
저자|Invisible(Xing Ying), NetEase 선임 데이터베이스 커널 엔지니어
편집 및 마무리|SelectDB 기술팀
소개: NetEase의 중요한 비즈니스 라인인 Lingxi Office와 Yunxin은 각각 Lingxi Eagle 모니터링 플랫폼과 Yunxin 데이터 플랫폼을 구축하여 대규모 로그/시계열 데이터 처리 및 분석 문제를 해결했습니다. 이 기사 에서는 NetEase 로그 및 시계열 시나리오에서 Apache Doris를 적용하는 방법과 Elasticsearch 및 InfluxDB를 대체하기 위해 Apache Doris를 사용하여 Elasticsearch와 비교하여 더 낮은 서버 리소스와 더 높은 쿼리 성능 경험을 달성하는 방법에 중점을 둘 것입니다. 최소 11배 향상되어 최대 70%까지 스토리지 리소스가 절약됩니다.
정보기술의 급속한 발전으로 기업 데이터의 양이 폭발적으로 증가했습니다. NetEase와 같은 대규모 인터넷 회사의 경우 내부 사무실 시스템이든 외부에서 제공되는 서비스이든 매일 대량의 로그와 시계열 데이터가 생성됩니다. 이러한 데이터는 문제 해결, 문제 진단, 보안 모니터링, 위험 경고, 사용자 행동 분석 및 경험 최적화를 위한 중요한 초석이 되었습니다. 이러한 데이터의 가치를 최대한 활용하면 제품 신뢰성, 성능, 안전성 및 사용자 만족도를 향상시키는 데 도움이 됩니다.
NetEase의 중요한 비즈니스 라인인 Lingxi Office와 Yunxin은 대규모 로그/시계열 데이터 처리 및 분석으로 인한 과제에 대처하기 위해 각각 Lingxi Eagle 모니터링 플랫폼과 Yunxin 데이터 플랫폼을 구축했습니다. 사업이 지속적으로 확장되면서 로그/시계열 데이터도 기하급수적으로 늘어나 스토리지 비용 증가, 쿼리 시간 연장, 시스템 안정성 저하 등의 문제가 발생하고 있습니다. 초기 플랫폼은 지속 가능하지 않았기 때문에 NetEase는 더 나은 솔루션을 찾게 되었습니다.
이 기사에서는 NetEase 로그 및 시계열 시나리오에서 Apache Doris 구현에 중점을 두고 NetEase Lingxi Office 및 NetEase Cloud Letter 비즈니스에서 Apache Doris의 아키텍처 업그레이드 사례를 소개하고 테이블 생성, 가져오기, 쿼리 등의 경험을 공유합니다. 실제 시나리오를 기반으로 한 튜닝 계획입니다.
초기 아키텍처 및 문제점
01 Lingxi-Eagle 모니터링 플랫폼
NetEase Lingxi Office는 차세대 이메일 협업 오피스 플랫폼입니다. 이메일, 캘린더, 클라우드 문서, 인스턴트 메시징, 고객 관리 등의 모듈을 통합합니다. Eagle 모니터링 플랫폼은 NetEase Lingxi Office에 대한 다차원적이고 다양한 세부 성능 분석을 제공할 수 있는 풀 링크 APM 시스템입니다.
Eagle 모니터링 플랫폼은 주로 Lingxi Office, Enterprise Email, Youdao Cloud Notes, Lingxi Documents 등의 비즈니스 로그 데이터를 저장하고 분석합니다. 로그 데이터는 먼저 Logstash를 통해 수집 및 처리된 후 실시간 로그를 수행하는 Elasticsearch에 저장됩니다. 검색 및 분석 또한 Lingxi Office에 대한 로그 검색 및 전체 링크 로그 쿼리 서비스를 제공합니다.

시간이 흐르고 로그 데이터가 증가함에 따라 Elasticsearch를 사용하는 과정에서 몇 가지 문제가 점차 드러나게 됩니다.
- 높은 쿼리 대기 시간: 일일 쿼리에서 Elasticsearch의 평균 응답 대기 시간이 길어 사용자 경험에 영향을 미칩니다. 이는 주로 데이터 크기, 인덱스 설계의 합리성, 하드웨어 리소스 등의 요인에 의해 제한됩니다.
- 높은 스토리지 비용: 비용 절감 및 효율성 향상의 맥락에서 기업은 스토리지 비용을 절감해야 하는 필요성이 점점 더 시급해지고 있습니다. 그러나 Elasticsearch에는 정행(forward row), 역행(inverted row), 열 저장(column Storage) 등 여러 데이터 저장소가 있기 때문에 데이터 중복 정도가 높아 비용 절감 및 효율성 향상에 대한 특정 과제가 발생합니다.
02 Yunxin-데이터 플랫폼
NetEase Yunxin은 NetEase의 26년간의 기술을 기반으로 구축된 융합 커뮤니케이션 및 클라우드 네이티브 PaaS 서비스 전문가로 IM 인스턴트 메시징, 비디오 클라우드, SMS, Qingzhou 마이크로서비스 및 미들웨어 PaaS를 포함한 융합 커뮤니케이션 및 클라우드 네이티브 핵심 제품 및 솔루션을 제공합니다. . 기다리다.
Yunxin 데이터 플랫폼은 주로 IM, RTC, SMS 및 기타 서비스에서 생성된 시계열 데이터를 분석합니다. 초기 데이터 아키텍처는 주로 시계열 데이터베이스인 InfluxDB를 기반으로 구축되었으며, 데이터 소스는 먼저 Kafka 메시지 큐를 통해 보고되었으며, 필드 구문 분석 및 정리 후 시계열 데이터베이스 InfluxDB에 저장되어 온라인 및 오프라인 쿼리를 제공했습니다. 오프라인 측은 오프라인 T+1 데이터 분석을 지원하고, 실시간 측은 지표 모니터링 보고서 및 청구서의 실시간 생성을 제공해야 합니다.
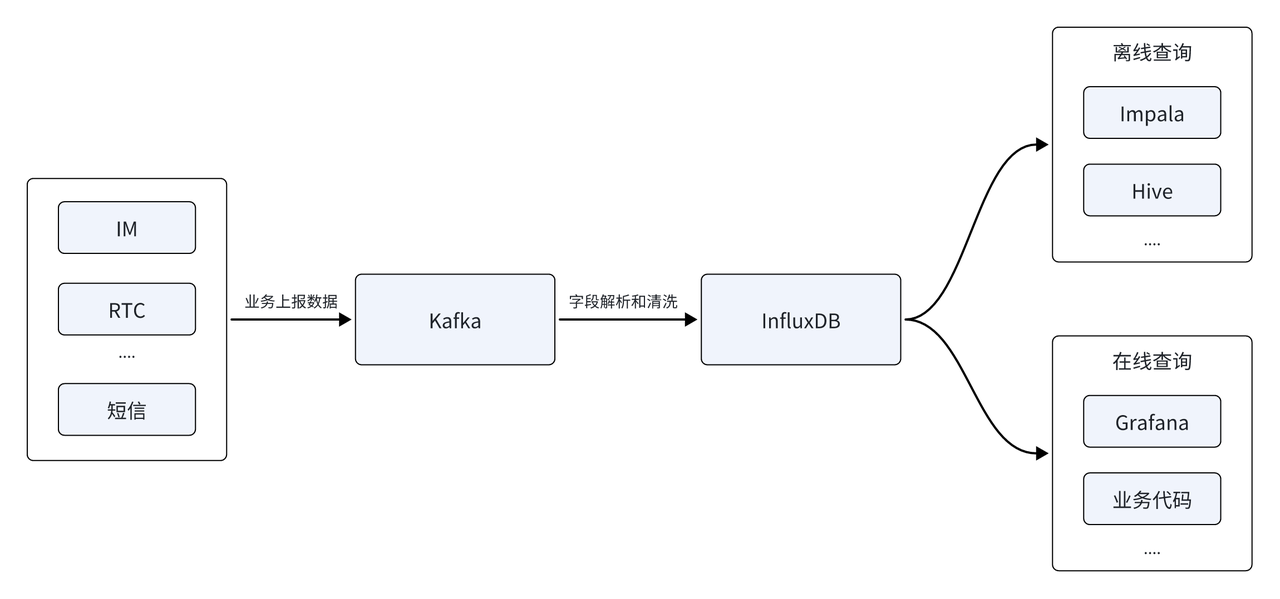
고객 규모가 빠르게 확대되면서 보고된 데이터 소스의 수가 계속 증가하고 있으며 InfluxDB도 일련의 새로운 과제에 직면해 있습니다.
- 메모리 오버플로 OOM: 데이터 소스가 많아질수록 여러 데이터 소스를 기반으로 오프라인 분석을 수행해야 하므로 분석의 난이도가 높아집니다. InfluxDB의 쿼리 기능에 의해 제한되는 현재 아키텍처는 여러 데이터 소스의 복잡한 쿼리에 직면할 때 메모리 부족(OOM)을 일으킬 수 있으며, 이는 비즈니스 가용성과 시스템 안정성에 큰 문제를 야기합니다.
- 높은 스토리지 비용: 비즈니스 발전으로 인해 클러스터 데이터 볼륨도 지속적으로 증가했으며, 클러스터 내 데이터의 상당 부분은 콜드 데이터입니다. 핫 데이터와 콜드 데이터가 동일한 방식으로 저장되어 스토리지 비용이 높아집니다. 이는 비용 절감과 양립할 수 없으며 효과적인 기업 목표와의 충돌을 증가시킵니다.
핵심 엔진 선택
이러한 이유로 NetEase는 로그 타이밍 시나리오에서 위의 두 주요 비즈니스가 직면한 문제를 해결하는 것을 목표로 새로운 데이터베이스 솔루션을 찾기 시작했습니다. 동시에 NetEase는 단 하나의 데이터베이스를 사용하여 두 가지 주요 응용 프로그램 시나리오의 비즈니스 시스템 및 기술 아키텍처에 적응하여 극도의 사용 용이성과 낮은 투자라는 업그레이드 요구 사항을 충족하기를 희망합니다. 이와 관련하여 Apache Doris는 특히 다음 측면에서 선택 요구 사항을 충족합니다.
- 스토리지 비용 최적화 : Apache Doris는 중복 스토리지를 줄이기 위해 스토리지 구조를 많이 최적화했습니다. 압축률이 더 높고 S3 및 NOS(Netease Object Storage) 기반의 핫 및 콜드 계층형 스토리지를 지원하므로 스토리지 비용을 효과적으로 절감하고 데이터 스토리지 효율성을 향상시킬 수 있습니다.
- 높은 처리량 및 고성능 : Apache Doris는 컬럼형 스토리지 고성능 디스크 쓰기, 순차적 압축 및 스트림 로드 효율적인 스트리밍 가져오기를 지원하며 초당 수십 GB의 데이터 쓰기를 지원할 수 있습니다. 이는 로그 데이터의 대규모 쓰기를 보장할 뿐만 아니라 지연 시간이 짧은 쿼리 가시성을 제공합니다.
- 실시간 로그 검색 : Apache Doris는 로그 텍스트의 전체 텍스트 검색을 지원할 뿐만 아니라 실시간 쿼리 응답도 지원합니다. Doris는 내부적으로 문자열 유형의 전체 텍스트 검색과 일반 숫자/날짜 유형의 범위 검색을 충족할 수 있는 반전 인덱스 추가를 지원합니다. 동시에 반전 인덱스의 쿼리 성능을 더욱 최적화하고 더 많이 만들 수 있습니다. 로그 데이터 분석 요구 사항에 적합합니다.
- 대규모 테넌트 격리 지원 : Doris는 수천 개의 데이터베이스와 수만 개의 데이터 테이블을 호스팅할 수 있으며, 하나의 테넌트가 하나의 데이터베이스를 독립적으로 사용할 수 있도록 하여 다중 테넌트 데이터 격리 요구 사항을 충족하고 데이터 개인 정보 보호 및 보안을 보장할 수 있습니다.
또한 작년에 Apache Doris는 로그 시나리오를 지속적으로 탐구하고 효율적인 역 인덱스, 유연한 Variant 데이터 유형 등과 같은 일련의 핵심 기능을 출시하여 로그/시간에 대한 더 나은 처리 및 분석을 제공했습니다. 시리즈 데이터 효율적이고 유연한 솔루션 . 위의 장점을 바탕으로 NetEase는 마침내 Apache Doris를 새로운 아키텍처의 핵심 엔진으로 도입하기로 결정했습니다.
Apache Doris 기반의 통합 로그 저장 및 분석 플랫폼
01 Lingxi-Eagle 모니터링 플랫폼

첫째, Lingxi Office-Eagle 모니터링 플랫폼에서 NetEase는 Elasticsearch를 Apache Doris로 성공적으로 업그레이드하여 통합 로그 저장 및 분석 플랫폼을 구축했습니다. 이번 아키텍처 업그레이드는 플랫폼의 성능과 안정성을 크게 향상시킬 뿐만 아니라 강력하고 효율적인 로그 검색 서비스도 제공합니다. 구체적인 이점은 다음에 반영됩니다.
- 저장소 자원이 70% 절약됩니다. Doris 컬럼 저장소와 ZSTD의 높은 압축률 덕분에 Elasticsearch는 동일한 로그 데이터를 저장하려면 100T의 저장소 공간이 필요하지만 Doris에 저장하려면 30T의 저장소 공간만 필요하므로 70T가 절약됩니다. 스토리지 리소스의 %입니다 . SSD는 저장 공간이 크게 절약되므로 동일한 비용으로 HDD 대신 핫 데이터를 저장하는 데 사용할 수 있으며 쿼리 성능도 크게 향상됩니다.
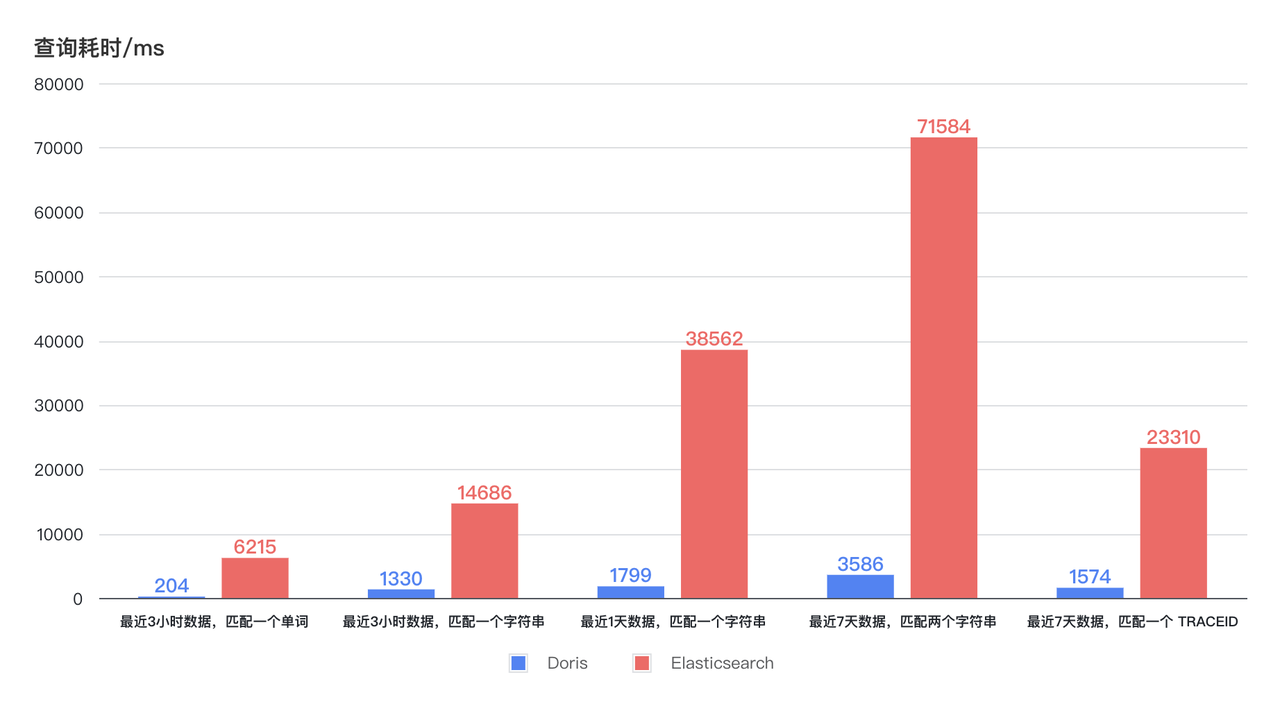
- 쿼리 속도가 11배 향상됩니다. 새로운 아키텍처는 CPU 리소스 소비를 낮추면서 쿼리 효율성을 수십 배 향상시킵니다. 아래 다이어그램에서 볼 수 있듯이 지난 3시간, 1일, 7일 동안 로그 검색을 위한 Doris 쿼리 시간은 4초 미만으로 안정적으로 유지되며 가장 빠른 응답은 1초 이내가 될 수 있습니다. Elasticsearch의 쿼리 시간은 가장 긴 시간이 최대 75초, 가장 짧은 시간도 6~7초가 걸리는 등 큰 변동을 보입니다. 리소스 사용량이 낮을수록 Doris의 쿼리 효율성은 Elasticsearch의 쿼리 효율성보다 최소 11배 더 높습니다 .
02 Yunxin-데이터 플랫폼
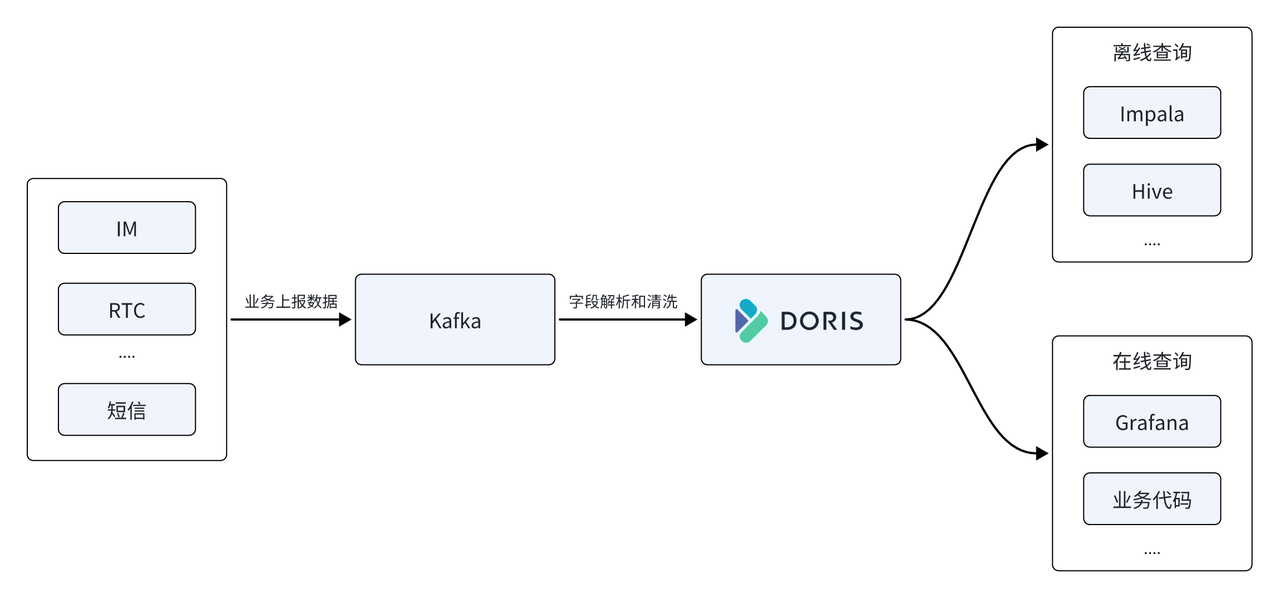
Yunxin 데이터 플랫폼에서 NetEase는 Apache Doris를 사용하여 초기 아키텍처의 시계열 데이터베이스 InfluxDB를 대체하고 이를 데이터 플랫폼의 핵심 스토리지 및 컴퓨팅 엔진으로 사용하며 Apache Doris는 통합 오프라인 및 실시간 쿼리 서비스를 제공합니다.
- 높은 처리량 쓰기 지원: 평균 온라인 쓰기 트래픽 500M/s, 최대 1GB/s, InfluxDB는 22개의 서버를 사용하고 CPU 리소스 사용량은 약 50%인 반면 Doris는 11개의 시스템만 사용하며 CPU 사용량은 약 50%입니다. , 전체 리소스 소비는 이전 리소스의 1/2에 불과합니다 .
- 스토리지 리소스 67% 절약: 11개의 Doris 물리적 머신을 사용하여 22개의 InfluxDB를 대체했습니다. 동일한 데이터 규모를 저장하려면 InfluxDB에는 150T의 스토리지 공간이 필요한 반면, Doris에 저장하려면 50T의 스토리지 공간만 필요하므로 스토리지 리소스가 67% 절약됩니다 .
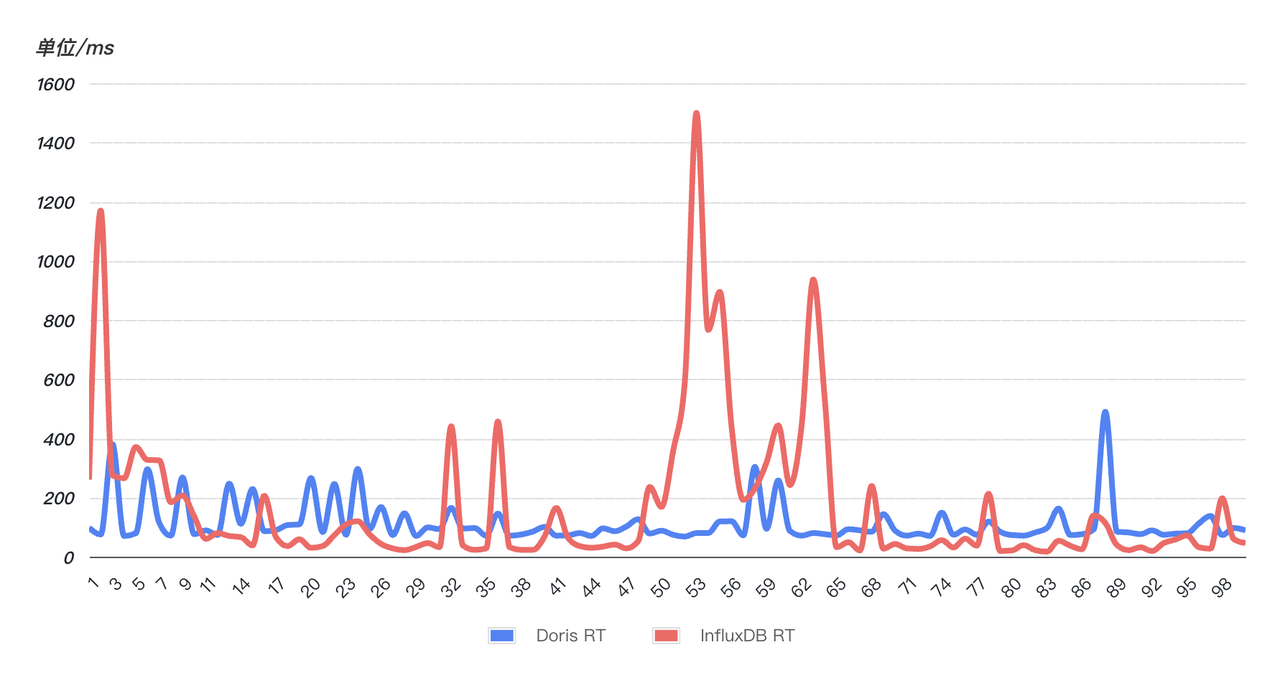
- 쿼리 응답이 빠르고 안정적임: 쿼리 응답 속도를 확인하기 위해 온라인 SQL을 무작위로 선택(지난 10분간의 문자열과 일치)하여 해당 SQL을 99회 연속 쿼리했습니다. 아래 그림에서 볼 수 있듯이 Doris(파란색)의 쿼리 성능은 InfluxDB(빨간색)보다 안정적입니다. 99개의 쿼리는 비교적 안정적이며 뚜렷한 변동이 없습니다 . 그러나 InfluxD는 여러 번의 비정상적인 변동을 경험했습니다. 쿼리 시간이 급증하여 쿼리 안정성에 심각한 영향을 미쳤습니다.
연습과 튜닝
비즈니스 구현 과정에서 NetEase도 몇 가지 문제와 과제에 직면했습니다. 저는 이 기회를 빌어 이러한 귀중한 최적화 경험을 정리하고 공유하여 모든 사람의 사용에 대한 지침과 도움을 제공하고 싶습니다.
01 테이블 생성 최적화
데이터베이스 스키마 디자인은 성능에 매우 중요하며 이는 로그 및 시계열 데이터를 처리할 때 예외는 아닙니다. Apache Doris는 이 두 가지 시나리오에 대해 몇 가지 특수한 최적화 옵션을 제공하므로 테이블 생성 중에 이러한 최적화 옵션을 활성화하는 것이 중요합니다. 실제로 우리가 사용하는 구체적인 최적화 옵션은 다음과 같습니다.
- DATETIME 유형의 시간 필드를 기본 키로 사용하면 최신 n개 로그를 쿼리하는 속도가 크게 향상됩니다.
- 시간 필드를 기반으로 한 RANGE 파티셔닝을 사용하고 동적 Partiiton을 활성화하여 매일 자동으로 파티션을 관리함으로써 데이터 쿼리 및 관리의 유연성을 향상시킵니다.
- 버킷팅 전략은 랜덤 버킷팅을 위해 RANDOM을 사용할 수 있으며, 버킷 수는 대략 클러스터 디스크 전체 수의 3배로 설정된다.
- 자주 쿼리되는 필드의 경우 쿼리 효율성을 높이기 위해 인덱스를 구축하는 것이 좋으며, 전체 텍스트 검색이 필요한 필드의 경우 검색의 정확성과 효율성을 보장하기 위해 적절한 단어 분할기 매개 변수 구문 분석기를 지정해야 합니다.
- 로그 및 시계열 시나리오의 경우 특별히 최적화된 시계열 압축 전략이 사용됩니다.
- ZSTD 압축을 사용하면 더 나은 압축 효과를 얻고 저장 공간을 절약할 수 있습니다.
CREATE TABLE log
(
ts DATETIME,
host VARCHAR(20),
msg TEXT,
status INT,
size INT,
INDEX idx_size (size) USING INVERTED,
INDEX idx_status (status) USING INVERTED,
INDEX idx_host (host) USING INVERTED,
INDEX idx_msg (msg) USING INVERTED PROPERTIES("parser" = "unicode")
)
ENGINE = OLAP
DUPLICATE KEY(ts)
PARTITION BY RANGE(ts) ()
DISTRIBUTED BY RANDOM BUCKETS 250
PROPERTIES (
"compression"="zstd",
"compaction_policy" = "time_series",
"dynamic_partition.enable" = "true",
"dynamic_partition.create_history_partition" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-7",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "250"
);
02 클러스터 구성 최적화
FE 구성
# 开启单副本导入提升导入性能
enable_single_replica_load = true
# 更加均衡的tablet分配和balance测量
enable_round_robin_create_tablet = true
tablet_rebalancer_type = partition
# 频繁导入相关的内存优化
max_running_txn_num_per_db = 10000
streaming_label_keep_max_second = 300
label_clean_interval_second = 300
BE 구성
write_buffer_size=1073741824
max_tablet_version_num = 20000
max_cumu_compaction_threads = 10(cpu的一半)
enable_write_index_searcher_cache = false
disable_storage_page_cache = true
enable_single_replica_load = true
streaming_load_json_max_mb=250
03 스트림 로드 임포트 튜닝
비즈니스 피크 기간 동안 Yunxin 데이터 플랫폼은 100만 개가 넘는 쓰기 TPS와 1GB/s의 쓰기 트래픽에 직면하며 이는 의심할 여지 없이 시스템 성능에 대한 요구가 매우 높습니다. 그러나 비즈니스 측면에는 소규모 동시 테이블이 많고 쿼리 측면에서는 데이터에 대한 실시간 요구 사항이 매우 높기 때문에 배치 처리를 짧은 시간 내에 충분히 큰 배치로 누적하는 것은 불가능합니다. 비즈니스 당사자와 공동으로 일련의 최적화를 수행한 후에도 Stream Load는 여전히 Kafka에서 데이터를 신속하게 소비할 수 없어 Kafka의 데이터 백로그가 점점 심각해지고 있습니다.
심층 분석 결과, 비즈니스 피크 기간 동안 비즈니스 측의 데이터 가져오기 프로그램에서 CPU 및 메모리 리소스의 과도한 점유로 인해 성능 병목 현상이 발생한 것으로 나타났습니다. 그러나 Doris 측의 성능은 아직 큰 병목 현상이 나타나지 않았지만 Stream Load의 응답 시간은 뚜렷한 상승 추세를 보이고 있습니다.
비즈니스 프로그램이 Stream Load를 동기식으로 호출하므로 이는 Stream Load의 응답 속도가 전체 데이터 처리 효율성에 직접적인 영향을 미친다는 것을 의미합니다. 따라서 단일 스트림 로드의 응답 시간을 효과적으로 줄일 수 있다면 전체 시스템의 처리량은 크게 향상될 것입니다.
Apache Doris 커뮤니티의 학생들과 대화한 후 Doris가 로그 및 타이밍 시나리오에 대해 두 가지 중요한 가져오기 성능 최적화를 시작했다는 사실을 알게 되었습니다.
- 단일 복사본 가져오기: 먼저 하나의 복사본에 쓰고 다른 복사본은 첫 번째 복사본에서 데이터를 가져옵니다. 이 방법을 사용하면 여러 복사본의 반복적인 정렬 및 색인 작성으로 인해 발생하는 오버헤드를 피할 수 있습니다.
- 단일 태블릿 가져오기: 일반 모드에서 여러 태블릿에 데이터를 분산시키는 쓰기 방식과 비교하여 한 번에 하나의 태블릿에만 쓰는 전략을 채택할 수 있습니다. 이 최적화는 쓰기 중에 생성되는 작은 파일 수와 IO 오버헤드를 줄여 전반적인 가져오기 효율성을 향상시킵니다. 이 기능은 가져오는 동안
load_to_single_tablet매개변수를 로 설정하여 활성화할 수 있습니다.true
위의 방법을 사용하여 최적화한 후 가져오기 성능이 크게 향상되었습니다.
- Kafka 소비 속도가 2배 이상 증가합니다.
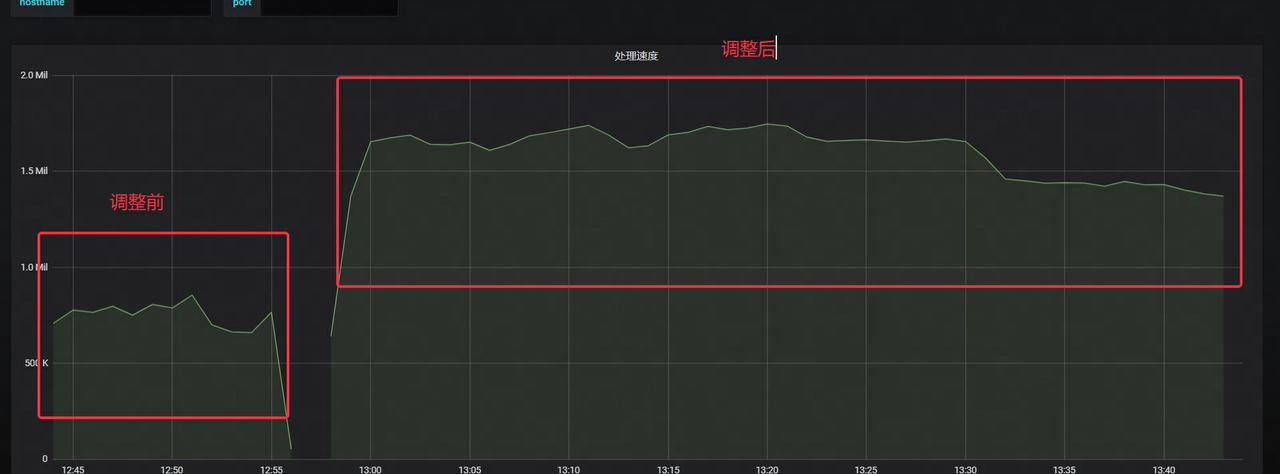
- Kafka의 대기 시간은 원래 시간의 1/4로 크게 감소했습니다.
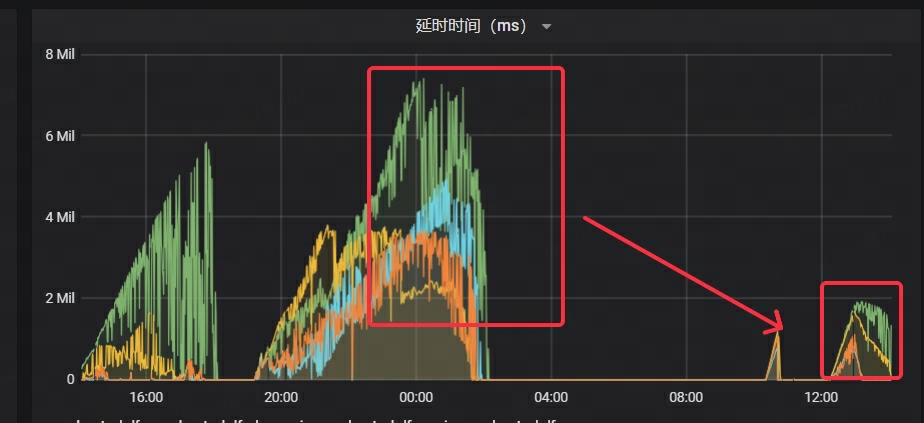
- 스트림 로드의 RT가 약 70% 감소합니다.
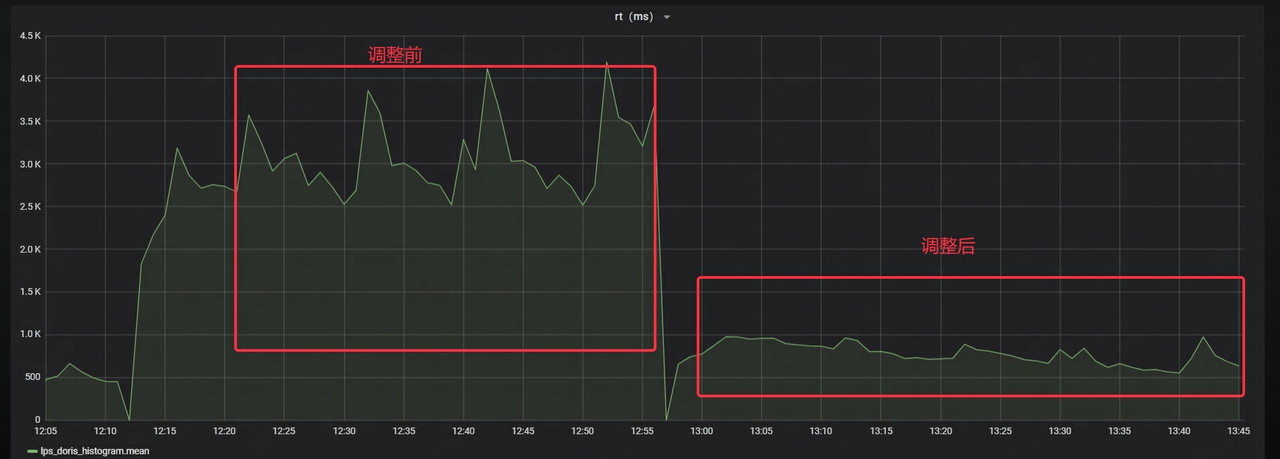
NetEase는 또한 공식 출시 전에 엄격한 스트레스 테스트와 그레이스케일 시험 운영을 수행했으며 지속적인 최적화 작업을 거쳐 마침내 시스템이 대규모 시나리오에서 온라인으로 안정적으로 실행될 수 있도록 보장하여 비즈니스에 강력한 지원을 제공했습니다.
1. 스트림 로드 시간 초과:
스트레스 테스트 초기에는 데이터 가져오기의 잦은 타임아웃 및 오류 보고 문제가 있었고, 프로세스 및 클러스터 상태가 정상일 때에는 모니터링에서 BE의 Metrics 데이터를 정상적으로 수집할 수 없었습니다.
Pstack을 통해 Doris BE의 스택을 획득하고, PT-PMT를 사용하여 스택을 분석합니다. 주된 이유는 클라이언트가 요청을 시작할 때 HTTP Chunked 인코딩이나 Content-Length가 설정되지 않아 Doris가 데이터 전송이 아직 종료되지 않았다고 잘못 믿고 대기 상태에 머물렀던 것으로 나타났습니다. 상태. 클라이언트에 청크 인코딩 설정을 추가한 후 데이터 가져오기가 정상으로 돌아왔습니다.
2. Stream Load가 한 번에 가져오는 데이터의 양이 임계값을 초과합니다.
streaming_load_json_max_mb매개변수를 250M(기본값 100M)로 늘리면 문제가 해결됩니다.
3. 사본 부족 및 쓰기 오류: alive replica num 0 < quorum replica num 1
show backends한 BE의 상태가 비정상이고 OFFLINE으로 표시되는 것으로 확인되었습니다 . 해당 be_custom구성 파일을 확인하고 존재하는지 확인하십시오 broken_storage_path. BE 로그를 추가로 조사한 결과 "열린 파일이 너무 많습니다"라는 오류 메시지가 나타났습니다. 이는 BE 프로세스에서 열린 파일 핸들 수가 시스템에서 설정한 최대값을 초과하여 IO 작업이 실패했음을 의미합니다.
Doris 시스템은 이 이상 현상을 감지하면 디스크를 사용할 수 없는 것으로 표시합니다. 싱글 카피 전략으로 테이블을 구성하다 보니, 유일한 카피가 있는 디스크에 문제가 생기면 카피 수가 부족해 데이터 쓰기를 계속할 수 없게 된다.
따라서 프로세스 FD의 최대 오픈 제한을 100만개로 조정하고 be_custom.conf구성 파일을 삭제한 후 BE 노드를 다시 시작하여 마침내 서비스가 정상 작동을 재개했습니다.
4. FE 메모리 지터
비즈니스 그레이스케일 테스트 중 FE에 연결할 수 없는 문제가 발생했습니다. 모니터링 데이터를 확인한 결과, JVM 32G 메모리가 소진되었으며, FE 메타 디렉터리의 bdb 파일 디렉터리가 비정상적으로 50G로 확장된 것으로 확인됐다.
비즈니스에서는 동시에 스트림 로드 데이터 가져오기 작업을 수행해 왔으며 FE는 가져오기 프로세스 중에 관련 로드 정보를 기록하므로 각 가져오기에서 생성되는 메모리 정보는 약 200K입니다. 이러한 메모리 정보의 정리 시간은 streaming_label_keep_max_second매개변수에 의해 제어됩니다. 기본값은 12시간입니다. 5분으로 조정하면 FE 메모리가 소진되지 않습니다. 그러나 일정 시간 동안 실행하면 메모리가 소진되는 것으로 나타났습니다. 1시간 주기에 따라 지터가 발생하고 최대 메모리 사용량이 80%에 도달합니다. 코드를 분석한 결과 레이블을 정리하는 스레드가 label_clean_interval_second매번 실행되는 것을 발견했습니다. 기본값은 1시간으로 조정한 후 FE 메모리가 매우 안정적입니다.
04 쿼리 튜닝
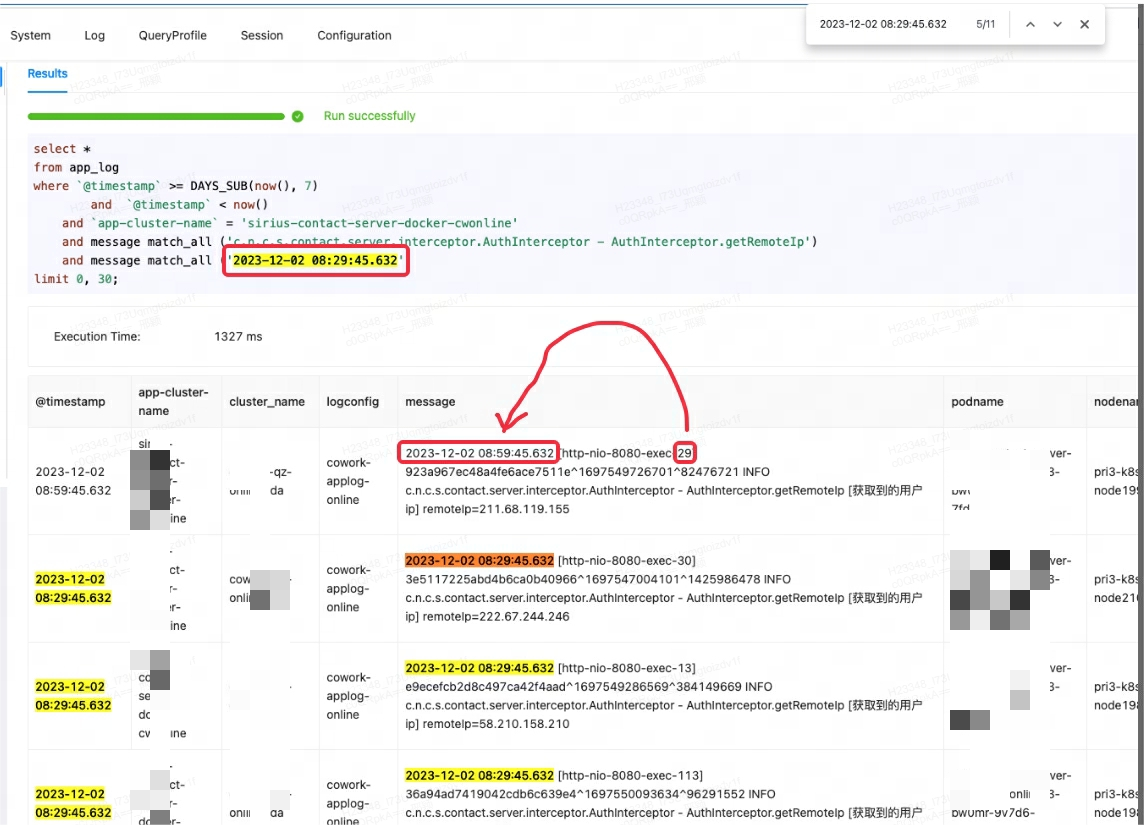
Lingxi-Eagle 모니터링 플랫폼이 쿼리 테스트를 수행할 때 일치 조건을 충족하지 않는 결과를 읽은 것으로 의심되었습니다. 이러한 현상은 예상한 검색 논리를 분명히 준수하지 않습니다. 아래 첫 번째 레코드에 표시된 대로:
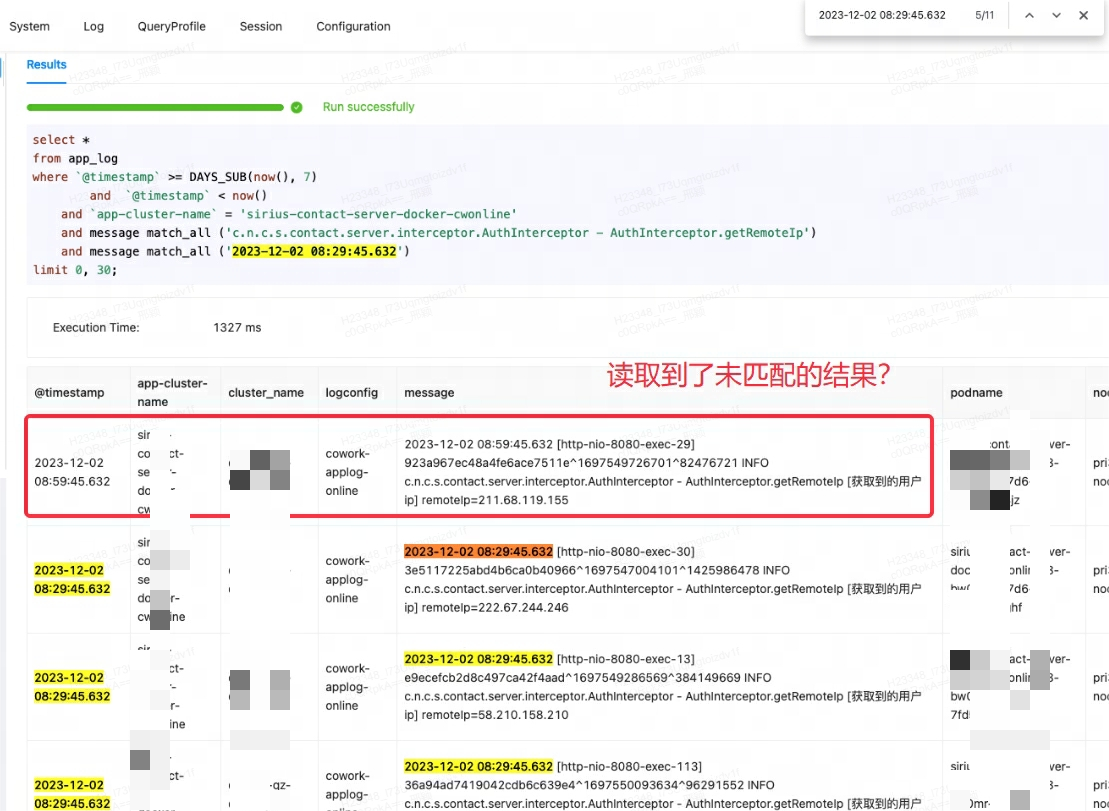
처음에는 도리스 버그인줄 착각해서 비슷한 이슈와 해결방안을 찾아보았습니다. 그러나 커뮤니티 회원들과 상의하고 공식 문서를 주의 깊게 검토한 결과 문제의 근본 원인은 match_all사용 시나리오에 대한 오해라는 사실이 밝혀졌습니다.
match_all의 작동 원리는 단어 분할이 존재하는 한 일치를 수행할 수 있으며 단어 분할은 공백이나 구두점을 기반으로 한다는 것입니다 . 이 경우 match_all의 '29'가 첫 번째 레코드의 후속 내용에 있는 '29'와 일치하므로 예상치 못한 결과가 출력됩니다.
이 경우 올바른 방법은 텍스트의 주문 요구 사항을 충족할 수 있는 MATCH_PHRASE일치를 사용하는 것입니다.MATCH_PHRASE
-- 1.4 logmsg中同时包含keyword1和keyword2的行,并且按照keyword1在前,keyword2在后的顺序
SELECT * FROM table_name WHERE logmsg MATCH_PHRASE 'keyword1 keyword2';
매칭을 사용하는 경우 MATCH_PHRASE인덱스를 구축할 때 이를 지정해야 합니다 support_phrase. 그렇지 않으면 시스템이 전체 테이블 스캔을 수행하고 하드 매칭을 수행하므로 쿼리 효율성이 저하됩니다.
INDEX idx_name4(column_name4) USING INVERTED PROPERTIES("parser" = "english|unicode|chinese", "support_phrase" = "true")
이미 데이터가 기록된 테이블의 경우 이를 활성화하려면 기존 인덱스를 삭제한 후 새 인덱스를 추가하면 support_phrase됩니다 . 이 프로세스는 테이블 전체의 데이터를 다시 쓰지 않고 기존 테이블에 증분적으로 수행되므로 작업의 효율성이 보장됩니다.DROP INDEXADD INDEX
Elasticsearch에 비해 Doris의 인덱스 관리 방식은 더욱 유연하며 비즈니스 요구에 따라 빠르게 인덱스를 추가하거나 삭제할 수 있어 더 큰 편의성과 유연성을 제공합니다.
결론
Apache Doris의 도입은 로그 및 타이밍 시나리오에 대한 NetEase의 요구 사항을 효과적으로 충족하고 NetEase Lingxi Office와 NetEase Cloud Letter의 초기 로그 처리 및 분석 플랫폼의 높은 스토리지 비용과 낮은 쿼리 효율성 문제를 효과적으로 해결합니다.
실제 애플리케이션에서 Apache Doris는 낮은 서버 리소스로 평균 500MB/s의 온라인 쓰기 트래픽과 1GB/s 이상의 최고 값을 전달했습니다. 동시에 쿼리 응답도 Elasticsearch와 비교하여 11배 이상 향상되었습니다. 또한 Doris는 압축률이 높아져 이전보다 70%의 저장 자원을 절약할 수 있습니다.
마지막으로 지속적인 지원을 해주신 SelectDB 기술팀 에 특별히 감사드립니다 . 앞으로 NetEase는 계속해서 Apache Doris를 홍보 하고 NetEase의 다른 빅 데이터 시나리오에 심층적으로 적용할 것입니다. 동시에, Doris에 관심이 있는 더 많은 비즈니스 팀과 심도 있는 교류를 통해 Apache Doris 개발을 공동으로 추진할 수 있기를 기대합니다.
오픈소스 기여
비즈니스 구현 및 문제 해결 과정에서 NetEase 학생들은 오픈 소스 정신을 적극적으로 실천하고 Apache Doris 커뮤니티에 일련의 귀중한 PR을 기고하여 커뮤니티의 발전과 발전을 촉진했습니다.
- 스트림 로드 버그 수정
- 스트림 로드 코드 최적화
- 적절한 행 집합 최적화를 찾기 위한 핫 및 콜드 계층화
- 핫 및 콜드 계층화로 잘못된 순회 감소
- 핫 및 콜드 계층형 잠금 간격 최적화
- 핫 및 콜드 계층화 데이터 필터링 최적화
- 온냉 성층화 능력 판단 최적화
- 핫 및 콜드 계층적 정렬 최적화
- FE 오류 보고 표준화
- 새로운
array_agg기능 - 집계 함수 버그 수정
- 실행 계획 버그 수정
- TaskGroupManager 최적화
- BE 충돌 수리
- 문서 수정:
- https://github.com/apache/doris/pull/26958
- https://github.com/apache/doris/pull/26410
- https://github.com/apache/doris/pull/25082
- https://github.com/apache/doris/pull/25075
- https://github.com/apache/doris/pull/31882
- https://github.com/apache/doris/pull/30654
- https://github.com/apache/doris/pull/30304
- https://github.com/apache/doris/pull/29268