리는 혁신과 최적화를 동등하게 강조한다는 개념을 고수하고 제품에 대한 심층적인 연마와 포괄적인 업그레이드를 수행합니다. 모든 세부 사항의 개선은 탁월한 품질을 향한 우리의 끊임없는 추구입니다. 이러한 새로운 기능이 귀하의 비즈니스 운영과 발전에 도움이 되어 디지털 혁신을 더욱 원활하게 만들어주기를 바랍니다.
다음은 Kangaroo Cloud 제품 기능 업데이트 보고서 09호의 내용입니다. 더 자세히 알아보려면 계속해서 읽어보시기 바랍니다.
오프라인 개발 플랫폼
새로운 기능 업데이트
1.작업 템플릿
배경: 고객은 일상적인 공통 코드 템플릿을 오프라인으로 유지 하고 데이터 개발 중에 직접 참조하기를 원합니다 .
템플릿과 구성요소의 차이점:
1. 템플릿 코드 참조 이후에는 편집이 지원되지만, 컴포넌트 참조 이후에는 편집이 지원되지 않습니다.
2. 템플릿 변경은 참조된 작업에 영향을 미치지 않지만 구성 요소 변경은 참조된 작업에 영향을 미칩니다.
새로운 기능 설명: 작업 유형별 프로젝트 코드 템플릿 및 테넌트 코드 템플릿을 지원하고, 작업 생성 시 코드 템플릿 참조를 지원합니다 .
2. 에이전트의 쉘/에이전트의 Python은 새로운 프로젝트 차원 제어를 추가합니다.
배경:
에이전트의 셸은 오프라인 플랫폼을 위한 특수 작업 유형입니다.
셸 작업은 클러스터 배포 컴퓨터에서 직접 실행되지 않지만 셸은 독립적으로 배포된 서버 노드에서 실행됩니다. 하나의 오프라인 작업에는 두 개의 코어가 필요하므로 고객 시나리오에서 Shell 작업이 많은 경우 클러스터 리소스를 채우기 가 쉽습니다 . 따라서 독립적으로 배포된 노드에서 Shell 및 Python과 같은 작업을 실행하면 클러스터에 대한 부담을 효과적으로 줄일 수 있습니다.
현재 문제가 있습니다. 고객이 EM과 콘솔에서 노드와 서버 사용자를 구성하는 한 클러스터 아래의 모든 프로젝트는 구성된 노드와 서버 사용자를 사용할 수 있습니다. 이로 인해 보안 문제가 발생합니다. 예를 들어, 루트와 같은 높은 권한을 가진 사용자의 경우 고객은 보안 문제에 더 많은 관심을 갖고 모든 프로젝트에서 이 계정을 사용하는 것을 원하지 않으므로 서버 노드의 구성을 제어할 수 있는 솔루션을 설계해야 합니다. 그리고 서버 사용자는 이 문제를 해결해야 합니다.
새로운 기능에 대한 설명:
1. 콘솔은 프로젝트 인증을 통해 노드 및 서버 사용자 권한을 제어합니다 .
2. 오프라인 프로젝트의 작업은 인증된 서버 노드 및 사용자 선택을 지원합니다.
기능 최적화
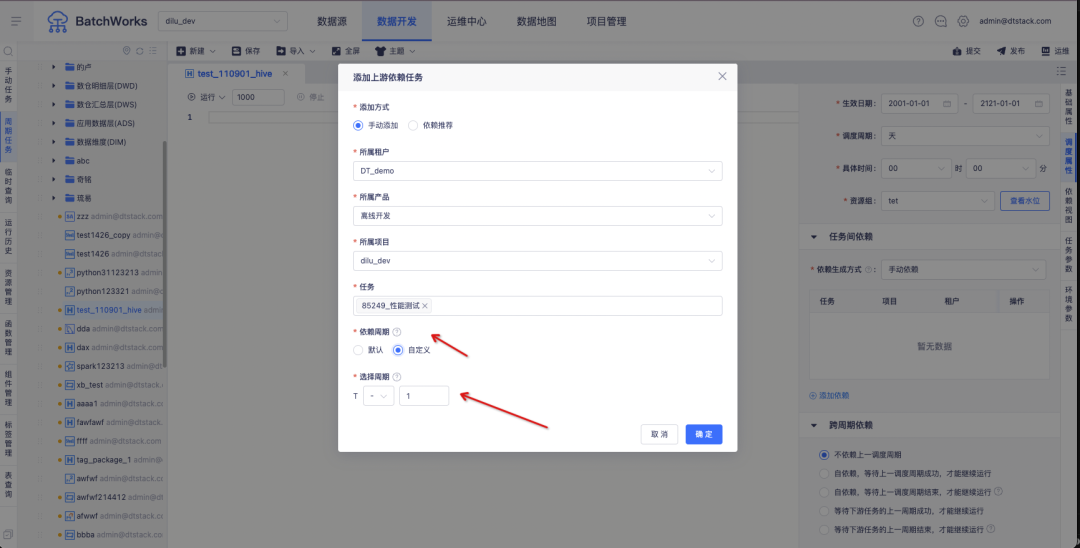
1. 업스트림 작업에 의존하는 모든 주기적 인스턴스를 제어할 수 있는 스케줄링 구성 최적화
배경:
현재 Zhongtian 작업 예약은 기본적으로 현재 주기의 업스트림 인스턴스에만 의존할 수 있습니다.
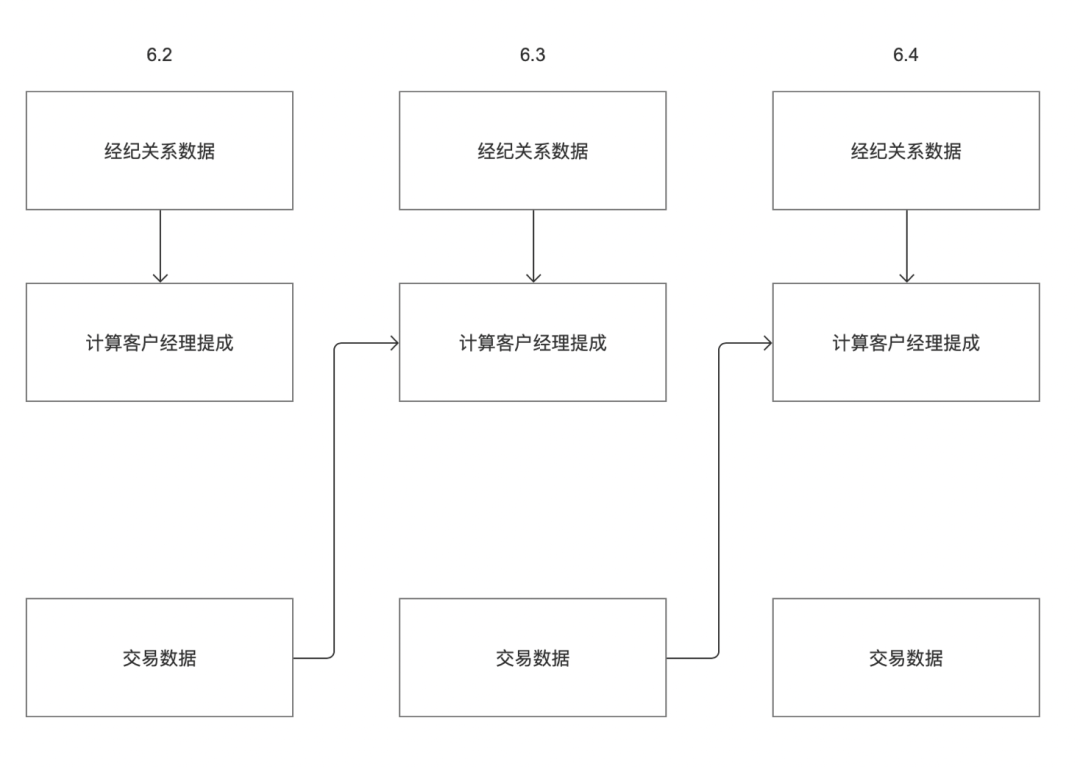
예를 들어, 고객에게 "중개 관계 데이터"와 "거래 데이터"라는 두 가지 비즈니스 시스템이 있다고 가정해 보겠습니다. 6월 3일 고객의 수수료는 각각 "중개 관계 데이터"와 "거래 데이터"를 기반으로 계산되어야 합니다. 위 그림에서 볼 수 있듯이 6월 2일 "중개관계 데이터" 비즈니스 시스템 데이터 출력 시간은 6월 3일이며, 6월 2일 "거래 데이터" 비즈니스 시스템 데이터 출력 시간은 6월 2일 저녁입니다.
현재 오프라인 업스트림 및 다운스트림 종속성 논리에 따르면 "계정 관리자 커미션 계산" 작업은 6월 3일에만 작업을 얻을 수 있지만 6월 2일에는 작업을 얻을 수 없습니다. 따라서 작업 인스턴스 종속성 설정을 지원하도록 수정해야 합니다. 주기를 사용자 정의할 수 있습니다.
경험 최적화 지침:
종속 업스트림 작업의 예약 주기 사용자 정의를 지원합니다 .
T는 현재 작업(다운스트림 작업)의 계획된 시간을 나타내고, "+ -"는 오프셋 방향을 나타내고, "+"는 미래에 대한 시간 오프셋을 나타내고, "-"는 과거에 대한 시간 오프셋을 나타내고, "-"는 기본적으로 선택됩니다.
오프셋은 최대값 10, 최소값 1의 숫자 입력 상자로, 오프셋의 업스트림 작업 주기 수를 나타냅니다.
실시간 개발 플랫폼
새로운 기능 업데이트
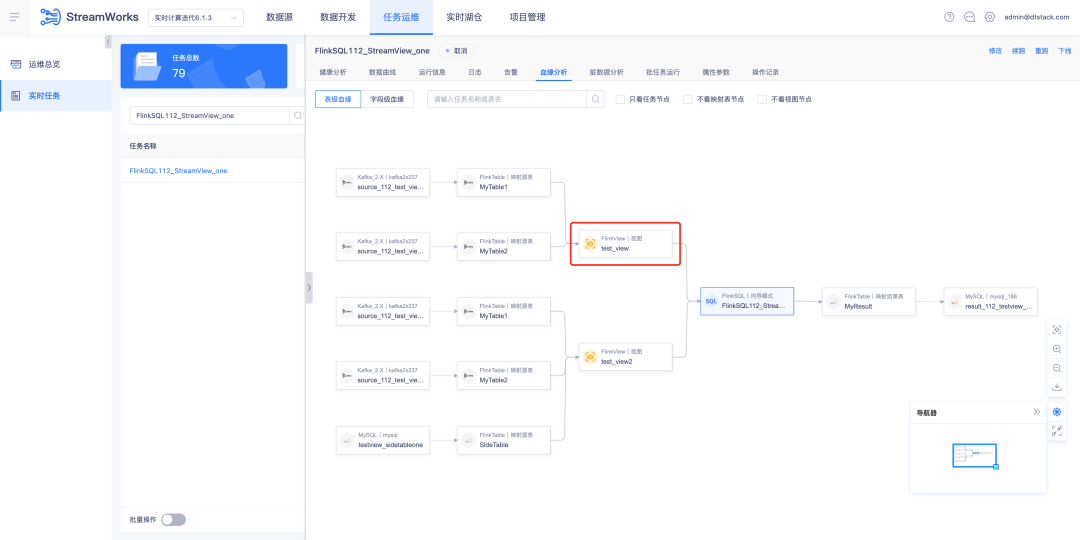
1. 혈통분석 보기
배경: 현재 SQLParser는 FlinkSQL의 뷰 계보 분석을 지원하지 않습니다. 그러나 일반적인 개발 시나리오에서 작업에 3개 이상의 테이블이 관련된 경우 많은 회의에서는 SQL 논리 읽기를 용이하게 하기 위해 IDE에서 뷰를 작성하도록 선택합니다.
기능:
1. SQLParser는 FlinkSQL 뷰 테이블을 지원하여 혈연 분석을 표시합니다.
2. 태스크 운영 및 유지관리 - 실시간 태스크 - FlinkSQL 태스크 내역 - 혈통 분석 표시 기능
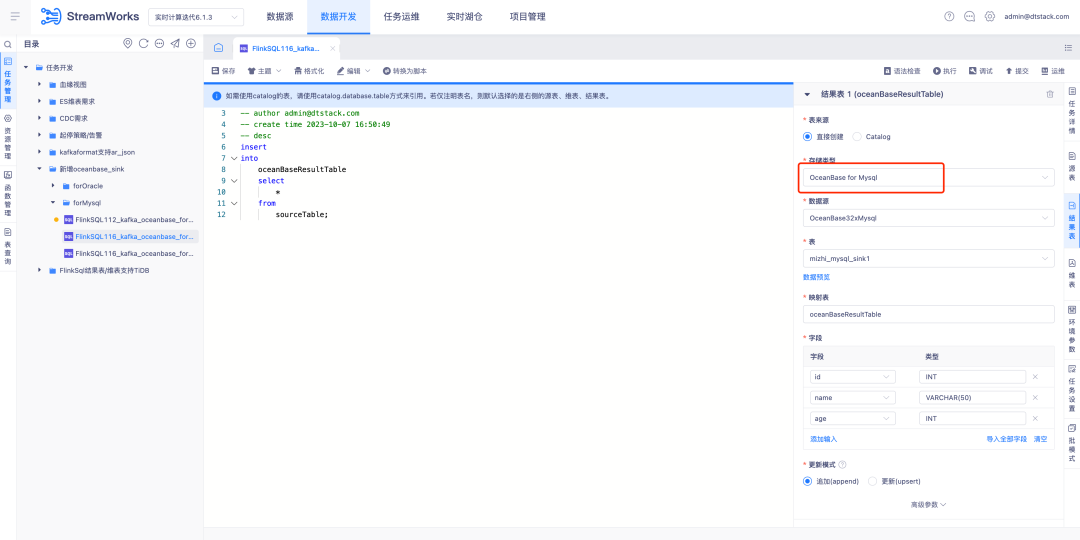
2.FlinkSQL은 Oceanbase Sink를 지원합니다.
FlinkSQL 버전 1.16은 OceanBase 결과 테이블을 지원 하고 OceanBase 버전 4.2.0의 MySQL 및 Oracle 모드와 호환되어 사용자에게 보다 유연하고 효율적인 데이터 처리 기능을 제공합니다.
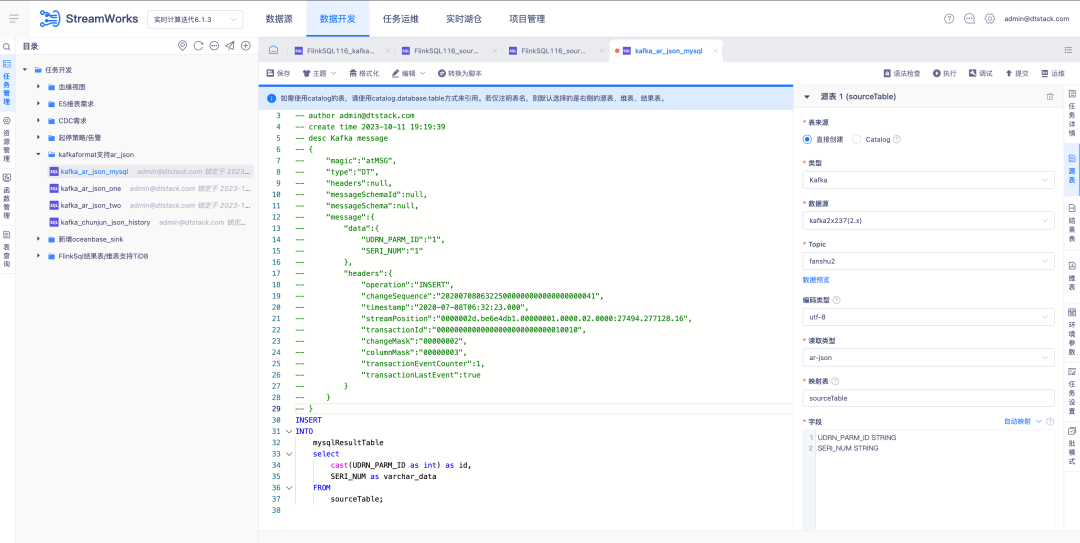
3. 소스 테이블 Kafka 읽기 유형은 AR Json을 지원합니다.
배경: OGG와 Attunity Replicate 는 해외에서 널리 사용되는 두 가지 상용 제품입니다 . 고객 요구를 더 잘 충족하려면 Kafka의 JSON 형식이 AR Json 읽기 유형과 호환되는지 확인해야 합니다.
새로운 기능 설명: FlinkSQL1.16 버전 소스 테이블 Kafka 읽기 유형은 AR Json 유형을 지원하고 Json을 구문 분석하는 자동 매핑 관련 기능을 지원합니다.
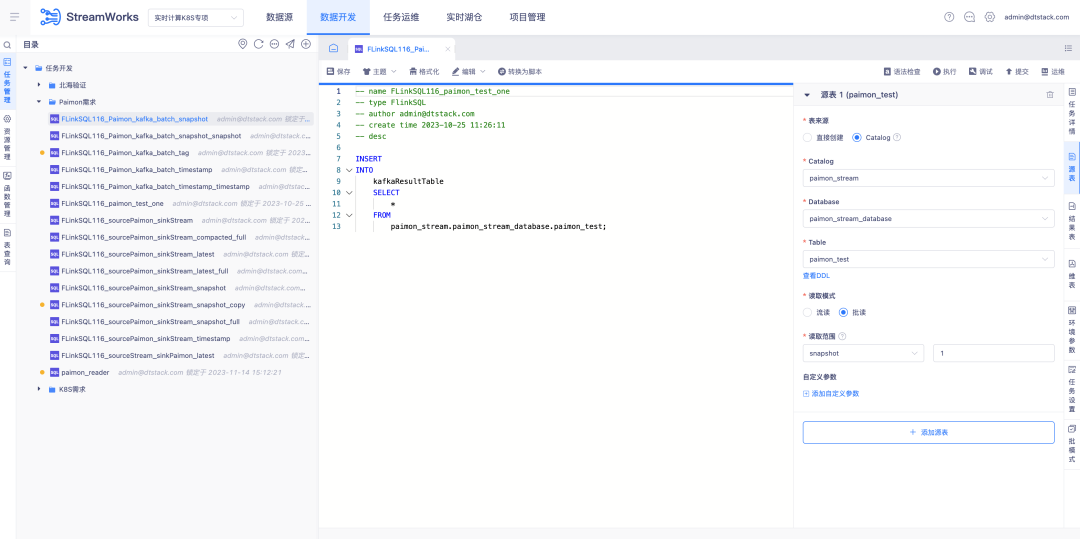
4. 실시간 호수창고 파이몬 지원
배경: Paimon의 개발과 함께 이번에는 새로운 FlinkSQL 개발 모델을 반복해야 합니다. 이 모델을 사용하면 레이크 창고 관리 모듈을 전체 체인에 걸쳐 연결할 수 있습니다.
새로운 기능에 대한 설명:
1. Lake 창고 관리에 Paimon 테이블을 추가, 삭제, 수정 및 쿼리하는 기능이 추가되었습니다.
2. 데이터 개발 플랫폼에 파이몬 테이블의 시각적 구성 기능을 추가합니다.
3. 데이터 개발 플랫폼은 IDE를 사용하여 Paimon 테이블의 읽기 및 쓰기 기능을 완성합니다.
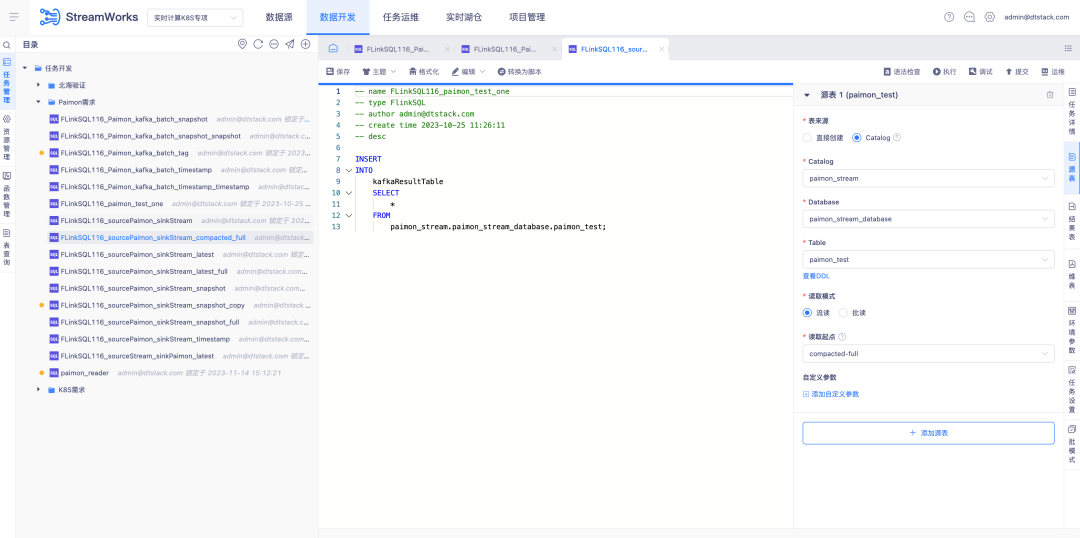
5.FlinkSQL 내장 FlinkCDC
배경: FlinkCDC는 반복 속도가 매우 빠른 오픈 소스 실시간 수집 구성 요소입니다. 이 구성 요소가 사용하는 기본 Flink 프레임워크도 우리가 사용하는 ChunJun 프레임워크와 동일합니다. 따라서 우리는 이를 실시간 플랫폼 배포를 위한 기본 구성 요소로 만들고 이를 시스템에 패키징하는 것을 고려합니다.
새로운 기능에 대한 설명:
1. 실시간 기본 배포 패키지, FlinkCDC 실시간 수집 설정 가져오기
2. 플랫폼 스크립트 모드에서는 FlinkCDC의 내장 컬렉션 기능과 지원되는 커넥터를 확인해야 합니다.
3. 플랫폼 마법사 모드는 프로젝트 상황에 따라 FlinkCDC에서 지원하는 커넥터 컬렉션을 구성합니다.
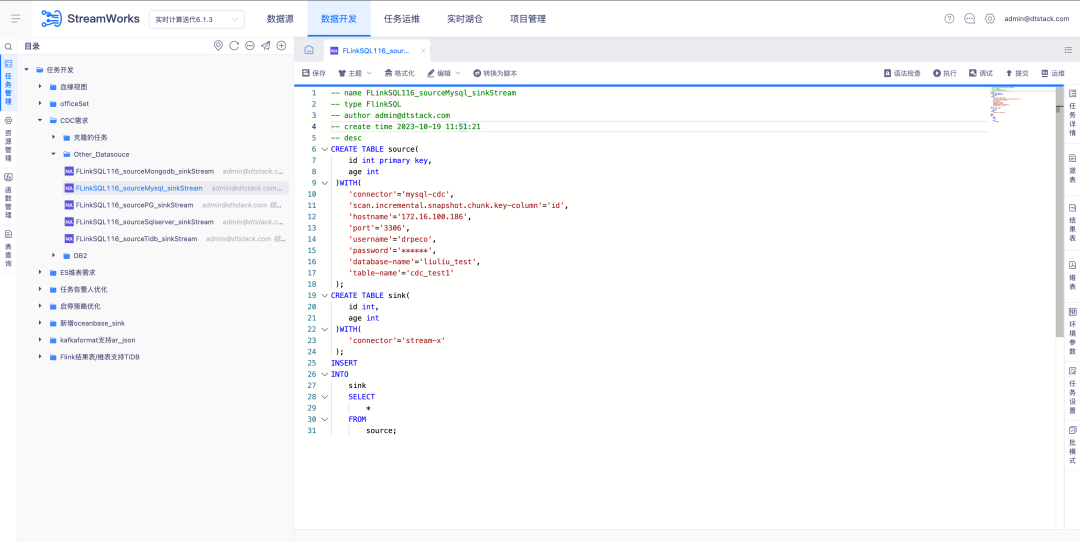
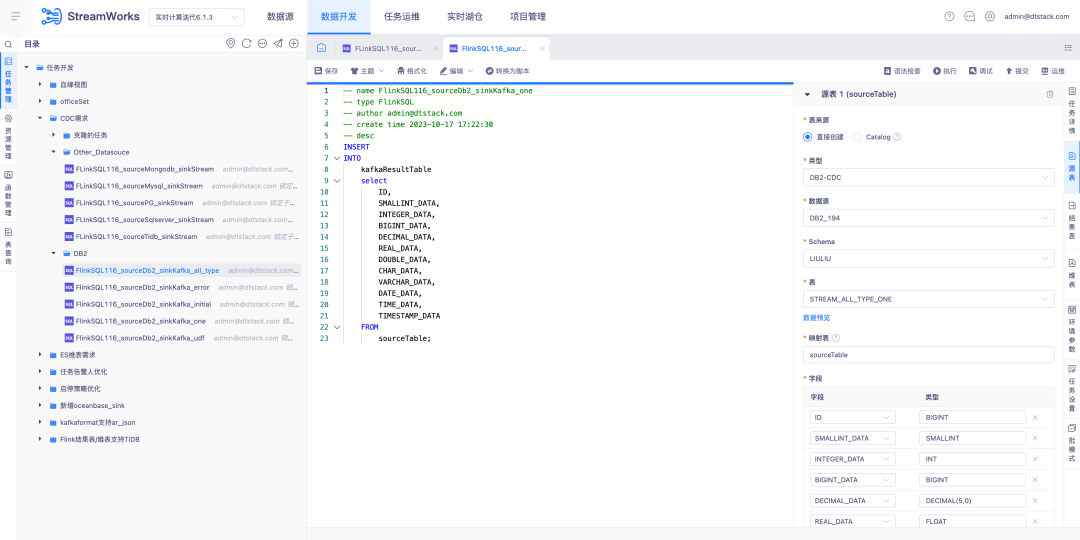
6.FlinkSQL은 FlinkCDC DB2 데이터 소스를 지원합니다.
배경: 고객은 DB2의 실시간 수집을 지원해야 합니다. CDC 커넥터 개발이 어렵다는 점을 고려하여 FinkCDC에서는 이를 지원하므로 하위 계층에서는 FlinkCDC의 기능을 차용합니다.
새로운 기능 설명: 실시간 플랫폼은 소스 테이블을 DB2-CDC 데이터 소스 로 구성하는 마법사 모드를 지원합니다 .
기능 최적화
1.연속 로직 최적화
배경: CheckPoint를 통해 실시간 작업을 재개하고 계속 실행하는 경우 시점을 수동으로 선택해야 하지만 실제로 대부분의 연속 시나리오에서는 최신 CheckPoint를 선택합니다.
경험 최적화 설명: CheckPoint를 통해 복원하고 계속 실행하도록 최적화하는 경우 날짜 내에 가장 가까운 CheckPoint가 자동으로 선택됩니다.
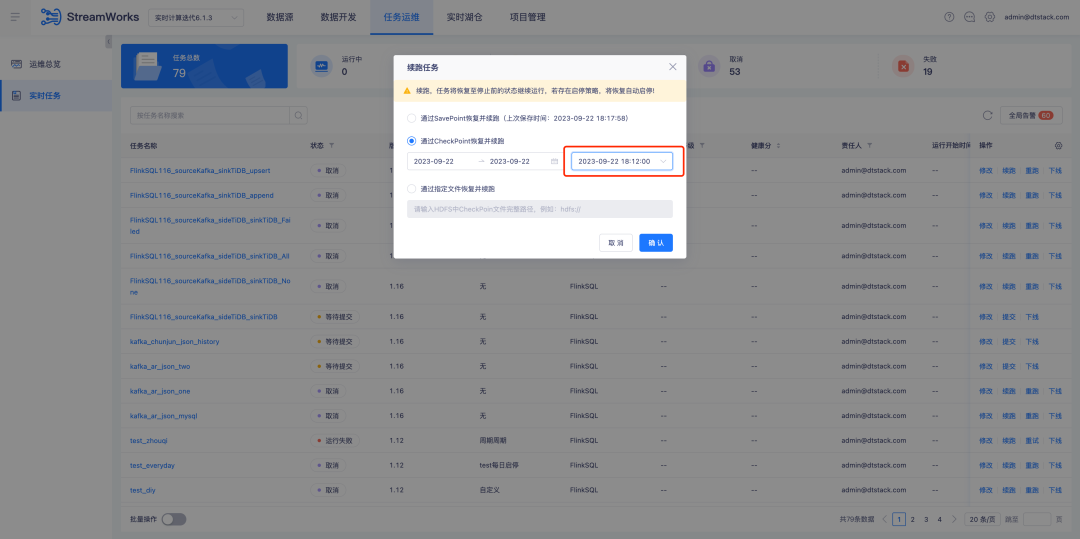
2. 스타트-스톱 전략/오프사이트 최적화
배경: 고객이 심층적으로 사용하는 동안 시작-중지 전략, 제출 및 재실행과 같은 측면을 최적화하여 보다 효율적인 작업 흐름과 더 나은 사용자 경험을 달성할 수 있다는 사실을 발견했습니다.
현재 데이터 개발 소스 테이블의 오프사이트 타임스탬프 구성이 수정되었습니다. 그러나 실시간 작업 컴퓨팅 시나리오에서 일부 고객은 그날의 데이터 계산에만 집중하므로 매일 작업을 다시 실행하도록 시작-중지 정책을 구성합니다. 그들은 고정된 타임스탬프를 사용하는 대신 매일 자정부터 작업을 다시 실행할 수 있기를 원합니다. 최신은 이론적으로 이 요구 사항을 충족할 수 있지만 실시간 작업 시작 시간을 소비하면 실제 실행 시간이 0에서 벗어나 데이터 오류가 발생할 수 있습니다.
경험 최적화 지침:
1. 시작-중지 정책 구성을 최적화하고 이제 교차일 시작-중지 정책을 지원하며 현재 시작-중지 정책 페이지 상호 작용을 개선하여 보다 효율적이고 편리한 운영 경험을 제공합니다.
2. 데이터 개발 - 소스 테이블, 오프사이트 위치 의 매개변수화된 구성 지원
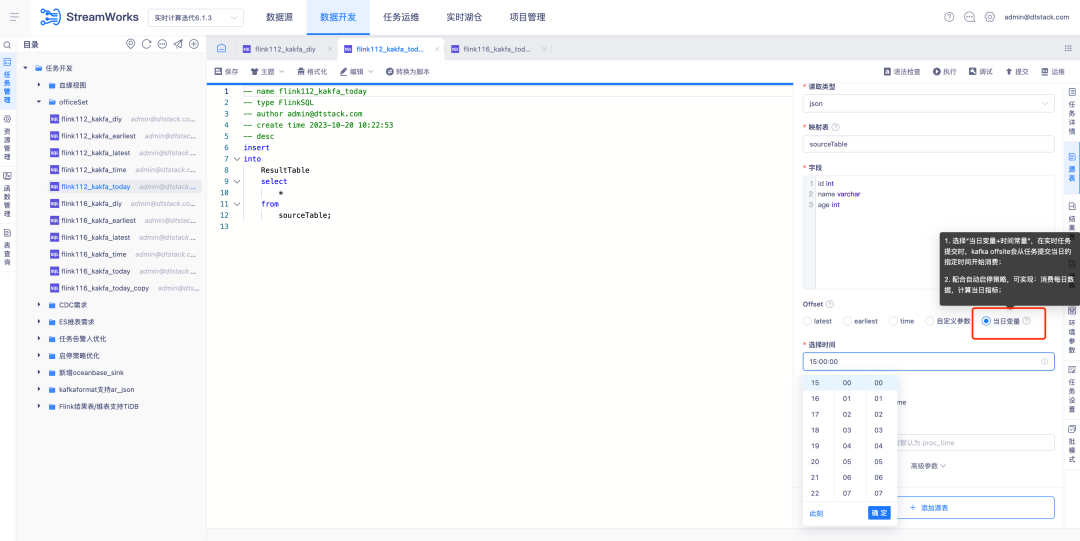
3.FlinkSQL1.16 버전 ES7.x 플러그인 최적화
배경: FlinkSQL 버전 1.10의 ES 플러그인은 차원 테이블 시간 초과 시간 및 시간 초과 데이터 제한 구성을 지원합니다. 이 기능은 현재 FlinkSQL 버전 1.16에서 일시적으로 사용할 수 없으며 적극적으로 최적화되고 있습니다.
경험 최적화 지침:
FlinkSQL1.16 버전 ES7.x 플러그인 차원 테이블은 table.exec.async-lookup.timeout을 구성하거나 힌트 구문을 사용하여 차원 테이블의 LRU 모드에서 작업을 실행하는 경우 비동기 쿼리 시간 초과가 발생합니다. 효과.
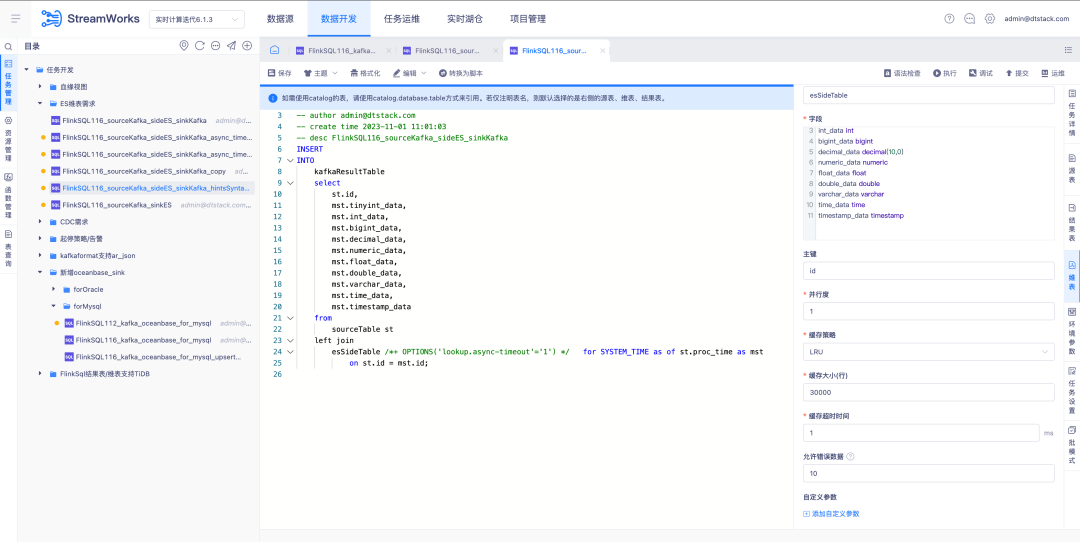
4.알람 구성 최적화
배경: 작업 알람 규칙에서 알람 수신 구성을 수동으로 선택해야 합니다. 동시에 작업 책임자에 따라 알람 정보를 자동으로 일치시켜 보내는 것은 불가능합니다. 업무 담당자에 따라 해당 알람 정보를 자동으로 전송하는 것은 불가능합니다.
경험 최적화 지침:
1. 단일 작업 알람 규칙 구성 수신자 조정 기본적으로 작업 책임자가 선택됩니다. 선택 상자를 통해 다른 수신자를 선택할 수 있습니다.
2. 작업책임자를 체크하면 실제로 글로벌 알람 룰 구성이 각 작업책임자에게 전송됩니다. 다른 수신자를 선택하면 선택한 작업이 비정상일 때 선택한 작업이 선택된 수신자에게 전송됩니다.
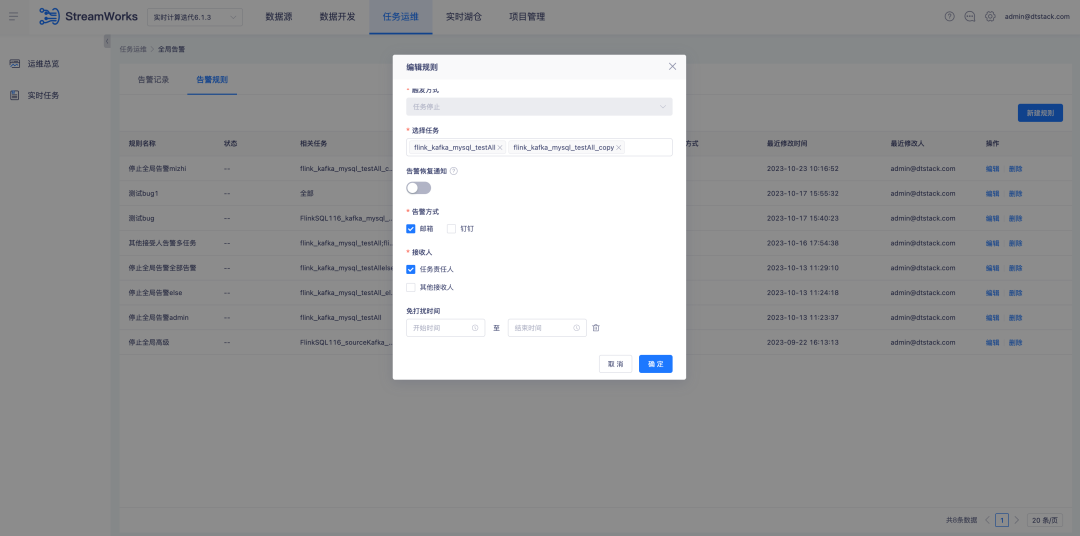
5.FlinkSQL1.12&1.16 버전 Tidb 플러그인 플랫폼이 호환됩니다.
배경: FlinkSQL 버전 1.12 및 1.16은 Tidb에 대한 적용을 완료했습니다. 그러나 플랫폼 계층은 버전 1.10에서만 적용되었으므로 버전 1.12 및 1.16은 지원되지 않습니다.
경험 최적화 지침:
실시간 플랫폼은 Tidb 플러그인 버전 1.12&1.16과 호환되며 차원 테이블과 결과 테이블을 모두 지원해야 합니다.
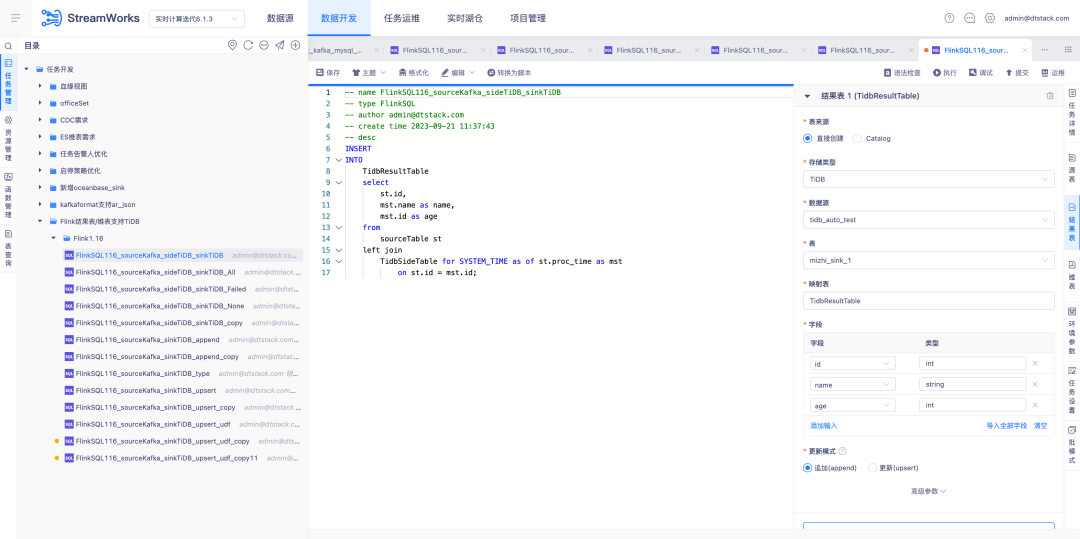
6.FlinkSQL1.12&1.16 버전 Hive huaweiCloud 적응
배경: Kafka 데이터의 실시간 백업은 MRS Hive에 입력되며, 실시간 계산 데이터에 문제가 있는 경우 Hive에 있는 백업 메시지를 분석할 수 있습니다.
경험 최적화 지침:
FlinkSQL 버전 1.12&1.16은 Hive huaweiCloud에 적용됩니다. 데이터 소스 센터, 엔진 및 플랫폼은 Hive huaweiCloud 결과 테이블을 지원하기 위해 동시에 개발됩니다. Kerberos를 활성화하는 시나리오에 주의해야 합니다.
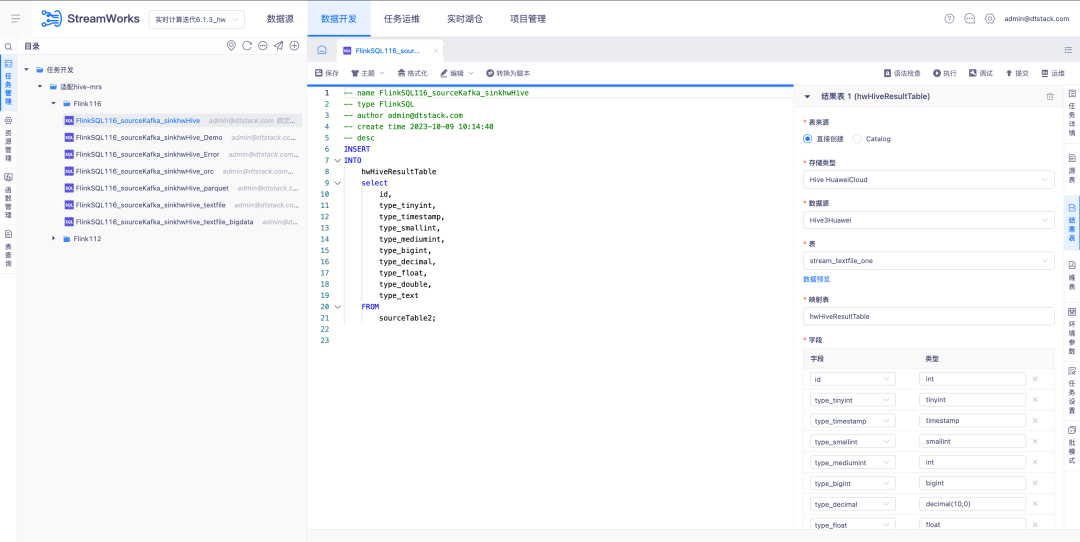
데이터 서비스 플랫폼
새로운 기능 업데이트
1. HBase TBDS 버전 생성 API 지원
마법사 모드 생성 API , 가져오기 및 내보내기, 대상 프로젝트에 게시를 포함한 HBase TBDS 버전 생성 API가 추가되었습니다 .

기능 최적화
1. Oracle 데이터 소스는 DML을 지원합니다.
DML 이 지원하는 데이터 소스를 개선합니다 .
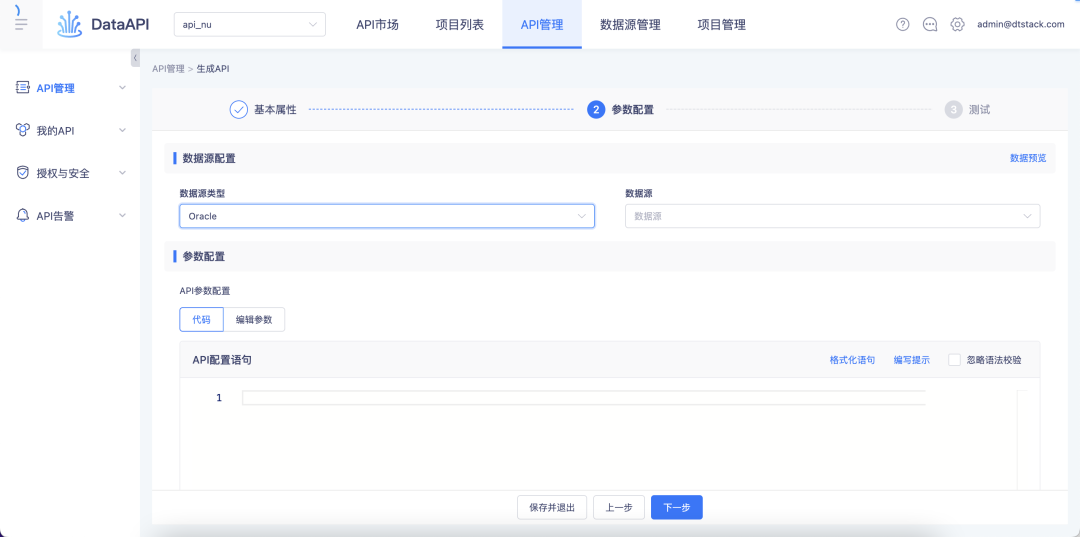
2. 사용자 정의 SQL 모드 주석 구문 분석이 더 이상 설명을 덮어쓰지 않습니다.
배경: 기록 논리의 경우 사용자 지정 SQL 스키마가 데이터베이스에 대해 다시 구문 분석된 후 데이터베이스와 함께 제공되는 설명이 수정된 지침을 덮어씁니다.
경험 최적화 지침: 기록 논리를 수정합니다. 수정된 지침의 경우 다시 구문 분석한 후 데이터베이스의 주석을 더 이상 덮어쓰지 않습니다.
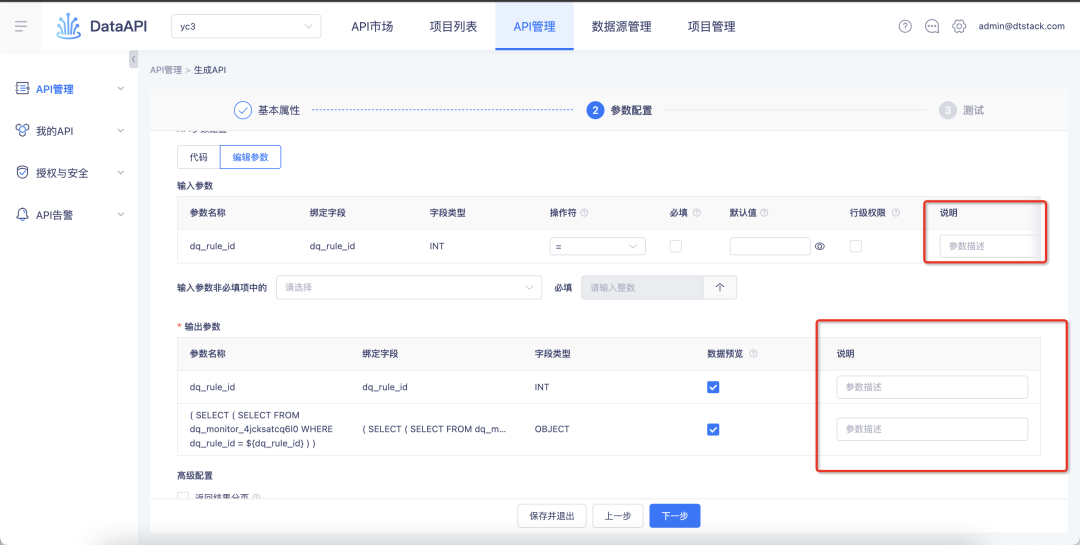
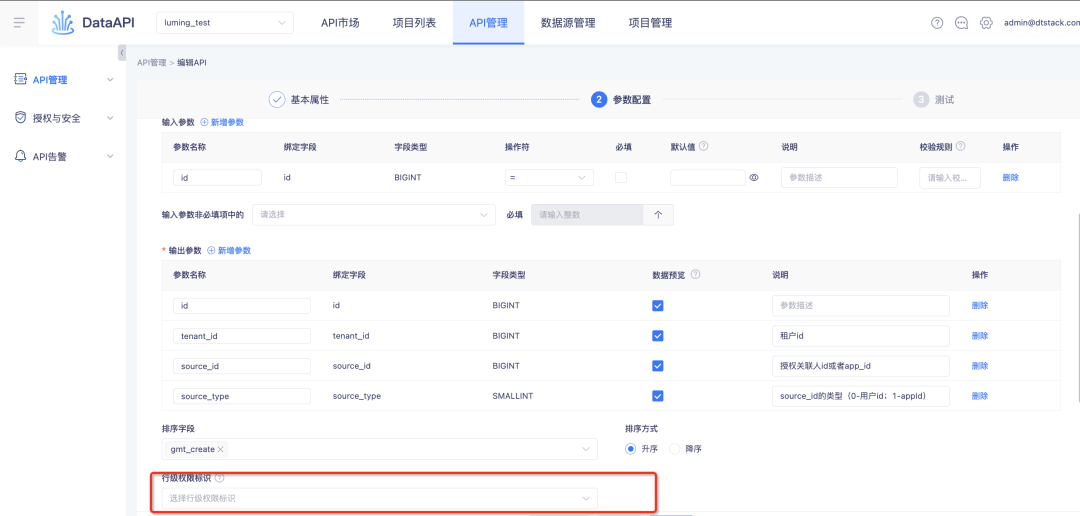
3. 행 수준 권한이 활성화된 후에는 기본적으로 입력할 필요가 없습니다.
배경: 기록 행 수준 권한의 경우 테이블의 필드에서 행 수준 권한이 활성화되고 나면 해당 필드가 기본적으로 필요하며 사용자 취소는 지원되지 않습니다.
경험 최적화 설명: 이 반복은 API 수준에서 행 수준 권한이 활성화되고 API가 테이블을 사용할 때 행 수준 권한에 의해 제한됩니다.
4. 프레임워크 버전 및 구성요소 업그레이드
Spring Cloud(Boot) 프레임워크 버전이 업그레이드되고, Nacos 컴포넌트 가 업그레이드되어 취약점 발생 확률을 줄이고 API 자체의 안정성을 강화합니다.
고객 데이터 통찰력 플랫폼
새로운 기능 업데이트
1. 사용자 정의 UDF 기능 지원
배경: 고객이 처리하는 데이터에 포함된 휴대폰 번호, ID 번호 및 기타 데이터는 암호화된 데이터입니다. 감사 관점에서 이러한 종류의 데이터는 일반 텍스트로 표시될 수 없지만 일반 텍스트 콘텐츠가 표시되는 시나리오가 있습니다. 상위 비즈니스에 표시됩니다. 예: 휴대폰 번호를 기반으로 한 SMS 마케팅.
고객은 최대한 늦게 복호화 프로세스를 넣어 라벨 플랫폼에 올려 완료해야 하며, UDF 기능 맞춤화를 통해 맞춤 라벨을 추가해 처리를 완료해야 합니다.
새로운 기능에 대한 설명: UDF 기능을 생성하고, 보고, 삭제할 수 있는 새로운 기능 관리 모듈이 태그 센터에 추가되었습니다 (Trino385 이상 버전에서만 기능 생성을 지원합니다).
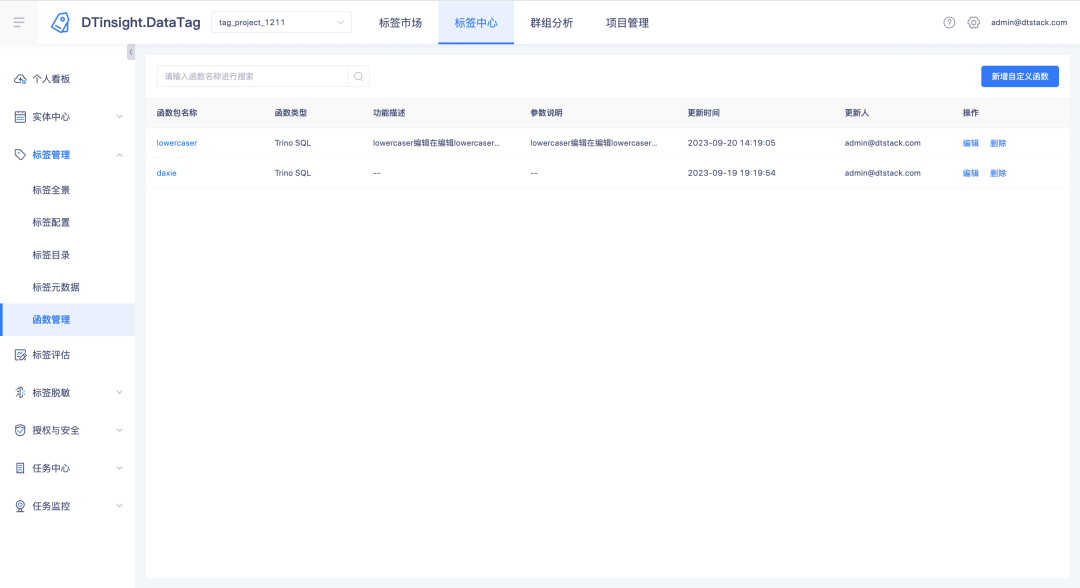
업로드된 함수의 경우 함수 이름을 클릭하면 함수 세부정보를 볼 수 있습니다.
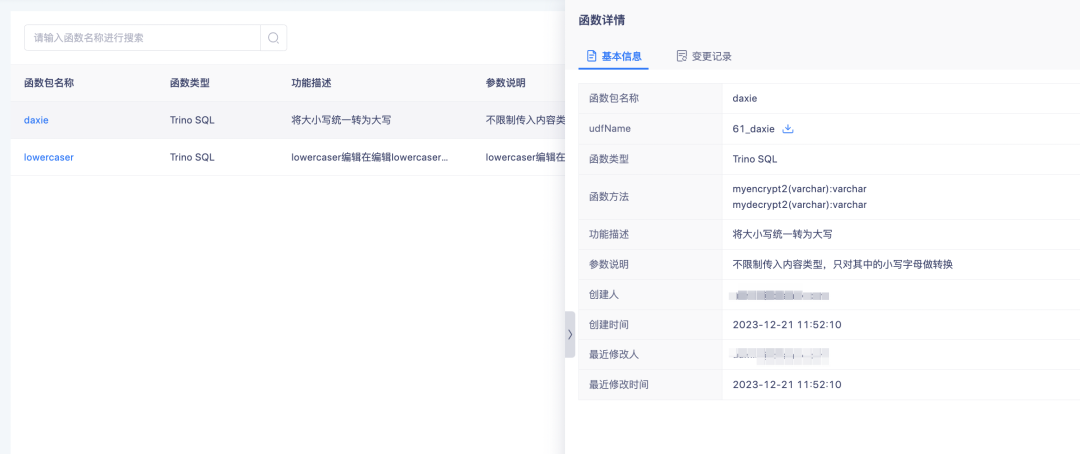
업로드된 함수는 주로 파생된 SQL 태그를 처리하는 데 사용됩니다.
2. 다중 값 태그 처리 지원
배경: 파생 태그 및 결합 태그에 대한 현재 처리 규칙은 인스턴스가 처음 특정 규칙 조건에 도달하면 해당 태그 값이 인스턴스에 표시되고 결국 다른 태그 값은 더 이상 일치하지 않는다는 것입니다. , 단일 값 태그 결과는 데이터베이스에 저장됩니다.
그러나 실제 적용에서는 조건이 반드시 상호 배타적인 것은 아닙니다. 예를 들어 사용자는 특정 유형의 제품을 구매한 횟수를 기준으로 사용자에게 제품 선호도 라벨이 제공됩니다. 이 경우 여러 값을 지원해야 합니다.
새로운 기능에 대한 설명:
파생 규칙 태그, 파생 SQL 태그, 조합 태그, 사용자 정의 태그 처리는 다중 값 태그 로 구성을 지원하며 시스템은 설정된 태그 값 유형을 기반으로 이를 계산합니다.
• 단일 값 태그: 규칙 구성에 따라 순서대로 일치합니다. 특정 태그 값에 도달하면 일치가 중지됩니다. 데이터 결과에 최대 1개의 태그 값이 있습니다.
• 다중 값 태그: 규칙 구성 순서에 따라 순서대로 일치합니다. 각 규칙은 데이터 결과에 최대 n개의 구성된 태그 값이 일치합니다.
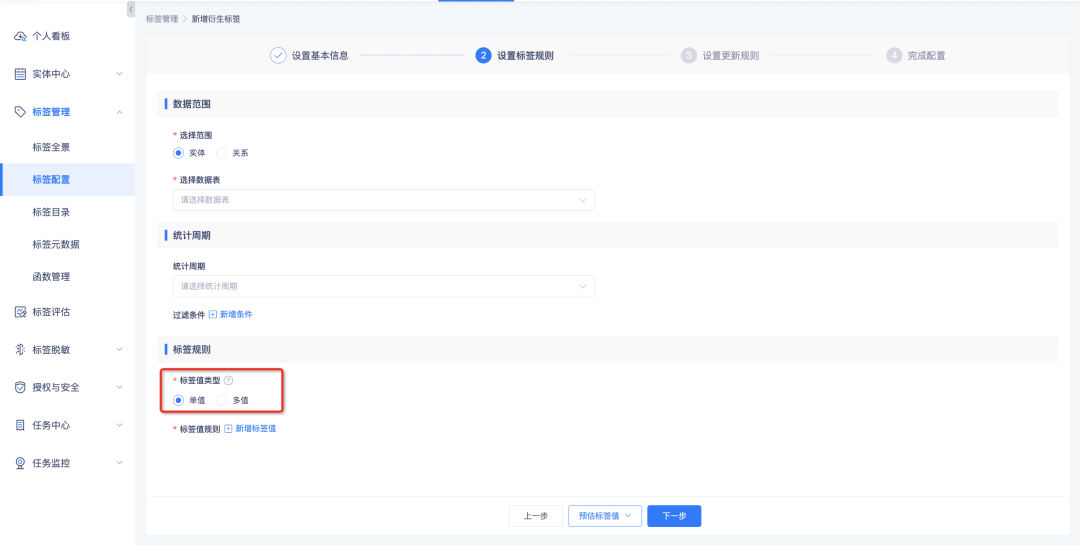
계산 결과에 따라 라벨 세부정보는 각 개별 라벨의 인스턴스 수를 계산합니다. 즉, 단일 값 라벨의 각 라벨 값에 포함된 인스턴스 수의 합은 라벨에 포함된 인스턴스 수입니다. , 다중 값 레이블의 각 레이블 값이 적용되는 인스턴스 수의 합은 레이블 적용 인스턴스 수보다 크거나 같습니다.
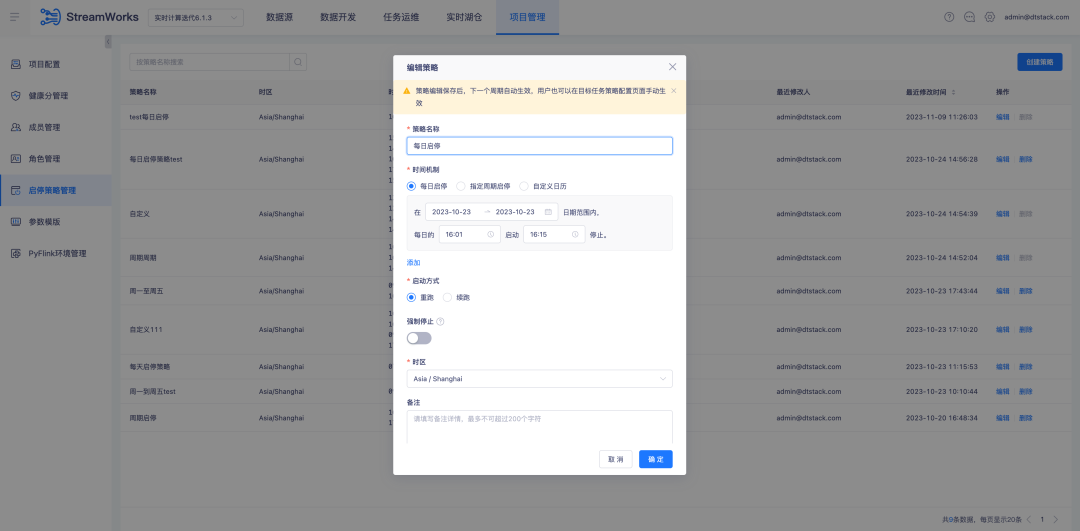
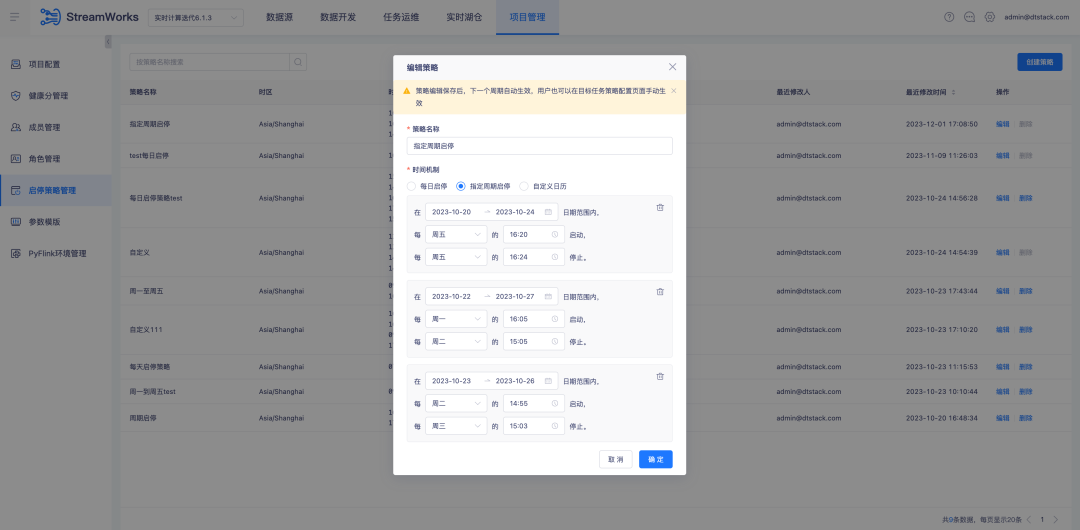
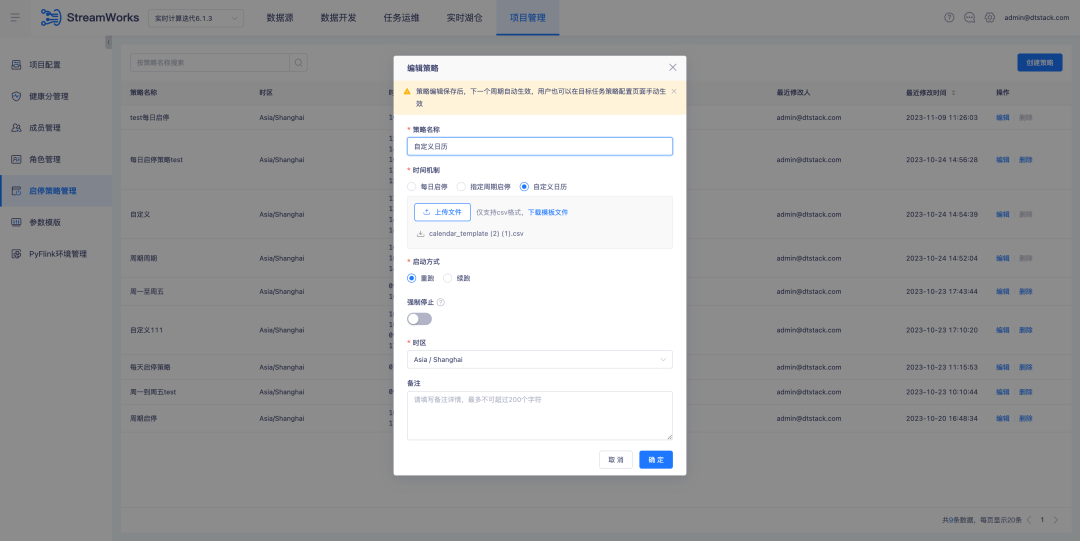
3. 맞춤형 역할 도킹 비즈니스 센터
배경: 이전에는 역할이 시스템에 내장되어 있어 역할을 추가/수정/삭제할 수 없었으며 역할 권한을 사용자 정의할 수 없었습니다. 기능이 너무 고정되어 실제 비즈니스 시나리오에 따라 유연하게 조정할 수 없었습니다. 버전 6.0에서는 비즈니스 센터에 사용자 정의 역할 기능이 추가되었으며 태그 제품은 비즈니스 센터의 이 기능에 연결되어 다음과 같은 효과를 얻습니다.
1. 새로운 역할 지원
2. 사용자 정의 역할 권한 지원
새로운 기능 설명: 비즈니스 센터에서 역할과 해당 표시 권한을 구성하면 라벨링 플랫폼이 쿼리에 대한 권한 구성 결과를 자동으로 소개합니다.
1. 비즈니스 센터에서 새 역할을 추가하고 역할 권한 지점을 구성합니다.
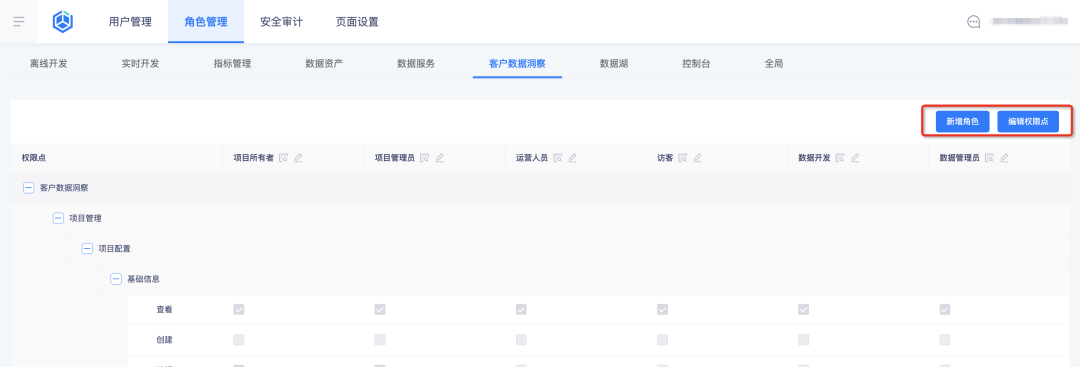
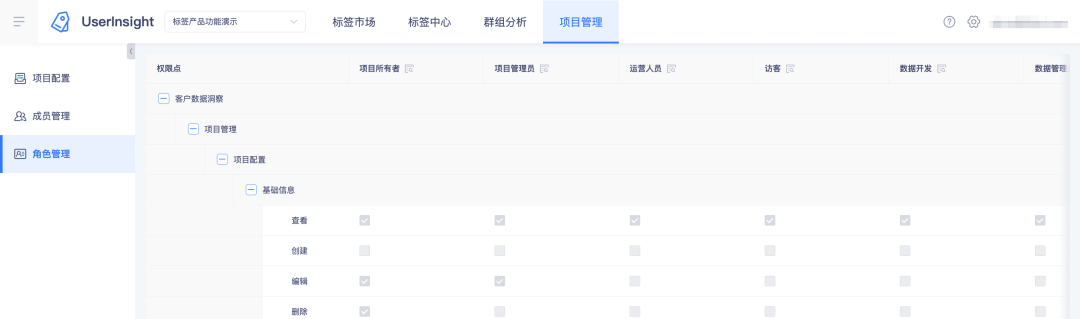
2. 태그 플랫폼에서 역할과 권한 포인트를 확인하세요.
4. 데이터 표시 형식은 사용자 정의를 지원합니다.
배경: 숫자 태그의 경우 표시 정밀도 설정이 현재 지원되지 않아 페이지가 불규칙하게 표시됩니다. 일부는 1과 같은 정수를 표시하고 일부는 1.234와 같은 소수점을 표시합니다. 이는 사용자의 만족도를 높이기 위한 것입니다. 경험상 데이터 표시 규칙 설정을 추가해야 합니다.
새로운 기능에 대한 설명:
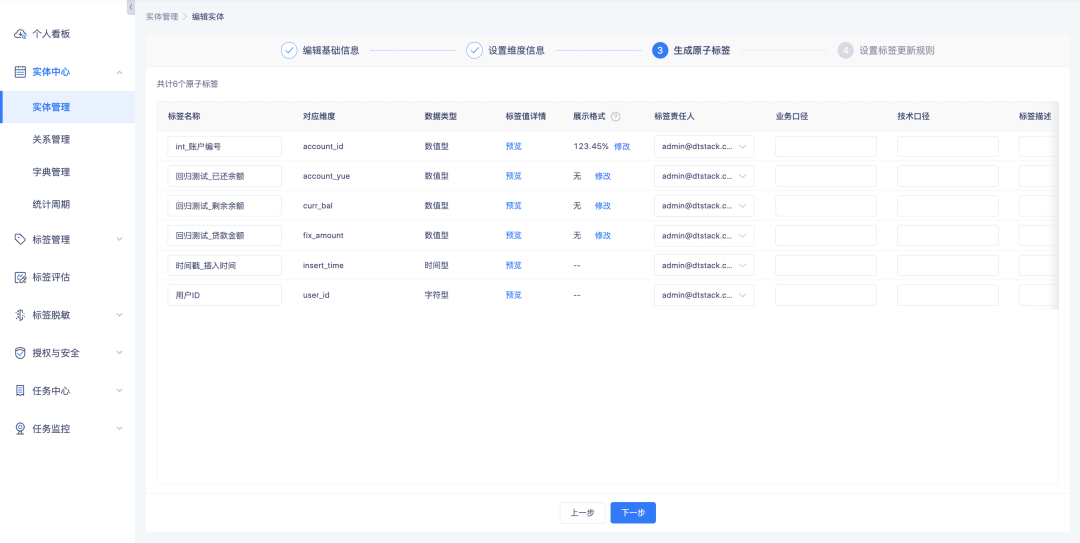
1. 엔터티 생성/편집, 원자 태그 편집, 파생 SQL 태그 생성/편집 시 숫자 태그에 대한 표시 규칙을 설정하는 것이 지원됩니다.
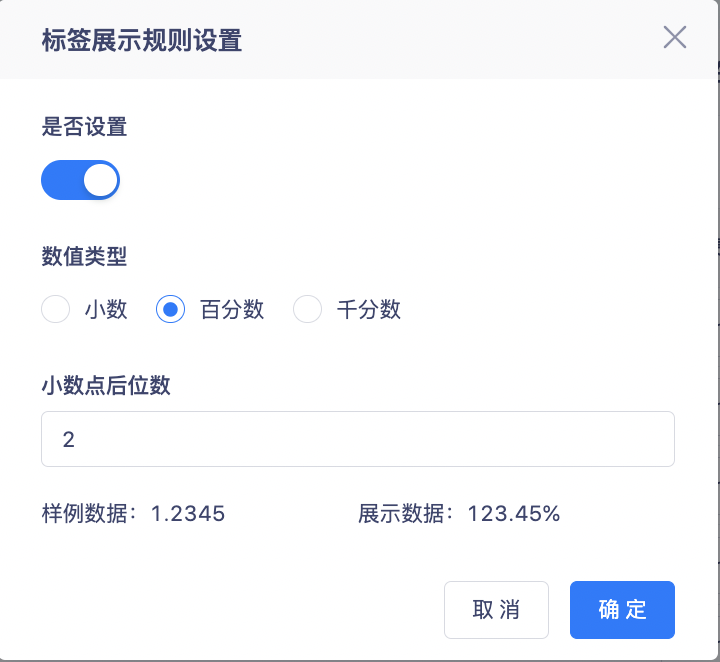
2. 소수점, 백분율, 천분율 표시를 지원하고 소수점 이하 자릿수 설정을 지원합니다.
3. 그룹 관련 페이지에 표시되는 태그 데이터는 설정된 표시 규칙에 따라 표시됩니다.
5. 태그/그룹 파일 업로드는 업로드 진행 상황 보기를 지원합니다.
배경: 현재 파일 가져오기 기능은 진행 메시지 없이 업로드됩니다. 파일이 너무 크면 대기 시간이 길어져 사용자가 페이지가 중단된 것으로 오해하게 되므로 현재 진행 상황을 명확하게 하기 위해 진행 메시지를 추가해야 합니다. 사용자.
새로운 기능에 대한 설명:
1. 레이블, 그룹 파일 업로드 및 오프라인 쿼리 작업 중에 진행률 프롬프트를 추가했습니다.
2. 그룹 파일 업로드가 최대 500M 크기의 파일 업로드를 지원하도록 조정되었습니다.
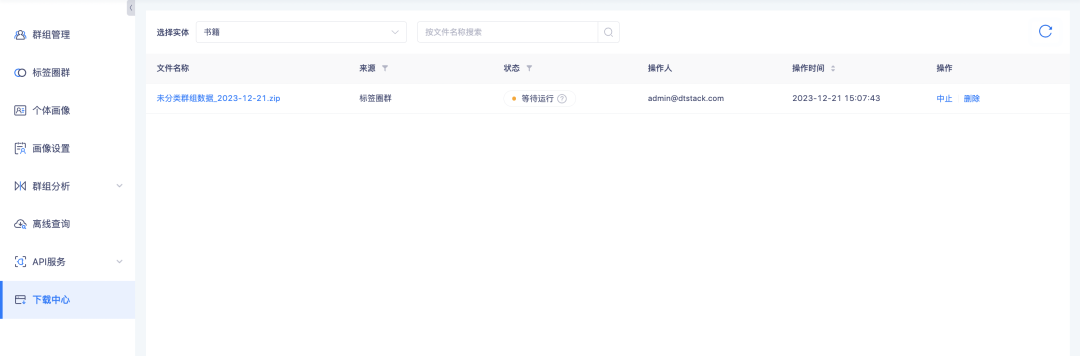
6. 다운로드 센터는 다운로드 진행률 쿼리를 지원합니다.
배경: 데이터 다운로드 프로세스 중 데이터 양이 많기 때문에 데이터를 다운로드하기 전에 데이터를 준비하는 데 오랜 시간이 걸립니다. 사용자는 사용할 때 이를 기대하지 않으며 다운로드 여부를 확인하기 위해 자주 새로 고쳐야 합니다. 수행될 수 있습니다. 사용자가 대기 시간을 결정하도록 안내하려면 다운로드 진행률 프롬프트를 추가해야 합니다.
새로운 기능 설명: 다운로드 센터 작업 상태에 실행 대기 및 중단된 상태가 추가됩니다. 그 중 태그원 그룹-그룹 목록, 그룹 세부정보-그룹 목록, 업로드 로컬 그룹-인스턴스 목록, 오프라인 쿼리-그룹 세부정보-인스턴스 목록, 그룹 교차점 및 차이-인스턴스 목록의 다운로드는 그룹 목록 데이터에 따라 다릅니다. 다운로드 볼륨이 크면 직렬 다운로드 모드로 실행됩니다. 그룹 목록과 관련된 작업은 순차적으로 실행을 위해 대기열에 추가됩니다. 대기열에 추가되지 않은 데이터 볼륨이 있는 다른 다운로드는 직접 실행됩니다. . 작업이 실행되는 동안 더 이상 필요하지 않은 작업을 중단할 수 있습니다.
기능 최적화
1. 다운로드 센터를 통해 파일을 다운로드할 수 있도록 데이터 내보내기가 조정되었습니다.
배경: 일부 페이지의 파일 다운로드가 직접 다운로드되어 버튼이 항상 실행 상태에 있어 사용자가 다운로드 진행 상황을 인식할 수 없습니다.
경험 최적화 설명: 데이터 내보내기와 관련된 버튼을 클릭하면 파일이 비동기적으로 다운로드됩니다. 다운로드가 완료된 후 "다운로드 센터" 모듈에 들어가 데이터 세부 정보를 다운로드할 수 있습니다. 태그 서클 그룹 - 데이터 내보내기, 그룹 세부정보 - 그룹 목록 - 데이터 내보내기, 로컬 그룹 업로드 - 인스턴스 목록 - 데이터 내보내기, 오프라인 쿼리 - 업로드 로컬 그룹/그룹 교차점 및 차이 세부정보 - 데이터 내보내기, 그룹 교차점 및 차이 데이터 내보내기.
데이터의 양이 너무 많은 경우 시스템은 사용자가 설정한 기록 수의 상한선에 따라 별도의 파일로 내보냅니다.
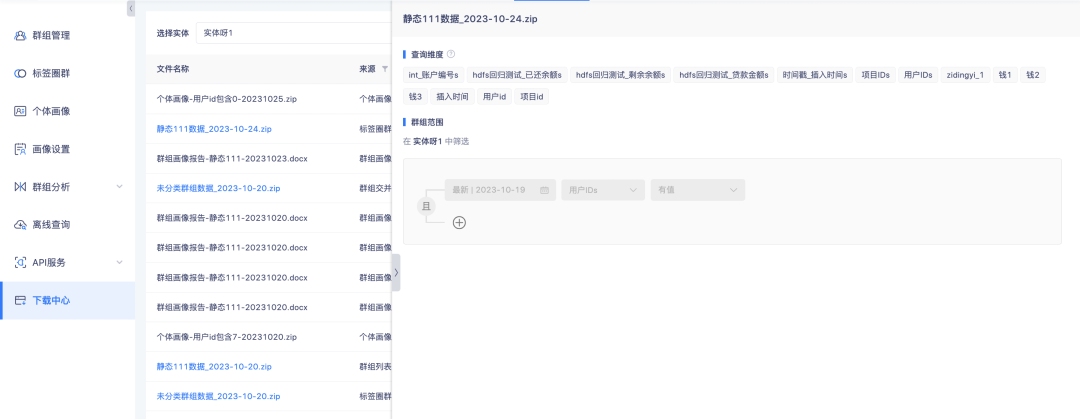
2. 다운로드 센터의 태그 서클 그룹 및 그룹 세부 정보의 목록 데이터는 구성 세부 정보 보기를 지원합니다.
배경: 현재 다운로드 센터에는 파일 소스가 많아 파일명만으로 내용을 구별하는 것이 불편하다. 데이터 가용성을 높이기 위해서는 파일 데이터 소스를 늘려야 한다.
경험 최적화 설명: 태그 서클 그룹 및 그룹 세부 정보 지원 클릭의 데이터를 나열하여 구성 세부 정보를 엽니다.
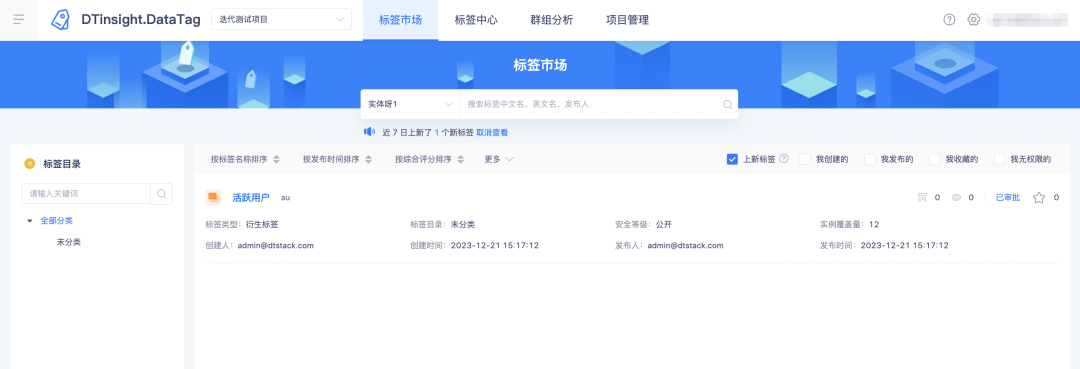
3. 태그 시장의 새로운 태그 기능 최적화
배경: 현재 플랫폼에서는 새로운 태그의 정의를 설명하지 않으며 추가가 필요합니다.
경험 최적화 설명: 플랫폼의 새로운 태그는 지난 24시간으로 정의되지만, 실제 사용 시 사람들은 일반적으로 주말에 해당 태그에 주의를 기울이지 않습니다. 금요일부터 일요일 오전까지는 지난 7일로 정의를 조정하세요.
4. 하위 제품 간 전환 권한 적응 최적화
태그된 제품이 하위 제품 간에 전환되면 페이지의 탭 콘텐츠가 누락됩니다. 이는 권한 문제로 인해 발생합니다. 이 최적화를 통해 제품 간에 페이지를 전환할 때 해당 기능을 사용할 수 있습니다.
5. 열 너비 조정 및 사용자 정의 지원
그룹 목록, 그룹 세부정보-그룹 목록, 태그원 그룹-사용자 목록, 그룹 교차점 및 차이-인스턴스 목록 , 태그 목록 열 너비 사용자 정의를 지원합니다.
열 너비를 사용자 정의한 후에는 현재 브라우저와 현재 로그인한 사용자를 기반으로 후속 사용에 적용됩니다. 사용자가 새 브라우저를 사용하여 로그인하거나 현재 브라우저의 캐시를 지우거나 다시 로그인하면 기본 설정이 표시됩니다.
지표 관리 플랫폼
새로운 기능 업데이트
1. 맞춤형 역할 도킹 비즈니스 센터
배경: 이전에는 역할이 시스템에 내장되어 있어 역할을 추가/수정/삭제할 수 없었으며 역할 권한을 사용자 정의할 수 없었습니다. 기능이 너무 고정되어 고객의 실제 비즈니스 시나리오에 따라 유연하게 조정할 수 없었습니다. .
새로운 기능에 대한 설명:
비즈니스 센터에서 역할과 해당 지표 권한을 구성하면 지표 플랫폼이 쿼리에 대한 권한 구성 결과를 자동으로 소개합니다.
1. 비즈니스 센터에서 새 역할을 추가하고 역할 권한 지점을 구성합니다.
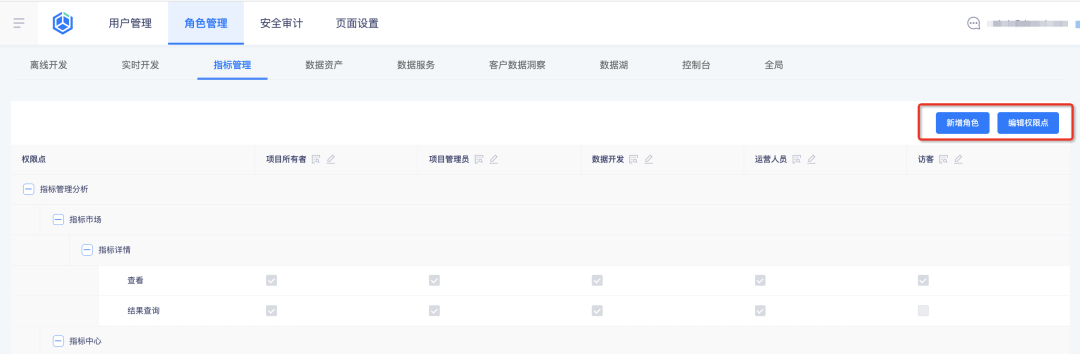
2. 표시기 플랫폼에서 역할 및 해당 권한 포인트 보기
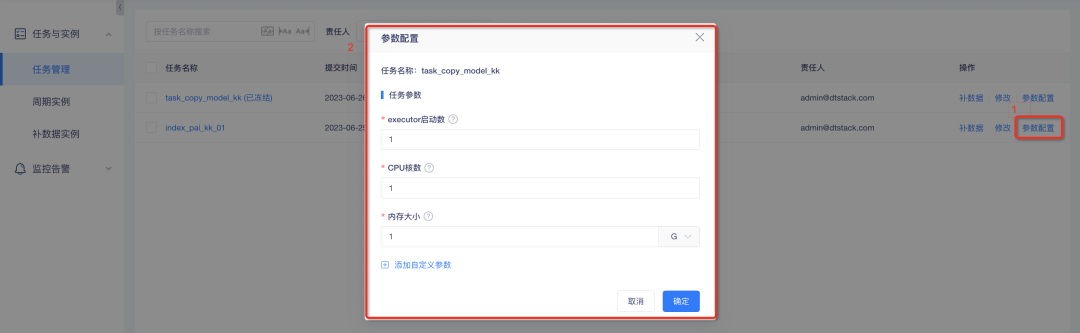
2.Spark 및 데이터 동기화 작업은 사용자 정의 매개변수 구성을 지원합니다.
배경: Spark 작업 및 데이터 동기화 작업의 경우 매개변수 조정은 현재 콘솔을 통해서만 이루어질 수 있습니다. 조정 결과는 전역적으로 적용됩니다. 그러나 표시기 작업 간의 데이터 크기 차이가 크고 동일한 매개변수를 구성하면 낭비가 발생합니다. 따라서 Spark 및 데이터 동기화 작업에 대해 작업 수준 매개변수를 설정하여 작업을 유연하게 제어할 수 있습니다.
새로운 기능에 대한 설명:
1. Spark 작업 사용자 정의 매개변수 구성 : 그중에서 실행기 시작 수, CPU 코어 수 및 메모리 크기가 필요한 사용자 정의 매개변수를 설정할 수 있습니다.
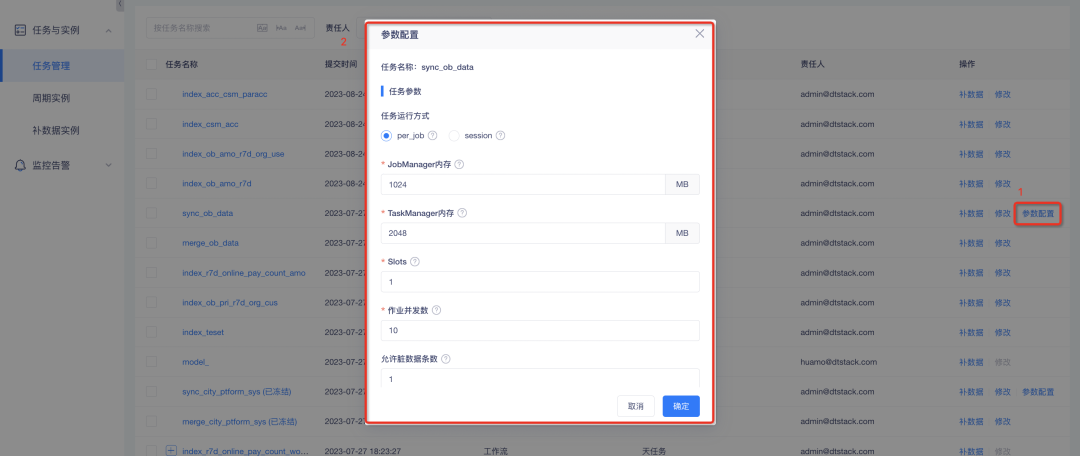
2. 데이터 동기화 작업을 위한 사용자 정의 매개변수 구성 : 작업별 모드에서는 작업 관리자 메모리, 작업 관리자 메모리 및 슬롯이 필요하며 HBase의 WriteBufferSize 사용자 정의 매개변수를 설정할 수 있습니다.
기능 최적화
1. 브라우저는 동시에 여러 프로젝트 열기를 지원합니다.
배경: 기록 기능에서 쿠키는 프로젝트 매개변수를 저장하지 않습니다. 따라서 데이터 스택이 새 프로젝트 창을 열면 기록 창의 내용이 새로 고쳐지고 사용자는 프로젝트의 프로젝트 목록 페이지로 돌아갑니다. 고객의 사용에 영향을 미치는 선택입니다.
경험 최적화 설명: 이 최적화는 브라우저가 쿼리, 작업 등을 위해 동시에 여러 프로젝트를 열 수 있도록 지원하여 제품 사용 효율성을 향상시킵니다.
2.edge 브라우저 호환
egde 브라우저와 호환되므로 주류 브라우저에서 제품의 유용성을 향상시키기 위해 기능이 적절하게 조정될 것입니다.
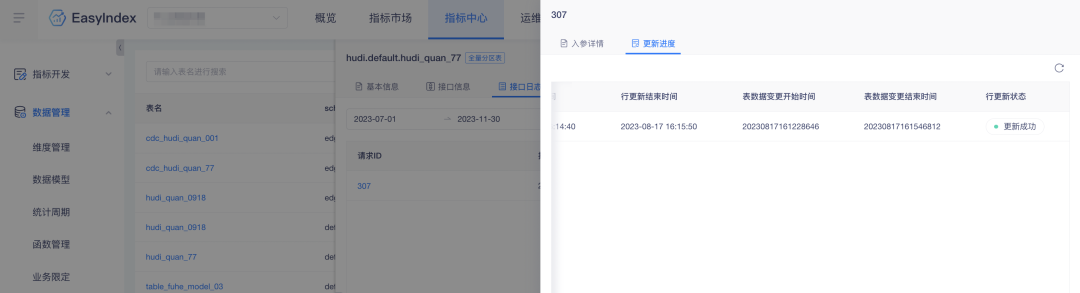
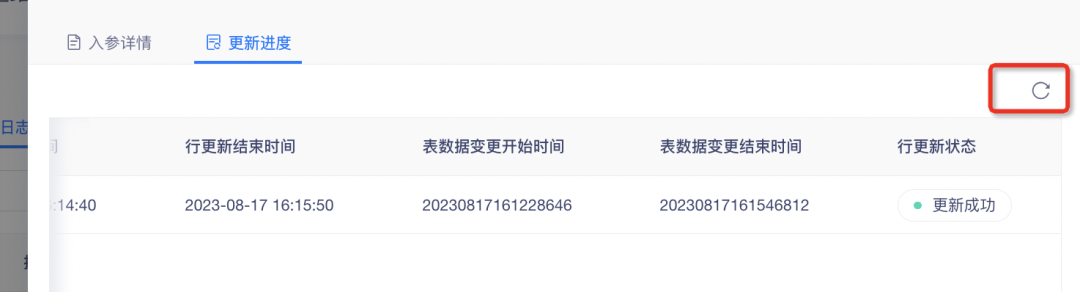
3. 행 업데이트 보충 테이블 업데이트 시간
배경: 행 업데이트 데이터 레코드에는 테이블 데이터 변경 기간이 부족하여 데이터 검색이 불편합니다. 데이터 검색의 효율성을 높이기 위해 관련 데이터가 플랫폼에 추가됩니다.
경험 최적화 설명: 표시기 행 업데이트에 테이블 데이터 변경 시작 시간과 종료 시간이 추가됩니다.
4. 행 업데이트 상태에 수동 새로 고침 기능 추가
행 업데이트 프로세스 중에 업데이트 진행 상황을 시기적절하게 후속 조치할 수 있도록 페이지에 새로 고침 버튼이 추가되어 새로 고침 효율성이 향상됩니다.
5. 모델이 채워진 차원 객체 및 차원 속성 함수의 최적화
모델을 편집할 때 차원 정보를 설정하는 단계에서 사용자가 기록 버전에서 관련 차원을 수정했고 주의를 기울이지 않은 경우 시스템은 기본적으로 기본 차원 테이블 필드에 바인딩된 차원 정보를 다시 채웁니다. 편집 과정에서 조정하면 잘못된 데이터가 저장됩니다. 데이터 오류율을 방지하기 위해 이전 버전에 저장된 정보를 반영하도록 조정되었습니다.
6. API 게이트웨이는 사용자 지정 접두사를 지원합니다.
표시기의 접두사 정보는 현재 API의 구성 항목에 기록됩니다. 동시에 API에는 API 구성 유연성을 향상시키기 위한 사용자 지정 접두사 기능이 있습니다. 이때 표시기의 API 구성 항목이 API 사용자 지정 접두사와 일치하지 않는 경우 데이터를 정상적으로 호출할 수 없으므로 전역 구성이 고유하도록 도킹 API의 구성 설정에 맞게 조정해야 합니다.
"Dutstack 제품 백서" 다운로드 주소: https://www.dtstack.com/resources/1004?src=szsm
"데이터 거버넌스 산업 실무 백서" 다운로드 주소: https://www.dtstack.com/resources/1001?src=szsm
빅데이터 제품, 산업 솔루션, 고객 사례에 대해 더 알고 싶거나 상담하고 싶은 분들은 Kangaroo Cloud 공식 홈페이지( https://www.dtstack.com/?src=szkyzg )를 방문해 주세요.
Linus는 커널 개발자가 탭을 공백으로 대체하는 것을 막기 위해 스스로 노력했습니다. 그의 아버지는 코드를 작성할 수 있는 몇 안되는 리더 중 한 명이고, 둘째 아들은 오픈 소스 기술 부서의 책임자이며, 막내 아들은 오픈 소스 코어입니다. 기고자 Robin Li: 자연 언어 는 새로운 범용 프로그래밍 언어가 될 것입니다. 오픈 소스 모델은 Huawei에 비해 점점 더 뒤쳐질 것입니다 . 일반적으로 사용되는 5,000개의 모바일 애플리케이션을 Hongmeng으로 완전히 마이그레이션하는 데 1년이 걸릴 것입니다. 타사 취약점. 기능, 안정성 및 개발자의 경험이 크게 개선된 Quill 2.0 이 출시되었습니다. Ma Huateng과 Zhou Hongyi는 "원한을 제거하기 위해" 공식적으로 출시되었습니다. Laoxiangji의 소스는 코드가 아닙니다. Google이 대규모 구조 조정을 발표한 이유는 매우 훈훈합니다.